
基于改进YOLOv4的移动机器人障碍物检测*
2023-10-21 08:43:28淡文慧毛鹏军栗俊杰
组合机床与自动化加工技术 2023年10期
淡文慧,毛鹏军,苏 坤,方 骞,栗俊杰
(河南科技大学机电工程学院,洛阳 471003)
0 引言
在“中国制造2025”与“互联网+”战略背景下,移动机器人技术成为智能制造的重要课题。避障是移动机器人面临的最基本问题之一。实时监测障碍物信息可以确保机器人安全工作,避免碰撞事故发生,因此要求移动机器人必须要有一定的障碍物识别和检测能力。
目前,国内外对于移动机器人的避障检测的研究主要是采用视觉传感器、激光测距传感器及雷达传感器等,其中深度相机受磁场或传感器相互间干扰作用更小,相比激光雷达更廉价、更易于部署、适用范围更广,在机器人环境感知方面,目前最接近人类感知的方法是视觉应用[1]。吴亚辉等[2]采用视觉方法进行环境感知并利用人工势场法进行避障决策。李娟等[3]提出了一种以STM32F1处理器为核心的视觉避障控制系统。LI等[4]采用YOLOv3的目标检测方法对障碍物进行实时检测并结合动态窗口法实现避障决策。方东君等[5]提出了一种融合深度相机获取的几何信息的SSD目标分割方法,在障碍物尺寸测量上优势明显,提高了障碍物检测精度。
人工智能(AI)是智能制造的重要组成部分,机器视觉作为实现智能制造的重要技术窗口,在AI应用技术中占比超过40%[6]。在以往的研究中,在卷积神经网络进行图像分类识别方面取得了很好的研究成果。典型的基于回归的目标检测算法有YOLO(you only look once)[7]、SSD(single shot multibox detector)[8]系列等,主要是利用端到端的思想及卷积神经网络回归预测出图像中目标的位置并对目标物体进行分类识别。YOLO算法具有高准确率和高检测速度的优点,通过数据集训练后可以解决障碍物识别的位置和分类两个问题[9]。一些研究者对深度学习算法进行了不同程度的改进,蔡舒平等[10]修改了YOLOv4的主干网络中的残差组件并使用了软性非极大抑制算法,对果园障碍物进行实时检测。刘力等[11]改进了YOLOv4的锚框选择方法并加入了压缩和激励模块,在不增加检测时间的同时提升了检测效果。彭继慎等[12]提出了一种改进的YOLO网络用于无人机避障,缩小了模型体积,大幅提升了预测速度。
上述研究提高了网络的准确率和检测速度,但在移动机器人障碍物检测的应用中,仍存在模型复杂度高、参数量大、难以部署和检测速度较慢的问题。为解决上述问题,使用MobileNetv3代替原主干特征提取网络,同时使用深度可分离卷积块代替加强特征提取网络中的普通卷积块,此外,引入控制距离损失函数代替原网络损失函数。该改进可以有效减小图像处理所需的内存,提高复杂环境下障碍物检测的效率和准确性。
1 YOLOv4网络介绍
YOLOv4算法是从YOLOv3发展而来的,YOLO网络一般可以分为主干特征提取网络、加强特征提取网络和预测网络。首先把图像信息送入主干特征提取网络,这部分网络主要负责图像特征的提取,随着网络层数的增加,提取的特征信息不断丰富。YOLOv4的骨干网络是在YOLOv3的Darknet53上增加5个CSP模块改进为CSPDarknet53,CSPDarknet是由若干CBM和CSPX组成的。CBM模块中的Mish函数避免了由封顶引起的饱和,它的平滑性能让信息更好地传入,提高了神经网络的准确性和泛化性能,防止了梯度消失和梯度爆炸[13]。
加强特征提取网络由空间金字塔池化(SPP)和路径聚合网络(PANet)构成,对从骨干网络中提取的浅层特征进行处理和增强,从而得到有效特征层。SPP模块结构如图1所示,通过多尺度Maxpooling方式得到不同尺度特征图,然后将特征图结合起来得到固定大小的特征图,这种方法增加了卷积核的感受野。PANet是基于特征金字塔网络[14](FPN)和Mask RCNN的创新,FPN特征信息丰富,但卷积层跨度大,存在消耗时间大的问题,而PANet使用下采样连接高层特征,缩短了特征融合路径,有效地解决了该问题,其网络结构如图2所示。

图1 SPP模块

图2 PANet结构
预测网络主要用在最后的检测,对获得的特征进行分类和回归。它在特征图上应用锚框,最终输出包含目标、目标种类和置信度的预测框。PANet将特征图进行拼接,经过卷积运算,获得3个尺度不同的head,利用3个不同尺度的head,可以检测大、中、小3种目标。
2 YOLOv4改进
2.1 网络结构改进
MobileNetv3-Large[15]是一个轻量级神经网络,采用MobileNetV3-Large代替CSPDarkNet-53作为YOLOv4的骨干网络,这种替换可以有效地减少图像处理所需的内存,加快对小目标的检测。MobileNetV3-Large综合了深度可分离卷积和线性瓶颈反向残差结构,并引入轻量级的注意力机制,减少了特征图的计算负担,加快了特征图在网络中的传播速度。
改进的轻量级障碍物检测模型结构如图3所示,括号内的数字代表图像分辨率、通道数、卷积核大小、步长以及是否存在注意力机制,backbone模块接收大小为416×416的图像,然后从backbone模块选择3个有效特征层导入neck模块,通过neck模块加强特征提取,之后prediction模块得到3个特征图,分别为用于小目标检测的52×52特征图、用于中等目标检测的26×26特征图和用于大目标检测的13×13特征图。最后,对输入图像进行预测,输出带有障碍物标签的图像。

图3 障碍物检测模型结构
深度可分离卷积将标准卷积拆分为一次纵向卷积和多次逐点卷积,降低了计算量,但输出变化不大。为进一步减少训练参数,提高检测速度,将加强特征提取网络中的所有普通卷积修改为深度可分离卷积,并在特征输出后用1×1的卷积进行特征平滑,提高特征提取能力。
2.2 损失函数改进
IoU只考虑重叠面积的计算,存在不同预测框有相同的结果的情况[16]。在IoU的基础上,GIoU通过增大检测框的尺寸来实现与真实框的重叠,然后利用IoU loss来最大化重叠区域,但这种方式有收敛速度慢和回归不准确的缺点。DIoU综合考虑了目标与锚的重叠度、距离和尺度等因素,使得预测框回归更加稳定,解决了IoU和GIoU等训练过程中的散射问题。但当预测框中心点在同一位置时,无法区分那个预测框与真实框重叠度更高,同时存在计算过程会比较耗时情况。
为解决上述问题,引入控制距离IoU(control distance IoU,CDIoU)和LCDIoU,计算公式如式(1)~式(5)所示。如图4和图5所示,CDIoU没有直接度量预测框与真实框质心距离和形状的相似性,但最终计算结果却反映了两者之间差异程度的度量,CDIoU值越高,差异程度越低,相似度越高,反向传播过程中,模型更加倾向于将预测框的4个顶点拉向真实框的位置,使之重合度最高。
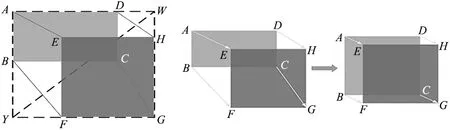
图4 CDIoU损失 图5 损失函数变化过程
(1)
CDIoU=IoU+λ(1-diou)
(2)
LIoUs=1-IoU
(3)
LCDIoU=LIoUs+diou
(4)
LIoUs=1-IoU
(5)
3 实验结果及分析
3.1 数据集与实验介绍
(1)数据集。训练数据集由自制数据集和公开数据集结合制作,从VOC数据集和ImageNet数据集中选取5500张包含工厂内常见移动障碍物的照片,以及网络中下载500张工厂内部照片,合并作为障碍物数据集。标注后的标签文件格式为xml文件,最终获得6000张标注后的数据集,按9:1比列划分为训练集和测试集,置信阈值取0.5,该目标检测网络共训练500个epoch、批处理尺寸大小为8、学习率0.001。采用随机梯度下降法(SGD)进行参数优化。
训练前将数据集中的图片尺寸统一处理为416×416的大小,数据增强采用Mosaic数据增强方法,4张照片为1组,每次对1组照片分别进行随机缩小、翻转、变换等,然后拼接成为一张新的图片并生成对应的xml标签作为训练数据。Mosaic数据增强极大地丰富了被检测目标的背景,在数据集数量有限的情况下仍能得到较好的效果。同时引入学习率余弦退火算法和分阶段迁移学习,增强模型收敛速度。
(2)实验平台。模型训练硬件平台CPU为Inter i5 11400H @ 2.7 GHz,GPU为GeForce RTX 3050,4 G显存,16 G运行内存,运行系统为Windows10专业版,CUDA版本为11.2,深度学习框架为Tensorflow。
采用如图6所示的四轮差速驱动移动机器人实验平台,该平台由机器人底盘、视觉传感器、电源等模块组成。视觉传感器采用Kinect深度相机,平台搭载Ubuntu18.04LTS操作系统,软件部分使用ROS(robot operating system)的melodic版本。

图6 实验平台
3.2 障碍物检测实验分析
为了验证所提算法应用于障碍物检测的有效性,设计了4组实验进行验证。实验一是使用通过K-means算法聚类生成先验框的原始YOLOv4识别网络。实验二是使用CDIoU提高对障碍物区域的检测能力。实验三是利用MobileNetv3网络代替CSPDarkNet53作为主干特征提取网路。实验四是综合实验二的CDIoU方法和实验三的mobilenet网络进行实验。
图7给出了改进模型的损失函数收敛曲线。训练开始时损失函数的最大值为76,损失值在前100步迅速下降,随后速度逐渐减慢,经过200个epoch,该值接近于1,表明已经实现收敛。横坐标为训练批次数,纵坐标为均方误差。

图7 改进的YOLOv4损失函数收敛曲线
评估相同的数据集训练下的模型表现如表1所示,综合比较模型改进前后的检测性能。
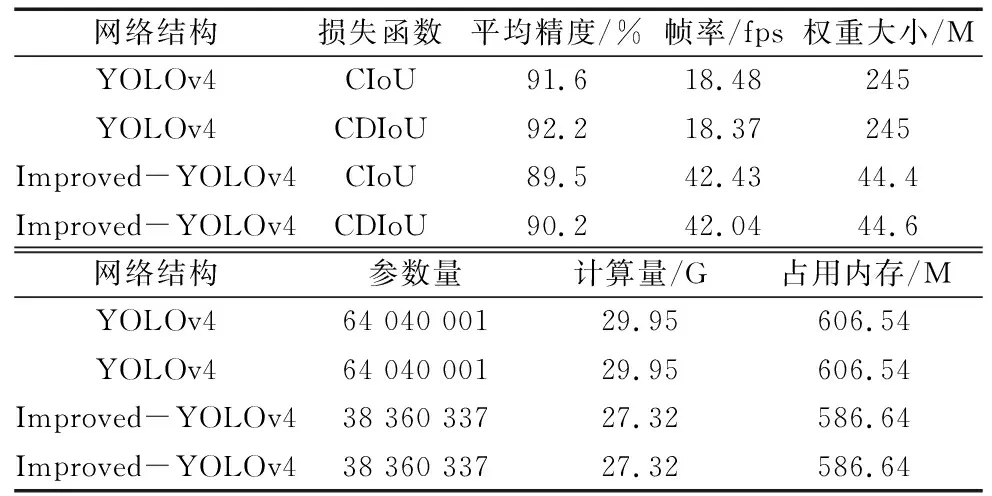
表1 不同模型检测结果比较
从表1可以看出,改进网络结构后,检测帧率相比于原始YOLOv4的18.48 fps提高了23.95;在原始网络结构的基础上把损失函数改为控制距离损失函数,Map提升了0.6%;在改进网络结构的基础上,改进损失函数,检测精度虽然降低了1.5%,但帧率提高到了42.04 fps,检测速度得到了大幅度提升。其中,改变网络结构对检测速度的提升更大,这是由于改进后的网络结构得到了精简,参数减少了40%,模型计算量减少到了27.32 G,模型内存占用量减少了20 M,从而影响了检测速度。此外,训练后得到的权重大小也由245 M减小到了44.6 M。总体而言,对比原始YOLOv4模型,改进模型不影响检测精度的情况下检测速度得到了大幅度提升。
图8为4种实验模型的障碍物分类的P-R曲线,1号线为原始的YOLOv4模型障碍物分类的P-R曲线,随着Recall值的增长,Precision值不断降低同时保持平稳;2号线为将损失函数替换为CDIoU的模型的P-R曲线,随着Recall值的增长,Precision稳定地保持在很高的数值,说明模型对障碍物识别具有高的学习水平;3号线为主干网络是Mobilenetv3的模型P-R曲线,Precision值在Recall为0.4时开始降低,在0.8开始快速降低,1.0时降到最低值;4号线为网络结构和损失函数同时改进的模型分类P-R曲线,随着Recall值的增长,Precision值仍保持较高的水平。相较于其他3种模型的P-R曲线,改进后的YOLOv4模型的P-R曲线下降较快同时保持平稳。
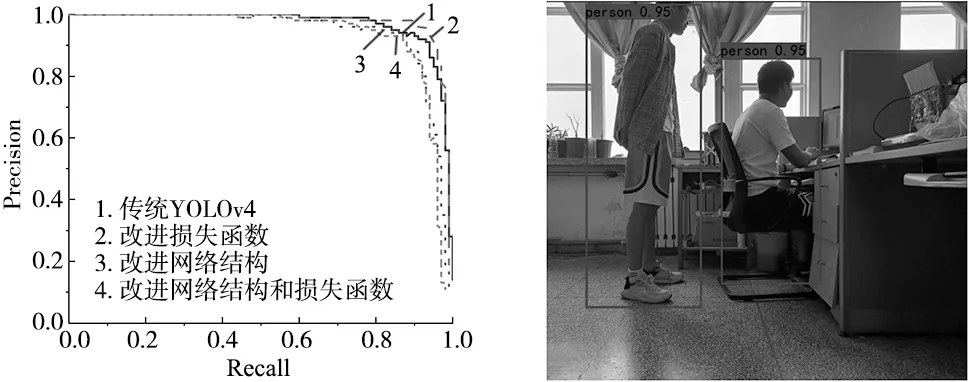
图8 P-R曲线 图9 测试结果
模型训练完成后,运行模型的预测程序,得到如图9所示的识别结果。
从4种算法的实验结果对比可以看出,几种方法精度相差不大,但是在检测速度方面,改进后的YOLOv4算法参数量大大减少,速度得到明显提升,改进的YOLOv4模型具有较强的学习能力,经过训练能够快速检测到障碍物。
3.3 障碍物定位实验分析
深度相机的深度距离可达4.5 m,本次实验对深度相机所能检测到的障碍物进行采样测量。采用移动机器人定点放置,使用Kinect获取图像的距离信息,再逐一测量障碍物与相机之间的实际距离,再与程序测得的5次数值均值作为实测数据,计算实验数据的相对误差,实验结果如表2所示。

表2 定位精度实验对比
4 结论
为了满足移动机器人避障识别的实时性要求,对网络结构进行了轻量化改进,使用MobileNetv3网络作为主干特征提取网络,减小了模型体积;然后使用深度可分离卷积替换加强特征提取网络中的一般卷积,减少了模型的参数量;为了满足移动机器人避障识别的准确性要求,使用CDIoU替换原有损失函数,提高检测精度。实验结果表明,改进的YOLOv4模型在多种障碍物场景中均能实时有效地检测,在实时性方面具有较好的性能,在牺牲了1.5%精度的情况下,将FPS提升到了42.04,说明算法适用于移动机器人的实时障碍物检测。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02 01:59:12
动漫界·幼教365(中班)(2020年3期)2020-04-20 11:03:27
铁道通信信号(2020年9期)2020-02-06 09:15:54
制造技术与机床(2017年3期)2017-06-23 08:11:21
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28 12:21:31
中国海洋大学学报(自然科学版)(2014年7期)2014-02-28 12:21:19
