
关于语保工程和采录展示平台建设的若干思考
2023-10-31 19:42:16丁喜霞
现代语文 2023年9期
丁喜霞



摘 要:中国语言资源保护工程和采录展示平台在政府统筹规划、规范标准设计、现代技术运用、资源保护利用、人才队伍建设等方面取得了突出成效。同时,在调查点布局和点位数量、方言片区归属和语言属性标注等方面,也存在一些有待完善之处。当前,语保工程和平台建设应在政府统一规划指导下,着力从补充完善前期成果、提高调查点的整体覆盖率、科学标注语言属性、壮大专业人才队伍等方面,推动语言资源库和采录展示平台的持续升级。
关键词:中国语言资源保护工程;采录展示平台;中原官话;点位布局;属性标注
中国语言资源保护工程(以下简称“语保工程”),是教育部和国家语委于2015年正式启动的一项大型语言文化工程,是目前世界上规模最大的语言资源保护项目,主要包括中国语言资源调查汇聚、文化典藏、采录展示平台建设等内容[1]、[2]。一期工程已于2019年底完成,二期建设正有序推进。总的来看,语保工程在政府统筹规划、规范标准设计、现代技术运用、语言资源保护利用、语保人才队伍建设等方面,取得了许多成功经验和突出成效。由于语保工程规模浩大,牵涉面广,建设周期长,平台建设专业性强,在具体实施过程中会遇到各种各样的困难和挑战,也难免会存在一些有待完善之处。本文在概述语保工程和平台建设已取得成效的基础上,以专业平台采录展示的中原官话点的语料为例,客观分析专业平台建设的实绩及存在问题,探讨其产生原因和发展方向,希望能够为推动语言资源库和平台建设的持续升级完善提供参考。
一、语保工程和平台建设的显著成效
语保工程建立了科学有效的管理体系,推行行之有效的“国家统一规划、地方和专家共同实施、鼓励社会参与”的工作模式。它在全国范围内整合专家学者成立调查团队,设立了专业机构、专家咨询委员会和核心专家组,组织相关专家和技术人员,研制了系列工作规范和技术规范,对语保工程各方面、各环节的工作都做出了严格、明确的规定,保证了专业技术工作的科学性、规范性和一致性。制定了调查规范、语料整理规范、音像加工规范、属性标注规范、资源编码系统,研发了语保工程专用录音软件、摄录软件、规范命名软件、电子材料校验软件、语料标注软件等相关技术软件[3]、[4],针对工作规范、技术标准、软硬件使用等进行专项培训,明确并统一质量要求。2019年,已完成1712个点的语言资源调查采集任务,调查范围涵盖全国所有省份和123个语种及其主要方言[5],调查收集到原始语料数据1000多万条,其中,音视频数据各500多万条,总容量达100TB。参与语保工程建设的高校和科研机构达350多家,组建专家团队1000多个,投入专业技术人员4500多名,并且针对各项具体工作举办了57期专项培训,培训人次达4700余人次,在全国范围内锻炼、造就了一支优秀的语保人才队伍[6]。
中国语言资源保护工程采录展示平台(以下简称“语保平台”),是语保工程的重要组成部分,主要任务是在汉语方言、少数民族语言、方言文化等资源调查保存的基础上,利用前沿技术,开展语言资源的数字化、存储管理、整理分析和应用展示等工作。通过科学整理加工,建成大规模、可持续增长的多媒体语言资源库,推进深度开发应用,最终建成一个具有科学性和前瞻性的语言资源采录展示平台,全面、立体、直观地呈现我国语言资源的实态面貌,并利用互联网面向社会大众采集语言资源,保护和促进语言多样性。语保平台是一个综合性的、科学研究和社会化应用相结合的信息化建设项目,主要包括中国语言资源库子系统、中国语言资源统一管理系统、中国语言资源采录展示系统。其中,中国语言资源采录展示系统是语保平台的重点建设内容,按照用户群体分为专业平台和公众平台两个子系统。专业平台立足语言资源调查和科研需求,开发语言资源数据存储、展示、检索和分析应用,为语言学领域的专家学者提供数据分析、检索等专业服务[7]。
语保平台自2015年开始建设、2016年上线以来,研发和运行顺利,成效显著。2019年底,该平台已汇集展示了32个省区、1396个调查点的语言资源数据,其中,汉语方言调查点1079个,少数民族语言调查点317个,收录音频资源400多万条,视频资源300多万条,总物理容量达46TB[7]。截至2020年9月底,语保平台已汇聚了语保工程1613个调查点的语言资源数据,其中,汉语方言调查点1284个,少数民族语言调查点329个,其他调查点的语言资源数据经过科学、规范地整理加工后,也将通过己有资源汇聚的方式陆续进入语保平台,向社会各界开放使用[5]。
总体而言,语保工程顶层设计科学合理,管理机制严密规范,各环节都有严格的制度监控,保证了工程质量,特别是在政府统筹规划、规范标准设计以及现代化技术手段运用等方面,具有显著的先进性和前瞻性[4]、[2]。同时,语言资源库和语言资源管理系统在分布式存储技术、流媒体技术、全文索引等关键技术的支持下,始终保持高效、高可用的服务状态,在方言保护、语言研究和传统文化传承方面的价值和效用也得到了有效体现[7]。
二、专业平台所展示的中原官话点现状
如前所述,语保工程和平台建设已经取得了显著的成效,不过,由于诸种原因,也难免会存在一些问题。鉴于中原官话在汉语方言发展史上的重要地位,我们以专业平台所采录展示的中原官话点的语料实态为例,着重从方言调查点的数量和区域分布、方言片区归属及其标注等方面,客观分析语保工程和平台建设在方言调查、采录、展示方面取得的实绩,以推动语保平台建设的持续升级完善。
(一)调查点数量和区域分布
据《中国语言地图集(第2版)》(以下简称《地图集》)[8],中原官话的分布范围,以中原地区黄河两岸为核心,南北拓展,东西绵延,横跨河南、河北、山东、江苏、安徽、山西、陕西、甘肃、宁夏、青海、新疆、四川等12个省区、400个县市,东西长约3000多公里,南北宽约600多公里,使用人口达1.86亿左右[9]。中原官话在汉语发展史上具有重要地位,对现代汉语各大方言的形成和发展产生了重大影响,在不同区域与不同方言和少数民族语言呈现出各种层次的接触与互动,如西北部與兰银官话、藏语、阿尔泰语以及其他少数民族语言,中部与晋语、西南官话等,东部与冀鲁官话、胶辽官话、江淮官话等,对于语言演变研究和语言接触研究具有重要价值[10]。
从语保专业平台所展示的中原官话点的情况来看,至2022年3月底,共涉及11个省区、110个县市和7个方言岛。其中,有109个县市点见于《地图集》,另有1个方言点和7个方言岛不见于《地图集》,涉及江苏、湖南、海南、江西、山西5个省区。具体如表1所示:
专业平台展示的每个中原官话点,都明确标注调查点名称及所在省份、调查点的方言片区归属、调查点负责人及所在单位、调查点简介等内容。其中的简介部分,对每个调查点的方言特征、区域分布和使用人口等情况作了简明扼要的介绍,并配以方言分布地图和1000个单字、1200条词汇、50个例句以及地普、话语讲述、话语对话和口头文化等音频、视频材料,内容丰富翔实。同时,对发音人和讲述人的相关情况也进行了详细说明和音视频记录,保证了专业平台采录展示的方言材料的真实可靠,为学界利用相关资料进行中原官话研究及其与周边方言的比较研究提供了极大便利。
值得注意的是,专业平台还展示了不见于《地图集》的1个中原官话点和7个中原官话方言岛。1个中原官话点是江苏省徐州市贾汪区(贾汪),简介将其归为中原官话洛徐片。7个中原官话方言岛,分别是江苏苏州市吴江区菀平镇河南话、江西吉安永丰河嘚佬话、湖南吉首市古丈县死客话、郴州嘉禾城关土话、海南东方付马话、海南陵水疍家话、山西长治沁源河南话。其中,前6个方言岛平台均标注为中原官话信蚌片,沁源河南话则标注为郑曹片。具体如表2所示:
中原官话方言岛的形成与历史上的中原移民尤其是河南移民有关,随着推普力度的加大和经济的快速发展,岛方言使用者的语言心理亦发生了变化;同时,受普通话和包围方言的挤压,其生存空间趋于萎缩,今多属濒危方言,急需进行抢救性的调查保护。专业平台采录展示的7个中原官话方言岛的材料,体现了中原官话方言的复杂性,它不仅对于研究中原官话的历史演变、中原官话内部的一致性与差异性、中原官话与周边其他汉语方言或少数民族语言之间的历史与现实关联,提供了更多的语言材料,而且对于保护汉语方言多样性,促进方言地理学、历史语言学、社会语言学、文化语言学等学科的研究,均具有独特的学术价值。
专业平台已经采录展示了110个中原官话方言点和7个中原官话方言岛的语料,为中原官话研究提供了大量真实可靠的资料,但与400个县市点的中原官话分布范围相比,平台采录展示的中原官话方言点的数量仍显不足,区域分布也有待进一步完善。
从语保专业平台展示的中原官话点的数量来看,方言点最多的省份是河南和陕西,均超过20个点;其次是甘肃和山西,均超过10个点;再次是山东、江苏、安徽,不足10个点;宁夏、青海、新疆、河北等省区更少,不足5个点;四川则暂无数据。从中原官话点的省区分布来看,主要集中在中部的河南、山西和西北部的陕西、甘肃等省区,东部的山东、江苏、安徽和西北部的宁夏、青海、新疆等省区设点较少。
从各省区中原官话点的采录完成度(表1百分比栏)来看,江苏省的完成度最高,省内共有11个中原官话点,全部属于徐淮片,平台已展示9个点,完成度达82%。此外,平台还展示有江苏省不见于《地图集》的一个中原官话点和一个方言岛。其次是宁夏回族自治区,区内有中原官话点6个,平台已展示4个,完成度达67%。河北省只有2个中原官话点,平台已展示1个,完成50%。山西、甘肃两省的完成度较高,分别达到48%和38%。而中原官话的核心区河南省的完成度较低,只有25%,安徽也只有23%;西北部的青海省和新疆维吾尔自治区完成度仅有15%和2%,需要投入更多的人力、物力和精力。
我们对中原官话方言片区的点数分布进行了统计,具体如表3所示:
从中原官话方言片区的点位分布来看,在14个方言片区中,点数最多的是秦隴片63、南疆片56、关中片48,其次是兖菏片33、汾河片和南鲁片29、信蚌片25、郑开片24、商阜片23,再次是漯项片17、洛嵩片15、徐淮片和陇中片14、河州片10。专业平台所展示的中原官话方言点,数量最多的是关中片19、秦陇片17、汾河片13,其次是徐淮片和兖菏片10,而中原官话的核心区河南省所在的6个片区(郑开片、洛嵩片、南鲁片、漯项片、商阜片、信蚌片),方言点数略显不足,河州片仅有1个点(占10%),南疆片只有2个点(约占4%),相关数据有待增补。
(二)方言片区归属的标注
专业平台所展示的中原官话方言点与方言岛的方言片区归属和标注,绝大部分归属得当,标注准确,并且在调查点简介中对该调查点的方言特征、区域分布和使用人口等情况作了具体说明,标注与简介彼此对应,相互印证,为中原官话研究提供了可资利用的翔实可靠的语料依据。由于参与方言调查采录和平台展示的工作人员较多,并且非一时一地完成,在具体的操作过程中难免会出现一些疏漏,因此,专业平台在中原官话的方言片区归属和标注方面也存在一些有待完善的地方。
第一,有些调查点的方言片区归属,专业平台没有标注,简介也没有相应说明。在平台所展示的109个见于《地图集》的中原官话点中,此类情况共有25个点,约占23%。如山东济宁市曲阜市(曲阜),平台没有标注其方言片区归属,只在简介中说明曲阜语言单一,正在向普通话靠拢,没有说明其方言片区属于中原官话兖菏片;安徽宿州市埇桥区(埇桥),简介只说它是宿州方言,没有标注和说明其方言片区应为中原官话商阜片;甘肃庆阳市宁县(宁县),简介中提及宁县方言有新宁话和早胜话两种口音及其特点和分布,没有标注说明其方言片区应为中原官话关中片;甘肃定西市陇西县(陇西),简介中提及陇西方言有四种口音及其特点和分布,没有标注说明其方言片区应为中原官话秦陇片;江苏连云港市赣榆区(赣榆),简介中提及赣榆方言大致可分为五片及主要特点,没有标注说明其方言片区应为中原官话徐淮片。
又如,安徽淮北市相山区(相山)、河南开封市兰考县(兰考)、河南开封市鼓楼区(开封)、山东临沂市兰山区(兰山)、甘肃陇南市武都区(武都)、甘肃天水市秦州区(天水)、江苏徐州市丰县(丰县)、江苏徐州市雎宁县(雎宁)、江苏徐州市新沂市(新沂)、江苏徐州市云龙区(徐州)、江苏徐州市沛县(沛县)、江苏徐州市邳州市(邳州)、宁夏固原市原州区(固原)、山西运城市芮城县(芮城)、山西运城市垣曲县(垣曲)、山西临汾市乡宁县(乡宁)、山西临汾市洪洞县赵城镇(赵城)、山西临汾市尧都区(临汾)、陕西安康市汉滨区(安康)、陕西汉中市城固县(城固)等方言点,平台均未标注其方言片区归属,简介也未有相关说明。
有些调查点的方言片区归属,平台虽然没有标注,简介却有相关说明,可以起到一定的弥补作用,令人遗憾的是,简介并未对其方言片区归属进行具体描述。在平台展示的109个见于《地图集》的中原官话点中,此类情况共有11个点,约占10%。如甘肃陇南市文县(文县),平台没有标注其方言片区归属,简介说:“文县地处中原官话和西南官话交界地带,碧口镇为西南官话,文县其他地方为中原官话”,虽有说明文县方言属中原官话,却未具体说明它属于中原官话秦陇片。河北邯郸市魏县(魏县),平台没有标注其方言片区,简介说:“魏县汉语方言的种类是晋语和中原官话。魏县的绝大部分是中原官话”,没有具体说明它属于中原官话郑开片。江苏宿迁市宿城区(宿迁),平台没有标注其方言片区,简介说:“宿迁市区方言从地域角度可以分为两大片,东部……属江淮官话;中部西部大部分乡镇均不保留入声,属中原官话”,没有具体说明它属于中原官话徐淮片。安徽阜阳市颍州区(阜阳)、甘肃临夏回族自治州临夏市(临夏)、甘肃甘南藏族自治州临潭县(临潭)、甘肃平凉市崆峒区(平凉)、陕西渭南市韩城市(韩城)、陕西渭南市富平县(富平)、陕西渭南市合阳县(合阳)、陕西宝鸡市岐山县(岐山)等方言点,也存在类似情况。
第二,个别调查点的方言片区归属,标注术语和标准不够统一。中原官话的划分标准、分布范围、方言片区归属等问题,一直是方言学界比较关注的重要课題。随着研究的不断深入,虽然对一些方言点的具体归属仍有不同看法,如河南南部、湖北西北部、陕西南部的一些方言点,但在许多重要问题上已经达成了基本共识,这集中体现在2012年版的《地图集》“汉语方言卷”中。从专业平台标注中原官话方言片区归属的整体情况来看,它的分区标准和术语基本上是采用了《地图集》的意见,同时,也有个别方言片区的归属和标注,使用的是较早时期不同体系的划分标准和术语。
如河南平顶山市鲁山县(鲁山),平台标注为中原官话郑汴片,郑汴片是张启焕等在《河南方言研究》中提出的中原官话方言片区[11];按照2012年版《地图集》的划分,鲁山点属于中原官话南鲁片。江苏徐州市贾汪区(贾汪),平台标注为中原官话洛徐片,洛徐片是1987年版《地图集》划分的中原官话方言片区[12];在相关研究的基础上,2012年版《地图集》对中原官话方言片区进行了调整,将之前的洛徐片分为洛嵩片和徐淮片,贾汪点属于徐淮片。山西长治沁源河南话,平台标注为郑曹片,郑曹片是1987年版《地图集》划分的中原官话方言片区;按照2012年版《地图集》的调整和划分,山西长治沁源河南话应属于郑开片。
第三,个别调查点的方言片区归属,标注与简介不尽相符。总体来看,专业平台对中原官话方言片区归属的标注,与调查点简介的内容能够相互印证,但也有个别方言点的方言片区归属,标注与简介内容不尽一致。如安徽淮南市田家庵区(淮南),平台标注其方言片区属江淮官话洪巢片,简介说它属中原官话信蚌片。根据该地方言特征,宜标注为中原官话信蚌片。甘肃酒泉市敦煌市(敦煌),平台标注为中原官话南疆片,简介描述该地方言特征则说敦煌方言内部有两种口音:河东话和河西话。河东话属中原官话,河西话则属兰银官话。也就是说,属于中原官话南疆片的是“敦煌河东话”而非整个“敦煌”。宁夏吴忠市同心县(同心),平台标注为兰银官话银吴片同心小片;由简介可知,同心境内属于兰银官话和中原官话的过渡地带,按口音大体分为南北两片,北片属兰银官话银吴片,南片则属中原官话秦陇片。因此,对于同心点的方言归属,标注为“同心县(南片)”属中原官话秦陇片,“同心县(北片)”属兰银官话银吴片,可能更为合适。
此外,个别调查点还存在标注信息不全的情况。如陕西安康市白河县(白河),平台标注为“官话,中原官话,小片系属不明”,没有注明其方言片区属于中原官话关中片;陕西咸阳市三原县(三原)和陕西西安市户县(户县),平台均标注为“关中片”,没有明确其方言片区归属为中原官话关中片。
三、相关问题的产生原因
专业平台所展示的中原官话点语料,在调查点布局和点位数量的充分性、方言片区归属标注的准确性等方面存在一些有待完善之处。究其原因,主要是受到了以下几个方面因素的影响和制约:
第一,语保工程和采录展示平台是面向全国的、持续的分期建设项目。我国的语言资源十分丰富,按照学界比较通行的说法,目前有130多种语言,分属汉藏、阿尔泰、南岛、南亚和印欧五大语系;就汉语方言而言,有官话、晋方言、吴方言、闽方言、粤方言、客家话、赣方言、湘方言、徽方言、平话土话等十大方言;官话内部又可分为东北、北京、冀鲁、胶辽、中原、兰银、江淮、西南八种方言,中原官话只是其中之一。语保工程要实现对全国范围内的所有汉语方言和少数民族语言的实态语料进行全面调查、采录、整理加工、保存、展示和开发应用的目标,实非短时间内所能完成,需要根据国家统一规划、按照统一的调查方案和工作计划分期实施。语言资源采录展示平台作为语保工程的重要组成部分,也不可能一蹴而就。在先期的平台建设中,在展示某种方言语料的充分性和标注方言片区归属的准确性等方面,难免会存在一些不足,这在任何一种大规模的分期建设项目中都是正常的现象,发现存在的问题,经过后续不断补充完善,才能最终实现建设目标。
第二,中原官话分布地域广,需要调查的方言点位多。据贺巍的研究,中原官话在汉语八大官话区的方言中分布范围最大[13]。2012年版《地图集》显示,中原官话分布于12个行政省区,若以一个县市作为一个调查点,共有400个县市点。从各省区所占的方言点数和中原官话的历史发展来看,中原官话的分布区域主要集中于中部的河南和西北部的陕西、新疆、甘肃等省区,方言点数分别为105、73、55、50;其次是山东、山西和安徽,分别有31、27、26个方言点;青海、江苏、宁夏、河北、四川等地的中原官话,则与历史上的中原移民有关,是中原官话的边缘地区,方言点数较少,依次为13、11、6、2、1。可见,区域分布很不平衡。新疆、甘肃等省区的中原官话方言点分布比较分散,有些方言点地处偏远,交通不便,进行实地的田野调查需要投入更多的时间和经费;有些省区的中原官话方言点数很少,如四川省内只有一个点。面对如此大范围、多点位分布的中原官话方言,按照语保工程的统一规划,初期只能完成部分相对集中的方言点的调查采录和整理加工,专业平台目前也只能展示部分中原官话调查点的语料。我们相信,随着语保工程的持续开展,中原官话调查点的语料会得到不断增补并陆续进入平台展示。
第三,中原官话的分布区和部分方言点的归属仍有争议。“中原官话”作为区域方言概念,始见于李荣的《官话方言的分区》[14],继而在1987年出版的《地图集》中被正式命名并得到学界的普遍认同。但关于中原官话的分布区域和部分方言点的片区归属问题,学界目前仍有不同意见。如贺巍认为,中原官话的分布范围跨11个省区,387个县市[13];熊正辉、张振兴认为,中原官话的分布区共有397个县市[9];段亚广认为,中原官话的分布区共有394个县市[15](P3);2012年版《地图集》认为,中原官话的分布区跨12个省区,共有400个县市[8](P55)。关于中原官话与兰银官话的分合、中原官话关中片与汾河片的分合、河南南部/湖北西北部/陕西南部一些方言点的归属等,也仍有争议。有些地区方言情况复杂,如陕西省安康市汉滨区的方言主要有中原官话、江淮官话、混合方言区、江南话、赣语方言岛等,中原官话主要分布在城关、流水、恒口、大同、五里、建民、河西、关庙、张滩、大河、茨沟、枣阳等乡镇。如何标注陕西安康汉滨(安康)的方言片区归属,目前还没有令人满意的方案。随着相关研究的深入开展,这些问题将会得到有效解决,专业平台对于中原官话调查点的方言片区归属标注也将得到完善。
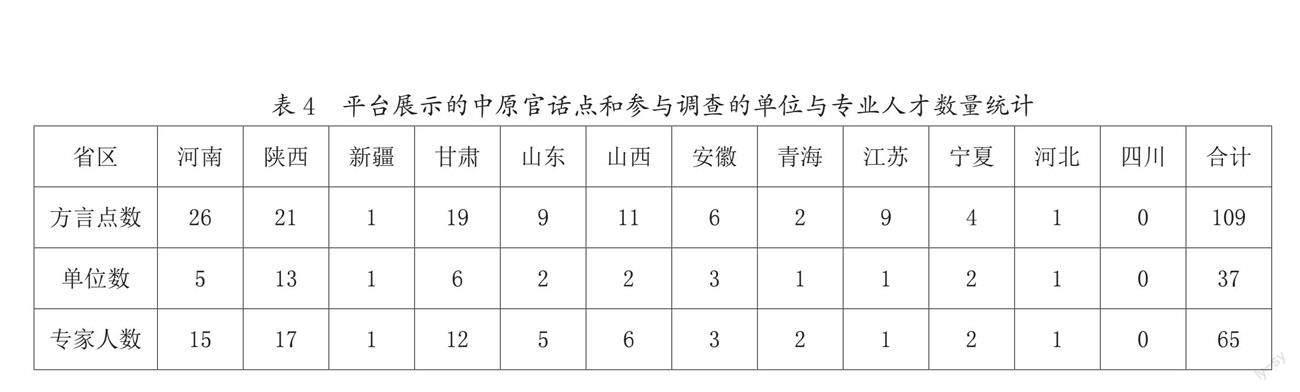
第四,专业人才数量不足,部分地区力量比较薄弱。从专业平台展示的109個中原官话点的情况来看,目前从事中原官话点方言调查采录的专业人才共有65名,来自37个单位,主要集中于中部核心区的河南和西北部的陕西、甘肃等省区,东部的山东、安徽、江苏和西北部的新疆、青海、宁夏等省区,参与中原官话点方言调查的单位和专业人才较少。具体如表4所示:
整体而言,各省区参与调查的单位和专业人才数量与完成调查点的数量呈正比,参与调查的单位和专业人才越多,完成的调查点就越多;反之,参与者越少,完成的方言点数也越少。如河南省有5个单位15个人参与调查采录,完成了26个点;陕西省有13个单位17个人参与调查采录,完成了21个点;甘肃省有6个单位12个人参与调查采录,完成了19个点。宁夏有2个单位2个人参与调查采录,完成4个点;青海有1个单位2个人参与调查采录,完成2个点;新疆和河北各有1个单位1个人参与调查采录,各完成1个点。
参与中原官话调查采录的单位和专业人才数量,不仅在省区之间存在地域分布的不均衡,即使是同一省区之内,不同单位参与调查的专业人才数量也存在差异。如河南省,河南大学参与6人,完成了16个点;河南师范大学参与1人,完成了1个点。陕西省投入了13个单位17人,其中,陕西师范大学参与5人,完成5个点;其他12个单位各参加1人,每个单位完成1—2个方言点。甘肃省,兰州城市学院参与5人,完成了11个点;兰州大学参与2人,各完成1个点。要完成中原官话全部400个县市点的调查采录工作,现有的专业人才数量明显不够,不同省区、不同单位之间专业人才的分布也不均衡,部分地区力量比较薄弱,有的需要进行大量培训和锻炼。
四、语保工程和平台建设的发展方向
鉴于持续开展语保工程和采录展示平台建设的重大意义,针对目前专业平台展示中原官话点语料中所存在的问题和产生原因,语保工程和采录展示平台建设的发展可以着力于以下几个方面:
第一,在国家统一规划的指导下,进一步扩大和完善语保工程成果,促进展示平台建设的改造升级。我国语言资源丰富,但在城镇化和现代化的进程中,许多汉语方言和少数民族语言迅速衰变,它们所承载的民族文化和地域文化快速流失。面对如此严峻的语保工作形势,亟需在前期已取得的语言资源调查成果的基础上,统筹规划,点面结合,进一步扩大语言资源调查保护的覆盖面,扩大语言资源库的建设规模,为语言资源采录展示平台建设和今后的语言研究、语言资源的开发应用提供更多的基础材料。与此同时,也需要对平台展示的语言资源开展科学系统的数据维护,对前期展示的语料中存在的一些疏漏进行后续的补充完善,以提高语言数据的准确度,促进语保工程语言资源的深度加工与应用开发,加快语言资源采录展示平台的改造升级,有效提升语言资源数字化和语言信息服务水平。
目前,语保工程二期建设正在有序推进,语保平台展示的语言资源数据处于持续更新中,至2022年9月底,语保平台已汇聚展示1718个调查点的语言资源数据,比2019年底的1396个点增加了322个点。其中,汉语方言调查点新增210个,达1289个点;少数民族语言调查点新增112个,达429个点。2022年10月,语保工程采录展示平台也完成了一次升级改造,在技术层面和视觉效果层面进行了优化和提升,新版语保工程采录展示平台也已上线[16]。需要指出的是,语言资源的调查保护和开发利用不是一次性的,语言资源采录展示平台的建设不会一劳永逸,语言资源后续的补充完善和平台的升级改造仍有很大空间。
第二,统筹规划,合理布局,提高中原官话调查点的整体覆盖率。中原官话地域分布广泛,消失速度较快,虽然语保专业平台展示的中原官话方言点的数量,已由2019年底的102个点[10]增加到目前的110个点和7个方言岛,但与400个县市点的中原官话总量相比仍有较大缺口。同时,中原官话方言点的地域分布和片区分布也不平衡:河南、陕西、甘肃三省的点数相对较多,分别是26/105、21/73、19/50,新疆、青海等地则只有1/55、2/13;关中片、秦陇片、汾河片的点数较多,依次是19/48、17/63、13/29,洛嵩片、漯项片、南疆片则只有2/15、3/17、2/56,难以体现中原官话的整体语言面貌和内部各片区的方言差异。需要在已有语言资源调查成果的基础上,根据中原官话的生存状态和使用情况,在面向全国进行大规模方言调查的同时,统筹规划,合理布局,进一步扩大中原官话的调查范围:对尚未涉及的中原官话方言点,特别是非中心区方言点、与其他汉语方言或少数民族语言有接触互动的方言点进行深度调查;对当前使用人口少、分布范围小、语言活力弱的方言岛进行抢救性调查。切实提高中原官话调查点的整体覆盖率,进一步丰富和完善专业平台采录展示的中原官话语料,为系统推进专业平台建设和中原官话的深入研究提供基础语料。
第三,深度调查,核定争议,科学标注方言片区归属。语保平台作为语保工程的重要组成部分,肩负展示工程成果的重大使命,尤其是在大数据时代,语言资源的科学性也将在学术研究领域得到凸显。正如范俊军所指出的:“基础的、核心部分的语料采集、加工必须精炼、准确、严密”,“表现在语言学的标注和描写方面,所有基础语料必须是完整的、系统的、完全标注且不留疑点的”[17]。鉴于目前平台展示的中原官话点的方言片区归属还存在一些有待完善之处,今后的语保平台建设应继续在语保工程科学性定位的指导下,在前期研制的技术标准和相关软件的基础上,根据语保工程调查采录的语言资源和已有的研究成果,对平台展示的方言语料及片区归属标注进行补充完善。对某些存有争议的中原官话方言点的片区归属,需要通过扎实的田野调查和先进的技术手段进行分析,以核实争议,确定科学的描写原则和统一的标注术语进行规范、准确的标注。有些地区方言情况复杂,需要在深入调查的基础上,依据该调查点的方言特征,准确描写该地的语言事实,科学标注其方言片区归属。
第四,加强培训,进一步壮大专业人才队伍。经过语保工程和语保平台的前期建设,初步形成了一支比较成熟、业务能力过硬的专业人才队伍,已投入专业人才4500多名。不过,与我国丰富的语言资源和语保工程的目标任务相比,现有专业人才总量仍显不足,人才的地区分布也不均衡。以平台所展示的中原官话点的情况来看,目前仅有37个单位的65名专业人才参与中原官话方言调查,共完成110个中原官话点和7个方言岛语料的调查采录。要想完成400个中原官话点的语言资源调查采录和平台展示工作,则需要有更多的科研院所和专业人才(包括语言调查、采录与平台建设、数据维护等专业人才)投身其中。这就要求在政府相关政策支持下,在已有专业人才队伍的基础上,投入更多的时间、精力和物力,增强专业培训力度,进一步壮大专业人才队伍。同时,促进语言科学与计算机科学的高度结合,提升专业技术人员的工作能力,培养更多高水平、高素质的语言资源保护、开发应用的专业人才和研究人才。并根据中原官话的区域性特点和方言使用情况,对调查团队和专业人才进行合理布局,以期在较短时间内尽快完成对中原官话点的全面调查采录和展示工作。
综上所述,中国语言资源保护工程和语言资源采录展示平台建设是一个系统工程,在国家统一规划的指导下,在语保工程提供的规范要求和模板基础上,不断补充完善方言调查语料。随着新版语言资源采录展示平台的上线,专业平台展示方言点数量不足和方言片区归属标注不规范的情况,已得到一定程度的改善。今后应通过扩大语言资源调查范围和持续开放的语言数据汇聚,进一步深化和拓展语保工程成果,不断研发语言资源应用工具和服务形式,持续开展语言资源采录展示平台的改造升级,从而顺利实现语保工程建设目标,将语言资源采录展示平台建成世界上规模最大的语言资源库和“准确权威、开放共享的语言资源公共服务平台”[18],全面提升我国语言资源保护利用和语言文字工作的信息化水平。
(本文的撰写得到辛永芬教授的指正,特此致谢!)
参考文献:
[1]曹志耘.中国语言资源保护工程的定位、目标与任务[J].语言文字应用,2015,(4).
[2]丁石庆.中国语言资源保护工程语料资源的质量、价值和效用——以少数民族语言材料为例[J].暨南学报(哲学社会科学版),2018,(10).
[3]王莉宁.中国语言资源保护工程的实施策略与方法[J].语言文字应用,2015,(4).
[4]曹志耘.关于语保工程和语保工作的几个问题[J].语言战略研究,2017,(4).
[5]中华人民共和国教育部.中国语言资源采录展示平台上线试运行[EB/OL].(2020-09-30)[2023-08-18].http://www.moe.gov.cn/jyb_xwfb/gzdt_gzdt/s5987/202009/t20200930_492655.html.
[6]新华网.中国语言资源保护工程二期建设启动实施[EB/OL].(2021-04-19)[2023-08-18].http://www.xinhuanet.com/2021-04/19/c_1127349143.html.
[7]林佳庆,李涓子,张鹏.中国语言资源采录展示平台的关键技术及其应用[J].语言文字应用,2019,(4).
[8]中国社会科学院语言研究所,中国社会科学院民族学与人类学研究所,香港城市大学语言资讯科学研究中心.中国语言地图集(第2版)·汉语方言卷[M].北京:商务印书馆,2012.
[9]熊正辉,张振兴.汉语方言的分区[J].方言,2008,(2).
[10]辛永芬.中原官话学术史梳理与研究展望[J].河南大学学报(社会科学版),2022,(2).
[11]张启焕,陈天福,程仪.河南方言研究[M].开封:河南大学出版社,1993.
[12]中国社会科学院,澳大利亚人文科学院合编.中国语言地图集[M].香港:朗文出版有限公司,1987.
[13]賀巍.中原官话分区(稿)[J].方言,2005,(2).
[14]李荣.官话方言的分区[J].方言,1985,(1).
[15]段亚广.中原官话音韵研究[M].北京:中国社会科学出版社,2012.
[16]语宝网.新版语保工程采录展示平台上线啦[EB/OL].(2022-10-03)[2023-08-18].http://www.china languages.cn/.
[17]范俊军.语保工程的语料资源利用问题[J].西北民族大学学报(哲学社会科学版),2019,(3).
[18]田立新,易军.中国语言资源保护工程的建设成效及深化发展[J].语言文字应用,2019,(4).
Some Reflection on the Project for Protecting Language Resources China and
the Collection and Service Platform
——Take Zhongyuan Mandarin Survey Point on the Professional Platform for Instance
Ding Xixia
(College of Chinese Language and Literature, Henan University, Kaifeng 475001, China)
Abstract:The Project for Protecting Language Resources China and the Collection and Service Platform have achieved outstanding results in the government overall planning, standard design, application of modern technology, protection and utilization of language resources and talent team construction. However, there are still some areas to be improved in terms of the sufficiency of the layout and number of survey points, the scientificity of regional attribution and language attribute annotation. At present, under the guidance of national unified planning, we should further supplement and improve the previous achievements, improve the overall coverage of the survey points, scientifically mark the language attributes, expand the team of professionals, promote the continuous upgrading and improvement of the construction of the language resource base and platform.
Key words:the Project for Protecting Language Resources China;China Language Resources Collection and Service Platform;Zhongyuan mandarin;survey point layout;attribute annotation
