
一种基于PCIE 总线的高性能数据传输架构设计
2023-11-05 03:33翟栋梁丁志辉
现代电子技术 2023年21期
洪 畅,翟栋梁,丁志辉
(中国船舶集团有限公司第七二四研究所,江苏 南京 211153)
0 引 言
数据传输系统被广泛应用于雷达、遥感、通信、图像处理等领域,随着电子技术的高速发展,电子设备或系统的功能复杂度不断提高,数据处理能力也大幅增强,因此数据传输系统需要满足数据吞吐量大、传输带宽高的特点[1-8]。为了充分发挥FPGA 可编程的优点,业内通常将FPGA 设计为数据接口,主要作用是接入数据采集前端发送过来的数据,并通过高速通信总线发送给数据处理后端完成处理,例如CPU、GPU、DSP 等,而FPGA 与后端处理节点之间的传输带宽和效率成为制约系统处理性能的关键因素[9-11]。PCIE 总线由于其具有高带宽、低延迟的优点,目前被广泛应用于高性能数据传输系统中。国内外对于基于PCIE 总线的DMA 数据传输架构开展了深入研究,能够实现较高吞吐量的数据传输,但是多数方案存在带宽利用率不高的问题,或者往往仅聚焦于传输效能的提升而忽略后端数据解析对系统资源和性能的开销,并且通用性和可移植性较差。文献[10]设计了一种PCIE DMA 控制器,通过简化状态机流程来提高带宽利用率,但该方案没有考虑数据流传输时后端处理节点的数据解析开销。文献[11]设计了一种多通道视频数据传输系统,通过降低PIO 写入延迟和动态拼接等措施实现高效传输,但该方案通用性和可移植性较差。文献[12]设计了一种DMA 数据传输系统,在X4 gen1 下最大DMA 写速率为793.2 MB/s,并没有充分利用PCIE 通信带宽。文献[13]实现了一种多通道DMA 传输系统,针对数据流传输设计了专用的数据解析机制,但该方案基于阻塞式DMA 实现,传输效率还有提升空间,并且可扩展性较差。
针对上述问题,本文基于PCIE 总线设计了一种高性能数据传输架构,采用分散-聚集式DMA 传输方式,通过优化传输流程进一步提升传输效率。本架构中传输参数用户可配置并且描述符结构可扩展,因而大大增强了本设计的适应性和可移植性,并且通过反馈数据特征参数的方式可以有效解决后端数据解析开销大的问题,能够满足诸如雷达信息处理、图像处理等应用场景中海量数据流传输和实时解析的需求。
1 PCIE 总线
PCIE 总线采用端点到端点的连接方式,通过串行差分信号进行传输,其层次结构由低到高分为物理层、数据链路层和事务层[14]。物理层确保数据传输的物理环境和电信号符合要求,并完成链路训练和状态管理;数据链路层定义了一系列的DLLP(数据链路层包)来实现数据的可靠传递和链路维护;事务层的主要功能是处理设备核心层的数据请求,将其转换为TLP(事务层包)并传递给数据链路层。
PCIE 总线传输峰值带宽很高,这得益于PCIE 总线具备较高的单Lane 线速,并且支持多个Lane 通路同时传输,但是实际传输数据的有效带宽会受到很多因素影响[15]。
1)事务层开销
以PCIE V3.0 规范为例,读写存储器事务的TLP 报文通用格式如图1 所示。

图1 PCIE V3.0 TLP 报文格式
TLP 报文中开始字段由物理层添加,占4 个字节,表示一个TLP 的开始;序列号和链路层校验由数据链路层添加,共6 个字节;TLP 头提供了该TLP 报文的属性信息,64 位地址访问时为4 个双字,其余为3 个双字;数据载荷为传输的有效数据,长度可为0~1 024 个双字,实际由MPS 参数(最大负荷长度)决定。事务层校验是可选的,占一个双字,由事务层添加。
2)物理层和数据链路层开销
物理层额外开销包括数据编码和时钟补偿,PCIE Gen3 以上摒弃较早的8b/10b 转换,采取128b/130b 转换,大大降低了带宽损失。物理层产生一个周期性时钟补偿序列用于解决时钟漂移问题。数据链路层额外开销主要由ACK/NAK 报文和流量控制报文引起,由于接收TLP 个数的阈值和流量计算没有统一的标准,因而这部分开销难以准确计算[16]。
3)应用开销
除协议开销外,PCIE 传输架构设计需要对数据获取及封装、处理状态机、FPGA 与处理器之间握手交互、数据解析等逻辑功能进行合理设计,将应用开销尽可能降到最低。
2 数据传输架构设计
本文设计的基于PCIE 总线的高性能数据传输架构用于实现数据由PCIE 设备到主机的高速传输,PCIE 设备由FPGA 实现,主机为CPU 处理器。高速传输必须采用DMA 传输方式,其实质为FPGA 将待发数据封装为存储器写请求TLP,发送到处理器系统的内存中,应用软件再从内存中获取数据并解析处理。
2.1 阻塞和分散-聚集式传输
阻塞式传输在每次DMA 启动时需要等待上一次传输彻底结束,使用同一片物理地址连续的内存区域作为DMA 数据缓冲区。分散-聚集式传输是将多个内存区域链接起来,每个内存区域内部物理地址连续,各内存区域之间是不连续的。常规的阻塞和分散-聚集式DMA传输流程如图2 和图3 所示。

图2 阻塞式DMA 传输流程
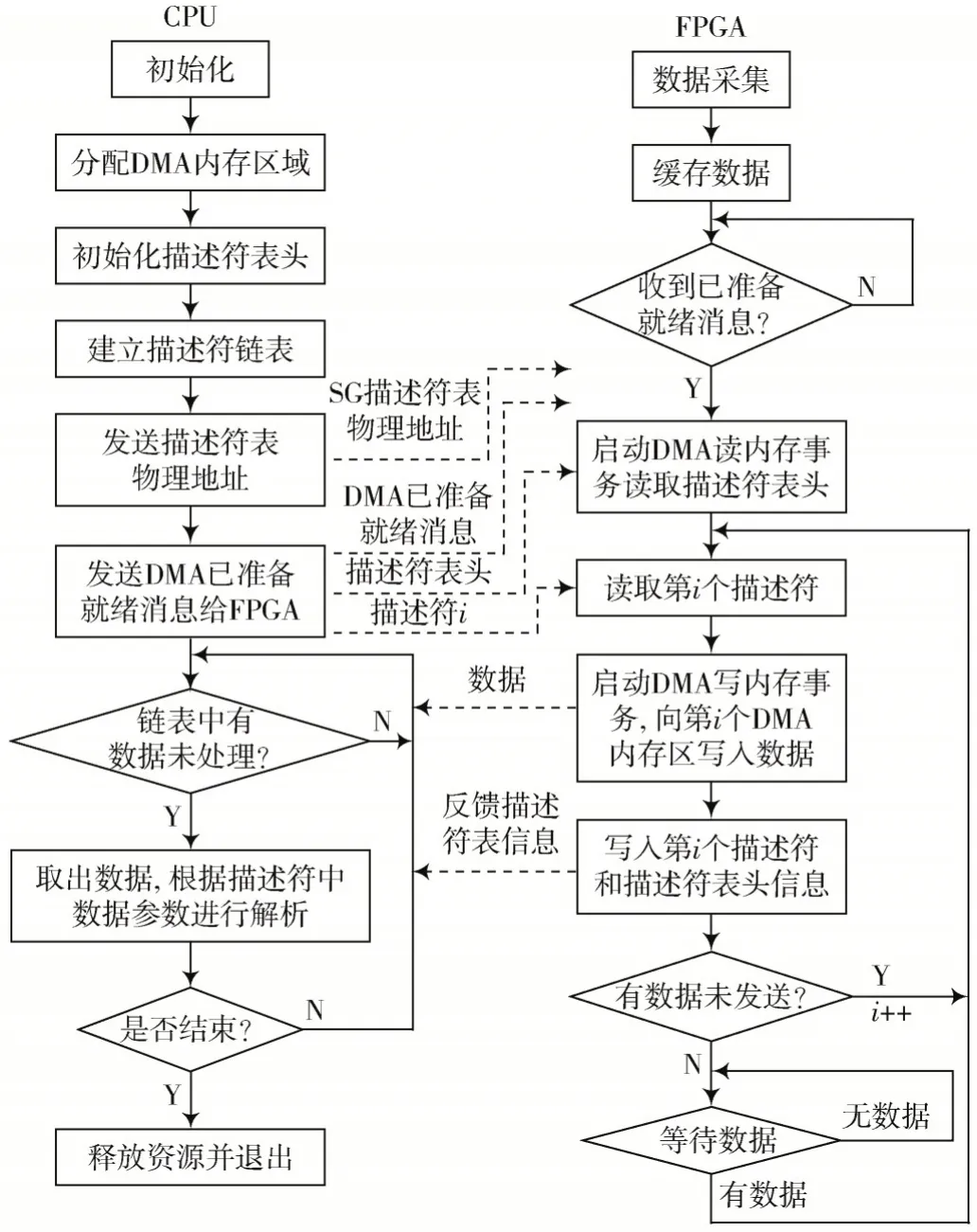
图3 分散-聚集式DMA 传输流程
对比传输流程可以发现二者存在如下差异:
1)阻塞式传输每次DMA 均由CPU 发起和控制;分散-聚集式传输FPGA 仅首次需要等待CPU 准备就绪消息,后续传输均由FPGA 自主控制。
2)阻塞式传输过程中CPU 和FPGA 无法同时工作,因此传输过程有大片时间处于互相等待过程;分散-聚集式传输过程通过传递多个描述符实现,FPGA 获取描述符和CPU 轮询链表是同时进行互不干扰的。
3)相比阻塞式传输,分散-聚集式传输在实现方法和交互逻辑上都更加复杂。CPU 端需要建立和维护描述符链表,每次传输FPGA 先读取描述符进而获取数据缓冲区物理地址,数据发送完成后再向CPU 反馈描述符及表头信息。
2.2 改进的传输架构
分散-聚集式传输具有非阻塞的特性,基于描述符链表能够实现流水线式数据传输,因而传输效率更高,因此本文在常规的分散-聚集式DMA 传输架构之上进行设计改进,通过优化传输流程从而进一步提高带宽利用率和数据吞吐量。此外,传输参数可由应用软件进行配置,并且描述符结构中表项可扩展,这可以极大增强本架构的适应性和可移植性。FPGA 发起写存储器TLP将数据和相应的数据特征参数发送给CPU,有助于处理器完成后续的数据解析工作,使得处理器的性能及资源得到充分利用。
2.2.1 传输流程优化
在常规的分散-聚集模式下,每次DMA 传输FPGA都需要完成两次描述符的读取/反馈操作,导致带宽损失。因此,本设计中对CPU 与FPGA 之间的交互逻辑进行优化,在传输开始前CPU 将所有必要的传输信息一次性发送给FPGA,从而避免了FPGA 在传输过程中频繁读取描述符,包括描述符个数、数据缓冲区大小、描述符表头地址、描述符地址以及数据DMA 地址,FPGA 中DMA 控制器自动载入描述符完成数据传输和信息反馈。改进的分散-聚集式DMA 传输流程如图4 所示。

图4 改进的分散-聚集式DMA 传输流程
CPU 端处理流程为:初始化主要包括初始化PCIE设备、申请和映射I/O 资源等;分配DMA 内存区域,需要完成描述符表头、所有描述符和数据缓冲区内存空间的申请;初始化描述符表头,完成链表头初始化、描述符个数和数据长度等字段的填充;建立描述符链表,初始化描述符并形成循环链表;发送传输参数,将所有需要的传输信息发送给FPGA;发送DMA 已准备就绪消息,通知FPGA 可开启DMA 流程;周期性轮询描述符链表,检测数据区为满时表示有新数据到达,取出数据并开启后续的解析处理;判断是否结束,若是则退出并释放资源,否则,继续轮询链表。
FPGA 端处理流程为:不断采集数据并缓存到DDR中;等待收到处理器端准备就绪消息;加载第i个描述符,并发起DMA 读存储器请求TLP 获取第i个数据区指示信息;若数据区为空,则发起写存储器请求TLP 完成数据传输;反馈描述符信息,将数据区指示置满;若还有数据未发送,则继续读取下一描述符,否则FPGA 可控制传输结束或等待数据。
与常规的分散-聚集传输相比,本架构中FPGA 拥有DMA 传输的完全自主权,传输过程中交互逻辑更少,FPGA 和CPU 端处理流程更加简化。数据区空/满指示信号不仅有利于CPU 轮询链表的实现,应用软件通过检测该信号为满时取出数据,而且实现了一种数据区保护机制,FPGA 只有当检测到该信号为空时才往该数据缓冲区发送数据,在传输瞬时大带宽数据时能够避免因CPU 取数据慢导致的数据覆盖问题。
2.2.2 描述符设计
不同应用平台下软硬件环境和数据传输业务存在差异,主要包括:FPGA 可利用资源大小不同;支持的PCIE 规范及通道不同;内存容量不同;操作系统不同,从而可申请的最大物理连续内存大小可能不同;数据采集率和预期传输的数据大小可能不同;数据来源及数据类型可能不同。因此,本架构设计了一种用户可配置、表项可扩展的描述符循环链表来实现数据的传输和解析,其基础结构如图5 所示。
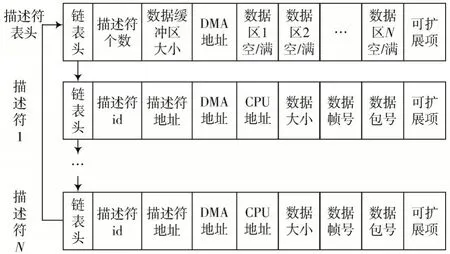
图5 描述符链表结构
描述符表头信息包括传输参数、DMA 地址和数据区指示信息。传输参数有描述符个数和数据缓冲区大小,均可由应用软件根据实际进行配置;DMA 地址即描述符链表头基物理地址;数据区指示信息用于CPU 与FPGA 之间的握手,指示该数据区空或满。描述符信息包括描述符id、地址信息和数据特征参数。描述符id 是描述符的唯一标识;地址信息分为描述符地址、DMA 地址和CPU 地址,描述符地址即该描述符基物理地址,DMA 地址指对应的数据缓冲区起始物理地址,CPU 地址为数据缓冲区的内核虚拟地址;数据特征参数有数据大小、数据帧号和数据包号,数据大小为该数据缓冲区内的有效数据大小,数据帧号为每一帧数据的报文计数,数据包号为一帧数据拆分后的子包号。此外,描述符表头及描述符中均预留可扩展项,用户可根据需要增加额外的控制信息或数据特征参数,例如DMA 结束、数据来源、类型等。
数据传输及处理的另一个难点在于处理节点的数据解析,当传输数据帧长度不固定和大数据帧分包传输时,难以确定数据缓冲区内的有效数据范围和数据帧分包数量等信息,传统方式通过查找报文帧头帧尾来完成拼包解析,数据解析耗费大量处理器时间片和系统资源。通过反馈描述符信息的方式,将数据特征参数发送给处理器,处理器借助于数据特征参数可以完成数据解析,从而减轻处理器负担,将处理器性能最大限度地用于数据的后续处理上。
3 实验及结果
一种CPU+FPGA 信息处理板用于测试本架构在PCIE gen3 X8 下的性能表现,FPGA 为复旦微电子JFM7VX690T80,CPU 为飞腾FT1500A/16,操作系统为银河麒麟。测试参数设置如下:PCIE 最大负荷长度为1 024 B;描述符个数为256 个;数据缓冲区大小为1/2/4 MB;每次发送数据大小固定为4 MB,数据为递增的计数器,速率可自定义调节;报文个数为1 024 个。测试方法为:自测试软件发送DMA Ready 消息起计时,最后一帧数据到达时结束计时;结束传输后,检测接收数据帧号及包号是否连续,并校验接收数据是否连续递增;调节测试数据速率进行多次测试,最终得出实际最大有效传输速率。测试条件不变,对常规的分散-聚集式DMA 传输架构进行测试。测试结果分别如表1 和表2 所示。
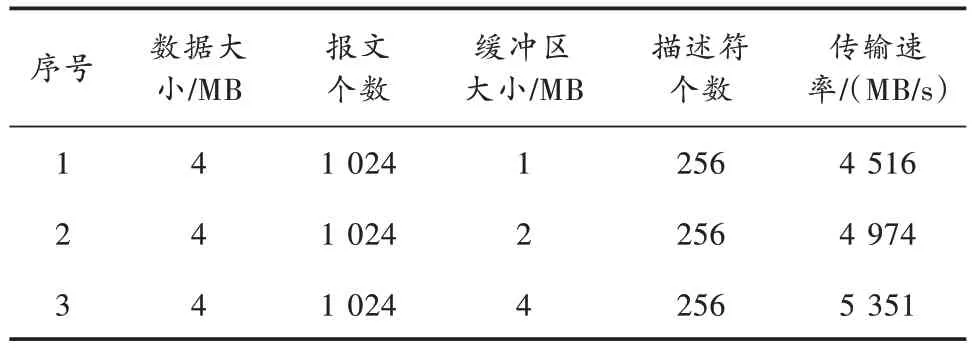
表1 改进的分散-聚集式DMA 性能测试
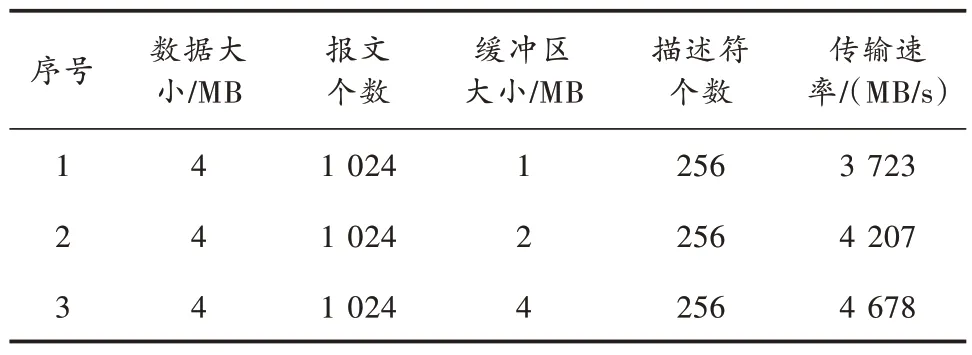
表2 常规的分散-聚集式DMA 性能测试
由测试结果可以发现:当配置数据缓冲区由1 MB增大为2 MB 和由2 MB 增大为4 MB 时,改进架构传输速率分别提升10.1%和7.5%,常规架构分别提升13.0%和11.2%;在三种数据缓冲区下改进架构相比常规架构传输速率分别增长21.3%、18.2 和14.4%,但增长速度逐渐变慢,最大传输速率可达5.2 GB/s。测试结果表明:增大数据缓冲区减少了数据分包和握手开销,从而能够提高传输带宽利用率;改进架构相比常规的分散-聚集式传输架构传输效率得到显著提升。
4 结 语
本文设计了一种基于PCIE 总线的高性能分散-聚集式DMA 传输架构,目前已成功部署于某型雷达国产化信息处理平台中,通过全互联的CPU+FPGA 异构处理模块实现了雷达中频数据的实时传输和处理。该架构具有带宽利用率高、通用性强、资源开销小、报文易解析的优点,能够满足海量数据和不定长数据帧的高速传输及数据解析的需求。
注:本文通讯作者为洪畅。
猜你喜欢
测绘学报(2022年12期)2022-02-13
计算机应用与软件(2020年6期)2020-06-16
成都信息工程大学学报(2019年2期)2019-08-28
第二课堂(课外活动版)(2019年12期)2019-02-10
成都信息工程大学学报(2018年1期)2018-05-31
数字通信世界(2018年1期)2018-04-18
水利规划与设计(2017年11期)2017-12-23
测绘科学与工程(2017年5期)2017-05-07
项目管理技术(2015年3期)2015-04-23
电测与仪表(2014年1期)2014-04-04
