
基于高光谱特征参数的冬小麦氮营养指数估算
2023-10-23 08:18:50王玉娜李粉玲李振发吕书豪
麦类作物学报 2023年11期
王玉娜,李粉玲,李振发,吕书豪
(西北农林科技大学资源环境学院,陕西杨凌712100)
氮素是作物生长必需的营养物质之一,与作物的生长状况、产量和蛋白质含量息息相关[1-2]。氮营养指数(nitrogen nutrition index,NNI)是定量表达作物氮素营养丰缺程度的一个重要指标,能够从作物群体特征出发,较准确地反映作物的氮营养状况[3]。实时、快速、无损监测作物氮营养指数是掌握农田氮素养分分布、协调田间管理措施的重要依据[4-5]。
随着高光谱遥感技术的发展,国内外学者在实时监测叶片叶绿素含量(LCC)、叶片氮素含量(LNC)、叶片氮素积累(LNA)、植株氮素浓度(PNC)、植物氮素吸收(PNU)等作物氮素营养方面取得了一定的研究成果[6],但利用高光谱技术对作物NNI实时监测的研究还比较少。研究表明,利用线性内插法红边位置(REPLI)估测冬小麦NNI的精度较高,决定系数可达0.859[7];春玉米NNI与黄边内一阶微分光谱中的最大值相关性较高[8];在可见光至近红外光的冠层光谱反射率区域,对夏玉米NNI最敏感的光谱带位于710和512 nm[9]。植被指数与作物NNI也密切相关。如,植被指数与甜椒NNI在果实生长早期和开花期存在较强的相关性,但相关性在营养阶段和收获阶段变弱[10];Yu等[11]提出了一种基于双植被指数的NNI遥感指数(NNIRS),可用于监测作物氮素状况。然而,目前还没有具体的植被指数用于跨多个生长发育时期的NNI反演。在目前的高光谱遥感研究中,偏最小二乘回归、支持向量机、随机森林回归等算法被广泛应用,而且均显示出了强大的模型构建能力,但不同算法在具体实践中应用效果各有千秋,如对玉米冠层原始高光谱信息预处理后,结合随机森林算法反演NNI的精度要优于偏最小二乘回归和BP神经网络回归[9]。总体来看,作物冠层高光谱技术结合机器学习算法是NNI估算的潜在途径,但目前基于冠层高光谱的NNI估算精度整体不高,而且对不同生育时期的估算结论有待验证。如,基于无人机高光谱成像影像构建了NNI的随机森林估算模型,虽然模型较为稳定,但其解释能力不到80%[12];基于无人机高光谱成像影像和不同时期的植被指数预测冬小麦NNI时,扬花期的解释能力要高于拔节期和孕穗期[13];机器学习算法结合遥感数据、土壤、气候和田间管理参数会进一步提升作物NNI估算模型的精度[14]。
有研究者认为,吸光度变换(ABS)[15]、连续统去除变换(CR)[16]等光谱变换能在一定程度上减弱作物冠层原始光谱背景噪声,提升作物理化参数的反演精度[17-18]。本研究对获取的冬小麦冠层高光谱数据进行光谱变换,构建“三边”参数、任意两波段光谱指数和植被指数三类光谱参数,筛选对NNI敏感的光谱特征参数,基于偏最小二乘回归、随机森林、支持向量机回归和梯度增强回归构建冬小麦NNI模型,并对模型精度进行比较,以期获得最佳NNI估算方法,为诊断调控冬小麦氮素营养、实时监测生长状况和后期田间管理提供基础数据。
1 材料与方法
1.1 试验设计
2017-2019年在陕西省咸阳市乾县梁山镇齐南村设置冬小麦小区种植试验(34°38′N,108°07′E)。该区土壤类型为壤土,0~40 cm耕层有机质含量为13.36 g·kg-1,全氮含量为0.48 g·kg-1,速效氮含量为44.86 mg·kg-1,有效磷含量为13.54 mg·kg-1,速效钾含量为182.88 mg·kg-1。供试小麦为当地主栽品种小偃22。试验设置不同水平的氮磷钾单因素处理,每个处理重复两次,小区面积90 m2(10 m×9 m)。氮素处理设置0、30、60、90、120和150 kg·hm-26个施氮水平,各处理均施磷(P2O5)45 kg·hm-2和钾(K2O)60 kg·hm-2;磷素处理设置0、22.5、45、67.5、90 和112.5 kg·hm-26个施磷(P2O5)水平,各处理均施氮90 kg·hm-2和钾肥(K2O)60 kg·hm-2;钾素处理设置0、15、 30、45、60 和 75 kg·hm-26个施钾(K2O)水平,各处理均施氮90 kg·hm-2和施磷(P2O5)45 kg·hm-2。小区种植管理方式同当地大田。
1.2 光谱数据及处理
采用美国SVC HR-1024I型野外光谱辐射仪,分别在2017、2018、2019年冬小麦生长发育的四个关键时期(拔节期、抽穗期、开花期和灌浆期)进行冠层高光谱测定。调整光谱仪视场角25°,镜头垂直向下距冬小麦冠层1 m处,重复测定冠层光谱10次。每个样区选取两个样点,取平均值作为该样区的光谱反射率。每次冠层光谱测定前进行标准白板校正,以确保良好的光谱测定质量。为减弱或消除光谱的背景噪声,提高敏感波段的灵敏度,本研究对350~1 350 nm范围内高光谱反射率数据分别进行平滑光谱变换(SM)、一阶导数光谱变换(FD)、吸光度变换(ABS)和连续统去除光谱变换(CR)4种预处理[19]。
1.3 农学参数获取
采集冠层高光谱数据后,各小区以测定点为中心,采集0.5 m×0.5 m范围内的植株地上部。从样品中随机选取20株称鲜重,放置105 ℃烘箱杀青30 min,然后于80 ℃下烘干48 h以上,根据范围比例计算记录各小区地上部干物质重。烘干的样品粉碎后称取0.2 g,使用凯氏定氮法测定冬小麦植株氮浓度(%)。NNI定义为作物地上部植株氮浓度与临界氮浓度的比值[20]。NNI=Nc/Nct;Nct =4.28W-0.49。式中Nc为作物植株氮浓度(%),Nct为临界氮浓度(%)。临界氮浓度为作物达到最大干物质所需要的最低氮浓度,本研究采用李正鹏基于小偃22建立的关中平原冬小麦临界氮浓度模型[21]:W为作物地上部生物量(t·hm-2)。
1.4 光谱参数的提取与选择
为充分利用光谱信息构建光谱参数,提高作物高光谱监测精度,本研究构建三类光谱参数进行估算分析:(1)“三边”参数,是在原始光谱和一阶导数光谱的基础上构建的光谱参数,主要包括蓝边内最大一阶导数值(Db)、红边内最大一阶导数值(Dr)、黄边内最大一阶导数值(Dy)、绿峰反射率最大值(Rg)、红谷反射率最小值(Rr)、蓝边面积(Sb)、黄边面积(Sy)、红边面积(Sr)、红边面积和蓝边面积的比(Sr/Sb)、红边面积和黄边面积的比(Sr/Sy)、红边面积和蓝边面积归一化值((Sr-Sb)/(Sr+Sb))及红边面积和黄边面积归一化值((Sr-Sy)/(Sr+Sy))等12类特征参数;(2)任意两波段光谱指数,是在各变换光谱350~1 350 nm波段范围内计算任意两个光谱反射率之间的差值(DSI)、比值(RSI)和归一化指数(NDSI);(3)筛选与NNI相关性较好的植被指数,主要包括红边指数1(VOG1)、MERIS 陆地叶绿素指数(MTCI)、改进红边比值植被指数(mSR705)、改进红边归一化植被指数(ND705)、最佳植被指数(VIopt)、修正型三角植被指数(MTVI2)和土壤调节植被指数(SAVI)等7类[22]。
1.5 模型构建
对构建的三类光谱参数与NNI进行皮尔逊相关性分析,利用逐步回归对与NNI呈极显著相关的光谱参数进行敏感性和不存在共线性筛选,筛选出的敏感光谱参数参与NNI建模。本研究的建模方法包括偏最小二乘回归(PLSR)、随机森林(RFR)、支持向量机回归(SVR)和梯度增强回归(GBDT)。
PLSR是多元线性回归分析、典型相关分析和主成分分析集成的建模方法,通过主成分分析对样本数据进行筛选,确定对因变量解释性最强的变量参与建模,克服变量的多重相关性问题[23-24]。RFR是通过自助重采样,从原始的训练样本中有放回地随机采样构建决策树进行分类预测的一种算法,具有很好的抗过拟合能力和抗噪声能力[25-26]。SVR通过使样本实测值与预测值之间的损失函数最小化和靠超平面最远的样本点之间的间隔最大来确定模型[27-28]。GBDT通过样本建立决策树,得到预测值和残差,后面的决策树基于前面决策树进行残差学习,直到样本预测值和实测值的残差为零[29-30]。本研究在SPSS20.0软件中进行偏最小二乘回归,在R软件中实现随机森林算法,在Python软件中进行SVR和GBDT。
1.6 模型精度检验
本研究将三年拔节期、抽穗期、开花期和灌浆期的数据混合,共采集样本数据432个,按照3∶1的比例随机划分为建模集和验证集。模型精度采用决定系数(r2)、均方根误差(RMSE)和相对预测偏差(RPD)检验。r2反映模型拟合能力,RMSE和RPD可以衡量预测值与实测值之间的离散程度和偏差,r2越接近1,RMSE越小,模型预测效果越好,RPD大于2时,模型具有极好的预测能力[31]。
2 结果与分析
2.1 敏感光谱参数筛选
2.1.1 任意两波段光谱参数筛选
利用Matlab软件分析350~1 350 nm波段范围内四种预处理光谱中任意两波段组合的归一化光谱指数(NDSI)、差值光谱指数(DSI)和比值光谱指数(RSI)与NNI的相关性,分别选择与NNI相关性最大的波段组合参与显著性检验,入选波段见表1。拔节期入选波段集中在可见光区域,随着生育时期的变化,入选波段向长波方向偏移,在可见光和近红外区域均有分布。

表1 各生育期任意两波段光谱参数入选波段Table 1 Optimal bands selection in any two-band spectral index for each growth stage
2.1.2 三类光谱参数与氮营养指数的相关性
相关性分析(图1)表明,各生育时期“三边”参数中,拔节期“三边”参数与NNI相关性最好(图1a),红边内最大一阶导数值、红边面积、红谷反射率最小值、红边面积和蓝边面积的比、红边面积和黄边面积的比、红边面积和蓝边面积归一化值、红边面积和黄边面积归一化值与NNI的相关系数分别为0.33、0.27、0.25、0.41、0.32、0.42和0.32,均达到极显著水平(P<0.01)。总体来看,红边位置计算的光谱参数与NNI的相关性较好,拔节期、开花期和灌浆期的红边内最大一阶导数值、红边面积与NNI均相关极显著。
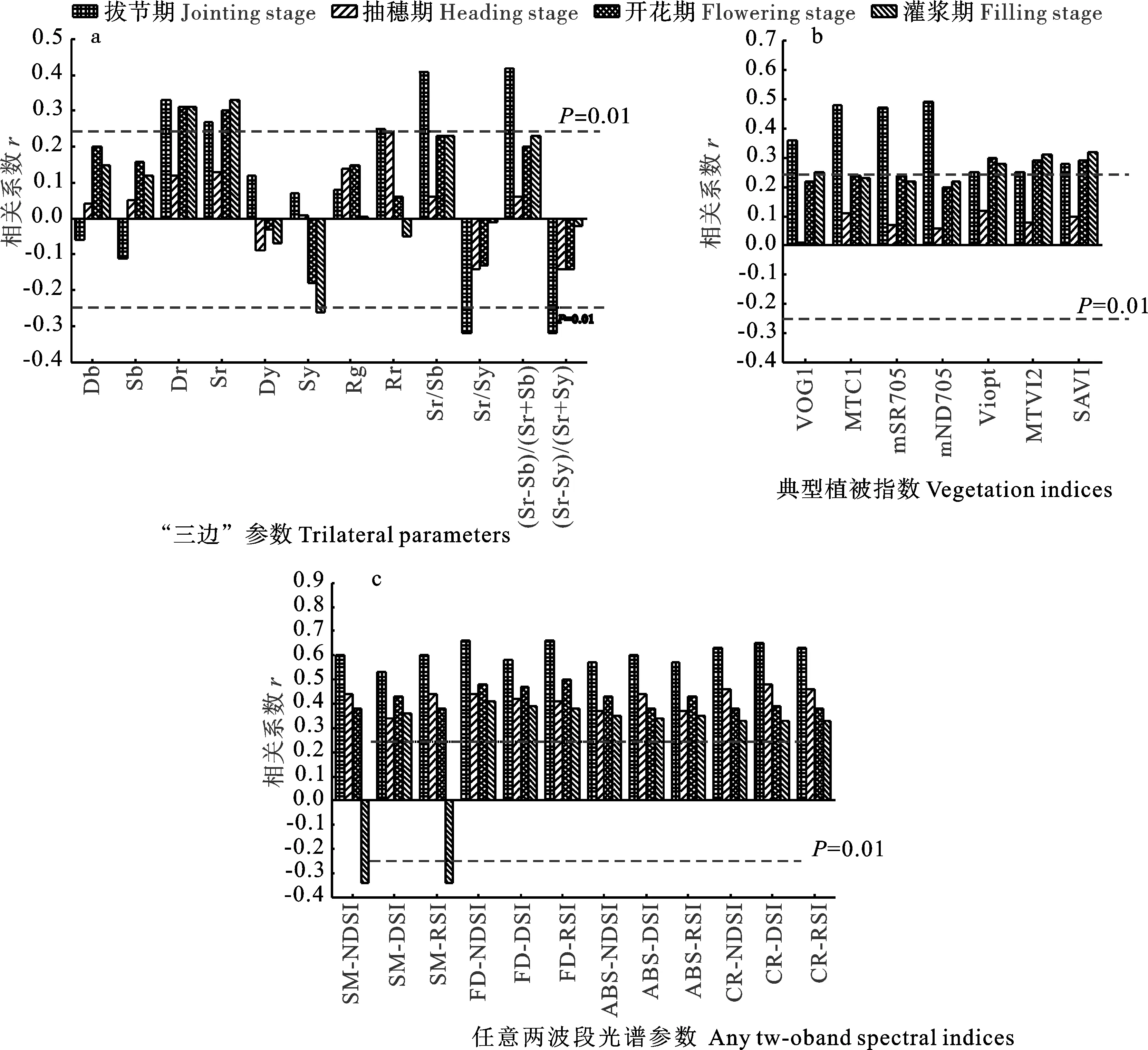
图1 光谱参数与氮营养指数的相关性Fig.1 Correlation between spectral parameters and nitrogen nutrition index (NNI).
在拔节期,典型植被指数与NNI均极显著相关(图1b)。在开花期,VIopt、MTVI2、SAVI与NNI的相关系数分别是0.30、0.29和0.29,均极显著相关。灌浆期的VOG1与NNI也通过了0.01水平的显著性检验。抽穗期各参数与NNI的相关性均未通过0.01水平的显著性检验。
各生育时期的任意两波段光谱指数与NNI的相关性均通过0.01水平的显著性检验(图1c)。其中,拔节期的任意两波段光谱参数与NNI的相关性最佳,相关系数均大于其他时期,其中基于一阶导数光谱的NDSI和RSI与NNI的相关系数最大,均为0.66。
2.1.3 基于逐步回归筛选敏感光谱参数
从各个生育时期与NNI呈极显著相关的光谱参数中,利用逐步回归法剔除多重共线性的光谱参数,筛选出对模型敏感的解释变量(表2)。其中,拔节期敏感光谱为任意两波段光谱参数和“三边”参数,抽穗期、开花期和灌浆期的敏感光谱参数均为任意两波段光谱参数,植被指数三个时期均未入选。

表2 各生育期敏感光谱参数Table 2 Sensitive spectral parameters ateach growth stage
2.2 NNI模型的构建和验证结果
基于各生育时期的敏感光谱参数,分别采用偏最小二乘回归(PLSR)、随机森林算法(RFR)、支持向量机回归(SVR)和梯度增强回归(GBDT)构建冬小麦NNI预测模型。从图2来看,拔节期、抽穗期、开花期和灌浆期基于GBDT构建模型的预测精度均高于其他三个模型,决定系数(r2)分别为0.96、0.92、0.90、0.95,均方根误差(RMSE)分别为0.05、0.05、0.05、0.03,同时基于GBDT验证模型的决定系数(r2)也高于其他三个模型,模型精度相对较高。
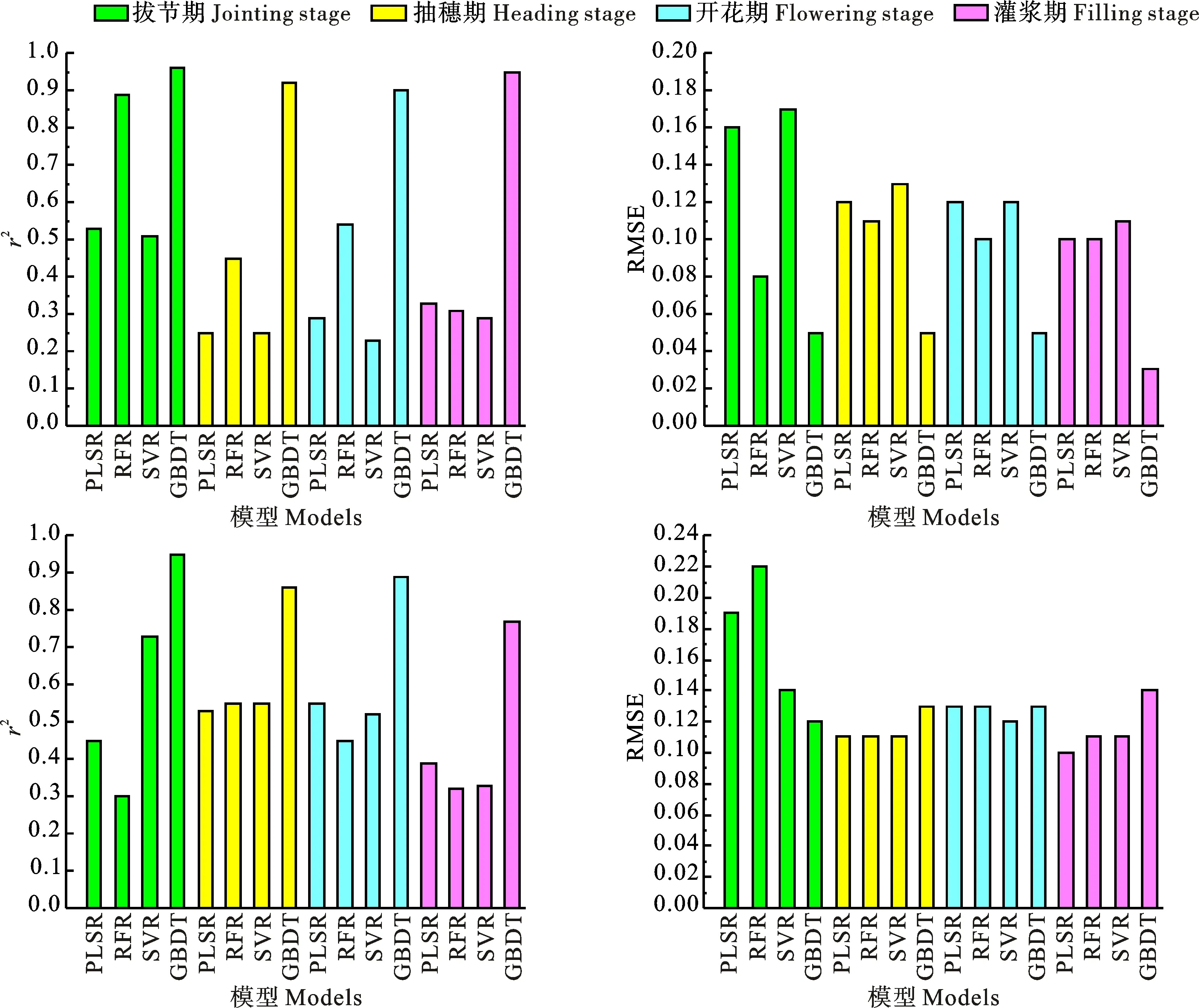
图2 基于PLS、RFR、SVR和GBDT的冬小麦NNI的建模精度
比较四个生育时期,建模集中,拔节期四个模型的决定系数(r2)高于其他生育时期,其中GBDT模型的建模精度最佳,r2和均方根误差(RMSE)分别为0.96和0.05;其次是RFR模型,r2和RMSE分别为0.89和0.05,其他模型的建模精度相对较低。
所有模型中,拔节期GBDT模型的验证精度也最佳,r2和RMSE分别为0.95和0.12;其实测值与预测值斜率为0.87,散点空间分布接近1∶1线(图3)。从相对预测偏差(RPD,实测值和预测值之间标准差和均方根误差之比)(图4)看,拔节期GBDT模型的RPD最高,为2.12;其次为SVM模型,其RPD为1.92。其余模型的RPD均小于1.5。总体来看,各个生育时期GBDT模型精度相对较高,拔节期建立的NNI模型精度优于其他时期,且拔节期基于GBDT的NNI模型具有较好的预测能力。
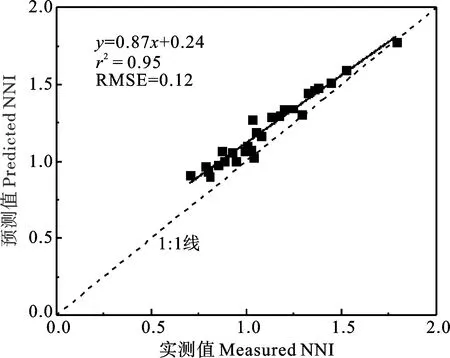
图3 拔节期基于GBDT的NNI预测值与实测值相关性

图4 冬小麦NNI估算模型相对预测偏差对比
3 讨论
快速精准实现作物氮素管理对于提高氮肥利用率、减少土壤和地下水污染至关重要[32-33]。NNI综合植株氮浓度和生物量在诊断氮素营养状况的不同作用,为快速实现作物氮素营养诊断和管理提供支持。本研究中,任意两波段筛选出的比值光谱指数位置为749和763 nm,与王仁红等得到的冬小麦NNI引用比值指数位置相似[7],也表明了红边参数与农学组分之间的密切关系[34]。对原始冠层光谱进行一阶导数、吸光度和连续统去除变换,能够在一定程度降低噪声干扰,增强光谱特征[35]。本研究基于变换光谱的任意两波段光谱参数与NNI的相关性优于“三边”参数和植被指数,其中由拔节期一阶导数光谱组成的归一化、比值光谱指数与NNI相关性最高。
本研究采用偏最小二乘回归、随机森林算法、支持向量机回归和梯度增强回归分别建立冬小麦的NNI模型,其中梯度增强回归模型和随机森林模型均未出现过度拟合现象。梯度增强回归显著提升了NNI的估算精度,这是因为梯度增强回归通过多个决策树构建更强大的模型,不断迭代,决策树深度小[29],预测速度快,参数设置比随机森林算法和支持向量机回归更敏感,模型精度更高。拔节期基于梯度增强回归构建的NNI预测模型决定系数达到0.95,精度优于王仁红等[7]基于线性内插法共边位置对冬小麦NNI的估测(决定系数为0.86,均方根误差为0.08)。不同于刘昌华等[13]的研究,本研究中拔节期基于梯度增强回归的NNI模型取得了最佳验证精度。如果在拔节期能够准确估测冬小麦NNI,这对于科学精准施肥,对于提高冬小麦产量和改善冬小麦品质有着重要的意义[36]。本研究为拔节期冬小麦氮素的评估提供了理论和方法,这一结果还有待更多的数据集进行验证。另外,计算NNI时,临界氮浓度采用了同为研究关中平原地区冬小麦氮素的李正鹏等[21]的临界氮浓度稀释曲线模型,该模型是基于小麦品种小偃22所建,因此未来需要针对不同品种建立更为广适的临界氮浓度模型,以进一步增强NNI高光谱监测的普适性。
4 结论
本研究通过相关性分析法和逐步回归法,分别筛选出各生育时期与冬小麦NNI敏感的解释变量,利用偏最小二乘回归、随机森林算法、支持向量机回归和梯度增强回归分别建立冬小麦NNI模型。从拔节期到灌浆期,任意两波段光谱参数与NNI均极显著相关,相关性明显优于“三边”参数和植被指数,其中拔节期任意两波段光谱参数与NNI的相关性高于其他生育时期,且基于一阶导数光谱的归一化光谱指数和比值光谱指数与NNI的相关系数最大。在各生育时期中,基于梯度增强回归的NNI模型精度高于其他模型,其中拔节期该模型的精度最高,r2、RMSE和RPD分别为0.95、0.12和2.12,说明其具有较好的预测能力。
猜你喜欢
今日农业(2021年6期)2021-11-27 08:05:59
水土保持研究(2018年5期)2018-10-12 05:29:52
中国农业信息(2018年2期)2018-07-28 08:02:10
植物保护(2017年1期)2017-02-13 06:44:34
动物营养学报(2015年10期)2015-12-01 06:45:19
西藏科技(2015年1期)2015-09-26 12:09:29
中学生(2015年4期)2015-08-31 02:53:50
科技创新与应用(2015年28期)2015-05-30 20:03:40
新疆农垦科技(2014年5期)2014-02-28 19:20:00
新疆农垦科技(2014年2期)2014-02-28 19:19:18
