
一种基于有限数据的改进DCGAN图像生成方法
2023-10-31 12:02王士斌高梓雕刘栋
河南师范大学学报(自然科学版) 2023年6期
王士斌,高梓雕,刘栋
(河南师范大学 a.计算机与信息工程学院;b.“教育人工智能与个性化学习”河南省重点实验室,河南 新乡 453007)
近年来,生成对抗网络(GAN)在合成高保真图像方面取得了巨大的进展.然而,GAN框架的不稳定性极大影响了模型的性能.为了解决上述问题,RADFORD等[1]首次提出了将CNN与GAN相结合的深度卷积生成对抗网络模型(DCGAN).在图像生成的任务中,与其他无监督生成模型相比,DCGAN利用CNN来增强模型提取图像特征的能力[2],不仅提高了模型生成图像的保真度,并且在更深层的网络中,模型依然可以稳定地训练.
但是,DCGAN模型的稳定训练依赖于大量的训练数据.当数据稀缺时,DCGAN依然会出现模型训练的不稳定[3]、生成图像的保真度低[4]和模型崩溃[5]等问题.因此在训练数据稀少、类型单一的条件下,如何设计构造一个可以稳定训练并能生成高质量图像的GAN模型至关重要.现有的方法利用数据增强技术[6-7]来增加有限数据的多样性,从而防止GAN模型出现过拟合.
本文从不同的角度来处理DCGAN在有限数据上的生成任务:模型正则化.目前,虽然有很多正则化技术[8-9]来提高GAN生成图像的保真度,但是很少有旨在提高GAN在有限数据集下生成图像质量.为此,在DCGAN中引入一种新的正则化技术[10]来控制判别器的预测,进而提高模型的生成能力.具体来说,在对当前真实图像的预测和追踪生成图像的历史预测的移动平均变量之间施加一个L2范数.理论证明在温和的假设下,正则化将WGAN公式转换为最小化的f-散度称为LeCam散度.通过实验证明,在有限的训练数据下,LC-DCGAN模型可以更好地学习图像的语义信息来生成高质量的图像,并且提高了模型的稳定性.
1 相关工作
目前,GAN在计算机视觉领域取得了显著性的成就.自2014年原始GAN提出后迅速与全卷积网络进行融合,并且继承了CNN最成功的设计,例如池化层[11],批量归一化[12],Leaky ReLU[13]等.随着GAN技术的发展,GAN在风格迁移[13]和超分辨率[14]等领域被广泛应用.与此同时,为了GAN的稳定训练,许多相关技术相继产生,例如数据增强[15]和对抗损失[16]等.
生成对抗网络的正则化:GAN的稳定训练离不开正则化方法的引入.大多数现有的正则化方法都是为了解决模型的稳定训练和缓解模型崩溃的问题.如BERA等[17]提出了一种新的称为谱归一化的权重标准技术来稳定判别器的训练.具体来说是使用第一奇异值的运行估计对参数进行归一化操作,在判别器上强制保持Lipschitz连续性.ODENA等[18]研究了GAN中生成器的雅可比行列式奇异值的分布,发现性能依赖于生成器的训练.
有限数据下的生成对抗网络:当在数据样本有限的情况下训练GAN模型时,会导致网络模型训练动态不稳定、生成图像的质量差等问题.为此LI等[19]提出了一种简单的正则化损失,提高了DCGAN模型架构的性能,解决了网络模型训练不稳定和模型缺失的问题.ZHAO等[20]提出了一种改进的一致性正则化(ICR)将潜在一致性正则化(zCR)和平衡一致性正则化(bCR)结合起来,提高网络模型的稳定性和生成图像的质量.KARRAS等[21]提出一种自适应的判别器增强机制,使网络模型在有限的数据样本下稳定地训练,并提高了模型的泛化能力.
2 预备知识及模型架构
2.1 生成对抗网络
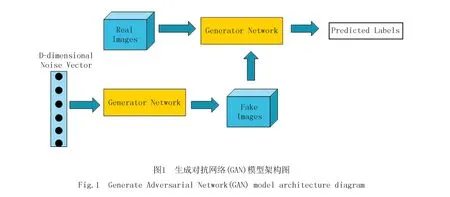
GAN是一种无监督深度学习的模型,主要是由生成器和判别器两部分组成,GAN训练过程中通过相互博弈来逐步提高模型的学习能力.其中,生成器主要通过模型学习真实数据的特征分布规律生成虚假数据,而鉴别器的主要作用是鉴定数据是真实数据还是新生成的虚假数据.GAN训练的最终目标是鉴别器输出的概率值为0.5,达到纳什平衡.GAN模型架构如图1所示.
GAN的目标函数如下所示:
其中,x表示真实数据,z表示随机高斯噪声,pdata表示真实数据概率分布.令VD和LG分别表示判别器和生成器的训练目标函数,则GAN模型的训练可以描述为:
(1)
其中,fD,fG和Gx表示映射函数.
2.2 模型架构
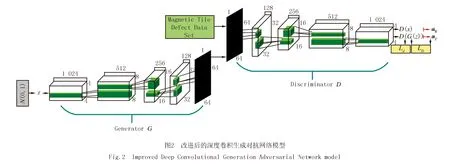
为了提高DCGAN模型在有限数据下的性能,通过在DCGAN的判别器上引入两个指数移动平均变量αR和αF(即称为锚点),用以跟踪判别器对真实图像和生成图像的预测,其目的是减少小批量之间的方差,并且稳定RLC正则化项,使其判别器的预测逐渐收敛到平稳点. LC-DCGAN整体结构图如图2所示.
αR和αF的计算公式如下所示:
α(t)=γ×α(t-1)+(1-γ)×ν(t),
(2)
其中,α是指数移动平均变量(即αR和αF),ν(t)是训练步骤t的当前值,γ是衰减因子.使用式(1)中描述的相同的目标函数LG来训练生成器,并最小化判别器的正则化目标函数LD:
(3)
(4)
2.3 LeCam-divergence
将正则化项与f-divergence之间的关系称为LeCam-divergence.对于两个离散分布Q(x)和P(x),f-divergence的定义为如下所示:
(5)
如果f是一个凸函数,则f(1)=0.对于WGAN正则化目标为式(3)所示,其中RLC是一个单锚并且λ>0.假设对于一个固定的生成器,锚点收敛于一个平稳值α(α>0).当固定最优判别器D时,生成器的目标函数用C(G)表示,如下所示:
(6)
Δ(P‖Q)是LeCam散度,三角形判别公式如下所示:
(7)
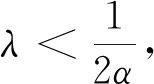
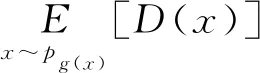
(8)
其中α>0是真实图像的单锚.由于D(G(z))≤0,所以当使用单锚时,αR=-αF=α.
判别器的正则化目标:
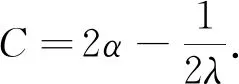
最优判别器D*计算公式如下所示:
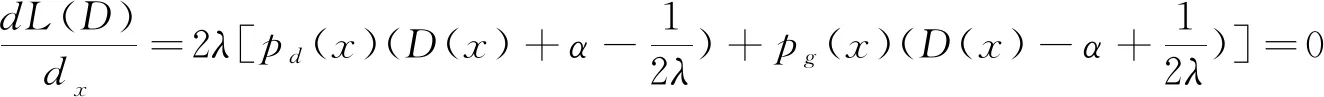
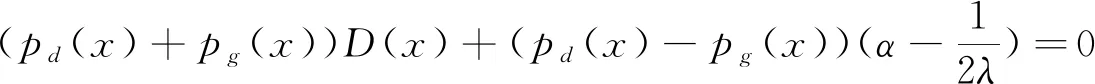
当固定判别器D,则生成器的目标函数如下所示:
由于正则化项只添加到判别器上,生成器保持不变,所以C(G)的表达式如下所示:
3 实 验
3.1 数据集
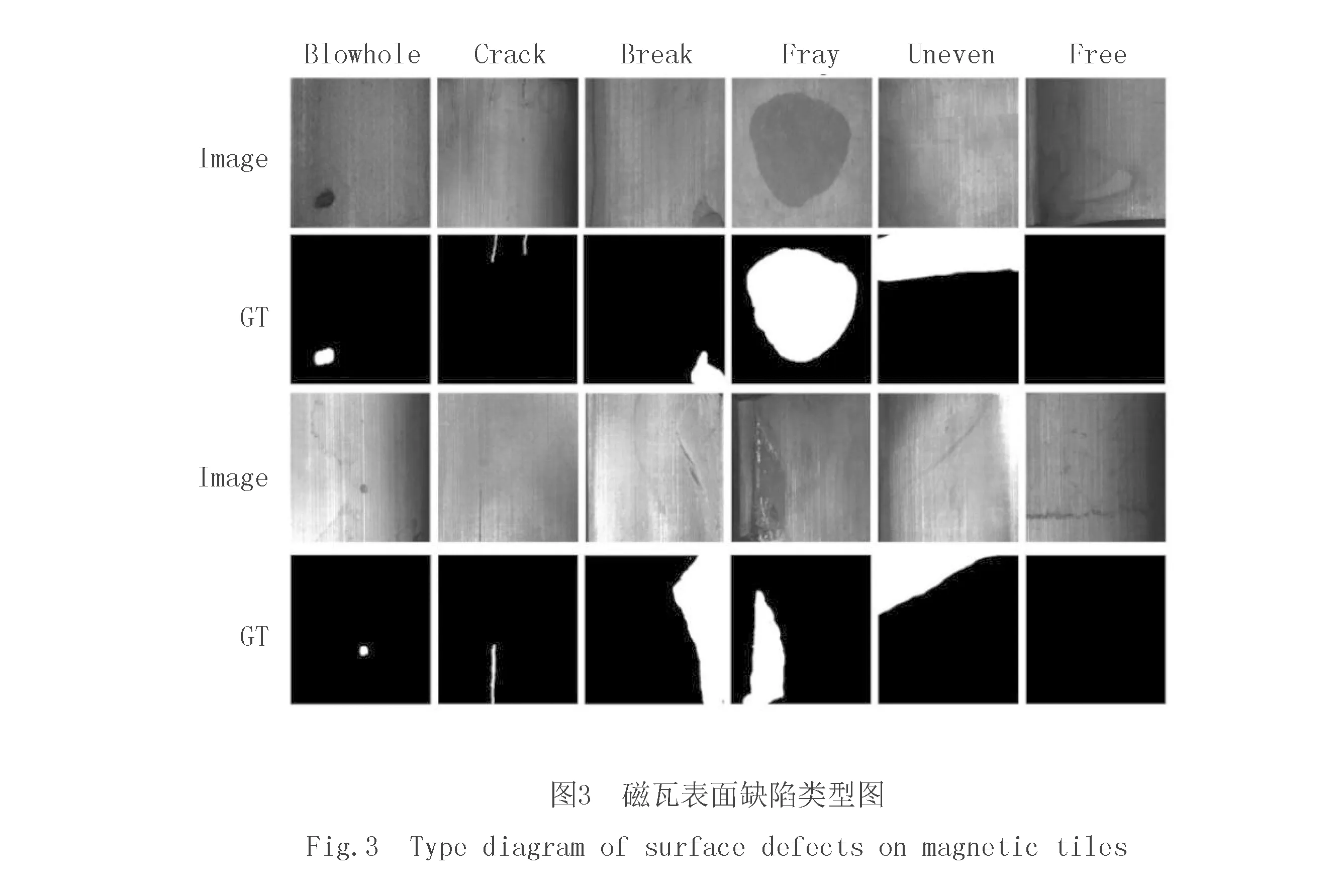
在实验中采用磁瓦表面缺陷数据集作为该模型训练的数据,该数据集是中国科学院自动所收集的6种常见磁瓦缺陷的图像,共含有1 344张图像,其中包含5种缺陷类型(破损、裂纹、磨损、表面不均匀、气孔),1种无缺陷类型.磁瓦表面缺陷类型如图3所示.
3.2 分类算法
在机器学习中,ELM-LRF是一种分类速度快、效率高的分类算法,该分类算法将卷积层和池化层融合到ELM中,通过卷积对输入图像进行特征提取,使用ELM的权重输出公式对输入图像进行分类.因此本文中采用ELM-LRF分类算法对生成图像和真实图像进行分类,根据分类的准确率来评判生成图像质量.ELM-LRF网络架构如图4所示.
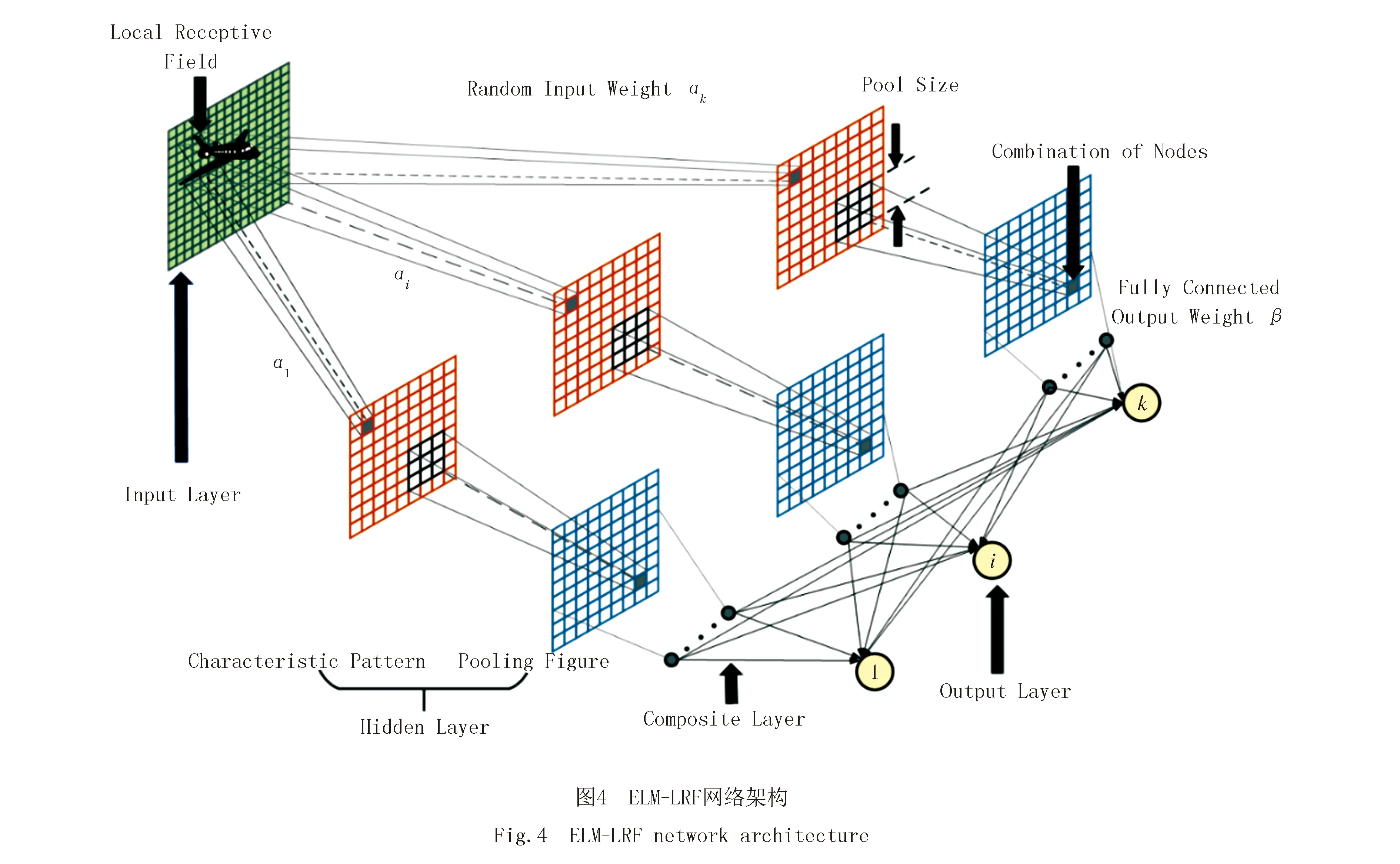
输入K个不同的输入权重,输出K个不同的特征图,该过程的实现细节如下所示.
1)随机生成初始权重Ainit.假设图像的宽和高均为d,局部感受野的宽和高均为r,则特征图的高和宽为d-r+1.其具体的计算公式为:
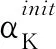
求出Ainit后,利用奇异值分解(singular value decomposition,SVD)算法将Ainit正交化.Ci,j,k表示为第k个特征图的节点,其计算公式如下:
2)平方根池化.其计算过程如下所示:
其中,e代表边到池化中心之间的距离,即池化大小.池化图的高和宽均为(d-r+1).
3)计算输出权重矩阵.其具体的计算公式如下所示:
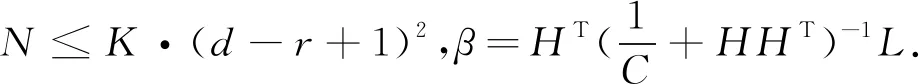
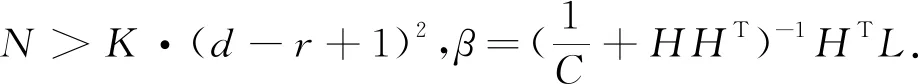
3.3 实验结果分析
由于数据集里的图像大小不一致,不同缺陷类型的感兴趣区域(Rogin of interest,ROI)也不相同,所以在该模型训练之前,先将数据集重塑为64×64的图像(图5(a)),在实验的过程中发现所生成图像质量(图5(b))并不能满足实验要求.本文使用Wellner自适应阈值的二值化算法,将图像转换为二值图(图5(c)).将经过转换的二值图输入至LC-DCGAN模型后可以生成更高质量的图像(图5(d)).

因此,通过将5种磁瓦缺陷原图(图6(a)),使用Wellner自适应阈值的二值化算法,将磁瓦缺陷原图转换为二值图(图6(b)),将其作为改进后模型的输入,输出的生成磁瓦缺陷图像如图6(c)所示.为了验证改进模型的性能,本文将转换后的二值图分别输入至DCGAN和GAN模型中进行训练,网络模型生成的图像分别如图6(d)、图6(e)所示.

通过图6的实验对比图可以看出,使用相同数据集作为模型的训练样本时,LC-DCGAN模型生成图像的噪声杂质是最少的,并且生成图像更接近原图像二值图的缺陷特征.
为了检测LC-DCGAN模型生成的图像质量是否符合数据集中的图像,本实验中采用ELM-LRF分类算法对生成图像和原始图像分类.在分类的对比实验中共进行了4组对比实验,每组实验重复50次,分别计算每种实验的平均分类准确率并将平均分类准确率作为测量生成图像质量的评价指标.在第1组实验中,磁瓦缺陷原图像作为LC-DCGAN模型的训练集和测试集.其图像数量设置如表1所示.

表1 第1组训练集和测试集的数量设置
第2组实验,将原样本作为模型的训练集,选择同种类型相同数量的生成样本作为测试集.第3组实验,选择与原图像数据类型相同且数量相同的生成图像作为训练集,将所有的原图像作为测试集.第4组实验,将所有原图像和与原图像类型相同数量相同的生成图像进行堆积混合,选取前50%的图像数据作为训练集,后50%的图像数据作为测试集.按照以上的训练设置来依次进行分类实验.
使用ELM-LRF分类算法分别对以上4种数量设置的训练集和测试集进行对比实验,每组的平均分类准确率如表2所示.

表2 ELM-LRF分类实验平均分类准确率
由表2可知,在4组分类实验中平均分类准确率分别为88.93%、88.69%、87.47%、91.49%.第3组在实验中的分类结果最差,第4组的分类结果最好.在第1组实验中,模型的训练集和测试集数据,均来自磁瓦缺陷的原图像,并且训练样本和测试样本的数量与其他3组实验均不相同,因此将第一组实验的分类准确率作为其他3组实验的参考.第2组实验中,将原图像作为训练集,模型学习原图像的缺陷类型,然而生成的图像含有其他缺陷类型的图像,当把生成图像作为训练集时,平均分类准确率不会太高也不会太低.第3组实验中,将生成图像作为训练集,模型可以学习到更多缺陷类型的特征,所以当把原图像作为测试集时,平均分类准确率将会是4组中最低的.在第4组实验中,因为将生成图像与原始图像随机混合后提高了图像缺陷类型的多样性,因此在模型训练的过程中,模型具有更高的泛化性能,则该组的分类准确率最高.
由4组实验的分类准确率可知,其他3组的平均分类准确率与第1组的平均分类准确率十分接近,由此证明,改进的深度卷积生成对抗网络模型生成的磁瓦缺陷图像可以满足ELM-LRF磁瓦缺陷分类的实验要求.
4 结束语
在这项工作中,针对数据有限的情况下,生成对抗网络容易出现训练不稳定和生成图像样本质量低的问题,提出了一种基于DCGAN的模型,加入了一种在训练数据稀少情况下训练DCGAN模型的正则化方法.在模型训练阶段,提高模型的稳定性和生成图像的保真度.实验结果证明LC-DCGAN在样本稀少的情况下,不仅可以生成高保真度的图像,而且可以使得模型训练时更加稳定.在未来的研究中,将进一步在提高生成图像的保真度和高分辨率的生成任务上努力.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
数学年刊A辑(中文版)(2019年1期)2019-01-31
数学杂志(2018年5期)2018-09-19
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
