
基于逆强化学习的混合动力汽车能量管理策略研究*
2023-11-09 03:56:50齐春阳宋传学宋世欣靳立强
汽车工程 2023年10期
齐春阳,宋传学,宋世欣,靳立强,王 达,肖 峰
(1.吉林大学,汽车仿真与控制国家重点实验室,长春 130022;2.吉林大学汽车工程学院,长春 130022;3.吉林大学机械与航空航天工程学院,长春 130022)
前言
混合动力汽车的主要目标是提高动力系统的效率和降低燃料消耗。在给定动力系统配置的情况下,影响混合动力汽车油耗的最重要因素是发动机和电气系统之间的功率分配比。能量管理策略(energy management strategy,EMS)是混合动力汽车的关键技术之一,需要在满足电力需求的约束下协调发动机和电气系统之间的功率分配。对于同一车型,同一行驶周期,不同能量管理策略对应的油耗相差20%[1]。因此,研究混合动力汽车的能量管理策略具有重要意义。在混合动力汽车能量管理策略的研究过程中,研究者将大部分的控制策略主要分为3 类:(1)基于规则;(2)基于优化;(3)基于学习。其中,基于规则又可以分为确定性规则和模糊性规则;基于优化可以分为全局优化和瞬时优化。基于规则的能量管理策略需要制定控制规则来确定不同驱动模式下的能源分布情况[2]。基于规则的方法优点在于,规则制度很容易开发,并且可以应用在实施控制系统中。但是规则的开发非常需要经验丰富的专家工程师的知识。与基于规则的能量管理策略相比,全局优化算法调整的参数优于确定性规则。近几年,基于学习的方法越来越受到研究者们的关注。其中,强化学习方法能够解决与实时优化方法相关的任务得到了大家的青睐。强化学习智能体根据累计的奖励能够在不同状态下采取适应的行动。重庆理工大学的庞玉涵[3]提出了一种分层机构的强化学习方法,为能量管理策略提供了新思路。北京理工大学的刘腾[4]从强化学习算法出发,探索了以强化学习为基础的能量管理策略在最优性、自适应性和学习能力下的优化,并将强化学习算法深入到实时优化过程中,为实时性的强化学习算法提供了思路。重庆大学的唐小林等[5]提出一种基于深度值网络算法的能量管理策略,实现深度强化学习对发动机与机械式无级变速器的多目标协同控制。Li 等[6]提出了一种利用优先级经验重放机制改进DQN(deep Qnetwork)模型。Chaoui 等[7]提出了一种基于强化学习的方法,用于平衡具有多个电池的电动汽车电池的荷电状态,该方法可以延长电池寿命并减少电池的频繁维护。
另外,强化学习状态之间有很强的相关性,会不同程度影响学习效果。Liu 等[8]将基于 GPS 得到的行程信息与强化学习算法结合,在状态变量中加入剩余行驶里程,仿真结果显示取得了良好的优化效果。Liu 等[9]提出一种应用数据来驱动的算法,并且成功用于能量管理策略中,实现了良好的节油性能。在基于强化学习的能量管理策略中,强化学习奖励函数设定的问题经常会被忽略。奖励函数通常是主观的和经验的,它不容易客观地描述专家的意图,也不能保证给定的奖励函数会导致最优的驾驶策略。在混合动力能量管理控制策略问题中,奖励函数的不同直接会导致训练方向的改变。直观地说,电池与发动机的参数决定训练的方向是发动机最优油耗还是电池的最优状态,奖励函数的设定掺杂了过多的人为因素。深度强化学习是智能体与环境的不断交互学习的结果,通过不断交互、不断更新策略来最大化累计奖励值。奖励值作为智能体更新策略的关键,设计奖励值时更需要具有客观理论依据,奖励函数的设计关乎到整个训练网络的方向。针对以上问题,本文提出了一种逆强化学习方法,通过反向推导权重参数并校准正向强化学习算法来优化能量管理。逆强化学习算法的目标是构造一个关于状态的奖励函数的特征向量,并通过收集合理的专家呈现轨迹来学习最优奖励函数的权重向量。这种方法能够描述专家策略,克服经验设计的随机性质。
1 混合动力汽车系统方案
混合动力汽车的结构可以理解为能量通路与控制端口之间的连接关系,它也是一个较为复杂的系统,而且具有很强的非线性特性。混合动力汽车的系统具有多变性,它是将多个非线性系统耦合而成的,建立非常精确的数学模型是极其困难的,所以更加需要统一的建模方法。在混合动力汽车构型研发中,较为基本的方法是基于模型的方法。本文中针对某款混联混合动力汽车展开研究,车型的结构如图1 所示。行星齿轮机构与驱动电机平行布置,行星齿轮机构行星架通过减振器连接至发动机端,太阳轮连接到发电机MG1,齿圈通过齿轮连接到MG2和输出轴。此外,发动机与减振器之间有一个单向离合器,即便发动机反转时也能及时自锁。当进行能量管理的模拟仿真时,需要依托仿真软件构建整车的动力学模型,还需要从整车各个部件的建模入手分别建模,主要包括电机模型、发动机模型、电池模型、变速器模型、车轮模型、驾驶员模型等,相关部件的基本参数如表1所示。
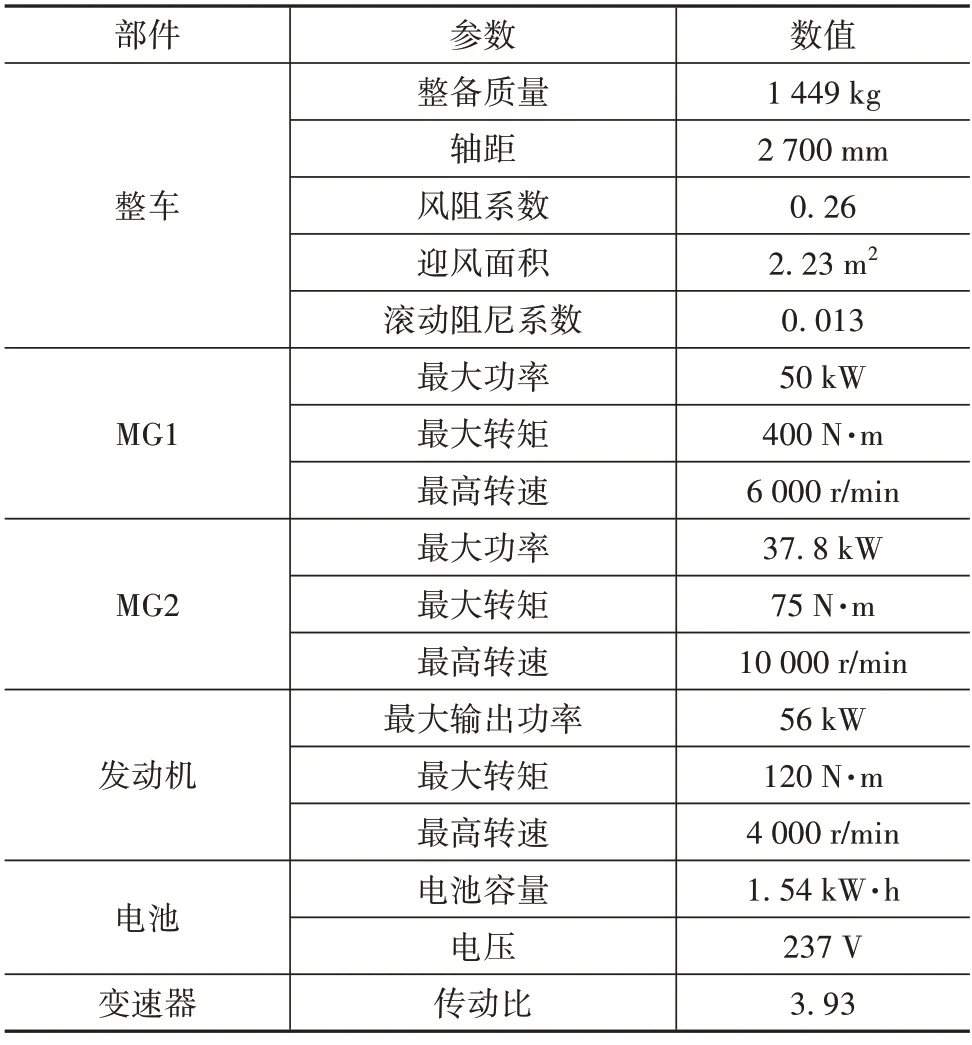
表1 本文研究对象参数
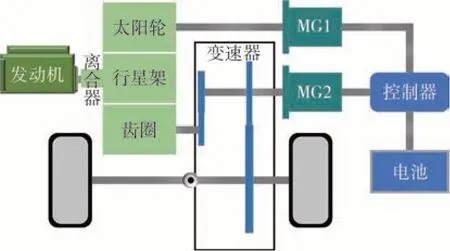
图1 本文车辆研究对象
2 逆向强化学习方法奖励函数参数匹配
2.1 基于强化学习方法的管理策略参数分析
在很多基于强化学习的能量管理策略当中,奖励函数的优化准则为在SOC 值变化范围相同下,燃油消耗尽可能的低,尽可能延长电池寿命,发动机工作在最优燃油区间。对于强化学习奖励函数还存在实验性的调参,奖励函数的构造通常具备主观经验性,不容易客观地描述专家意图,从而不能保证在给定奖励函数下智能体能学习出最优的驾驶策略。以下,列举了很多优秀的强化学习能量管理策略方法中奖励函数的设定[10-23]。
式中:r表示各个文献中的奖 励函数符号;为在不同的文献中所表示的燃油消耗率;ΔSOC表示电池SOC变化范围;α表示发动机燃油消耗的权重参数;β和ε表示奖励函数中电池的权重参数;fuel(t)表示t时刻的燃油消耗量;SOC(t)表示t时刻的SOC值;elec(t)表示t时刻的电能消耗量;SOCref表示电池初始SOC值;表示时刻τ时SOC值变化的平方;SOCmin表示最低的SOC值要求;SOCmax表示最高的SOC值要求。
一个合理的奖励函数不仅可以加速训练过程,同时可以使得策略优化的过程更加稳定。从上述的奖励函数表达式可以明确虽然能量管理强化学习方法的优化方式不同,但是基本符合以下表达式:
式中参数α与β是维持燃油消耗率与SOC 维持关系的线性权重。指定这样的加权函数优点在于能够直接使用具有标准化的强化学习算法,但是这也直接导致了在训练开始之前就需要确定权重,这对于能量管理问题是极其困难的。一方面,奖励函数需要偏重于SOC维持基本功能,经常会表现的较为保守,不能充分利用电池缓冲。另一方面,受限于目标任务,多目标任务的不同参数也无法确定。另外,在这些研究中,发动机和电池之间权衡的主观因素是不可避免的。强化学习是寻求累积奖励期望最大化的最优策略,而这种奖励方程的设置通常是人为或环境提供的。混合动力汽车环境下的强化学习任务过于复杂,而人为设计的奖励函数过于困难,且具有较高的主观性和实效性。奖励函数设置的不同导致了最优策略的不同。如果没有适当的奖励,强化学习算法很难收敛。接下来,详细阐述本文提出的逆向强化学习参数确定方法。
2.2 逆向强化学习能量管理策略任务
一般来说,在正向强化学习中,以发动机最佳工作点与电池最佳SOC变化之间的差异为优化目标来训练网络。相反,本章提出一种逆向强化学习的方法,探索其最优的参数匹配。与正向强化学习不同,在逆向强化学习中,需要利用发动机和电池的最佳状态来推导权重系数。首先将车辆作为强化学习环境,输入为从原始的行驶循环变为发动机最优工作点和电池最优工作状态。随后,将电池和发动机作为强化学习的两个智能体,通过反向强化学习得到两个智能体的权系数来指导智能体的行为。在本文当中,正向强化学习是作为逆向强化学习的一个验证过程。所以正向强化学习与逆向强化学习的状态空间与动作空间保持一致,这样正向强化学习更容易验证本文的算法。状态空间与动作空间如下:
其中,状态空间S由发动机转矩T、发动机转速n和电池SOC值组成,强化学习的动作值A由发动机需求功率Pre确定。
在本文中,逆向强化学习与正向强化学习的奖励函数都应符合如下公式:
其中,Enginerweight与Batteryreweight就是本文利用逆向强化学习方法客观的确定其权重系数。
本文逆向强化学习的流程主要分为如下4 个部分:第1 部分表示发动机和电池的最佳状态,对于发动机而言是最佳工作点,对于电池而言是保持电池SOC 值的合理稳定,最大化电池寿命,并输入到第2部分中循环训练得到参数权重系数;第2 部分是逆向强化学习的算法框架,定义最大熵逆向强化学习;第3 部分表示强化学习环境,将参数输入到环境中;第4 部分是强化学习DQN 算法。第1、2 部分结构如图2(a)所示,图2(b)显示的是第3、4 部分的具体构成。
综上,该算法的具体流程如下:基于专家轨迹和强化学习基础,确定奖励函数为状态和动作的函数。然后,将新的权重系数输入到奖励函数中,输出到第3 部分进行正向强化学习。在该逆向强化学习算法中,将发动机和电池视作多智能体结构,以最佳状态输入到强化学习网络中。合理的奖励函数可以加快训练,获得更加稳定的策略优化进程,能量管理策略也会趋向于更稳定的方向训练。在逆向强化学习中,可以把奖励函数看做是状态值与权重系数相乘的结果,表达式如下:
式中:i表示分量数;r(si,ai)表示(si,ai)状态动作的奖励值;fi表示奖励函数第i个特征分量;θi表示奖励函数权重向量第i个特征分量;d表示奖励函数中特征向量的个数,在本研究中,采用双智能体强化学习结构,电池和发动机双代理,所以d取值为2。
在强化学习能量管理策略中,专家策略很难用表达式表达。从发动机出发,专家策略是使得发动机在最佳工作点附近工作;从电池出发,专家策略是使得电池SOC变化在合理的范围之内。所以本节通过逆向强化学习的方式探索电池与发动机之间的权重系数。逆向强化学习的方法为最大熵逆向强化学习。强化学习在面对环境中随机因素时,双智能体会产生不同的专家轨迹。首先,定义一个最佳能量管理控制策略的轨迹ξ:
这条轨迹的奖励函数记为r(ξ):
在面对能量管理策略任务时,环境是具有不确定性的随机因素,所以肯定会存在多条专家轨迹,记为m,专家的特征期望为
在最大熵理论当中,具备最大熵分布的模型是最优模型,对于能量管理控制策略的问题,在已知发动机最优工作点和电池最优SOC变化范围的情况下,利用最大熵模型就可以得到奖励函数的参数值。最大熵优化问题可以表示为
式中p(ξi|θ)表示在参数θ下,发生轨迹ξi的概率。最大熵逆强化学习的轨迹概率可以表示为
在最大熵逆向强化学习中,混合动力能量管理的专家轨迹出现的概率越大,说明训练学习到的奖励函数越能反映出混合动力汽车能量管理任务隐含的分布。初始化的优化目标为最大化专家轨迹的概率分布:
式中fueldemo为专家演示轨迹,也是混合动力汽车最佳发动机工作点,通常将原始优化问题转化为最小化问题。优化目标变为最小化损失函数J(θ)。
其中,优化目标为
式中:rθ(si,ai)表示当前状态动作的奖励值;π(aj|sj)表示当前状态动作对(si,ai)出现的概率。
由于匹配的函数采用的是能量管理策略抽样轨迹拟合,因此可以用梯度法得到全局最优解。关于优化函数J(θ),用奖励函数的权重θr求导:
最终,依据上式可以学习到奖励函数的全局最优解。根据优化后的θr参数,可以推导出当前的奖励函数rθ(si,ai),并将求解得到的奖励函数作为前向强化学习的优化目标,更新当前策略,直到奖励函数更新小于给定的阈值。用最大熵逆强化学习获得奖励函数权重的伪代码如表2所示。
3 逆向强化学习参数确定结果分析
3.1 逆向强化学习奖励函数权重确定
在图3 中,蓝线表示最佳发动机运行曲线。在求解奖励值权重的过程中,考虑到数据量过大,占用了较高的计算成本,所以将发动机map 图划分为528 个区域,每个区域由一个10×10 矩阵组成。到达每个矩阵内的工作点的奖励值的权重作为该矩阵的权重值。如果存在多个工作点,则计算各工作点权值的平均值作为矩阵的奖励权值。由于其他区域的奖励值并不高,因而将奖励值的权重分别标记在蓝色最优曲线上。通过逆强化学习算法得到了发动机油耗的加权系数。图4显示了电池SOC变化时电池内阻和电动势的变化。从图4 中可以看出:电池SOC 在0.2-0.8之间工作,可获得稳定的电动势;电池内阻在0.3-0.7 范围内较低,这个范围的效率较高,即SOC在0.3-0.7 范围内设置为电池的最佳状态。经过正则化后得到的权系数如图5 所示。权重系数结果如式(31)所示。
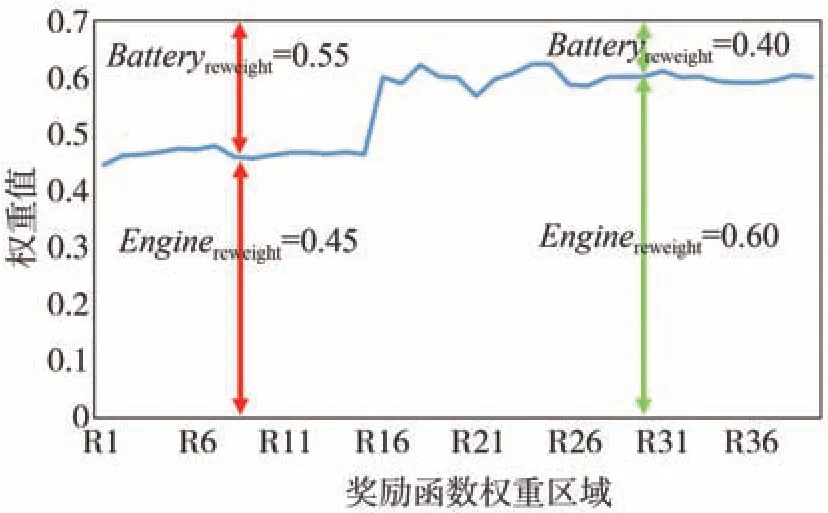
图5 正则化后的加权系数
从图5可以看出:在R1-R16区间(R1-R16区间具体对应转速参见图3)内,发动机转速n为1 000 r/min,发动机代理的加权系数为0.45,电池代理的加权系数为0.55;在其他区间中,发动机代理的加权系数为0.6,电池代理的加权系数为0.4。
式中:Enginerweight代表发动机代理的加权系数;Batteryreweight代表电池代理的加权系数。
3.2 正向强化学习
利用上节中得到的奖励函数参数值,本节从油耗值、SOC 变化值以及动力源转矩变化3 种典型特征验证该权重值的优越性。将车辆的初始状态设置为:油箱处于最大储油容量的状态和初始SOC 值为0.65。本文的训练工况 是CLTC,IM240、FTP75、WVUINTER 和JN1015。图6 显示了新建的行驶工况,并将其作为本文的测试工况,表3 显示了在终值SOC大致相同的情况下,5个典型驾驶周期和新建工况中强化学习算法和具有更新的权重系数的强化学习算法之间的比较。其中对比值表示逆向强化学习算法对应强化学习基础算法的油耗值减少率。
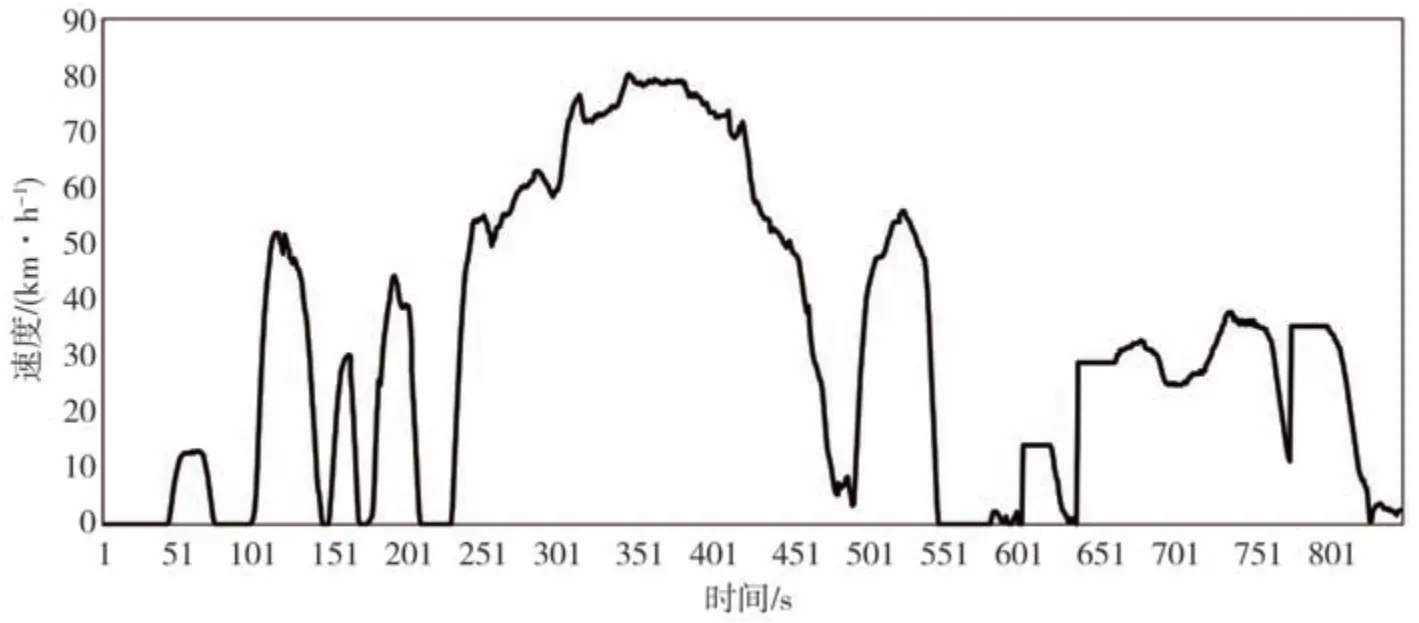
图6 新建工况图
为了更加直观地显示燃油消耗,图7显示出5种典型工况的发动机油耗直方图,并且使用逆向强化学习权重值作为训练方向,从结果看出油耗明显低于其他两种算法。Q 学习(Q-learning)算法是提出时间很早的一种异策略的时序差分学习方法;DQN则是利用神经网络对 Q-learning 中的值函数进行近似,并针对实际问题作出改进的方法;而DDPG(deep deterministic policy gradient)则可以视为DQN(deep Q-network)对连续型动作预测的一个扩展。DQN 与DDPG 都是强化学习的经典算法,本文以这两个算法为基准进行对比。DQN-IRL(deep Qnetwork-inverse reinforcement learning)表示拥有逆向参数的DQN 算法,DDPG-IRL(deep deterministic policy gradient-inverse reinforcement learning)表示拥有逆向参数的DDPG算法。
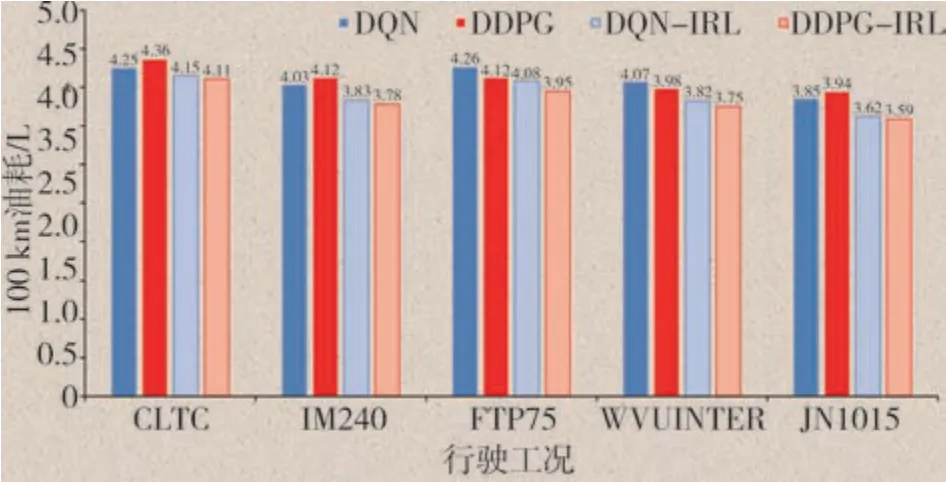
图7 发动机油耗直方图
图8 显示了5 种训练工况的奖励值变化,工况1到工况5 分别是CLTC、IM240、FTP75、WVUINTER、JN1015。从图中可以看出各个算法都朝着最大奖励值的方向稳步推进,最终达到平滑。另外,图9 揭示了在测试工况下,DQN、DQN-IRL、DDPG、DDPGIRL的SOC值变化曲线,可以看出所有4种算法都处于较低的内阻和较高的电池效率区间,从而也证实了强化学习算法在解决能量管理问题方面的优越性。虚线代表IRL 算法,与另外两种经典算法对比,SOC值的波动较小,在同等使用时间下,电池的使用寿命会更长。
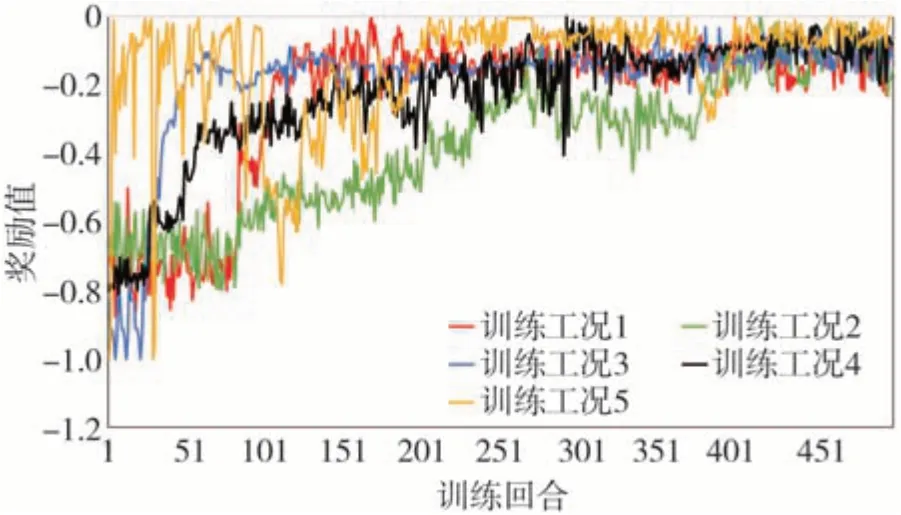
图8 奖励价值趋势图
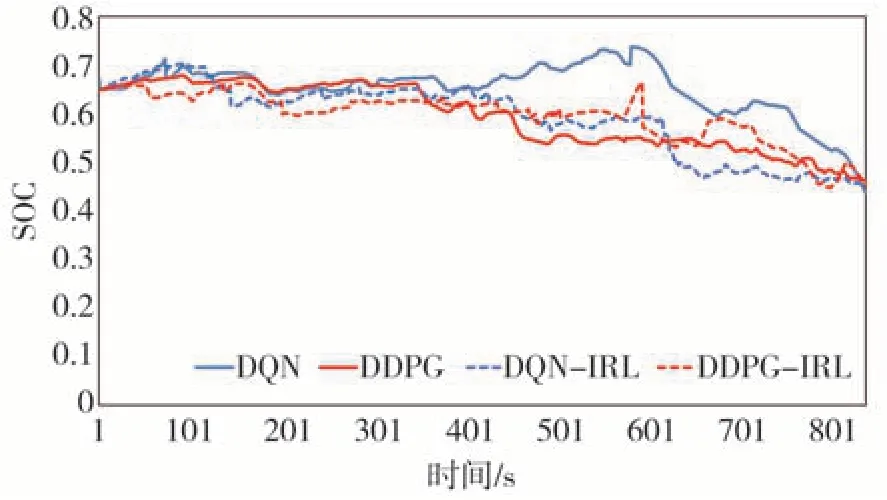
图9 4种算法的SOC变化曲线
图10 和图11 分别显示了以DQN 算法为例拥有逆向参数前后的发动机转矩、MG1 转矩、MG2 转矩变化,可见添加逆向强化学习参数后,发动机起停次数减少,MG1与MG2转矩变化平稳。
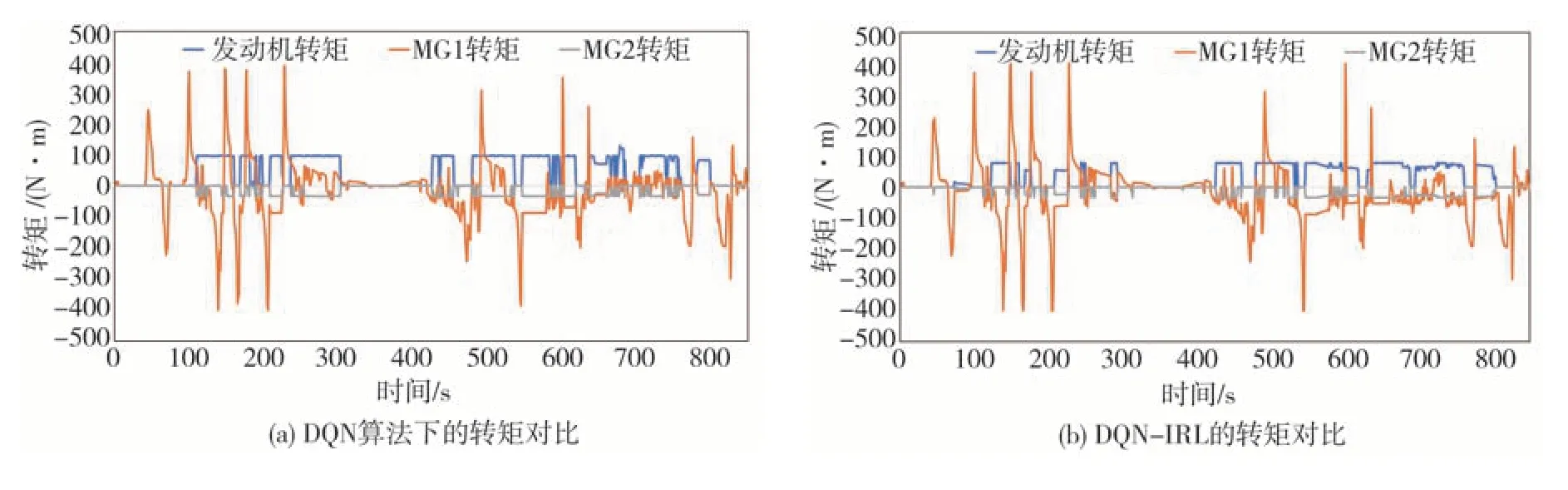
图10 DQN算法发动机转矩、MG1转矩、MG2转矩对比
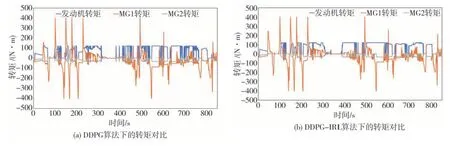
图11 DDPG算法下发动机转矩、MG1转矩、MG2转矩对比
4 硬件在环实验验证
4.1 硬件在环实验台搭建
为了评估本文所提出的能量管理策略的实际应用潜力,实施并分析了硬件在环实验。如图12 所示,实验系统由混合动力模型、驾驶员操作系统、虚拟场景系统、传感器系统、ubuntu RT 系统和车辆控制单元组成。虚拟场景系统为驾驶员提供了真实的驾驶环境,使其接近真实的驾驶体验,还可以通过数据交互为驾驶员提供丰富的交通环境信息、道路信息和地理位置信息,以支持交通能量管理策略的研究和测试。在虚拟场景系统中,道路信息和地理位置信息是非常重要的。通过这些信息,驾驶员可以了解自己当前所处的位置和行驶方向,以及周围的道路状况、车流量等信息。此外,交通环境信息也非常重要,例如交通信号灯、车辆速度、行驶方向等信息,这些信息可以为驾驶员提供实时的交通情况,帮助其做出正确的驾驶决策。数据交互也是虚拟场景系统的一个重要特点。通过数据交互,虚拟场景系统可以与其他系统进行信息交换,例如车辆控制系统、交通信号控制系统等,以实现交通能量管理策略的研究和测试。同时,数据交互还可以支持多车协同驾驶和交通模拟等功能,增强虚拟场景系统的实用性和可扩展性。车辆控制系统的主要作用是实施所提出的策略并将控制参数输出到执行。驾驶员的操作信息全部反馈给转向系统,而车速状态信息和机电系统的状态由实时仿真系统提供。
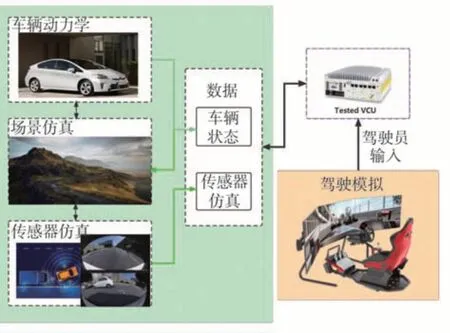
图12 硬件在环实验系统构成
集成系统如图13 所示。本文的硬件在环平台是课题组自研的硬件设备,其中,下位机是ubuntu RT 系统,上位机是自研的场景系统。ubuntu RT 系统采用的是amd Ryzen5 处理器,6700XT显卡。在图13 中,将数据检测系统与驾驶员操作系统相结合,驾驶员操作系统显示在驾驶员下方。基于现有配置和技术条件,利用CAN 通信技术实现数据交互,实时获取转向盘角度、加速度和制动踏板数据。然后将数据输入车辆控制单元(VCU)。

图13 集成系统和驾驶员操作系统
4.2 硬件在环数据结果分析
为了进一步验证本文逆向强化学习能量管理策略,本节在4.1 节构建的硬件在环设备基础之上进行验证实验。图14 表示在该硬件在环设备上运行的一段实际工况,表4 显示了原始的DQN/DDPG 算法与本文算法在HIL 硬件在环测试下的油耗对比结果,在初始SOC值与终止SOC值变化大致的前提下,可以看出具有本文权重值的强化学习算法油耗值较低。
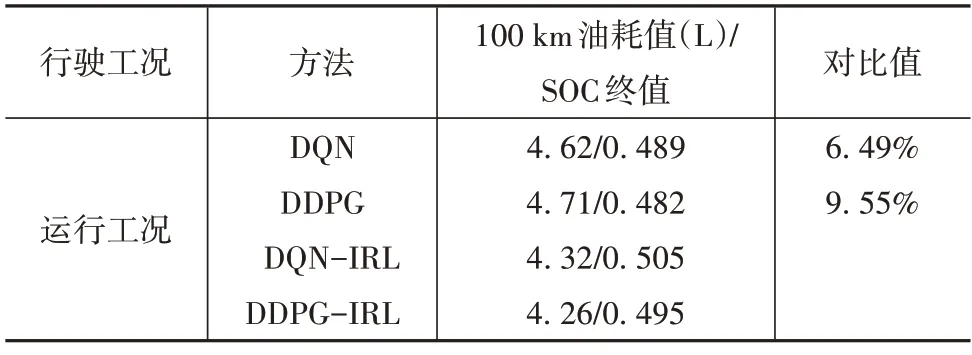
表4 仿真数据与HIL数据在燃油消耗方面的对比
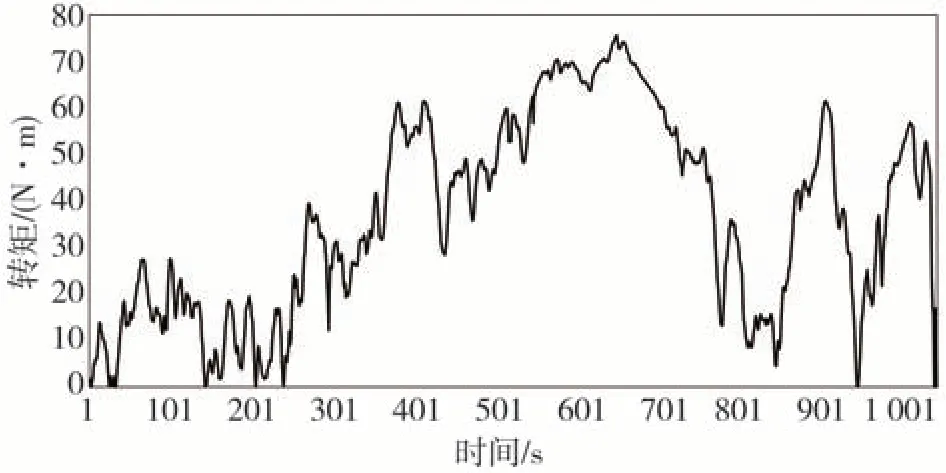
图14 硬件在环场景中运行的工况
图15 和图16 显示了电池SOC 值在仿真测试与HIL 测试中的变化范围,黑线表示在离线仿真情况下的电池SOC 变化,红色线表示在HIL 下的电池SOC 值变化。从图中可以看出在实时策略下,两种策略都可以保持良好的电量范围,电池的性能和状态也在较佳的状态,电池性能正常,可以提高整体的生态驾驶策略的可靠性和稳定性,确保系统顺畅运行。图17 与图18 分别显示了DQN 算法和DDPG 算法与DQN-IRL 算法和DDPG-IRL 算法在该硬件在环环境下的发动机转矩、发电机MG1 转矩、电动机MG2 转矩的变化对比图。蓝色线代表发动机转矩,橙色线代表MG1转矩,灰色线代表MG2转矩。从图中可以看出,具有逆向强化学习参数的算法发动机转矩优化明显,减少了发动机起停。

图15 HIL下DQN算法的SOC值变化
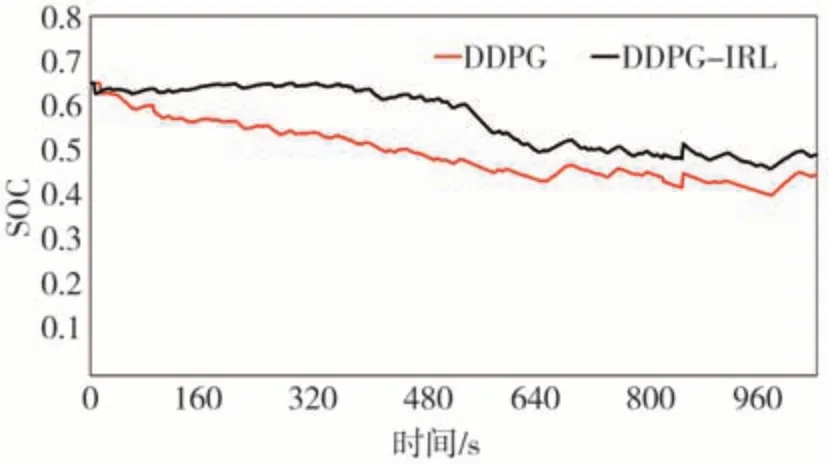
图16 HIL下DDPG算法的SOC值变化
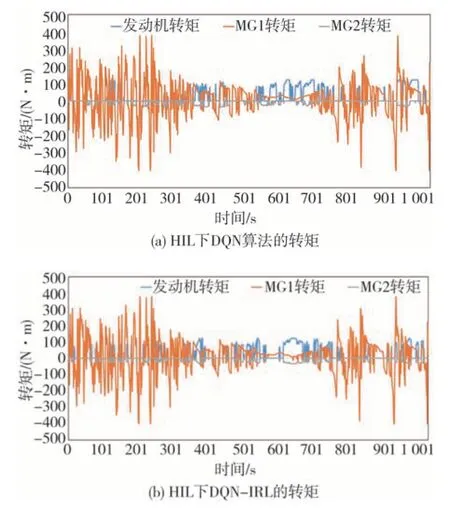
图17 HIL下DQN与DQN-IRL转矩对比
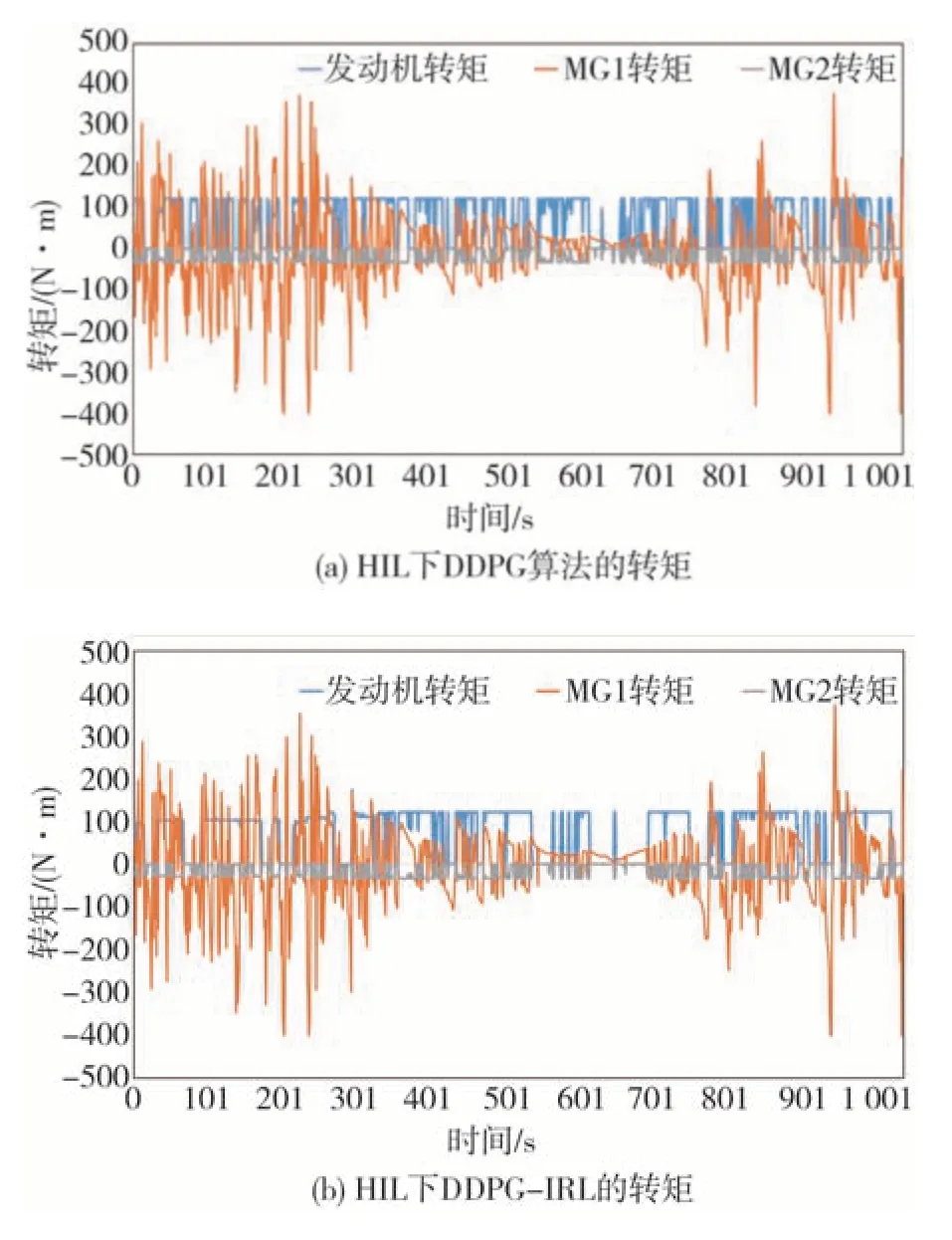
图18 HIL下DDPG与DDPG-IRL转矩对比
5 结论
本文对混合动力汽车能量管理策略的奖励值函数展开研究。强化学习的智能体与环境交互的引导方向是由奖励函数决定的。然而,目前的奖励功能设计仍然存在缺陷。逆向强化学习是一种从演示中学习的特殊形式,它试图从提供的例子中估计马尔可夫决策过程的奖励函数。奖励函数通常被认为是对任务最简洁的描述。在简单的应用中,奖励函数可能是已知的,或从系统的性质中很容易推导出来,并应用到学习过程中。在大多数强化学习能量管理策略中,奖励函数的设计具有主观性和经验性,很难客观地描述专家的意图,发动机和电池之间的权衡不可避免地存在主观因素。但是,在给定的奖励函数下,该条件不能保证智能体学习到最优驾驶策略。另外,混合动力汽车环境下的强化学习任务过于复杂,而人为设计的奖励函数过于困难且高度主观和经验。奖励函数设置的不同会导致最优策略的不同。如果没有适当的奖励,强化学习算法很难收敛。针对这些问题,本文提出了一种基于逆向强化学习的能量管理策略,获取专家轨迹下的奖励函数权值,并用于指导发动机智能体和电池智能体的行为。该方法的主要过程是利用逆强化学习得到的权重系数对奖励函数进行修正,并根据最新的奖励函数输入正向强化学习任务。最后,将修正后的权值重新输入到正向强化学习训练中。从油耗值、SOC 变化曲线、奖励训练过程以及动力源转矩等方面,表明该算法具有一定的优势。本文的主要成果总结如下:
(1)从电池荷电状态的变化值来看,荷电状态的变化区间处于电池效率高、内阻低的区域,燃油消耗处于较低水平;
(2)逆向强化学习获取的奖励参数结果是分段式的;
(3)在强化学习训练过程中,奖励值稳步向最大方向前进,最终达到平稳状态,训练有效。
猜你喜欢
建材发展导向(2022年10期)2022-07-28 03:03:58
音乐天地(音乐创作版)(2022年1期)2022-04-26 13:51:38
大众投资指南(2021年23期)2021-12-06 05:46:40
建材发展导向(2021年12期)2021-07-22 08:06:32
建材发展导向(2021年9期)2021-07-16 07:11:10
四川冶金(2018年1期)2018-09-25 02:39:26
中学课程辅导·高考版(2017年6期)2017-06-13 07:21:57
通信电源技术(2016年1期)2016-04-16 04:57:26
电机与控制应用(2015年3期)2015-03-01 03:49:59
应用技术学报(2014年3期)2014-02-28 14:52:32
