
基于信息增益比-支持向量机的泥石流易发性评价
2023-11-02 11:47姚皖路赵俊三李坤
城市勘测 2023年5期
姚皖路,赵俊三,李坤
(1.昆明理工大学国土资源工程学院,云南 昆明 650093; 2.智慧矿山地理空间信息集成创新重点实验室,云南 昆明 650093;3.云南省高校自然资源空间信息集成与应用科技创新团队,云南 昆明 650211)
0 引 言
泥石流是在自然因素、人文因素或者自然与人文因素共同作用下形成的对生态环境或人类生命财产造成破坏的地质灾害[1],据自然资源部发布的《2020年全国地质灾害通报》统计,2020年全国共发生地质灾害 7 840起,其中泥石流灾害899起,约占地质灾害总数的11.47%,对基础设施、城市发展和人民生命财产造成重大损害和威胁。因此,开展区域泥石流灾害易发性评价,对泥石流预警和防治具有重要的意义。
目前,泥石流易发评价方法主要分为定性评价方法(泥石流编录方法和知识驱动方法)和定量评价方法(数据驱动方法和物理驱动方法)[2]。定性评价方法依据主观经验来筛选泥石流指标因子,然后根据指标因子来计算某区域泥石流暴发的概率,容易获得,但是受到主观因素影响较大。物理驱动方法主要是通过模拟泥石流暴发的环境来对泥石流进行预测,由于模型构建复杂且造价高,不适用于区域性的泥石流易发性评价[3]。随着数据质量的提高,基于数据驱动的定量评价方法被广泛运用于区域泥石流易发性评价。数据驱动评价模型主要包括信息量模型[4]、证据权重[5]、逻辑回归[6]、人工神经网络[7]、支持向量机[8]和随机森林[9]等。在这些模型中,机器学习方法因为其良好的非线性预测能力,成为泥石流易发性评价建模主流。泥石流暴发受多种不同指标因子共同控制,不同指标因子对泥石流发育的贡献率不同,一些因子可能包含着噪声,从而降低泥石流易发性模型的精度。因此,有必要对泥石流影响因子的贡献率进行评估,选择合适的因子,并去除不相关或不重要的因子进行进一步的分析[10]。使用信息增益比来计算各指标因子对于泥石流发育的贡献率,信息增益比为定量识别和选择泥石流易发性建模的主控因子提供了强有力的方法。
本文以典型高原山区的东川区为例,综合考虑研究区复杂的自然条件,从地形地貌、水文气象、地质条件、植被覆盖和人类活动5个维度选取泥石流易发性评价指标因子。使用信息增益比来筛选影响泥石流发育的主控因子,结合支持向量机模型(SVM)来构建东川区泥石流易发性评价模型,并对研究区泥石流易发性进行分析,旨在提高地质灾害的预报能力,让决策者可以更好地了解东川区地质灾害发生的空间概率,进而更加准确地对地质灾害进行监测、预测并且能够及时对灾害进行预警,将地质灾害所带来的损失降至最低,以期为国土空间规划提供决策参考。
1 研究区域与数据来源
1.1 研究区域
研究区位于云南省东北部,昆明市最北端,地处云贵高原北部边缘,东与会泽县接壤,南与寻甸县相接,西与禄劝县相靠,北与四川省会东县和会理县隔金沙江相望,介于102°47′E-103°18′E,25°57′N-26°32′N,国土面积约为 1 865 km2(图1)。研究区内沟谷纵横,地势险峻,海拔介于695~4 344.1 m之间,高差达到 3 649.1 m,主要水系为小江流域,由南向北贯穿整个研究区,复杂的地形条件和水文条件在该地区地质灾害中起着重要的作用。由于长期的伐木炼铜、过度垦殖等人类活动造成研究区植被覆盖率较低。其独特的地形条件和人类活动等因素造成整个研究区地质灾害频发,主要有泥石流、滑坡、崩塌等。其中,泥石流灾害最为严重,主要分布于小江流域和金沙江流域,有“世界泥石流天然博物馆”之称。

图1 研究区域和泥石流点区位图
1.2 数据来源及处理
(1)泥石流指标因子来源及处理
指标因子的选择与处理对泥石流易发性评价有着重要的影响[11-12]。本文结合研究区的实际情况,从地形地貌、水文气象、地质条件、土地覆盖和人类活动五个方面来选取泥石流指标因子。①地形地貌因子数据,使用研究区 30 m分辨率的DEM数据,经ArcGIS表面分析工具得到研究区坡度、坡向和剖面曲率数据;②水文气象数据,使用会泽站、昆明站和宜良站的降雨量数据,利用Kriging插值得到研究区2020年5—10月降水量。根据东川区第三次全国国土调查数据获取研究区河网信息,处理后得到距河网距离;③地质条件数据,使用研究区地层岩性和断裂带数据,利用ArcGIS欧氏距离和栅格化处理后得到研究区距断裂带距离和地层岩性;④植被覆盖数据,采用研究区2020年7月植被最为茂盛时 30 m分辨率的Landsat 8近红外和远红外波段计算得到归一化植被指数(NDVI);⑤人类活动数据,使用东川区第三次全国国土调查数据,经ArcGIS欧氏距离处理后得到距道路距离;地形湿度指数(TWI)分别由下式计算:
(1)
式中:Ac表示要计算的栅格单元上游的汇水面积/m2;β表示栅格单元的坡度;Lc表示栅格单元的宽度/m。所有栅格图层的空间分辨率均为 30 m×30 m。主要数据来源如表1所示:
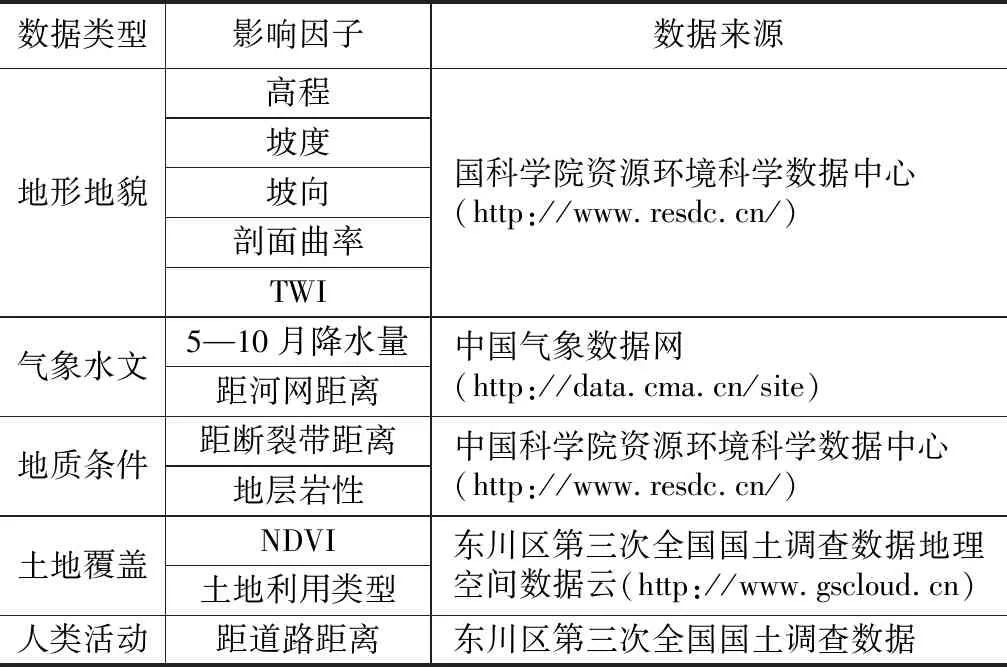
表1 指标因子数据来源表
(2)泥石流编录数据
泥石流编录的收集对于泥石流易发性评价有重要作用[13]。首先,以高分辨率遥感影像数据(GF-2:2017-7)结合中国科学院资源环境科学与数据中心获取的研究区地质灾害点空间分布数据对泥石流灾害点初步解译。然后,在内业解译的基础上开展野外现场调查。最终识别出研究区共有106个泥石流点(图1)。
2 研究方法
2.1 支持向量机
支持向量机(SVM)是在20世纪90年代发展起来的[14],在本文的研究过程中,实际是将泥石流数据集映射到一个高维空间,然后通过支持向量机(SVM)模型在高维空间中寻找超平面,尽可能地将是否发生过泥石流(发生过:1,未发生过:0)两类样本分开。最佳超平面可通过解决优化函数问题来寻找:
(2)
其中:ξi表示松弛变量,c(>0)表示误差的正则化变量。为了对样本进行分类,SVM的决策函数表示如下:
g(x)=ωTφ(x)+b
(3)
其中φ(x)表示泥石流样本x从输入空间到高维特征空间的映射;ω=(ω1,ω2,…,ωd)为法向量,b表示位移项,两个参数的最佳值均可由优化函数计算获得。
在SVM中常用的核函数包括线性核函数、多项式核函数、径向基(Radial Basis Function,RBF)核函数、Sigmoid核函数。RBF核函数由下式计算:
(4)
式中K表示核函数,γ为核函数的超参数。
本文采用Python语言结合Scikit-learn库建立和训练模型,通过GridSeachCV模块对模型进行超参数调优后,支持向量机模型的核函数为径向基核函数(RBF),惩罚系数C为1,参数γ为0.109 854。
2.2 信息增益比
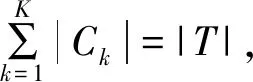
(5)
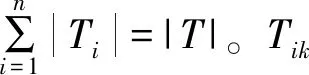
(6)
Info(T|a)表示在给定特征a的前提下,对数据集T进行分类的不确定性。信息增益为:
Gain(T,a)=Info(T)-Info(T|a)
(7)
数据集T关于特征a的值的信息熵为:
(8)
因此特征a的信息增益率为:
(9)
3 指标因子体系构建
3.1 多重共线性分析
在构建泥石流易发性模型之前,有必要检查各指标因子之间是否存在共线性。一般采用容差和方差膨胀因子(VIF)来评价各指标因子之间共线性情况[16],本文使用SPSS20.0软件,对12指标因子进行多重共线性分析,当VIF小于5并且容差大于0.2时,表明各因子之间不存在共线性问题,反之存在共线性。如表2所示,各指标因子之间并没有存在共线性问题,可以用于构建泥石流易发性评价模型。

表2 多重共线性分析与因子贡献率评价表
3.2 指标因子选取
由于各指标因子对于泥石流发育的贡献率不同,过多的指标因子会增加数据量,不仅会带来数据冗余,还有可能导致因子间存在一定的相关信息,对模型精度造成一定的影响。因此有必要筛选出最能诱发泥石流的指标因子来构建易发性模型。虽然坡度、距路网距离、距河网距离等因子对泥石流的形成有重要影响,但并不是最重要的[18],本文通过逆向淘汰方法,利用信息增益比计算各指标因子的贡献率,主要根据信息增益比模型计算得到的指标因子贡献率中,坡度、距路网距离、距河网距离等因子贡献率较低。其值越大的指标因子对泥石流易发性模型的精度提升越大。如图2所示,根据信息增益比的结果表明,NDVI、剖面曲率、5—10月降水量和TWI为诱发研究区泥石流的主控因子。

图2 东川区泥石流灾害各指标因子贡献率
支持向量机具有计算速度快,结果稳定等特点,经常被用于泥石流易发性评价。为了进一步优化指标因子,剔除不重要的因素,本文首先使用所有初选因子训练模型,然后根据信息增益比所计算的因子重要性从低到高逐个剔除因子,当剔除了坡度、距道路距离、距河流距离的时候精度最高,继续剔除因子后精度逐渐下降。如表3所示:当消除了坡度、距路网距离和距河网距离三个因子后,模型的曲线下面积(Area Under Curve,AUC)值达到了 0.903 3,然而当继续剔除距断层距离和地层岩性两个因子时,模型的AUC值逐渐下降分别为 0.884 8和 0.872 7。剔除了不重要因素以后能明显提高模型的精度,最后选择9个指标因子用于构建泥石流易发性评价模型。
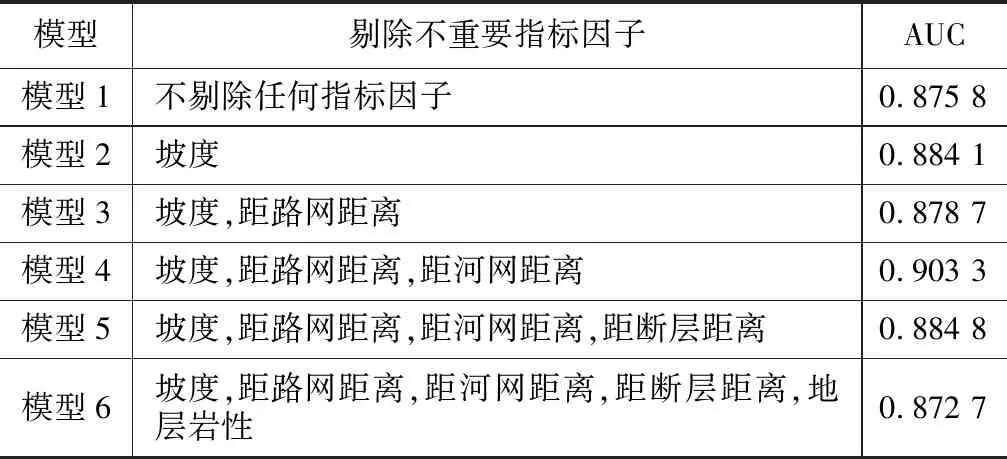
表3 剔除不重要指标因子后模型精度表
4 泥石流易发性评价与精度分析
4.1 泥石流易发性模型构建与验证
东川区在30 m×30 m分辨率的条件下被划分为 2 074 122个栅格,其中研究区已发生的106处泥石流共划分为 87 078个栅格单元,没有发生过泥石流共有 1 987 044栅格单元。在对模型进行训练时,为解决数据集不平衡问题,采用欠采样方法随机选择与泥石流栅格相同数目的非泥石流栅格单元,共同组成一个新数据集作为模型的输入变量,将新数据集按照7∶3的比例划分为训练数据集和测试数据集分别用于泥石流易发性模型的训练与测试。模型的预测结果为各栅格单元内的泥石流概率,泥石流栅格单元取1,非泥石流点取0。本文的支持向量机模型采用python语言通过scikit-learn框架来构建,并通过GridSeachCV模块对模型进行超参数调优。
本文采用10折交叉验证来验证模型的稳定性,并统计每一次验证的精确度(ACC)值,如表4所示,发现该模型较为稳定,训练样本的平均ACC值为 0.820 5,测试样本的平均ACC值为 0.815 7。图3为模型对测试数据集的泥石流概率结果与实际泥石流概率的散点分布图,从图中可以看出模型对非泥石流区域的预测更加准确。

表4 BP神经网络评价结果ACC值记录表
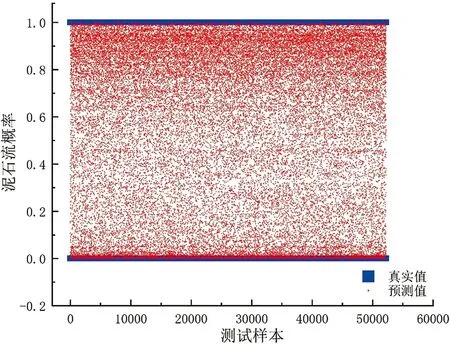
图3 模型输出结果和实际值的散点分布图
4.2 泥石流易发性评价
在构建的泥石流易发性模型平稳运行之后,计算各栅格单元的泥石流易发性指数,利用ArcGIS10.2软件的自然断点法将泥石流易发性指数划分为:极高易发区、高易发性区、中易发区、低易发区和极低易发区5个等级。然后,根据所划分的易发性等级并使用GIS对研究区进行泥石流易发性制图。
从图4中可以看出,研究区泥石流高和极高易发区主要集中分布在小江河谷、乌龙河、块河和金沙江南岸,其中在拖布卡镇、乌龙镇、铜都街道西部、阿旺镇北部、因民镇和舍块乡北部分布最为集中;低和极低易发区分布最为广泛,主要集中分布于红土地镇、舍块乡、因民镇和阿旺镇南部、铜都街道东部;中易发区主要沿着高和极高易发区分布,与高和极高易发区的分布大致相同。评价结果可以采用泥石流密度来显示,泥石流密度为某易发性等级内泥石流内栅格比例与其易发性等级内栅格比例的比值,反映出对应易发性等级内的泥石流强度。各易发区的泥石流数量和密度的直观统计图如图5所示,其中高和极高易发区内的实际泥石流栅格数量占总泥石流栅格数量的88.47%。

图4 东川区泥石流灾害易发性等级图
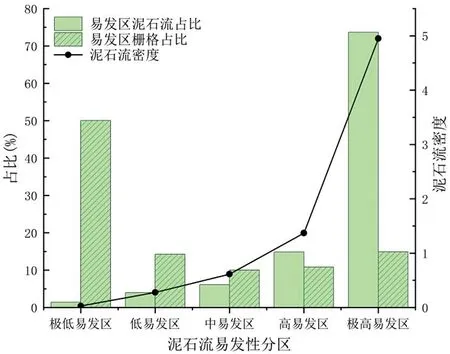
图5 各易发区间比例及泥石流密度统计
4.3 优化指标因子前后模型精度
对泥石流易发性模型的精度评价通常采用受试者工作特征曲线(Receiver-Operating Characteristic,ROC)以及曲线下面积(Area Under Curve,AUC)来对模型的性能进行评价[17]。ROC曲线越靠近左上角,意味着模型的性能越好,反之,则模型的性能越差,曲线如果在参考线的下方,证明模型完全无法使用;AUC值介于0~1,值越高表明模型的精度越好。根据以往的研究,基于AUC值的模型的性能可以分为几个层次:0.5~0.6=差,0.6~0.7=中等,0.7~0.8=可接受,0.8~0.9=优秀,0.9~1=近乎完美[19-20]。
从图6中可以看出,指标因子经过优化以后,ROC曲线更趋向于右上角,曲线下面积AUC值为 0.903 3,说明模型具有较好的精度。同时还计算了指标因子优化前的评价结果的ROC曲线,AUC值为 0.875 8,经过优化指标因子后,模型的精度提升了2.75%。对比结果表明,使用信息增益比剔除了对泥石流爆发贡献率较小或者含有错误的指标因子后,模型的精度有了一定的提升。

图6 模型ROC曲线
5 结 论
(1)本文通过信息增益比-支持向量机模型建立了泥石流易发性评价模型,对指标因子进行优化处理后发现,NDVI、剖面曲率、5—10月降水量和TWI为诱发研究区泥石流的主控因子,土地利用类型、高程、坡向、地层岩性和距断层距离对泥石流的发育起到重要影响,ROC曲线检验模型的AUC值为 0.903 3有较高精度,满足评价需求,可为东川区的灾害防治提供参考。
(2)根据对研究区泥石流易发性制图结果显示,东川区大部分处于泥石流低和极低易发区,主要集中分布于红土地镇,舍块乡、因民镇和阿旺镇南部,铜都街道东部,其中红土地镇分布最广;高和极高易发区分布较为集中,主要集中分布于小江河谷两岸和金沙江南岸,其中在拖布卡镇、乌龙镇、铜都街道西部、阿旺镇北部、因民镇和舍块乡北部分布最为集中;中易发区的分布与高和极高易发区的分布大致相同,主要集中分布于乌龙镇、拖布卡镇、汤丹镇、舍块乡和因民镇北部、铜都街道西部和阿旺镇北部。
(3)文中在评价单元的选择上仍有一些不足,本文使用栅格单元作为评价单元,虽然栅格单元在计算统计方面具有很强的优势,但是流域单元即保证了流域的完整性,又反映出泥石流与指标因子之间的联系。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
今日农业(2021年10期)2021-11-27
科技创新与应用(2021年31期)2021-11-09
今日农业(2021年1期)2021-03-19
杂文月刊(2018年21期)2019-01-05
海峡姐妹(2017年6期)2017-06-24
环球时报(2017-06-14)2017-06-14
科技知识动漫(2016年1期)2016-01-27
弹箭与制导学报(2015年1期)2015-03-11
