
基于属性补全的药物与疾病关联预测
2023-10-31 09:39唐瑞泽
智能计算机与应用 2023年10期
唐瑞泽, 玄 萍
(1 黑龙江大学 计算机科学技术学院, 哈尔滨 150080; 2 汕头大学 计算机科学技术系, 广东 汕头 515063)
0 引 言
研发一个用于疾病治疗的新药需要一个漫长的过程约10 ~15 年,同时还会花费8 ~15 亿美元[1]。药物重新定位是为已批准的药物寻找新的治疗效果[2]。 已上市的药物具有已知的安全性和药理学特征,因此药物重新定位可以将药物开发的时间缩短到6.5 年,并把研发成本降低到3 亿美元。
计算已批准药物的新治疗适应症,有助于在筛选现有药物进行进一步实验验证时预测候选疾病。现有的计算预测方法大致可分为3 类,两种药物的功能越相似,就越有可能与类似的疾病相关。 因此,第一类的方法主要是利用药物-疾病关联、疾病相似性和药物相似性数据进行药物-疾病关联预测。例如,Zhang 等[3-4]利用非负矩阵分解和相似性约束的矩阵分解来整合已知的药物和疾病信息,获取药物和疾病的关联概率。 还有一些方法通过在药物-疾病异构网络上随机游走来预测关联分数[5-6]。Wang 等[7]构建了一个支持向量机模块(SVM)来推断药物的未知治疗效果。 然而,随着药物相关数据的增加和多样化,除了考虑药物的基本靶点信息和蛋白质结构外,其他信息对预测疾病候选者也很重要,而这些方法并没有整合这些多源数据。
第二类方法考虑使用与药物和疾病相关的多个数据源进行关联预测。 已经开发了几种方法,非负矩阵分解、稀疏子空间学习或推理概率矩阵分解来预测候选药物注释。 还有一些方法通过在构建的异构网络上随机游走来预测各种药物的候选疾病[8]。然而,多个数据源表现出复杂的非线性关系,整合这些数据对于探索药物与疾病的相关性至关重要。
第三类方法采用深度学习方法整合药物和疾病相关信息,以更准确地识别合适的疾病候选者。Xuan 等[9]提出了一个基于CNN(Convolution Neural Network)和BiLSTM(Bi-directional Long Short-Term Memory)架构的模型,用于预测药物-疾病关联分数。 此外,还构建了基于卷积神经网络的模型和基于图卷积网络(GCN)的模型来推断药物的候选疾病。 然而,在深度学习过程中,没有考虑以节点间的拓扑关系为指导,通过加权聚合有属性节点的属性来补全无属性节点的属性[10]。 在这项研究中,本文提出了一个基于属性补全的预测模型,从不同的元路径编码和捕捉异构网络中节点的拓扑嵌入,为无属性节点进行属性补全。
1 材料和方法
为了预测特定药物的潜在适应症即候选疾病,本文提出了药物-疾病关联预测模型。 首先,基于多种药物相似性、疾病相似性和药物-疾病关联构建了3 种不同的药物-疾病异构网络;构建多个元路径,用来编码和学习药物和疾病节点的拓扑嵌入,并提出一个基于元路径层面的注意力机制,融合来自多个元路径的不同的语义信息;以融合后的药物(疾病)节点的拓扑嵌入为指导,对有属性的药物节点的属性进行加权聚合来补全没有属性的疾病节点的属性;最后,将得到的3 个网络的药物-疾病节点对的属性通过1×1 卷积融合,通过两层全连接神经网络,输出药物和疾病是否存在关联的分数。
1.1 相关数据集
本文从以往的药物-疾病关联预测工作中获得药物与疾病的关联、药物的化学亚结构、药物的靶蛋白结构域、药物的靶注释以及疾病语的语义相似性。3 051个已知的药物-疾病关联数据最初是从联合医学语言系统(UMLS)中提取的,其中包含763 种药物和681 种疾病之间的治疗关系。 本文主要利用了3种药物属性,药物的化学结构是从PubChem 数据库中提取的化学指纹,从InterPro 数据库和UniProt 数据库中获得了药物的靶蛋白结构域和药物的靶注释。 相关的疾病命名由美国国家医学图书馆提供(MeSH)。
1.2 药物和疾病的多源数据矩阵表示
1.2.1 多种药物属性表示
基于多种药物相关的数据,本文用矩阵Bp(p =chem,doma,anno) 分别表示药物的3 种属性,即药物的化学子结构,药物靶蛋白的目标域和基因注释。Bp被定义为式(1):
其中,Nr表示药物的数量,Nchem(Ndoma,Nanno)是药物化学子结构(药物靶蛋白的目标域,基因注释)的数量,Nchem =623,Ndoma =1 426,Nanno =447。
如果Bchem(i,j) 的值为1,表示药物ri具有化学子结构cj,否则值为0。 同样地,如果药物ri含有靶蛋白结构域oj(基因注释tj),将Bdoma(i,j)(Banno(i,j) )的值置为1,否则为0。
1.2.2 多种药物相似性表示
两个药物ri和rj之间具有越多相同的化学子结构,通常这种情况下药物ri和rj在功能上具有更高的相似性;类似地,当药物ri和rj具有更多相同的靶蛋白域或者靶注释,ri和rj之间也会具有更高的相似性。 基于这些生物性前提,Wang 等[11]通过余弦相似性计算得到了3 种不同的药物相似。 3 个药物相似矩阵分别为Srchem,Srdoma,Sranno。 药物相似性矩阵定义为式(2):
反映了药物之间在化学亚结构方面的相似度大小,Srdoma(Sranno) 表示一对药物在蛋白质结构域(靶注释)下的相似度大小,取值范围在[0,1]之间,数值越大说明两种药物就越相似。
1.2.3 疾病相似性表示
有向无环图(DAG)通常被用来表示一种疾病,该图是由多个与该疾病相关的疾病术语组成。 两个疾病有越多相同的疾病术语,两个疾病之间越相似。通过余弦相似性计算得到的矩阵Sd∈表示两种疾病之间的相似性,Nd是疾病的数量,的值域[0,1],值越高,di和dj之间越相似。
1.2.4 药物-疾病关联表示
关联矩阵Ard∈包含了Nr个药物和Nd个疾病之间的关联。 每一行和每一列分别代表一种药物和一种疾病。 如果ri和dj之间存在关联,则Arijd的值为1,否则Arijd =0。
1.3 多个药物-疾病的异构网络
面对3 种不同的药物相似性,构建3 个药物-疾病异构网络Gp =(V,E) 。 每个异构网络包含了两种类型的节点V =(Vr∪Vd) 和3 种类型的边E =(Erp-r∪Ed-d∪Er-d) 。 每个异质网络中的节点总数是药物节点和疾病节点数量之和(Ntotal=Nr+Nd),Erp-r是基于第p种药物相似性建立的药物-药物相似性的边。 利用已知的关联数据,建立药物-疾病的边,用Er-d表示。 如果节点vi,vj∈V之间存在一个连接,那么eij∈E。
1.4 多个药物-疾病双层网络的邻接矩阵
基于药物-疾病关联和多种药物相似性矩阵,本文构建了p个双层异构网络的邻接矩阵Hp∈RNtotal*Ntotal,式(3):
其中,(Ard)T是Ard的转置矩阵。
1.5 基于元路径的成对拓扑结构编码
本文构建的双层异构网络Hp, 包含药物和疾病节点。 多重关系也包括在内,r -r,d -d,r -d表示药物-药物相似性,疾病-疾病相似性以及药物和疾病之间的关联关系。 在异构图中,许多节点可以通过具有不同语义的路径连接,被称为元。 长度为m的元路径定义为式(4):
其中,v1,v2,…,vm+1表示节点类型,n1,n2,…,np表示连接v1和vm+1的边的类型。
一个元路径实例被定义为异构图中的一个节点序列。r1和r4可以通过元路径r -r -r和r -d -r的方式连接。 例如,目标节点r1的元路径r1- r2- r4,如果药物r1和r4都有r2类似的功能,其可能是相似的;在r1- d3- r4中,这两种药物都和疾病关联,表明r1可能和r4相似。 不同的元路径显示出不同的语义信息。 考虑到药物ri的直接邻居和经过两跳之后的邻居对其影响较大。 因此,本文建立长度为1的元路径和长度为2 的元路径δ∈{r - r,r - d,r -r - r,r - d - r,r - r - d,r - d - d}。 同样的,对于疾病节点dj,分别建立长度为1 和长度为2 的元路径δ∈{d - r,d - d,d - r - r,d - d - r,d - r - d,d - d - d}。 用Pδr(Pδd) 表示药物(疾病) 节点的元路径。
基于Hp结构信息,药物和疾病之间存在各种连接关系,φ∈{r - r,r - d,d - d,d - r}。 元路径与这些关系相对应的邻接矩阵表示为Xk∈RNtotal*Ntotal,其中k∈φ。 以k =r - d为例,Xk被定义为式(5):
当且仅当节点i和j之间存在r - d的关系时,1,否则为0。
对于每条元路径,都要建立其相应的拓扑嵌入。对于元路径k包括在δ中的第e个关系的邻接矩阵被归一化为,式(6):
其中,Oi表示第i行元素之和,Zj表示第j列元素之和。 元路径δ的拓扑嵌入是T,式(7):
其中,|δ |是长度。
例如,元路径r - r - d的长度为2,相对应的拓扑嵌 入在 不 同 的 元 路 径 下表示药物(疾病) 节点基于Hp下的拓扑嵌入,其中p∈{chem,doma,anno}。
1.6 多种语义信息的融合
给定药物ri(疾病dj) 的元路径Pδr(Pδd), 其特定的语义表示为(T pr,δ)i((T pd,δ)j)。 每一个元路径都反映了一个特定的语义信息,对构造药物(疾病)节点的拓扑嵌入有着明显不同的贡献。 因此,本文提出了一个元路径层面的注意力机制,有助于融合多种语义。 以药物节点为例,元路径类型层面的注意力得分为(spr,δ)i,式(8):
其中,tanh 表示一个非线性激活函数;δ∈{r -r,r - d,r - r - r,r - d - r,r - r - d,r - d - d};batte是注意力参数;qT是可学习参数。
(βpr,δ)i代表归一化的注意力权重,式(9):
药物节点的拓扑表示(hpr)i通过元路径层面注意力机制增强后定义如下,式(10):
类似地,也得到了疾病dj在不同元路径聚合下的拓扑表示(h pd)j。
1.7 基于邻居层面注意力机制的属性补全
给定一对药物和疾病节点(ri,dj),和其相对应的节点拓扑嵌入表示(hpr)i和(hpd)j,本文用Vr+表示所有与疾病dj相关联的药物节点的集合,其中药物ri具有节点属性,疾病dj不具有节点属性。 通过对与疾病节点dj直接相连的药物节点的属性加权聚合作为疾病节点dj的属性,实现对疾病节点dj的属性补全,属性补全的示意图如图1 所示。
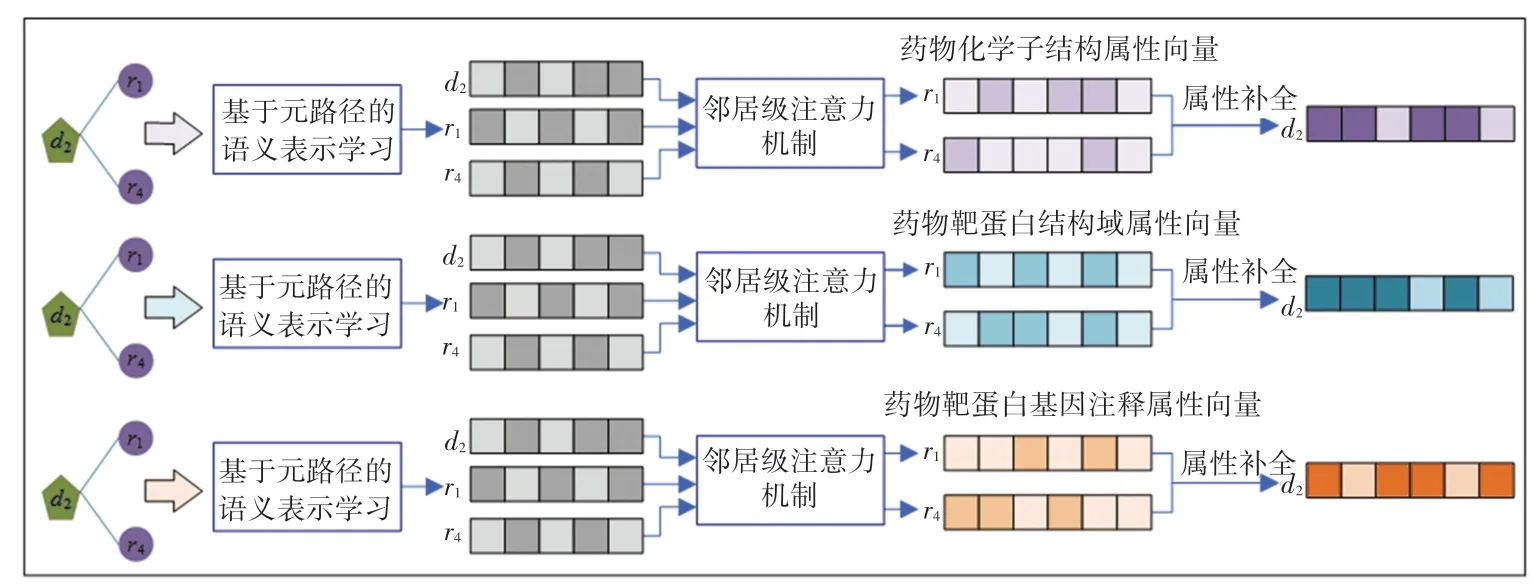
图1 基于疾病节点属性补全的示意图Fig.1 Schematic of disease node attribute complement
因为局部拓扑结构不同,每个节点的邻居在属性聚合的重要性不同,也就是一个节点的邻居越多,其对每个邻居的重要性就越低。 因此,本文提出一个邻居层面的注意力机制来学习节点不同邻居的重要性,式(11):
其中,σ是激活函数,Wpc是权重矩阵。
归一化注意力权重apij表示如式(12):
最终利用注意力机制对与疾病dj相连的药物节点的属性加权聚合对疾病dj实现了属性补全,补全后的属性向量Xpj定义为式(13):
本文还建立了多头注意力机制,用来稳定属性补全的学习过程,式(14):
由于药物节点具有3 种药物属性,根据不同的属性分别对疾病节点进行属性补全。 最后,疾病节点的属性矩阵被表示为Xdp(p∈{chem,doma,anno})。 为了使属性补全过程是可学习的,同时保证补全的属性的准确性,按照比例μ将药物节点V r随机划分为两个部分,分别是和, 其 中,删除掉中药物节点的属性,通过对丢掉属性的节点进行属性补全,计算得到的节点的重构属性定义为式(15):
为了使重构的属性尽可能的接近于原始属性,通过计算原始属性和重构属性之间的欧氏距离得到属性补全的监督损失losspc,式(16):
通过属性补全机制,对已有的药物节点属性和补全的疾病节点属性进行组合,得到了关于药物和疾病节点的属性矩阵Xnewp,式(17):
1.8 最终整合和预测
通过属性补全机制,得到p个药物-疾病节点的属性矩阵Xnpew, 其中药物节点ri的属性表示为(Xnpew)ri,疾病节点dj的属性表示为(Xnpew)dj。 为了利用每个属性矩阵的特征,将其降维到相同的维度后上下堆叠,用1×1 卷积进行融合,得到ri -dj最终的属性向量表示t,并将其作为全连接层的输入,以得到药物ri和疾病dj的关联得分。
2 实验结果与分析
2.1 评价指标
本文使用五倍交叉验证法来评估基于属性补全预测模型的性能。 将所有已知的关联关系视为正例样本,并随机分为5 组,其中4 组用于训练,另一组用于测试。 将所有未观察到的药物-疾病相关性视为反例样本。 随机选择与正例样本数同等数量的反例样本进行训练,剩余的反例样本进行测试。
评估指标包括受试者操作特征(ROC) 曲线、ROC曲线下的面积(AUC)、精确召回曲线(PR曲线)、PR曲线下的面积(AUPR)。 真阳率(TPR) 和假阳率(FPR) 的计算,式(18) 和式(19):
其中,TP(TN) 表示正确预测的正例(反例) 样本数,FP(FN) 表示错误预测的正例(反性) 样本数,用来计算绘制ROC曲线,该曲线是以TPR为纵坐标,FPR为横坐标, 其曲线下方的面积表示为AUC值,用于评估模型的性能。AUC值越高代表模型的性能越优秀。
精确度和召回率是评估机器学习模型性能的重要指标。 精确度表示预测为正例样本中真实正例样本的比率,式(20);而召回率表示在所有正例样本的样本中被正确识别为正例样本的比率,式(21)。
通过绘制以Precision为纵轴、Recall为横轴的曲线,可以直观地展示模型的性能。 如果这条曲线处于左上角附近,那么就意味着模型的性能更佳。相反,曲线越靠近右下角则意味着模型性能越差。
2.2 与其他方法的比较
为了评估基于属性补全预测模型的性能,将本文提出的方法与6 种最先进的有关药物疾病关联预测 的 方 法 进 行 比 较, 包 括 GFPred、 CBPred、SCMFDD、 LRSSL、MbiRW 和HGBI。 为了使比较结果更具说服力,本文的模型和所有比较的模型在训练和测试时使用了相同的数据集,并且每种对比方法的最佳性能是通过使用各自文献中提供的最优参数设置。
在五倍交叉验证中,本文对763 种药物进行了评估,并计算了各自的平均AUC和AUPR;最终将所有763 种药物的平均AUC(或AUPR) 作为最终结果。 不同预测模型的ROC曲线与PR曲线如图2所示。 在所有方法中,基于属性补全的预测模型取得了最佳的性能,优于其他对比模型;GFPred 在性能上排名第二,其从多个异构网络中学习,获得药物(疾病)节点的拓扑表示,该结果表明,融合多个异构网络的信息可以提高预测性能;CBPred 考虑了节点对之间的路径信息,在性能上排名第三;尽管LRSSL 和MBiRW 的AUC没有明显差异,但LRSSL的AUPR明显更高,这是因为前者利用了多种药物的相似性,而后者只考虑一种药物的相似性。SCMFDD 和HGBI 的性能稍差,其AUC和AUP几乎没有差别,这是因为两者都没有利用多种药物的相似性。 与上述方法相比,基于属性补全的预测模型的性能提高主要是通过多个不同的路径,捕获了药物和疾病节点的多种拓扑结构表示,并基于这些拓扑信息通过注意力机制对疾病节点进行属性补全。
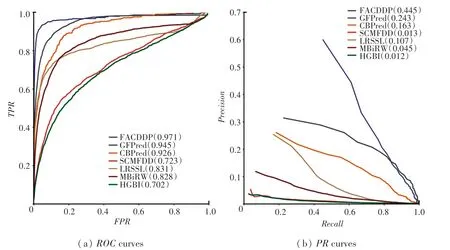
图2 不同预测模型的ROC 曲线与PR 曲线(分图)Fig.2 ROC curves and PR curves of different prediction methods
3 结束语
本文提出了一个新的预测模型,融合药物和疾病数据的相似性和关联性、药物-疾病节点对的特性,以及来自多个元路径的语义信息,并且为无属性的疾病节点进行了属性补全以预测药物-疾病的关联。 建立了3 个异构网络,以便于学习每个异构网络中节点的属性表示。 本文还提出了2 个注意力机制,将更高权重分配给更重要的元路径和节点邻居。通过与其他6 个预测模型的比较,本文提出模型在AUC和AUPR方面均取得了更好的预测性能。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
小学教学研究(2022年5期)2022-04-28
新世纪智能(数学备考)(2021年9期)2021-11-24
河北画报(2020年8期)2020-10-27
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
中国洗涤用品工业(2017年2期)2017-04-16
读者(2017年5期)2017-02-15
电信科学(2016年11期)2016-11-23
浙江大学学报(工学版)(2016年2期)2016-06-05
