
数字图书馆个性化服务行为信息挖掘系统的设计
2023-10-31 06:58蔡瑜婉
信息记录材料 2023年9期
蔡瑜婉
(永春县图书馆 福建 泉州 362600)
0 引言
传统信息挖掘系统的缺陷就是系统响应速度慢,无法实现信息共享,不能够满足学生通过数字图书馆个性化服务交互行为对教学资源进行共享。以此,本文设计数字图书馆个性化服务行为信息挖掘系统,通过数据挖掘技术实现个性化交互服务行为信息的二次处理,对数字图书馆个性化交互服务行为信息潜在价值进行挖掘,从而实现高校教育教学的发展。数字图书馆使用信息挖掘技术,能够提高信息资源组织、使用、集成和加工的效率。信息技术和智能技术的结合,为数字图书馆个性化推荐系统提供支撑。
1 数字图书馆信息挖掘系统的架构
1.1 云服务平台的基本框架
设计个性化服务行为信息挖掘系统中的云服务平台框架,要求与图书馆实际情况结合,整合和合理使用图书馆内部资源。云服务能够将大量的数据提供给系统,使系统稳定地运行。在设计云服务平台框架的过程中,基于基础功能设计使图书馆内部资源作为系统设计重点,从而增强框架适应能力,提高扩展性,降低成本。
1.2 信息挖掘系统的架构设计
在个性化服务行为信息挖掘系统架构设计的过程中,将SSH框架作为核心架构。此框架开发周期短、结构简单、维护方便,在多领域中广泛使用,图1为信息挖掘系统的总体架构。

图1 信息挖掘系统的总体架构
(1)用户层。使用JSP技术设计个性化服务行为信息挖掘系统架构用户层,此技术具备高效处理优势,被广泛应用在多领域中,能够实现个性化服务行为信息挖掘系统与用户的交互逻辑处理。
(2)业务层。为了能够使个性化服务行为信息挖掘系统稳定地运行,在设计业务层架构的过程中使用SSH框架开发系统业务层,实现系统业务层的层次细化,包括PO层、DAO层、Service层和Web层。利用细化的个性化服务行为信息挖掘系统业务层架构,方便个性化服务行为信息挖掘系统的维护,并且系统开发简单方便。
(3)数据挖掘层。在设计数据挖掘的过程中,通过数据挖掘工具Weka处理数据,使Weka作为个性化服务行为信息挖掘系统数据挖掘架构核心,与聚类、神经网络、决策树分类等算法结合,以此实现个性化服务行为信息挖掘系统数据的规划处理,使个性化服务行为信息挖掘系统稳定性得到提高。
(4)数据层。主要包括读者浏览信息、借阅信息、图书信息和个人信息等,该层能够实现数据存储。所以,实现图书馆内部数据资源的整合,通过此关系型数据库存储数据信息。
2 系统的详细设计
2.1 数据预处理模块
将数据处理过程划分为在线与离线2个部分,利用系统处理之间的合理分配,使推荐速度得到提高[2]。离线设计是针对Web日志中的大规模海量数据信息,通过数据挖掘技术实现数据信息的加工处理,会耗费大量的时间,在线设计能够处理当前会话用户的在线推荐引擎问题。
2.1.1 数据准备
离线部分的主要功能就是准备数据,系统后台存储大量用户访问信息,通过处理之后得出有用的信息。在数据处理过程中,能够实现用户访问信息、属性信息的处理与过滤,对数据维度的处理过滤能够促进数据挖掘[3]。数据准备为Web访问挖掘的基础工作,也是数据准备核心工作。在数据准备中,要对用户访问信息实现处理过滤等操作,具体步骤为:
(1)数据收集。在处理用户访问日志数据的过程中,要对客户端与服务器端的数据信息进行收集。利用客户端将多站点与单用户的访问行为反映出来,在服务器端用户访问的浏览行为比较模糊,客户端比较精准;
(2)数据清洗。在收集用户访问Web的数据信息之后,要进行清洗与分类,对有价值的信息服务进行挖掘。清洗基于Web的访问信息数据,实现数据的抽取和删除,具体包括:①删除与数据挖掘无关的数据,在用户访问Web日志信息中,存在与用户Web访问无关的数据,比如图像文件等,需删除无关的数据;②在一段时间内解析用户数据挖掘的信息,合并后得出精准访问Web数据信息,使数据信息转化成为其他格式的数据。
(3)用户识别。通过数据清洗的数据对每个用户进行识别,有大量识别用户的方法,比如利用IP地址、用户注册、嵌入会话ID等,都具有各自的优缺点。
(4)会话识别。用户在对Web进行访问时将此访问划分成为多个会话,此时能够对不同用户访问记录进行区分。针对同个页面,用户访问会话能够在访问日志中单独存储。针对某用户访问时间跨度大的请求,会在用户访问某站点时,对不同会话使用时间窗表示。针对某时间窗,设置timeout值。
2.1.2 创建用户兴趣模型库
(1)创建的意义。数字图书馆为资源信息集合中心,存储大量资源信息。在用户海量信息与数据方面,要求读者寻找信息。另外,此类资源与信息不断增加,所以要使用相应的措施快速寻找。因此,要求设计用户兴趣模型库,根据知识模式寻找。
(2)用户兴趣模型库。针对用户个性化需求,无法使用统一标准对用户需求多元素进行衡量,用户在系统中不仅能够对Web页面感兴趣,还能够对图书感兴趣,利用用户兴趣库衡量其他用户的个性化需求,实现个性化信息服务设计[4]。数字图书馆为重要数据信息服务部门,假如要为用户提供个性化信息服务,就要为用户创建满足实际用户需求的兴趣模型库,包括用户需要的数据和信息。之后通过数据挖掘算法与规则处理Web用户数据,得到用户兴趣和行为习惯。
2.2 用户兴趣模型库的生成
数字图书推荐系统使图书信息实现数字化,数字图书馆具有大量信息,用户在海量资源中寻找自己需要的信息不容易。目前,图书推荐系统要创建图书资源[5]。此时,应转变为以读者用户的思路创建,用户兴趣模型库能够使用户深层次需求得到满足,为其提供个性化推荐服务,图2为用户兴趣模型库生成流程。
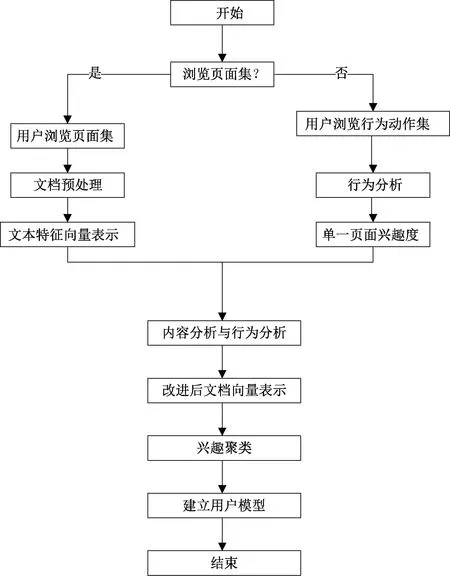
图2 用户兴趣模型库生成流程
第一阶段为创建用户兴趣描述文档,得出用户信息需求,创建用户兴趣描述文档包括Web浏览方式与浏览内容;第二阶段为根据对象所描述的用户兴趣,关联资源信息实现用户兴趣信息组织。Web浏览内容挖掘能够分析用户浏览的页面聚类,创建用户兴趣数据库模型,分析用户浏览页面行为。在此过程中,使两者结合,能够得出用户感兴趣的主题和感兴趣程度,得出带有加权的向量用户兴趣数据库模型[6]。
针对用户来说,分析用户行为能够快速得出用户兴趣。用户浏览页面与站点,在此基础上会发生很多动作行为,比如用户访问页面时的查询和标记书签等动作,还包括访问页面时的访问次数、停留时间、编辑、保存等行为,此浏览行为能够使用户访问页面兴趣度得到展现。
2.3 用户兴趣数据库的更新
读者在对资源信息进行访问时,读者的兴趣也会有所改变。兴趣变化会影响读者的兴趣领域知识中心,以此使资源信息分类树节点权值改变,对读者用户重新归类。在整个过程中,节点权值能够相互链接。对于读者用户,如果没有经常访问就会降低权值,方便使最近访问的节点在前面。
(1)权值更新。以读者用户对于资源信息不同的访问方式修改资源信息分类树中的权值,从而识别读者兴趣程度和领域,模型修改方法为式(1):
Newweight=oldWeight+r*t*k/D
(1)
式(1)中的r指的是读者用户对于资源信息访问方式的参数,以方式重要性实现某值的设置,本文使用专家小组指定;t指时间长度;k指文献资源信息关联度,取值范围为0~1;D指调节常量,对不同分类兴趣增长速度控制。
(2)权值衰减。用户兴趣数据库模型会改变读者的用户兴趣度,读者如果没有对某资源信息进行访问,那么相应的权值也会减少。在此过程中,如果当天访问和没有访问的,就要区别对待,不能够降低权值。连续没有访问天数的节点具有快衰减。那么,在对权值衰减设计的过程中,利用斐波那契数列实现权值衰减模型的设计,通过系统管理员实现兴趣衰减的设置。
斐波那契数列为式(2):
fibo[0]=0,fibo[1]=1,fibo[n]=[n-1]+fibo[n-2]
(2)
对权值衰减时,在fibo[i]中的i=0的时候,不会衰减当天访问节点的权值。如果i越大,表示连续没有访问天数比较长,权值衰减比较快。
2.4 智能代理服务
利用智能过滤技术创建数字图书馆个性化推荐服务,以信息共享平台和智能推荐系统将个性化信息提供给用户。结合用户兴趣爱好、专业、教育背景等全面分析用户的知识结构,将信息数据进行智能化过滤,通过大数据挖掘技术分析用户的兴趣习惯,及时推荐给用户文献资源。以信息智能化的分类,系统中的用户需求存在代理动态,根据智能过滤技术使用户个性化需求得到满足。
2.5 个性化定制
在用户需求分析的过程中,个性化定制能够通过用户的行为数据模型预测用户的需求,从而为用户推送信息服务。此种服务模式要针对用户个性化需求和自主意愿,利用有效数据集合推算分析和用户兴趣变动,预测用户可能产生的阅读行为和习惯,对系统中参数进行调整,并且提供用户自主选择功能,根据用户的需求制定个性化的信息推荐服务[7-9]。通过结合用户的结构知识和个人兴趣,智能化定制馆藏数字资源与网络资源,使用户个性化信息的获取更加方便,主要实现代码如图3所示。
3 系统的测试
系统的运行环境详见表1,对数字图书馆个性化交互服务的行为信息挖掘系统进行集成测试,根据测试规定步骤实现测试,对每个模块之间的协调能力与数据流向进行掌握,测试的步骤详见图4。

表1 系统的运行环境

图4 测试的步骤
通过以上系统测试步骤与运行环境,设置测试次数为50次,以传统信息挖掘系统对各页面响应时间进行记录。表2为页面响应时间的对比,不同界面系统具有不同的响应时间。传统信息挖掘系统的登录界面响应时间比较短,本文系统能够使进入到系统的速度加快。以此可见,本文信息挖掘系统能够促进系统响应速度。

表2 页面响应时间对比
4 结语
因为图书馆内部的信息比较多,会导致个性化服务行为信息挖掘系统在挖掘信息的时候出现响应速度慢等问题。为了使此问题得到解决,本文设计了个性化服务行为信息挖掘系统,并且对系统开展测试。通过测试结果表明,本文信息挖掘系统的平均响应速度比较快,此研究具有优势。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
大众投资指南(2021年35期)2021-02-16
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
文苑(2020年4期)2020-05-30
新闻传播(2018年12期)2018-09-19
电力与能源(2017年6期)2017-05-14
自动化学报(2017年7期)2017-04-18
汽车与新动力(2016年6期)2017-01-04
现代电子技术(2016年15期)2016-12-01
信息通信技术(2015年6期)2015-12-26
