
基于相对熵和二元熵的多粒度直觉语言TODIM决策方法
2023-10-17 23:37:00郭奉佳高建伟陈炜
计算机应用研究 2023年10期
郭奉佳 高建伟 陈炜


摘 要:针对评估信息为多粒度直觉语言集的决策问题,提出一种基于相对熵和二元熵的TODIM方法。该方法首先定义了直觉语言数的相对熵和二元熵,以度量决策信息的差异和不确定性;其次,构建了基于相对熵和二元熵的专家赋权模型,并建立了主观权重完全已知、部分已知和完全未知场景下的属性赋权模型;最后,为集结多粒度群体决策信息,提出了多粒度直觉语言加权算术平均(MIL-WAA)算子。算例分析表明,该方法能够较好地度量决策信息的不确定性和差异性,并考虑了决策者的有限理性行为,具有一定的合理性和有效性。
关键词:多属性决策; 直觉语言集; 赋权模型; 相对熵; 二元熵
中图分类号:C934 文献标志码:A 文章编号:1001-3695(2023)10-009-2939-06
doi:10.19734/j.issn.1001-3695.2023.02.0059
Multi-granular intuitionistic linguistic TODIM method based on
relative entropy and binary entropy
Guo Fengjia1, Gao Jianwei2, Chen Wei1
(1.School of Management & Engineering, Capital University of Economics & Business, Beijing 100070, China; 2.School of Economics & Mana-gement, North China Electric Power University, Beijing 102206, China)
Abstract:To solve the decision problem in which the evaluations are multi-granular intuitionistic linguistic sets, this paper proposed a TODIM method based on relative entropy and binary entropy. Firstly, this method defined relative entropy and binary entropy of the intuitionistic linguistic sets to measure the difference and uncertainty of decision information. Secondly, it built an expert weighting model on the basis of relative entropy and binary entropy, and proposed attribute weighting models under the scenarios where the subjective weight was completely known, partially known and completely unknown. Finally, in order to gather the information of multi-granularity group decision information, this paper developed a multi-granular intuitio-nistic linguistic weighted arithmetic average (MIL-WAA) operator. The example analysis shows that this method can better measure the uncertainty and difference of decision information, and it considers the limited rationality behavior of decision-makers, so it is reasonable and effective.
Key words:multi-attribute decision-making; intuitionistic linguistic set; weighting model; relative entropy; binary entropy
0 引言
鉴于决策环境的复杂性和人类思维的模糊性,决策者倾向于采用“好”“一般”“差”等定性语言表述评估信息。Zadeh[1]首次定义了语言术语集以描述定性信息;Xu等人[2]提出了虚拟语言术语集,将离散的语言术语集拓展为连续形式。为合理量化语言术语集,同时避免决策信息的丢失和扭曲,Herrera等人[3]给出了二元语义变量。然而,语言术语集和二元语义变量仅反映了决策者的语义评估,未能体现决策者对自身评估的把握程度。为此,王坚强等人[4]定义了直觉语言集的概念,即在语言术语集的基础上增加了决策者对该语义评估的支持度、反对度和犹豫度。采用直觉语言集描述专家评估信息,既可表述语义评估值又可反映决策者对该语义评估的信心水平和犹豫程度,实现决策者不确定评估的细致表述。直觉语言集以其良好的信息表征特质,被应用于厂址优选、风险评估和投资选择等多屬性决策问题中[5]。
目前,针对直觉语言集的多属性决策方法已引起国内外学者的广泛关注,现有方法主要包括间接排序模型、直觉语言集结算子和直接排序模型三类。间接排序模型将直觉语言集转换为精确数或数值型模糊集,借助其决策方法实现方案的排序优选。例如刘宁元[6]将直觉语言评估信息转换为区间数,结合区间可能度函数提出直觉语言PROMETHEE决策方法;Gao等人[7]借助记分函数将直觉语言集转换为精确数,进而确定方案排序。间接排序模型具有计算简单的优势,但信息转换时存在原始信息的缺失和扭曲。直觉语言集结算子直接集成多维决策信息以获取备选方案的综合效益值。例如Wang等人[8]构建直觉语言集的有序加权几何算子和混合几何算子,据此集结多属性决策信息;杨艺等人[9]定义了带参数的Hamacher直觉语言算子,进而提出基于信息集结算子的多属性决策方法。基于集结算子的排序模型无须对原始信息进行转换,可有效避免原始信息的扭曲,然而该类方法通常基于期望效用理论,忽略了决策者的有限理性行为。直接排序模型借助直觉语言集的距离测度实现了方案的排序优选。例如高建伟等人[10]定义了直觉语言集的R-距离公式,进而提出基于累积前景理论的多属性决策方法;刘宁元[11]利用直觉语言集的距离测度提出了直觉语言TODIM方法。直接排序法既可刻画决策者的风险偏好态度,又可避免转换过程中的信息扭曲,可有效提高决策结果的合理性。
值得注意的是,直觉语言距离测度是直接排序模型的核心,然而,现有直觉语言集距离公式的测算精度仍有待提高。一方面,专家在实际决策评估时可能会选择不同粒度的语言术语集,而现有直觉语言距离公式无法度量多粒度直觉语言信息之间的差异;另一方面,现有距离公式通常将直觉语言集中包含的元素进行集成运算,未能合理度量各个元素的偏差。例如,文献[4]所提距离公式未考虑直觉语言集的犹豫度偏差;文献[10]将语言术语的下标与相对隶属度的乘积视为一个整体,据此度量直觉语言数之间的差异,当语言术语的下标与相对隶属度的乘积相同,而两个直觉语言数所含语言术语、隶属度和非隶属度存在偏差时,该公式无法度量其差异。此外,权系数的取值对决策结果至关重要。在专家赋权方面,现有方法可归纳为两类:a)利用个体决策矩阵与理想决策矩阵或其他个体决策矩阵的差异度确定专家重要度[12];b)根据个体评估矩阵的不确定程度确定决策者在方案评估时的把握程度[13]。目前尚未有学者结合差异度和不确定度来研究多粒度直觉语言环境下的专家赋权模型。属性权重的确定方法主要分为主观、客观和组合赋权法三类[14],其中组合赋权法综合了主、客观因素,可有效提高权重确定的合理性。然而,组合赋权法通常采用简单的加权平均或几何平均的方式对主客观因素进行组合处理,当主观权重信息部分已知或完全未知时,该类模型失效。
针对以上问题,本文首先定义直觉语言集的相对熵测度,以度量多粒度直觉语言集之间的差异,该相对熵可综合反映直觉语言集中语言评估值、隶属度、非隶属度和犹豫度的差异,有效提高现有距离公式的测算精度;针对专家赋权问题,定义直觉语言集的模糊熵及犹豫熵(二元熵),以量化评估信息的不确定性;进而结合二元熵和相对熵确定决策者的重要度,该赋权方法综合考虑了直觉语言信息的差异度和不确定度。针对属性赋权问题,分别建立了主观权重完全已知、部分已知和完全未知情景下的优化模型,然后结合专家赋权模型、属性赋权模型和多粒度直觉语言加权平均(MIL-WAA)算子提出多粒度直觉语言环境下的TODIM群体决策方法。最后将该方法应用于企业的投资决策中,验证了该方法的合理性和有效性。
1 预备知识
1.1 直觉语言集的基本概念
3 算例分析
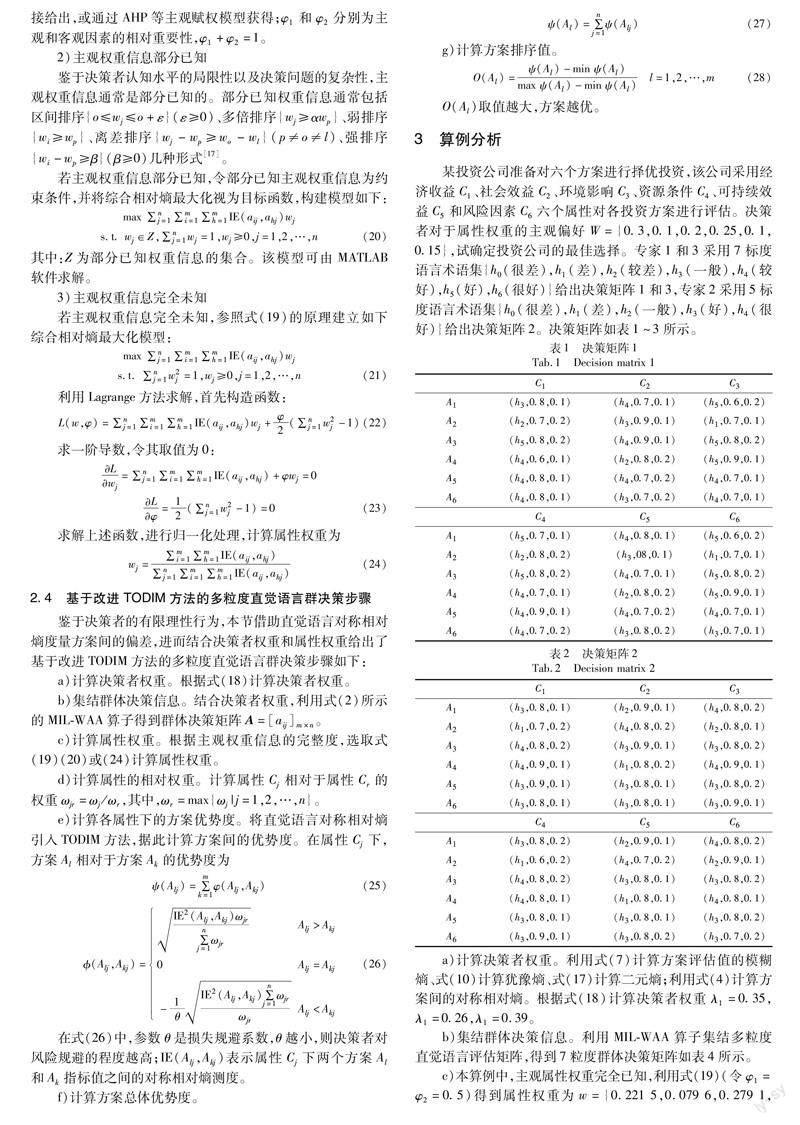
某投资公司准备对六个方案进行择优投资,该公司采用经济收益C1、社会效益C2、环境影响C3、资源条件C4、可持续效益C5和风险因素C6六个属性对各投资方案进行评估。决策者对于属性权重的主观偏好W={0.3,0.1,0.2,0.25,0.1,0.15},试确定投资公司的最佳选择。专家1和3采用7标度语言术语集{h0(很差),h1(差),h2(较差),h3(一般),h4(较好),h5(好),h6(很好)}给出决策矩阵1和3,专家2采用5标度语言术语集{h0(很差),h1(差),h2(一般),h3(好),h4(很好)}给出决策矩阵2。决策矩阵如表1~3所示。
a)计算决策者权重。利用式(7)计算方案评估值的模糊熵、式(10)计算犹豫熵、式(17)计算二元熵;利用式(4)计算方案间的对称相对熵。根据式(18)计算决策者权重λ1=0.35,λ1=0.26,λ1=0.39。
b)集结群体决策信息。利用MIL-WAA算子集结多粒度直觉语言评估矩阵,得到7粒度群体决策矩阵如表4所示。
c)本算例中,主观属性权重完全已知,利用式(19)(令φ1=φ2=0.5)得到属性权重为w={0.221 5,0.079 6,0.279 1,0.198 9,0.054 3,0.166 6}。
d)计算指标Cj相对于指标C+j的相对权重Rj={0.793 8,0.285 2,1.000 0,0.712 8,0.194 7,0.597 0}。
e)令θ的取值為1[11],计算方案Ai相对于Al的优势度。
f)计算总体优势度。计算方案Ai的总体优势度Z(A1)=-0.28,Z(A2)=-4.47,Z(A3)=0.22,Z(A4)=-1.85,Z(A5)=-0.28,Z(A6)=-0.71。
g)计算方案排序值。计算方案的排序值S(A1)=0.89,S(A2)=0.00,S(A3)=1.00,S(A4)=0.56,S(A5)=0.89,S(A6)=0.80。据此对备选方案排序为A3>A1>A5>A6>A4>A2,因此,公司选取A3为最优投资方案。
为验证所提决策方法的合理性和优越性,本文采用直觉语言加权平均算子[4]、直觉语言PROMETHEE方法[6]以及直觉语言TODIM方法[11]对本算例进行求解。因为上述方法均未涉及多粒度群体信息的集结,所以令群体决策信息为输入矩阵;此外,为保证决策结果的可比性,令指标权重为w={0.221 5,0.079 6,0.279 1,0.198 9,0.054 3,0.166 6}。方案优选结果如表5所示。
由表5可知,本文方法所得计算结果与利用直觉语言TODIM方法计算所得决策结果一致,但是,当利用文献[4]中的集结算子和记分函数计算该算例时,方案A4的排序结果与其他两种方法的排序不一致。此外,利用PROMETHEE方法无法计算本算例的排序结果,具体分析如下:
a)文献[4]基于集结算子和记分函数的决策方法认为方案A4为最优决策方案。由表4专家决策信息可知,方案A4在属性C1、C3、C4和C6下具有最优的表现值,而在属性C2和C5下的表现最差,若决策者完全理性,方案A4在C1、C3、C4和C6方面的优势可以弥补其在C2和C5方面的不足,因此,A4为最优决策方案。但是,该方法未考虑决策者的风险厌恶心理和损失规避态度,在实际决策中,A3在属性C2和C5下具有最优的表现值,同时在属性C1、C3、C4和C6下的表现处于中上水平,此时,决策者更偏向于选择方案A3来规避风险。本文提出的基于熵和二元熵的改进TODIM方法和文献[11]均有效度量了决策者的心理偏好行为,认为方案A3为最优方案。
b)直觉语言PROMETHEE方法首先将直觉语言数转换为区间数,并据此展开运算,然而当直觉语言数的犹豫度为0时,直觉语言数转变为实数,此时该方法在度量直觉语言数距离时失效。本文定义了基于直觉语言对称相对熵的距离测度,该测度可全面量化两个直觉语言数在语义值、隶属度、非隶属度以及犹豫度方面的偏差。
c)本文分别针对主观属性权重完全已知、部分已知和完全未知场景构建了优化赋权模型,而文献[4,6,11]中的决策方法直接给出了属性权重,但未给出科学的赋权模型,当属性权重未知时,决策模型失效。本文决策方法的适用范围更广。
d)本文考虑了属性值为多粒度直觉语言数的决策问题,而文献[4,6,11]均未考虑不同决策矩阵的评估粒度应有所不同。
4 结束语
本文提出了一种基于相对熵和二元熵的多粒度直觉语言TODIM群决策方法。为提高直觉语言信息测度的有效性,该方法首先定义了直觉语言数的对称相对熵,该公式度量了两个直觉语言集包含的语义值、隶属度、非隶属度和犹豫度之间的偏差,具有良好的测算精度,可有效解决现有距离测度在度量信息差异时出现的计算失准现象;其次,给出了直觉语言数的二元熵,模糊熵可以度量语义评估的模糊程度,犹豫熵可以刻画决策者对该语义评估的犹豫程度,二元熵结合了模糊熵与犹豫熵,可全面量化决策信息的不确定性。针对赋权问题,结合相对熵和二元熵构建了计及信息差异性和不确定性的专家赋权模型;同时建立了主观权重完全已知、部分已知、完全未知场景下的属性赋权模型,所建模型综合考虑了主、客观因素,可有效提高权重计算的合理性。最后,为集结多粒度直觉语言决策矩阵,定义了多粒度直觉语言加权算术平均(MIL-WAA)算子,结合集结算子和赋权模型,给出了直觉语言TODIM群决策方法,该方法有效刻画了决策者的有限理性行为特征。此外,鉴于群体决策规模的日益扩张,在未来的研究中将针对多粒度直觉语言环境下的大规模群体信息聚类共识展开分析。
参考文献:
[1]Zadeh L A. The concept of a linguistic variable and its applications to approximate reasoning[J].Information Sciences,1975,8(3):199-249.
[2]Xu Zeshui, Wang Hai. On the syntax and semantics of virtual linguistic terms for information fusion in decision making[J].Information Fusion,2017,34(2):43-48.
[3]Herrera F, Martinez L. A 2-tuple fuzzy linguistic representation mo-del for computing with words[J].IEEE Trans on Fuzzy Systems,2000,8(6):746-752.
[4]王坚强,李寒波.基于直觉语言集结算子的多准则决策方法[J].控制与决策,2010,25(10):1571-1574,1584.(Wang Jianqiang, Li Hanbo. Multi-criteria decision-making method based on aggregation operators for intuitionistic linguistic fuzzy numbers[J].Control and Decision,2010,25(10):1571-1574,1584.)
[5]Gao Jianwei, Guo Fengjia, Ma Zeyang, et al. Multi-criteria decision-making framework for large-scale rooftop photovoltaic project site selection based on intuitionistic fuzzy sets[J].Applied Soft Computing,2021,102(4):107098.
[6]劉宁元.基于PROMETHEE方法的直觉语言多属性群决策方法[J].统计与决策,2019,35(2):49-53.(Liu Ningyuan. Intuitionistic linguistic multi-attribute group decision-making method based on PROMETHEE method[J].Statistics and Decision,2019,35(2):49-53.)
[7]Gao Jianwei, Guo Fengjia, Ma Zeyang, et al. Multi-criteria group decision-making framework for offshore wind farm site selection based on the intuitionistic linguistic aggregation operators[J].Energy,2020,204(8):117899.
[8]Wang Xinfan, Wang Jianqiang, Deng Shengyue. Some geometric opera-tors for aggregating intuitionistic linguistic information[J].International Journal of Fuzzy Systems,2015,17(2):268-278.
[9]杨艺,李延来,丁恒,等.直觉语言Hamacher加权集结算子及其应用[J].运筹与管理,2021,30(1):87-93.(Yang Yi, Li Yanlai, Ding Heng, et al. Intuitionistic linguistic Hamacher weighted aggregation operators and their application[J].Operations Research and Management Science,2021,30(1):87-93.)
[10]高建偉,刘慧晖.基于累积前景理论的直觉语言风险型多属性决策方法[J].数学的实践与认识,2016,46(23):57-65.(Gao Jianwei, Liu Huihui. Intuitionistic linguistic risky multiple attribute decision making method based on cumulative prospect theory[J].Mathematics in Practice and Theory,2016,46(23):57-65.)
[11]刘宁元.考虑决策者心理行为的直觉语言多属性决策方法[J].运筹与管理,2019,28(7):11-16.(Liu Ningyuan. Multiple attribute decision-making method of intuitionistic linguistic considering psychological behavior of decision-maker[J].Operations Research and Management Science,2019,28(7):11-16.)
[12]刘久兵,彭莉莎,李华雄,等.考虑权重信息未知的区间直觉模糊三支群决策方法[J].运筹与管理,2022,31(7):50-57.(Liu Jiu-bing, Peng Lisha, Li Huaxiong, et al. Interval-valued intuitionistic fuzzy three-way group decisions considering the unknown weight information[J].Operations Research and Management Science,2022,31(7):50-57.)
[13]马珍珍,朱建军,张世涛,等.面向犹豫模糊语言信息的大型群体分类集结模型[J].控制与决策,2019,34(1):167-179.(Ma Zhenzhen, Zhu Jianjun, Zhang Shitao, et al. Classification-based aggregation model on large scale group decision making with hesitant fuzzy linguistic information[J].Control and Decision,2019,34(1):167-179.)
[14]肖勇,徐俊.基于组合赋权与TOPSIS的储能电站电池安全运行风险评价[J].储能科学与技术,2022,11(8):2574-2584.(Xiao Yong, Xu Jun. Risk assessment of battery safe operation in energy storage power station based on combination weighting and TOPSIS[J].Energy Storage Science and Technology,2022,11(8):2574-2584.)
[15]王坚强,王佩.基于直觉模糊熵的直觉语言多准则决策方法[J].控制与决策,2012,27(11):1694-1698.(Wang Jianqiang, Wang Pei. Intuitionistic linguistic fuzzy multi-criteria decision-making method based on intuitionistic fuzzy entropy[J].Control and Decision,2012,27(11):1694-1698.)
[16]高建伟,李响珍.基于概率语言术语信息的前景决策方法[J].计算机应用研究,2021,38(7):1973-1978.(Gao Jianwei, Li Xiangzhen. Prospective decision-making method based on probabilistic language terminology[J].Application Research of Computers,2021,38(7):1973-1978.)
[17]Ahn B S. Extreme point-based multi-attribute decision analysis with incomplete information[J].European Journal of Operational Research,2015,240(3):748-755.
收稿日期:2023-02-16;修回日期:2023-04-10
基金项目:国家自然科学基金资助项目(72071134,72071076);北京市属高校高水平科研创新团队建设支持计划资助项目(BPHR20220120)
作者简介:郭奉佳(1996-),女,山东临沂人,讲师,博士,CCF会员,主要研究方向为系统优化与决策;高建伟(1972-),男,河北无极人,教授,博导,博士,主要研究方向为新能源电力与低碳发展、系统优化与决策;陈炜(1975-),男(通信作者),宁夏固原人,教授,博导,博士,主要研究方向为量化金融与风险管理(chenwei@cueb.edu.cn).
