
利用多特征协同深度网络的高分遥感影像分类
2023-11-01 13:02胡春霞聂翔宇傅俊豪储征伟
测绘通报 2023年10期
胡春霞,聂翔宇,林 聪,3,傅俊豪,储征伟
(1. 南京市测绘勘察研究院股份有限公司,江苏 南京 210019; 2. 南京市时空信息智能服务工程研究中心,江苏 南京 210019; 3. 武汉大学测绘遥感信息工程国家重点试验室,湖北 武汉 430079)
随着对地观测技术的不断发展,遥感卫星所获取的影像数据呈高空间分辨率、高光谱分辨率、高时间分辨率和大数据量等特点[1]。具有丰富空间信息的高空间分辨率遥感影像(高分影像)为准确的地物分类、场景识别、目标检测等相关研究和应用提供了数据基础[2]。在遥感影像处理领域,土地利用/地表覆盖分类始终是研究的热点方向[3],遥感影像分类的最终目的是将遥感影像分为多个同质性区域[4]。根据模型在构建过程中是否需要标记样本,遥感影像分类可进一步分为监督分类和非监督分类。
高分影像数据量大,场景结构复杂,覆盖地物类型众多[5],传统机器学习算法缺少对于空间特征的有效表征,分类精度普遍较低。因此,这类方法通常先进行人工设计特征,再使用支持向量机(support vector machine,SVM)或随机森林(random forest,RF)等分类器进行分类[6-7]。近年来,随着深度学习方法在自然图像处理领域的兴起,众多研究者尝试将其应用于遥感影像的分类任务中[8-10]。如,文献[11]基于卷积神经网络(convolutional neural network, CNN)构建了一种低维特征提取模型,用于提取高分遥感影像中的判别性语义信息,并使用多核的SVM作为分类器完成分类。为了有效描述影像中的场景信息,文献[12]使用预训练的VGG-Net作为特征提取器初步提取抽象特征,基于所提出的相关性判别分析策略进行特征融合。文献[13]构建了一种由浅层到深层的特征提取网络,对输入的高分遥感影像进行多阶段的特征提取与融合,最后通过全连接层直接输出预测结果。然而,现有的面向高分影像分类的深度网络依然存在一定的不足:①训练样本的数量和质量难以满足深度神经网络的训练要求;②高分影像场景信息复杂,现有深度神经网络难以有效维持影像内在的空间结构。
为此,本文提出一种多特征协同深度网络(MFCDN)学习算法。该方法的创新和优势在于:①以多类型浅层特征作为网络输入,综合考虑不同类型特征间的协同作用;②有效获取不同空间尺度下的地物信息,用于应对不同难度的地物空间关系;③结合通道和空间注意力机制动态捕获多尺度高维特征的关键信息;④构建多个特征提取层和数据下采样层获取多尺度特征中的语义信息,并通过逐元素相加的方式得到更具判别意义的融合特征。
1 理论基础
1.1 卷积神经网络
如图1所示,一个典型的CNN分类模型通常由卷积层、标准化层、池化层和全连接层构成。其中,卷积层通过卷积算法能够将输入图像从原始空间维度映射到新的特征维度中;标准化层通过对特征的数值分布进行规范化处理,有效解决了训练过程中所出现的梯度消失或梯度爆炸问题;池化层的主要作用是进行数据压缩,在降低参数量的同时缓解模型在训练过程中所存在的过拟合现象,加快模型的训练速度;全连接层用于输出最终的分类结果。
1.2 注意力机制加权
在CNN网络框架中引入注意力机制,使模型具备动态捕获关键信息的能力。如图2所示,引入CBAM[14]模块实现通道和空间自适应加权。其中,通道自适应加权可以看作是一种特征优化方法,而空间自适应加权则是对空间信息的筛选,用于确定关键信息的空间位置。
2 基于MFCDN的影像分类
2.1 浅层特征提取
通过数学形态学[15]、扩展属性剖面[16]和灰度共生矩阵[17]在内的三类浅层特征提取方法获取更具判别意义的特征图,将其作为MFCDN输入,以降低网络内部的特征提取难度。
(1)数学形态学通过使用多种结构元素有效度量影像中相对应的几何形态,在保留影像基本形态的同时,去除大量冗余和干扰信息。本文选取的形态特征包括:开运算、闭运算、顶帽运算、底帽运算、重构开运算和重构闭运算。
(2)扩展属性剖面能够将影像的处理单位从单个像元扩展为一定邻域范围内具有相同或相似属性的所有像元,有效反映了影像中不同地物类型的空间结构关系。通过扩展属性剖面方法提取的属性特征包括:连通区域面积、连通区域外接矩形对角线长度和连通区域内像元灰度值的标准差。
(3)纹理特征是对影像中不同像元之间关系的度量,反映了像元强度值的局部变化信息。在多种纹理特征提取方法当中,灰度共生矩阵的应用最为广泛。本文基于灰度共生矩阵所构建的纹理特征包括:均值、熵、方差、角二阶矩和对比度。
2.2 MFCDN整体架构
MFCDN的整体架构如图3所示,共包括5个部分。
(1)线性映射层:每类浅层特征的通道数不同,因此在输入网络前通过线性运算将各类特征的通道数进行统一。本文的线性映射运算使用核大小为1×1,步距为1,输出通道数为16的卷积层实现。
(2)多尺度特征提取模块:本模块以并行结构的形式,使用多组不同大小的卷积核并结合组标准化(group normalization, GN)和ReLU函数提取多尺度特征。3个空间尺度对应的卷积核大小分别为3×3、5×5和7×7,步距均为1。完成特征提取后,将输入特征和所得到的多尺度特征按照通道维度进行叠加。其中,GN的数学表达为
(3)注意力机制加权:首先,将所得到的高维多尺度特征经过通道注意力机制进行特征优化。然后,使用空间注意力机制进行空间维度上的加权。最后,通过核大小为1×1,步距为1,输出通道数为48的卷积层对数据进行降维。
(4)深度特征融合模块:本模块构建4个特征提取层和4个下采样层以获取多尺度特征中的语义信息,并通过逐元素相加的方式将下采样层3和下采样层4的结果融合。其中,特征层1、4的卷积核大小为3×3,特征层2、3的卷积核大小为5×5,所有特征层的步距均为1。下采样层1和下采样层2为平均池化,下采样层3和下采样层4为最大池化,所有下采样层的核大小均为2×2,步距均为2,即经过下采样层后特征图的高宽减半。
(5)多层感知机模块:本模块作为分类器,用于输出最终的分类结果。所使用的多层感知机由4个全连接层和ReLU函数构成,前3个全连接层的输出神经元个数分别为512、256和128,最后一层的神经元个数为类别数,且丢弃率(drop rate)设置为50%。
完成上述5个模块的运算后,将多层感知机模块的输出结果经过 Softmax 函数,使其满足和为 1 的概率分布。此外,MFCDN以32×32大小的影像块作为输入,采用的损失函数为交叉熵损失(CrossEntropy Loss)。MFCDN中最为关键的多尺度特征提取模块和深度特征融合模块的具体信息见表1。
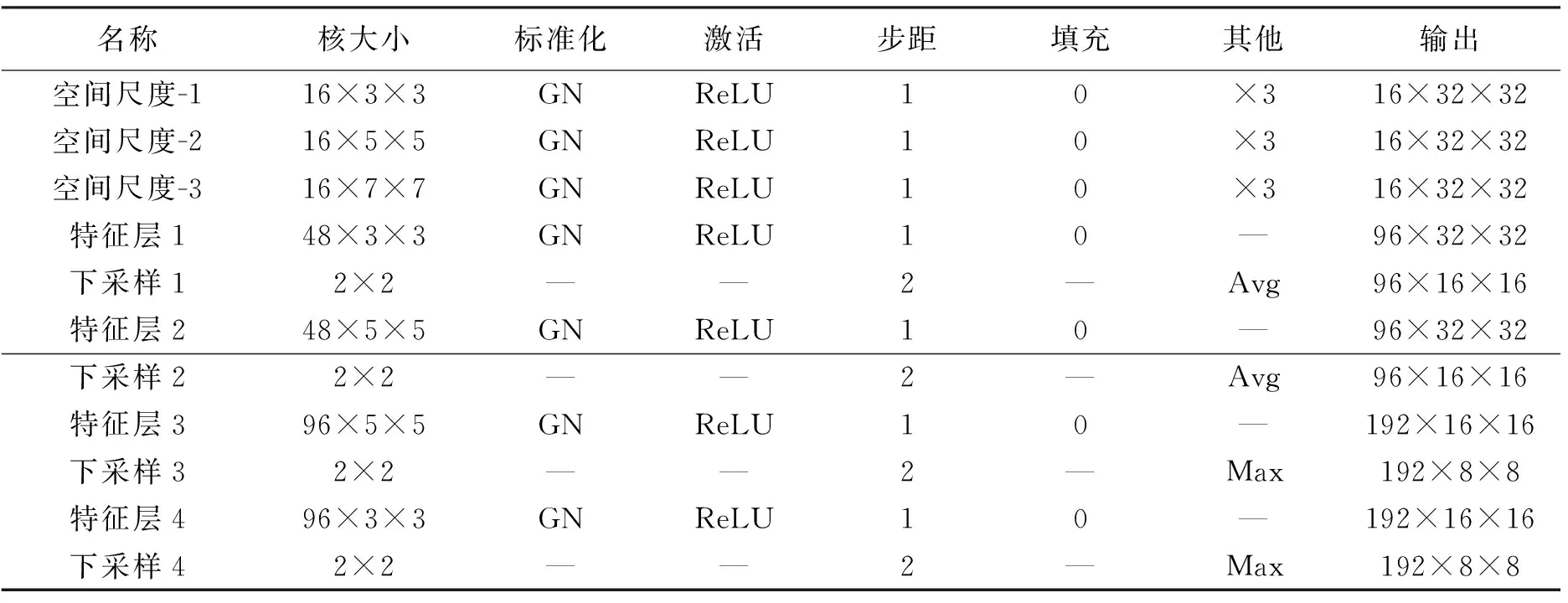
表1 多尺度特征提取模块和深度特征融合模块设置信息
3 试验结果与分析
3.1 试验数据集
(1)Zurich 17 (ZH17) 测试数据集:由快鸟卫星(QuickBird satellite)于瑞士苏黎世市区上空获取。影像大小为1025×1112像素,空间分辨率为0.62 m,包含近红外在内共4个光谱波段。影像的彩色合成图及地物标签如图4所示,共标记了7类地物,具体信息见表2。

图4 ZH17数据集
(2)雄安新区测试数据集:由中国科学院上海技术物理研究所研制的高分专项航空系统全谱段多模态成像光谱仪于雄安新区马蹄湾村上空采集,空间分辨率为0.5 m。如图5所示,从原影像中选取了大小为1000×1150像素的区域用于测试,且仅使用了其中3个波段的数据(R:120,G:72,B:36)。所选取的影像区域共包含13类地物,具体信息见表3。
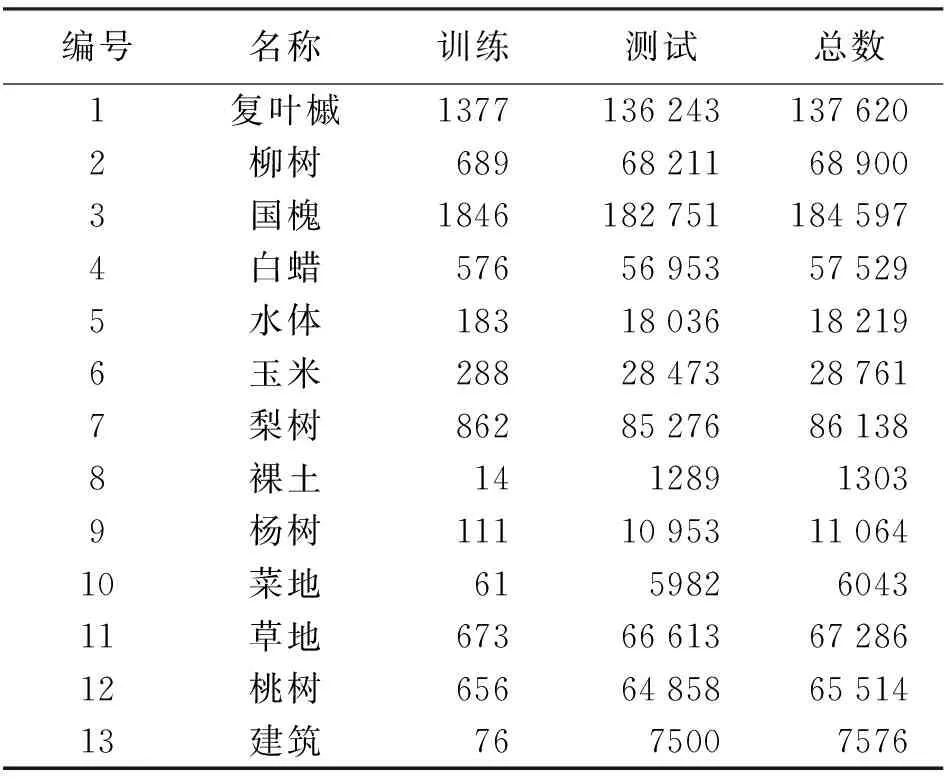
表3 雄安数据集样本数量

图5 雄安数据集
3.2 试验设置
对比方法包括随机森林(RF),支持向量机(SVM),深度金字塔残差网络[18](deep pyramidal residual networks,DPRN)和空谱特征标记化Transformer网络[19](spectral-spatial feature tokenization transformer,SSFTT)。
评价标准包括总体精度(over accuracy,OA)、平均精度(average accuracy,AA)和卡帕系数(Kappa statistic,κ)。
训练过程中,优化器设置为Adam,Batch Size设置为32,GN的组数设置为2,最大迭代次数设置为150,学习率设置为10-4。
3.3 分类结果
(1)ZH17数据集的分类结果见表4,MFCDN方法取得了96.70%的OA、96.53%的AA和0.956 9的κ,较其余对比方法分别提升了2.95%~9.27%、2.89%~15.58%和3.84%~12.08%。针对每类的分类精度,本文方法在6个不同类别上取得了最高的分类精度。各方法的分类如图6所示,RF和SVM方法的分类中存在明显的类似椒盐噪声的情况,整体的平滑度较差。相较之下,DPRN和SSFTT分类的整体平滑度和准确度都有明显提升。综合对比来看, MFCDN的分类结果图最为准确,证明了本文方法的有效性。
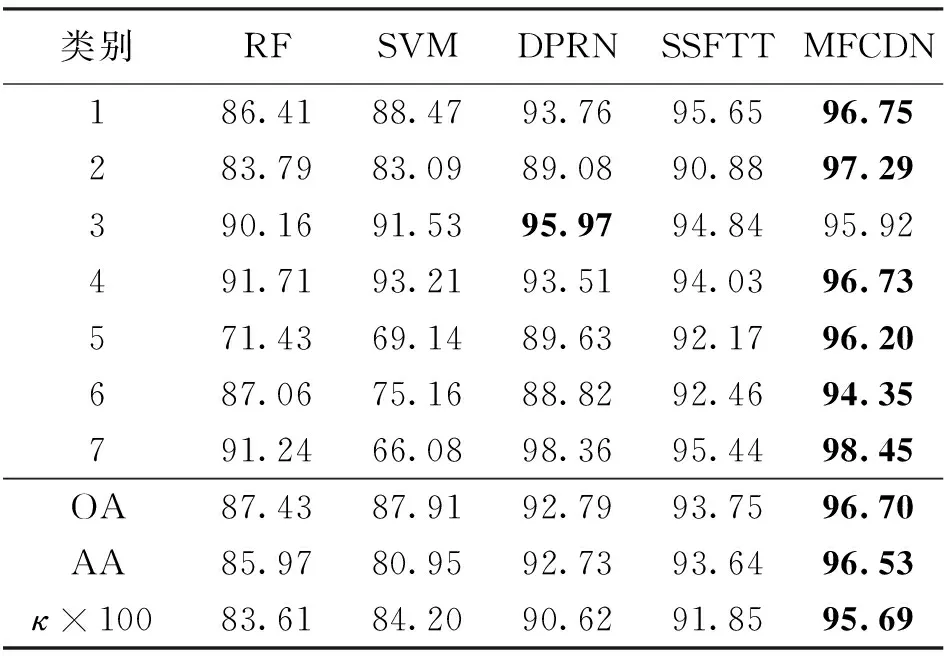
表4 ZH17数据集分类结果 (%)

图6 ZH17数据集上各个方法分类结果
(2)雄安数据集的分类结果见表5,MFCDN在该数据集上的OA、AA和κ分为98.91%,97.03%和0.987 3,较其余方法提升了5.87%~25.82%、8.09%~36.48%和6.86%~30.49%。从单类别的分类表现来看,MFCDN在12类地物上取得了最高分类精度。从图7中的分类结果来看,RF和SVM方法的分类表现依旧不佳,分类中存在大量的噪点。基于深度学习的DPRN和SSFTT方法的分类表现虽然有所提升,但仍然存在明显错分的情况,分类的准确度和整体平滑度远低于所提出的MFCDN。
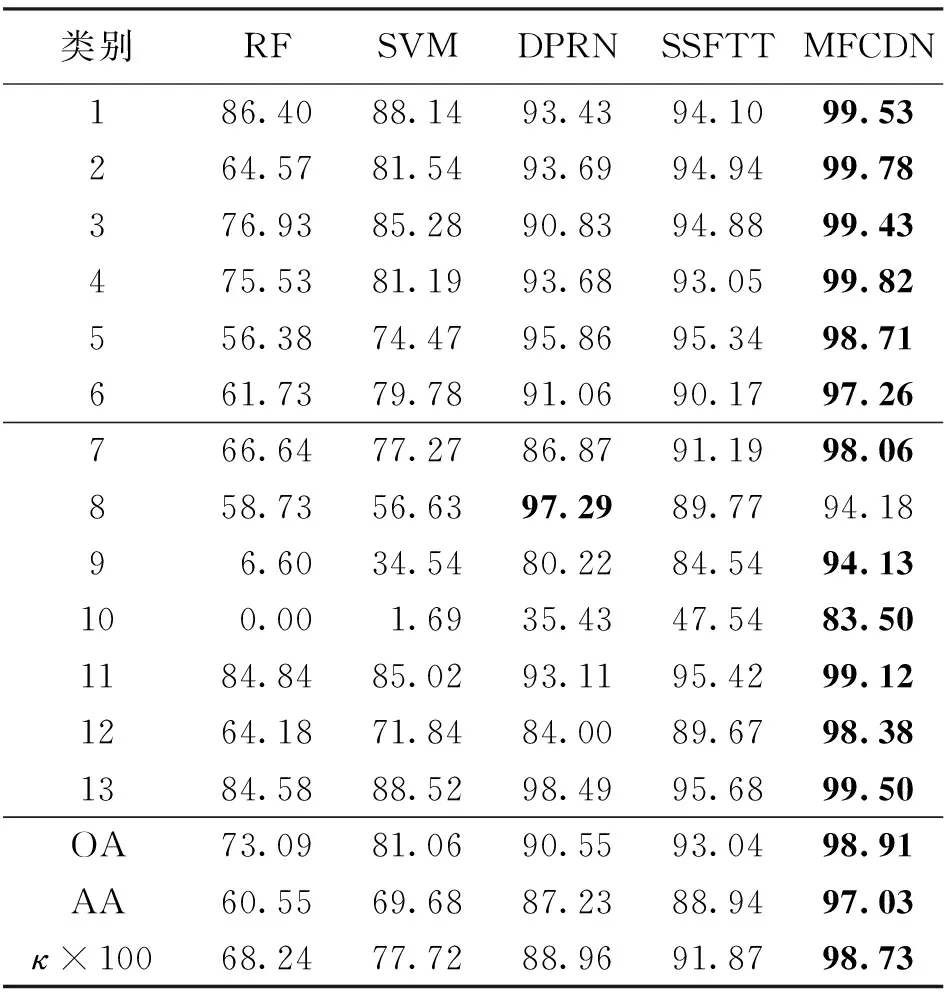
表5 雄安数据集分类结果 (%)

图7 雄安数据集上各个方法分类结果
3.4 训练样本影响性分析
训练样本对分类精度的影响如图8所示。从图中OA的变化趋势来看,随着训练样本数量的增加,各分类方法的OA也在不断提高,且MFCDN始终保持着最高的分类精度。当训练样本的占比仅为0.2%时,MFCND在ZH17数据集和雄安数据集上的OA分别为90.14%和90.12%,对比其余方法提升了1.5%~6.48%和6.09%~23.65%。当训练样本占比为0.6%时,MFCND在两个数据集的OA分别达到了95.11%和97.05%,此时最具竞争力的SSFTT的OA仅为92.62%和90.79%。综合来看,本文的MFCND方法在不同占比训练样本下的总体精度始终处于领先位置,即使在训练样本数量非常有限的情况下也能取得优异的分类结果,证明了该方法具有良好的泛化能力。
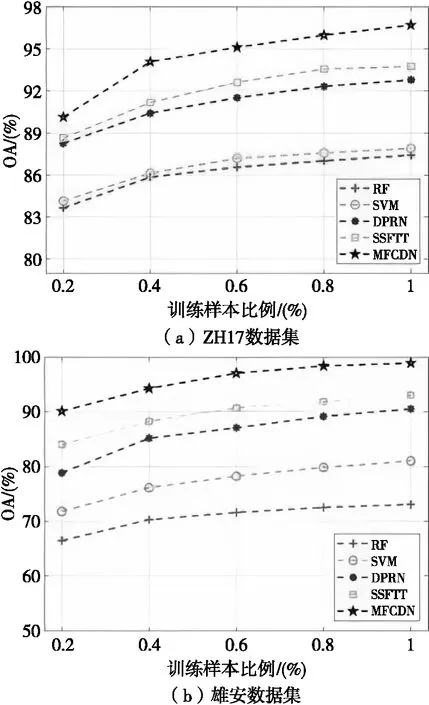
图8 训练样本数量对分类精度的影响
3.5 消融分析
通过对比MFCDN与其变体方法的分类精度以验证各模块的有效性。①仅使用形态特征,记为V1;②仅使用属性特征,记为V2;③仅使用纹理特征,记为V3;④去除多尺度特征提取模块,记为V4;⑤去除深度特征融合模块,记为V5;⑥去除注意力机制模块,记为V6。
消融学习的试验结果如图9所示,对比V1、V2和V3的OA可以发现,属性特征具有比纹理和形态特征更强的判别性。对于V4,由于缺少多尺度信息,在ZH17和雄安数据集上的精度分别降低了1.34%和2.29%。V5在两个数据集上的精度分别下降了3.23%和2.78%,该结果证明了经过深度融合后的特征更具判别性。相较之下,缺少注意力机制的V6在两个数据集上的精度分别降低0.79%和0.46%,下降幅度最小。综合来看,MFCDN中各个融合部分都有助于提升分类性能。
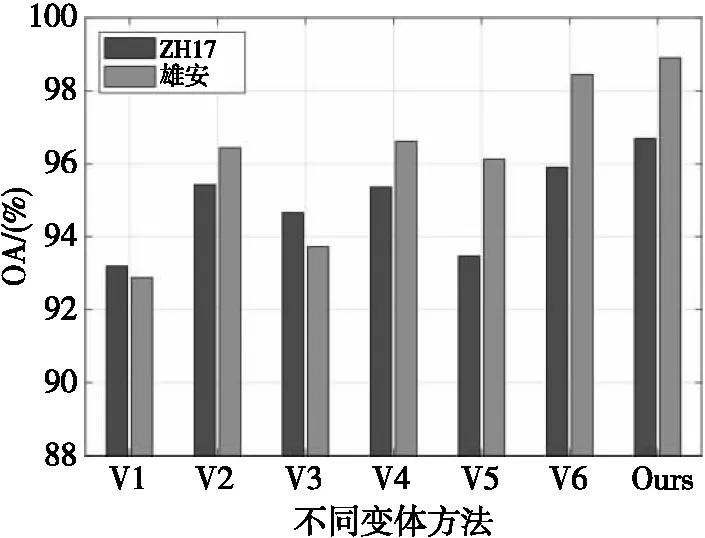
图9 MFCDN不同变体方法的分类精度对比
4 结 语
本文提出了一种新的MFCDN方法用于高分遥感影像分类。该方法综合考虑了多类型特征间的协同作用,并且通过多尺度特征提取模块和深度特征融合模块分别进行多尺度的空间信息提取和深层次的语义特征融合。不同分类方法精度对比的试验结果证明了本文方法的先进性。训练样本影响性分析表明,基于不同数量的训练样本,MFCDN始终可以取得较其余对比方法更高的分类精度。消融分析结果证明,各个模块共同影响最终的分类结果,验证了本文方法的有效性。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
科技创新与应用(2020年6期)2020-02-29
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
太空探索(2016年5期)2016-07-12
噪声与振动控制(2015年4期)2015-01-01
时代英语·高三(2014年5期)2014-08-26
