
结合特征对齐与实例迁移的跨项目缺陷预测
2023-10-17 12:07:01李莉赵鑫石可欣苏仁嘉任振康
计算机应用研究 2023年10期
李莉 赵鑫 石可欣 苏仁嘉 任振康


摘 要:为解决跨项目缺陷预测中源项目和目标项目分布差异较大的问题,提出了一种基于特征对齐和实例迁移的两阶段缺陷预测方法(FAIT)。首先,在特征对齐阶段,根据边缘概率分布进行特征的边缘分布对齐;然后,基于源项目和目标项目构建条件分布映射矩阵完成条件分布对齐;最后,在实例迁移阶段,通过改进了权重调整策略的TrAdaBoost方法构建跨项目缺陷预测模型。以F1作为评价指标,当目标项目有标签实例比例为20%时,FAIT性能最佳,且两过程特征对齐优于单一过程特征对齐。此外,FAIT的预测性能在AEEEM和NASA数据集上分别提高了10.69%、15.04%。FAIT在一定程度上解决了源项目与目标项目的分布差异,能够取得较好的缺陷预测性能。
关键词:跨项目缺陷预测;特征对齐;最大均值差异;实例迁移;TrAdaBoost
中图分类号:TP311.5 文献标志码:A 文章编号:1001-3695(2023)10-032-3091-09
doi:10.19734/j.issn.1001-3695.2023.02.0068
Cross-project defect prediction combining feature alignment and instance migration
Li Li,Zhao Xin,Shi Kexin,Su Renjia,Ren Zhenkang
(College of Computer & Control Engineering,Northeast Forestry University,Harbin 150040,China)
Abstract:To address the problem of significant distributional differences between source and target projects in cross-project defect prediction,this paper proposed a two-stage defect prediction method based on feature alignment and instance transfer (FAIT).In the feature alignment stage,FAIT aligned the marginal distributions of features based on their probability distributions.Next,this method constructed a conditional distribution mapping matrix based on both source and target projects to achieve conditional distribution alignment.Finally,in the instance transfer stage,it built a cross-project defect prediction model using an improved weight adjustment strategy for TrAdaBoost.FAIT achieves the best performance when the proportion of labeled instances in the target project is 20%,with F1 as the evaluation metric.Furthermore,dual-process feature alignment outperforms single-process feature alignment,and FAITs predictive performance improves by 10.69% and 15.04% on the AEEEM and NASA datasets,respectively.To some extent,FAIT addresses distributional differences between source and target projects and achieves good defect prediction performance.
Key words:cross-project defect prediction(CPDP);feature alignment;maximum mean discrepancy;instance transfer;TrAdaBoost
0 引言
隨着软件复杂度的不断增长,软件开发难度不断变大,由于开发过程不规范、需求理解错误等问题,导致软件中存在大量缺陷;而软件缺陷若无法尽早修正,将会带来巨大的人力物力损失[1,2]。软件缺陷预测技术可以帮助开发人员和测试人员尽可能早地识别出项目中存在的缺陷。目前,大部分缺陷预测工作集中于项目内,即对当前项目的历史信息进行挖掘分析,构建模型,然后对新版本进行预测[3]。但是对于新项目,没有足够的数据积累,无法保证缺陷预测性能。因此,跨项目软件缺陷预测(CPDP)应需而生,即基于其他项目训练模型对新项目进行预测。然而,源项目与目标项目之间通常因为业务和编程语言等因素不同导致数据分布存在较大的差异,该差异主要包括特征分布差异和实例分布差异。特征分布差异使得源项目和目标项目分属不同的知识空间,源项目的知识表现形式无法应用于目标项目;实例分布差异使得源项目大部分实例与目标项目实例关联程度较低,模型在源项目中学习到的实例信息在目标项目中的泛化能力不足。因此,跨项目软件缺陷预测首先需要减小源项目和目标项目之间的特征分布差异和实例分布差异。虽然现有研究已提出多种数据过滤策略以解决该问题,但是此类方法无论是在减小特征分布差异还是实例分布差异方面,都只注重源项目的数据选择而忽视了目标项目潜在的先验知识,导致跨项目缺陷预测性能提升受限。
针对上述问题,本文提出了一种结合特征对齐与实例迁移的跨项目缺陷预测方法(cross-project defect prediction based on feature alignment and instance transfer,FAIT)。FAIT方法包括两个阶段:在特征的分布对齐阶段,通过边缘分布对齐和条件分布对齐对特征进行迁移,使源项目和目标项目的特征在再生希尔伯特空间具有一致的分布;在实例迁移阶段,基于TrAdaBoost[4]方法并对其进行改进,给源项目中与目标项目具有相似分布的实例赋予更高权重,构建跨项目缺陷预测模型。
1 相关工作
跨项目软件缺陷预测技术通过有类标的其他项目(源项目)数据建立模型来尽可能地识别出被测项目中有缺陷的模块,是一个二分类问题。由于项目间程序语言等各要素不同,源项目和目标项目的特征分布及实例分布均可能存在较大差异。为探究跨项目缺陷预测的可行性,文献[5]基于回归方法对Jwrite项目进行跨项目预测,实验结果表明利用源项目对目标项目预测的性能优于随机预测,但无法达到同一项目之间的预测性能。近年来,研究人员已提出多种跨项目缺陷预测方法,其大致可以分为基于训练数据清洗的CPDP方法和基于迁移学习的CPDP方法两类。
1.1 基于训练数据清洗的CPDP方法
基于训练数据清洗的CPDP方法旨在通过对训练数据进行特征变换、特征选择[6]以及缺陷实例过滤[7]等操作进行数据预处理,为目标项目数据找到合适的源项目数据。
特征变换是根据特征之间的关系将原始特征集通过某种变换映射到一个新的特征空间内,在降低特征维度[8]的同时避免模型在源项目上过拟合。文献[9]认为不同源的数据会导致训练集结构复杂,不利于跨项目缺陷预测模型的训练,提出利用主成分分析(principal component analysis,PCA)对数据训练集进行特征变换以克服该问题。文献[10]基于PCA方法提出了核主成分分析(kernel principal component analysis,KPCA),通过对不同特性的核函数充分提取原特征的非线性关系,取得了较优的缺陷预测效果。文献[11]则进一步将具有不同表达能力的核函数进行组合,使变换后的数据保留更多主要成分,然后与集成学习结合提出了基于多核集成学习的跨项目软件缺陷预测(cross-project software defect prediction based on multiple kernel ensemble learning,CMKEL)方法,但该方法需要对所有特征进行多次核映射,当特征数量较多时计算代价较大。文献[12]在特征提取过程中实现了特征降维,不会出现文献[10]的维度灾难问题,它从统计学的角度分析了每个特征的16种描述性统计,将原始特征转换成16维的新特征。其中,采用方差、异种比率等描述特征取值的离散性;采用峰度和偏态等描述特征的形状;采用均值、中位数、众数等描述特征的集中趋势。
特征选择是从原特征中选取部分与类标关联性较大的优质特征组成新的特征集。文献[13]利用最大信息系数(maximal information coefficient,MIC)衡量特征与类标之间的关联程度,进而对特征进行过滤。虽然MIC是一种优秀的数据关联性衡量指标,但单一指标无法保证筛选结果的准确性。文献[14]考虑四种关联性衡量指标,基于Boruta算法、交替条件期望(alternating conditional expectation,ACE)、回归子集和简单关联分析四种指标进行特征非线性分析。由于使用多种衡量指标需要考虑特征选择结果的交集,所以在特征选择过程中会抛弃更多特征,导致更多信息丢失。文献[15]提出在多指标中选取top-k统计方法验证预分类的可接受性能,然后通过删除冗余指标来最小化top-k指标子集,并使用单因素方差分析检验测试了此类最小指标子集的稳定性。此方法是一种权衡方法,可在保证筛选结果准确性的同时避免信息丢失过多。
无论是特征变换还是特征选择,均是在项目内部对特征进行处理,源项目与目标项目特征处理并无关联,这就导致了在源项目内得到的特征集与目标项目内得到的特征集之间仍然存在著分布差异。本文考虑到该问题,在特征处理过程中关联源项目特征与目标项目特征,利用特征迁移技术对源项目和目标项目的特征进行对齐。
实例过滤是通过算法对源项目实例进行筛选,筛选出与目标项目分布相似最高的实例加入到训练集中。从目标项目角度出发,文献[16]使用Burak过滤法,对于每个目标项目的实例获取10个与其欧氏距离最小的源项目实例加入到实例集中。从源项目角度出发,文献[17]提出Peters过滤法,首先基于源项目选择距离最近的目标项目实例,然后再基于该目标项目实例选择与其距离最近的源项目实例,该双向选择策略使得从源项目中选择的实例不存在冗余。从全局和局部角度出发,文献[18]分析了全局实例选择和局部实例选择对跨项目缺陷预测模型性能的影响,在局部实例选择中使用不同的聚类方法对源项目实例进行聚类,实验表明聚类后的源项目可使模型具有更好的预测性能。
上述研究均对源项目实例进行筛选,这意味着需要丢弃源项目中的部分实例,同样会导致部分信息丢失。本文考虑到该问题,在实例处理阶段,利用TrAdaBoost的加权方式为源项目实例设置权重并进行动态调整,在不损失或少损失源项目信息的前提下,提高与目标项目分布相似较高的实例的权重。
1.2 基于迁移学习的CPDP方法
基于迁移学习的CPDP方法旨在设计具有强大学习能力和泛化能力的算法构建分类器。根据迁移对象的不同可以分为特征迁移和实例迁移两类迁移方法。
特征迁移通过算法对特征进行映射,使得源项目和目标项目在同一空间内具有相似的特征分布。跨项目缺陷预测中常用的是迁移成分分析(transfer component analysis,TCA),文献[19]利用TCA解决源项目和目标项目之间的分布差异问题,该方法通过训练得到一个特征变换矩阵,利用该矩阵同时对源项目特征和目标项目特征进行变换,为本文的边缘分布对齐提供了参考。文献[20]针对软件缺陷预测对TCA进行了扩展提出TCA+方法,通过添加定制的归一化规则来最小化源项目和目标项目之间的特征分布差异。文献[21]在TCA中引入流形学习,提出局部保留联合分布适配方法。缺陷预测可以借鉴联合分布适配思想,在边缘分布对齐后继续进行条件分布对齐。条件分布对齐的前提是目标项目具有类标,然而目标项目不存在类标。文献[22]在特征迁移过程中通过为目标项目生成伪类标的方式解决该矛盾,对目标项目中的实例与源项目中的实例按照距离进行匹配,将源项目实例的类标赋予目标项目实例。
实例迁移是根据目标项目中部分有类标实例,调整源项目中实例的权重,使得源项目与目标项目相适配的迁移方法。文献[23]介绍了基于代价敏感思想的权重更新策略:对于分布相似的源项目实例和目标项目实例,如果误分则增加权重,否则降低权重;对于分布差异较大的实例,如果误分则稍降低权重,否则降低更多的权重。文献[24]认为源项目中与目标项目相似的实例应该被分配更高的权重;文献[25]提出FeCTrA(cross-project software defect prediction using feature clustering and TrAdaBoost)方法,在特征迁移阶段借助TrAdaBoost从源项目中选择训练实例。TrAdaBoost是AdaBoost方法在跨项目缺陷预测中的应用,其权重更新策略为:如果误分源项目实例,认为该实例与目标项目冲突,降低该实例权重;如果误分目标项目实例,认为该实例很难被分类,提高其权重。该方法在一定程度上提高了跨项目缺陷预测性能,取得了比较好的结果。
2 FAIT方法
2.1 研究动机
软件缺陷预测利用历史版本库构建模型,对新模块进行缺陷预测,然而新项目(目标项目)并没有历史版本信息,无法获取训练实例。因此,需要基于遗留项目(源项目),利用迁移学习技术进行跨项目缺陷预测。遗留的源项目可提供充足的有类标训练实例,但是基于源项目构建的模型无法保证在目标项目上具有良好的、稳定的缺陷预测性能,其原因如下:
a)从特征分布角度考虑,源项目和目标项目之间存在着较为严重的分布差异,该差异会导致模型与目标项目的特征分布无法适配。为更加直观地探究源项目和目标项目之间的分布差异,本文以AEEEM数据集中的PDE(源项目)、ML(目标项目)和NASA数据集中的PC3(源项目)、CM1(目标项目)为例,对源项目和目标项目的特征分布进行了可视化,并计算了源项目和目标项目之间的最大均值差异(maximum mean discrepancy,MMD)衡量分布之间的距离,如图1所示。AEEEM数据集的源项目呈聚集分布,目标项目呈条形分布,源项目和目标项目之间的MMD达到了7.035 7。NASA数据集的源项目和目标项目呈现不同的聚集分布状态,但二者交集并不多,源项目和目标项目之间的MMD也较大。无论是定性的可视化结果还是定量的最大均值分布差异,均可以得出相同的结论,即源项目和目标项目之间存在较大的分布差异。因此,在进行跨项目缺陷预测前需要通过特征迁移对齐源项目和目标项目的特征分布。
b)从实例分布角度考虑,由于源项目与目标项目业务和程序语言等因素的不同,源项目中存在着冗余实例和无用实例,尤其是当源项目實例数目远大于目标项目时,无用实例会严重影响模型在目标项目上的分类性能。所以,需要对源项目中的实例进行选择。
特征分布差异和实例分布差异是导致跨项目缺陷预测性能不良的两类不同因素,本文分别从特征分布对齐和实例迁移两个方面进行研究。
2.2 方法流程
FAIT方法的流程如图2所示,该方法包括特征对齐和实例迁移两个阶段。
a)特征对齐阶段。该阶段包括两个过程:(a)根据源项目和目标项目的数据集构建边缘分布映射矩阵,通过该矩阵可得到边缘分布对齐后的源项目和目标项目数据;(b)生成目标项目伪类标,利用带类标的源项目和具有伪类标的目标项目构建条件分布映射矩阵,得到最终对齐的源项目和目标项目数据。
b)实例迁移阶段。从目标项目中选取少量带有类标数据加入训练集内,利用改进了误分权重调整策略的TrAdaBoost方法,经过迭代训练获得若干弱分类器。根据改进后的评估指标对弱分类器进行加权集成得到最终的强分类器。本文目标项目中有类标的实例选择比例为20%。
2.3 特征对齐阶段
源项目和目标项目通常存在着数据分布差异,该差异可分为边缘分布差异和条件分布差异两类。边缘分布差异是导致模型与目标项目特征无法适配的主要原因。特征对齐的最终目标是使得源项目上的条件概率与目标项目上的条件概率相同,即P(yS|XS)=P(yT|XT),其中XS和XT分别表示源项目数据和目标项目数据,yS和yT分别表示源项目数据和目标项目数据对应的标签。因此,本文特征对齐包括两个步骤:a)通过边缘分布对齐,使得源项目和目标项目特征具有类似的边缘概率分布;b)在步骤a)的基础上,通过条件分布对齐使得源项目和目标项目具有类似的条件概率分布。
2.3.1 边缘分布对齐
边缘分布对齐是在特征迁移过程中使得源项目和目标项目特征的边缘分布趋于一致的特征对齐方法。当源项目和目标项目处于不同的分布时,即P(XS)≠P(XT),将两个分布内的数据同时映射到同一个高维再生希尔伯特空间。在此空间内,最小化源项目和目标项目数据边缘分布距离的同时,最大限度保留其各自的内部属性。边缘MMD可衡量分布之间的距离,其计算公式如式(1)所示。
算法1首先使用输入的源项目数据集和目标项目数据集纵向拼接,构造矩阵X,其时间复杂度为O(N2);然后基于X和格拉姆矩阵计算公式可得到核矩阵,核矩阵能够将X映射到高维再生希尔伯特空间,时间复杂度同样为O(N2);借助于核技巧,将式(1)改写后需要计算矩阵L,通过对式(1)展开可得L的计算公式(式(3));其次,通过构造中心矩阵H1计算中间矩阵M,构造中心矩阵涉及矩阵相减操作,其时间复杂度为O(N2);计算中间矩阵M涉及矩阵乘法操作,时间复杂度可控制在O(N2)~O(N3);对中间矩阵进行特征分解能够得到用来进行特征对齐的矩阵W,特征分解的时间复杂度为O(N3);最后,利用特征对齐矩阵W与X相乘可得到对齐后的结果,拆分返回即可。由上述分析可知,算法1的时间复杂度为O(N3)。
2.3.2 条件分布对齐
条件分布对齐的目标是寻找一个变换A使得经过变换后的源项目数据和目标项目数据具有类似的条件概率分布,即P(yS|ATXS)≈P(yT|ATXT)。但是对于目标项目来说,并不存在yT,无法求得目标项目的条件概率分布。此处可利用源项目数据训练一个简单分类器Ψ,通过Ψ可获得目标项目上的伪标签T。同样在再生希尔伯特空间内最小化源项目和目标项目之间的条件分布距离,条件MMD的计算公式为
从Z中获取DS和DT返回。
算法2同样根据输入构造矩阵,并初始化Mc=0,Mc是由式(5)化简而来;然后开始迭代计算矩阵A,矩阵A是由求解式(6)得到的特征向量组成,是最终用来进行条件分布对齐的变换矩阵,分解特征向量时间复杂度为O(N3);在迭代过程中通过源域训练分类器,在目标域上获取伪标签,并基于伪标签更新具有类标信息的条件分布MMD矩阵Mc,利用Mc可优化矩阵A;迭代结束后利用变换矩阵A与Q相乘可得到对齐后的结果,拆分返回即可。算法2使用决策树作为分类器,训练分类器的时间复杂度可看做是O(N)。更新矩阵Mc的时间复杂度是O(N2),迭代次数T2是常数可忽略,最终获取对齐结果的时间复杂度是O(N2)。由上述分析可知,算法2的时间复杂度为O(N3)。
2.4 实例迁移阶段
本文采用改进的TrAdaBoost方法进行实例迁移。TrAdaBoost改进了项目内集成算法AdaBoost,采用错误率作为权重衡量指标,对源项目和目标项目采用两种相反的误分实例权重调整策略。然而,软件缺陷预测数据集存在类不平衡问题,错误率并不适合作为存在着类不平衡问题的数据集;此外,虽然TrAdaBoost的误分实例的权重更新策略提供了一个新的思路,但是其更新策略仍可进一步优化。基于此,本文从权重衡量指标和权重更新策略两个方面对TrAdaBoost进行改进,提出了RTrAdaBoost(refined TrAdaBoost)方法。RTrAdaBoost是FAIT实例迁移阶段用到的方法,属于FAIT方法的一部分。为更好地说明本文对TrAdaBoost方法的改进效果,下文涉及实例迁移的内容将采用RTrAdaBoost进行描述。
对于源项目来说,误分有缺陷实例,小幅度降低其权重;误分无缺陷实例,大幅度降低其权重。对于目标项目来说,误分无缺陷实例小幅度提升其权重;对于K近邻中异类实例数量等于K的实例,误分后不调整其权重;对于K近邻中异类实例数量小于K的实例,误分后大幅度提升其权重。所有实例的权重调整幅度是由其K近邻中异类实例数量自适应决定。对于源项目来说,误分的实例与目标项目冲突,仍然降低其权重,但是无缺陷实例属于类不平衡中的多数类,对模型负面影响更大,因此需要大幅度降低其权重;而有缺陷实例提供的信息更有助于模型识别缺陷,在降低冲突的同时仍希望保留缺陷信息,因此小幅度降低其權重。对于目标项目来说,K近邻中异类实例数量等于K的有缺陷实例完全分布于无缺陷实例中,是最易被误分的样本,如果不断提升其权重,会使得分类边界侵入到无缺陷实例一侧,证明1给出了该命题的数学证明。如果降低其权重,会导致其越来越容易被误分,而调整权重的目的是使得误分实例被分类正确,因此对该类实例权重不做调整;对于K近邻中异类实例数量小于K的有缺陷实例,由于其很难被分类,而且其提供的信息更有助于模型识别缺陷,所以大幅度提升其权重使得模型能够更准确地识别缺陷。对于无缺陷的实例被误分,仍需提高其权重,只是相对于有缺陷的实例提升幅度较低,目的是使得模型着重学习有缺陷实例的信息。
其中:EFt表示第t次迭代的弱分类器ht上的评估因子。
算法3 实例迁移
输入:特征迁移后的源项目数据Euclid Math OneDApS,有少量类标的目标项目实例Euclid Math OneDApLT和无类标的目标项目实例Euclid Math OneDApT。
输出:Euclid Math OneDApT的预测结果。
分别获取Euclid Math OneDApS、Euclid Math OneDApLT和Euclid Math OneDApT实例数量n、m′和m;
初始化有类标实例的权重w1=(w11,w12,…,w1n+m′),其中:
算法3首先统计了源项目、有少量类标的目标项目和无类标项目的实例数量,并基于实例数量计算了有类标实例权重以及权重更新参数β,上述每一步操作的时间复杂度均为O(1);然后迭代更新优化实例权重,在迭代中,首先计算第t次迭代的样本权重,然后训练一个弱分类器,通过改进的评估因子,根据式(12)调整实例权重,训练弱分类器的时间复杂度是O(N)。式(12)为权重调整的幅度添加了限制系数η,以此来实现不同实例权重调整幅度不同的更新策略,η的计算需要统计实例周围异类样本的数量,可通过KD树来实现,其时间复杂度为O(N log2 N)。迭代次数T3是常数可忽略,因此算法3的时间复杂度是O(N log2 N)。
3 实验结果分析
3.1 数据集
本文实验采用公开的软件缺陷预测数据集AEEEM和NASA。AEEEM每个项目均含有61个特征,其中包括线性衰减熵和权值衰退两类特征,并已被证明能够使得缺陷预测拥有更高性能。NASA作为缺陷预测中的经典数据集被广泛使用,具有普遍性和可信性。NASA和AEEEM数据集仅拥有一个共同的特征,因此可用来对比验证不同特征空间下缺陷预测模型的预测性能。此外,实验选取的项目在样本数和缺陷样本比例方面均同时满足较少、适中及较多的要求,以此探究源项目和目标项目样本数量缺陷样本比例对跨项目缺陷预测性能的影响。表1、2分别给出了AEEEM和NASA数据集中项目的详细信息。
3.2 评价指标
软件缺陷预测的工作是评估目标项目中的实例是否存在缺陷,最终的分类结果共有四种情况:有缺陷实例被正确分类,记为TP;有缺陷实例被错误分类,记为FP;无缺陷实例被正确分类,记为TN;无缺陷实例被错误分类,记为FN。根据上述四种情况,可得出其他度量指标:
a)精确度是指真正有缺陷的实例在所有被预测为有缺陷的实例中的占比,其计算公式为
b)召回率是指被正确预测为有缺陷的实例在所有真正有缺陷的实例中的占比,其计算公式为
c)F1度量是对精确度和召回率两个指标的综合衡量,被认为是一个在类不平衡问题中能够更好地对模型预测性能进行评价的指标。本文使用F1度量作为评价模型性能的评价指标,其计算公式为
3.3 实验设计
为了验证FAIT方法的有效性和预测性能、两过程特征对齐的合理性、RTrAdaBoost方法的必要性和先进性以及FAIT方法的参数设置,本文实验主要分析验证以下四个问题。
实验1 FAIT方法与目前优秀的跨项目软件缺陷预测方法的预测性能对比。目前在跨项目软件缺陷预测方向已存在多种优秀方法,本实验考虑与基于特征迁移和实例迁移的跨项目缺陷预测方法(FeCTrA)[25]、基于特征选择和TrAdaBoost的跨项目缺陷预测方法(FSTr)[10]、基于两阶段特征增强的跨项目缺陷预测(TFIA)[26]以及未改进TrAdaBoost的FSNTr四种基线方法进行对比。其中,FeCTrA同样从特征分布和实例分布两个方面缩小源项目和目标项目间的分布差异,并与TCA+、Burak过滤法、Peters过滤法等经典跨项目缺陷预测方法进行了对比且有非常明显的性能提升;FSTr改进了TrAdaBoost实例选择的评估因子,本文则是在该评估因子基础上对TrAdaBoost权重更新策略进行的改进;FSNTr同时使用了基于训练数据清洗和基于迁移学习的CPDP方法,采用单一核主成分分析对缺陷数据进行预处理,然后在处理后的数据中进行特征选择,最后利用未改进的TrAdaBoost进行缺陷预测,取得了较优的预测性能。FAIT在特征对齐阶段贪心地选择最佳特征并在分类阶段强化高度相关特征的重要性,创新性地将特征迁移与特征选择相结合。
实验2 FAIT方法的特征对齐包括两个过程,不同的对齐过程可以对齐不同的分布,对最终的预测性能影响也可能不同。本实验根据样本分布状态进行逐步对齐的过程性探究实验,包括只执行边缘分布对齐的单一过程和在前一过程基础上进行条件分布的两过程实验,验证了FAIT方法中两过程对齐的合理性和有效性。
实验3 FAIT方法在经过特征对齐后又进行了实例迁移,当源项目和目标项目特征分布对齐后不进行实例迁移可否获得较好分类性能和稳定性。若有必要进行实例迁移,那么RTrAdaBoost与TrAdaBoost相比是否具有先进性。因此,本实验考虑在实例迁移阶段对比三种情景下(不进行迁移、应用TrAdaBoost进行迁移和应用RTrAdaBoost进行迁移)模型的预测性能以验证FAIT方法的合理性。
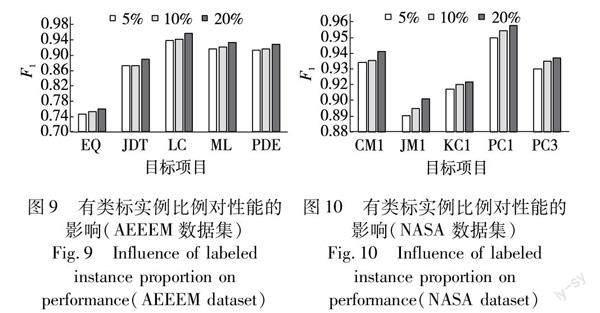
实验4 在实例迁移阶段,探究源项目中有类标实例占比对FAIT方法预测性能的影响。由于目标项目缺少类标信息,而人工标注需要耗费大量人力和物力,所以跨项目软件缺陷预测工作期望以少量的有类标实例获得较好的预测性能。根据实际开发情况,20%的标注工作量是可接受的。因此,本文考虑目标项目中20%、10%、5%的有类标实例比例分析其对FAIT方法性能的影响。
3.4 参数设置
本文选取目标项目中20%有类标实例加入到源项目中作为训练集,在实验过程中,每个项目互相作为源项目和目标项目进行一对一的跨项目软件缺陷预测。除实验4外,所有结果均采用10次跨项目5折交叉验证结果的平均值,即利用目标项目中20%有类标的实例作为训练集训练模型,然后对目标项目中其余80%无类标实例进行预测。
实验4中,对于20%的目标项目有类标实例,采取10次跨项目5折交叉验证;对于10%的目标项目有类标实例,采取10次跨项目10折交叉验证;对于5%的目标项目有类标实例,采取10次跨项目20折交叉验证。
3.5 实验结果分析
3.5.1 实验1的结果及分析
本实验选择AEEEM和NASA数据集,对FAIT方法的有效性和预测性能进行验证,利用决策树作为弱分类器,目标项目中有类标实例选择比例为20%,同时将FAIT方法与其他四种方法进行对比。采用F1度量作为评价指标,实验结果如表3、4所示。
在表3、4中,第一列表示源项目对目标项目的跨项目预测,代表不同的场景,如PDE→EQ表示源项目是PDE,目标项目是EQ;其他列表示在不同算法在不同源项目和目标项目下预测的F1值。AVG表示每种方法在该数据集上的平均性能,每行的最大值进行了加粗表示。
从表3、4的实验结果可以看出,FAIT方法的预测性能明显优于其余四种对比方法,在大部分场景下的表现均较好,能够取得更好的预测性能。在AEEEM数据集中,对于AVG,FAIT与FSTr、FSNTr、FeCTrA和TFIA相比分别提高了7.11%、10.76%、13.34%和11.53%,FAIT方法在20个场景下取得16次最优值。例如PDE→ML,FAIT方法的F1度量为0.934,相比于FSTr(0.868)、FSNTr(0.835)、FeCTrA(0.803)和TFIA(0.754),F1度量分別提高了7.60%、11.86%、16.31%和15.27%。FAIT未取得最优值的场景是EQ作为目标项目,而该类场景下TFIA均取得最优值。结合FSTr、FSNTr、FeCTrA三种方法在EQ项目上的表现来看,可能是因为EQ的数据分布非常适合TFIA方法。此外,还可以发现当目标项目为EQ时,五种方法在EQ上的表现均不如其他项目,可能原因是EQ样本数较少(324个)且缺陷样本比例较高(39.81%)。在NASA数据集上,FAIT方法全部取得了最优预测性能,即使是在与EQ类似的CM1数据集上仍有较大的性能提升。例如KC1→CM1,FAIT方法的F1度量为0.946,相比于FSTr(0.815)、FSNTr(0.805)、FeCTrA(0.807)和TFIA(0.851),F1度量分别提高了16.07%、17.52%、17.22%和10.04%。对于平均性能,FAIT与FSTr、FSNTr、FeCTrA和TFIA相比分别提高了12.89%、14.75%、19.43%和13.09%。
在基线方法中,FSNTr和FeCTrA均不加改进地使用了TrAdaBoost方法。在探究FAIT方法在两过程特征对齐后同样不加改进地使用TrAdaBoost方法的实验效果时发现,FAIT缺陷预测性能同样优于FSNTr与FeCTrA。在AEEEM数据集中,FAIT取得的F1度量均值为0.889,与FSNTr和FeCTrA相比分别提升了10.16%和13.83%;在NASA数据集中,FAIT取得的F1度量均值为0.930,与FSNTr和FeCTrA相比分别提升了14.39%和19.07%。因此,不仅可以认为FAIT方法优于FSNTr和FeCTrA,同时可以证明FAIT方法的两过程特征对齐优于FSNTr方法的两过程特征选择和FeCTrA方法基于聚类的特征迁移。
根据第2章中的论述可知,FAIT方法最坏的时间复杂度为O(N3)。基线方法中,FSTr、FSNTr需要进行矩阵分解,FeCTrA在特征迁移阶段采用的是基于特征相关度的聚类算法,时间复杂度均为O(N3),而TFIA方法最坏的时间复杂度可达到O(N5),还有可能存在无解状态。因此,FAIT方法在时间复杂度方面并不高于其他方法。
本实验可以证明,本文FAIT方法拥有更好的缺陷预测性能。
3.5.2 实验2的结果及分析
本实验通过只执行边缘分布对齐的单一过程对齐和执行在前一过程基础上进行条件分布的两过程对齐,探究FAIT方法中两过程对齐的合理性以及第二次对齐的必要性。为更直观地展示边缘分布对齐和条件分布对齐对样本分布的影响结果,以AEEEM数据集中PDE→ML和NASA数据集中PC3→CM1为例给出可视化图和MMD距离,如图3、4所示。
从可视化结果定性来看,PDE→ML的源项目呈聚集分布,目标项目呈条形分布。经过边缘分布对齐后,二者均趋于散射分布,此时源项目和目标项目分布较为接近。继续经过条件分布对齐后,二者均趋于V形分布,可明显看出二者分布更加的相似。PC3→CM1的源项目和目标项目呈现不同的聚集分布状态,但二者交集并不多。经过边缘分布对齐后,二者均趋于纺锤形分布,此时源项目和目标项目分布较为接近。继续经过条件分布对齐后,二者均趋于扫帚形分布,同样可明显看出二者分布更加地相似。
从MMD结果定量来看,PDE和ML原分布之间的MMD距离已经达到了7.035 7,经过边缘分布对齐后分布差异减小了95.50%,继续经过条件分布对齐后,分布差异又缩小了一个量级。PC3和CM1原分布之间的MMD距离是2.693 4,经过边缘分布对齐分布差异减为原来的一半,而继续经过条件分布对齐后,分布差异可以缩小2个量级。
为探究特征对齐过程对FAIT方法预测性能的影响,图5、6给出了单一过程对齐和两过程对齐F1度量的实验结果对比。
在图5、6中,横坐标代表不同的源项目对目标项目的预测,即不同的场景,纵坐标表示单一过程对齐和两过程对齐取得的F1度量值。从图5、6的实验结果中可以看出,两过程对齐的预测性能明显优于单一过程对齐,在绝大部分场景下的表现均较好,能够取得更好的预测性能,这与可视化的结果分析相符。在AEEEM数据集中,对于AVG,两过程对齐的F1度量(0.893)比单一过程对齐的F1度量(0.889)提高了0.45%。两过程对齐在20个场景下取得19次最大值。例如ML→EQ,两过程对齐的F1度量为0.746,相比于单一过程(0.761),F1度量提高了2.01%。在NASA数据集中,对于平均性能AVG,两过程对齐的F1度量(0.932)比单一过程对齐的F1度量(0.928)提高了0.43%。两过程对齐在20个场景下取得18次最大值。例如PC3→PC1,两过程对齐的F1度量为0.940,相比于单一过程(0.926),F1度量提高了1.51%。
两过程特征对齐的结果是优于单一过程的,可认为FAIT方法中设置两过程对齐具有合理性和有效性。
3.5.3 实验3的结果及分析
FAIT方法的过程包括特征对齐和实例迁移两阶段,特征对齐已经将源项目和目标项目的分布距离缩短。为了探究特征对齐后再进行实例迁移的必要性,以及RTrAdaBoost相对于TrAdaBoost的先进性,本文考虑AdaBoost(Ada)、TrAdaBoost(TrAda)和RTrAdaBoost(RTrAda)进行三组对比实验。使用F1度量作为评价指标,实验结果如图7、8所示。
在图7、8中,横坐标分别代表三种不同实例迁移方法,纵坐标代表其对应的F1度量值。由图7、8可以发现,经过实例迁移后,缺陷预测性能得到提升。例如,在AEEEM数据集中,经过实例迁移后AVG(0.889)比不进行实例迁移(0.831)提高了5.8%。此外,PDE做源项目时,实例迁移前后的缺陷预测性能大幅度提升,可能的原因是PDE中存在大量无用实例,因此为避免在跨项目软件缺陷预测过程中出现该类情况,应该进行实例迁移。在NASA数据集中,经过实例迁移后AVG(0.930)比不进行实例迁移(0.921)提高了0.98%。因此,在进行特征对齐后进行实例迁移是有必要的。
由图7、8还可以发现,在对TrAdaBoost改进后,缺陷预测性能进一步得到提升。在AEEEM数据集中RTrAdaBoost与TrAdaBoost和AdaBoost相比AVG分别提高了0.50%和7.52%,并在20個场景下取得18次最大值。例如ML→EQ,RTrAdaBoost方法的F1度量为0.761,相比于TrAdaBoost(0.744)和AdaBoost(0.754),F1度量分别提高了2.28%和0.93%。在TrAdaBoost的F1度量值下降时,仍可提高该场景的缺陷预测性能。在NASA数据集中RTrAdaBoost与TrAdaBoost和AdaBoost相比AVG分别提高了0.26%和1.26%,并在20个场景下取得16次最大值。例如KC1→CM1,RTrAdaBoost方法的F1度量为0.946,相比于TrAdaBoost(0.932)和AdaBoost(0.932),F1度量分别提高了1.50%和1.50%,在TrAdaBoost无法提升F1时仍可提升缺陷预测性能。此外,RTrAdaBoost比TrAdaBoost缺陷预测性能更加稳定,RTrAdaBoost在AEEEM和NASA数据集上F1度量的方差分别为0.005 166和0.000 402,而TrAdaBoost在两个数据集上F1度量的方差分别为0.005 393和0.000 419。
RTrAdaBoost比TrAdaBoost方法稳定性更高,缺陷预测性能更优,可以认为RTrAdaBoost具有先进性。
3.5.4 实验4的结果及分析
本实验考虑5%、10%和20%三种有类标实例比例加入到源项目中,以此探究目标项目中不同比例的有类标实例对FAIT方法预测性能的影响。因为人工标注实例费时费力,根据行业实际情况,本文考虑将该比例控制在20%以下,在减少开销的同时提升模型的缺陷预测性能。对于5%、10%以及20%的比例,可通过跨项目的20折、10折以及5折交叉验证完成。目标项目中有类标实例比例对FAIT方法缺陷预测性能的影响结果如图9、10所示。
在图9、10中,横坐标代表跨项目缺陷预测中的目标项目,纵坐标代表利用其他项目对该目标项目进行预测取得的平均F1度量值。从图9可以看出,当目标项目有类标实例比例从5%增加至10%时,F1处于较稳定的状态。但比例增加到20%时,与10%的比例相比,在EQ、JDT、LC、ML和PED中F1分别提高了1.06%、1.80%、1.62%、1.33%和1.36%,F1有非常明顯的提高。从图10可以看出,FAIT的缺陷预测性能随着有类标实例比例的增加而不断提升。当比例从5%增加到20%时,在CM1、JM1、KC1、PC1和PC3中F1分别提高了0.91%、1.43%、0.60%、0.97%和0.89%。对于JM1项目,虽然FAIT方法在该项目上的预测性能最低,但是当有类标实例比例增加时,该项目上的F1增长幅度却最大(分别为0.62%和0.81%)。主要是因为该项目样本数(7 720)过多,源项目中的样本无法完全适配该项目;但JM1缺陷样本数(1 612)充足,随着比例的增加,目标项目缺陷信息也更多,在该项目上的缺陷预测性能也随之提升。因此,在FAIT方法中,有类标实例的比例选定为20%比较合理。
4 结束语
本文提出了一种结合特征对齐与实例迁移的跨项目缺陷预测方法,在特征对齐中采用两过程特征对齐缩小源项目和目标项目间的边缘分布距离和条件分布距离,同时在实例迁移中对TrAdaBoost的误分类权重调整策略进行改进,以保证从源项目中选取较优的训练实例,继而实现实例迁移,构建跨项目缺陷预测模型。实验结果表明,该方法在跨项目软件缺陷预测中表现优异,缺陷预测性能明显优于现有优秀方法,在一定程度上提高了跨项目软件缺陷预测性能。
在接下来的工作中,将进一步探讨:a)分类器的集成策略对FAIT方法预测性能的影响,如对弱分类器分段集成;b)对数据进行预处理,进一步提高FAIT方法的有效性和鲁棒性。本文方法对于实例数量较多的目标项目(如JM1项目数为7 720)的预测性能可进一步提高,因此需要对数据进行预处理。下一阶段中,可以对实例过多的项目进行欠采样,采样的准则应该是不损失或少损失项目的特征分布信息;也可以对项目实例进行划分,对实例较多的项目进行多次跨项目缺陷预测。
参考文献:
[1]Aftab S,Ahmad M,Khan M,et al.Machine learning empowered software defect prediction system[J].Intelligent Automation and Soft Computing,2021,31(2):1287-1300.
[2]李冉,周丽娟,王华.面向类不平衡数据集的软件缺陷预测模型[J].计算机应用研究,2018,35(9):2806-2810.(Li Ran,Zhou Lijuan,Wang Hua.Software defect prediction model based on class imbalanced datasets[J].Application Research of Computers,2018,35(9):2806-2810.)
[3]杨丰玉,黄雅璇,周世健,等.结合多元度量指标软件缺陷预测研究进展[J].计算机工程与应用,2021,57(5):10-24.(Yang Fengyu,Huang Yaxuan,Zhou Shijian,et al.Survey of software defect prediction combined with multi-metrics[J].Computer Engineering and Applications,2021,57(5):10-24.)
[4]Dai Wenyuan,Yang Qiang,Xue Guirong,et al.Boosting for transfer learning[C]//Proc of the 24th International Conference on Machine Learning.New York:ACM Press,2007:193-200.
[5]Briand L C,Melo W L,Wust J.Assessing the applicability of fault-proneness models across object-oriented software projects [J].IEEE Trans on Software Engineering,2002,28(7):706-720.
[6]Pal S,Sillitti A.Cross-project defect prediction:a literature review [J].IEEE Access,2022,10:118697-118717.
[7]Zou Quanyi,Lu Lu,Yang Zhangyu,et al.Joint feature representation learning and progressive distribution matching for cross-project defect prediction[J].Information and Software Technology,2021,137(9):106588.
[8]Saifudin A,Yulianti Y.Dimensional reduction on cross project defect prediction [J].Journal of Physics:Conference Series,2020,1477:32011.
[9]Goel L,Sharma M,Khatri S K,et al.Defect prediction of cross projects using PCA and ensemble learning approach[C]//Proc of the 3rd International Conference on Micro-Electronics and Telecommunication Engineering.Singapore:Springer,2020:307-315.
[10]李莉,石可欣,任振康.基于特征選择和TrAdaBoost的跨项目缺陷预测方法[J].计算机应用,2022,42(5):1554-1562.(Li Li,Shi Kexin,Ren Zhenkang.Cross-project defect prediction method based on feature selection and TrAdaBoost [J].Journal of Computer Applications,2022,42(5):1554-1562.)
[11]黄琳,荆晓远,董西伟.基于多核集成学习的跨项目软件缺陷预测 [J].计算机技术与发展,2019,29(6):27-31.(Huang Lin,Jing Xiaoyuan,Dong Xiwei.Cross-project software defect prediction based on multiple kernel ensemble learning[J].Computer Technology and Development,2019,29(6):27-31.)
[12]He Zhimin,Shu Fengdi,Yang Ye,et al.An investigation on the feasibility of cross-project defect prediction[J].Automated Software Engineering,2012,19(2):167-199.
[13]Lei Tianwei,Xue Jinfeng,Han Weijie.Cross-project software defect prediction based on feature selection and transfer learning[C]//Proc of the 3rd International Conference on Machine Learning for Cyber Security.Cham:Springer,2020:363-371.
[14]Shakhovska N,Yakovyna V.Feature selection and software defect prediction by different ensemble classifiers [C]//Proc of the 32nd International Conference on Database and Expert Systems Applications.Cham:Springer,2021:307-313.
[15]He Peng,Li Bing,Liu Xiao,et al.An empirical study on software defect prediction with a simplified metric set[J].Information and Software Technology,2015,59(3):170-190.
[16]Yuan Zhidan,Chen Xiang,Cui Zhanqi,et al.ALTRA:cross-project software defect prediction via active learning and TrAdaBoost[J].IEEE Access,2020,8:30037-30049.
[17]Peters F,Menzies T,Marcus A.Better cross company defect prediction[C]//Proc of the 10th Working Conference on Mining Software Repositories.Piscataway,NJ:IEEE Press,2013:409-418.
[18]Herbold S,Trautsch A,Grabowski J.Global vs.local models for cross-project defect prediction:a replication study [J].Empirical Software Engineering,2017,22(8):1866-1902.
[19]黄燕,徐贤,虞慧群,等.一种特征转移和域自适应的异质缺陷预测方法 [J].小型微型计算机系统,2022,43(1):186-192.(Huang Yan,Xu Xian,Yu Huiqun,et al.Feature transfer and domain adaptation approach for heterogeneous defect prediction[J].Journal of Chinese Computer Systems,2022,43(1):186-192.)
[20]Nam J,Pan S J,Kim S.Transfer defect learning [C]//Proc of the 35th International Conference on Software Engineering.Piscataway,NJ:IEEE Press,2013:382-391.
[21]Li Jingjing,Jing Mengmeng,Lu Ke,et al.Locality preserving joint transfer for domain adaptation[J].IEEE Trans on Image Proces-sing,2019,28(12):6103-6115.
[22]Pan Yingwei,Yao Ting,Li Yehao,et al.Transferrable prototypical networks for unsupervised domain adaptation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:2234-2242.
[23]Du Xiaozhi,Yue Hehe,Dong Honglei.Software defect prediction method based on hybrid sampling[C]//Proc of International Confe-rence on Frontiers of Electronics,Information and Computation Technologies.New York:ACM Press,2022:article.No.93.
[24]何吉元,孟昭鵬,陈翔,等.一种半监督集成跨项目软件缺陷预测方法[J].软件学报,2017,28(6):1455-1473.(He Jiyuan,Meng Zhaopeng,Chen Xiang,et al.Semi-supervised ensemble learning approach for cross-project defect prediction[J].Journal of Software,2017,28(6):1455-1473.)
[25]倪超,陈翔,刘望舒,等.基于特征迁移和实例迁移的跨项目缺陷预测方法[J].软件学报,2019,30(5):1308-1329.(Ni Chao,Chen Xiang,Liu Wangshu,et al.Cross-project defect prediction method based on feature transfer and instance transfer[J].Journal of Software,2019,30(5):1308-1329.)
[26]Xing Ying,Lin Wanting,Lin Xueyan,et al.Cross-project defect prediction based on two-phase feature importance amplification[J].Computational Intelligence and Neuroscience,2022,2022:2320447.
收稿日期:2023-02-10;修回日期:2023-04-19基金项目:黑龙江省教育科学规划课题(GJB1421251)
作者简介:李莉(1977-),女(通信作者),河南孟州人,教授,硕导,博士,CCF会员,主要研究方向为先进软件工程、区块链、群智能优化、大型分布式计算等(lli@nefu.edu.cn);赵鑫(1998-),男,黑龙江海伦人,硕士研究生,主要研究方向为软件缺陷预测等;石可欣(1997-),女,山东聊城人,硕士,主要研究方向为软件缺陷预测;苏仁嘉(1998-),男,黑龙江大庆人,硕士研究生,主要研究方向为软件缺陷预测等;任振康(1996-),男,山东青岛人,硕士,主要研究方向为软件缺陷预测等.
