
基于LERT和双通道模型的微博评论情感分析研究
2023-10-23 02:58荀竹
计算机时代 2023年10期
荀 竹
(湖北工业大学理学院,湖北 武汉 430068)
0 引言
在信息化背景下,对社交媒体下的网民评论进行情感分析有助于相关机构监管网络环境、掌握舆论走向、加强网络舆情引导,具有非常重要的现实意义。
情感分析最早由Nasukawa[1]等人提出,此后出现了大量研究,随着研究的不断深入,基于深度学习的情感分析方法[2-4]已成为主流的研究方向,并逐渐由词向量技术演变为预训练语言模型。为了更好地理解中文文本的情感倾向,一些学者引入依存句法分析技术来辅助模型分析。杜启明[5]等人提出一种依存关系感知的嵌入表示,针对性地挖掘不同依存路径对情感分析任务的贡献权重。代祖华[6]等人使用图神经网络分别获取词的句法结构特征表示和融合外部知识库信息的词特征表示。张文豪[7]等人用层次词汇图代替普通的依存句法树,更关注词汇之间的共现关系。先前的工作大多是将语言知识结构与复杂模型结合,而Cui[8]等人提出一种语言学信息增强的预训练模型LERT(Linguistically-motivated bidirec-tional Encoder Representation from Transformer),不需要增加模型的复杂程度,而且在同等训练规模下的训练效果更好。
因此,本文构建了LERT-BiGRU-TextCNN 模型对评论文本进行情感分析,主要贡献如下:
⑴提出一种基于LERT 语义向量的情感分析模型,该模型预训练阶段使用了Transformer 结构中的encoder部分对文本进行词性标注、命名实体识别以及依存句法分析标注,生成深层的双向语言表征。
⑵基于LERT得到的基础语义向量,设计BiGRU和TextCNN的双通道结构,进一步对语义特征进行优化融合,得到可用于情感分析的高质量情感语义特征。
⑶ 在数据集SMP2020-EWEC 上的实验结果表明,LERT-BiGRU-TextCNN 模型具有更高的准确率和F1值,体现了该模型的有效性。
1 LERT-BiGRU-TextCNN 模型
与传统文本情感分析模型不同的是,本文提出的模型使用LERT预训练模型作为embedding层,能够包含更多的语言信息,并且在对该模型进行训练时,可以只训练BiGRU、TextCNN 部分的参数,大大降低了模型训练成本,提升了模型的训练效率。如图1所示,模型分为三个部分:首先通过LERT 预训练模型得到文本中词的向量表示,再将词向量序列分别输入到BiGRU、TextCNN 模型中进一步提取语义信息,最后通过全连接层输出情感分类结果。
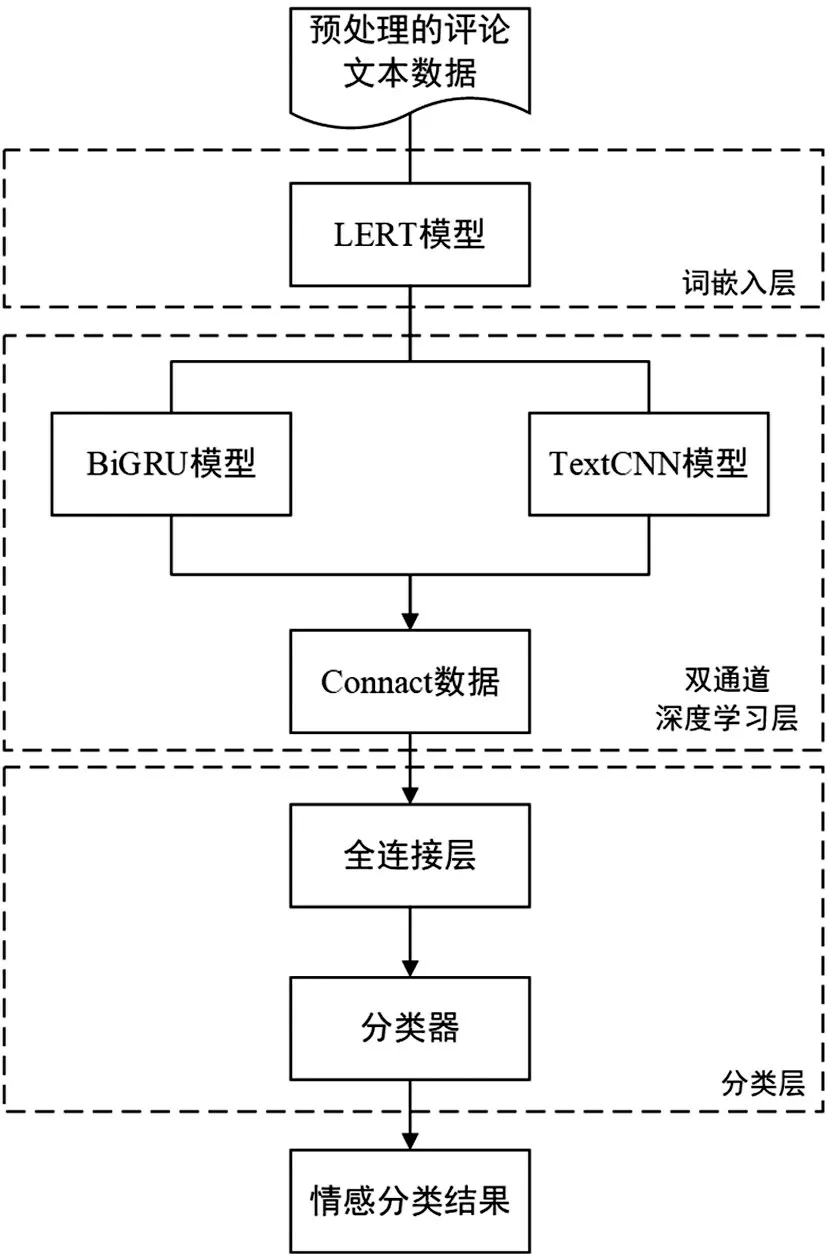
图1 LERT-BiGRU-TextCNN模型结构
1.1 LERT预训练模型
LERT 是一种语言学信息增强的预训练模型,在掩模语言模型的基础上结合语言基础平台(LTP)对评论文本进行训练。如图2 所示,其流程主要分为语言分析和模型预训练两个部分。

图2 LERT框架
⑴语言分析。使用LTP 对输入的文本进行词性标注(POS)、命名实体识别(NER)和依存句法分析(DEP)标注,生成语言学标签。
⑵模型预训练。LERT 只对掩码位置进行预测,将每个输入投影到相应的POS、NER 和DEP 中使用LTP进行标注。
比如,网络中Transformer 的最后一个隐藏层为H∈RN×d(N为输入的文本向量长度,d为隐藏层大小),用来表示掩码特征信息的向量为Hl∈H,输入的词嵌入矩阵为E∈RV×d(V为语言标签数量)。对于任一语言分析任务(POS、NER 和DEP),其归一化概率pi计算如下:
1.2 双通道深度学习模型
1.2.1 BiGRU通道
考虑到词语与上下文之间的联系,本文使用BiGRU 网络提取特征信息,从文本序列前、后两个方向完成遍历,挖掘隐含特征。BiGRU 由前向GRU和反向GRU 组成,在计算自身隐藏状态时相互独立,其结构如图3所示。

图3 BiGRU结构
BiGRU 在t 时刻的隐藏层状态gt由前向GRU 隐藏状态-1和反向GRU 隐藏状态-1加权求和得到,计算如下:
1.2.2 TextCNN通道
TextCNN融合了CNN网络结构的优点,同时解决了词袋模型的稀疏性问题,其结构分为四个部分:
⑴嵌入层将训练好的词向量输入到网络中,并用矩阵表示输入的文本序列,如下:
其中,k为序列所含词个数;xi为第i个词的词向量;⊕为拼接操作符。
⑵卷积层使用多个不同大小的卷积窗口同时提取文本信息,再通过非线性激活函数f得到特征映射矩阵C=[c1,c2,⋅⋅⋅,cn,],特征公式为:
其中,ci为第i次卷积值;Cj为第j个卷积核通过卷积得到的矩阵;H为卷积核;h为卷积核大小;b为偏置参数;n为卷积核个数。
⑶池化层通过最大池化法得到一个定长的向量表示,并实现矩阵降维,防止过拟合现象的发生。
⑷全连接层在全连接层使用dropout 函数,以减少网络对连接的过度依赖。
2 实验结果与分析
2.1 实验数据
为了评估LERT-BiGRU-TextCNN模型的有效性,使用SMP2020-EWECT 微博评论数据集进行实验。首先将数据分为积极评论和消极评论两大类,使用HarvestText 和Pyhanlp 清洗评论文本,删除网页链接与冗余符号,但保留“?”“!”等具有情感色彩的标点符号,经整理得到的有效数据统计信息如表1所示。
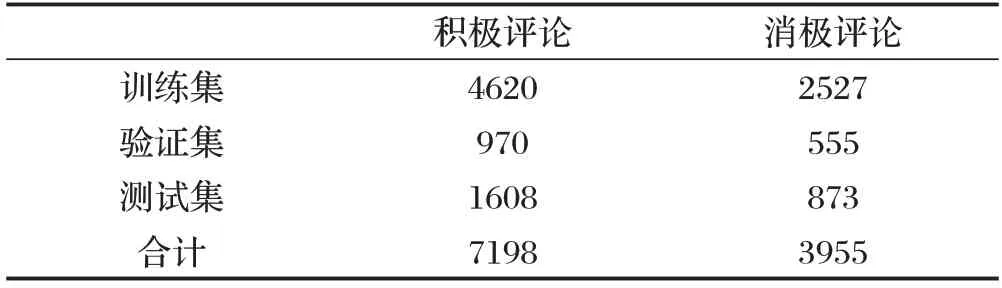
表1 实验数据统计表
2.2 实验环境与参数
针对本文使用的模型,选择LeakyReLU 作为激活函数,以避免ReLU 函数的神经元死亡问题;采用随机梯度下降法更新权重,优化器选用Adam 算法;模型的损失函数为CrossEntropyLoss。模型参数设置见表2。

表2 模型参数设置
2.3 对比实验
为验证LERT-BiGRU-TextCNN 模型的有效性,选用以下四个模型作为基线进行对比实验。
BiRNN:该模型能够获取文本序列的上下文信息。
TextCNN:该模型使用多个尺寸的卷积核同时提取特征,并通过池化层聚合重要特征、降低特征维度。
BiGRU:一种双向循环神经网络模型。在门控递归单元的基础上,采用双向结构进行情感分析。
BERT-TextCNN-BiGRU:在BERT 基础上,添加了融合TextCNN和BiGRU的双通道神经网络结构。
2.4 实验结果及分析
本文使用准确率和F1值作为模型性能评估指标,实验结果如表3所示,本文所用模型为LERT-BiGRUTextCNN。
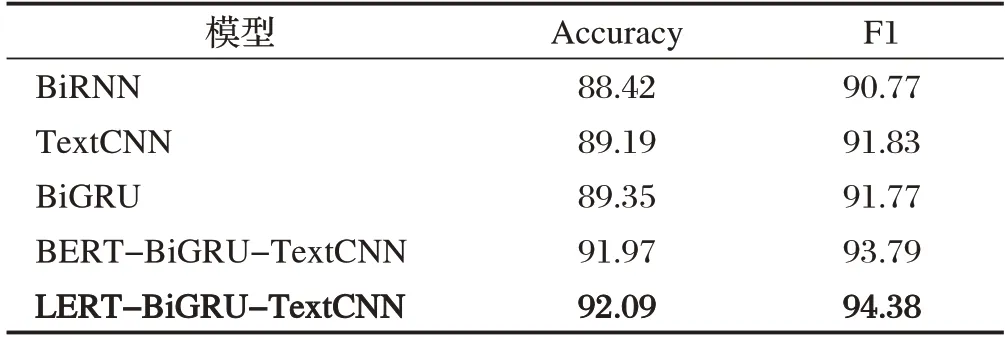
表3 模型实验结果对比(%)
由表3 可以看出:本文模型在数据集上的表现均优于对比实验模型。这是因为BiRNN、TextCNN 和BiGRU 模型无法解决文本时序特征的问题,容易发生梯度爆炸。BERT-BiGRU-TextCNN 模型基于Transformer 结构并行计算,解决了传统情感分析模型的梯度爆炸问题,因此在对比实验中具有较高准确率。本文提出的模型使用LTP 对文本进行POS、NER和DEP 标注,能够包含更多语言信息,更适用于处理含有大量中文的微博评论数据,因而拥有更高的准确率和F1值。
3 结束语
本文提出了一种基于LERT 预训练语言模型和BiGRU-TextCNN 双通道的情感分析方法。使用LERT 进行语义标注,将语义信息输入到双通道模型中进行训练。对比现有的研究方法,本文方法具有更高的准确率和F1值,模型训练效果更显著。接下来还需要考虑融入方面词特征,结合LERT 表征情感词的多义性,以提高文本情感分析模型的识别精度。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
昆明医科大学学报(2021年4期)2021-07-23
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
电子设计工程(2015年16期)2015-02-27
电视技术(2014年19期)2014-03-11
