
基于信息熵的工业网络涉密信息安全防护策略研究
2023-11-01 02:01杨耀忠段鸿杰王文蔚
自动化仪表 2023年10期
杨耀忠,段鸿杰,胥 林,王文蔚,史 进
(中国石油化工股份有限公司胜利油田分公司,山东 东营 257000)
0 引言
随着工业生产的需求不断加大,为实现工业与信息的持续融合,工业网络应运而生。但工业网络中存在的数据信息常受到入侵威胁,会导致工业网络环境受到较大损害[1-2]。工业网络中的涉密信息需要有效的安全防护,以保障工业生产的持续发展。当前已有相关领域研究学者对信息安全防护方法进行研究。例如:李军等[3]研究基于贝叶斯序贯博弈模型的智能电网信息物理安全;廖元媛等[4]研究基于贝叶斯推理的铁路信号安全数据网信息安全动态风险评估。但以上方法在现阶段无法有效控制多种攻击的入侵,且在遭受入侵攻击后缺少统一的特征衡量标准。
熵方法起初应用于热力学领域。随着大量学者的不断研究,熵方法的应用领域不断扩大,产生了经济熵、地理熵等。有学者将熵概念引入信息论中,产生了信息熵,并提出相关信息熵理论。通过相关信息熵,可以实现多个变量相关性的衡量。
基于此研究背景,本文研究了基于信息熵的工业网络涉密信息安全防护策略。本文通过相关信息熵筛选工业网络入侵数据特征,并提高工业网络信息安全性。本文利用K均值算法提取工业网络入侵数据特征,通过提取到的入侵数据特征实现工业网络入侵检测,以设计全面的安全防护机制。
1 工业网络涉密信息安全防护策略
1.1 涉密信息安全防护机制功能分析
本文采用客户机/服务器方式构建工业网络涉密信息安全防护机制。所构建的安全防护机制具有以下功能。
①保障工业网络涉密信息的安全性。客户机对用户访问涉密信息的次数进行监控,并统计用户浏览信息的次数以及下载涉密信息文件的次数等[5-7]。
②保障用户对涉密信息操作时的信息稳定性。服务器全面分析工业网络中的浏览器版本以及操作系统等性能,确保工业网络稳定。
③服务器保障用户操作时的信息加密性。监控用户对工业网络涉密信息的全部操作,并管理用户的来源[8-9]。
④保障工业网络涉密信息的防篡改性,以及用户操作时的信息加密性。基于相关信息熵与K均值算法实现对工业网络入侵数据的检测,提取入侵数据的特征,及时做好入侵防护。
⑤保障工业网络涉密信息传输过程的安全性。服务器分析多种形式网际互连协议(internet protocol,IP)网络主机的存活性[10-11]。
通过上述分析,本文能够明确工业网络涉密信息安全防护机制的功能,为实现入侵数据安全特征选择奠定理论基础。
1.2 工业网络入侵数据安全特征选择
本文利用相关信息熵对入侵数据进行特征选择,全面分析工业网络入侵数据特征之间的关联性,以及该特征与所属类别的关联性。相关信息熵属于信息熵的1种优化形式,通常应用于多种数据融合领域,并完成多变量的相关性计算。
按照相关信息熵原理,本文设初始工业网络入侵数据特征集合为X={v1,v2,…,vn},并利用该集合表示n个工业网络入侵数据的多变量系统。所属类别集合为L={l1,l2,…,lm},表示系统的时间序列。与其相应的多变量时间矩阵的转置通过F表示。
(1)
式中:Iij为与工业网络入侵数据特征相应的时间点lj的互信息,其中每个元素均存在互信息。
同时,本文利用工业网络入侵数据特征描述系统变量,并利用所属类别描述相应时间序列。Iij为:
Iij=I(vi;lj)=H(vi)+H(lj)-H(vi,lj)
(2)
式中:vi为工业网络入侵数据特征。
本文通过规范化的形式对F进行操作,构成规范化后的多变量时间矩阵P,并根据工业网络入侵数据特征与所属类别的关联情况设计相关矩阵。
(3)

本文设初始特征集合为X、当前完成排序的特征集合为S、还未排序的特征集合为X-S。本文从未排序的特征集合中获取特征vi,添加至已排序的特征中,并设RS∪{vi}为相关矩阵。本文利用矩阵变换理论与信息论的计算方法,通过式(4)计算与S相应的相关信息熵。
(4)
式中:λRS∪{vi}为添加vi后相关矩阵的特征值。
当工业网络入侵数据特征冗余性逐渐下降时,该特征与所属类别的相关程度会逐渐上升,与之相应的相关信息熵也会随之增大。
本文通过2个部分实现相关信息熵的特征选择。2个部分分别为特征排序与特征子集筛选。在特征排序中,通过互信息实现与已完成排序的特征相关信息熵的排序;在特征子集筛选中,利用标准支持向量机(standard-support vector machine,S-SVM)分类器,对衡量值进行计算,并筛选出与最大衡量值相应的特征子集作为下一步应用的特征子集。相关信息熵的特征选择具体可通过以下步骤实现。
①设算法的输入为所属类别集合L、输出为特征子集T。T与前k个特征构成的子集f相对应。
②初始化变量S,使其能够用于保存已排序的特征集,S=∅,T=∅。
③利用式(2)计算Iij,并获取F。
④规范化计算F,获取P。
⑤利用式(3)计算出相关矩阵R。
⑥获取互信息中的最大特征,并将该特征作为特征子集中的首个元素放置在S集合中。S(1)=argmax(Inm)。
⑦通过式(4)对HS∪{vi}进行计算。
⑧取出相关信息熵的最大特征,将其设为特征子集的最后元素,存放至S集合。S(j)=argmax(HS∪{vi})。
⑨对前k个特征构成的f进行运算。
上述步骤分别实现初始化参数、工业网络入侵数据特征排序以及工业网络入侵数据特征子集筛选。经过筛选后即可选择工业网络的入侵数据特征,以实现入侵数据的特征筛选。
1.3 基于K均值算法的入侵数据检测
K均值聚类算法是1种应用较广的非监督学习聚类算法。该算法通过抽取数据局部特征,可以提取空间维度上数据的特征。本文选取优化K均值聚类算法,以实现工业网络入侵数据的特征提取。本文将上述过程中进行特征选择后的样本作为输入数据,将输入数据输入至K均值聚类算法中进行寻优操作。入侵数据检测具体算法步骤如下。
①从上述工业网络入侵数据特征选择后构成的特征子集中随机挑选1个数据点,并设该点为首个聚类簇中心c1。
②将现阶段已选择的聚类簇中心c1设为原点,对每个数据点到达该中心的最短欧式距离进行计算,并将其归到最近的聚类簇中心的类中。下一次某个数据点为聚类簇中心的概率为:
(5)
式中:D(x)为欧式距离计算结果,m;x为某个数据点。
对全部数据点的概率进行划分,通过随机的形式制造0~1区间内的数值。当该数值位于某个区间,则该区间序号相应的数据点为再次出现的聚类簇中心。
③反复执行步骤②,直至挑选得到h个聚类中心。
④对其他点到达各中心的欧式距离进行计算,并将分配给数据点距离最近的中心汇集成点簇。
(6)
式中:xak、xbk分别为第a、b条数据的第k个维度值;dab为2条数据间的欧式距离,m。
⑤依据式(6)计算得到的结果,对每个点簇内全部点的均值进行计算。
(7)

⑥若再次挑选的点簇中心为上一次挑选出的中心,则完成迭代;若并非上一次挑选出的中心,则返回步骤④。在实际计算过程中,需通过式(8)设置迭代完成条件,以防止迭代计算次数增大。
(8)
式中:θ为设定数值较小的阈值;c为点簇中心构成的集合。
当条件满足后,算法迭代即完成。
通过K均值聚类算法,可以有效减少算法的迭代次数,并提升算法计算效率,从而利用入侵数据的特征实现工业网络入侵检测。
2 试验分析
本文将所提方法应用至某DeviceNet工业网络中,对该网络内的涉密信息进行防护,以验证所提方法的有效性。试验采用的网络入侵检测数据集为澳大利亚安全实验室发布的UNSW-NB15数据集。该数据集共有1种正常数据和9种异常数据。9种异常数据分别为“蠕虫攻击”“主机入侵”“欺骗攻击”“重放攻击”“DoS攻击”“篡改攻击”“单源拒绝服务攻击”“伪造源地址拒绝”和“多目标主机单端口攻击”。本文将这9种异常数据作为工业网络入侵检测的攻击类型。试验平台采用Windows10 i7-8700、16 GB内存系统,仿真软件为MATLAB2021b。
2.1 信息熵分析
本文利用MATLAB源代码,使用Python下的K均值函数设定平均码长为3.4 bit、累加概率为0.16、码元携带信息量为0.4 nbit、传码率为2 400 bit/s,以此完成N进制码编制。本文设置N进制码元为0,在工业网络中注入攻击,对涉密信息数据特征子集进行聚类。通过式(6)计算2条数据间的距离,以求取信源的异常熵值。源地址熵值变化分析如图1所示。

图1 源地址熵值变化分析Fig.1 Analysis of changes in entropy value of source address
由图1可知,本文采用所提方法获取7周时间内的异常流量数据,发现在第6周和第7周时源地址上的熵值增加。这说明所提方法能够有效采集工业网络中的异常流量数据,为大规模网络攻击检测提供数据支持。
2.2 攻击检测分析
本文对DeviceNet工业网络进行多种不同种类的攻击,并设计不同的攻击次数,以分析应用所提方法后对攻击检测的命中率以及误报次数。入侵检测分析如表1所示。

表1 入侵检测分析Tab.1 Analysis of intrusion detection
由表1可知,在不同网络入侵类型下,所提方法都能有效实现攻击防护,且攻击检测命中率均达到90%以上。同时,所提方法能够有效降低误报次数,全部攻击类型下的误报次数均保持在10次以下,能够为网络提供精准的安全防护。这是因为所提方法利用相关信息熵对入侵数据进行特征选择,经过筛选后能够选择工业网络的入侵数据特征。
2.3 通信带宽分析
本文以文献[3]方法、文献[4]方法作为试验对比方法,分析应用所提方法前后在不同攻击速率下工业网络涉密信息传输时的通信带宽变化情况。通信带宽变化情况分析如图2所示。
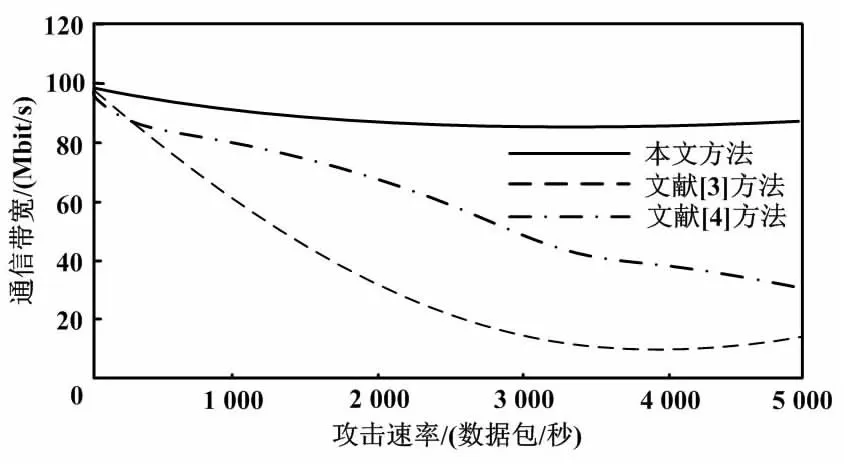
图2 通信带宽变化情况分析Fig.2 Analysis of communication bandwidth changes
由图2可知,随着攻击速率的增长,工业网络的通信带宽存在一定的下降。在应用文献对比方法时,通信带宽随着攻击速率的增加迅速下降,使涉密信息的传输存在一定困难。而应用所提方法后,在攻击速率持续加大的情况下通信带宽仅有小幅度下降,且始终保持在80~100 Mbit/s之间。这说明应用所提方法后,在涉密信息传输受到较大的攻击时依然能有效保持通信带宽的稳定。
本文假设工业网络涉密信息的通信带宽始终为80 Mbit/s,并且在传输信息的第4 h时发生入侵攻击。在这种情况下,本文分析应用所提方法前后的通信带宽变化情况。发生攻击时通信带宽变化情况如图3所示。
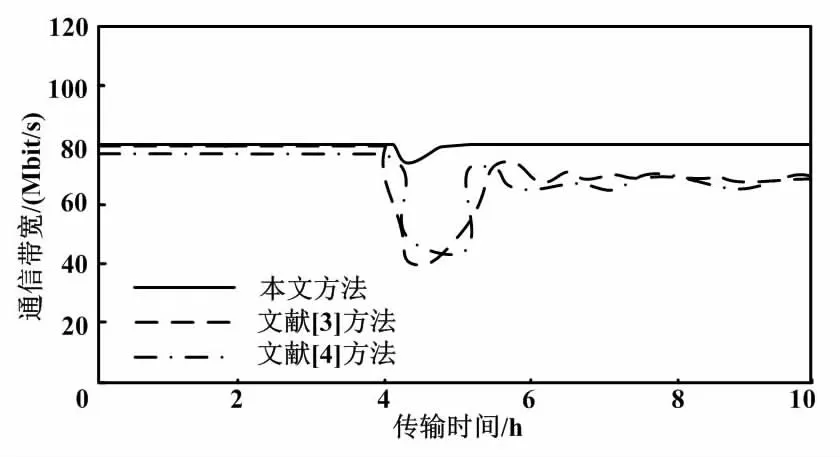
图3 发生攻击时通信带宽变化情况Fig.3 Changes of communication bandwidth when attack occurs
由图3可知,当传输过程中第4 h出现入侵攻击时,通信带宽突然出现波动。在应用文献对比方法情况下,在突然出现入侵时,通信带宽迅速下降。文献[3]方法从80 Mbit/s下降至40 Mbit/s。文献[4]方法从80 Mbit/s下降至42 Mbit/s。之后虽然带宽有所上升,但在传输第6 h后仍然存在带宽波动情况。而应用所提方法后,发生入侵攻击时带宽仅小幅度波动,未对传输造成过大影响,且波动后迅速回归至预设带宽。因此,所提方法能够有效保证涉密信息的传输安全。
2.4 攻击速率分析
本文分析应用所提方法后,在不同入侵检测次数下对各种攻击速率检测的响应时间。不同攻击速率检测响应时间如图4所示。

图4 不同攻击速率检测响应时间Fig.4 Different attack rate detection response times
由图4可知,在不同入侵检测次数下,不同攻击速率的响应时间仅存在小幅度差距。当处于0.1 Mbit/s的攻击速率时,所提方法能够快速实现入侵检测,响应时间基本保持在2 s左右。当攻击速率为1 Mbit/s时,检测的响应时间在3 s左右。而当攻击速率达到10 Mbit/s时,虽检测的响应时间有所增加,但依然保持在8 s以下。这说明应用所提方法能够快速实现入侵的检测,可以实时防护工业网络涉密信息安全。
3 结论
本文研究基于信息熵的工业网络涉密信息安全防护策略。该策略经涉密信息安全防护机制的全方位构建,利用入侵数据的特征实现工业网络入侵检测和工业网络涉密信息的安全防护。通过试验分析,该策略可具体实现以下功能。首先,该策略可以有效提高工业网络入侵检测的能力,对多种攻击检测的误报情况进行优化,并提升预测命中率。其次,当工业网络遭到较大攻击速率的攻击时,该策略可保障涉密信息传输的通信带宽稳定,并保证攻击发生后通信带宽能够迅速恢复到初始状态。最后,该策略提高了工业网络入侵检测的响应时间,保障不同攻击速率下均能够实现迅速检测。
后续研究可对当前成果继续优化,以加深对多类型网络信息的安全防护,使信息得到有效保障。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
黄河之声(2018年5期)2018-05-17
电子测试(2017年15期)2017-12-18
电子测试(2017年12期)2017-12-18
雷达学报(2017年6期)2017-03-26
雷达学报(2017年6期)2017-03-26
池州学院学报(2015年3期)2016-01-05
Coco薇(2015年10期)2015-10-19
电子设计工程(2015年6期)2015-02-27
机械制造文摘(焊接分册)(2014年6期)2014-03-20
