
高分辨质谱与深度学习视阈下的藏红花品质分析
2023-10-25 06:38魏哲文巩志国
分析测试学报 2023年10期
宋 含,房 芳,魏哲文,杨 丽,巩志国*,张 荣,贾 玮*
(1.陕西科技大学 食品科学与工程学院,陕西 西安 710021;2.乌鲁木齐海关技术中心,新疆 乌鲁木齐830063;3.阿拉山口海关技术中心,新疆 阿拉山口 833418)
藏红花为高附加值产品,存在劣质原料掺假现象,而溯源分析可保障藏红花产业链高质量发展。高分辨质谱具有全扫描、高通量、非靶向的特点[1],与化学计量学数据分析方法结合,可作为判定藏红花品质的有效手段。目前,深度分析质谱数据特征的方法包括:决策树算法、朴素贝叶斯算法、逻辑回归算法、K-近邻算法、支持向量机算法、偏最小二乘判别分析算法、正交偏最小二乘判别分析算法、K-均值聚类算法、层次聚类分析与Mean Shift密度聚类法[2]。前期研究发现,藏红花素(C44H64O24)、苦藏红花素(C16H26O7)和藏红花醛(C10H14O)的浓度是评价藏红花品质的重要指标[3],但在判别模型拟合过程中,部分隐匿数据被认定为冗余信息或阈值设定不准确,均将导致判定结果假阳率与假阴率升高。
深度学习算法具有高效率整合海量样本数据的优势,可解决数据的分类、回归和聚类问题。该方法可从输入数据中提取局部或全局特征表示的信息结构,依据稀疏连接和权重共享策略,降低模型过度拟合现象。自深度学习模型提出以来,已衍生出视觉几何组网络(VGG)[4]、残差神经网络(Res-Net)[5]、密集神经网络(Dense-Net)和“U”型卷积神经网络(U-Net)[6]等优化模型,为数据处理与图像融合提供了理论支撑和实践经验。与传统数据处理方法相比,基于深度学习的数据处理方法具有以下优势:(1)显著的特征提取和分析能力。深度学习模型可获取原始数据的特征信息[7],并通过连续迭代过程提高对特征信息的解读能力。(2)灵活的网络架构。基于深度学习的数据处理方法可在数据采集过程中自动调整提取数据信息的能力[8],突破了传统分析方法通过手动调整规则来提高数据提取能力的限制。(3)端到端的分析过程[9]。深度学习模型是将原始数据直接输入,通过多层网络处理,自动提取特征,输出最终结果。
本文基于深度学习算法在代谢组学数据采集与处理方面的应用,总结分析了通过深度学习算法处理藏红花质谱数据,实现藏红花品质精准鉴别的可行性,助力藏红花产业链高质量发展,以期为后续研究中药材等复杂基质成分提供参考资料。
1 深度学习算法在高分辨质谱代谢组学数据分析中的应用
代谢组学数据具有高维、小样本、高变异性、相互作用关系复杂、相关性和冗余性、分布的不规则和稀疏性等特点,传统数据分析策略(包括功能表征、注释和集成)难以解释代谢组学数据中隐藏的复杂数据关系。深度学习算法通过多层网络处理,将初始的“低层”特征转化为“高层”特征[10],构建“简单模型”,分类复杂信息,提高数据分析的能力和解释性,现已应用于质谱数据采集与处理过程中的噪音过滤、峰检测、整合和对齐、重叠峰的去卷积、子结构预测和代谢物识别等方面。深度学习算法主要包括:人工神经网络、长短期记忆神经网络、循环神经网络、生成对抗神经网络、卷积神经网络及其衍生网络(图1)。
目前深度学习在目标物质检测等领域取得的突破性进展大多是以卷积神经网络为基础搭建识别模型而实现的,卷积神经网络是处理代谢组学数据的常用深度学习模型[14],用于目标物质精准识别与杂峰剔除。卷积神经网络的卷积层富含类似于神经元的卷积核,可对输入数据进行特征提取,依托参数共享策略进行分组激活,提高算法运算速度,减少分析时间(公式1)。
式中,Pm表示卷积层的参数量,Dk、Hk分别表示卷积层的宽和高,Dk*Hk表示卷积核的维度,Ni表示输入通道数,Nr表示输出通道数,K表示偏置项参数。
Johnsen 教授团队[15]使用PARAllel FACtor analysis 2(PARAFAC 2)算法对不同洗脱图谱进行分类建模,但在处理质谱数据时,存在费时、耗力等缺点。Risum 教授团队[16]使用卷积神经网络分类洗脱图谱,将其划分为化学峰(代谢物)、基线和其他非相关峰,并筛选出最佳匹配峰(图2A),对化合物进行定性与重复性分析。Yanshole 教授团队[17]开发了一种用于峰值检测和积分的“峰值”算法,该算法使用卷积神经网络模型将质谱数据分为噪声、化学峰和不确定峰值区域,确定了积分的峰值边界。他们发现卷积神经网络与手动提取的峰面积的平均相对误差为4%,并比较了卷积神经网络与XCMS、MZ mine软件的性能,发现卷积神经网络可以97%的精准度实现阳性峰的检测(图2B),提高了代谢组学数据匹配峰的覆盖率。
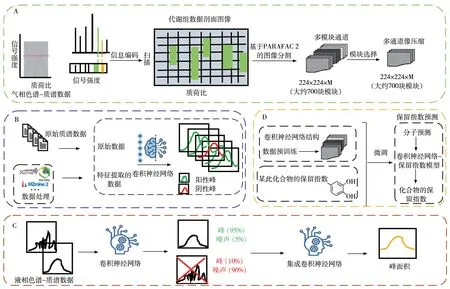
图2 卷积神经网络识别气相色谱-质谱数据的真阳性峰[16](A);卷积网络模型精准检测色谱数据峰值[17](B);卷积神经网络识别液相色谱-高分辨率质谱数据峰[18](C);深度神经网络模型提高液相色谱-串联质谱数据的保留时间预测性能[22](D)Fig.2 Recognition of true positive peaks in GC-MS data by convolutional neural networks[16](A);convolutional network model accurately detects the peak value of chromatographic data[17](B);convolutional neural networks identify peaks in liquid chromatography-high resolution mass spectrometry data[18](C);deep neural network model improves retention time prediction performance of liquid chromatography-tandem mass spectrometry data[22](D)
自动化和高精度的峰值分类器显著提高了峰值检测效率,突破了人工解析质谱数据费时、耗力的困局。但这种方法尚未与多变量统计和机器学习方法进行比较。Kantz教授团队[18]开发了深度神经网络联合多元逻辑回归模型的方法,对非靶向代谢组学数据的质谱特征进行分类。该方法将峰的形状转换为图形对象,基于预测峰组参数medRelFWHM(公式2),剔除了90%的阴性峰(噪音),保留了98%的阳性峰(图2C),提高了代谢组学数据处理的准确性。Li 和Wang[19]提出了一种基于循环神经网络的ChromAliggnNet算法,使用该算法学习和训练单峰(特定的m/z和保留时间)水平上的数据,在检测真阳性结果时具有84% ~ 96%的可信度。
未知化合物鉴定主要依赖于HMDB、METLIN[20]等质谱数据库,利用二级谱图信息,结合质谱获取的精确质量数、同位素分布及碎片离子等化合物结构信息,获得候选化合物。但因参考质谱图数量有限,且化合物的质谱图随仪器类型和所施加的碰撞能量不同而变化,增加了未知化合物的识别难度。基于未知化合物和已知化合物之间的相似性,Lu 教授团队[21]设计了一种基于神经网络的DeepMASS 框架,该框架利用已知代谢物与未知代谢物之间的结构相似性及其产生的质谱图,识别未知化合物,但该方法仍受已知化合物的可用性及其在参考数据库中覆盖范围的限制。Risum 等[16]在化合物结构信息的基础上进一步探究了应用保留指数提高注释化合物准确率的可行性。METLIN 小分子保留时间(SMRT)数据集中包含了80 038 个小分子的反向色谱保留时间。Zhang 等[22]基于SMRT 数据集构建了预测色谱保留时间的深度学习模型(GNN-RT),并比较了GNN-RT 模型、随机森林模型、贝叶斯回归模型和卷积神经网络模型的预测精度。该模型将化合物的国际化学标识符(International Chemical Identifier,InChl)作为输入,保留时间作为输出,随机选择SMRT数据集中80%的化合物作为训练集,10%作为验证集,10%作为测试集。结果发现4种模型的平均滤除率依次为50.6%、21.6%、41.3%和38.5%。GNN-RT过滤掉的候选化合物中假阴性率最高,均方误差(MSE,公式3)为4.9%,中位绝对误差(MedAE,公式4)为3.2%,显著提高了模型的预测精度,使未知化合物的识别覆盖度提高了30%(图2D)。
式中,yi为真实值,为GNN-RT模型的预测值,m为样本量。
表1给出了深度学习算法在代谢组学数据处理方面的一些应用。

表1 深度学习算法处理代谢组学数据的应用Table 1 Applications of deep learning algorithms to processing metabolomics data
2 深度学习算法结合高分辨质谱数据鉴别藏红花品质
藏红花具有养血活血功效,深受消费者青睐,但因经济效益高,时常存在原料掺假现象[33]。现有研究主要采用化学/非化学技术结合传统数据分析策略对藏红花及其掺假物进行鉴别。Farag 团队[34]采用气相色谱-质谱联用技术对藏红花及其掺假物(红花和金盏花)进行分析,依据差异代谢物筛选掺假物。但样品的代谢组学数据具有高度复杂性,若部分隐匿数据被视为冗余信息剔除,将会降低判别模型的拟合度,影响判别结果的准确率。在代谢组学数据处理过程中,深度学习算法可直接识别或检测数据信息,建立相关特征的预测模型,降低模型过拟合现象,提高分类准确性。通过深度学习算法鉴别藏红花品质,在保障藏红花产业链高质量发展方面具有重要意义。
表2为深度学习算法在鉴别藏红花品质方面的代表性应用。

表2 深度学习算法在鉴别藏红花品质中的应用Table 2 Applications of deep learning algorithms in saffron quality identification
Neshat 团队[35]采用Inception-v4 卷积神经网络对藏红花图像进行分类评估及识别,准确率达99.5%。在分级评价真假藏红花或因加工方式不同导致的藏红花颜色不同时,Inception-v4 卷积神经网络的性能显著优于常规卷积神经网络和传统分类器(支持向量机、随机K-近邻算法)。Rohani团队[36]开发了一种基于卷积神经网络的藏红花品质鉴别模型,并使用批量归一化(BN)算法(公式5)进行优化,加快了模型收敛速度,提高了模型识别真假藏红花的准确率。通过与VGG11、ResNet18、ResNet50、DarkNet53 和Inception-v3 5 种模型的性能进行比较,发现经批量归一化算法优化的模型在鉴别藏红花品质方面的性能更佳,准确率为99.67%,交叉熵损失为0.019。
式中,β、γ表示可训练的参数;ε 表示可忽略的参数,用于避免被零除;m表示每次调整参数前所选取的样本数量。
Minaei 团队[38]依托人工神经网络和智能感官系统,开发了一种基于藏红花香气的识别系统,用于伊朗不同产区藏红花香气强度的分析并以100%的成功率实现了藏红花香气的指标分级。人工神经网络类似于大脑的神经元,接收输入的神经信号,产生非线性输出,并将其作为下层神经网络的输入信号。ReLU 激活函数(公式6)位于神经元内,通过响应输入的神经信号,提取输入的y值并给予权重W,将其相加并插入激活函数g中,用J表示激活函数输出,得到公式(7)。
式中,b表示隐藏层数,i表示所分析的样本量,w为第i个样本的权重。
人工神经网络模型处理藏红花数据时,基于随机参数启动模型,自动比较预测值与输出值。通过调整参数,降低误差,使输出值无限接近预测值。因梯度值处于一定动态范围内,陈宏文等[41]使用均方误差MSE 作为损失函数,提高模型收敛性,减少训练时间。决定系数(R2)、均方误差(MSE)可作为评估模型拟合度的指标,R2越趋近于1,MSE值越小,则模型拟合效果越好。
Heidarbeigi 等[42]将机器学习算法和人工神经网络相结合,以高分辨质谱测定的代谢物信息作为中转载体,判别藏红花样品中藏红花醛的浓度。结果发现,相同数据集下,人工神经网络的预测性能优于机器学习算法,且基于人工神经网络的质谱数据以98.81%的准确率预测了藏红花醛的浓度。该课题组[43]使用同样方法以98.80%的准确率预测了藏红花样品中的藏红花素浓度。
高分辨质谱技术具有高分辨率、高质量精度和高灵敏度的特点[44-46],可对复杂基质中的痕量成分进行定性确证和定量检测。现有研究主要集中于以高分辨质谱测定的代谢物信息作为中转载体,探究藏红花品质。Hajslova 团队[47]采用超高效液相色谱-高分辨质谱检测西班牙藏红花和掺假藏红花中的藏红花素及相关代谢物浓度,并将质谱获取的代谢物信息转换为图像,使用基于循环神经网络结构的长短期记忆神经网络进行训练,探究藏红花样品中相关代谢物的含量,预测藏红花品质。
区别于人工神经网络,循环神经网络是一种反馈神经网络,其在隐藏单元中保存序列先前时刻的“状态向量”,循环隐藏单元为公式(8)~(9)。循环神经网络使用并行计算算法,从数据集中提取特征信息,可提高数据处理准确性,加快运行效率。ReLU 激活函数(公式6)可影响循环神经网络的性能[48],提高循环神经网络模型的收敛性或鲁棒性。
式中,ht和ht-1分别为模型中t和t-1 时刻的隐藏单元状态,xt表示t时刻输入的训练样本,by表示偏置向量,yt表示t时刻的输出结果,V表示t时刻输入的训练样本的权重矩阵,W、U分别表示t和t-1时刻隐藏单元状态下的权重矩阵,bh表示偏置向量。循环神经网络模型处理藏红花长序列数据信息时存在梯度消失或梯度爆炸现象,导致判别结果的准确率降低。Han 团队[49]开发了一种基于循环神经网络的长短期记忆神经网络,消除了梯度爆炸或梯度消失现象,提高了模型预测精度。长短期记忆神经网络通过遗忘门、更新门和输出门调节过去和现在活动之间的信息流以及循环单元的输入和输出[50]。此过程可由公式(6)、(10)、(11)表示。
式中,Lu、L0、Lf分别表示t时刻更新门、输出门和遗忘门的门控信号,ct表示内部存储单元的中间候选状态,ct-1表示内部存储单元前一时刻的值,表示t时刻的候选记忆信号。该模型经自适应粒子群(IAPSO)算法优化,可降低人工选择超参数对预测精度的影响,提高模型的收敛速度。该模型将层次分析(AHP)法获取的数据作为输出,均方根误差(RMSE)(公式12)作为目标函数,以匹配长短期记忆神经网络模型的最优超参数组合。以藏红花素、藏红花醛、苦藏红花素的浓度作为输入,藏红花品质值作为输出,建立基于IAPSO-LSTM 的藏红花品质鉴别模型,通过相关系数鉴别藏红花品质,可为实现藏红花品质鉴别提供参考依据。
式中,yi表示实际值,表示预测值,m表示样本数量。RMSE 值越小,长短期记忆神经网络模型的超参数组合匹配率越高,建立的模型的预测精度越高。
藏红花中的基质成分复杂,深度学习算法可从多角度评估藏红花代谢组学数据,在减小组内样本差异、差异代谢分析、分类准确性等方面具有显著优势。
3 结论与展望
本文总结了利用深度学习算法处理代谢组学数据的现有工作及优势,分析了深度学习算法结合高分辨质谱技术鉴别藏红花品质的可行性。深度学习算法可自动提取数据特征,降低数据处理过程中判别模型过度拟合的现象,提高判别模型预测性能和精准度,实现藏红花品质的精准鉴别。随着高分辨质谱配套智能软件分析能力的不断完善,以深度学习为代表的智能算法在在高分辨质谱数据处理中将有广阔前景。
猜你喜欢
食品安全导刊(2021年20期)2021-08-30
家庭百事通·健康一点通(2019年10期)2019-11-11
国际口腔医学杂志(2019年3期)2019-05-31
江苏卫生保健(2018年10期)2018-10-27
天然产物研究与开发(2018年2期)2018-04-04
中成药(2016年4期)2016-05-17
中国民族医药杂志(2016年1期)2016-05-09
当代化工研究(2016年5期)2016-03-20
医学研究杂志(2015年11期)2015-06-10
特产研究(2014年4期)2014-04-10
