
基于迁移学习的玉米病害图像识别
2023-11-02 07:49:06张彦通苏前敏
中国农业科技导报 2023年10期
张彦通, 苏前敏
(上海工程技术大学电子电气工程学院,上海 201600)
玉米营养价值丰富,具有耐寒、耐旱、耐贫瘠等特性,在全国各地均有种植[1]。玉米在生长发育过程中常常由于各种因素而发生病害,主要有褐斑病、枯萎病、茎腐病等。有效防治病害成为农作物稳产、高产的关键,而及时准确的病害诊断又是防治病害的必要前提。传统的病害诊断方式主要通过人工经验和观察,存在主观上的不确定性和效率较低等问题,亟需开发快速精准的诊断方式,以提高作物病害的诊断和防治效率,减少农作物的生产管理压力[2]。
随着人工智能技术的快速发展,越来越多的研究人员利用图像处理技术对农作物病害进行自动化智能识别研究,能够实现对农作物病害的高效诊断,为农业领域现代化开创新局面。深度学习技术在图像识别分析领域取得了长足的进步[3],但是必需以较为充足的训练数据作为支撑,才能理解数据的潜在模式。当前缺乏大型公开的单一作物病害图像数据集,除了PlantVillage[4]和AI Challenge[5]等几个比较流行的植物病害图像共享数据库外,研究人员大多和农业种植园进行合作自行拍照收集,或者通过网络收集相关植物病害图像,由于解决问题的复杂性,模型的扩展性不强,难以实际应用。迁移学习[6]作为一种深度学习方法,其基本原理是将模型自身在相关任务中学习的知识(权重和参数)迁移到新场景下,因为原网络已经通过大型数据集的训练学习到了图像的丰富特征,具有良好的泛化能力,可以通过网络微调以实现特定领域的学习,具有良好的扩展性。相比于全新学习[7],迁移学习除了可以加速模型的训练外,同时也解决了训练数据不足的问题。史红栩等[8]利用迁移学习将GoogleNet深度卷积神经网络进行训练,最终获取诊断模型,并将该模型实际应用,实现了香蕉病害远程诊断系统,平均测试精度达到了98%,可以快速准确地在线诊断香蕉常见病害。李静等[9]利用TensorFlow 框架将Inception-v4 预训练模型的网络结构知识迁移到玉米螟虫害识别的任务上,在训练的过程中,通过优化神经网络算法最终实现对玉米螟虫害的识别,平均准确率达到了96.44%。龙满生等[10]将AlexNet 模型在ImageNet 图像数据集上学习的分类共性知识迁移到油茶病害识别任务,通过对比实验优选出模型的超参数,并通过数据增强技术对数据集进行预处理和扩充,提升了模型的鲁棒性,为植物叶片病害的识别诊断提供了参考。
本文利用轻量化网络结构并结合深度迁移学习技术对玉米病害图像数据集进行训练,通过对比实验分析挑选出模型的优化器,以及使用学习率动态衰减策略完成训练过程中的模型微调,最后结合TensorFlow Lite 框架将优化后的模型部署在移动端,完成玉米病害识别应用的开发,为农业现代化领域提供参考。
1 材料与方法
1.1 数据集
图像数据来自公共数据集Kaggle机器学习数据平台,共搜集了灰叶斑病、枯萎病、锈蚀病3 种常见的玉米病害及健康图像,共1 527 张。图1 是数据集中各类玉米病害(包括健康)的图像基本特征,表1 为数据扩充前后各病害及健康图像的数量,与健康及锈蚀病不同,枯萎病和灰叶斑病的叶片图像相似度较高,为了提升模型对病害的识别精度,这2种病害扩充后的的图像数量也更多。
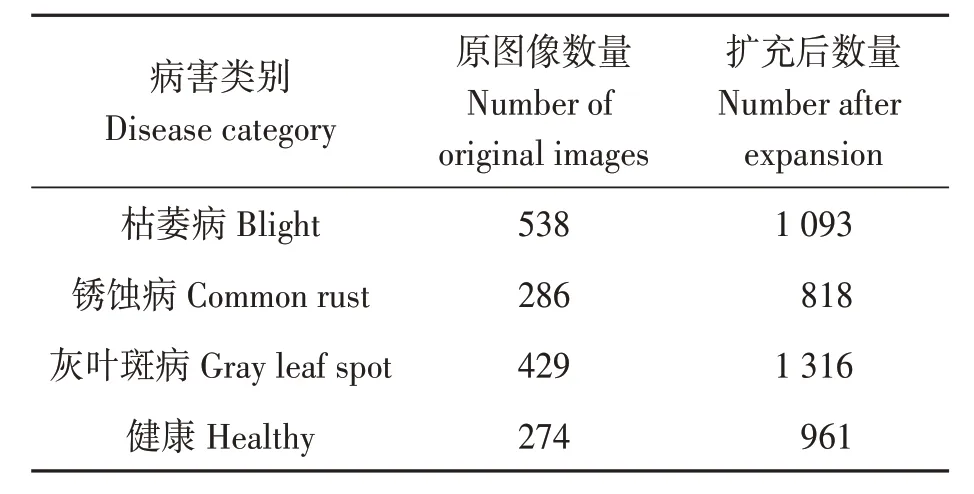
表1 扩充前后的图像数量Table 1 Number of images before and after data augmentation

图1 健康及染病的玉米叶片图像Fig. 1 Images of healthy and diseased corn leaf
1.2 模型与方法
1.2.1 MobileNetV2 模型 深度神经网络模型被广泛应用在图像分类、物体检测和目标跟踪等计算机视觉任务中,但是不同模型大小不同,往往无法在移动端等计算能力和存储能力有限的终端上得到充分发挥和应用。经与VGG16、ResNet50、InceptionV3、Xception 模型对比分析,本研究选择MobileNetV2[11]模型作为玉米病害识别模型的基础架构模型,如图2所示。
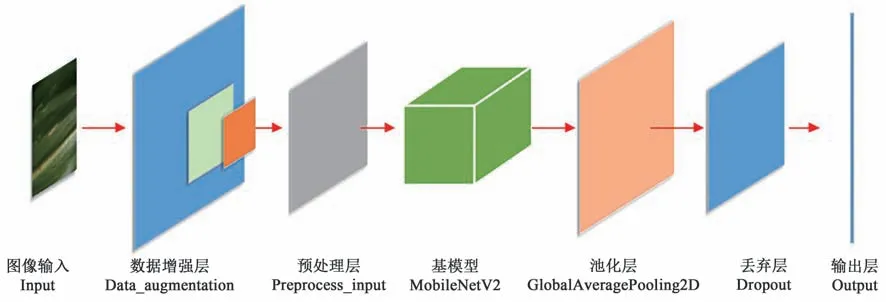
图2 基于MobileNetV2模型的玉米病害识别模型架构Fig. 2 Architecture of corn disease recognition model based on MobileNetV2
基模型MobileNetV2 作为整个识别模型的核心组件,其详细结构见表2,第1 层是卷积核大小为3×3 的标准二维卷积。接下来是17 个线性瓶颈的倒置残差结构(Bottleneck),该模块由3 层网络结构组成:①扩展层,使用1×1 的卷积神经网络[12],目的是将低维空间映射到高维空间进行升维,升高的维度倍数即膨胀系数与表中的系数等价,激活函数使用的是ReLU6;②深度可分离卷积(depthwise convolution)[13],使用3×3 的卷积核作为标准卷积核的大小,主要功能为完成卷积提取特征功能、降低计算量和参数量,同样使用ReLU6非线性激活函数是由于其在低精度计算中更具有鲁棒性,并在训练期间加入了dropout 和BN,加速模型的训练并降低过拟合现象的发生;③使用1×1 的卷积网络,目的是将高维特征映射到低维空间进行降维,让网络重新缩小,使用Linear线性激活函数,如使用非线性激活函数可能会造成信息丢失或破坏。后面是由卷积核为1×1的二维卷积网络、7×7的平均池化层和1×1的二维卷积网络构成。
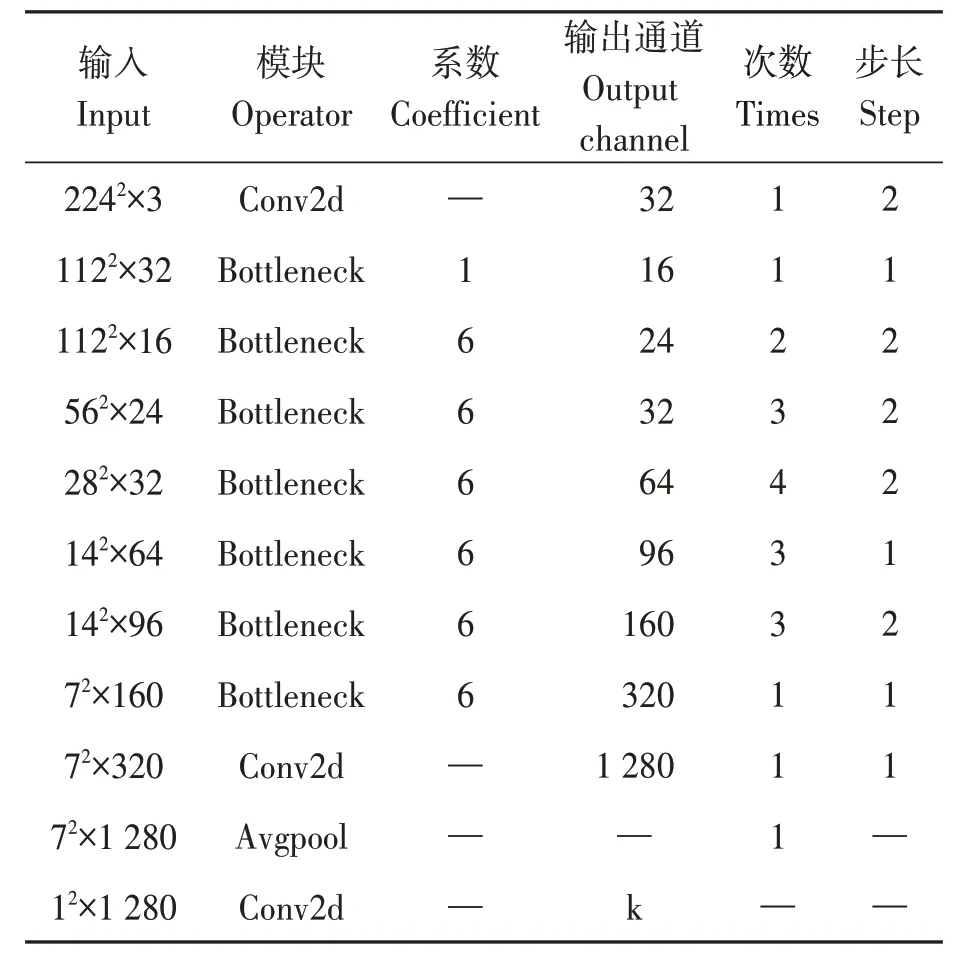
表2 MobileNetV2结构Table 2 Structure of MobileNetV2
1.2.2 实验环境及模型参数 模型的训练以及优化均在Google Colab 上使用TensorFlow 框架完成。硬件环境:Tesla P100-PCIE GPU,16 G 显存,12 G内存,Intel(R)Xeon(R)@2.30 GHz CPU,软件环境TensorFlow 2.8.0, Python 3.8.0。
模型训练时,图像的输入尺寸为160×160×3像素,在输入到模型之前将图像像素值缩放至[0,1],池化层类型为最大平均池化,其卷积核大小为3×3 像素,滑动步长为2,输出单元数为1 280,Dropout 层的丢弃率为0.2,输出单元数为1 280,输出层为全连接层,输出单元数为4,对应分类数量。训练批次(Batch_Size)大小设置为32,模型的损失函数选择SparseCategoricalCrossentropy,并在训练的过程中将数据集打散,目的是在使用自适应学习率算法的时候,可以避免发生某些数据集中出现而导致模型学习出现过拟合现象。
1.2.3 模型优化 为了提高模型的准确率,首先将整个数据集按7∶2∶1 的比例划分为训练集、验证集和测试数据集,然后分别选择SGD、Adam 和Nadam 优化器作为模型的超参数,将初始学习率设置为0.001 0、0.000 5 和0.000 1,迭代次数设置为50、100 和2 003 个,对比不同优化器对模型识别性能的影响。
确定识别模型的优化器后重新进行训练,整个模型的训练次数设置为250,在前200 次的训练过程中,“冻结”模型的后50 层并通过设置动态阶梯式的学习率衰减,同时通过参考TensorFlow API 中的默认值并结合实际经验,将衰减系数设置为0.96,衰减步长设置为20,即在训练的过程中每20 次迭代学习率就会降低。在后50 次的迭代训练过程中通过自定义设置学习率并将识别模型的后50 层“解冻”并重新训练,目的是让识别模型更具特殊性,以提升模型的识别精度。
1.3 玉米病害识别模型部署
1.3.1 模型转化 在确定了最终的玉米病害识别模型后,导出后的模型并不能直接用于应用程序的开发。TensorFlow 框架提供了相应的解决方案,即将Saved-Model格式的文件通过转化器转化为TensorFlow Lite model(一种由.tflite 文件扩展名标识且被优化后的Flatbuffer 二进制格式,该格式可以被Android Studio 软件直接加载)。Saved-Model 包含1 个完整的TensorFlow 程序模型,其中包括模型训练后得到的参数和权重等信息。
1.3.2 应用架构 由于模型的输入大小固定,在将图像输入到模型之前需要进行图像尺寸的判断,如果图像尺寸不符合模型的输入大小,需要对图像进行预处理,最后模型将计算后的结果通过应用程序界面展示出来,玉米病害识别应用的总体架构流程如图3所示。
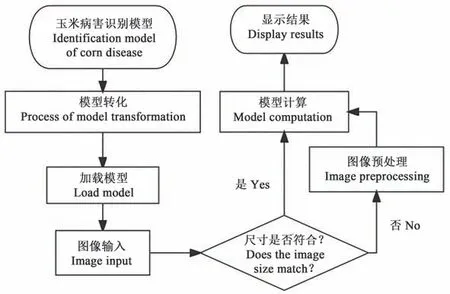
图3 识别应用总体架构流程Fig. 3 Overall architecture flow for recognition applications
2 结果与分析
2.1 数据增强效果分析
考虑到实际的应用场景,如用户的拍摄角度、光线等都会对模型的识别结果产生影响,因此为了提升模型的稳定性、鲁棒性和识别精度,对原数据集进行数据增强,增加图像的多样性,以提升模型的识别准确率和应用场景。利用TensorFlow 框架中的ImageDataGenerator 以及预处理模块对图像进行平移、旋转、改变饱和度和增强对比度操作,增加了数据集的复杂性,使其更符合实际情况,图4 为玉米病害图像数据增强前后的效果变化。
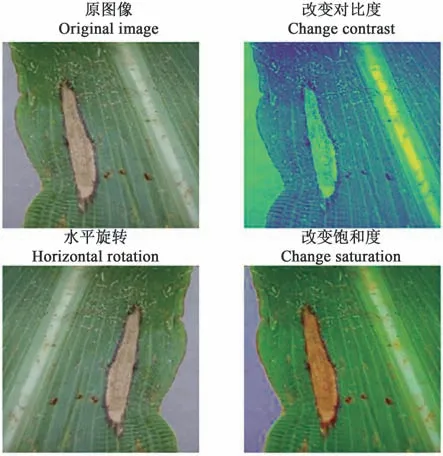
图4 数据增强效果Fig. 4 Effect of data augmentation
2.2 不同模型训练能力分析
轻量化网络旨在保持模型精度的基础上近一步减少模型参数量和复杂度,既包含了对网络结构的探索,同时也推动了深度学习技术在移动端及嵌入式端应用的落地。通过表3 的对比结果可知,MobileNetV2模型体积以及执行耗时上都要比其余4 个网络结构小很多,虽然MobileNetV2 的识别准确率低于其他的网络,但是其模型本身的识别准确率也达到了较好的水平。考虑到移动端设备的计算能力,最终选择MobileNetV2 作为玉米病害识别模型的基础架构模型。
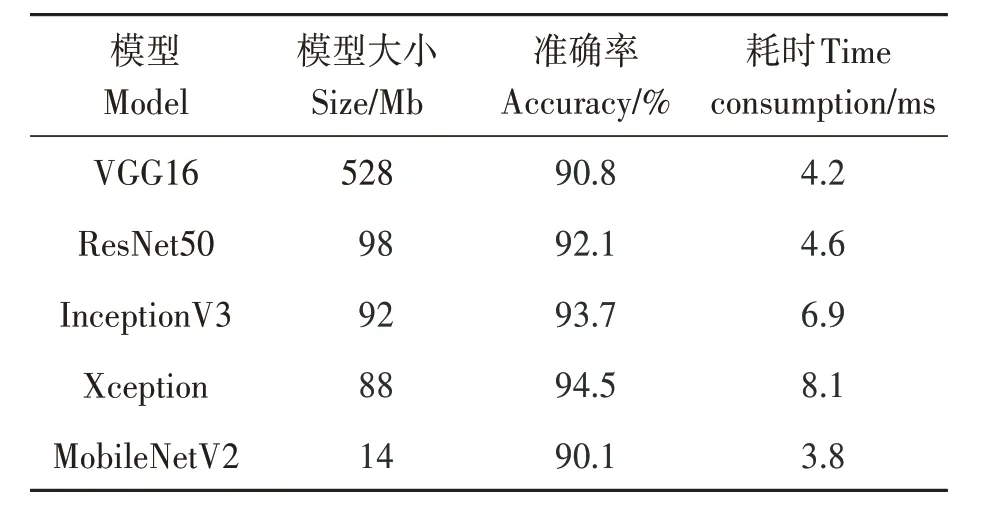
表3 预训练模型参数对比Table 3 Comparison of pre-trained model parameters
2.3 不同优化器对模型识别精度的影响
根据表4 的结果分析,SGD 优化器在模型识别精度上明显小于Adam 和Nadam,经过200 次的迭代后在训练集上的平均识别精度也只能达到87.69%,从识别精度和损失上比较,采用Nadam作为模型的优化器效果更好一些,原因是Nadam算法将Adam 和Nesterov 加速的自适应矩估计结合,这样Nadam 对学习率有了更强的约束,同时对梯度的更新也有更为直接的影响。
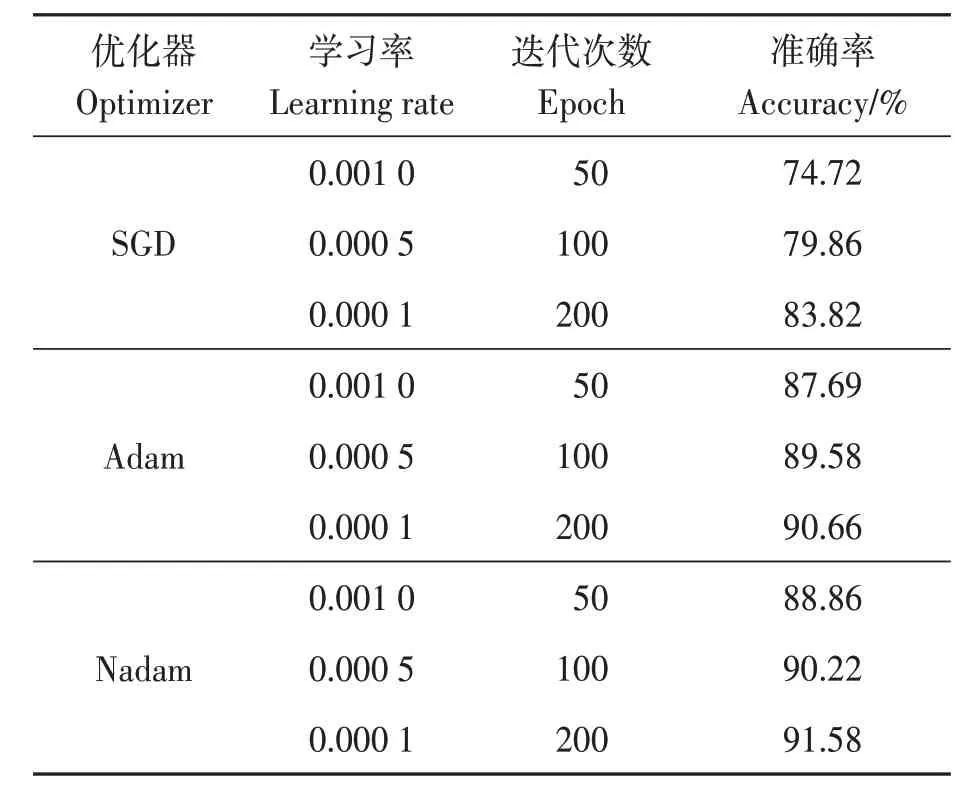
表4 模型的识别精度Table 4 Average accuracy and loss of the model
2.4 模型优化分析
模型训练及优化曲线如图5 所示,在迭代训练区间0 至200 内,随着迭代次数的增加,模型在训练集和验证集上的准确率和损失率的变化情况逐渐趋于平稳并且曲线的波动较小,在150至200区间内,模型逐渐趋于收敛状态,识别准确率最高达到91.58%,损失率最低为0.23。
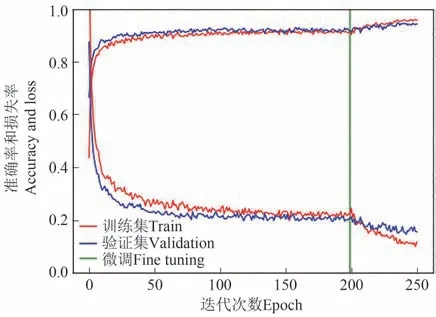
图5 模型的训练曲线Fig. 5 Training curve of the model
为了进一步提升模型的识别准确率,在迭代次数为200 的时候,通过自定义设置将模型的学习率修改为初始学习率0.000 1 的1/10,模型准确率和损失率的变化趋势比较明显,训练集和验证集的准确率逐渐提升,损失率也逐渐降低。同时也表明在训练的过程中学习率的变化会对模型的性能产生较大的影响。最终模型在训练集上的识别准确率最高在98.64%,训练集的损失率最低大约在0.11,验证集识别准确率最高为95.61%,验证集的损失率最低为0.19。
2.5 模型评估效果分析
混淆矩阵可以用来比较实际类别与预测结果的关系,是表达分类准确性的有效方式。使用测试集416张图像对获得的模型进行测试,最终模型对测试集的识别准确率为96.83%,将模型的分类结果和实际测得值比较,最后利用混淆矩阵将测试结果的精度进行展示,结果如表5所示。
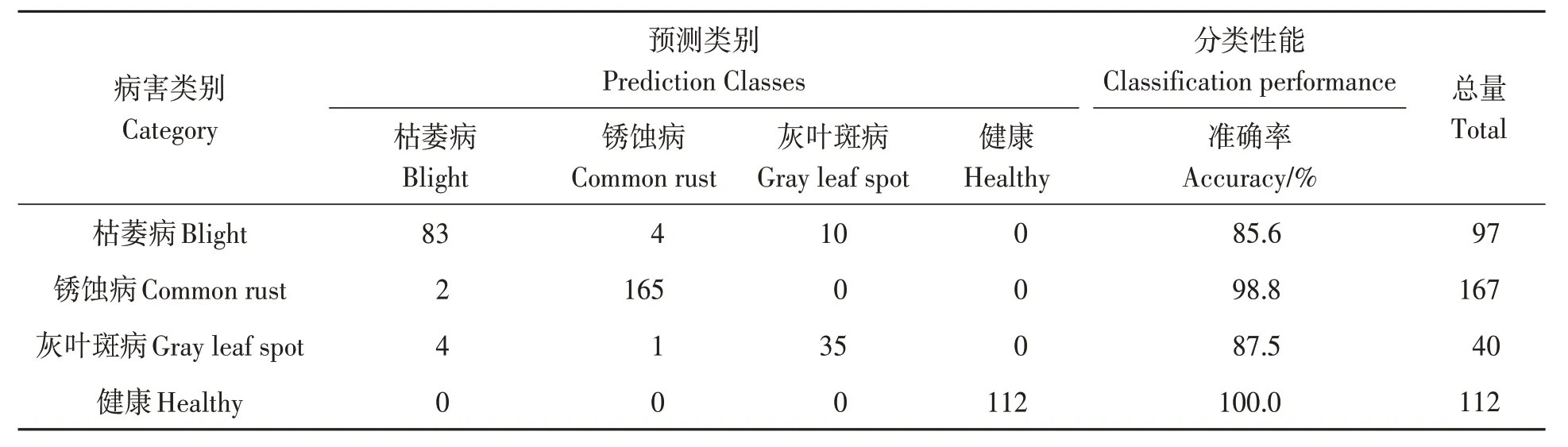
表5 测试集的混淆矩阵Table 5 Confusion matrix of the model
经过测试,模型的分类性能从高到低分别为健康、锈蚀病、灰叶斑病以及枯萎病。识别准确率较低的主要为枯萎病和灰叶斑病,分别为85.6%和87.5%,原因是这2 种病害图像的相似特征较多,另外在某些情况下,同一植物叶片中会出现不同病害的症状或者同一病害在不同的阶段会出现不同的发病症状,从而影响分类结果。另外在将图像输入到模型之前也会改变图像的分辨率,也会导致模型的识别存在一定误差。
2.6 玉米病害识别程序应用
最后应用所呈现的主要功能是使用相机进行拍照或者选择相册中的图像进行识别。如图6 所示,当用户上传图像成功后,模型就会在后台进行计算,最终将计算后的各类别的玉米病害概率显示在界面上。经过测试,该应用的识别准确率以及处理速度都达到了较好的水平。

图6 玉米病害识别应用程序Fig. 6 Application of corn disease diagnostic
3 讨论
目前,利用深度学习技术在处理图像任务领域已经取得了巨大成功,其基本的方法包括分割、滤波和特征提取,当数据集达到一定规模,同时数据集标注质量较高时,就能达到很好的准确率和鲁棒性。但是其在农业病害识别领域中会受到数据集质量、规模及硬件条件的制约。如模型体积大,采用客户端-服务器模式将其部署在服务器上,存在网络因素的限制,本文选择轻量级预训练模型MobileNetV2,并利用模型迁移技术将模型嵌入到移动端设备中,利用数据增强和预处理技术对数据进行处理,以提高模型的应用场景,并充分利用手机的计算资源,不需要服务器等额外资源的开销,与人为识别和传统的深度网络模型对比,该模式在识别精度、速度和应用场景上均高于传统识别方式,最终该模型的识别精度达到96.83%。
SGD 优化算法由于每步接受的信息有限,对梯度的估计准确性低,造成目标函数的收敛状态不稳定甚至出现不收敛状况、随机性较大以及不能保证全局最优解。另外Adam 算法现存一些问题,Wilson 等[14]通过实验总结出,在同一问题下,不同的优化算法可能会找到不同的答案,但Adam往往会错过全局最优解;Sashank 等[15]通过反例验证了Adam 算法在某些情况下可能出现不收敛状况。因此,本文选择结合Adam 和Nesterov 算法,在训练的过程中,Nadam算法的应用效果更有效。
和传统的深度学习模型VGG16、InceptionV3和ResNet50 相比,基于轻量化网络的模型迁移不仅在模型识别准确率以及模型的实际应用上都取得了很好的效果。本研究一方面提高了模型的识别准确率、速度以及充分利用手机设备的计算资源,同时也为其他农作物病害识别应用的研究提供了可行性的参考,但仍需要进一步扩充数据集的数量、质量和种类,进一步提升模型的准确率和增加模型的识别种类。
猜你喜欢
今日农业(2022年3期)2022-06-05 07:12:02
今日农业(2021年8期)2021-11-28 05:07:50
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
烟台果树(2021年2期)2021-07-21 07:18:28
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
今日农业(2020年19期)2020-11-06 09:29:38
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
