
融合语言模型的化验单文字识别矫正研究
2023-11-02 12:35:24张煜楠吕学强黄庆浩游新冬董志安
计算机应用与软件 2023年10期
张煜楠 吕学强 黄庆浩 游新冬 何 健 董志安 黄 跃
1(北京信息科技大学网络文化与数字传播北京市重点实验室 北京 100101)
2(北京洛奇智慧医疗科技有限公司 北京 100015)
3(清华大学互联网产业研究院 北京 100084)
4(首都医科大学宣武医院 北京 100053)
0 引 言
2019年,据中国国家统计局抽样调查推算,中国总人口已超14亿。庞大的人口基数为国家的不断发展提供了丰富的人力资源。与此同时,人民群众对医疗资源的需求也在逐步提升,其中看病难问题已经成为一个普遍的社会现象,并引起了政府的高度重视。2019年1至11月期间,全国医疗卫生机构总诊疗人次达77.5亿人次,同比提高2.8%。化验检测对于就医患者必不可少,同时会产生大量的医疗化验单,极大地增加了医生的工作量[1]。由于患者数量大而医生数量有限,患者在进行化验检测、得到化验结果后,不能及时对化验单进行解读而导致病情延误,这也是医患纠纷问题时常发生的主要原因之一。
随着深度学习和人工智能的不断发展与进步,计算机视觉领域成为热点研究方向,吸引了来自学术界与工业界的广泛关注[2]。计算机视觉通过其对图像的强大的解读能力,为各行各业提供了技术支持。其中,医疗领域提出了智慧医疗的建设,并在近些年取得了突破性进展。自2005年起,由Google不断维护的开源Tesseract-OCR在文字识别领域取得优异的成绩[3],使整个学术界以及工业界掀起了一股人工智能的浪潮,各类文字识别算法应运而生。在医疗领域,OCR技术可以通过识别化验单文字,结合医疗信息系统,利用人工智能与大数据对化验单进行初步的解读,不仅能够使患者得到及时的就诊,同时也可以减轻工作人员的工作量,大大提升诊断效率。在我国,“互联网+医疗”是医疗领域发展的新契机,智慧医疗的出现能够很好地缓解看病难问题[4]。
基于人工智能的医疗化验单智能解读工作分三步,首先对医疗化验单进行文本检测,然后通过OCR系统对文字进行识别,基于NLP对识别结果进行后处理,将图像数据转化为文本数据,最后通过医疗数据库、医疗知识图谱、医疗大数据等方式,将相关信息全面直接地呈现给患者[5]。通过这种方式,患者不仅能够充分了解自身的病情,缓和自身情绪,而且可以帮助患者与医生更好地交流沟通,提高就医效率,缓解就医压力。
本文源于医疗化验单文字识别系统,针对自然场景下化验单识别效果欠佳的情况,提出了一种融合语言模型的文字识别矫正方法。使用语言模型矫正形近字错误,通过融合编辑距离和最长公共子序列的方法匹配最贴切的识别结果,最后使用对应关系匹配,进行前后矫正,进一步提高识别精确度。
1 相关研究
自然场景下的医疗化验单识别形近字矫正在OCR矫正中被广泛使用。单个错字的矫正可以通过建立医学词典,对单字进行模糊字处理的方法矫正。张淙悦等[6]通过建立医学词典并通过模糊字文件进行内容纠错,其方法针对特定的模糊字有较好的处理效果,但需要针对模糊字逐字添加,泛化性较差。李琴等[7]在建立医学词库的基础上,对词条进行单字符模糊匹配,然后计算字符间的相似度进行矫正。其方法可以有效地矫正单个错字,但方法使用条件受模糊匹配参数影响较大。单字的矫正往往不能满足矫正需求,统计语言模型是对语言内在描述的数学模型[8]。这种方法可以通过建立语料库,使用统计方法来发现语言中的普遍规律,以此对形近字进行矫正。王霈珺[9]将统计语言模型应用到OCR识别结果矫正工作中,有效降低了OCR系统的识别错误率。但该方法只考虑字符间的统计信息,对统计数据有较高的要求,在单个形近字的矫正中表现很好,但却难以应对OCR识别结果中的字符串缺失、合并等现象。
OCR字符串矫正主要采用字符串相似度算法,广泛应用的相似度算法主要有编辑距离算法、最长公共子序列算法及其变种。编辑距离(Levenshtein Distance,LD)算法常被用来衡量两个文本之间的相似度。该算法通过插入、删除、替换等操作使一个序列变成另外一个序列花费最小操作次数[10]。利用编辑距离进行OCR后处理,通过查阅构建的医学词表,选择与识别结果最小编辑距离的词语来矫正识别结果中的检验项名称。该算法在处理速度和效果上都取得不错的效果,但对于较短序列或识别结果出现缺失等情况,该算法不能进行有效的矫正。
王宸敏[11]提出的化验单OCR识别结果矫错方案首先建立了医学词库,通过计算编辑距离进行初步的匹配,然后采用常用文字相似度比较来解决编辑距离计算中存在的多个候选项的问题。该方法取得了不错的效果,但通过计算文字相似度来解决多个候选项相似度相同的问题,在识别结果存在缺失、合并时,难以精确地选择合适的候选项,从而导致识别结果错误。
最长公共子序列(Longest Common Subsequence,LCS)算法常被用于查找两个序列的最长公共子序列的问题[12],可以用于计算字符串间的相似度。李明[13]指出最长公共子序列算法可以很好地进行文本相似度比较。文中使用了动态规划算法,计算两个序列最长公共子序列,这样便可以有效地解决文字识别中的缺失或增加问题,动态规划算法能够将基础问题化为子问题,通过构建动态转移方程,迭代求出问题的解。该算法能够有效地计算文本相似度,但是对于长度不同且有相同公共子序列的两个序列的矫正将出现问题,如医学词库中存在核糖核苷酸,脱氧核糖核苷酸两个词条,当识别结果为核糖核苷酸时,在矫正时会出现争议。
综上所述,对于自然场景下化验单文字识别后处理,目前存在的后处理方法都存在一定的缺陷。对此,本文提出了一种融合语言模型和传统方法的OCR识别后处理方法。首先利用语言模型得到更加符合实际情况的预测序列,然后根据构建的医疗词库进行完全匹配。若匹配成功可以根据化验单检测项的对应关系进行前后矫正;若匹配失败,可以根据改进的编辑距离和最长公共子序列的方法选择最接近的医疗词库中的词语矫正,然后再根据对应关系进一步矫正,从而提高识别准确率。
2 一种融合语言模型和传统方法的化验单识别矫正方法
融合语言模型的化验单文字识别矫正处理方法,可以有效解决形近字识别错误和医学名词识别错误的情况,其整体流程如图1所示。主要分为两个部分对自然场景下化验单的识别进行矫正,第一步是预处理,构建医疗词库和识别矩阵。第二步是OCR后处理矫正,主要包括基于语言模型的矫正、基于对应关系的矫正、基于编辑距离、最长公共子序列的矫正。
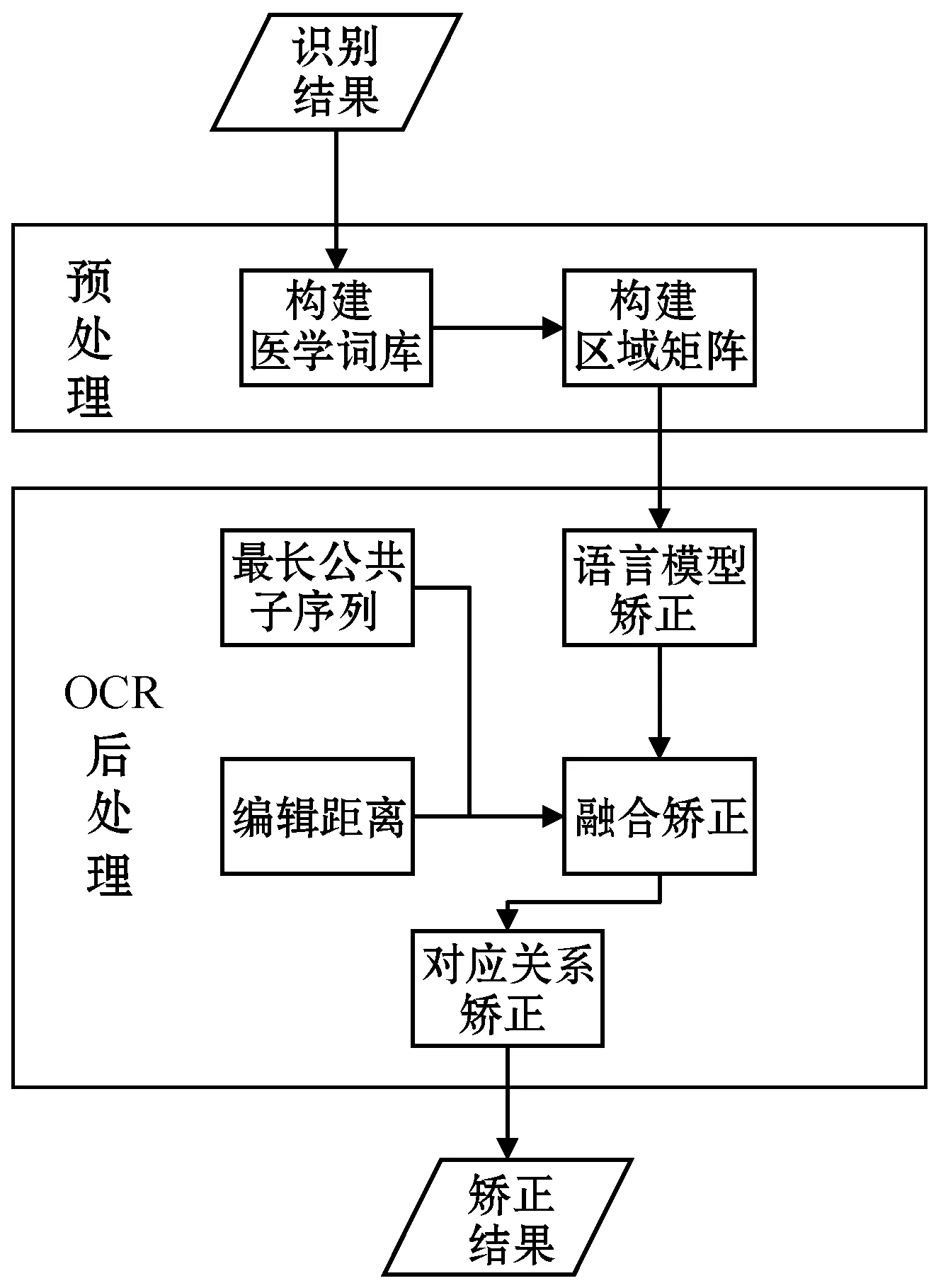
图1 矫正流程
2.1 识别结果矫正预处理
首先根据某实验室提供的真实数据,构建医学词库,然后根据识别结果的每个区域取前三名,构建识别结果区域矩阵。传统文字识别只取每个区域的最高预测结果,通过区域组合得到最终结果,其最大问题在于在某一区域一旦出现识别错误,就会导致整体出错。这里构建每个区域概率预测前三的结果组成区域矩阵,为后期引入语言模型奠定基础。
2.2 基于语言模型的识别结果矫正
语言模型是对语句概率分布的建模,它通过收集真实的语言文字,并对收集到的语言文字进行统计分析,从而得到语言文字所存在的规律[14]。语言模型可以通过概率分布来统计字符出现的概率,从而有效地对识别结果进行初步的矫正。具体来说,是通过统计结果,计算可以得到最大的条件概率的组合。
以词条“醛固酮”为例,其计算公式如式(1)所示。第一个检测区域识别的结果S1,选取CRNN[15]网络中间层给出的前三个候选字“醛”“酚”“醚”;第二个候选区域识别结果S2,选取前三个候选字“回”“固”“田”;第三个候选区域识别结果S3,选取前三个候选字“桐”“铜”“酮”。每个候选区域的概率W(Si)需要根据网络预测的概率分别归一化,识别结果区域矩阵一共有33种组合。根据概率统计分析,条件概率P(Si+1|Si),即Si出现的情况下后面出现Si+1的概率,由此可以计算得出所有组合的出现概率,f值最大的组合即为最优的组合,这样便可利用统计的方式进一步提高识别准确率。同理,对于长度为n的预测序列S1,S2,…,Sn,需要根据式(2)计算各种组合下的概率。这里的W(Si)根据CRNN中间层输出的预测概率进行重新归一化,条件概率P(Si+1|Si)需要根据预处理部分建立的医学词库,统计Si出现的次数N(Si),统计Si和Si+1前后共同出现的次数N(Si,Si+1),条件概率公式如式(3)所示。
f=W(S1)P(S2|S1)W(S2)P(S3|S2)W(S3)
(1)
f=W(S1)P(S2|S1)W(S2)P(S3|S2)…
W(Sn-1)P(Sn|Sn-1)W(Sn)
(2)
(3)
上述方法可以计算条件概率和预测概率,但是组合情况的复杂度呈指数级增长,在有效的时间内很难得到最终结果,故引用Viterbi算法[16]求解最优组合路径问题,最优路径组合可以抽象为一个动态规划的问题,首先构造动态转移方程。如果最优路径经过某个节点Si,那么从初始节点也一定会经过Si,且这条路径是到达Si的最优路径,每个节点只会影响前后两个节点的条件概率。根据这个思想,可以将这个问题划分为若干个子问题,在求经过Si的最优路径时候只需要求经过Si-1的所有候选点的最优路径即可,动态转移方程如下:
dp[i,j]=max(dp[i-1,k]+value(k,j))
(4)
动态转移方程中的k表示选取的预测值个数,value(k,j)表示第i个区域的第k个点到第i个区域的第j个点的条件概率,如图2所示,虚线为动态规划求解过程,每个节点,只需要选择一条最优到达路径即可。这样每步只需计算要n次即可,依次递推求解每个子问题的解,逐步求出问题的最优解。
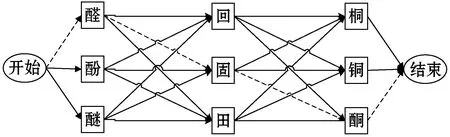
图2 动态转移过程
基于语言模型的识别结果矫正作为识别结果矫正的第一步,能够较好地解决OCR识别结果中的形近字识别错误的问题,为后续的矫正方法提供基础。接下来,使用融合最长公共子序列和编辑距离的方法匹配最贴切的识别结果,对结果进一步矫正。
最长公共子序列主要用于求两个序列之间的相似度,也可以用来矫正文字识别。对于输入序列x和y分别表识别结果和医学词库中的医学名词,LCS[i,j]表示序列x的前i个元素和序列y的前j个元素的最长公共子序列,动态转移方程如式(5)所示。若序列x的第i个元素和序列y的第j个元素相等,那么最长公共子序列长度加1,C[i,j]=C[i-1,j-1]+1;若序列x的第i个元素和序列y的第j个元素不相等,C[i,j]取C[i,j-1]和C[i-1,j]的最大值,等价于删除第i个元素或第j个元素后序列的最长公共子序列。此时,C[i,j]表示当前公共子序列的长度,依据该数组回溯,便可找到最长公共子序列。
(5)
最长公共子序列算法可以很好地体现两个字符串的相似程度,但化验单检验项如“白细胞”“白细胞酯酶”“镜检白细胞”存在包含关系,如果识别结果为“白细胞”则与三者的最长公共子序列均为3,从而产生歧义,无法正确矫正。
Levenshtein距离又称编辑距离(Edit Distance)是度量两个序列相似程序的常用算法。该算法通过插入、删除和替换等操作,将一个序列转化为另一个序列,并统计所需的最小步数[17]。设输入序列s和e分别表识别结果和医学词库中的医学名词,LD[i,j]表示序列s的前i个元素和序列e的前j个元素的编辑距离,动态转移方程如式(6)所示。若序列s的第i个元素和序列e的第j个元素相等,那么编辑操作为0,LD[i,j]=LD[i-1,j-1];若序列s的第i个元素和序列e的第j个元素不相等,那么LD[i,j]可以进行三种操作,第一种操作方式是删除序列s的第i个元素,第二种方式删除序列e的第j个元素,第三种方式替换操作使得第i个元素和第j个元素相等,三种方式取最小值。
(6)
编辑距离算法体现了字符串间的差异程度,可以避免公共子串带来的歧义。但使用神经网络识别化验单文字需要先切分文字再识别,因文字密集、光影变化等原因,切分文字过程中会出现多字、漏字、合并字符串等现象[18]。如检验项X=“网织红细胞计数”因切分问题被识别为Y=“只红细胞计数”,后者与前者及Z=“红细胞数”的编辑距离均为2,造成歧义。基于编辑距离的相似度公式如式(7)、式(8)所示,计算X与Y、Z相似度均相等,不符合X与Y更相似的直观认知[19],存在一定的局限性。
(7)
(8)
综上所述,单独使用编辑距离算法或是最长公共子序列算法矫正都会出现歧义。本文融合了编辑距离方法和最长公共子序列方法。识别序列长度为i,医学词库中医学名词序列长度为j,Q[i,j]表示两序列相似度,相似度共识如式(9)所示。其中,参数α与β为比例系数且α+β=1。通过已有数据统计α与β的最优比例,可以使算法更好地应用于不同的数据集。通过对标注数据的统计,在本文后续实验中,α为0.3,β为0.7。
Q[i,j]=α·dp[i,j]+β·(min(i,j)-C[i,j])
(9)
2.3 对应关系的识别结果矫正
化验单OCR与自然场景下的OCR相比存在一定的特殊性,根据某实验室提供的真实化验单数据,每张化验单最多包含七项,分别为序号、项目名称、缩写、检测结果、单位、参考值范围、提示。其中,项目名称、缩写与单位、参考值范围存在固定的对应关系,如果一个检验项的项目名称或缩写确定,那么这个检验项的单位和参考范围也可以确定。在医疗机构提供的检验项表单的基础上,根据标注数据进行增补,建立了化验单OCR识别矫正的检验项词表,示例如表1所示。如果一个检验项的项目名称和缩写识别正确,便可以通过这种基于对应关系的矫正方法,对其他列的识别结果进行矫正。部分化验单还存在一行多个检验项的情况,需要根据对列名的识别结果配合检验项文字,核对并拆分一行中的两个检验项,并对两个检验项分别进行如上矫正处理。
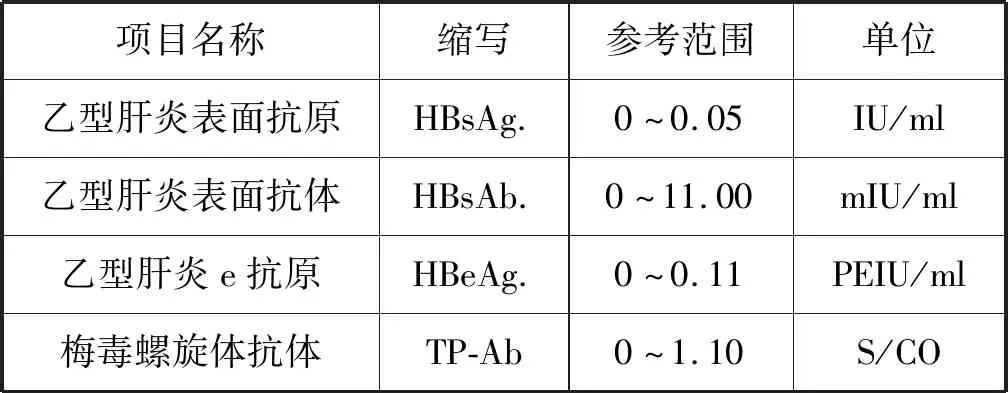
表1 检验项词表示例
3 实 验
3.1 实验数据及评价指标
本实验由某智慧医疗科技有限公司提供真实化验单数据5 000余张,分某实验室、某医院两大类。通过检验指标数据合成和数据增强,数据扩充至10 000余张,化验单数据如图3、图4所示。通过使用自然场景下化验单文字检测方法(BHS-CTPN)进行文字检测,将检测的文本框进行切割,然后利用一种改进CRNN的识别方法进行文字识别,最后对识别结果进行后处理矫正。
图3 实验原始数据
图4 实验原始数据
本文使用准确率(Precision)、召回率(Recall)和F-Measure(F1值)对模型做性能评估。TP表示正类判断成正类的数目;TN表示负类判断成负类的数目;FP表示负类判断成正类的数目;FN表示正类判断成负类的数目。在矫正任务中,一般使用准确率表示识别出的字符中正确识别的字符数量,而用召回率表示化验单字符中正确识别的字符数量,准确率、召回率、F1值计算公式如式(10)-式(12)。
(10)
(11)
(12)
3.2 实验细节
本实验的输入为化验单识别结果和构建的医学词库,输出为矫正的识别结果。实验构建的医学词库2 000余项,实验的硬件为Intel Xeon E5-2603 v4处理器,64 GB内存,Nvidia Tesla k 80显卡,操作系统为Ubuntu 16.04.10,实验的软件配置为Python 3.6.8,实验的区域预测选择概率最大的前三个。首先利用语言模型进行识别结果矫正,然后根据构建的词表,利用对应关系进行矫正,最后利用融合的编辑距离和最长公共子序列的方法进行识别结果矫正。
3.3 实验结果
3.3.1定量分析
如表2、表3所示,在实验室化验单数据和医疗化验单数据上,对本论文提出的后处理矫正方法各模块分别进行消融实验。使用Imp-CRNN作为基线模型,分别加入语言模型、对应关系、编辑距离和最长公共子序列以验证各模块的有效性,然后将各模块结合得到本文的矫正方法。与基线模型相比,本文的方法在实验室化验单数据上的识别准确率、召回率、F1值分别提升了2百分点、3百分点、2百分点,在医院化验的数据上的识别准确率、召回率、F1值分别提升了2百分点、3百分点、3百分点。实验结果表明加入后处理的文本识别更加精确,且方法适用于不同的数据集,具有一定的泛化性。本组实验的对比和相关指数的提升可以有效地说明本文模型的性能。
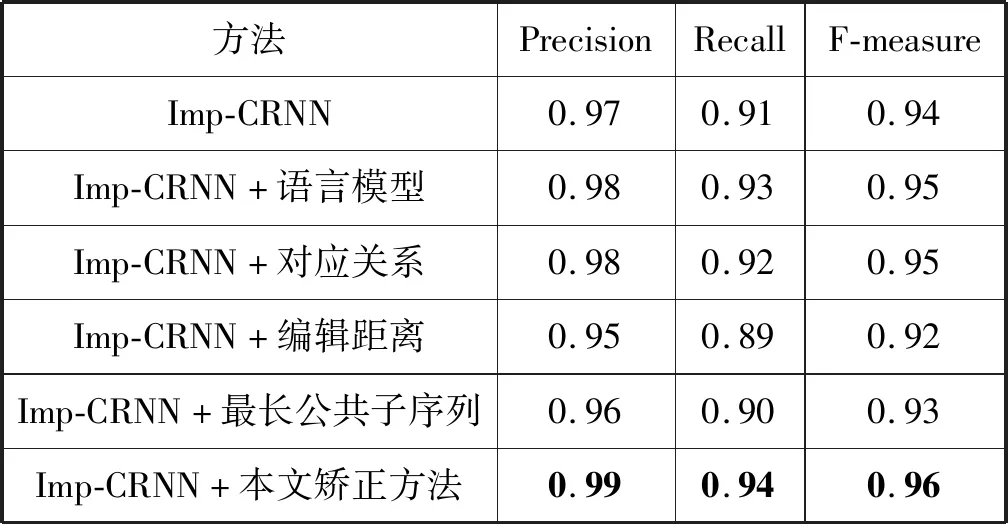
表2 某实验室化验单识别结果对比
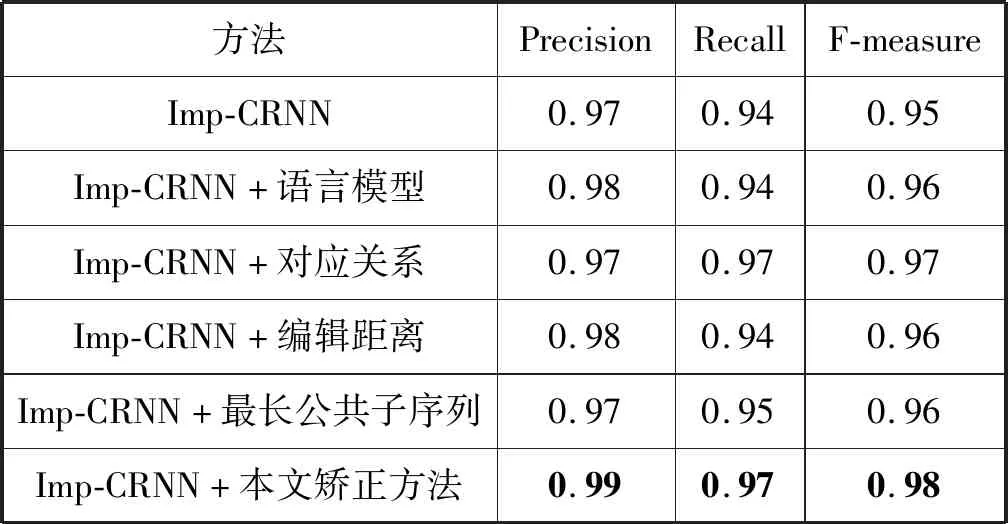
表3 某医院化验单识别结果对比
3.3.2定性分析
为了能够客观地进行分析比较,选取两张典型的化验单案例,对比其识别结果与校正后结果,如图5、图6所示。在没有引入后处理时,会出现形近字识别错误和多字少字现象。通过使用本文提出的后处理方法可以矫正大部分错误,同时还能通过后处理将识别结果进一步规范化,方便后期处理。定性分析体现了引入后处理可以有效地解决常见识别错误,提升准确率。
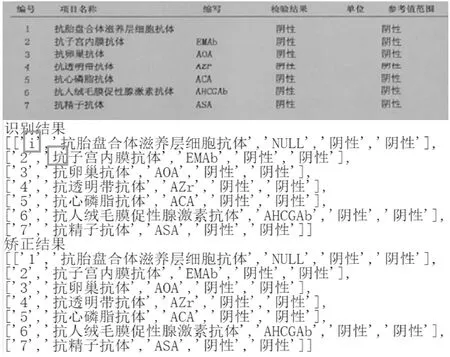
图5 识别矫正对比图一

图6 识别矫正对比图二
4 结 语
本文针对自然场景下化验单识别效果欠佳的情况,提出了一种融合语言模型的文字识别矫正方法。在传统语言模型矫正方法的基础上,引入神经网络的输出建立识别结果矩阵,使用统计条件概率预测最佳符合医学词库的识别结果。本文提出了一种融合编辑距离和最长公共子序列的字符串匹配算法来匹配最贴切的识别结果,最后通过对应关系匹配,进行前后矫正,进一步提高识别精确度。对比实验表明,在引入本文提出的矫正方法后,化验单的识别准确率得到了提高,证明了该方法的有效性。但该方法还有一些不足之处,如需要更新词库、相似度算法计算量有待优化、训练数据分布不均匀会导致鲁棒性不足等问题。在接下来的工作中,一方面将对所提出的方法进行改进,优化方法,减少计算量,进一步提高本方法的效率;另一方面将提升词库的规模,使数据均匀分布,扩大数据的覆盖范围,进一步提高方法的鲁棒性。
猜你喜欢
中国自行车(2018年2期)2018-05-09 07:03:05
特别健康(2017年11期)2017-03-07 11:38:20
特别文摘(2017年2期)2017-01-24 19:43:57
英语知识(2016年1期)2016-11-11 07:07:54
福建人(2016年6期)2016-10-25 05:44:15
Coco薇(2015年7期)2015-08-13 22:47:12
中国医疗美容(2015年2期)2015-07-19 10:11:59
电脑迷(2014年14期)2014-04-29 00:44:03
中国医药指南(2014年35期)2014-01-29 04:55:38
电脑迷(2012年15期)2012-04-29 17:09:47
