
基于文本挖掘的食品添加剂知识图谱构建和应用
2023-11-07 11:45张寅升秦贝贝向剑勤张燕新王海燕
食品工业 2023年10期
张寅升,秦贝贝,向剑勤,张燕新,王海燕*
浙江工商大学(杭州 310018)
食品添加剂是指为改善食品的品质和色、香、味以及为防腐和加工工艺的需要而加入食品中的化学合成或天然的物质[1]。添加剂的非法、过量使用和滥用情况持续存在,给民众健康、行业发展以及政府监管带来挑战。围绕食品安全及添加剂监管问题,国外部分学者认为食品安全监管是各利益主体之间的博弈[2]。研究主题也多是关注于食品安全本身及社会背景,如消费者行为[3]及政府监管方式等。国内学者则总结分析添加剂滥用引发的安全问题并提出对策[4-5]。同时,添加剂作用机理研究、检测技术研发和膳食开发等方面的研究也未止步[6-8]。
从现有文献来看,针对食品安全及食品添加剂问题的研究大多集中在完善管理机制、提高添加剂检测技术水平、发现添加剂的新应用领域等方面,运用文本挖掘分析食品添加剂的数据驱动型研究仍处于新兴阶段[9]。基于以上背景,文章通过关联规则学习与文本挖掘技术,从政府抽检数据和新闻通报等多渠道信息来源中获取不同食品与相应食品添加剂的关联强度/支持度,构建可视化的知识图谱,借以直观了解特定食品易含有的非法添加剂和食用添加剂种类,并应用时空演化分析,得到食品安全事件的区域性和季节性特征。
1 方法
1.1 方案思想
数据资源是准确分析问题和科学决策的基础,获取到包含食品实体与添加剂实体之间关联关系的知识图谱是解决分析问题的关键。食品安全问题的信息具有极强的主题性,因此若要构建食品实体与添加剂实体的知识图谱、实现食品安全事件的时空演化,需要构建食品安全主题语料库并从中提取食品、添加剂、时间、地点等关键实体。基于上述逻辑,文章中所用到的整体研究方案见图1。
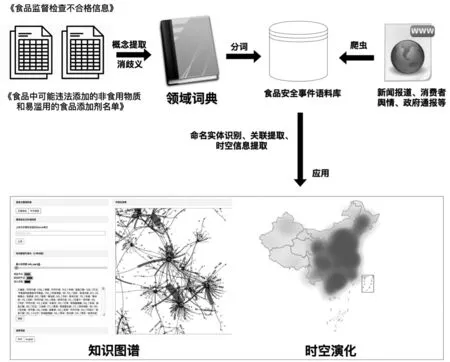
图1 整体研究方案
1.2 方案步骤
第一步:数据采集与清洗。数据采集包括官方发布的食品添加剂界定文件以及通过网络爬虫工具收集食品安全相关的新闻报道、事件通报、网购评论、消费者舆情等文本数据。数据清洗时完成无用字符的删除以及数据格式的转换。网络评论、消费者舆情等网络文本可能涉及企业、法人或消费者的隐私信息,针对此类数据,在数据采集和数据清洗阶段将使用脱敏和匿名化技术处理。
第二步:构建食品安全事件语料库。语料库中的每条文本记录包含了食品安全事件的关键信息,如事件时间、地点、事件原因、不合格食品种类、非法或超量添加剂种类等特征。通过设置定期运行的爬虫脚本,可以不断更新和扩展该语料库。
第三步:构建知识图谱。对语料库中的信息完成分词与词频统计操作,并进行基于词典的命名实体识别(Dictionary-based named entity recognition,NER)与关联提取,根据实体共现频率构建食品和添加剂的知识图谱,并使用力导向图进行知识图谱的交互可视化。
第四步:时空演化分析。时空演化的可视化使用cpca(chinese_province_city_area_mapper)实现,cpca可用于提取简体中文字符串中省、市和区,并能够进行绘图。在提取语料库中的时空信息后应用cpca进行图像的绘制。
1.3 相关算法原理
在构建食品实体与添加剂实体的知识图谱时用到了力导向图,其依托于力导向布局可视化算法实现,在此对相关算法的原理进行介绍。
1.3.1 力导向布局算法
力导向布局算法的原理是自然界中电子之间的相互作用。在力导向布局算法中,各节点和连线的位置是通过斥力和引力的作用不断更新的,在力的作用下节点经过不断位移之后趋于平衡[10]。
力导向布局算法中的引力与斥力按式(1)和(2)计算。
式(1)中:d为两节点之间的笛卡尔距离;K为调节全局节点之间的斥力常量;符号“-”为斥力的表征方向。
式(2)中:H为弹簧力的倔强系数;Li为第i层的默认弹簧长度,且Li/Li+1=I,即第i层和第i+1层的边长比值为一个固定常数I[11]。
力导向布局算法因其结果具有良好的对称性和局部聚合性而被广泛应用于知识图谱和复杂网络的可视化中。
2 试验结果
2.1 数据采集与清洗
文章针对食品安全问题,使用了五类数据来源,见表1。其中从《食品监督抽查不合格信息》《食品中可能违法添加的非食用物质和易滥用的食品添加剂名单》中整理出食品和添加剂的术语,作为初始的领域词典。从《中国食品安全网-抽检通告》《食安网-食品安全专栏》《食安网-曝光台专栏》中挖掘食品安全事件中食品实体与添加剂实体的关联关系及食品安全事件的时空实体,为构建知识图谱和时空演化分析等应用奠定基础。

表1 数据来源
2.2 构建语料库
2.2.1 构建初始领域词典
首先,从《食品监督抽查不合格信息》《食品中可能违法添加的非食用物质和易滥用的食品添加剂名单》中获取添加剂的术语,并手动添加缺失的添加剂术语,确定最终的添加剂名单。然后,按照(食品,添加剂,关联强度)的格式对获取到的食品和对应添加剂等数据进行提取处理,获取到4 548种食品种类、275种添加剂及7 075组表示食品与相应添加剂关联强度的组合信息。
2.2.2 构建食品安全事件主题语料库
食品安全事件的关键信息包括事件时间、地点、事件原因、不合格食品种类、非法或超量添加剂种类等特征。通过网络爬虫工具收集“中国食品安全网-抽检报告”“食安网-食品安全专栏”“食安网-曝光台专栏”中与食品安全相关的文本数据,对初始领域词典进行补充,并根据食品安全事件的相关特征构建食品安全事件语料库,最终得到一个包含13 698份文本的专题语料库。
2.3 知识图谱构建
2.3.1 命名实体提取
2.3.1.1 分词与词频统计
常用的分词工具有jieba、HanLP(汉语言处理包)、SnowNLP(中文的类库)、Jiagu(甲骨NLP)、pyltp(哈工大语言云)等,通过对不同分词工具的效果进行测试发现,Jiagu(甲骨NLP)在MSR(微软亚洲研究院语料库)、PKU(人民日报语料库)等多个数据集上表现最优。因此,最终选用Jiagu(甲骨NLP)对所获得食品安全事件主题语料库进行分词,接着利用遍历对关键词进行词频统计并实现词云可视化。
2.3.1.2 词云可视化
对语料库中的食品实体与添加剂实体进行词频统计与可视化,词云可视化效果见图2。

图2 词云可视化
通过词云可视化可以清晰关注到语料库中食品种类和添加剂种类出现的频率。在食品种类中,茶叶的出现次数最多;在添加剂种类中,铅和镉的出现次数居于首位。
2.3.2 构建知识图谱
2.3.2.1 知识图谱的构建
知识图谱构建的依据是食品实体和添加剂实体的共现频率(关联强度),语料库中食品实体与添加剂实体关联强度前十的组合见表2。

表2 食品实体与添加剂实体的关联强度(前10位)
这十条语义关联反映了不恰当使用食品添加剂的最典型、最广泛的几个场景,下面将逐一分析,并为监管部门提供重点抽检参考。
鳊鱼和黄鳝中检测出环丙沙星的频率高居榜首。环丙沙星(ciprofloxacin,CIP)是恩诺沙星(enrofloxacin,ENR)在动物体内发生脱乙基反应生成的具有活性的代谢产物,具有毒副作用且极易产生耐药性。恩诺沙星是第一个动物专用的抗生素,人若是长期使用则会影响软骨发育,产生畸形。目前NY 5071—2002《无公害食品渔用药物使用准则》[12]已将环丙沙星列为禁用渔药。GB 31650—2019《食品安全国家标准食品中兽药最大残留限量》[13]将水产动物中ENR及其代谢产物CIP的总残留限量定为100 μg/kg,但近年来在各类食品的抽检中,常有在淡水鱼中检测出超标恩诺沙星的问题。
在年糕中检测出的脱氢乙酸是能够抑制酵母菌、霉菌繁殖的防腐剂,如按照国家规定的剂量使用食用后不会在体内残留,但如果超量,则会造成皮肤问题,在2021年已被禁用;在豇豆中检测出的甲氨基阿维菌素苯甲酸盐(甲维盐)则是一款常用绿色生物杀虫剂,少量残留对身体无害,但若是长期使用甲维盐超标的食品则会对人体造成影响;海蜇中的铝是由于多次使用盐矾造成的,高浓度的铝残留会迫害人体肾脏和神经系统;香蕉和老姜中检测出的噻虫胺则是一种新型杀虫剂,与常规农药无交互抗性,但仍是要在标准剂量范围内使用。
2.3.2.2 知识图谱的可视化
前文完成各种食品类型和相应添加剂的关联强度/支持度的提取,形成了食品实体和添加剂实体的知识图谱,为使食品实体与添加剂实体的关联情况更清晰直观,提高关联信息的可解读性,文章基于Apache ECharts使用力导向图实现了知识图谱Web端的交互可视化,效果见图3。
通过对图3的观察可以得知,得到的关于[食品,添加剂,关联强度]的知识图谱直观展示了同一食品类型与不同添加剂之间的关联强度关系以及不同产品类型容易检测出哪些添加剂。
以我国大宗淡水养殖鱼类鳊鱼为例,鳊鱼实体与添加剂实体关联强度知识图谱见图4。在此次爬取的数据中,在鳊鱼中检测出了孔雀石绿、氯霉素、硝基呋喃代谢物、地西泮、培氟沙星、环丙沙星、恩诺沙星、磺胺类药物和铝共9种添加剂。

图4 鳊鱼实体与添加剂实体关联强度知识图谱
其中:孔雀石绿、氯霉素、硝基呋喃代谢物因致癌、致畸、引起再生障碍性贫血等副作用被列为禁用药物[14];地西泮则是第二类精神药品,有致癌风险;培氟沙星是一种通过干扰DNA的复制和菌体蛋白的合成发挥作用的抗生素,已被停用;起杀菌、防腐作用的环丙沙星、恩诺沙星、磺胺类药物和铝(盐矾的残留)常在鳊鱼的加工环节中用到,但是常被检测出超标,如环丙沙星和恩诺沙星的含量之和要<100 μg/kg、磺胺嘧啶等12种磺胺类总量要<100 μg/kg[15]。
以上数据说明在鳊鱼的加工制作中滥用环丙沙星、恩诺沙星、磺胺类药物和盐矾(残留物为铝)较为普遍,是监管部门、消费者及相关上下游企业应重点关注的食品质量安全项目。综上,构建出食品与相应添加剂的知识图谱后,食品与添加剂之间的关系更为直观,能够提升社会公众以及相关部门对食品安全现状的认知,并指导后续的购买、抽检、政策制定等行为。
2.4 时空演化可视化
知识图谱本质上是由具有属性的实体通过关系链接而成的网状知识库,单独使用难以直观表示食品安全事件的分布以及发展态势,时空演化的可视化则充分利用了从新闻报道、网络舆情等文本数据中实时提取食品安全事件的时间和地理信息,为特定的食品安全事件渲染时空演化过程,使得读者了解重大事件的起源、发展和消亡,以及不同食品的区域性和季节性风险特征。
根据语料库中食品安全事件的时空信息,对2014—2022年间的数据以三年为一组进行可视化,同时按照季度分类进行可视化,得到如图5和图6所示的年份分布图和季度分布图。从图5和图6中可以直观看出在不同年份下食品安全事件发生的分布特点以及各季度下食品安全事件发生的分布特点。图中颜色越深,则表示该区域安全事件发生的频率越高。

图5 食品安全事件年份分布图

图6 食品安全事件季度分布图
以上介绍的知识图谱交互可视化及时空演化技术,有望推广到更多的应用场景中,能够发现研究对象之间的隐含联系,为决策行为提供支撑依据。
3 结语与讨论
3.1 主要贡献
3.1.1 开放的、自动定期更新的专题语料库
基于目前由于食品添加剂相关数据多源异构造成的问题,初步整合互联网上的分散数据,部署了一个支持公开访问、可自动更新的食品添加剂专题语料库。该语料库可以作为研究食品安全及食品添加剂问题的基础性工具,提供已经整理好的添加剂名单,相关研究可以基于此语料库开展。
3.1.2 开放的、自动定期更新的可视化知识图谱和时空演化
表示食品实体与添加剂实体关联关系的可视化知识图谱以及表示食品安全事件区域性、季节性风险特征的可视化时空演化同样是自动更新且可公开访问的。政府监管部门、研究同行及其他想要了解食品安全问题的群体,均可通过此种方式对食品添加剂不恰当使用的实时情况以及食品安全事件的时空演化过程有一个直观的掌握。
3.2 讨论及展望
针对研究的不足之处,为能够更简便、准确地为决策行为提供依据,表示食品实体与添加剂实体关联度的知识图谱仍需不断完善,未来的研究可以从以下问题进行展开。
3.2.1 语义粒度的细化处理
研究在爬取添加剂实体信息时,未将添加剂进行细化分类,在实际应用中,添加剂可以按照不同的性质分为食用/不可食用,抑或是加工合成/天然形成,还可按照作用和功能分类为抗氧化剂、漂白剂、着色剂和营养强化剂等[1]。后续工作可以考虑将分类信息作为添加剂实体的属性,细化语义粒度,构建更加详细的知识图谱应用。
另外,目前只是对食品实体是否含有添加剂进行提取,而未对添加剂的含量进行判定和约束。科学表明,符合国家标准的合理适量的食品添加剂使用并不会对人体健康产生威胁。因此,后面还可以考虑将提取到的添加剂含量融合到语义关联强度的计算中。
在时空演化应用中,后续可以考虑细化到市县级层次,在各个省份内做时空分析,以获取地域性更强的时空演化规律。
3.2.2 新命名实体的处理
随着食品技术和化学工业的发展,新型食品及新食品添加剂的产生是不可避免的,准确高效地识别新的命名实体是一个重要挑战。采用经典的基于词典(dictionary-based)的方法,为发现新出现的命名实体,需要持续及时地更新领域词典。为克服该不足,后面可以尝试基于规则(rule-based)和代表最前沿(state-of-the-art,SOTA)的基于深度学习(deep learning-based,DL)的方法。其中,基于深度学习的命名实体识别方法能够基于海量文本数据,习得各种单词之间的语义和句法关系,其鲁棒性和有效性得到了保证[16]。
3.2.3 APP/小程序的开发
专题语料库、知识图谱以及代码库可服务于研究机构和学者的二次开发及科研,但对于普通消费者群体,存在一定的技术壁垒。为此,后续将进行APP/小程序的开发,提供面向消费端的知识图谱和时空演化等应用,并定期推送食品添加剂相关的事件统计信息。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
中国计算机报(2021年9期)2021-04-26
小学生学习指导(低年级)(2020年11期)2020-12-14
天津外国语大学学报(2020年1期)2020-03-25
作文大王·低年级(2018年10期)2018-12-06
小猕猴智力画刊(2016年5期)2016-05-14
华南农业大学学报(社会科学版)(2015年1期)2016-01-11
语言与翻译(2015年4期)2015-07-18
计算机与网络(2014年1期)2014-03-25
中国质量与标准导报(2013年8期)2013-03-11
