
场景关系图学习的群组行为识别
2023-10-17 15:08:31焦畅吴克伟于磊谢昭李文中
计算机应用研究 2023年10期
焦畅 吴克伟 于磊 谢昭 李文中


摘 要:为解决群组行为识别中复杂个体关系描述不准确,造成的个体关系推理不可靠的问题,关注于面向个体、群体、场景三个方面来构建场景关系图,提出场景关系图网络用于实现群组行为识别。该网络包括特征提取模块、场景关系图推理模块以及分类模块。特征提取模块通过卷积神经网络提取个体特征、群组特征、和场景特征。为了充分描述场景对于个体和群组描述的影响,场景关系图推理模块通过使用两分支网络分别建立个体—场景关系图以及群组—场景关系图帮助学习个体特征和群组特征。场景关系图推理同时考虑了个体特征对群组特征的影响,并引入了跨分支关系。分类模块用于将个体特征和群体特征进行分类预测。实验结果显示该方法在volleyball和collective activity数据集上的群组识别准确率分别提升了1.1%和0.5%,证实了提出的场景关系图在描述个体特征和群组特征上的有效性。
关键词:群组行为识别;场景关系图;关系建模;行为识别
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2023)10-045-3173-07
doi:10.19734/j.issn.1001-3695.2022.12.0828
Scene relation graph network for group activity recognition
Jiao Chang,Wu Kewei,Yu Lei,Xie Zhao,Li Wenzhong
(School of Computer Science & Information Engineering,Hefei University of Technology,Hefei 230601,China)
Abstract:To solve the problem of inaccurate description and unreliable relation inference in group activity recognition,this paper focused on constructing a scene relationship graph for three aspects:individual,group,and scene,and proposed a scene relationship graph network(SRGN) for group activity recognition.This method included a feature extraction module,a scene relation graph inference module,and a classification module.The feature extraction module extracted individual features,group features,and scene features by convolutional neural network.To fully explore the impact of scene on individual and group descriptions,the scene relation graph inference module learnt individual features and group features by building individual-scene and group-scene relationship graphs in a two-branch framework.Scene graph inference took into account the influence of individual on group and introduced a cross-branch module.It used
the classification module to classify individual features and group features for prediction.The experimental results show that the group recognition accuracy of the proposed method on volleyball and collective activity data sets is improved by 1.1% and 0.5%,respectively.It verifies the validity of the scene graph in describing individual feature and group feature.
Key words:group activity recognition;scene relation graph;relation modeling;action recognition
0 引言
群組行为识别是视频理解中的一个重要问题,这个任务是对多人组成的群组进行集体活动的分析,它是很多视觉应用的基础任务,如公共监控视频分析、体育视频分析以及社交场景分析等。传统方法直接提取个体边界框的深度特征作为群组特征[1~3],这导致个体特征在训练过程中缺少来自其他相关个体的影响信息,最终识别结果的精度也较低。尽管一些方法通过引入辅助信息,如标签语义[4]和人体骨架[5]等来帮助增强场景中一些重要个体的特征表达,但都未取得明显效果。
与面向视频分类的人体行为识别不同,群组行为识别需要对多个成员的互动以及他们周围的环境(如其他成员和物体)进行分析。因此近年来大部分的群组行为识别方法[6,7]不光考虑了个体特征提取,还从关系建模的角度来为个体特征添加补充信息来解决问题。这些工作使用RNN[8]或者LSTM[9]构建个体的关系,但这种方式不能计算关系权重,为所有个体提供的补充信息是没有区分度的。为了进一步挖掘个体间的关系,一些方法[10~14]引入了Transformer来计算注意力关系。其中AT[11]使用Transformer为个体特征计算自注意力关系,GF等工作[12,14]将个体先聚类然后计算类间的注意力,Dual-AI[13]构造了时空Transformer,分别学习时间和空间的个体注意力,但Transformer模型复杂度较高,关系推理能力也较弱。随着图卷积网络的兴起,Wu等人[15]看中了其高效的关系推理能力,将其应用在群组行为识别领域,提出了个体关系图ARG。后续大部分的工作[16~22]将其作为关系建模的重要手段。其中MLIR等工作[16,20]构建了不同层次的个体关系图,DIN等工作[21,22]将关系图扩展到时间维度,为整个视频建立时空个体关系图。
上述关系图模型都只考虑到了个体与个体之间的互动关系,忽略了视频图像中重要的场景信息。一些方法[23~28]尝试过使用场景特征来增强个体特征。StagNet[26]将动作标签作为场景语义特征加入到关系推理,没有考虑到场景的视觉特征。GAIM[27]将整张图像压缩成一个代表全局信息的节点特征,却因此丢失了场景的完整空间信息。
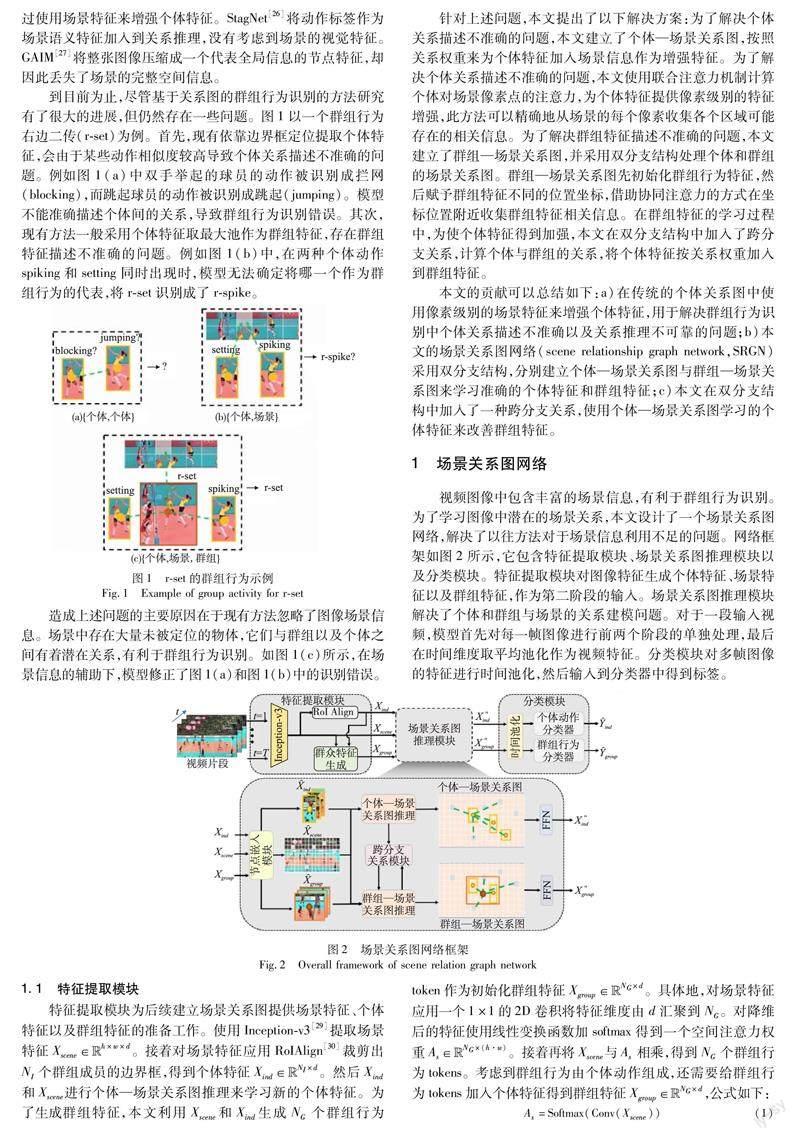
到目前为止,尽管基于关系图的群组行为识别的方法研究有了很大的进展,但仍然存在一些问题。图1以一个群组行为右边二传(r-set)为例。首先,现有依靠边界框定位提取个体特征,会由于某些动作相似度较高导致个体关系描述不准确的问题。例如图1(a)中双手举起的球员的动作被识别成拦网(blocking),而跳起球员的动作被识别成跳起(jumping)。模型不能准确描述个体间的关系,导致群组行为识别错误。其次,现有方法一般采用个体特征取最大池作为群组特征,存在群组特征描述不准确的问题。例如图1(b)中,在两种个体动作spiking和setting同时出现时,模型无法确定将哪一个作为群组行为的代表,将r-set识别成了r-spike。
造成上述问题的主要原因在于现有方法忽略了图像场景信息。场景中存在大量未被定位的物体,它们与群组以及个体之间有着潜在关系,有利于群组行为识别。如图1(c)所示,在场景信息的辅助下,模型修正了图1(a)和图1(b)中的识别错误。
针对上述问题,本文提出了以下解决方案:为了解决个体关系描述不准确的问题,本文建立了个体—场景关系图,按照关系权重来为个体特征加入场景信息作为增强特征。为了解决个体关系描述不准确的问题,本文使用联合注意力机制计算个体对场景像素点的注意力,为个体特征提供像素级别的特征增强,此方法可以精确地从场景的每个像素收集各个区域可能存在的相关信息。为了解决群组特征描述不准确的问题,本文建立了群组—场景关系图,并采用双分支结构处理个体和群组的场景关系图。群组—场景关系图先初始化群组行为特征,然后赋予群组特征不同的位置坐标,借助协同注意力的方式在坐标位置附近收集群组特征相关信息。在群组特征的学习过程中,为使个体特征得到加强,本文在双分支结构中加入了跨分支关系,计算个体与群组的关系,将个体特征按关系权重加入到群组特征。
本文的贡献可以总结如下:a)在传统的个体关系图中使用像素级别的场景特征来增强个体特征,用于解决群组行为识别中个体关系描述不准确以及关系推理不可靠的问题;b)本文的场景关系图网络(scene relationship graph network,SRGN)采用双分支结构,分别建立个体—场景关系图与群组—场景关系图来学习准确的个体特征和群组特征;c)本文在双分支结构中加入了一种跨分支关系,使用个体—场景关系图学习的个体特征来改善群组特征。
1 场景关系图网络
视频图像中包含丰富的场景信息,有利于群组行为识别。为了学习图像中潜在的场景关系,本文设计了一个场景关系图网络,解决了以往方法对于场景信息利用不足的问题。网络框架如图2所示,它包含特征提取模块、场景关系图推理模块以及分类模块。特征提取模块对图像特征生成个体特征、场景特征以及群组特征,作为第二阶段的输入。场景关系图推理模块解决了个体和群组与场景的关系建模问题。对于一段输入视频,模型首先对每一帧图像进行前两个阶段的单独处理,最后在时间维度取平均池化作为视频特征。分类模块对多帧图像的特征进行时间池化,然后输入到分类器中得到标签。
1.1 特征提取模块
特征提取模块为后续建立场景关系图提供场景特征、个体特征以及群組特征的准备工作。使用Inception-v3[29]提取场景特征Xscene∈Euclid Math TwoRAph×w×d。接着对场景特征应用RoIAlign[30]裁剪出NI个群组成员的边界框,得到个体特征Xind∈Euclid Math TwoRApNI×d。然后Xind和Xscene进行个体—场景关系图推理来学习新的个体特征。为了生成群组特征,本文利用Xscene和Xind生成NG个群组行为token作为初始化群组特征Xgroup∈Euclid Math TwoRApNG×d。具体地,对场景特征应用一个1×1的2D卷积将特征维度由d汇聚到NG。对降维后的特征使用线性变换函数加softmax得到一个空间注意力权重As∈
1.2 场景关系图推理模块
在缺失场景信息时,个体关系描述不准确会导致关系推理不可靠,从而得到不准确的群组特征。为了学习个体特征和群组特征对场景的注意力关系,本文设计了场景关系图推理模块。该模块采用双分支结构,分别进行个体—场景关系图推理与群组—场景关系图推理。具体地:a)个体—场景关系图推理将Xind和Xscene作为输入,加入对应位置编码得到个体节点ind和场景节点scene,并使用这两种节点建立了个体—场景关系图GIS={ind∪scene,EIS},其中EIS是两种节点的连接边,它的值代表了个体—场景关系;b)群组—场景关系图推理先将群组token特征Xgroup转换成群组节点group,然后使用group和场景节点scene一起建立群组—场景关系图GGS={group∪scene,EGS}来学习新的群组特征,其中EGS是场景节点与群组节点的连接边,它的值代表群组—场景关系;c)在双分支结构中,为了让群组—场景关系图推理过程中获得个体特征的增强,本文还使用了跨分支关系来学习得到融合群组特征Xfusegroup。
1.2.1 个体—场景关系图推理
个体—场景关系图推理模块通过建立个体—场景关系图来帮助改善个体特征,通过联合注意力机制来计算个体对场景各个区域的关注程度,作为个体与场景的相互关系。然后使用图推理为个体特征更新包含场景关系的信息,输出新的个体特征。
图3上半部分展示了该分支的结构。它包含三个模块,黄色部分是节点嵌入模块,粉色部分是关系图推理模块,蓝色部分是前馈网络模块(参见电子版)。为了在后续的场景关系计算中保留位置信息,节点嵌入模块将输入特征的位置编码特征和原始特征一起嵌入到节点特征空间中。对于个体节点,将Xind加上位置编码后使用一个线性变换函数得到个体节点特征ind。接着对个体节点进行一次基于自注意力的节点更新。这是为了捕捉不同位置不同个体之间的相关关系,使所有个体特征先在内部根据注意力权重相互传递信息。对于场景节点,为Xscene加上位置编码后将特征维度降到d′,并且将空间维度拉平,得到场景节点特征scene。
考虑到个体节点和场景节点之间可能会有多种类型的相关关系,例如球员与观众,球员与教练,甚至球员与裁判之间的联系。可以采用多头协同注意力机制,每个注意头专门处理一种场景关系类型。假设使用单个注意头计算个体特征表示为X″ind=attention(ind,scene),则使用多头注意力表示如下:
1.2.2 群组—场景关系图推理
群组—场景关系图推理模块通过群组—场景关系图来学习群组特征。图3的下半部分展示了群组—场景关系图分支,它的结构与个体—场景关系图推理类似。群组—场景关系图推理同样经过节点嵌入层、场景关系图推理层以及前馈网络层这三个模块来建立群组—场景关系图并进行推理。节点嵌入模块使用了群组特征Xgroup生成群组节点group。具体地,为了让Xgroup从场景中获得不同区域的相关上下文,本文将群组行为特征的位置编码加入,然后嵌入到了场景图的节点空间,得到群组节点。
接着将scene和group交给场景关系图推理模块建立群组—场景关系图,在场景中收集与群组行为相关的上下文信息。本文的群组节点是不同种类群组行为的查询,这些查询之间并没有相关关系,而是与场景各区域特征有着强烈的联系,所以只需要学习群组节点与场景节点的相关关系即可。
场景关系图推理模块计算群组节点group和场景节点scene的所有节点之间的协同注意力作为群组场景关系图的边EGS={eGSi,j|i=0,1,…,NG;j=0,1,…,hw}。其中eGSi,j代表第i个群组节点groupi和第j个场景节点scenej的注意力关系。在群组和场景的联合注意力中,将groupi当做查询,scenej当做键和值,计算群组节点与场景节点的联合注意力,并通过注意力权重对场景像素特征加权求和来更新群组节点特征:
其中:X″group是图推理过后的群组特征。群组—场景关系有多种不同类型,这同样可以使用不同的注意力头学习不同类型群组场景上下文关系。因此,也可以使用多头注意力形式来学习X″group:
1.2.3 跨分支关系模块
群组行为会受到其中个体动作的影响,并且身处群组中的每个个体对群组行为的影响并不相同。因此,为了在群组特征的学习过程中使用个体特征来增强群组特征表示,本文设计了一个跨分支关系模块来建立每个个体与不同群组之间的关系。图3中,紫色方框是跨分支关系模块。它位于两个分支的每层图推理输出位置之间,在編码过程中通过加强与群组行为相关的个体特征来改善群组节点特征。
具体地,为了得到不同群组行为对于场景中每个个体的注意力关系,本文先根据个体特征X″ind和群组特征X″group计算一个相似度分数矩阵。接着使用
1.3 训练损失
对于一个T帧的输入视频片段,一共得到T×NI个个体特征,以及T×NG个群组特征。以往的方法一般先学习个体特征,然后对个体特征取最大池作为群组分类器的输入,而本文单独构造了群组特征,对群组行为数量NG取最大池得到的才是真正的群组特征表示。最后将两种特征在时间维度T上取平均池化后分别输入到两种分类器。分类器是两个全连接层,最终输出个体动作预测标签Y^ind和群组行为预测标签Y^group。本文模型是以端到端的方式进行训练的,损失函数使用的是标准的交叉熵损失函数,表述如下:
其中:Lgroup和Lind分别是群组行为识别和个体动作识别的损失函数;Ygtgroup和Ygtind分别是群组行为和个体动作的真实标签;Y^group和Y^ind则是模型的预测标签;λ是一个超参数,它起到平衡两种损失函数的作用。
2 实验
2.1 数据集与评价标准
本文在本领域两个广泛使用的数据集上进行了大量实验,它们分别是volleyball dataset(VD)[1]以及collective activity dataset(CAD)[31]。
1)volleyball dataset 该数据集包含55场排球比赛的视频,每个视频被分为数量不同的若干片段,总共4 830个片段(其中3 493段作为训练集,1 337段作为测试集),每一视频片段的中间一帧有人工标注,包括个体边界框的坐标、个体动作的真实标签、群组动作的真实标签。个体动作标签有九类,包括waiting,setting,digging,falling,spiking,blocking,jumping,mo-ving,standing。群组行为标签有八类,包括right set,right spike,right pass,right win-point,left set,left spike,left pass,left win-point。
2)collective activity dataset 该数据集包含44个手持摄像机拍摄的视频,拍摄场景包括街道和室内,总共被分为2 481个片段(其中80%作为训练集,20%作为测试集)。每个片段的中间帧标注个体边界框和对应的个体动作。每帧图像的边界框数量不一,最大为13。个体动作包括NA,crossing,wai-ting,queuing,walking and talking。群组行为标签根据场景中最多的个体动作标签决定。
3)评价指标 本文在两个数据集上的评价指标均采用多类分类精度(multi-class classification accuracy,MCA),本文使用群组行为MCA(group)以及个体动作MCA(individual)。
2.2 实验细节
对于volleyball dataset,输入视频图像帧数T=10帧,输入图像大小调整至720×1 080。个体边界框数量NI=12,群组token特征数量NG=8。所有输入特征的维度d=1 024,转换成节点特征的维度d′=128,后续输出特征采用同样的特征维度。个体分类器采用(128,9)的全连接层,群组分类器采用(128,8)的全连接层。训练期间,网络超参数设置如下:批量训练样本容量为8,dropout 比率为0.8,学习率初始化为10-4,网络训练周期设置为150个周期,期间每经过30个周期,将学习率下降到之前的1/2,经历4次衰减后会停止衰减学习率。
对于collective activity dataset,同样输入T=10帧的视频图像,将图像大小调整为480×720。个体边界框取最大数量NI=13,如果场景中的个体数量不足13个,则缺少的部分使用全零的特征向量代替。群组token特征数量NG=5。所有输入的特征维度为d=1 024,节点嵌入层以及输出的特征维度为d′=128。群组分类器采用(128,5)的全连接层。训练期间,网络的超参数设置如下:批量训练样本容量为16;dropout比率为0.5;学习率初始化为10-3;网络训练周期设置为50个周期,不采用学习率衰退策略。
两个数据集的场景关系图建立过程都使用了多头联合注意力模块,本文将注意力头的数量设置为m=4。两个数据集都使用了Adam优化器,参数设置分别为β1=0.9,β2=0.999和ε=10-8。所有实验的系统平台为Ubuntu18.04操作系统,使用深度学习框架PyTorch,GPU为两张GTX 1080Ti显卡。
2.3 对比实验
表1展示了在volleyball dataset数据集上的对比实验结果,其中extra表示是否使用额外模态信息。
本文将对比方法主要分为非场景图方法和场景图方法两类。非场景图中,HDTM是传统的深度学习方法,没有使用关系建模加强特征。HRN和SRNN使用RNN关系建模。ARG、MLIR和DIN则使用了个体关系图。AT、GF和Dual-AI使用了组合的Transformer学习个体关系。这些方法都没有使用场景信息来增强个体特征表示。场景图方法中,StagNet使用语义标签作为场景信息,GAIM则把整个场景特征压缩成单个节点建立场景关系图。
从表1中可以看出,本文方法在群组行为和个体动作识别准确率超越了其他方法,说明本文方法学习到了准确的群组特征和个体特征。与非场景图方法相比,本文的场景关系图方法能够提供其所不能关注到的场景特征。具体地,传统方法是因为没有使用关系建模,而其他关系建模的方法是因为没有将场景特征作为关系推理的对象,所以本文方法的识别性能更好。与其他的场景关系图方法相比,本文方法可以提供更丰富的增强特征。而其他方法只利用了场景特征的一部分,忽略了所有像素级特征和个体特征存在的潜在关系,造成了其模型性能甚至不如某些个体关系图方法。
表2展示了在collective activity數据集上的对比实验结果,其中extra表示是否使用额外模态信息。结果显示,没有使用关系建模的方法性能较差,例如HDTM。这可能是由于没有计算关系权重,个体间也无法传递相关信息。CAD的群组行为识别是由场景中多数个体动作共同决定的,构造具有区分度的个体特征是很重要的。
加入额外模态特征可以帮助模型取得较好的识别效果,例如AT和GF的识别准确率得到了提高,但同时可能引入不必要的额外噪声。基于图方法的模型可以学习个体关系作为特征更新的权重,同样可以增强个体特征。其中ARG学习个体的个体关系,DIN则是时空关系一起学习。只是这些方法缺失了图像中的场景信息,使用了场景图的方法。StagNet没有使用图像特征作为场景特征,GAIM将图像压缩成单个节点。这些方法设计的场景特征都丢失了图像的空间信息,因此没有取得明显的提升。本文的场景图方法在没有加入额外模态特征的前提下,充分利用了场景特征本身包含的上下文信息。与其他方法相比,本文方法在群组行为识别准确率上有所提升,已经具备与先进方法相当的模型性能。
2.4 消融实验
本节将在volleyball dataset上对本文所提出的模型进行一系列消融实验,以验证各个模块方法的有效性和贡献。
1)节点类型对模型的影响 本文的场景关系图使用了多种类型的节点,通过消融实验来验证不同节点的有效性。结果如表3所示。当只使用ind,场景图退化成个体关系图ARG[15],并采用图卷积建立个体关系。个体节点特征仅提取了个体边界框内的特征,本文将其当做Base Model。在此基础上可以加入场景上下文节点scene,并且使用GCN建立ind与scene的关系以进行节点间的信息交换,结果显示模型性能并未提升,这可能是因为GCN将场景图像特征压缩到低维度空间,无法给个体节点提供详细的场景空间信息。本文使用了场景关系图(SRGN),取场景特征中的每个像素作为场景节点,并且使用协同注意力机制建立个体节点与场景节点的关系。从结果来看模型性能有所提升,尤其是个体识别精度提升幅度较大。这是因为个体特征在图推理过程中在场景节点中收集自身关注区域的场景上下文信息,加强了个体特征表示。以上三种方案将个体特征取最大池化作为群组行为特征交给分类器,而本文引入了一组独立的群组节点特征group,在场景特征图中收集相关群组行为信息。结果显示模型的群组行为识别性能提升明显。这是由于群组节点的特征不仅来自个体节点,同时还来自场景中相关区域的上下文特征,所以群组特征得到了增强。
2)关系边对模型的影响 场景关系图有个体—场景关系图分支和群组—场景关系图分支。两个分支的关系边连接节点不同,学习到的关系类型也不同。为了证明不同类型关系建模的有效性,本文对场景图的关系边进行了消融实验,实验结果如表4所示。
根据实验结果可以得到以下结论:a)不加入场景关系边,此时SRGN只能学习个体间的相关关系,关系的计算方法使用的是自注意力,相比于Base Model,模型性能提升较少;b)只使用个体—场景关系边,相当于模型只有个体—场景关系图,此时个体节点可以利用场景特征信息加强个体特征,群组节点虽然无法获得场景信息的加强,但由于本身由场景特征和个体特征生成,所以模型的群组行为识别性能也得到了提升;c)加入群组—场景关系边,相当于采用了双分支结构,此时场景图可以建立群组和场景的关系。从结果可以看出,群组行为识别准确率得到较大的提升,但是加入群组—场景关系图对个体动作识别性能影响较小,这是因为两个分支在特征学习的过程中没有传递增强信息。本文将跨分支关系当做个体与群组的连接边加入,从结果可以看出,群组行为的识别准确率得到大幅提升,这说明个体特征对于群组特征的学习指导起到了作用,而个体动作的识别准确率提升较小。
3)多头注意力对模型的影响 场景关系图主要靠联合注意力层对上下文信息进行聚合,它采用多头形式。在这里本文对注意力头的个数进行消融实验,同时对是否使用位置编码也进行了研究。表5中,head表示注意力头数,PE表示是否使用位置编码。从表5的实验结果来看,注意力头的个数并不是越多越好,经过验证,注意力头数设置为4个最好,这是因为场景与场景中的实例(个体节点或者群组节点)关系不会有很多种类型,比如在排球比赛的视频图像中,场景信息包括观众、裁判、教练以及一些媒体记者等,一般不会出现更多更复杂的场景。因此设置更多的注意力头学习到的场景关系都很相似,对模型性能提升不大。对于位置编码信息,它在场景关系建模的过程中提供了坐标信息,将实例节点的关注范围缩小,更精确地收集了场景相关上下文信息,因此,位置编码的使用是十分必要的。表5中,本文设置了一个未采用位置编码的4头注意力模块,结果显示识别准确率相比使用了位置编码的有所下降。
2.5 可视化结果分析
本文的场景图根据场景像素节点与个体节点以及群组节点的注意力关系来为它们提取场景的上下文特征作为特征增强信息。为了验证场景关系有助于这两种节点关注图像中与自身相关的场景特征,本文将场景关系可视化,通过可视化图分析两种特征对场景中的哪些实例关注度更高。本文将不同方法对于群组行为的预测结果标注在图像上,红色标签表示错误的预测结果,绿色标签表示正确的预测结果(参见电子版)。
1)个体—场景关系可视化 图4中,展示了各方法在识别个体动作时对整个场景的注意力关系。图4第一行是l-spike的示例,第二行是l-set的示例,从左至右三列分别是ARG、GAIM和本文的SRGN对图像的注意力可视化图。为方便展示,本文将所有个体对场景的注意力取平均,然后可视化在场景图像中。该可视化图以热图的形式呈现,红色的程度越深代表个体对这一场景区域关注度越高,则从该区域获得场景上下文信息就越多。
从图4中可以看出,ARG和GAIM的关注区域主要集中在球员身上,而忽略了球场周围的场景信息。第一行l-spike活动中,ARG主要关注左侧在网前蹲下的球员,这使模型认为这是l-pass活动。而GAIM关注左侧后撤的白衣球员,这导致模型认为这是一个l-set活动。第二行l-set活动中,本文方法和GAIM捕捉到了排球在左边二传球员的正上方,因此判断这是l-set活动,而ARG却将其忽略导致判断错误得到l-pass。总结本文方法中个体特征对场景信息的关注重点主要为以下两个方面:a)对场景中其他个体的关注,尤其是在群组互动中起到关键作用的个体,在以往的工作中也提出过,关键个体对其他个体的影响更大,例如第一行l-spike活动中正在做扣球动作的球员,她的扣球动作引起了整个群组行为的改变;b)场景中其他非球员的因素,例如第二行l-set活动中的排球,以及场边教练组对场上球员的指挥,这些场景上下文信息都是以往方法中没有重视的,而本文将这些信息作为个体的增强信息,使用场景关系图捕捉这些信息,并且取得了良好的效果。
2)群组—场景关系可视化 图5展示了各方法在群组特征的注意力可视化图,其中第一行是r-spike的示例,第二行是r-winpoint的示例。本文将群组特征对场景的注意力取平均然后可视化在场景图像中。本文设置的群组特征由个体特征和场景特征共同初始化,在场景关系图推理过程收集图像中的相关信息。
从图5中可以看到,ARG和GAIM都有不同程度的识别错误。第一行r-spike活动中,ARG将右边蹲下球员当做关键人物,得到了r-pass的识别结果。GAIM关注到左侧三名球员的动作,于是判断成l-pass。第二行r-winpoint活动中,活动的主体应该是场上庆祝的球员,但由于场边观众参与庆祝,导致ARG和GAIM关注区域偏移到左侧,都识别错误得到l-winpoint。而本文的SRGN能够准确地定位发生区域,得到准确的群组行为特征。本文方法中群组特征与场景关系的特点主要是:a)参与群组行为的个体以及周围区域的场景,即相比于个体—场景关系,群组—场景关系对个体特征关注范围更大,因为一个群组行为需要多个个体参与,所以一个群组行为需要关注的成员个数也更多;b)与个体特征相比,对场外信息的关注减弱,更关注场内提供的场景特征,这也是因为群组行为本身的特点,即个体动作以及它们之间相互作用构成了群组行为。在个体—场景关系图中已经为个体特征融入了其他区域的场景信息,所以群组行为只需要关注个体特征。相比于其他方法采用个体特征最大池来代表群组特征,本文方法直接从整个图像收集群组行为的相关信息可以得到准确的群组特征。
3 结束语
本文提出了基于场景关系图的群组行为识别方法,構建了一个场景关系图网络(SRGN)。该网络通过建立个体特征与场景像素点的关系解决了个体关系描述不准确以及个体关系图推理不可靠的问题。SRGN还使用了群组特征生成模块得到独立的群组特征,帮助提高群组行为识别准确率,解决了群组特征描述不准确的问题。对比实验证实了本文方法的有效性,后续工作可以考虑将场景关系图拓展到时间维度,实现时空场景关系建模。
参考文献:
[1]Ibrahim M S,Muralidharan S,Deng Zhiwei,et al.A hierarchical deep temporal model for group activity recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2016:1971-1980.
[2]Goyal A,Bhargava N,Chaudhuri S,et al.Hierarchical deep network for group discovery and multi-level activity recognition[C]//Proc of the 11th Indian Conference on Computer Vision,Graphics and Image Processing.New York:ACM Press,2018:1-7.
[3]戎炜,蒋哲远,谢昭.基于聚类关联网络的群组行为识别[J].计算机应用,2020,40(9):2507-2513.(Rong Wei,Jiang Zheyuan,Xie Zhao.Clustering relational network for group activity recognition[J].Journal of Computer Applications,2020,40(9):2507-2513.)
[4]Li Xin,Chuah M C.SBGAR:semantics based group activity recognition[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2017:2895-2904.
[5]Zappardino F,Uricchio T,Seidenari L,et al.Learning group activities from skeletons without individual action labels[C]//Proc of the 25th International Conference on Pattern Recognition.Piscataway,NJ:IEEE Press,2021:10412-10417.
[6]Ibrahim M S,Mori G.Hierarchical relational networks for group activity recognition and retrieval[C]//Proc of European Conference on Computer Vision.Berlin:Springer,2018:742-758.
[7]Shu Xiangbo,Tang Jinhui,Qi G J,et al.Hierarchical long short-term concurrent memory for human interaction recognition[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2019,43(3):1110-1118.
[8]Biswas S,Gall J.Structural recurrent neural network(SRNN) for group activity analysis[C]//Proc of IEEE Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE Press,2018:1625-1632.
[9]Shu Xiangbo,Zhang Liyan,Sun Yunlian,et al.Host-parasite:graph LSTM-in-LSTM for group activity recognition[J].IEEE Trans on Neural Networks and Learning Systems,2020,32(2):663-674.
[10]张天雨,许飞,江朝晖.基于时空自注意力转换网络的群组行为识别[J].智能计算机与应用,2021,11(5):77-81,87.(Zhang Tianyu,Xu Fei,Jiang Chaohui.Spatio-temporal transformer network for group activity recognition[J].Intelligent Computer and Applications,2021,11(5):77-81,87.)
[11]Gavrilyuk K,Sanford R,Javan M,et al.Actor-transformers for group activity recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:836-845.
[12]Li Shuaicheng,Cao Qianggang,Liu Lingbo,et al.GroupFormer:group activity recognition with clustered spatial-temporal Transformer[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:13648-13657.
[13]Han Mingfei,Zhang D J,Wang Yali,et al.Dual-AI:dual-path actor interaction learning for group activity recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2022:2980-2989.
[14]王傳旭,刘冉.基于交互关系分组建模融合的组群行为识别算法[J].计算机与现代化,2022(1):1-9.(Wang Chuanxu,Liu Ran.Group activity recognition algorithm based on interaction relationship grouping modeling fusion[J].Computers and Modernization,2022(1):1-9.)
[15]Wu Jianchao,Wang Limin,Wang Li,et al.Learning actor relation graphs for group activity recognition[C]//Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:9956-9966.
[16]刘继超,刘云,王传旭.基于核心人物和交互关系建模的群组行为识别[J].青岛科技大学学报:自然科学版,2022,43(3):98-106.(Liu Jichao,Liu Yun,Wang Chuanxu.Group activity recognition based on relationship network and core person modeling[J].Journal of Qingdao University of Science and Technology:Natural Science,2022,43(3):98-106.)
[17]Pei Duoxuan,Li Annan,Wang Yunhong.Group activity recognition by exploiting position distribution and appearance relation[C]//Proc of International Conference on Multimedia Modeling.Cham:Springer,2021:123-135.
[18]Hu Guyue,Cui Bo,He Yuan,et al.Progressive relation learning for group activity recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:977-986.
[19]李骏,程雅儒,谢昭.融合时间和空间上下文特征的群体行为识别[J].智能计算机与应用,2022,12(9):45-49,55.(Li Jun,Cheng Yaru,Xie Zhao.Group activity recognition based on temporal and spatial context features[J].Intelligent Computer and Applications,2022,12(9):45-49,55.)
[20]Lu Lihua,Lu Yao,Wang Shunzhou.Learning multi-level interaction relations and feature representations for group activity recognition[C]//Proc of the 27th International Conference on Multimedia Mo-deling.Berlin:Springer-Verlag,2021:617-628.
[21]Yuan Hangjie,Ni Dong,Wang Mang.Spatio-temporal dynamic infe-rence network for group activity recognition[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:7456-7465.
[22]劉斯凡,林国丞,秦建伟.基于选择性融合及关系推理的群组行为识别[J].计算机应用研究,2023,40(3):914-918,924.(Liu Sifan,Lin Guocheng,Qin Jianwei.Group activity recognition based on selective fusion and relational reasoning[J].Application Research of Computers,2023,40(3):914-918,924.)
[23]黄江岚,卿粼波,姜雪.融合场景及交互性特征的多人行为识别[J].四川大学学报:自然科学版,2022,59(6):77-88.(Huang Jianglan,Qing Linbo,Jiang Xue.Multi person behavior recognition based on scene and interactive feature[J].Journal of Sichuan University:Natural Science Edition,2022,59(6):77-88.)
[24]Tang Yansong,Wang Zian,Li Peiyang,et al.Mining semantics-preserving attention for group activity recognition[C]//Proc of the 26th ACM International Conference on Multimedia.New York:ACM Press,2018:1283-1291.
[25]Tang Yansong,Lu Jiwen,Wang Zian,et al.Learning semantics-preserving attention and contextual interaction for group activity recognition[J].IEEE Trans on Image Processing,2019,28(10):4997-5012.
[26]Qi Mengshi,Qin Jie,Li Annan,et al.StagNet:an attentive semantic RNN for group activity recognition[C]//Proc of European Conference on Computer Vision.Berlin:Springer,2018:104-120.
[27]Lu Lihua,Lu Yao,Yu Ruizhe,et al.GAIM:graph attention interaction model for collective activity recognition[J].IEEE Trans on Multimedia,2019,22(2):524-539.
[28]Yuan Hangjie,Ni Dong.Learning visual context for group activity re-cognition[C]//Proc of AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2021:3261-3269.
[29]Szegedy C,Vanhoucke V,Ioffe S,et al.Rethinking the inception architecture for computer vision[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2016:2818-2826.
[30]He Kaiming,Gkioxari G,Dollár P,et al.Mask R-CNN[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2017:2961-2969.
[31]Choi W,Shahid K,Savarese S.What are they doing? Collective acti-vity classification using spatio-temporal relationship among people[C]//Proc of the 12th IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2009:1282-1289.
收稿日期:2022-12-28;修回日期:2023-02-20基金项目:安徽省重点研究与开发计划资助项目(202004d07020004);安徽省自然科学基金资助项目(2108085MF203);中央高校基本科研业务费专项资金资助项目(PA2021GDSK0072,JZ2021HGQA0219)
作者简介:焦畅(1998-),男,安徽黄山人,硕士,主要研究方向为计算机视觉、群组行为识别;吴克伟(1984-),男(通信作者),安徽合肥人,副教授,硕导,博士,主要研究方向为计算机视觉(wu_kewei1984@163.com);于磊(1972-),男,安徽合肥人,讲师,硕士,主要研究方向為计算机视觉;谢昭(1980-),男,安徽合肥人,副教授,硕导,博士,主要研究方向为计算机视觉;李文中(1995-),男,河南信阳人,硕士,主要研究方向为计算机视觉.
