
基于时域卷积网络的中文句子级唇语识别算法
2023-10-18 14:58:04刘培培贾静平
计算机应用研究 2023年9期
刘培培 贾静平


摘 要:针对现有中文句子级唇语识别技术存在的视觉歧义、特征提取不充分导致识别准确率偏低的问题,提出了一种基于时域卷积网络,采用三维时空卷积的中文句子级唇语识别算法——3DT-CHLipNet(Chinese LipNet based on 3DCNN,TCN)。首先,针对特征提取不充分的问题,所提出算法采用了比长短期记忆网络(LSTM)感受野更大的时域卷积网络(temporal convolutional network,TCN)来提取长时依赖信息;其次,针对中文唇语识别中存在的“同型异义”视觉歧义问题,将自注意力机制应用于中文句子级唇语识别,以更好地捕获上下文信息,提升了句子预测准确率;最后,在数据预处理方面引入了时间掩蔽数据增强策略,进一步降低了算法模型的错误率。在最大的开源汉语普通话句子级数据集CMLR上的实验测试表明,与现有中文句子级唇语识别代表性算法相比,所提出算法的识别准确率提高了2.17%至23.99%。
关键词:中文唇语识别; 深度学习; 时域卷积网络; 注意力机制
中图分类号:TP391.4 文献标志码:A
文章编号:1001-3695(2023)09-005-0000-00
doi:10.19734/j.issn.1001-3695.2023.02.0051
Lip-reading algorithm for Chinese sentences based on
temporal convolutional network
Liu Peipei, Jia Jingping
(School of Control & Computer Engineering, North China Electric Power University, Beijing 102206, China)
Abstract:Existing lip-reading algorithms for Chinese sentences are inadequate at feature extraction and visual ambiguity resolution, which leads to low accuracy. Aiming at this problem, this paper proposed a lip-reading algorithm for Chinese sentences based on temporal convolutional network and 3D convolutional neural network(3DT-CHLipNet) . Firstly, it used a temporal convolutional network to extract long-term features from lip dynamics sequences, which has a much larger receptive field than the long short term memory network. Secondly, in order to minimize the visual ambiguity in Chinese lipreading, it adopted a Transformer model with the self-attention mechanism to capture the context information and improve the accuracy of sentence prediction. Finally, it introduced a temporal masking data augmentation strategy in the data preprocessing to further reduce the error rate of the algorithm. Comparison experiments on CMLR, the largest open-source sequence-to-sequence Chinese mandarin lip reading dataset, show that the improvement in accuracy over representative lip reading algorithms for Chinese sentences ranges from 2.17% to 23.99%.
Key words:Chinese lip recognition; deep learning; temporal convolutional network; attention mechanism
0 引言
唇語识别(lip recognition),也称为视觉语音识别(visual speech recognition),唇读(lip reading),其目的是通过分析说话者唇部图片序列运动信息来推测其所说内容。这项研究涉及到图像分类、语音识别和自然语言处理等多个领域,在辅助语音识别[1]、人脸安全性身份检测[2]、辅助听觉障碍学生教育[3]等方面有着广阔的应用空间。
近几年来,深度学习在计算机视觉和自然语言处理等领域取得的显著成果,也促进了应用神经网络来解决唇语识别的研究,唇语识别方法已经从基于隐马尔可夫模型(HMM)的人工提取特征[4~6]转变为端到端架构的深度学习方式[7,8],基于深度学习的框架方法已经逐渐取代传统方法,成为唇语识别的主流方法。然而,在没有语境的情况下,唇读仍然是一项极具挑战的任务,大多数唇读动作除了嘴唇运动之外,还有潜在的舌头、牙齿和声带等口腔内部变化,在没有上下文的情况下很难消除视觉歧义;而且,相对于单词唇读,句子级的唇语识别对时间连续性的依赖更强,在进行特征提取时,仅提取低维唇动特征不足以提升句子级别的识别准确率。
目前,唇语识别研究已经在英语单词和句子级层面取得了一定的成果。例如:英语单词方面,残差网络(residual networks)和双向长短时记忆网络(bidirectional long short memory neural network,Bi-LSTM)的组合结构[9],在LRW数据集[10]上实现了83.0%的准确率;稠密连接时域卷积网络(densely connected temporal convolutional network,DC-TCN)[11]在孤立词LRW数据集上实现了88.36%的准确率;英文句子方面,Assael等人[12]提出了第一个同时学习时空视觉特征和序列模型的端到端句子级唇读模型LipNet,其唇读准确率超过了专业唇读者;Chung等人[10]提出了“看、听、听、拼”网络模型(WLAS),利用了一种新颖的双重注意机制,引入了双模态输入,证明了在有音频的情况下,视觉信息有助于提高语音识别性能,在所收集的LRS[13]句子级数据集上的性能大大超过以往在标准唇读基准数据集上的工作;Ma等人[14]提出的一个双模态视听语音识别模型Conformers,可以以端到端方式训练,将特征提取阶段与连接时序分类(connectionist temporal classification,CTC)后端结合起来,共同训练模型,这进一步提升了算法的识别性能。
然而,对汉语进行的唇读研究还很少[15],相较于英文唇读研究,中文数据集历历可数[16]。比较有代表性的中文唇语识别研究有Zhao等人[17]于2019年提出的综合拼音、声调和字符预测的级联序列—序列模型CSSMCM,该模型在其收集发布的汉语普通话句子数据集CMLR[17]上的字符错误率为32.48%;中文句子级唇语识别模型LipCh-Net[18]在其自建数据集CCTVDS上取得了45.7%的句子准确率和58.51%的拼音序列准确率,并且该模型针对汉语发音特点,将唇语识别过程分为图片—拼音(P2P)、拼音—汉字序列(P2CC)两个子过程的研究方法得到了广泛认可,文献[19]所提的视觉拼音模型CHSLR-VP也是在ChLipNet两段式模型上作出的进一步改进。
以上工作都是通过中文发音的“拼音”中转媒介来规避视觉表达上的歧义性,并且大多是利用双向长短时记忆网络(Bi-LSTM)或双向门控循环单元(Bi-GRU)循环卷积来进行序列建模。但是Bi-LSTM和Bi-GRU网络的门控机制并不能记忆过去的全部信息,其遗忘门存在信息泄露问题,且循环卷积RNN进行序列建模时是串行计算、训练时内存消耗大,存在梯度消失问题,这导致在通过提取连续时间特征来提高拼音识别准确率和利用上下文语意来改善视觉歧义两方面仍有所不足。
为了解决以上问题,本文提出了基于时域卷积的中文句子级唇语识别研究方法,设计了3DT-CHLipNet(Chinese LipNet based on 3DCNN, TCN)模型,充分考慮了中文句子唇语识别的多样性和复杂性。在把中文句子唇语识别分为拼音序列识别和汉字序列识别两步骤的基础上,在第一步提取唇部运动特征后,首次提出引入时域卷积网络(TCN),与自注意力(self attention)机制相结合以充分利用上下文语意信息和时间连续性特征,提高拼音识别准确率,同时避免RNN带来的“梯度消失”问题;在第二步中,将在机器翻译领域取得良好效果的完全基于自注意机制的Transformer模型应用于拼音序列到汉字序列的识别,增强关键帧的语义表示,更好地捕获拼音序列的上下文信息,改善视觉歧义模糊性,提高汉字序列识别准确率。并且在数据预处理阶段应用时间掩蔽策略,去除冗余帧,进行数据增强,进一步降低了拼音预测阶段的错误率。实验结果表明,本文模型可以有效提取连续长时间步的特征信息,减少中文唇读的视觉歧义模糊性,提升中文句子识别准确率。
本文的主要贡献如下:
a)首次提出在中文句子级唇语识别的拼音序列识别步骤中,引入时域卷积网络,以提取更长时间步长的时序特征,与现有同类算法相比,本文算法在拼音序列识别步骤中的拼音错误率降低了0.05%至17.02%;
b)进一步提出了使用自注意力机制来捕获上下文信息,以消除视觉歧义,将拼音错误率降低了7.09%。同时,在数据预处理阶段,采用了时间掩蔽的数据增强措施,进一步提升了识别准确率;
c)在公开数据集上,通过对比实验验证了所提出算法,在汉字序列(中文句子)的识别准确率方面取得了比参与对比的算法更高的表现,字符错误率降低了2.71%至23.99%。
1 中文句子级唇语识别算法3DT-CHLipNet
目前中文唇语识别任务中存在的难题主要有以下三点:
a)现有数据集中的大部分视频片段,在开头和结尾部分有顿点,不含有效唇部运动,而现有识别方法是对视频帧中所有信息进行无差别学习,导致网络学到部分无效特征;
b)受不同说话者语速的影响、采集设备和环境的影响,视频帧率会有所不同,现有网络模型难以泛化由此带来的对识别结果的影响,因此网络需要捕获更长时间的信息特征来缓解外界不定因素所造成的不良结果;
c)中文在发音时,会出现不同单词对应同一口型的视觉歧义问题,以及相同单词由于语境不同而含义不同的情况,这要求网络具有能捕获唇部细微变化的能力,以及对上下文语义特征提取的能力。
本文充分考虑了中文句子唇语识别的多样性和复杂性,提出了基于TCN和Transformer的端到端模型3DT-CHLipNet(Chinese LipNet based on 3DCNN,TCN and Transformer),旨在解决中文唇语识别现存的特征提取不充分和视觉歧义问题,提高中文句子级唇语识别准确率。具体解决方案如下:
a)在数据预处理阶段,引入时间掩蔽增强策略,减少了部分冗余信息,尽可能保证后续模型提取到的是有意义的特征。
b)在特征提取和拼音序列预测阶段,本文把需要提取的特征分成三部分(视觉空间特征、连续时间特征、上下文语意特征),利用模型中不同的网络组成部分有针对性地提取不同的信息特征,以充分实现有效信息的提取。对于空间和时间维度的特征,构建了一个3DCNN+2DCNN+TCN的特征提取网络,其中2DCNN实现单帧图像的视觉特征提取,3DNN实现多帧连续图像的时间维度信息提取,TCN实现词间隔细微的连续时间特征提取。与其他处理时序问题的RNN相比,TCN感受野更大,可以抓取长时依赖,学习到更多信息,同时,在TCN网络之前还加入了注意力机制,可以为关键帧分配更多权重,使网络对重点信息的学习有所侧重,增强整体网络对连续唇部图片序列运动的特征提取效果。
c)中文同音字特点无可避免,为解决由此导致的视觉歧义问题,本文通过提高拼音到汉语识别模型的上下文语意理解能力来改善该问题。将基于多头自注意力机制的Transformer模型迁移到中文唇语识别研究中,Transformer编解码框架能够学习相关信息在不同的子空间表示,提高提取全局上下文特征能力,以进一步提升汉语句子的识别准确率。另外,在多音字的拼音到汉字的预测过程中,通过选取合适的解码策略(波束搜索),找到合适的波束宽度参数,辅助模型预测出更符合中文语义的句子序列,也在一定程度上缓解了视觉歧义引起的误差。
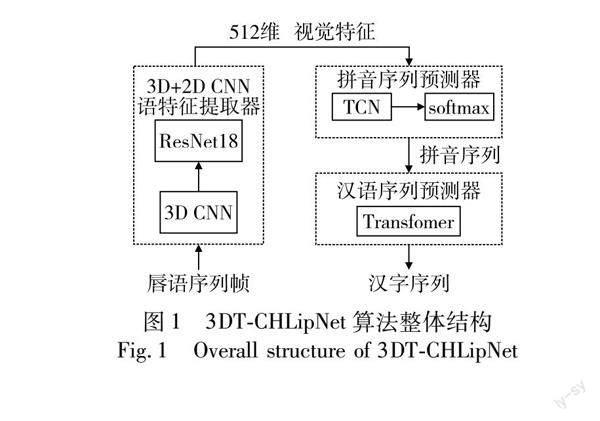
3DT-CHLipNet模型的基础框架包含三个部分:(a)数据预处理部分:从视频样本抽帧,应用时间掩蔽策略,去除冗余帧信息,对序列帧中的人脸区域进行裁剪,定位唇部区域;(b)拼音序列识别部分:将预处理后的唇部序列帧输入3D CNN和ResNet18网络,提取唇部运动特征和时间特征,得到视觉特征矩阵,通过self-attention层和TCN将视觉矩阵映射为拼音序列。这一部分通过拼音序列预测子网络实现;(c)汉字序列识别部分:将拼音序列输入Transformer模型进行处理,得到汉字序列构成的句子。这一部分通过汉字序列预测子网络实现。拼音序列预测和汉字序列预测两个子网络的网络结构如图1所示。
1.1 时间掩蔽策略
唇语样本以视频形式表示,需要对其进行预处理得到唇部帧序列图片,方可输入进拼音预测网络。先对视频进行抽帧,然后对视频帧进行人脸定位、唇部区域定位和唇部裁剪操作。最后,为了避免后续特征提取网络对所有帧进行无差别学习,学到部分无效特征,对关键信息产生干扰,本文采用时间掩蔽增强策略,去掉视频开头和结尾中不含唇部有效运动的某些唇部帧,仅保留包含关键信息的中间段帧,减少冗余信息,以保证拼音预测模型提取到的是有意义的特征。具体的掩蔽时长、帧长参数选择将在实验部分给出。
1.2 拼音序列预测子网络
拼音序列识别模型是将视频帧图片序列转为拼音序列。与大多数图像识别和孤立性单词分类任务有所不同,句子级拼音序列识别过程中除了提取低维的唇部序列图片特征外,还需要提取句子连续性的时间特征。因此,对于连续性句子识别,本文所提算法采用时域卷积网络(TCN)进行拼音预测,与文献[18,19]中的LSTM、GRU模型相比,TCN可以通过改变膨胀因子获得更大的感受野,获取更多的连续时间特征信息,可以更好地抓取长时的依赖信息,进行上下文语义分析。另外,长输入序列的情况下,LSTM和GRU不仅需要使用大量内存来存储其多单元门的部分结果,还存在梯度爆炸、梯度消失和局部过拟合等问题,而不使用门控机制的TCN,有更长的时间记忆[20],结构比LSTM和GRU等循环网络更简单、更清晰。文献[21]在英文单词数据集LRW和中文单词数据集LRW-1000[22]上展示了TCN结构在孤立词识别方面的结果,其准确率分别提升了1.2%和3.2%。
综上所述,为更好地解决连续性时间特征的提取问题,在中文句子唇读的拼音预测阶段,本文应用TCN对视觉特征进行时序建模,并且受文献[23]的启发,引入自注意机制(self-attention),将自注意力机制和TCN相结合,采用不同的权重进行时序建模,让模型能够辨识视觉特征中的关键信息。该模块主要由3D CNN、ResNet18、self-attention和TCN构成,其结构如图2所示。
首先,在视频帧中定位裁剪出唇部区域并转为灰度图,网络的输入是一个(B,T,H,W)的张量,每个维度分别对应批次、帧数、高度和宽度。接着,把每隔两帧的连续5张64×128唇部区域图片输入到3D CNN、最大池化层(MaxPooling)和标准ResNet18网络中提取视觉特征,并且在最后一次卷积后应用平均池化层AvgPooling,产生尺寸为(B,C,T)的特征输出,其中C是信道数量(此处为512)。然后,把视觉特征输入到self-attention模块(其具体结构如图3所示),对特征序列进行相关性计算和特征加权。最后,把加权后的视觉特征输入到TCN,经过线性层和softmax层输出拼音字母的概率分布,生成一个26维的向量并传递给连接时序分类(connectionist temporal classification,CTC)损失函数进行训练。
3DCNN不仅能从空间信息层面提取视觉特征,也能提取时间维度的特征。在3DCNN中3D卷积核通过将连接的相邻帧叠加到一起形成一个立方体,当前层的特征映射(feature map)可以和上层的多个连续的唇部图片帧连接起来。式(1)中vxyzij代表了经过3D卷积和ReLU函数非线性映射后在第i层第j个特征映射(x,y,z)处的值,w为卷积核的权重,v(x-p)(y-q)(z-r)(i-1)m为上一层对应位置处的特征映射值。
vχyzij=relubij+∑m∑Pi-1p=0∑Qi-1q=0∑Ri-1r=0wpqrijmv(x-p)(y-q)(z-r)(i-1)m(1)
對相邻帧特征向量进行自注意力机制处理,其具体运算操作如下:首先唇部帧输入序列X={x1,x2,x3,…,xt}经过图2中ResNet18网络的特征映射后,得到各帧的特征向量V={a1,a2,a3,…,at},每两个相邻帧对应的特征向量ai和ai+1分别与矩阵Wq和Wk相乘得到矩阵qi、ki;然后qi、ki做点乘运算得到每一帧唇部图片和其他帧的相关性系数矩阵α={αi,j}i,j∈[1,t],再对每一个相关性系数进行softmax运算,得到和自己的关联性系数矩阵α′={α′i,j}i,j∈[1,t];最后α′和对应帧的特征向量与矩阵Wv相乘所得的矩阵vi进一步做点乘运算所得特征向量即为self-attention层的输出。以上自注意力机制计算过程可总结为式(2),其中Q(query)、K(key)、V(value)均由对应qi、ki、vi组合而成。
attention=softmaxQKTdk·V(2)
TCN由4个时域卷积块(TCN block)顺序堆叠组成,每个时域卷积块由一个膨胀因果卷积(dilated casual conv)、一个批归一化层(batch normalization)、一个激活层(activate)和一个dropout层组成,其中,滤波器大小取3,膨胀系数dilations=[1,2,4,8]。在TCN网络层之后应用线性层和softmax层,利用CTC损失函数对整个网络进行训练。拼音序列预测阶段的CTC损失函数定义如式(3):
Lpinyin=-ln ppiminin(y|x)(3)
ppinyin(y|x)=∑w∈F-1(y)Pctc(w|x)=∑w∈F-1(y)∏Tt=1qtwt(4)
其中:T是输入序列X的长度,qtwt是指经过softmax后输出预测标签的概率,wt∈{b,p,m,f,…,i,u,v,blank}是第t帧预测的拼音字母序列,y是实际的拼音序列标签,F-1(y)是所有可能映射到实际拼音序列标签y的CTC路径,即所有可能的拼音输出序列的集合。
在测试阶段,将测试样本输入训练好的拼音序列预测子网络,利用贪婪搜索(greedy search)算法对CTC进行解码,在每个时间步上寻找概率最大的字符,并去掉连续重复的拼音字符和空白分隔符blank,即可在CTC路径中查找出全局最优的拼音预测序列,为下一阶段拼音到汉字序列预测做准备。
本文通过消融实验,发现自注意力机制在提升拼音序列预测准确率有明显效果,具体实验数据将在实验及结果分析部分给出。
1.3 汉字序列预测子网络
汉字序列预测子网络将拼音序列预测部分输出的拼音序列转为汉字序列。现有的基于深度学习的唇读技术主要有以下两种解决方案:a)基于连接时序分类(connectionist temporal classification,CTC)[24]的语音识别技术[25~27];b)基于注意力的序列到序列(sequence-to-sequence based attention)[28]神经网络翻译模型[10,29]。前者的结构组合一般是使用CNN提取特征,RNN进行特征学习,CTC作为目标函数,缺陷是该方法中简单的特征提取器不能胜任视频数据的特征提取,RNN则存在梯度消失或爆炸的缺陷;后者的注意力(attention)模型都是依附于编码—解码(encoder-decoder)框架来处理序列—序列问题,缺陷是encoder部分目前仍旧依赖于RNN,没有办法很好地获取中长距离之间两个词相互的关系。针对以上问题,尤其是考虑到汉语拼音和汉字的等长性,本文在拼音序列到汉字序列预测阶段采用了Transformer模型[23]。Transformer结构完全基于自注意力,且是多头自注意层,该特性能使网络对多音字进行预测时,充分学习前后不同词语的子空间表示,提高全局上下文语义理解能力,以改善视觉歧义问题,提升汉语句子的识别准确率。
汉字序列预测子网络如图4所示。汉字序列预测子网络的目标是将拼音预测子网络所得的拼音字母序列Xp={xp1,xp2,…,xpL1}映射为相应的目标汉语序列Yc={yc1,yc2,…,ycL2},Xp是L1个字符的序列,其中的每个字符xpi是 26 维向量。整个映射过程分为三步:预处理—生成语义编码—生成汉语句子。
首先,把拼音序列预处理成向量形式。将每个拼音序列分割成单个音节。例如,对于拼音“jia shi wen nuan de cun zai”,将其分割成“jia”“shi”“wen”“nuan”“de”“cun”“zai”。通过式(5)把每个音节xpi映射成词向量表示xi∈Rd,其中d=512是词向量维度。对于第i个词向量xi需要加上位置编码pi∈Rd,得到嵌入向量ei∈Rd,至此,拼音序列被映射为512维词嵌入向量形式。
xi=embedding(xpi)(5)
ei=xi+pi(6)
然后,准备将转为向量形式的序列输入进transformer编码器结构中,在输入之前,需要先在输入序列的开始和结尾分别添加起始符〈s〉和结束符〈/s〉作为标记。然后通过式(7)将预处理后的拼音序列input转换为一系列隐藏状态Z={z1,z2,…,zL3},也叫语义编码,作为编码器的输出。transformer编码器由6个编码器层堆叠而成,每个编码器层都由两个子层组成:一个多头自注意力子层和一个全连接前馈子层,这些子层都包含了残差连接和层归一化。编码器部分的完整公式化过程可总结为式(8):
Z=encoder(input)(7)
zi=encoderLayer(xpi)=
LayerNorm(xpi+MultiHead(xpi,xpi,xpi))+
LayerNorm(xpi+FFN(LayerNorm(xpi)))(8)
接下來,transformer解码器接收到编码器的输出隐藏状态Z={z1,z2,…,zL3},通过式(9)根据Z和前一个时间步生成的汉字yci-1,来生成解码器的输出隐藏状态HD={hd1,hd2,…,hdL4}。transformer解码器由6个解码器层堆叠而成,每个解码器层都由三个子层组成:一个多头自注意力子层、一个编码器—解码器注意力子层和一个全连接前馈子层,这些子层同样包含了残差连接和层归一化。解码器部分的完整公式化过程可总结为式(10)。
HD=Decoder(yci-1,Z)(9)
hDi=EncoderLayer(zi)=
LayerNorm(zi+MultiHead(zi,zi,zi))+
LayerNorm(zi+MultiHead(xpi,xpi,zi))+
LayerNorm(zi+FFN(LayerNorm(zi)))(10)
最后,解码器的输出隐藏状态HD经过一个linear线性变换和softmax函数后,生成汉语句子的概率分布,输出过程可用式(11)表示。再用波束搜索算法一步步从概率分布中选择出最可能的汉语句子,直到生成完整的句子序列Yc,或者遇到结束标记〈/s〉为止。
P(yci|y 汉字序列预测阶段的CTC损失函数Lcharacter定义如式(12)所示。 Lcharacter=-ln Pcharacter(yc|xp)(12) Pcharacter(yc|xp)=∑wc∈F-1c(yc)Pctc(wc|xp)=∑wc∈F-1c(yc)L1t=1qwctt(13) 其中:wct是第t个时间步长的预测汉字,qwctt是softmax层输出的预测汉字的概率,F-1c(yc)是所有可能映射到真实汉字序列yc的CTC路径,即所有可能的汉语句子输出序列的集合。 在预测阶段,将拼音序列预测子网络输出的拼音序列,输入训练好的汉字序列子网络,利用波束搜索(beam search)算法对CTC进行解码,获取最接近真实标签的预测汉字序列。波束搜索是对贪心搜索算法的改进,基于条件概率为输入的拼音序列在每个时间步长选择多个具有最高概率的可能汉字序列作为备选,扩大了搜索空间。 2 实验及结果分析 2.1 数据集 本文基于目前最大的开源汉语普通话句子级数据集CMLR[17](https://www.vipazoo.cn/CMLR.html)进行了算法测试和对比。该数据集包含了2009~2018年间《新闻广播》节目录制的11位发言者的102 072条句子,每条句子最多包含29个汉字,不包含英文、阿拉伯数字和稀有标点符号。整个数据集的样本按7:1:2的比例随机分为训练集、验证集和测试集,详见表1。 为了验证本文提出的3DT-CHLipNet的优势,选取了四种中文句子级唇语识别算法在CMLR数据集上进行了性能对比实验。这些算法分别是WAS[10]、LipCH-Net[18]、CSSMCM[17]、CHSLR-VP[19],它们均是端到端唇语识别方法。WAS是句子级唇读领域的经典方法,直接从样本视频中识别汉字序列;LipCH-Net、CHSLR-VP和本文模型结构类似,采用二级级联结构(拼音/视觉拼音预测、汉字预测),CSSMCM模型是拼音、声调、汉字预测的三级级联结构。 在后续的对比实验中,使用拼音错误率(pinyin error rate,PER)和字符错误率(character error rate,CER)来衡量各算法的性能。其中,字符错误率定义如式(14)所示,D,S,I分别是预测序列转换为真实标签时,需要删除、替换和插入的汉字个数,N是真实标签的汉字总数,拼音错误率定义与之类似。 CER=D+S+IN(14) 2.2 数据预处理和时间掩码增强 本文以25 fps频率将视频转换为连续的帧图片,每个样本序列包含该样本视频图片帧序列的灰度特征信息。在每个视频中,先使用dlib检测并跟踪68个面部标志点(facial landmark),再用64×128的边界框裁剪出唇部区域,最后将裁减后的图片通过OpenCV进一步转换为灰度图,并根据训练集上的总体均值和方差进行归一化处理。 CMLR数据集中没有给出拼音标签,因此在进行图片到拼音的模型训练之前,需要先用pinyin库将语句转换为拼音标签。文献[18]在进行拼音标签转换时删除了字间的空白区域,例如“家是温暖的存在”,其转换得到的拼音标签为“jiashiwennuandecunzai”,但是为了更符合中文句子的詞语间隔特点,本文在进行拼音标签转换处理时,保留了汉字之间的间隔,如“jia shi wen nuan de cun zai,实验表明,在相同训练批次大小(batch_size)条件下,使用无间隔的拼音标签进行模型训练所得的拼音错误率为57.76%,使用有间隔的拼音标签进行模型训练所得的拼音错误率为42.48%,降低了15%左右。 受文献[30,31]启发,本文引入了时间掩蔽策略进行数据增强处理,对输入的τ时间步长的视频帧序列,应用时间掩蔽,使s个连续的时间步长[t0,t0+s)被掩蔽,其中s从区间[0,T]中选择,T为时间掩蔽参数,t0从[0,τ-s)中选择。为避免丢失过多信息,在时间掩码T上引入一个上界,使时间掩模不能超过时间步长τ的p倍,p≤0.5。本文对比实验了不同T和s取值下的字符错误率(CER),实验结果如表2所示,可见当选择最大掩蔽时间T=2,最大掩蔽帧数s=2时数据增强取得了最低的字符错误率。 2.3 实验环境与配置 本文基于PyTorch库实现了所提出的3DT-CHLipNet算法,实验在Ubuntu 16. 04,NVIDIA GeForce GTX960 GPU, Python 3. 6. 2平台上训练和测试。在训练模型时,拼音序列预测阶段使用CTC损失函数和随机梯度下降(stochastic gradient descent,SGD)优化,拼音预测子网络的初始学习率(learning rate)设置为10-3,如果在4次迭代(epoch)内,每次的训练损失都没有下降,下调学习率50%。拼音预测子网络训练过程中训练集上和测试集上的拼音错误率,随迭代的变化曲线如图5所示。训练结束时,在训练集和测试集分别下降到17.8%、24.47%。 汉字序列预测训练阶段使用CTC损失函数和Adam优化器进行优化,初始学习率汉字序列预测训练阶段使用CTC损失函数和Adam优化器进行优化,初始学习率为10-4,当验证集上损失函数值稳定不变时,下调学习率50%,最终的学习率是10-5。在CMLR数据集上在此环境配置下,3DT-CHLipNet算法模型經过约159 h的训练,在验证集上的字符错误率收敛稳定在30.31%,完成训练,此时在训练集上的字符错误率为22.6%。汉字序列预测子网络训练过程中训练集上和测试集上的字符错误率,随迭代的变化曲线如图6所示。 2.4 拼音序列识别 将CMLR数据集样本进行预处理后所得到的唇部区域灰度图作为3DCNN的输入,每次输入5个唇形帧,每次间隔2帧。3D卷积核大小设置为(5,7,7),步长为(1,2,2)。ResNet18模块的卷积为(3,3),步长为(1,1),一共18层卷积,4次下采样,每层卷积后进行批归一化。在文献[21]多尺度TCN基础上,把TCN网络结构中的膨胀非因果卷积替换为膨胀因果卷积,使当前时间步的字符识别可以利用前一时间步已识别的字符信息。在CMLR数据集上的实验结果表明,在TCN中利用膨胀因果卷积的拼音准确率为75.53%,比膨胀非因果卷积的71.65%的正确率提升了约4%。 本文提出的3DT-CHLipNet,其拼音序列识别子网络的结构是3DCNN+ResNet18+self-attention+TCN+CTC,和目前的中文识别主流模型LipCH-Net、CSSMCM相比,加入了自注意力(self-attention)层并且将RNN替换为TCN,采用自注意力机制和TCN相结合的方法进行序列建模。 为了验证本文所提出的在拼音序列识别阶段应用时域卷积网络和自注意力机制的效果,本文与LipCH-Net、CSSMCM和CHSLR-VP算法进行了对比实验,结果如表3所示。可见3DT-CHLipNet模型在CMLR测试集上的平均拼音错误率为24.47%,比LipCH-Net的41.49%错误率降低了约17%,比CSSMCM的36.22%错误率降低了约12%。由此可看出自注意力机制结合时域卷积网络的有效性。 本文提出的3DT-CHLipNet模型在拼音预测阶段优于LipCH-Net、CSSMCM模型,是因为所采用的时域卷积网络TCN相比于后两者的RNN结构,避免了梯度消失或爆炸问题,有更好地长期依赖处理能力;RNN的递归属性决定了其对输入的微小变化非常敏感,影响识别性能,而TCN使用更简单的卷积,更加稳定。同时,3DT-CHLipNet模型中添加的自注意机制,为关键帧分配了更多权重,使网络侧重于对重点信息的学习,增强了对连续唇部图片序列运动的特征提取效果,提升了最终识别效果。另外,从表3中也可以看出,CHSLR-VP模型和本文提出的3DT-CHLipNet模型的拼音错误率接近,原因是CHSLR-VP模型中所用的视觉拼音标签要比本文模型中所用的26个字母标签更符合中文发音特点,这也是本文模型继续完善改进的研究内容。 2.4.1 消融实验 为了验证自注意力机制对拼音序列预测的效果,本文在拼音预测子网络中进行了自注意力层的消融实验,实验结果如表4所示。可见在时域卷积网络层前添加自注意力层,要比不添加自注意力层的拼音错误率低7%左右。这验证了自注意力机制能对每个时间步的视觉特征赋予不同的注意权重,在进行拼音预测时可以更好地进行上下文语义理解,进而提升拼音预测的准确率。 以样本“家是温暖的存在”为例,图7和8分别给出使用注意力机制与不使用注意力机制时,视频帧与预测拼音序列的对齐情况,可以明显看出使用注意力时(图7),对齐效果更好,更接近对角线走势。由此可看出引入自注意力机制结合时间卷积网络的有效性。 2.4.2 TCN和LSTM对比实验 为验证本文提出的在拼音序列识别步骤中应用时域卷积(TCN)的优越性,本文通过将TCN模块替换为LSTM网络结构来进行了拼音序列预测的对比实验。实验结果如表5所示。其中,LSTM网络选用了LipCH-Net模型[17]中表现效果最佳的结构:1层512的LSTM。实验结果表明,在其他网络结构相同,仅用TCN来替换LSTM网络时,拼音错误率降低了4.13%。 2.5 汉字序列识别 表6对比显示了本文算法与LipCH-Net、CSSMCM、CHSLR-VP和WAS算法在汉字序列预测步骤中的字符错误率。本文所提3DT-CHLipNet算法相较于LipCH-Net、CSSMCM、CHSLR-VP和WAS,在测试集上字符错误率分别降低了23.99%、2.17%、2.31%和12.43%。本文算法在汉字序列识别阶段的字符错误率数值(30.31%)高于拼音识别阶段的拼音错误率(24.47%,见表4),这是因为汉字序列识别是依托于拼音序列识别的,是在拼音序列识别错误的基础上累加了汉字序列识别的错误。 2.5.1 波束宽度选择 通过汉字预测子网络进行汉语句子预测时,将待测试拼音序列输入训练好的模型,利用波束搜索算法对CTC进行解码,找到最接近真实标签的句子序列。 波束宽度(beam width)是波束搜索算法中的一个重要参数,它决定了汉字预测子网络的解码器部分在每个时间步中选择的候选汉字结果数量,其大小会直接影响预测结果的质量和搜索效率。尤其对于同一组拼音可能对应多组汉字的情况来说,波束宽度越大,搜索空间包含的同音字越多,最终预测的汉语句子接近真实标签的可能性就更大。例如,样本“不变的事实”对应拼音序列“bu bian de shi shi”,其中的“shi shi”一词在进行汉字预测时可能搜索到的结果包括“实时”“实施”“史诗”“事实”等多个可能,只有波束宽度够大,真实的标签才更有可能被搜索到,才更能有效缓解中文唇语识别中的同型异义“视觉歧义”问题。 但过大的波束宽度需要较多的搜索时间,降低了搜索效率。因此,需要根据数据集和具体任务,在预测结果质量和搜索效率之间进行权衡,选择合适的波束宽度。经过实验,本文确定在CMLR数据集上,在汉语句子预测阶段选择波束宽度为20时效果最好。不同波束宽度对CER的影響如图9所示。 2.5.2 模型缺陷与解决思路 表7中列举了本文算法3个识别错误的句子,可从这三个典型样本中总结出识别错误的两类情况:a)同音字预测错误,如“实行”与“施行”“心中”与“信中”;b)尾音相同或相似时,首音预测错误,如“qia dang”与“xia jiang”“qian gua”与“jiang hua”。针对同音字预测错误,虽然本文算法中的自注意机制可以通过联系上下文来纠正语义,但是对于不影响整体句子理解的同音字识别仍有待改进。针对尾音相似,首音预测错误问题,可以考虑在进行拼音识别时按元音和辅音进行分类识别,而不只是26个字母。 3 结束语 本文针对中文句子级唇语识别中的视觉歧义、特征提取不充足的问题,提出了一个中文句子级唇语识别算法——3DT-CHLipNet,首次将时域卷积网络应用于拼音序列识别阶段,以提取长时序列特征,并利用自注意力机制捕获上下文信息,减少视觉歧义,还引入了时间掩蔽的数据增强措施,降低了识别错误率。在CMLR数据集上的实验数据表明,本文算法在拼音序列识别错误率和汉字序列识别错误率的性能指标上,优于现有的中文句子级唇语识别代表性算法。今后将考虑在以下方向进一步研究扩展:a)改变拼音分类预测标准,建立更适于中文识别的元音、辅音形式和视觉拼音标签库;b)采用多模态输入,加入语音数据,辅助视觉模型的训练,提高整体中文句子识别精度;c)选择不同背景、不同角度的多个数据集训练模型,以提高模型的泛化能力和可迁移性。 参考文献: [1]王一鸣,陈恳,萨阿卜杜萨拉木·艾海提拉木.基于SDBN和BLSTM注意力融合的端到端视听双模态语音识别[J].电信科学,2019,35(12):79-89.(Wang Yiming,Chen Ken,Aihaiti Abudusalamu.End-to-end audiovisual speech recognition based on attention fusion of SDBN and BLSTM[J].Telecommunications Science,2019,35(12):79-89.) [2]任玉强,田国栋,周祥东,等.高安全性人脸识别系统中的唇语识别算法研究[J].计算机应用研究,2017,34(4):1221-1225.(Ren Yuqiang,Tian Guodong,Zhou Xiangdong,et al.Lip-reading algorithm in face recognition systems for high security[J].Application Research of Computers,2017,34(4):1221-1225.) [3]雷江华.听觉障碍学生唇读汉字语音识别的实验研究[D].上海:华东师范大学,2006.(Lei Jianghua.Experimental study on lip-reading Chinese phonetic identification for the hearing handicapped[D].Shanghai:East China Normal University,2006) [4]Zhou Ziheng,Zhao Guoying,Pietikainen M.Towards a practical lipreading system[C]//Proc of CVPR.Piscataway,NJ:IEEE Press,2011:137-144. [5]Zhao Guoying,Pietikainen M,Hadid A.Local spatiotemporal descriptors for visual recognition of spoken phrases[C]//Proc of International Workshop on Human-centered Multimedia.2007:57-66. [6]Saitoh T,Morishita K,Konishi R.Analysis of efficient lip reading method for various languages[C]//Proc of the 19th International Conference on Pattern Recognition.Piscataway,NJ:IEEE Press,2008:1-4. [7]Tatulli E,Hueber T.Feature extraction using multimodal convolutional neural networks for visual speech recognition[C]//Proc of IEEE International Conference on Acoustics,Speech and Signal Processing .2017:2971-2975. [8]Noda K,Yamaguchi Y,Nakadai K,et al.Lipreading using convolutional neural network[C]//Proc of the 15th Annual Conference of the International Speech Communication Association.2014. [9]Stafylakis T,Tzimiropoulos G.Combining residual networks with LSTMs for lipreading[EB/OL].(2017).https://arxiv.org/abs/1703.04105. [10]Chung J S,Senior A,Vinyals O,et al.Lip reading sentences in the wild[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.2017:6447-6456. [11]Ma Pingchuan,Wang Yujiang,Shen Jie,et al.Lip reading with densely connected temporal convolutional networks[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision,2021:2857-2866. [12]Assael Y M,Shillingford B,Whiteson S,et al.Lipnet:Sentence-level lipreading[EB/OL].(2016).https://arxiv.org/abs/1611.01599. [13]Afouras T,Chung J S,Senior A,et al.Deep audio-visual speech recognition[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2018,44(12):8717-8727. [14]Ma Pingchuan,Petridis S,Pantic M.End-to-end audio-visual speech recognition with conformers[C]//Proc of IEEE International Conference on Acoustics,Speech and Signal Processing.2021:7613-7617. [15]馬金林,陈德光,郭贝贝,等.唇语语料库综述[J].计算机工程与应用,2019,55(22):1-13,52.(Ma Jinlin,Chen Deguang,Guo Beibei,et al.Lip corpus review[J].Computer Engineering and Applications,2019,55(22):1-13,52.) [16]马金林,朱艳彬,马自萍,等.唇语识别的深度学习方法综述[J].计算机工程与应用,2021,57(24):61-73.(Ma Jinlin,Zhu Yanbin,Ma Ziping,et al.Review of deep learning methods for Lip Recognition[J].Computer Engineering and Applications,2021,57(24):61-73.) [17]Zhao Ya,Xu Rui,Song Mingli.A cascade sequence-to-sequence model for chinese mandarin lip reading[M]//Proc of ACM Multimedia Asia.2019:1-6. [18]Zhang Xiaobing,Gong Haigang,Dai Xili,et al.Understanding pictograph with facial features:End-to-end sentence-level lip reading of Chinese[C]//Proc of AAAI Conference on Artificial Intelligence.2019:9211-9218. [19]何珊,袁家斌,陆要要.基于中文发音视觉特点的唇语识别方法研究[J].计算机工程与应用,2022,58(4):157-162.(He Shan,Yuan Jiabin,Lu Yaoyao.Research on lip-reading based on visual characteristics of Chinese pronunciation[J].Computer Engineering and Applications,2022,58(4):157-162.) [20]Bai S,Kolter J Z,Koltun V.An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[EB/OL].(2018).https://arxiv.org/abs/1803.01271. [21]Martinez B,Ma Pingchuan,Petridis S,et al.Lipreading using temporal convolutional networks[C]//Proc of IEEE International Conference on Acoustics,Speech and Signal Processing.2020:6319-6323. [22]Yang Shuang,Zhang Yuanhang,Feng Dalu,et al.LRW-1000:a naturally-distributed large-scale benchmark for lip reading in the wild[C]//Proc of the 14th IEEE International Conference on Automatic Face & Gesture Recognition.2019:1-8. [23]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[EB/OL].(2017-06-12).https://arxiv.org/abs/1706.03762. [24]Graves A,Fernandez S,Gomez F,et al.Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks[C]//Proc of the 23rd International Conference on Machine Learning.2006:369-376. [25]Xu Kai,Li Dawei,Cassimatis N,et al.LCANet:end-to-end lipreading with cascaded attention-CTC[C]//Proc of the 13th IEEE International Conference on Automatic Face & Gesture Recognition.2018:548-555. [26]Amodei D,Ananthanarayanan S,Anubhai R,et al.Deep speech 2:end-to-end speech recognition in english and mandarin[C]//Proc of PMLR.International Conference on Machine Learning.2016:173-182. [27]Graves A,Jaitly N.Towards end-to-end speech recognition with recurrent neural networks[C]//Proc of PMLR.International Conference on Machine Learning.2014:1764-1772. [28]Bahdanau D,Cho K,Bengio Y.Neural machine translation by jointly learning to align and translate[EB/OL].(2014).https://arxiv.org/abs/ 1409.0473. [29]Chung J S,Zisserman A.Out of time:automated lip sync in the wild[C]//Proc of Springer.Asian Conference on Computer Vision,2016:251–263. [30]Ma Pingchuan,Wang Yujian,Petridis S,et al.Training strategies for improved lip-reading[C]//Proc of IEEE International Conference on Acoustics,Speech and Signal Processing.2022:8472-8476. [31]Park D S,Chan W,Zhang Yu,et al.Specaugment:a simple data augmentation method for automatic speech recognition[EB/OL].(2019).https://arxiv.org/abs/1904.08779. 收稿日期:2023-02-23; 修回日期:2023-04-07 基金項目:北京市自然科学基金资助项目(4162056);中央高校基本科研业务费资助项目(2016MS33) 作者简介:刘培培(1998-),女,硕士研究生,主要研究方向为计算机视觉;贾静平(1978-),男(通信作者),讲师,博士,主要研究方向为计算机视觉与机器学习(rocsovsky@163.com).
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
