
基于注意力机制的GRA-EMD-BILSTM锂电池性能衰退趋势预测
2023-11-03 12:40:24刘美俊
电源技术 2023年10期
罗 鹏,刘美俊,俞 辉,陈 霞,魏 宪
(1.厦门理工学院电气工程与自动化学院,福建厦门 361024;2.中国福建光电信息科学与技术创新实验室(闽都创新实验室),福建福州 350108;3.中国科学院福建物质结构研究所,福建福州 350002)
车载锂电池作为纯电动汽车(BEV)最关键的动力来源,决定了BEV 的整体性能、生产成本和收益。近年来,不断报道的有关BEV 电池系统故障所造成的事故让消费者对BEV的安全感到担忧。由于BEV 的锂电池组性能衰退是不可逆的,对锂电池性能衰退趋势的预测工作可以帮助行车人员通过调整驾驶习惯延长电池组性能,并能有效地避免电池性能衰退造成的电池组故障,保障行车人员的生命和财产安全。
在早期,数据预测模型的构建通常使用线性回归、自回归移动平均模型等传统回归方法,但这类方法要求数据是稳定的,且对于存在非线性关系的数据预测效果较差。90 年代,深度学习这类模仿人脑神经的网络框架被运用到了各个领域,在预测和识别方面取得了不少成果[1],相比传统方法,深度学习对于网络参数拟合能力有很大的提升,且对象越复杂,优势越明显。但单一的算法训练过程容易出现梯度消失、爆炸的情况,且容易受到数据噪声的影响,此类情况会降低网络的预测精度。本文针对单一算法易出现的问题,提出了一种基于注意力机制的灰色关联分析法(GRA)-经验模态分解(EMD)-双向长短期记忆网络(BILSTM)预测模型,并在开源和非开源数据集上验证了该模型的性能。
1 关键特征选取
电池性能没有具体的参数,传统的方法是用电池容量[2]或电池内阻[3]表征电池性能,但电池容量无法在线获取,是一种典型的实验室测量方法,电池内阻通过传感器采集,采样精度受传感器的限制,且采样过程耗时耗力,因此这两种参数不宜表征实车的电池性能。电池组性能的衰退受外界复杂环境和驾驶习惯的影响,所以对实际电动汽车在行驶过程的参数变化进行分析并选取合适的参数表征电池性能的工作非常重要。
BEV 电池组通过多个单体电池串并联构成,各单体电池出厂时内部参数已出现细微差距,因此,充放电时间越长,各单体电池极值电压差异越大,一致性也越差,从长里程下观察电池包数据,单体电池压差是一项重要的参数,且该参数容易在实际车辆中获取。研究发现锂电池压差增大会加剧电池容量的衰减[4-5],而电池容量是表征电池寿命的参数,因此,锂电池单体电池压差的变化与电池寿命具有强相关性,此外,压差过大带来的不一致性极大地影响了电池组的性能,具体表现为整车充不满电、行驶里程缩短等情况。
通过对获取的实车电池包数据分析,随着运行里程的增加,电池内阻和电池组压差逐渐增大,呈正相关关系。内阻是电池健康状态(SOH)的重要参数,通过公式计算发现内阻增大会导致SOH的降低,SOH越低,电池性能越低,因此,内阻与电池性能呈反相关,由压差和内阻的关系推出压差与电池性能呈反相关,压差越大,电池性能越低。将单体电池压差视为关键特征,用于表征锂电池的性能,通过提前获取锂电池的终身运行数据,计算故障情况(电池容量小于80%)时的压差并设定故障阈值,压差的预测可在线帮助车主知晓车辆工况,提前给车主预警。综上所述,预测未来压差的增长趋势等同于预测锂电池性能衰退趋势。
2 模型设计
2.1 融合注意机制的BILSTM
非开源数据采样间隔短,变化幅度大,为了能够准确捕捉数据前后特征的序列信息,采用BILSTM 作为基本网络框架[6],此外,该网络还可以避免长序列在训练过程出现梯度消失或爆炸的情况,BILSTM 模型结构如图1 所示。

图1 BILSTM基本结构图
BILSTM 的神经元内部与LSTM[7]相同,包含三个门控模块,分别是遗忘门、记忆门和输出门。X表示的是t时刻的输入,C表示细胞状态,H表示隐层状态。网络的输入包括经过处理后得到的压差分量和影响压差变化的关联特征,压差分量依然保留了压差的时序信息,且受前向关联特征的影响。BILSTM 的神经元可以通过遗忘门、记忆门对细胞状态选择性地遗忘和记忆新信息,将这些有用的信息保存下来并传递给后续的神经元。信息的遗忘、记忆、输出是由上个时刻H和当前X通过神经元的内部权重计算得到的遗忘权重、记忆权重、输出权重控制。通过LSTM 神经元的三个门,能够有效抓取隐藏在关联特征与压差分量中的特征信息和时序信息。相比LSTM,BILSTM 可以编码从后到前的信息,提高获取隐藏信息的能力。
输入信息经BILSTM 神经元的处理后,得到的结果如式(1)~(2)所示,输出y是将Ht进行Softmax 处理。
式中:W0为输出权重;Wi为记忆权重;Wf为遗忘权重。
本文在BILSTM 网络框架中添加了注意力机制,根据结果与该点的误差大小合理分配权值,以此取代神经元随机分配权值的方式。融合注意力机制的BILSTM 模型如图2所示。
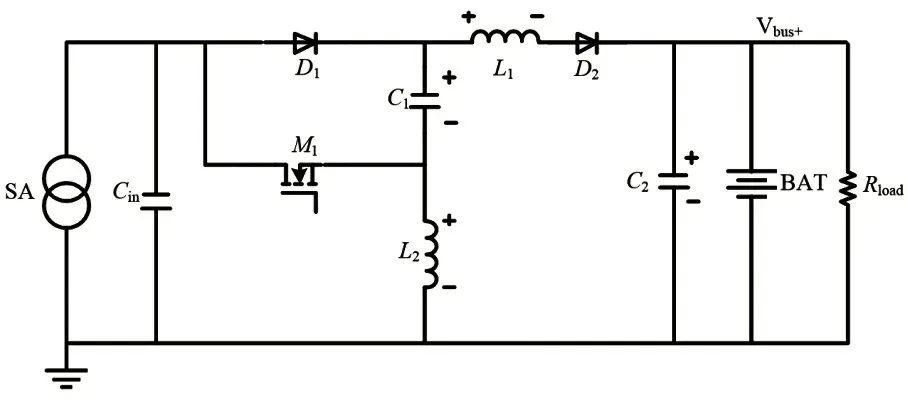
图2 融合注意力机制的BILSTM结构图
注意力机制可以通过合理分配权重的方式,对BILSTM提取的时序特征给予足够的关注,忽略不重要的信息。具体地,计算神经元内部隐含层hi'和前面的随机初始化的四个隐含层hi的相似度ei,如式(3)所示,下一步,使用Softmax 函数计算出注意力权重,得到注意力权重W后,与神经元的输出加权整合,通过全连接层映射,得到预测值。Softmax 公式如式(4)所示。
2.2 基于注意力机制的GRA-EMD-BILSTM 网络
开源/非开源数据中能反映车况信息的参数有总电流、总电压、电荷状态(SOC)、温度等参数,这些特征反映了汽车的外界环境和驾驶行为,但无法判断它们与压差是否存在关联,若关联度较差被做为冗余特征输入到网络中,会降低模型的预测精度,因此,采用GRA 计算上述参数与压差的关联度,筛选出非冗余特征。表1 为关联度分析表,选取关联度大于0.6 的参数,并视为与压差关联度较高的关联特征。

表1 关联度分析
式中:ρ为分辨系数,取0.5。
尽管BILSTM 能够捕捉压差序列的非线性和时序性,但是对于这类变化频率高的序列,非平稳部分会导致预测精度下降,因此,本文采用EMD 将压差序列分解成多个平稳的、多尺度的分量[8],相比傅里叶变化和小波变化,EMD 具有更好的信噪比。压差序列V(t)经EMD 分解,得到多个固有模态函数(IMF)和残余信号Res,如式(6)所示:
融合注意力机制的GRA-EMD-BILSTM 模型流程图如图3 所示。压差序列经过EMD 分解后得到多个分量,在构造特征工程中,将这些分量作为目标标签,结合与之相对应的GRA 筛选后的关联特征一同输入到BILSTM 网络中,在网络的输出部分引入注意力机制,经全连接层拟合后得到每个分量的预测值,将各分量的预测值叠加即为最终预测结果。
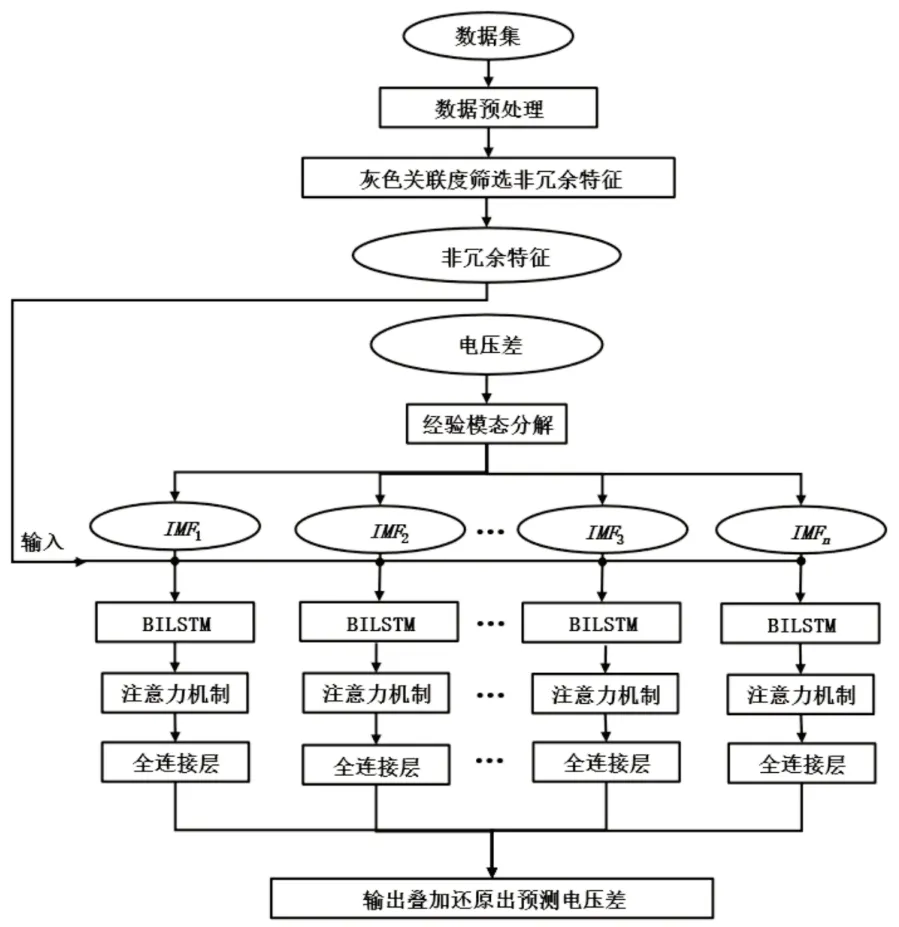
图3 模型流程图
3 实验验证
3.1 数据集预处理
本文使用了开源/非开源数据集验证提出的算法的预测精度。开源数据为上海市新能源汽车公共数据采集与监测研究中心提供的完整电池包数据,因此数据预处理阶段只需要进行归一化处理,消除各参数量纲之间的差异,归一化如式(7)所示:
式中:x表示样本数据;xmax表示样本数据的最大值;xmin表示样本数据的最小值。
非开源数据源于某品牌投放至市场中的纯电动汽车电池管理系统采集的电池实时数据。实际数据的多个参数与驾驶行为有很大的关系,驾驶行为的变化会导致参数产生突变,因此,收集的实际数据相比开源数据,变化频率更高,幅度更大,这些非线性的变化更能考验网络的特征提取和时序分析能力。
实际数据会因电池管理系统的异常导致上传的电池数据存在离散的空值,数据的不均衡会导致预测模型无法正常训练。由于采样间隔为10 s,相邻值差异较小,本文采用均值插补法,取空值上下值的平均值进行空值插补。
3.2 实验环境与设置
本文实验环境:操作系统Linux;显卡型号NVIDIA GEFORCE RTX2080Ti;深度学习框架Tensorflow2.91;编程语言Python3.7。
为了验证本文提出的方法的优势,设置了5 组对比实验,将提出的模型与GRA-EMD-BILSTM 模型、EMD-BILSTM模型、BILSTM 模型、LSTM 模型以及BP 模型做对比,评价模型的指标采用均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分误差(MAPE),评价指标如式(8)~(10)所示:
式中:yi表示压差预测值;xi表示压差实际值;N表示样本的数量。
为了保证实验的公平性,各网络的参数均统一:丢失层为0.5,传递的训练参数为126,训练次数为200,优化器为适应性矩估计(Adam),神经元个数为16,并且在训练过程中,利用回调函数保存最好的模型,利用该模型进行后续的预测工作。将数据集的前80%作为训练集,后20%作为测试集。
3.3 实验结果与分析
经GRA 分析,得到的各特征序列与压差序列的关联度如表2 所示。
由表2 可知,开源数据中,除速度、总电流外,关联度均小于0.6,属于失调状态,因此将速度和总电流作为网络的输入;对于非开源数据,将总电流、行驶里程、速度这三类关联度大于0.6 的参数作为网络的输入。
对初始信号V(t)进行EMD,分解结果如图4 所示,从高频到低频,V(t)被分解成10 个IMF和一个Res,经EMD 分解的多个分量,由上到下,IMF逐渐从非平稳趋于平稳,且各IMF的变化较为一致。
利用不同模型预测压差,各预测曲线和实际压差可视化图如图5~6 所示,图5 为开源数据集对比图,图6 为非开源数据集对比图。由于数据较多,基于原始图片,绘制了三个局部放大子模块A、B、C。

图5 开源数据预测结果

图6 非开源数据预测结果
由图5 可知,A 模块震荡较为剧烈,无法准确判断各模型的预测效果,B 模块中可以明显发现,当压差处于上升趋势时,BP 神经网络与真实值偏离幅度非常大;C 模块中当震荡幅度趋于平稳时,LSTM 网络的预测值与真实值相比,向下偏离。由图6 可知,A 模块中,BILSTM 网络的预测值相比实际值向上偏离;B 模块中,除BILSTM 外,EMD-BILSTM 也略微向上偏离;C 模块无法看出模型的差异。如上分析,BP 模型、BILSTM 模型和LSTM 模型,由于算法单一,无法准确提取变化特征,预测效果较差。在网络中添加EMD 后,预测效果提高,但在图6(c) B 模块中,预测值与实际值仍存在一定的偏离,这是因为预测模型受到冗余信息的影响,相比之下,本文提出的方法与GRA-EMD-BILSTM 模型在开源数据集和非开源数据集都能跟踪压差的变化趋势,可视化图无法直观判断两种模型的差异,需通过评价指标才能判断最优算法。
通过模型评价指标计算各模型的预测误差,如表3 所示。由表3 可知,BP 神经网络、LSTM 神经网络的误差较大,与图反映的一致,相对于LSTM,BILSTM 误差有所降低,证明本案例双向提取特征的方法优于单向提取特征,在BILSTM 中添加EMD 后,精度大幅度提升,说明EMD 可以通过分解关键特征,多分量预测的方法有效提高预测精度,通过GRA,去除冗余特征,预测精度也略微提升,最后在网络的输出阶段添加注意力机制得到的误差相比GRA-EMD-BILSTM 模型,误差有所降低,RMSE、MAE和MAPE分别为1.423 2/0.971 9,0.920 6/0.628 0 和8.187 3/11.444 0。此外,本文还收集了各算法所消耗的时间,该时间包含预训练模型的建立时间。
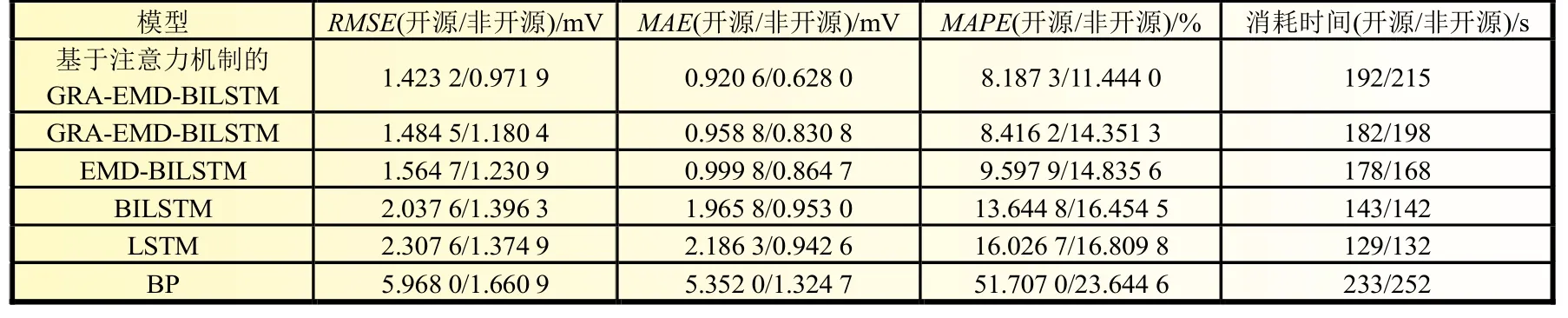
表3 不同模型直接的误差比较
综上所述,相比其它算法,本文提出的方法在开源和非开源数据集上有着较高的预测精度,从消耗的时间上分析,此方法消耗的时间并不长,如果应用于在线预测,在通过GRA 离线分析电池终身数据以确定关联参数的前提下,加上预训练模型的建立时间,仅需每五分钟传入数据,即可在下个阶段传入数据之前,得到预测结果,因此,此方法可在线应用于车辆工况预警。
4 结论
本文考虑了单一算法的缺陷,融合了多个方法,建立了GRA-EMD-BILSTM 模型,并加入了注意力机制,进一步提高模型的预测精度,此外,除开源数据外,还收集了变化频率更高的实际电动汽车的电池数据验证本文提出模型的性能,最后通过实验表明,使用BILSTM,并在网络中添加EMD、GRA和注意力机制,模型性能有不同程度的提高,因此,本文提出的基于注意力机制的GRA-EMD-BILSTM 模型具有更优的性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
创新作文(1-2年级)(2019年3期)2019-09-03 05:14:07
石油石化绿色低碳(2019年6期)2019-01-14 01:16:20
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
办公自动化(2016年18期)2016-08-20 12:50:20
办公自动化(2016年18期)2016-08-20 12:50:18
上海理工大学学报(社会科学版)(2015年3期)2015-11-30 03:02:13
应用数学与计算数学学报(2014年1期)2014-09-26 12:19:03
电测与仪表(2014年18期)2014-04-04 12:33:08
