
基于神经网络的医疗命名实体抽取研究
2023-10-19 11:00米仁沙艾尼
数字通信世界 2023年9期
米仁沙·艾尼
(喀什大学计算机科学与技术学院,新疆 喀什 844000)
1 基于多特征的医疗命名实体抽取
1.1 基于CRF的命名实体抽取
在对数据进行处理时,首先要将其转换为计算机可以识别的格式。由于不同的数据库中存在大量相同或相似的数据,所以需要使用一定的方法来消除这些重复和冗余的部分,从而使得数据更加简洁、规范。目前最常见的方式是利用命名实体识别技术来达到这一目的。命名实体识别就是通过分析语料库中的词与词之间的联系,找出其中所隐含的语义信息,并且能够准确地描述出该词语的意思。因此,本文选择命名实体识别技术作为主要的研究对象,以便获得更为精准的结果。命名实体识别主要包括以下几个步骤:第一步,确定一个领域;第二步,收集相关资料;第三步,构建知识库;第四步,建立模型。在进行命名实体识别时,首先要对语料库中所有的句子进行分句处理,然后再将其转化为相应的结构化形式,最后借助计算机程序自动完成这项工作。
1.2 基于BiLSTM-CRF的命名实体抽取
本文将从医疗文本中获取到的大量信息进行分析、处理和总结后,提取出与医疗相关的命名实体。在对这些信息进行分类时,需要先确定哪些是属于命名实体范畴内的内容,然后再去寻找与其对应的其他类别的信息。因此,首先要明确什么是命名实体以及它们之间存在怎样的关系,为后续工作做铺垫。本文通过引入BIESTRACK(Bidirectional information extract ion from Embeddings,从嵌入中提取双向信息)模型来解决这一问题。该模型主要包括两个部分:第一个部分就是对输入文本进行预处理;第二个部分则是利用BiLSTM(双向长短期记忆单元)模型对文本中的命名实体进行识别并输出其名称。在此基础上,我们可以得到一个关于医疗领域的命名实体集合。其中,每行代表一个实体,每列代表一个实体与另一个实体之间的关系。
1.3 基于CRF-SVM的命名实体抽取
在对医疗领域进行研究时,需要从大量的文本中提取出相关的知识。因此,本文将利用机器学习技术来分析这些文本中所包含的信息和规律,并从中获取有用的知识。为了更好地实现这一目标,我们首先要构建一个用于识别命名实体的分类器CRF-SVM。由于不同类型的命名实体之间在一定程度上存在联系,所以可以使用一种特殊的方法来表示它们之间的关系。
1.4 基于CRF+Word2Vec的命名实体抽取
在对医疗领域进行研究时发现,不同的实体之间可能存在着某种关联。为了能够更加全面地描述这种关系,本文引入词向量来表示实体与实体之间的语义关系,并将其作为模型中的一个重要参数。因此,本文提出一种基于CRF和Word2Vec的命名实体识别方法(CRF+Word2Vec),用以实现对医疗语料库中文本的自动分类任务。首先利用SkipGram算法从训练集中获取初始化的词嵌入矩阵;然后使用TextCNN提取出句子中每个单词对应的词向量;最后通过计算得到每条序列的概率分布函数P(x|θ),其中θ是指序列中所有词语出现的频率,即该序列所包含的实体数量。
1.5 基于CRF-Bert的命名实体抽取
在医疗文本中,有很多与疾病相关的名词和动词。这些词可以作为一个单独的实体来处理。因此,我们将这种方法称为“命名实体”(Named Entity)识别。本文使用了一种新的技术CRF-Bert来提取医疗文本中的实体名称,即命名实体识别(Named Entity Recognition)。该方法首先对句子进行分片,然后通过分析每个片段之间的上下文关系,获得每个单词的含义以及它们之间的相互关系,最后利用已经训练好的模型生成相应的规则,以便能够自动地识别出文本中的实体及其属性。
2 基于神经网络的医疗命名实体抽取
2.1 数据集
本文使用的是由复旦大学开发的中文医疗语料库。该语料库包含了大量与医学相关的文本信息和结构化知识,并且已经被广泛应用在各种领域中,如自然语言处理、机器学习等方面[1]。因此,我们可以利用这些丰富的资源来构建一个适合神经网络训练的医疗命名实体抽取的数据集。通过对现有文献进行分析发现,目前还没有学者提出过将关系作为输入向量的方法,如果能够把这种关系引入到命名实体识别任务当中去,就会使得整个系统更加完善。
2.2 数据预处理
在对医疗领域进行研究时,首先要做的就是获取相关的数据。本文所使用到的数据是由“医疗”“命名实体识别”和“关系”组成的三元组形式,其中“医疗”指的是与该任务有关的所有信息;而“命名实体识别”则表示了该任务中需要用到的各种方法;最后一个“关系”则代表着这些信息之间存在的联系。因此,我们将这三个元素作为输入向量,并通过训练来构建相应的模型,从而来完成整个任务,具体介绍如下。
(1)医疗数据集。本文所用到的数据来源于中国知网(CNKI)数据库,从中选取其中部分文献作为样本库。同时,还要保证每个样本都包含一定量的实体名称以及对应的属性词,这样才能够更好地满足实验要求。
(2)Doc2Vec模型的搭建。在进行模型搭建时,首先要对原始语料进行去噪和归一化操作,然后再利用TF-IDF算法计算出各个词语的权重值。由于篇幅有限,具体实现过程不再赘述。
(3)关系提取。实体与实体之间是有关联的,所以需要把这些关系提取出来,以便后面使用。
(4)命名实体识别。将上一步中得到的结果输入到Softmax分类器中进行训练学习。
(5)模型评价。通过准确率、召回率等指标对模型效果进行分析评估。
2.3 基于CRF的命名实体识别
在对文本进行处理时,需要将其转换为计算机能够理解和处理的形式。而这种转化过程就是命名实体识别(NER)。目前已经有很多关于命名实体识别的方法,但是这些方法都存在一定的局限性,因此本文采用了一种新的方法——CRF(条件随机场)来实现命名实体的识别。
2.4 基于CNN的命名实体识别
在对医疗领域中的命名实体进行分析后发现,这些实体之间存在着各种各样复杂的关系。为了能够更好地利用这些信息来提高医疗领域中文本信息的处理效率和准确率,本文采用一种新的命名实体识别算法——CRF(条件随机场)。该方法是由Liu等人提出并且已经被广泛应用到各个领域。它主要通过建立一个包含所有可能出现的命名实体以及其上下位词、属性特征等相关数据的语料库,然后使用神经网络模型对语料库中的实体与实体之间的关系进行学习训练,最后得到最优化的结果[2]。这个过程可以看作是一个不断优化的过程,也就是说随着实验次数的增加,模型会逐渐接近真实情况,从而达到最理想的效果。因此,本文选择使用CRF模型来完成医疗领域的命名实体识别任务。具体步骤如下:首先将收集到的文本信息输入到构建好的语料库中;接着利用BiLSTM层和双向GRU层分别提取出每个句子中的实体及其上下位词、属性特征等信息;再用CRF模型对这些信息进行处理,最终输出命名实体识别的结果。
3 实验结果与分析
3.1 数据集介绍
本文使用的是由复旦大学开发的中文命名实体识别(Chinese Named Entity Recognition)数据集。该数据集包括了20万条实体对以及对应的关系和实例。其中有5%左右的实体没有被标注出来,因此在训练时会将这些实体剔除掉。为了方便起见,我们只保留了80%的实体作为实验对象进行研究。结果显示,不同类型的实体其命名方式存在较大差异。例如,“人名”“地名”等都可以直接用汉字表示;而“机构名”则需要先转化成英文再翻译过来。此外,还有一些实体虽然名称相同但实际上却并不属于同一个类别。所以,如仅使用一个词去代表所有的实体显然是不合理的,必须要结合上下文才能够更好地理解它们之间的区别。本文采用的数据集中包含了26万条语料(每种类型的实体各选取一万),并且已经按照一定规则对语料中的实体及其关系进行标记。在本次实验中,我们将使用其中的50%作为训练样本来构建模型,剩余的50%用来验证模型的效果。由于医疗领域的命名实体数量较多,因此选择合适的方法显得尤为重要。目前,国内外学者针对这一问题提出了许多不同的解决方案,如:CRF、LSTM等。
为验证所构建模型的效果,将其与传统方法进行比较,并采用准确率(Accuracy)、召回率(Recall)以及F值作为主要评价指标来衡量不同模型在医疗领域中命名实体识别任务上的性能。其中准确率为正确识别出的实体数量占总数的比例;召回率为正确识别出的实体数量占所有被预测成实体的数量之比;F值是指精确度和召回率两者加权调和平均值,即:F值越大说明模型越好。相比于其他两种方法而言,BiLSTM_CRF模型具有最高的准确性,同时也能够达到较高的召回率及F值,因此该模型更适用于医疗领域的命名实体识别任务。
3.2 实验环境
在本次实验中,使用了Python语言、TensorFlow框架以及Keras深度学习库。其中,Python是一种通用型计算机程序设计语言;TensorFlow是一个开源机器学习框架,它可以让开发人员方便快捷地构建和训练自己的应用程序,而且其提供的API非常丰富,能够满足各种各样的需求;Keras是一个用C++实现的深度学习工具包,具有很好的扩展性,同时也支持多种编程范式,本文采用Pyhton作为后端平台进行模型搭建,并将模型部署到Numpy计算平台上运行。此外,还需要对数据集进行预处理操作以便于后续的实验工作。首先,要把文本转换成向量形式存储起来,然后再通过分词器对文本进行分句,最后得到相应的标签序列。在这里我们使用了jieba分词组件,这是由百度公司推出的一款自然语言处理软件,该系统不仅功能强大、界面友好,而且速度快,占用内存少。它可以自动识别句子中的单词和短语等信息,并按照一定规则生成对应的标签序列。其次,将训练集中的所有样本都输入到已经构建成功的神经网络结构中去,这样就完成了整个命名实体抽取任务。为了验证本文提出方法的有效性,采用准确率(Accuracy)、召回率(Recall)2个指标来衡量模型性能。其中,TP指被正确预测为实体的数量;FP表示被错误预测为实体的数量;FN则是未出现过的实体。最后,对实验结果进行可视化展示。
3.3 实验结果
在本次实验中,使用了2个不同的数据集进行测试。一个是来自NIST Web of Knowledge数据库中的医疗文本数据集(Dataset);另一个是来自CMU Penn Biomedical Laboratory的医学文献数据集(Documents)。其中,前者包含10万条记录,后者包含50万条记录。为了验证模型的有效性,将这两个数据集中的实体分别作为训练和预测对象。由于本文所采用的模型是一种通用型的命名实体识别方法,所以对于每个数据集来说,都需要单独构建相应的模型来完成任务[3]。因此,针对每一个数据集,我们首先通过人工标注的方式获得实体名称,并按照一定的规则建立起该实体与其他实体之间的关系,然后再利用这些关系生成对应的语料库文件。最后,利用上述模型进行实验,得到最终的评价指标。
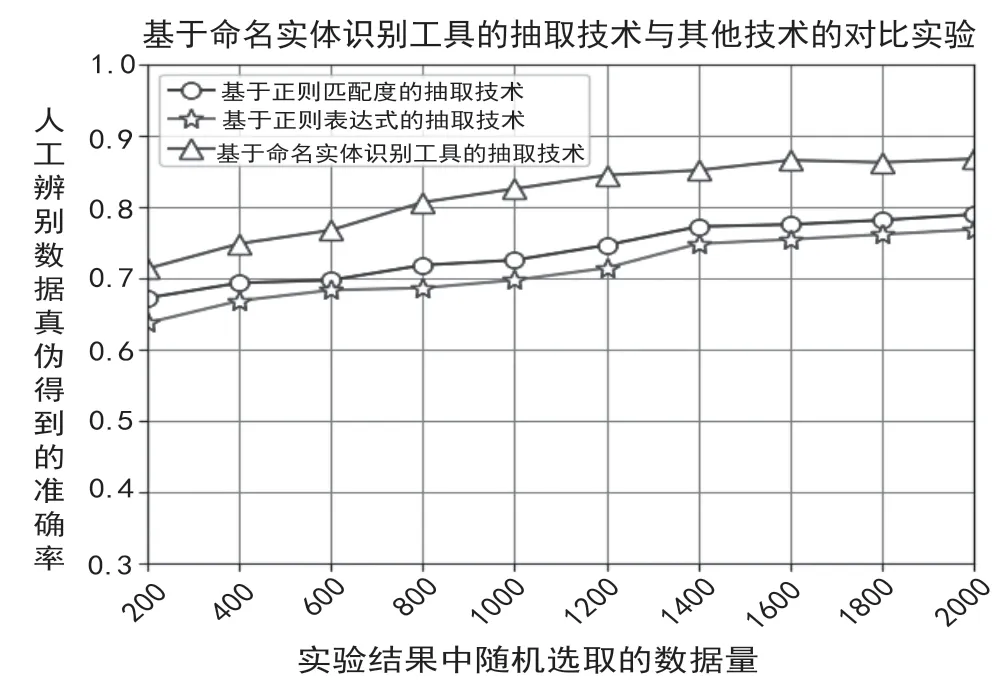
图1 基于命名实体识别工具的抽取技术与其他技术的对比实验图
4 结束语
综上所述,本文设计了一种基于BiLSTM编码解码器结构的命名实体关系抽取模型,并通过实验证明其具有较好的性能。最后,对未来相关工作做出了展望:①进一步完善命名实体识别模型,使得模型更加符合实际应用场景,从而提升模型的实用价值。②将更多注意力放在命名实体关系抽取方面,以期为后续研究提供参考依据。■
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
天津外国语大学学报(2020年1期)2020-03-25
中国外汇(2019年18期)2019-11-25
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
语言与翻译(2015年4期)2015-07-18
中国科技术语(2012年5期)2012-03-20
