
基于抑郁症患者微博平台数据的文本语义挖掘与情感分析
2023-10-31 11:40范文蓉
软件导刊 2023年10期
范文蓉,刘 峰
(南京邮电大学 教育科学与技术学院,江苏 南京 210023)
0 引言
据世界卫生组织统计,中国抑郁症患者数量已高达9 000 万,并且有逐年上升的趋势,然而最新抑郁症调查报告显示,我国抑郁症的治疗率仍然不到10%[1]。究其原因,我国对于心理问题的社会支持薄弱使得抑郁症患者的病耻感强烈,导致其更倾向于隐瞒病情而非主动寻求治疗。微博作为中国活跃人数较多的社交媒体平台,其保护用户隐私的平台特性为现实世界中的沉默群体提供了隐秘的倾诉途径,其中抑郁症患者也更倾向于在网络世界中表达自己的情感[2]。因此,挖掘并分析蕴含在微博文本中的有效信息能够为人类心理和行为研究开辟更广阔的空间。
1 相关研究
在现代社会,网络是人们获取和发布信息最快捷的途径,而人们在网络上的活动必然会留下许多数据,尤其是许多人经常在社交媒体上发布文字、图像以及视频记录生活,这些数据可以在一定程度上反映用户的行为习惯和情绪状态,对其进行挖掘分析可以对用户的身心健康状态进行监测。近年来,基于社交媒体的心理学研究逐年增多,信息科学与心理学的交叉融合越来越深入[3]。由社交媒体中提取的数据可被用于识别和预测抑郁症患者,进而为其提供专业的诊疗指导,而如何通过社交媒体数据准确提取出抑郁症患者的特征,将其用于训练识别模型并提高检测准确率是亟需突破的难题。
近年来,国内提取数据特征的方法不断完善。例如,曹奔等[4]将主题模型应用于心理学文本分析,用于探索心理咨询和社交媒体上人们的语言内容,进而对发布者的人格进行准确预测;林靖怡等[5]通过爬取抑郁用户和非抑郁用户的基本信息及微博内容,从中选择相关信息构建特征向量,通过XGBoost 算法构建分类模型,得到预测抑郁症的准确率为 91%,召回率为 59%;龚竞秋等[6]从微博树洞账号“走饭”的154 万人次评论数据中提取出292 581 个用户的微博号,对其空间分布特征进行可视化表达,发现经济发达地区人群的抑郁情况比经济欠发达地区严重;查国清等[7]基于Word2vec 词嵌入模型形成抑郁关键词表,进而判断被测微博是否表达出抑郁倾向,该法大大减少了专家标注工作量,提高了标注效率。国外使用的语言和社交媒体与国内不同,因此构建出的文本特征与情感词典有显著差异,但检测技术大致相同。例如,Jung 等[8]提炼出青少年抑郁症本体和术语,提供了相关语义基础,但缺少反映抑郁症的情感词语;Martínez-Castaño 等[9]提出一个用于实时处理社交媒体数据的可扩展平台,实现了抑郁症患者的早期监测;Chiong 等[10]提出一种基于社交媒体文本的通用抑郁症检测模型,该模型采用两个标记的公开Twitter 抑郁症数据集进行训练,即使测试数据集不包含抑郁症和诊断等特定关键词,该方法也能通过社交媒体文本有效检测抑郁症。
国内外针对社交媒体中抑郁症患者检测的研究尚处于初始阶段,构建文本特征与情感词典的方法正在探索当中。目前使用的很多检测技术为机器学习算法,存在较多缺陷,导致抑郁症患者的很多潜在语言和行为特征尚未被充分挖掘。此外,随着时代的发展变化,模型需要被持续调整训练以适应社交平台中不断更新的语句表述方式。
从社交媒体文本中提取有效信息需要文本数据挖掘和文本情感分析两个步骤。其中,文本数据挖掘将生活中非结构化但有价值的信息整理成结构化数据,以便从中提取细枝末节的语义和规律,大大降低了人工操作成本[11],具体分为选取数据来源选取、数据清洗及预处理、文本语义挖掘、可视化分析4 个步骤。近年来,主题模型作为一种非监督的聚类方法在文本数据挖掘领域得到广泛应用[12],其能够发现文档—词语之间所蕴含的潜在语义关系(即主题),将文档看作一组主题的混合分布,而主题又是词语的概率分布,从而有效提高了文本信息处理效率,因此本文选择隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型作为主要的语义挖掘工具。文本情感分析即对文本蕴含的情感信息进行抽取、分类、检索与归纳[13],情感词典的构建在情感分析任务中发挥着越来越重要的作用,其可以基于词语的语义倾向判断其所在文本的语义倾向,是包含情感词词性、极性和强度的词表[14]。抑郁症患者在微博平台中的倾诉欲比现实世界中更旺盛,其微博文本提供了大量蕴含情感的词汇。然而,由于中文的多变性以及语义的多重性,中文分词难度较大,国内的情感分析研究暂落后于国外。近年来,中文情感词典也在不断训练建设当中,如知网发布的情感分析用词语集、台湾大学发布的中文情感极性词典、清华大学李军教授发布的中文褒贬义词典等为中文情感分析提供了可靠的数据来源,但以上情感词典存在领域适应性差以及情感词类别单一的问题。相比之下,大连理工大学林鸿飞教授指导完成的中文情感词汇本体库的情感划分十分细致,更适用于社交媒体情感分析[15]。由于微博文本的情绪较为丰富,不只局限于正、负两个极端方向,应对其蕴含的情绪强弱进行判别,本文选择中文情感词汇本体库作为情感词典。
本文通过采集微博平台中的大量相关数据,运用文本语义挖掘与情感分析技术提取抑郁症患者的特征,对其平台形象、认知特征、行为特征及情感特征进行辨析与界定,以期感知抑郁症患者的真实处境,为在社交媒体中识别潜在的抑郁症患者提供新的途径。
2 研究方法
2.1 数据来源
微博平台中的#抑郁症#超级话题将许多抑郁症患者聚集在一起,从中筛选符合要求的发帖用户较为高效,具体步骤如下:①选取微博发布数量在100 条以上的用户;②进入用户首页观察其发帖习惯及正文内容,确定该用户是否为抑郁症患者;③优先选取在抑郁症超话发帖量较多的用户,审查网页信息获取用户id。经过筛选,最终选取样本总人数52 人,男女比例为9∶43,其中公开显示年龄的有22人,16人在18-25岁区间,4人在25-30岁区间,2人在30-35 岁区间。用户个人信息在一定程度上反映出女性、高中生、大学生3个群体患抑郁症的比例更高。
2.2 数据获取与预处理
2.2.1 数据获取
目前,获取数据的主要途径为网络爬虫,通过执行被设定好的要求自动获取网页数据程序或脚本,该技术在互联网搜索及数据分析领域被广泛使用[16]。
图1 为数据抓取流程。对于爬取微博数据这一任务而言,微博手机端比网页结构更易于获取URL 地址,然后使用拥有多种解析库的BeautifulSoup 库对网页进行解析。为简化获取的网页数据,方便后续文本数据分析,通过正则表达式检索并替换掉无用文本,然后将数据存储为CSV文件格式。

Fig.1 Data capturing process图1 数据抓取流程
使用爬虫技术选取每个用户从2018 年发布至今的原创微博数据,共获得微博7 750 条。原创微博中仍然存在一些与本文主题无关的微博信息,如新年让红包飞活动、过年抽福卡活动、明星打榜活动、投票内容以及其他平台的分享链接等,并不能反映抑郁症患者特征,因此对相关微博正文内容进行删除。数据清洗后最终获取有效微博4 979条,表1为某样本用户的部分微博内容展示。

Table 1 Partial Weibo content display of a sample user表1 某样本用户的部分微博内容展示
2.2.2 数据预处理
由于每个用户的微博文本表述存在个人风格差异,在进行数据分析前首先要对最终获取到的微博正文内容进行清洗与预处理,具体操作如下:①首先去除英文、数字及关键词“抑郁症”;②采用Python 语言中的jieba 分词算法将长语句分为单个词语;③删除标点符号;④删除停用词,如语气助词(啊、呀、了、么等),副词(极其、十分、非常等),介词(的、地等),连接词(虽然、因为、即使等)之类自身无明确意义的词汇;⑤对固有名词进行统一定义,从而构建研究所用的自定义词群表。例如将“爸”“妈”“母亲”“父亲”等替换为“父母”;将“曲唑酮”等抗抑郁药替换为“药物”;将“医院”“门诊”等替换为“医院”;将“林俊杰”等明星名字替换为“偶像”。
2.3 文本语义挖掘
2.3.1 高词频分析
某个词语出现的频率越高,表示用户越受其影响。因此,本文基于已经清洗和预处理过的CSV 文件,在Python中调用分词和词频分析功能,将出现频率排名前50 位的特征词从高到低按照字体大小显示,结果见图2。

Fig.2 Word frequency statistics图2 词频统计
可以看出,出现频次最高的词汇依次为“感情”“药物”“父母”“吃”“感觉”“世界”“希望”“偶像”“睡”“死”等,其中“感情”一词的出现频率多达653 次,体现了抑郁症患者情绪易波动的特点;“父母”一词的高频出现反映其是抑郁症患者十分关注的对象;“药物”“吃”“睡”“死”的高频出现体现了抑郁症患者吃药、暴食、嗜睡、有自杀倾向的日常行为特征;“感觉”“世界”的高频出现体现抑郁症患者对人生哲学的思考;“希望”的高频出现反映出抑郁症患者对恢复健康、回归正常生活的向往。
2.3.2 主题模型分析
为提高文本特征词的准确性,本文采用LDA 主题模型以无监督学习的方式对抑郁症患者微博文本的隐含语义结构进行聚类统计。LDA 主题模型认为文档由主题构成,而主题由词项构成,其目标为得到文档中主题的分布概率以及主题中词项的分布概率。使用经验设定法确定主题数K=5,α=10,β=0.01,模型构建完成后采用LDAvis 可视化包进行如图3所示的可视化展示[17]。

Fig.3 LDA model visualization图3 LDA模型可视化
图3 中左侧聚类形成的各个主题范围圆圈较分散,没有重合的地方,表明此次聚类的结果较显著,可信度较高;右侧则显示了构成某一主题的高频词合集,具体映射如表2 所示。根据主题高频词的主要表达内容其将分为人生思考、生活状态、抑郁症治疗、正面情感表达和负面情感宣泄5 类,与前文高词频分析结果基本一致,其中正负向情感的表达仍需进一步研究。

Table 2 LDA model theme-word specific mapping表2 LDA模型主题—词具体映射
3 抑郁症患者情感分析
3.1 情感词典构建
中文情感词汇本体库中的词汇共分为7 大类21 小类,从词语词性、情感类别、情感强度及极性等多角度对情感词汇进行了描述,词汇格式如表3所示。
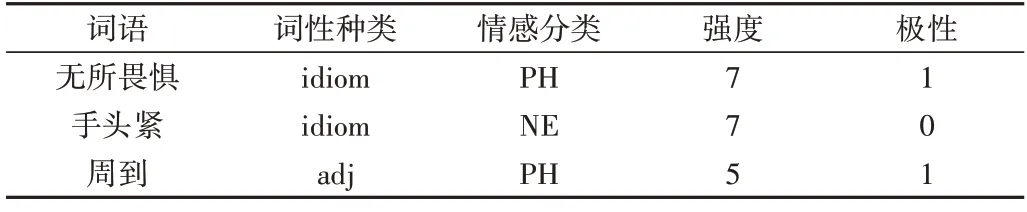
Table 3 Format of emotional vocabulary表3 情感词汇格式
在该词汇库中补充具有微博文本特征的情感词语,构成本文所需情感辞典,以提高对微博平台文本情感分析的精确度。将“乐”“好”归为积极情感倾向,将“怒”“哀”“惧”“恶”“惊”归为消极情感倾向,具体情感词汇分类如表4所示。

Table 4 Classification of emotional vocabulary表4 情感词汇分类
3.2 情感分析流程
情感分析流程见图4,具体步骤为:①将情感词典中的词汇按照类别整理成列表形式;②将经过分词处理的微博词语与情感词汇进行匹配,定位情感词;③载入否定词,对情感词前有否定词或双层否定词的词汇进行修正;④确认情感类别所属并计算每条微博的情感程度。

Fig.4 Emotional analysis process图4 情感分析流程
3.3 情感分析结果
3.3.1 情感词频
为直观了解微博平台抑郁症患者的情感倾向,分别对积极、消极倾向的情感词汇进行词频统计,以词云图的形式展示,结果见图5。图中展示了抑郁症人群常用于表达积极、消极的40 个情感词汇,字体越大表示提及次数越多。

Fig.5 Vocabulary frequency of positive and negative emotions图5 积极、消极情感词汇词频
对积极情感词汇进行深入分析,发现“希望”“喜欢”“快乐”“朋友”“坚持”等词汇出现频率较高,反映了抑郁症患者对美好生活的向往。社会普遍对抑郁症患者存在偏见,认为他们是危险人群,但通过情感分析发现他们的精神世界并不全是抑郁灰暗的,也有许多积极信念的支撑,其无时无刻不处于努力自救的状态,也非常渴望被亲人或朋友救赎。因此,适当的情感关怀是治疗抑郁症的有效方法之一。
对负向情感词汇进行深入分析,发现“难受”“讨厌”“痛苦”“害怕”“抑郁”等词汇的出现频率较高,反映出抑郁症患者情绪不稳定,时常处于低落状态。现代生活节奏较快,学业、工作、感情等多方面压力导致人们经常会有焦虑、悲伤等负面情绪,如不能及时有效调节疏导,可能会导致或加重抑郁症,这在微博平台中体现为用户对消极情感词汇的频繁使用。
3.3.2 基于时间序列的情感变化
以中文情感词汇本体库中情感词的强度得分为依据,基于时间序列对抑郁症患者的情感强度变化进行分析,结果见图6。其中,横坐标表示一天中的24 h,纵坐标表示平每位抑郁症患者发布的微博文本中所有情感词汇的平均倾向程度,黑色折线表示一天中患者表达消极情感程度的变化趋势,灰色折线表示一天中患者表达积极情感程度的变化趋势。
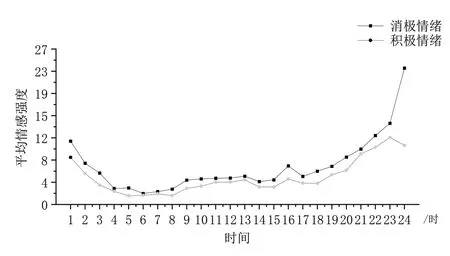
Fig.6 Emotional intensity changes based on time series图6 基于时间序列的情感强度变化
可以看出,在同一时间区间内抑郁症患者的消极情感表达一直强于积极情感表达,且两种情感表达强度变化趋势基本一致。抑郁症患者在夜晚21 点到凌晨1 点期间的消极情感词汇表达程度显著增加,并在24 点左右达到一天中的高峰值,强度达白天消极情绪表达的6 倍以上。本应属于正常人群休息和睡眠的时间却成为抑郁症患者爆发式宣泄消极情绪的时刻,严重影响其日常生活质量和工作学习效率。
3.3.3 消极情绪强度占比
为深入了解抑郁症患者的消极情绪表达情况,选择类别和程度两个指标进一步全面分析。以情感词强度得分为依据,对文本数据进行怒、恶、惊、惧、哀五大类消极情绪的细致分析,并以雷达图呈现,结果见图7。
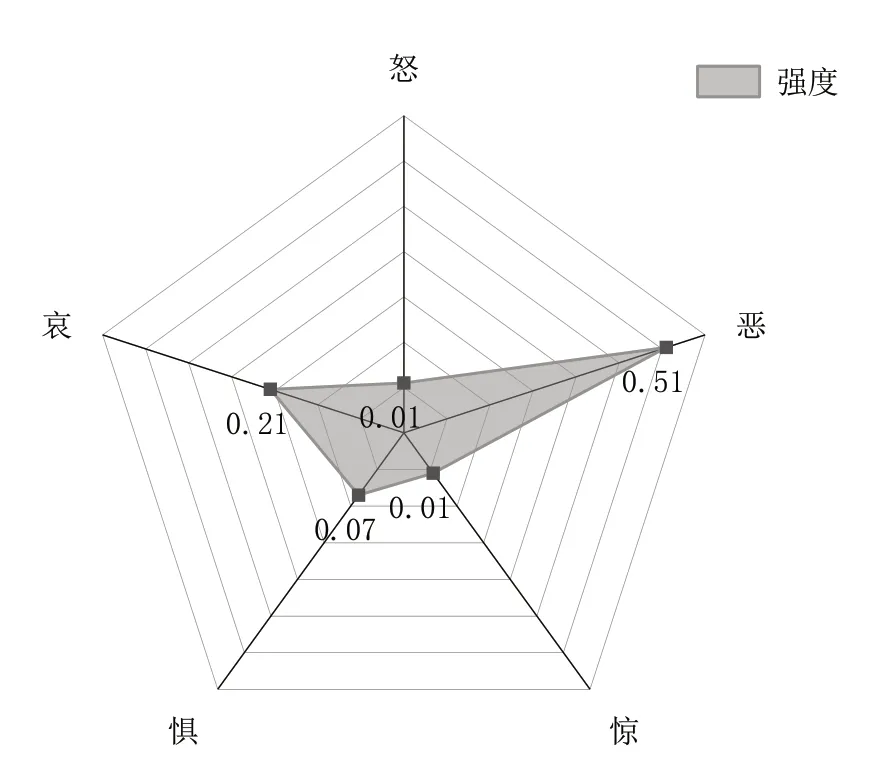
Fig.7 Proportion of intensity of five types of negative emotions图7 5类消极情绪强度占比
可以看出,微博平台抑郁症患者的5 类消极情绪强度有所差异,强度最高的为“恶”,代表性词汇为难受、讨厌、抑郁、恶心、焦虑等,其次为“哀”,代表性词汇为难过、痛苦、对不起、伤害、孤独等;再次为“惧”,“怒”和“惊”则较少出现。“恶”“哀”“惧”3 种主要消极情绪的具体高频词汇及其频次如表5 所示。情感分析结果提示抑郁症患者通常持有悲观的人生态度以及消沉的情感取向。

Table 5 Three main high-frequency vocabulary and frequency of negative emotions表5 3种主要消极情绪高频词汇及其频次
4 微博平台抑郁症患者主要特征
轻度抑郁症主要表现为情绪低落、经常性失眠、食欲下降,严重时会有自我伤害甚至自杀倾向。因此,在网络社交平台中,抑郁症患者的言语、行为、认知等模式与正常人群有明显差异,且包含除临床症状之外的其他信息。因此,本文根据微博文本数据挖掘与情感分析结果,从4 个维度总结提炼出社交平台中抑郁症患者的主要特征,以期提高该类人群的识别准确度,具体特征如图8所示。
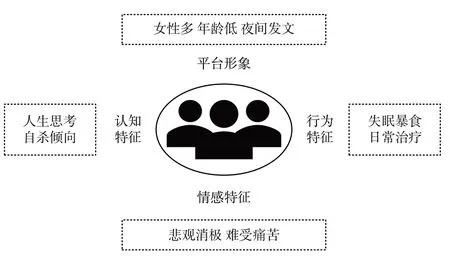
Fig.8 Main characteristics of depression patients on Weibo platform图8 微博平台抑郁症患者主要特征
4.1 平台形象特征
从性别角度来看,女性抑郁症患者人数多于男性,这与女性普遍更加关注情感状态相符合;从年龄角度来看,年龄在18-25 岁的抑郁症患者居多,即高中生、大学生两个群体患抑郁症的比例更高,符合原生家庭是抑郁症主要诱发因素之一的认知;从发博时间来看,抑郁症患者更倾向于在夜晚宣泄负面情绪,与患者经常失眠的症状相符合。
4.2 认知特征
抑郁症患者情绪长期低落,内心极度缺乏自信和安全感,害怕真实的自己会被别人笑话或伤害,不敢向别人表达自己内心的真实想法和感受,有回避正常社交的情况存在,因此具有隐匿性的微博平台成为他们的倾诉途径。LDA 模型聚类的第一个主题“人生思考”和高频词汇“无聊”“世界”“生活”“意义”等反映了该群体对真实世界的感受。此外,微博平台中抑郁症患者的自我价值感较低,在认知方面常常自我否定,严重者会表达出自杀倾向。患者往往从事日常活动便已十分困难,更不要说完成复杂工作,因此经常自觉能力低下,处处不如他人。本文抓取的“累”“活着”“死”等高频词汇充分体现了抑郁症患者容易缺乏自信,对自我持有消极态度,并时常出现轻生念头。
4.3 行为特征
本文数据显示绝大多数抑郁症患者存在睡眠障碍,并伴随暴食行为特征。入睡困难主要表现为患者入睡前思绪繁杂、辗转反侧,同时会有悲观、消极的念头,导致睡眠质量非常差。“睡”“晚安”“睡不着”“梦”“晚上”“安眠药”这些高频词汇体现出抑郁症患者睡眠障碍的行为特征。少部分抑郁症患者会出现暴饮暴食现象,这与微博文本中反复提及的“吃”字相呼应。短时间内大量强迫性进食的行为会增加人体摄入的脂肪量,导致神经中枢陷入休眠状态,进而加重抑郁症。
抑郁症患者的生活不尽如意,但并没有放弃寻求治疗的机会。LDA 模型聚类的第5 个主题和“药物”“医生”“医院”等高频词表明看医生吃药是他们日常生活经常做的事情,其中“药物”一词被提及358 次。此外,“朋友”“走”“音乐”等词在微博文本中被高频提及,可以看出抑郁症患者也会向朋友倾诉烦恼、无聊时外出散步、烦心时听听音乐,以平复心情、舒缓不稳定的情绪。
4.4 情感特征
抑郁症患者的情绪波动较大且常处于悲观消极的状态,词汇提及率第一的“感情”及消极情绪“恶”“哀”“惧”等高频词汇证实了这一情感特征。根据对微博平台抑郁症患者的情感分析可知,消极情绪中“恶”类的最高频词汇为“难受”,“哀”类中除与“难受”相接近的“难过”外,“痛苦”一词的出现频率也很高。这两类情绪即微博平台抑郁症患者的主要情感特征。
5 结语
本文基于微博平台真实数据,采用数据挖掘和情感分析方法从4 个维度总结提炼了抑郁症患者的主要特征,为社交平台中抑郁症人群的识别提供了参考依据。今后拟从以下两个方面继续开展研究:①针对没有抑郁倾向与有抑郁倾向两种人群的社交媒体平台信息进行分析,比较其语言、行为特征,提取形成对照表,利用深度学习算法训练抑郁症患者识别模型。该模型可通过导入社交媒体平台数据与抑郁症患者数据进行对比,进而得到相似度,通过相似度判断该用户是否患有抑郁症及其程度。该方法可帮助寻找潜在的抑郁症患者,对不愿就医、无法就医的抑郁症患者提供医疗帮助;②传统的抑郁症自测量表存在一定局限性,由社交平台挖掘出的抑郁症患者新特征可为量表的全面性和科学性进行补充和完善。
猜你喜欢
英语世界(2023年6期)2023-06-30
意林彩版(2022年2期)2022-05-03
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
疯狂英语·新策略(2019年10期)2019-12-13
中华胰腺病杂志(2019年4期)2019-08-29
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
河南科技(2014年23期)2014-02-27
中华胰腺病杂志(2012年3期)2012-11-07
