
改进YOLOv4-tiny的疫情协同口罩佩戴检测方法
2023-10-30 08:58程浩然王薪陶李俊燃郭子怡
计算机工程与应用 2023年20期
程浩然,王薪陶,李俊燃,郭子怡,刘 维
吉林大学 通信工程学院,长春 130012
在新冠疫情在全世界范围内大肆传播,严重影响人们的生活和工作的当下,疫情防控工作执行的有效性和快速性显得尤为重要。随着我国新冠疫情防控进入了常态化阶段,部分公民的防护意识有所松懈,出现了在公共场合不规范佩戴口罩或者不佩戴口罩的问题。如何在公共场合合理管控监督公民佩戴口罩,是防止疫情传播的重要一环。对于此问题,多数地区经常采用人工检测的方式,效率低且覆盖率低,同时还增加了检测者与行人的接触。因此,利用计算机视觉学习设计人脸口罩规范佩戴仪器以替代人力检测具有重要的研究价值。由于在近年来目标人群监测技术领域中大量算法应用的频繁出现,人们已经能够实现通过算法来搭配电脑显示器和摄像头来进行对体温测量和对口罩的佩戴进行实时、高精度的远程自动检测。
如今基于Deep Learning 的目标检测算法有很多种,其中有以YOLO系列为代表的one-stage目标检测算法,例如YOLOv3-tiny、YOLOv4 和SSD[1]等等,单阶段检测算法针对图像中目标的分类和位置信息等直接利用卷积神经网络进行预测[2],可以快速检测出结果,符合测试实时性规定,但其测试结果准确度还有待进一步的提升。还有以R-CNN[3]系列为代表的two-stage 目标检测算法,例如Fast R-CNN[4]、Faster R-CNN[5]算法等,先提取出目标框,再进行分析预测,可以提高检测精度,但检测速度相对较慢。YOLO 算法作为第一个单阶段算法最早是在2015 年被Redmon 等人首次提到,之后,基于YOLO 算法Redmon 等人同时又首先给出了基于YOLOv2[6]算子,设计制作出Darknet-19[7]的一种新型的基础网络,YOLOv3方式[8]是一种由Redmon等人所共同创建出的最后的一个版本的YOLO方式。由于YOLOv3的信息的高度融合类型使低级信息不能进行很好的使用,在工业应用领域存在限制。于是,YOLOv4算法又被Bochkovskiy 等人[9]提出。后来出现了基于YOLOv4 改进的YOLOv4-tiny算法,属于轻量级算法,参数只有原来的十分之一,这使检测速度大大提升,使用两个特征层,合并有效特征层时使用特征金字塔结构,性能优势显著。最近几年,随着目标检测的深入应用,人们不断提出了许多新的模块并逐步加入到YOLOv4 及其轻量级算法当中,从而在增加少量成本的基础上提高目标检测的精度。如,孔维刚等人[10]将YOLOv4的CSPDarknet53改为MobileNetv3-large 网络结构,提高了检测的实时性。王长青等人[11]基于YOLOv4-tiny 提出一种自适应非极大抑制的多尺度检测方法,对遮挡目标的检测能力有显著提升。
本文旨在提高公共场所大规模人群下实时人脸口罩佩戴检测的实时性与精确性。目前,已有很多学者研究人脸口罩佩戴检测算法。牛作东等人[12]基于RetinaFace人脸识别算法引入注意力机制,优化损失函数,实现人脸口罩佩戴检测。但是检测速度仍有所欠缺,很难满足口罩检测任务的实时性。邓黄潇等人[13]通过RetinaNet网络和迁移学习对佩戴口罩的人脸进行识别判别。王艺皓等人[14]在YOLO 算法中引入改进的空间金字塔池化结构和CIou 损失函数提升佩戴口罩目标的检测精度,不过检测速度依旧不理想且数据集背景相对较单一。
以上算法虽然实现了对轻量化算法精度的改进,但对在复杂场景中对流动的人群进行实时口罩佩戴的检测,仍在检测速度存在提升的必要。本文针对这个问题,提出基于YOLOv4-tiny 改进的目标检测算法,主要的改进包括以下三个方面:
(1)以YOLOv4-tiny 模型为基础,将YOLOv4-tiny中的CSP模块用两个ResBlock-D[15]来代替,降低了计算复杂度从而进一步提高检测速度。
(2)在用ResBlock-D改进主干提取网络的YOLOv4-tiny 基础上进行模型优化,引入SPP 模块进行特征层的多尺度池化和融合,增加感受野,提高检测的精度。
(3)插入新的注意力检测机制CA[16],更好地进行目标定位来提高检测精度。
1 YOLOv4-tiny算法概述及其原理
YOLOv4-tiny 算法是在YOLOv4 的基础上提出的一种轻量化目标检测模型,检测速度更快,检测准确度略有下降,但速度优势明显,降低了对硬件的要求,可以在一些可移动设备或者嵌入式系统中使用目标检测方法,并实现检测的实时性。
1.1 主干网络-CSPDarknet53-tiny
在主干部分,算法使用CSPDarknet53-tiny网络代替了原YOLOv4 的CSPDarknet53 网络。YOLOv4-tiny 网络结构图如图1 所示。其中,残差模块CSP 由CSPNet构成,CBL模块中还结合应用了卷积处理层Conv、归一化处理层BN,以及激活函数层Leaky 和Relu。结构中的主要部分进行了残差块的堆积,其他部分跨一大阶段层次连接到FPN 结构中后再和主干部分结合,最后,通过上采样实现特征融合,将图像划分为20×20 和40×40两种大小的特征图,实现对不同大小目标的检测。

图1 YOLOv4-tiny主干网络图Fig.1 YOLOv4-tiny backbone network diagram
在特征图融合部分,YOLOv4-tiny算法还采用了特征金字塔网络FPN(即YOLOv4-tiny_Neck)算法来分别获得了20×20和40×40两个尺度上的目标特征图,大大地提高了目标的检测融合速度;在激活函数的选择问题上,为了能提高检测的速度,把YOLOv 四网络中的Mish激活函数换作Leaky Relu函数,如公式(1)所示:
其中,t代表神经元输入,f(t)代表神经元输出,α是非零函数参数。当t是负值时,LeakyRelu 会有一个轻微的倾斜,以防止函数进入负半区时神经元失活,避免了稀疏问题的产生[17]。
1.2 网络特征输出
最后YOLOv4会输出3个YOLO Head,而YOLOV4-tiny会输出2个YOLO Head(图1)。
1.2.1 特征输出
在本实验中,输入图像的大小为(640,640),通道数为3,则两个特征层的大小分别为(640/16,640/16)、(640/32,640/32),输出的通道数不变。
1.2.2 损失计算-GIOU函数
在输出端,利用广义交并比(generalized intersection over union,GIoU)作为损失函数,其示意图如图2所示。

图2 广义交并比定义图Fig.2 Generalized intersection and union ratio definition diagram
GIoU和损失函数GIoU_Loss[18]定义如公式(2)、(3)所示:
其中,b与bgt分别表示预测框与真实框的中心点,v代表衡量两框尺度大小比例一致性的参数,γ是用来平衡比例的权重系数,不参与梯度计算。如公式(4)、(5)所示:
可见,计算GIoU_Loss的方法其实就是计算GIoU,只不过最终结果返回1-GIoU。这是因为1-GIoU 的取值范围在[0,2],且有一定的“距离”性质,即A、B两框重叠区域越大,损失越小,反之越大。GIoU_Loss 综合考虑了真实框与预测框之间的重叠率、长宽比例、中心点的距离,使得目标在回归过程中更加稳定,收敛精度更高。
2 YOLOv4-tiny算法改进
2.1 改进的Resblock-D模块
2.1.1 Resblock-D模块
Resblock-D模块构成如图3所示。
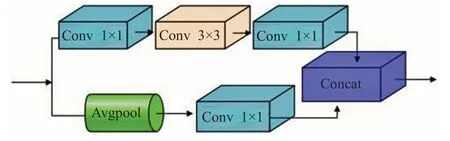
图3 Resblock-D模块结构图Fig.3 Resblock-D module structure diagram
ResBlock-D是由两条路径连接而成,一条路径分别经过三个1×1、3×3、1×1的卷积层,另一条路径经过平均池化后再经过1×1的卷积层,最后将两条路径的结果拼接即可得到ResBlock-D模块的输出。相比于改进前的结构而言,删减了各个卷积层后的激活函数,简化了模型的结构。
假设输入尺寸为100×100的图像,通道数为64。通过计算FLOPs的值比较ResBlock-D模块和CSP模块的性能。如公式(6)所示:
其中,D为所有卷积层之和,为第l个卷积层的输出特征的映射大小,为核大小的个数,Cl-1和Cl分别为输入和输出通道的个数。
CSPBlock的FLOPs为:
通过对比二者的计算复杂度可以发现,改进后的ResBlock-D 模块相比于传统CSP 模块的计算复杂度减少了10倍左右,可以得到CSPBlock和ResBlock-D的计算复杂度比率约为10∶1,有着比CSP更快的检测速度。同时,通过对比CSPBlock 和ResBlock-D 的模块结构可知,ResBlock-D的模块结构中对各个卷积层的维度进行了一定程度的缩减,减少了CSPBlock 中逐层经过激活函数的运算,简化了模块的结构,而且ResBlock-D中加入了CSPBlock 中所没有的平均池化层,能够减小因为邻域大小受限而造成的估计值方差增大,更多地保留图像的背景信息。经过上述分析可知,引入ResBlock-D可有效地提高检测速度,且一定程度上保留图像信息。
2.1.2 辅助残差网络模块
ResBlock-D模块虽然提升了检测速度,但不利于检测精度。基于此,辅助残差网络模块(Auxiliary Network Block)能够很好地改善精度问题。模块利用3×3 的卷积网络获得5×5 的感受野,从而提取全局特征,引用通道注意力(Channel Attention)和空间注意力(Spatial Attention)[19],来提取更多的物体特征信息,能够更精确地识别检测对象。其结构如图4所示。
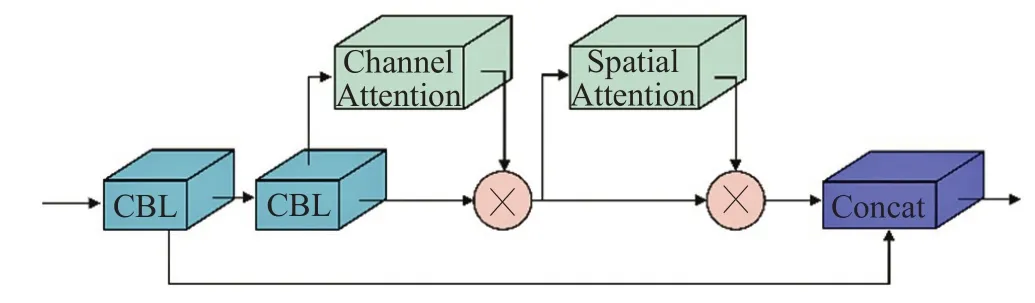
图4 Auxiliary Network Block结构图Fig.4 Auxiliary Network Block structure diagram
由图可以发现,Auxiliary Network Block的输出特征是第一个卷积网络和空间注意力机制的输出特征的一个组合。
最后将Auxiliary Network Block的输出与Backbone网络输出合并,从而在保证精度的前提下提高了目标检测速度,优化了系统性能。
2.2 融入通道注意力机制CA
研究表明,通道注意力对于提升模型识别精度起着重要的作用。本实验的Auxiliary Network Block 模块中也引入了通道注意力和空间注意力机制。但是通道注意力的使用通常会导致算法忽略对于生成Attention Maps的很重要的位置信息。于是引入一种能将位置信息嵌入通道注意力的移动网络注意力机制CA(coordinate attention block)。
CA模块的作用在于增强特征在移动网络中的表达能力,它将网络中任意特征张量X=[x1,x2,…,xc]∈RH×W×C进行转化,输出与X相同尺寸的特征增强的张量Y,即:Y=[y1,y2,…,yc]∈RH×W×C。
CA包括Coordinate信息嵌入和Coordinate Attention生成两部分,其模型框图如图5所示。

图5 CA模块结构图Fig.5 CA Structure diagram
CA将输入特征图分为高度和宽度两个方向进行全局平均池化,高度为h的第c通道输出和宽度为w的第c通道输出分别表示为公式(7)、(8):
这会使CA捕捉到沿着一个空间方向的长期依赖关系,并保存着沿着另一空间方向的精确位置信息,从而使目标的定位更加精确。
接着将获得的宽度和高度两个方向的特征图拼接在一起后送入共享的1×1卷积模块,降低维度到之前的C/r,把进行了批量归一化编码处理后得到的中间特征图F中,输入Sigmoid激活函数即可获得在垂直方向上和水平方向上的空间信息,可以进行编码处理的一个在中间的特征图映射,如公式(9)所示:
将f按照原来的高度和宽度进行1×1 卷积将其变换为具有相同通道数的张量输入到X,得到特征图在高度和宽度上的注意力权重gh和在宽度方向的注意力权重gw,如公式(10)、公式(11)所示:
最后通过加权计算得到CA模块的输出,如公式(12)所示:
将本文引入的CA 注意力机制与典型注意力机制(以CBAM[20]为例)进行比较。CBAM 对通道注意力机制和空间注意力机制进行了相应结合。对于特征层输入,分别进行通道机制处理和空间机制处理,获得相应的通道权值和空间特征点权值,分别乘入上元输入特征层中。而CA注意力机制把更多关注重心放在了通道注意力位置信息的嵌入上。利用精确的空间位置信号来对通道关系和长期依赖性特征实现编码,通过将二维全池局操作分解为两个一维编码过程,增强了关注对象的表示。相比于CBAM,注意机制CA具有更好的全局感受野,目标定位能力和迁移能力。是一种捕获位置信息和通道关系都更有实际效果的方法,能够增强移动网络中的特征,从而提高识别的精度。
2.3 增加SPP模块
为了避免在卷积层后使用扭曲或剪裁等方法来满足分类器层(即全连接层)的固定输入尺寸从而导致算法丢失掉重要信息。在卷积层和全连接层之间引入SPP模块,可通过把局部特性层映射至多个不同的维度空间,从而通过对所有它们进行池化和融合,来获得一个固定长度的输出[21],提高了局部特性层对目标信息的表达能力,提高了人脸识别精度。
如图6所示,首先将输入特征层进行多层卷积核处理,处理后进入SPP结构,使用三个尺度分别为3×3、7×7、11×11 的池化层结构进行Maxpool 处理,通过对尺度的调整可以产生任意尺寸的输出,使用灵活。然后把最开始的输入和经过Maxpool 数据处理后获得的产出在通道层次上加以堆叠,然后再经过下一次的三层卷积处理,输出结果。SPP 模块明显地增加了对网络的感受野,使网络可以满足作为一个任意尺寸的影像的输入,并可以形成一个指定的尺寸影像的输出,对物体的扭曲也具有了较好程度的鲁棒性,更全面有效地提取到了网络特征层的信息,学习了多尺度目标的特征。

图6 改进后的YOLOv4-tiny-ResBlockD-SPP-2CA算法网络图Fig.6 Improved YOLOv4-tiny-ResBlockD-SPP-2CA algorithm network diagram
2.4 改进后的口罩佩戴识别网络
本文在原始YOLOv4-tiny的基础上,将CSP模块改进为Resblock-D模块并加入辅助残差网络模块,通过缩短计算复杂度、扩大感受野,使算法在确保检测准确度高的前提下又加快了检测的速度,优化提高了整个系统性能;引入能将位置信息嵌入通道注意力的移动网络注意力机制CA,以便于更高效准确地快速捕获位置信息及其通道信息之间存在的关联、增强在移动通信网络环境中的识别特征,提升到了人脸的识别的精度;添加空间金字塔池化的SPP模块,完成了局部人脸特征图与全局人脸特征图的完美融合,从而进一步完善了深层特征图中的表达能力与空间信息,在提高人脸目标的检测识别精度方面提升很大。
此外,可以在空间金字塔池化模块SPP之后加入两个1×1的卷积模块,从而进一步减少了参数量以及计算量,缩短了算法运行时间。如图6所示为改进YOLOv4-tiny算法的口罩佩戴识别网络结构。
3 口罩佩戴识别实验过程与分析
3.1 实验环境配置与参数设置
为训练和评估所提出的改进的YOLOv4-tiny模型,本实验训练使用Linux系统,采用深度学习框架Pytorch,训练环境为E52680 v32080Ti,测试环境为NVIDIA GeForce GTX 16504G GPU。
为了验证模型在速度上的提升和精度上的准确性,本实验采取了YOLOv4、YOLOv4-tiny 以及改进型YOLOv4-tiny的对比分析。为了实验的公平性,本次实验使用的口罩佩戴人群图片均为公开的开源口罩识别数据集,对骨干网络的参数进行初始化,获得更好的模型初始性能。设置训练300个Epoch,共计22×300次迭代;batch_size 大小为64。初始学习率为0.001,学习率调整策略为余弦衰退策略,权重衰减为0.000 5;输入图像尺寸均归一化为640×640,均不采取预训练模型。
3.2 数据集概述与预处理
3.2.1 概述
本实验使用的口罩佩戴人群图片均为公开的开源口罩识别数据集,本数据集共包含1 940张图片,且已通过Labelimg 工具对图片进行标注,共包含两类目标:佩戴口罩(people_mask)和未佩戴口罩(people),图片覆盖不同职业人员、环境和尺度的情况,较贴近地拟合实际日常生活中不同场所的人群场景。在实验中,数据集按照7∶3的比例划分为训练集和验证集,其中训练集图片1 358张,验证集图片582张;同时,分别新增测试集500张图片和300 张图片,该数据集均为公开的开源数据集,且与训练集不属于同一数据集。
3.2.2 Mosaic数据增强
除使用了传统方法的图像进行随机的剪接、翻转、压缩、色域的转换、加入随机的噪声处理之外,本文中还应用到了马赛克数据的增强方法。对已准备处理好的数据集进行Mosaic增强数据预处理。Mosaic图像增强技术是指把四张图像分别进行了随机形式的剪辑,拼接后增加进数据集中,由此就完成了图像融合。其最大优点之一是丰富了照片中的背景,扩大了数据集,且将四张照片拼接在一起也从另一个角度上增加了batch_size,进而提高了训练性能。在处理过程中。每次对四张图片进行旋转、放缩以及颜色等方面的调整,并且按照四个方向位置进行图片和框的组合。处理后结果如图7所示。

图7 对部分样本进行Mosaic数据增强Fig.7 Mosaic data augmentation for some samples
3.3 评估指标
本实验训练网络采用的性能评价指标主要为mAP(mean average precision)、准确率(Precision,P)和召回率(Recall,R)[22],其计算公式如公式(13)~(15):
其中,将被正确识别的正类目标个数采用TP来表示,被正确识别的负类个数采用TN表示,被错误识别的负类目标个数采用FP表示,AP是目标测量精度的加权平均精度。本文主要采用IOU 阈值为0.5 时的mAP 值来进行评估,即mAP@0.5。运算的速率方面采用了每秒的传输帧节数(frame per second,FPS)作为衡量指标。
3.4 实验过程与结果分析
3.4.1 算法改进的实验过程
采用轻量化网络以及对其进行进一步改进是提高单目标检测算法YOLOv4 性能的常用方法。为了完成对比实验,本文首先以YOLOv4、YOLOv4-tiny 对目标进行识别检测。后为进一步提高检测速度,实验以YOLOv4-tiny模型为基础,对模型主干提取网络进行改进,将YOLOv4-tiny中的CSP模块用两个ResBlock-D来代替,降低主干特征提取网络复杂度,减少运行时间。通过对比改进前后的特征提取网络的结构参数和即可知,替换后的模型的FLOP 相比于改进前大幅下降,且改进后的特征提取网络结构存在一定程度的删减,其参数量与改进前相比也是降低了一个数量级,这意味着ResBlock-D的计算复杂度远小于CSPBlock。但基于ResBlockD 的YOLOv4-tiny 模型的检测精度却有所下降。为了进一步改进模型性能,减少降低计算复杂度对检测精度带来的影响,提高检测精度,对算法做出以下两点改进:(1)加入空间金字塔池化(SPP)。加入SPP是因为小物体在神经网络深处,即深层特征图上的信息很少,且由于深层特征图的分辨率很小,所以小物体的信息容易丢失。通过引入SPP结构,利用不同感受野的池化层,获取物体不同范围的局部特征信息,最后通过金字塔池化将多个局部特征信息融合后,可以丰富物体的空间信息。(2)引入新的注意力机制。为更好地选择适合该算法模型的注意力机制,实验引入了CBAM机制、一层CA 机制和两层CA 机制的改进模型对比实验。CA机制是一种全新的注意力机制,加入CA机制是为了提高算法的资源利用率,为不同的特征像素增加坐标权重,而权重即代表特征像素为目标物体的可能性,权值越大,即代表特征像素为目标物体的可能性也就越大,一定程度上降低了背景像素的干扰。且CA机制位置信息权值嵌入编码的过程本身不发生重叠,可重复进行引入。总体而言,为实现进一步提高检测速度的同时保证检测精度,本实验的基本思路为基于YOLOv4-tiny 模型,首先为了提高检测速度而引入主干网络更为简洁的ResBlockD结构,接着为了增加深层特征图上小目标的信息引入SPP模块,最后引入CA机制以提高算法利用率。
对改进过程中不同阶段模型统一初始化开始训练,随着epoch不断增加,Loss损失值在不断降低,训练进行到160轮后,Loss值趋于稳定。未出现明显过拟合、欠拟合的现象,参数设置合理。改变初始参数设置(batchsize等)重复训练,结果会发生波动但总体趋势未发生变化,可进行同向比较,说明实验对初始值的依赖性不高,改进算法具备合理性。实验最终确定基于ResBlock-D、SPP 和两个CA 机制的YOLOv4-tiny 为最终的改进模型。对改进后的算法进行性能分析。
3.4.2 改进算法的检测精度的分析
对改进过程中不同阶段算法的检测精度指标进行分析,在实验选取的开源口罩识别数据集上对比结果如表1所示。
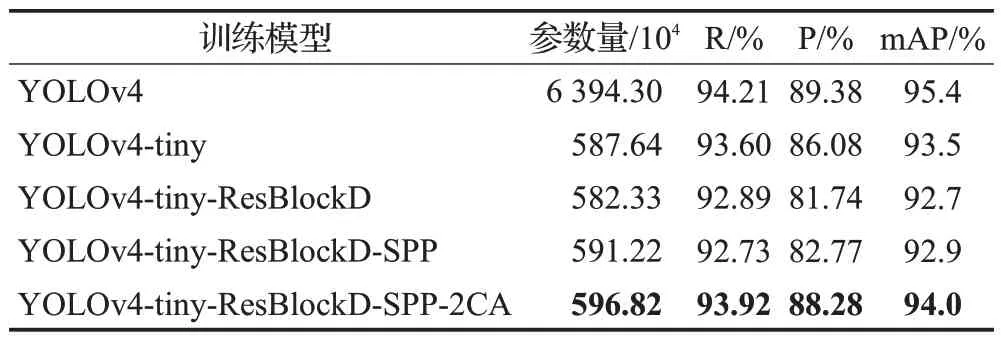
表1 不同阶段算法的检测精度对比Table 1 Comparison of detection accuracy of algorithms in different stages
由表1 可以看出,YOLOv4-tiny 的召回率为93.6%,预测率为86.08%,mAP 值为93.5%,相比于YOLOv4,YOLOv4-tiny在召回率和精准率上均有一定程度下降,mAP值下降了1.9个百分点。检测精度下降的重要原因是YOLOv4-tiny的CSPDarknet-tiny结构与CSPDarknet53相比删减了一定的网络结构,YOLOv4-tiny由于结构上的简化,在检测精度上会有一定程度的减小。YOLOv4-tiny-ResBlockD是以YOLOv4-tiny模型为基础的改进模型。其在模型主干提取网络部分进行改进,使用ResNet-D网络中的两个ResBlock-D模块代替CSPBlock模块,减少了网络计算的复杂性,并且还设计出了另外二个相同的Residual Network Blocks 来作为辅助残差块,并将其添加到ResBlock-D 模块中以保证精度。优化结果显示,相比于YOLOv4-tiny,基于ResBlock-D的YOLOv4-tiny 改进算法仍在识别精度上出现了一定程度下降,mAP下降了0.8个百分点。实验结果表明,YOLOv4-tiny模型、基于ResBlock-D的YOLOv4-tiny改进模型是以降低检测精度为代价来换取更快的检测速度。
在增加空间金字塔池化(SPP)的过程中。实验数据显示,引入SPP对提高检测精度有正影响,引SPP后,新改进模型的预测率(82.77%)和mAP 值(92.9%)有了少量提升。这是由于空间金字塔池化(SPP)解决了输入的图片大小不同造成的缺陷,同时由于从多方面进行特征提取,丰富了物体的空间信息,在一定程度上增加了目标检测的精度。对于新引入的注意力机制,为了更好地比较并选择适合该算法模型的注意力机制,进行了注意力机制对比实验,结果如表2 所示。数据显示,相比于典型的CBAM 和引入一层CA,引入两层CA 注意力机制的改进型轻量级算法其检测精度都更高,召回率达到了93.92%,预测率达到了88.28%,mAP 达到了94.0%。这是由于典型的CBAM 混合注意力机制重点在于通道注意力机制和空间注意力机制的结合,而“Coordinate Attention”(CA)是一个比较新颖独特的移动网络注意力机制,它把更多关注重心放在了通道注意力位置信息的嵌入上。利用精确的空间位置信号来对通道关系和长期依赖性特征实现编码,把通道注意力划分成二条一维特征编码进程并依次地沿着这两个特定空间方向进行聚合特征,以增强关注对象的表示,提高算法的资源利用率,从而达到提高目标检测精度的目的,引入两层CA机制进一步提高了精度性能。
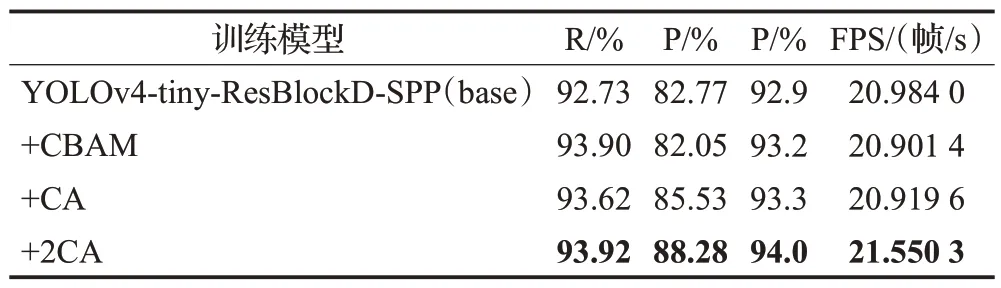
表2 注意力机制对比实验Table 2 Attention mechanism comparison experiment
实验结果所示,最终确定的基于ResBlock-D、SPP和两个CA 机制的YOLOv4-tiny 改进算法,检测精度较YOLOv4-tiny 及其他改进算法相比还要略微提高,其mAP 值可达到94.0%,相比于YOLOv4-tiny,mAP 值提高了0.5个百分点。改进算法的网络参数规模为596.82万,较YOLOv4-tiny 增加了9.18 万,有少量增长。可认为,经过改进后的模型在复杂度上相比于YOLOv4-tiny不存在较大的增幅,同时又一定程度上提高了检测精度。而参数量相比于传统YOLOv4 而言又有较大幅度的减小,极大程度地降低了模型的复杂度,提升了算法的检测速度。从网络整体参数规模上看,通过比较改进后的模型、YOLOv4 以及YOLOv4-tiny 可发现,改进后的模型在检测精度上相比于YOLOv4-tiny 有进一步提升且参数量仅存在微小的增加,而改进后的模型复杂度相比于YOLOv4却有大幅的下降,故其在综合检测性能中更具优势。
将不同算法下的mAP值随着算法迭代次数的逐渐增长进行可视化处理后得到如图8所示。

图8 不同算法的mAP变化曲线Fig.8 mAP curve of different algorithms
通过变化曲线可观察得到,随着迭代次数的增加YOLOv4 的mAP 在不同迭代中都较另外两种算法更高,而改进型的YOLOv4介于YOLOv4和YOLOv4-tiny之间,与实验预期的精度提升相符,同时也更加直观地说明了改进型YOLOv4-tiny 相比YOLOv4-tiny 在精度上的提升。
如图9 所示,P-R 曲线下的面积即为平均精确度(mAP),通过分析三种算法的P-R 曲线可以看出,YOLOv4的P-R曲线所包围的面积最大,其mAP值更高,精度更高,与实际检测结果相和理论相符。YOLOv4-tiny-ResBlockD-SPP-2CA 的P-R 曲线包围的面积较YOLOv4-tiny 更大,但相比YOLOv4 而言略有减小,其mAP值介于二者之间,从该角度也可看出:本实验改进后的YOLOv4-tiny-ResBlockD-SPP-2CA 的平均精确度比YOLOv4-tiny的要高,达到实验中所要求的提高检测精度的预期要求。
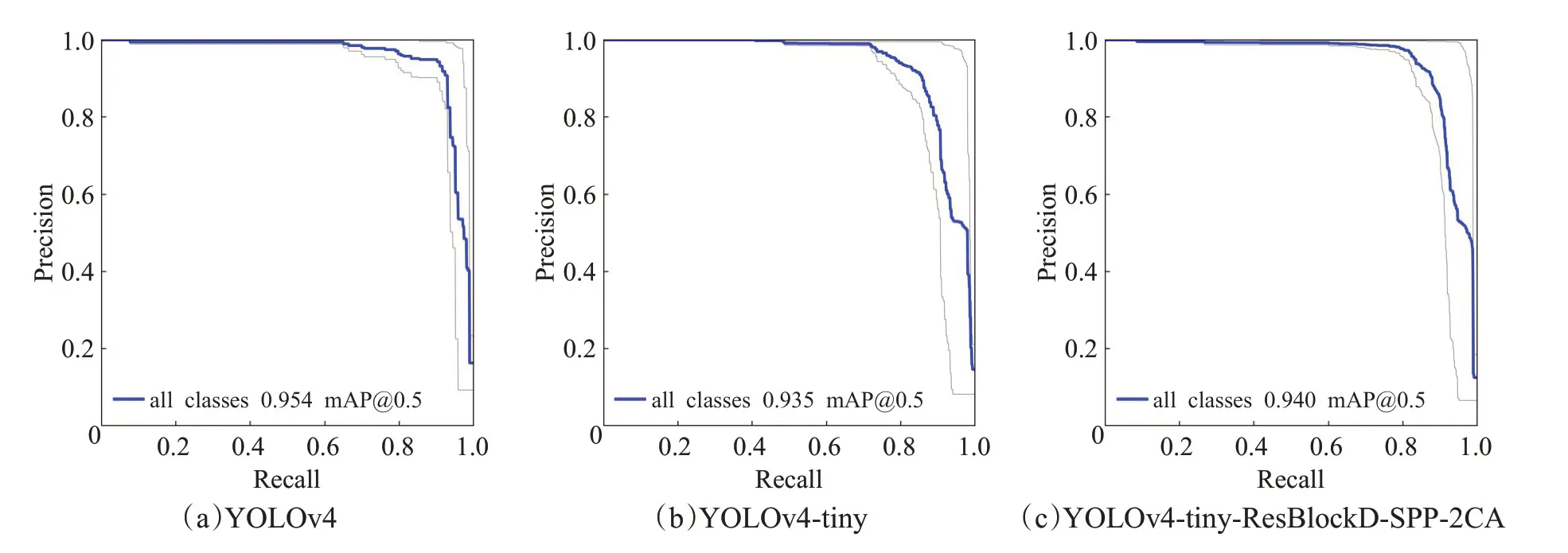
图9 不同算法的P-R曲线对比Fig.9 Comparison of P-R curves of different algorithms
3.4.3 改进算法的检测速度的分析
对不同算法的检测速度进行对比分析,如表3所示。

表3 不同阶段算法的检测时间对比Table 3 Comparison of detection time of algorithms in different stages
由表可知,YOLOv4-tiny 的FPS 为17.586 5 帧/s,相比于YOLOv4提升了5.01倍,检测速度较YOLOv4有了显著提升,主要原因就是,YOLOv4-tiny 通过特征金字塔网络收集了不同维度的目标变量,而不是采用传统YOLOv 四方法中所使用的路径聚合方式,从而增加了目标的效率且YOLOv4-tiny 的目标参量仅达到了587.64 万,远小于YOLOv4 的6 394.3 万的参数量,结构大幅简化。可以看出,YOLOv4-tiny模型有更迅速的检测速度,模型可以在以小幅减小精度的代价下,较为理想地提高检测效率,在大量人群口罩佩戴环境下更为适合实时性检测。
但在更大规模人群环境下,YOLOv4-tiny表现出的延迟性使得寻求在保持或者提高检测精度的前提下,进一步提升检测速度。
通过对比上述改进型的YOLOv4-tiny模型可知,加入ResBlockD 结构的YOLOv4-tiny 模型的FPS 可达到21.345 1 帧/s,较YOLOv4-tiny相比提升了21.37%,检测速度得到进一步改善。这是由于代替CSPBlock模块的ResBlockD模块具有更为简化的结构,通过残差结构的“跳跃链接技巧”,利用卷积核的升维和降维操作,实现降低参数量目的,从而加快模型的训练和检测速度。
可以看出,嵌入ResBlock-D 后的改进算法,在检测速度有了进一步的提升同时,参数量也大大减少,这有利于部署在CPU、GPU等资源有限的硬件设备上。
同时,本实验中也对引入空间金字塔池化(SPP)和CA 注意力机制的改进型YOLOv4-tiny 进行了速度检测,通过表3 可发现,引入SPP 和两个CA 机制的改进型YOLOv4-tiny 模型的速度比只使用ResBlockD 的YOLOv-tiny模型还要略微提高,达到21.550 3 帧/s。这是因为CA 机制先后进行了Coordinate 信息嵌入和Coordinate Attention生成两个步骤,在很好地获得全局感受野并编码准确的坐标信息的同时,更有利于目标的寻找,一定程度上促进了检测速度的提升。
实验中,对引入CBAM 机制、一层CA 机制和两层CA 机制的改进模型进行对比,结果如表2 所示。实验结果表明,相比于引入CBAM 机制和一层CA 机制,引入两个CA注意力机制的改进型轻量级算法其检测精度和检测速度都更高。
分别对300 张和500 张的数据集进行检测,如图10所示。
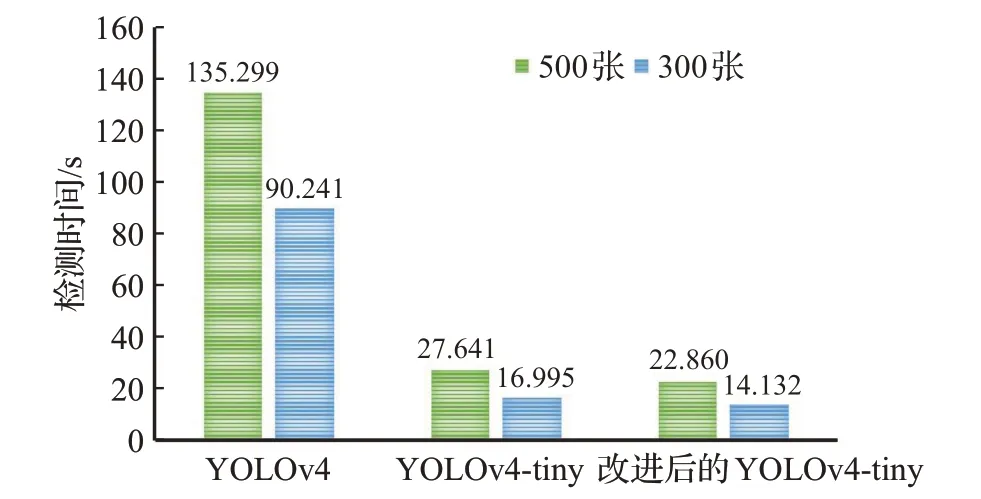
图10 不同算法的图像检测时间对比Fig.10 Comparison of image detection time of different algorithms
可以看出,针对300张和500张数据集的检测,改进型YOLOv4-tiny 模型的检测时间分别能达到22.86 s 和14.132 s,而传统YOLOv4对300张和500张数据集的检测时间则高达135.299 s和90.241 s,改进型YOLOv4-tiny模型在面对大量数据处理的情形时能够迅速作出反应并有效识别。本文提出的模型确实能够有效地对图像中所包含不同人的口罩佩戴进行检测。相比于原算法而言,检测结果精度有一定提升,且实时性更佳。
3.4.4 Loss值分析
对不同算法的Loss值进行分析,如图11所示。
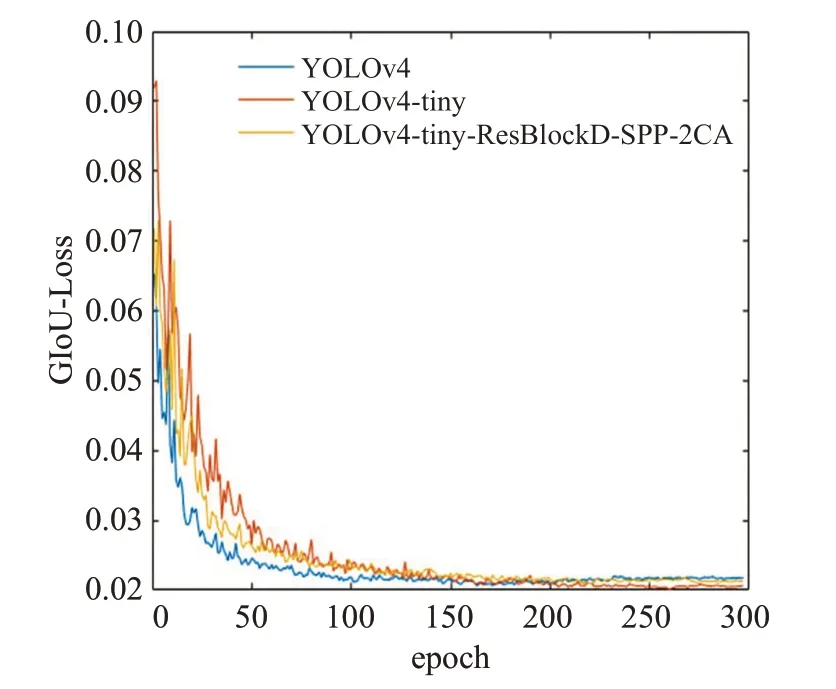
图11 不同算法的GIoU-Loss对比Fig.11 GIoU-Loss comparison of different algorithms
选取GIoU作为损失函数,从图中分析比较可知,在迭代次数较少时,YOLOv4所能降低的损失函数在三种算法中是最低的,由于此时并没达到过拟合,故最终所能达到的识别精度在三种算法中也最高。改进型YOLOv4-tiny 算法相较于YOLOv4-tiny 而言,损失函数的降低上有所改善,其精度也相比于传统的YOLOv4-tiny有一定幅度的提升。
在迭代次数超过200 后,YOLOv4-tiny 的损失函数相比于改进型YOLOv4-tiny和YOLOv4都要低,原因是此时YOLOv4-tiny出现稍微过拟合的现象,在训练集上的误差较小,但对测试集上的误差较大,泛化能力较弱,故其在测试集上的精度相比于改进型YOLOv4-tiny 和YOLOv4都要更低一些。
3.4.5 主流目标检测算法性能对比
实验通过与主流检测算法在相同数据集上的训练结果进行对比,进一步验证本文所提算法的综合性能。实验采取的评价指标包括参数量、mAP和检测速度,结果如表4所示。结果显示,本文提出的改进算法参数量为596.82万,较YOLOv4-tiny网络参数规模接近。mAP为94.0%,FPS达到了21.550 3 帧/s,相比于YOLOv4-tiny模型mAP 值提高了0.5 个百分点,FPS 提高了3.96 帧/s。这是因为本文算法策略引入了SPP 模块并且使用了两个CA通道注意力机制,增加了网络的参数量,提高了检测精度。而嵌入ResBlock-D 模块替代CSPBlock 的操作,因为ResBlock-D架构复杂度仅为CSPBlock的1/10,提高了检测速度。综合搭配后,网络参数规模与原模型接近,且综合性性能明显更优。相比于其他非轻量单阶段目标检测算法,例如YOLOv4、SSD和RetinaNet,三种算法参数规模均远大于本文算法,YOLOv4的检测精度相比本文算法有所提升,RetinaNet 算法(93.9%)和SSD算法(93.6%)检测精度略低于本文算法,但是三者网络参数规模均远大于本文算法,且检测速度均低于4帧/s,不到本文算法的20%,难以满足口罩检测实时性要求。相比于双阶段的目标检测算法,以Faster R-CNN为例,其mAP达到94.4%,但网络参数量达到了4 178.3万,检测速度仅为2.134 9 帧/s,检测速度更低。综合比较。本文算法的综合性能优于SSD、Faster R-CNN等其他主流算法,可以很好地满足口罩检测任务精度与实时性的要求,更适合应用于真实的摄像头检测中。
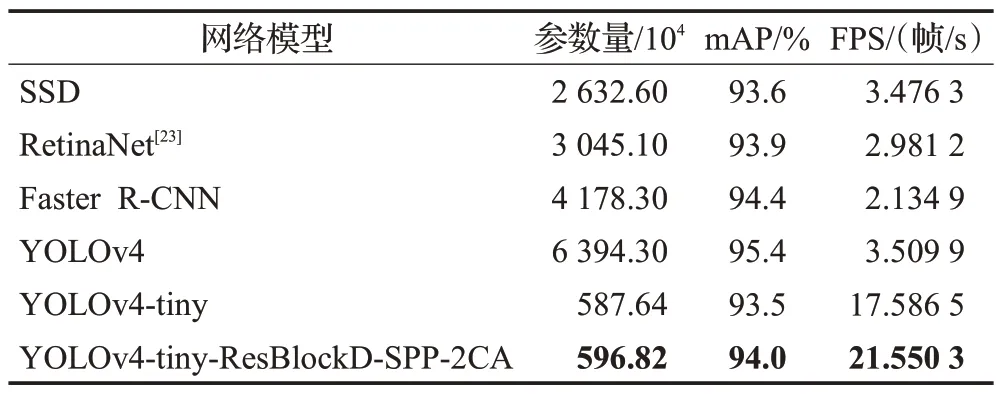
表4 主流目标检测算法性能比较Table 4 Performance comparison of mainstream target detection algorithms
3.4.6 消融实验
为了验证实验中所提出改进算法的充分性以及各个改进策略对模型带来的影响,进行了消融实验[24-25]。实验设置及结果如表5 所示。实验以YOLOv4-tiny 模型为基础,表中的“√”代表使用该改进策略,“×”代表未使用该策略。可以看出,第1 组为YOLOv4-tiny 基础模型;第2组实验在第1组实验的基础上引入了ResBlockD模块,用两个ResBlock-D替代原本的CSP模块,mAP值降低了0.8 个百分点,FPS 提高了3.76 帧/s,可以看出引入ResBlockD 模块的改进策略在牺牲少量精度的条件下,对提高检测速度有重要作用;第3组实验和第4组实验在第1 组实验的基础上分别引入了空间金字塔池化(SPP)和两层CA注意力机制,可以看出,mAP值均有较大幅度提升,但检测速度均有一定程度降低;第5 组实验在第1 组实验的基础上同时引入了空间金字塔池化(SPP)和两层CA 注意力机制,mAP 值达到了最高的94.3%,检测速度下降了4.34 帧/s,最为明显。结果表明,空间金字塔池化(SPP)和两层CA 注意力机制在检测速度有所下降的条件下,对提高检测速度均有正面影响,且互相无干扰因素。第6 组实验在第2 组实验的基础上引入空间金字塔池化(SPP),mAP 值提高了0.2 个百分点,FPS为20.984 帧/s。第7组实验在第6组实验的基础上同时引入了空间金字塔池化(SPP)和两层CA注意力机制,mAP值提高了1.1个百分点,FPS为21.550 3 帧/s,变化较低。表明同时引入空间金字塔池化(SPP)和两层CA 注意力机制可有效弥补ResBlock-D 替代策略造成的精度损失。相比于第一组实验mAP 值提高了0.5个百分点,且FPS 提高了3.96 帧/s,效果最佳。综上所述,本文算法对YOLOv4-tiny 的改进具备合理性,在口罩佩戴检测中提高了实时检测性能。
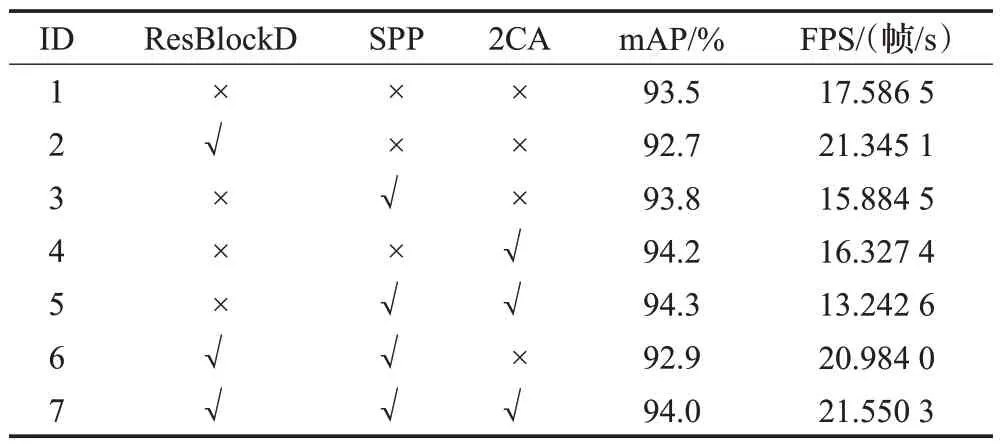
表5 消融实验Table 5 Ablation experiment
3.4.7 可视化分析
为了更直观地体现改进的目标检测算法的性能,如图12 所示,列举出了本文使用的轻量级YOLOv4 模型在口罩识别中的运行成果,从左往右依次是:YOLOv4、YOLOv4-tiny、YOLOv4-tiny-ResBlockD-SPP-2CA。

图12 不同模型实时可视化目标识别Fig.12 Real-time visualization of target recognition with different models
由可视化数据图可以看出,对不同环境下的口罩检测,YOLOv4、YOLOv4-tiny 以及YOLOv4-tiny-ResBlockDSPP-2CA 的检测精度表现不同。YOLOv4 检测精度总体更高,而YOLOv4-tiny 与YOLOv4-tiny-ResBlockDSPP-2CA 在不同的环境下检测精度方面相差较小,但YOLOv-tiny 在某些环境下,对同一目标的检测精度比YOLOv4-tiny-ResBlockD-SPP-2CA 更低。出现这种现象的原因也正说明了YOLOv4 由于结构更为复杂而表现出较高的检测精度,而改进型的YOLOv4 与传统的YOLOv4-tiny相比,分别引入SPP和CA机制,因这两种结构在精度上的改进,弥补引入ResBlockD模块所引起的精度下降的不足,故最终模型YOLOv4-tiny-ResBlockDSPP-2CA 的检测精度与YOLOv-tiny 相比较为接近,并且从总体而言YOLOv4-tiny-ResBlockD-SPP-2CA 精度更高,达到改进算法的效果,即实现改进后的算法的速度更快于YOLOv4-tiny且精度较YOLOv4-tiny更高。
3.4.8 基于摄像头的目标检测效果
上述中目标检测的图像都是直接输入的某一特定场合下的静态图片,故本实验中增加了引入摄像头进行拍摄的对比实验,从而更为真实地模拟了非特定场合下对不同人群的动态口罩检测捕捉。摄像头采用Chicony USB2.0 camera 型号,原摄像头像素分辨率为1 920×1 080,输入的是统一后的分辨率即480×640,其检测效果如表6所示。

表6 不同模型的检测效果Table 6 Detection effect of different models
由表中数据分析可知,基于两个CA机制、Resblock-D和SPP的YOLOv4-tiny模型在摄像头的运用中,检测时间更短,减少了延迟,目标检测的效果更为优秀,该算法更适合于具体运用在真实摄像头检测中。
4 结论与展望
本文在广域测温口罩识别的疫情具体应用下,给出了一个基于ResBlock-D、SPP和2CA的YOLOv4-tiny改进算法。首先采用了在ResNet-D 网络中的其他2 个ResBlock-D模块,来代替在YOLOv4-tiny网络中所使用的其他两个CSPBlock 模块,同时还专门设计出了与其他两个模块相同功能的Residual Network Blocks 模块来专门用作辅助残差块。在此基础之上加入空间金字塔池化(SPP)和两层“Coordinate Attention”(CA)注意力机制。在口罩佩戴人群数据集上进行了相同的训练和测试,结果表明,相比于最原始的YOLOv4-tiny算法,经改进后的YOLOv4-tiny-ResBlockD-SPP-2CA 模型的mAP提高了0.5个百分点,检测速度(FPS)提升了3.96 帧/s,综合性能得到提升。这样的改进,在保证检测结果精度有少量提升的基础上,降低了计算复杂度,有效提高了检测速度。有利于将算法部署到计算能力和内存等资源有限的嵌入式平台上,在医院、学校、商场等人流量较大的口罩佩戴环境下,更具实时性,更适合应用于真实的摄像头检测中。但是,在快速移动人群的检测中,由于位置目标不确定,目标难以捕捉完全,在实际应用中会出现一定误差。在保证网络的综合识别精度的基础上,进一步降低模型复杂度,提高检测速度,提高对移动人群识别检测的能力,使其更好地应用在广域测温识别疫情协同设备上是未来的重点研究内容。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
作文大王·笑话大王(2019年3期)2019-04-22
电子制作(2018年11期)2018-08-04
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
