
基于TextCNN的突发公共卫生事件网络舆情分类研究
2023-10-26 00:50袁琼芳张志强
无线互联科技 2023年15期
袁琼芳,张志强
(贵州师范学院 数学与大数据学院,贵州 贵阳 550018)
0 引言
突发公共卫生事件是近年来热点比较高的新闻事件,非常容易引起社会公众的关注和大面积的网络舆情讨论,这类舆情次生舆情爆发风险高,需要政府和相关部门具备全面的应急管理和舆情识别的技能。传统舆情情感分类技术在面对海量文本数据识别中存在速度慢、准确率低、成本高等问题,深度学习是近年来舆情情感分类的热点技术,可以快速准确低成本地对海量舆情进行情感分类。TextCNN是Kim[1]在2014年提出的文本分类模型,该模型将深度学习CNN推广应用到文本分类领域。基于上述背景,本文采用TextCNN模型对突发公共卫生事件网络舆情分类工作展开相关研究。
1 相关文献概述
深度学习在网络舆情情感识别方面的研究和应用是国内学者近年来研究的热点。邓磊等[2]搭建了基于深度学习的网络舆情监测系统框架;李芳等[3]设计了深度语义框架,构造自媒体网络舆情情绪分类模型,并在开放数据集中进行了实证研究;邵辉[4]提出了BERT-TextCNN 网络模型,并将该模型用于外卖中文评论数据集上进行情感分析;董晨[5]提出了基于深度学习算法的改进TextCNN分类模型且对新闻短文本数据进行了准确情感分类;彭清泉等[6]提出了基于ChineseBERT-BiSRU-AT的医疗文本分类模型,并对医学影像报告文本数据集进行了实验。
2 研究设计
2.1 研究思路
突发公共卫生事件发生后,新浪微博等互联网平台上充斥着社会公众对突发公共卫生事件的各种舆情信息,如何对海量舆情数据进行快速识别和有效引导是政府和相关企业工作的重要内容。本文的研究思路如图1所示。
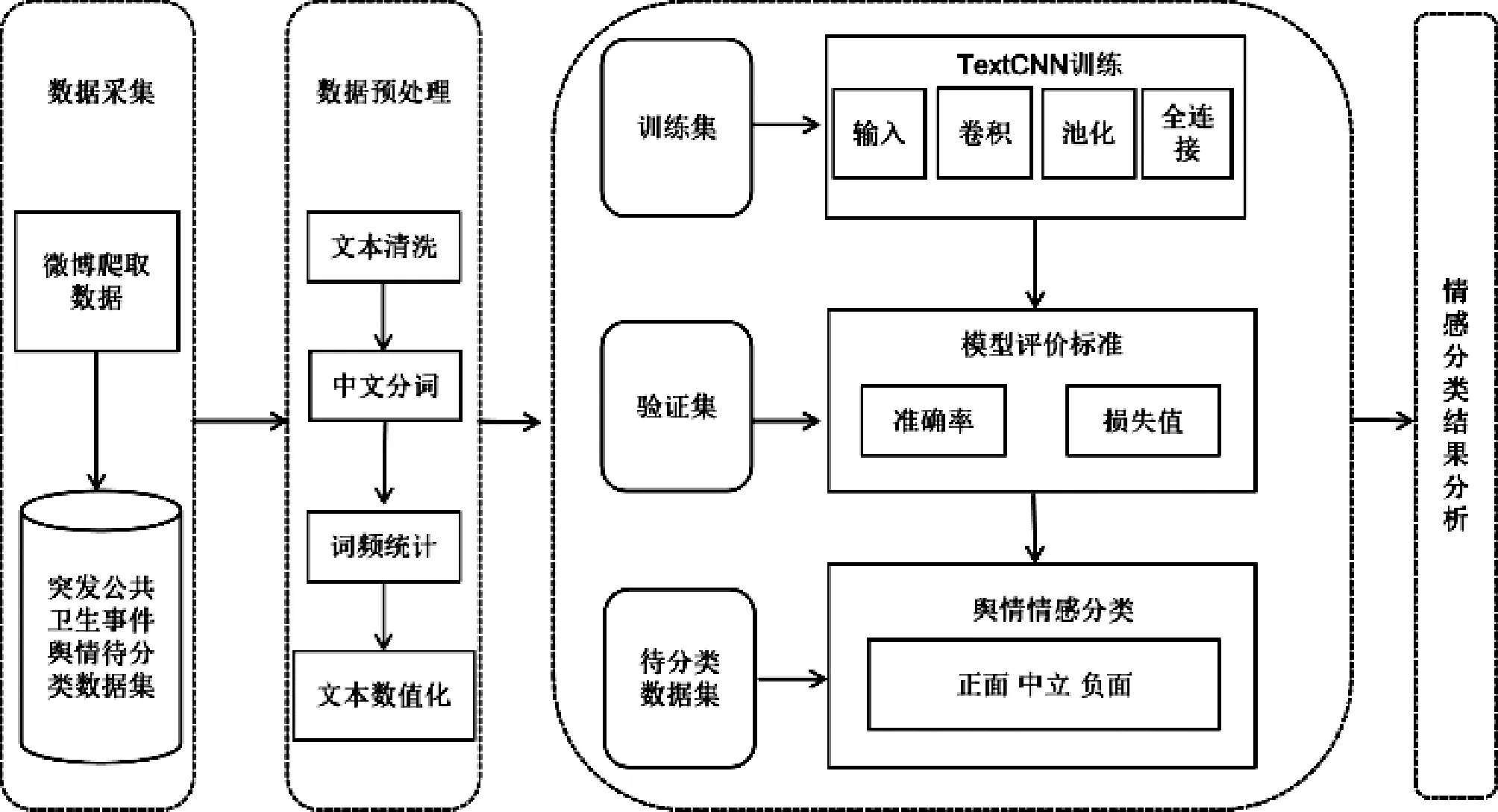
图1 研究思路
(1)突发公共卫生事件在新浪微博平台上相关网络舆情的数据采集和数据预处理。
(2)TextCNN卷积神经网络文本分类模型对训练集数据进行训练和对验证集数据进行验证。
(3)运用调试好的TextCNN模型对待分类海量数据集进行舆情情感分类。
2.2 研究步骤
2.2.1 数据采集
新浪微博是社会公众关注了解突发公共卫生事件新闻和发展趋势的主要平台,由此新浪微博上聚集了大量网民关于突发公共卫生事件的舆情讨论,也由此产生了大量的网络舆情数据。本文研究过程中通过相关爬虫工具从新浪微博平台爬取网民评论的舆情数据,将数据进行整理后形成待分类舆情数据集。
2.2.2 数据预处理
研究中采集得到的数据较多,很多是重复无效的评论,首先进行文本清洗,可通过Excel和Python对原始数据进行重复值删除、缺失值删除、数据合并与整合等文本清洗操作;文本清洗之后通过Python的jieba对评论文本数据进行中文分词、去停用词、统计词频操作;最后将中文分词后的每个词映射到一个数值索引,再通过字典将文本分词后的序列转为数值索引的序列。本文实验过程中转换时统一序列长度为20,以便输入模型,不满20长度的填充0,0对应
2.2.3 TextCNN模型
TextCNN模型针对舆情文本分类和情感识别工作都能够得到比较准确的结果,该模型经过以下4个步骤完成。
(1)输入层。
输入层的关键问题在于文本表示。本文研究中将数据预处理阶段处理后的数值序列导入模型,通过Embedding层,初始化权重使用Baidu Encyclopedia 百度百科中文词向量(300维)[7],将每个词表示成一个向量,此时数值序列转化为20×300的矩阵向量。
(2)卷积层。
卷积层中涉及多个超参数的设置,需要在具体实验任务中尝试才能得到最优的卷积效果,本文研究中对卷积层的参数调试后设置如下:卷积核数量(卷积中滤波器数量)设置为256,卷积核大小设置为3,激活函数设置为relu,初始化权值he_normal,strides设置为1。卷积操作之后将输入层向量转变成18×256的卷积特征矩阵。
(3)池化层。
池化层(Pooling)的主要作用是通过一定处理来减少模型参数个数,且在该过程中可以有效地防止模型出现过拟合现象。Pooling的方法很多,本文研究中选择的是全局最大池化 GlobalMaxPool1D,通过GlobalMaxPool1D操作将卷积层18×256的特征转化为一维的特征。
(4)全连接及输出层。
池化层操作之后进入全连接层,通过 Dropout 操作预防模型过拟合,最后通过 Softmax 计算每个情感类别的概率。
2.2.4 模型训练与验证
TextCNN模型基本框架设计出来之后,需要对模型中的参数进行不断调试,以确定最佳模型参数。对此,研究中从原始待分类数据集提取一部分数据(分为训练集和验证集)进行训练和验证。
为评估TextCNN模型文本情感分类算法的性能,本文选取准确率和损失函数两个指标对模型进行评价。
准确率(Accuracy)是指文本分类器判别的所有情绪类别中正确的情绪类别的占比,计算公式为:
其中,ncorrect表示突发公共卫生事件舆情评论被文本分类器正确分类的数量;ntotal表示突发公共卫生事件舆情评论的总数量。
损失函数(Lossfunction)一般指单个训练样本预测值与真实值之间的误差,在模型不存在过拟合的情况下,损失函数Loss值应该越小越好。损失函数有很多选择,对于解决多分类工作的情况,可以选择交叉熵损失函数来评价模型的误差情况。交叉熵的公式为:
其中,p(xi)表示样本的真实分布,q(xi)表示预测分布,n是总样本个数。
2.2.5 对待分类数据进行情感分类
为及时掌握网民对突发公共卫生事件的看法和情感走向,需要对爬取的舆情数据进行快速有效的情感识别和分类。基于上述构建的TextCNN模型,对待分类的数据集进行情感区分,本文将网民的情感区分为正面、中立、负面3种不同状态。
3 实验分析
3.1 实验环境
本研究数据运行需要的实验环境配置如表1所示。
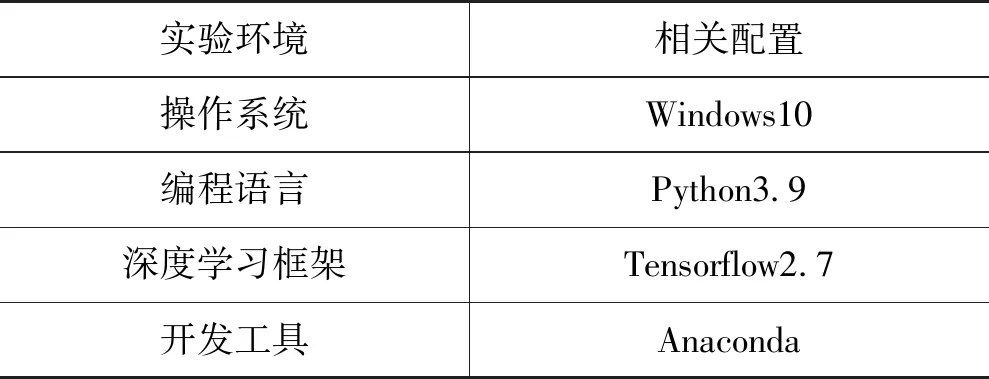
表1 实验环境配置
3.2 数据来源
本文通过大数据爬虫软件从新闻微博上爬取2020年和2021年的突发公共卫生事件相关新闻的舆情评论数据,通过数据预处理后共得到27 260条数据。
3.3 模型训练
TextCNN模型的最佳状态不是唯一的,需要通过训练集数据进行多次实验测试才能确定模型的最佳参数,还需要通过验证集数据对模型的预测准确性进行评价。从原始评论数据中选取1 200条舆情评论数据进行情感人工标注,为了使人工标注结果更具代表性,共标注出1 200条情感评论(400条正面评论、400条中立评论、400条负面评论),将1 200条人工标注情感的数据再次分为训练集数据(720条)和验证集数据(480条),将训练集数据代入TextCNN模型进行训练后,代入验证集数据进行验证,epoch次数会影响模型准确率,对dropout参数也做了多次调试,通过实验对比,确认最佳关键参数设置如表2所示。
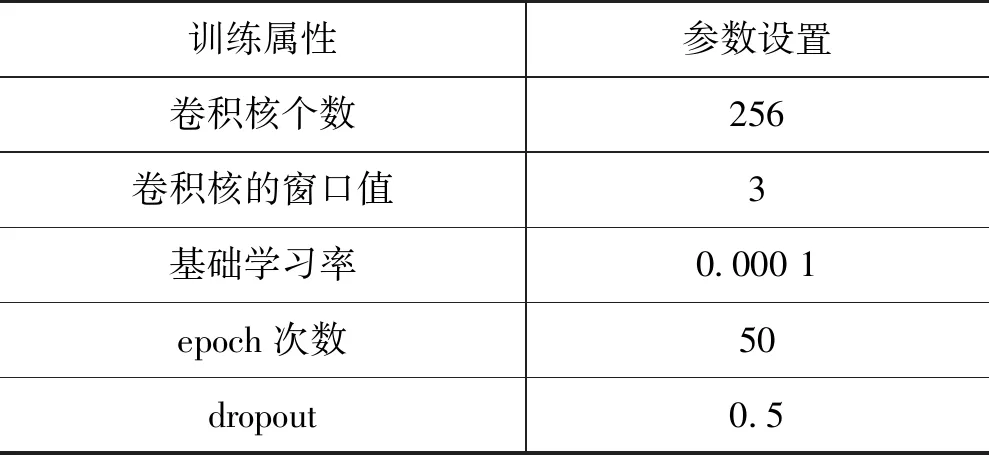
表2 模型主要参数设置
3.4 模型评价
模型准确率和损失值会随着epoch次数调整发生改变,通过模型训练,当epoch次数为50时,模型综合效果最优,训练集准确率达到99.86%,验证集准确率达到74.17%,训练集损失函数值0.117 2,验证集损失函数值0.698 9,具体如图2所示。

图2 不同epoch次数对应的模型准确率和损失值变化
图2中,左图的横坐标epoch表示模型训练次数,纵坐标Accuracy表示准确率;右图的横坐标epoch表示模型训练次数,纵坐标表示Loss损失函数值。
3.5 舆情情感分类
通过训练集训练得到最优的TextCNN模型后对待分类数据集进行情感分类,通过分类结果可以对网民的舆情情感进行判断。
4 结语
突发公共卫生事件是近年来热点比较高的新闻事件,非常容易引起社会公众的关注和大面积的网络舆情讨论,对网民的情感评判和引导是政府和相关企业工作的重要内容。本文基于TextCNN模型对突发公共卫生事件网络舆情进行情感分类,通过网络爬虫工具爬取微博平台上的突发公共卫生事件网络舆情数据,采用人工标注方式挑选出训练集数据和验证集数据,运用Python软件代入TextCNN模型进行训练测试后得到了较优的分类模型,该模型可以运用到突发公共卫生事件的具体实践分类中。本文的实证成果对政府相关部门快速判断公众舆情走向、把握舆论引导的最佳时机、掌握舆论引导的分寸火候均有一定参考意义。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
首都公共卫生(2019年5期)2019-02-12
北京航空航天大学学报(2018年1期)2018-04-20
首都公共卫生(2017年1期)2017-11-29
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
中国卫生(2014年3期)2014-11-12
中国卫生(2014年11期)2014-11-12
