
面向神经网络结构搜索的植物叶片病害增强识别方法
2023-10-16 12:17代国威田志民樊景超王朝雨
西北林学院学报 2023年5期
代国威,田志民,樊景超,3*,王朝雨
(1.中国农业科学院 农业信息研究所/国家农业科学数据中心,北京 100081;2.河北水利电力学院,河北 沧州 061001;3.中国农业科学院 国家南繁研究院,海南 三亚 572025;4.广汉市中医院,四川 广汉 618399)
农业是食物、原材料和燃料的主要来源,有助于一个国家的经济增长。随着全球人口的迅速增长,农业正努力满足人类的需求。当前,植物病害加剧危及到全球粮食安全,每年造成全球10%~16%的作物损失,产量降低的同时也严重影响到粮食质量[1]。为了确保粮食安全和农业生态系统生存,及时准确地识别植物病害显得尤为重要。
农业中最活跃的研究领域之一是植物病害的早期诊断[2-3]。通过机器学习和计算机视觉在植物病害的早期诊断中取得了较好的成果,它们能以较低的成本给出更有希望的结果,在一定程度上解决了依赖于专业农艺师或植物病理学家鉴别植物病害的问题[4-5]。随着时间的推移,人们对这些技术的应用进行了更深入的研究,目标识别正开始向基于深度学习技术的研究方向转变[6-9]。因此,依靠基于深度学习技术提取植物病害特征模式对多种病害进行诊断的方法变得越发丰富。经典的AlexNet、GoogLeNet、VGGNet、ResNet与MobileNet网络在大量的植物病害检测中被证明是有效的[10-12],但它们大多基于实验室条件的数据集,如PlantVillage数据集,用于训练和评估,导致模型在模糊特征或与其他病害特征重叠的情况下对特征的选择与提取变得困难,进而影响到模型的性能。此后一些能够提取复杂特征的方法被提出,赵恒谦等[13]、苏仕芳等[14]利用迁移学习训练神经网络模型,将ImageNet预训练模型通过微调训练策略获得目标领域更好的学习效果,该方法在原始模型的基础上将识别精度提高10%以上。Ozyurt等[15]采用ResNet网络作为特征提取器,将3个ResNet网络提取的特征结合起来,用近邻成分分析选择最好的区分特征,并通过SVM分类器建立一个非常快速的番茄病害检测模型。黄英来等[16]针对玉米叶片病害识别正确率不高、速度慢等问题,提出一种基于改进深度残差网络模型的方法,与其他网络模型相比准确率大幅提升,鲁棒性进一步增强。Liu等[17]利用生成对抗网络实现葡萄叶片病害图像的数据增强,并在Xception模型上的识别准确率达到了98.70%。以上采用经典深层神经网络模型识别植物病害的方法,实质上是以扩展数据集、设计网络层数更深与结构更复杂参数量更大的网络实现精度的提升,但这使得训练模型需要耗费巨大的计算成本,模型复杂性与部署将变得困难。因此,人们开始研究如何实现对植物病害关键特征的提取。张宁等[18]、Zhao等[19]以及何自芬等[20]提出利用注意力机制加强骨干网络提取特征同时抑制无关信息干扰,并与多种卷积模块相结合以扩大卷积核的感受野和增强特征提取能力,最终构建了网络复杂性与计算资源相对合理的模型,但研究中端到端实时植物病害识别的问题仍未得到有效解决,因而研究轻量化的植物病害识别方法十分必要。刘阳等[21]、胡玲艳等[22]提出改进轻量级卷积神经网络SqueezeNet,精简了模型的参数并提升了检测精度和运算速度。Chen等[23]基于MobileNet模型匹配修改后的Inception模块作为主干特征提取器来提取高质量的图像特征,该嵌入式系统实现了高准确率的水稻叶部病害识别。上述方法在模型轻量化方面取得了一定进展,但神经网络结构的设计还是依赖于人工,对于不同的应用场景需要具备专业的知识及经验。因此,设计测试过程较为繁琐,效率低下,成本较高。
本研究提出一种基于神经网络结构搜索的植物叶片病害识别方法,能够自动建立植物叶片图像识别模型,采用堆叠的方式建立网络结构,并结合队列选取组内最优子结构,实现灵活建立病害鉴别模型的同时胜任多种环境下的部署需求,可帮助农民提高植物产量。
1 材料与方法
1.1 数据集的获取与预处理
试验采用位于格德拉的施里马塔维什诺德维大学提供的叶片图像公开数据集(https://www.agridata.cn/data.html#/datadetail?id=290327),该数据集由健康叶和患病叶共同组成,整个数据集包含12种在经济和环境上有益的植物,共计22种叶片类型,由4 503张图像构成,其中包含2 278张健康叶图像和2 225张患病叶图像[24]。采集的图像分辨率为6 000×4 000像素,格式采用JPG。植物病害种类见图1。

上下图分别表示健康叶与患病叶,0.芒果(Mango)叶,1.番茄(Arjun)叶,2.为鸡骨常山属(Alstonia scholaris)叶,3.番石榴(Gauva)叶,4.海南蒲桃(Jamun)叶,5.麻疯树(Jatropha)叶;6.水黄皮(Pongamia pinnata)叶,7.石榴(Pomegranate)叶,8.柠檬(Lemon)叶,9.悬铃木(Chinar)叶。此外,10.木橘(Bael)患病叶,11.罗勒(Basil)健康叶。图1 作物叶片数据集样本Fig.1 Sample of crop leaf data set
图像处理在PC机进行,主要算法由Anaconda3和Python3.8执行,其中Pytorch和OpenCV库由GPU使用和加速,操作系统采用Windows11专业工作站版,处理器选择Intel(R) Core(TM) i7-11800H处理器、32.00 GB内存,NVIDIA GeForce RTX 3060 Laptop显卡,图像分辨率为6 000×4 000像素。为方便试验,每幅图像大小裁剪为256×256像素,利用自适应缩放防止图片信息的丢失,位深度为24,从数据集抽出4 000张图像并按8∶2随机划分训练集与验证集,保留503张图像作为保留测试数据集。
1.2 基于Inception模块的VGGNet-16
在卷积神经网络(convolutional neural networks,CNN)中,提高深度神经网络(deep neural network,DNN)的特征提取能力最直接的方法是增加模型的深度或宽度,但这可能会导致2个问题:一是更深或更宽的模型结构通常会带来更多的参数,从而使扩大的模型容易过度拟合;二是模型参数的增加会使计算资源消耗的大幅提高[25]。为了克服以上问题并更有效地提取特征,Inception模块利用各种大小的卷积核并行层,并在模块末尾连接其输出,以实现特征的融合,提升网络对多尺度信息捕捉的适应性[26]。为降低模型计算成本,通过级联2个3×3的卷积替换单个5×5卷积来改进原始Inception模块,这在保持了感受野范围的同时减少了参数数量。由图2可见,改进后Inception模块由并行的1×1卷积、3×3卷积和2个级联的3×3卷积组成,它们位于最大池化层左侧,可以并行提取大量有用特征。此外,在并行卷积层前后采用1×1卷积,可以减少权重参数数量和特征图维度。
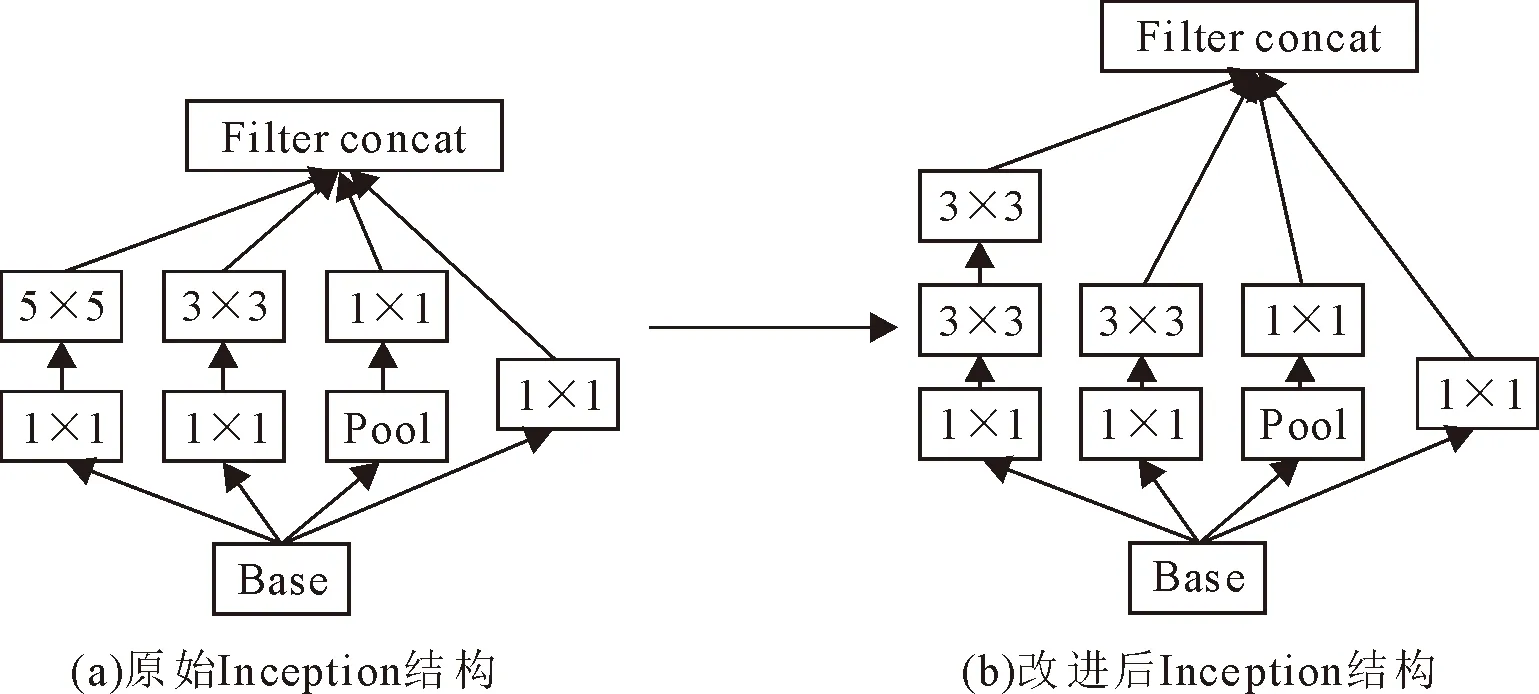
图2 改进Inception模块的结构Fig.2 Improving the structure of inception module
VGGNet是迁移学习中广泛采用的一种高度可移植的模型,VGGNet具有不同深度的网络层,例如VGGNet-11、VGGNet-13、VGGNet-16和VGGNet-19。在这项研究中,考虑VGGNet-19具有大量参数,因此将VGGNet-16指定为基础网络模型。
考虑Inception模块的上述特点,在VGG-16增加2个改进后Inception模块,以提高网络多尺度特征的提取能力,并解决植物病害检测中同一片叶子上有大小不一斑点的问题。改进后的VGGNet(VGG-INCEP16)模型的详细参数见表1。
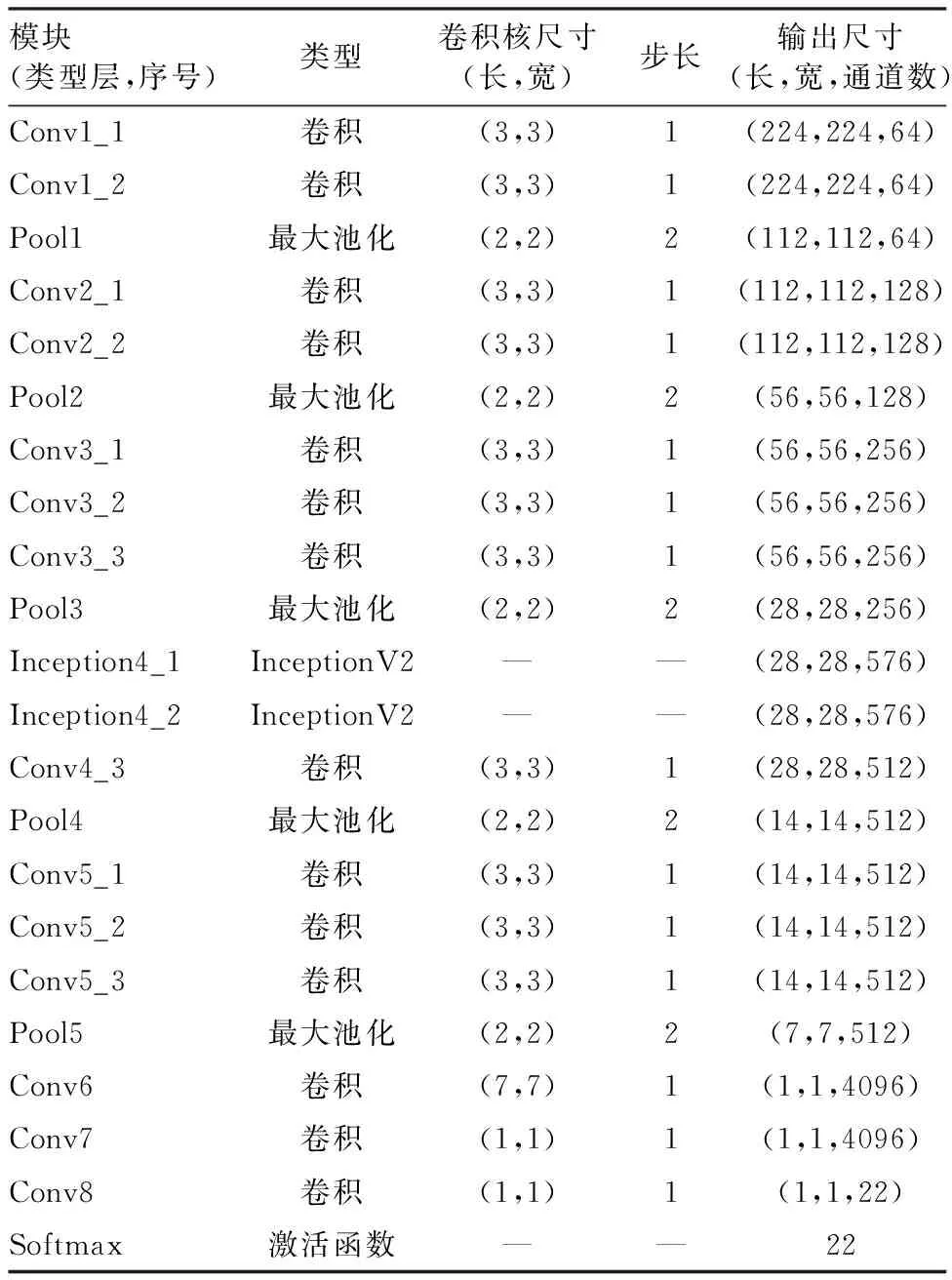
表1 VGG-INCEP16模型的详细参数Table 1 Detailed parameters of VGG-INCEP16 models
CNN前几层通常提取图像颜色、边缘和纹理特征,考虑改进Inception模块能够减小模型参数捕捉目标多尺度信息,提取这些特征的价值不大。因此,保留原始VGGNet网络结构的Conv1_1至Pool3层,用改进后的Inception模块替换VGGNet的Conv4_1和Conv4_2,以增强网络的多尺度特征提取能力。接着,将Conv4_3至Pool5层设置在Inception模块后。为了克服网络输入大小的限制,将VGGNet的全连接层Conv7与Conv8替换为1×1卷积,Conv6则采用7×7的卷积。最后一层是Softmax函数,以输出预测类别对应的预测概率值。
1.3 神经网络结构搜索架构
本研究提出了一种新的植物病害鉴定和分类方法,图3显示了方法的基本架构,该方法包括图像预处理、基于模糊c均值聚类(Fuzzy c-means clustering,FCM)算法的图像分割、斑点或感染特征提取和病害分类。在FCM阶段,采用模糊c均值聚类算法对预处理图像进行分割,可以降低k-means硬聚类可能出现的簇分离出错的问题,同时提高图像中有用信息的比例。分割获得的结果是目标感兴趣区域的信息,此步骤涉及从该首选区域中提取特征,但考虑特征的冗余性,方便提取重要特征,采用快速灰度共生矩阵(fast gray level cooccurrence matrix,FGLCM)对突出的视觉纹理特征进行提取和优化,取得的结果是叶片形状、颜色、颜色直方图等信息的一致性向量。从快速灰度共生矩阵计算提取6种常用易于计算且相关性较低的二级统计值作为叶片病害的纹理特征向量,并在主成分变换的帮助下选择权重较高的特征。为实现对提取特征信息的分类设计了一种神经网络结构搜索(neural network structure search,NNSS)方法,该方法能够渐进式建立神经网络结构并对植物病害鉴别,所形成的深度学习分类器可以以专家模型的形式存储。

图3 基于神经网络结构搜索的植物病害分类Fig.3 Plant disease classification based on neural network structure search
1.4 模糊c均值聚类图像分割
无监督FCM可以解决各种任务,如聚类、特征分析和分类器规划。在FCM过程中,每个明显的焦点被分配到一个簇中,从而将原始图像划分为不同的簇组合。聚类是通过反复减小每个像素在元素空间中与其聚类的距离来完成。
在一幅图像中,像素点具有很强的相关性。例如,突出区域的像素共享几乎相同的元素信息,因此,相邻像素之间的空间关系可以有效地指导图像分割。通过FCM,在模糊计算帮助下将像素分配到不同的类别。令X=(X1,X2,…,XN)为N像素的图像,在方程(1)中以尽可能低的成本重复执行聚类
(1)
式中:l为聚类的簇质心;N为像素着色信息的范围值;vj是集群模糊中心;uij是像素i对聚类j的隶属度关系;xi是单个像素的着色信息;V是集群大小,M是模糊常数的范围值,设置M=2。每个靠近其簇质心的像素被分配为高隶属度,而远离该质心的每个像素被分配低隶属度,基于成员关系完成聚类的方法步骤如下。
1)设X={X1,X2,X3,…,XN}为数据点的集合,V={V1,V2,V3,…,Vc}为中心集合。
2)随机选择c聚类中心。
3)计算模糊隶属度uij。
4)计算模糊中心Vj。
5)重复步骤2)和3),直到达到最小的j值或‖U(k+1)-U(k)‖<β。其中,k是迭代步骤,U=(uij)N*c是模糊隶属矩阵,β是[0,1]之间的终止标准,j是目标函数。
1.5 快速灰度共生矩阵特征提取
快速灰度共生矩阵与传统灰度共生矩阵相似,适用于消除不均匀的相关特征,但处理时间减小了约为200倍,在对邻近类边界的像素进行精确分类方面也优于传统的灰度共生矩阵(图4),考虑快速灰度共生矩阵对主要边界的影响,图4左侧矩阵为右侧4个相同矩阵之一,步长s为1表示经典的灰度共生矩阵。在步长s为1~16测量对去除特征质量的影响,对给定的处理时间进行归一化处理,以获得步长s为1的情况下相遇于其他步长的准备时间。可以得出结论,快速灰度共生矩阵可以大大缩短准备时间,大致缩短步长为2的系数,同时确保结构的卓越性[27]。
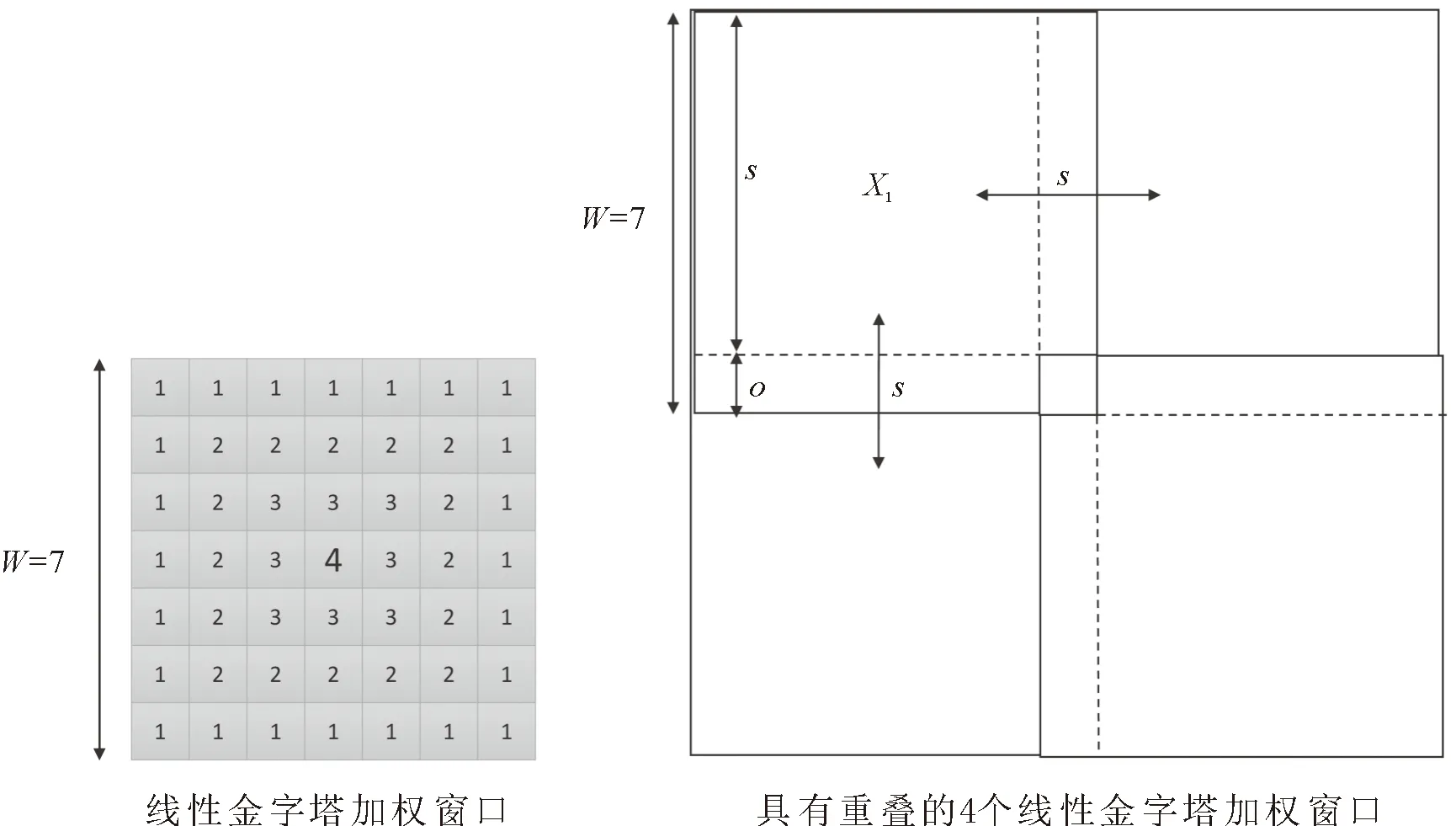
图4 灰度共生矩阵对图像显著区域的步长加速对比Fig.4 Comparison of GLCM step acceleration for significant areas of the image
为了评估快速灰度共生矩阵的有效性,一般做法是在每个周期中削弱灰度共生矩阵介质的权值,降低灰度共生矩阵的稀疏度,并对输入图像的灰度重新量化以降低图像的灰度级数。本研究将图像的灰度级数由256级降低到32级,因此,创建的灰度共生矩阵的大小为32×32,选用灰度共生矩阵的相关性(correlation)、能量(energy)、对比度(contrast)、同质性(homogeneity)、方差(variance)和熵(entropy)作为患病叶片分割处理后提取的主要特征。此外,为了防止这些特征向量过大或过小,需要对这些特征应用主成分变换(PCT)。
1.6 基于神经网络结构搜索的病害分类
CNN轻量级设计,传统方法主要依靠人工设计高效网络的计算方式来减少模型的参数和计算量,例如,减少卷积核数量、减少特征映射通道数量、设计高效的卷积操作模式。例如MobileNet、ShuffleNet与SqueezeNet等经典的轻量级神经网络模型都是通过上述方法设计的[28-30]。虽然这些人工模型取得了显著的成绩,但由于需要考虑层间连接方式、网络深度与卷积计算方法等各种因素,其设计需要大量的时间和人力资源。因此,为提高模型设计效率,本研究采用神经架构搜索(NAS)方法设计了具有轻量级和高识别精度的NNSS。
NAS是指通过特定的搜索策略,在特定的搜索空间中自动搜索出高性能CNN模型的方法。目前,NAS方法设计的CNN模型在图像分类和语义分割等视觉任务上表现出良好的性能。NAS的搜索空间可以分为全局搜索空间,用于直接搜索整个CNN架构,以及通过搜索和重复一些特定块结构形成整个CNN架构的局部搜索空间[31]。块架构搜索空间属于局部搜索空间的一种,它具有将搜索范围缩小到块的重复次数和卷积类型、卷积核大小、输出滤波器大小等特定块参数的特性。
经典NAS方法使用RNN作为控制器产生子网络,再对子网络进行训练和评估,得到其网络性能,最后更新控制器的参数。但是,由于每个子网络的性能不可导,导致无法直接对控制器进行优化,同时也不能直接深入到搜索块结构。因此,本研究采用了基于队列分块的局部搜索空间构造方法,该方法将CNN分解为不同的块,然后为每个块设置搜索空间,并在队列中选择优先级较高的块,从而有效地保证了构建模型的鲁棒性。基于此,本研究以相反的顺序来研究搜索空间,从最简单的块结构开始(表2),由只有1个块的B1结构开始建立所有可行的单元块配置,并将它们排列在1个队列中。然后,对队列中的所有单元进行评估和并行训练。接着,在B2的所有虚拟区块中,将每个块都扩大了1次。由于不可能训练和计算所有子网络,因此,本研究设计了一个基于访问单元的解释模块,将所有参与训练与评估的单元进行分析,解释过程可以是并发的。然后,所有包含块在内的单元都被分析处理,前K名优异的单元被保留在队列中。上述步骤重复进行,直到满足所有具有足够块的B被识别。

表2 神经网络结构搜索(NNSS)算法Table 2 Neural network structure search (NNSS) algorithm
NNSS确定最佳的块结构,需要预先确定数量的基本块被堆叠在彼此之上,同时参与堆叠的块结构形成单元。卷积参数根据训练次数的多少而改变,分类器是基于全局平均池化。就本研究数据集图像尺寸而言,为了降低计算成本,模型的起始部分设置为3×3的卷积核,stride使用2,只采用1种单元来缩小块的搜索空间。
2 结果与分析
2.1 模型评价指标
为了评价性能,计算了4个常用的指标:准确率(accuracy)、灵敏性(sensitivity)、特异性(specificity)与ROC曲线。分类结果分为真阳性(TP)、假阳性(FP)、真阴性(FN)和假阴性(TN)。在这种情况下,准确率是正确预测的数量(植物患病)与测试数据集样本总数的比率;灵敏度表明该模型所有真阳性中被准确分类的比例,衡量了分类器准确分类植物病害的能力;特异性反映了模型对所有假阴性中被准确分类的比例,衡量了模型准确识别健康植物叶片的检测能力;ROC曲线能够解决当测试集中的正负样本分布变化的时候,性能曲线保持不变。以上3项指标的取值范围均为0~1,值高表示模型分类能力强,其定义如下
(2)
(3)
(4)
2.2 结果与分析
将所提出的过程与其他先进方法进行比较,选择4个著名的AlexNet、GoogLeNet、InceptionV3和VGGNet-16模型作为基线方法进行对比实验[32]。应用迁移学习的方法,将网络头部的原始分类层截断,并在网络中嵌入一个新的FC Softmax层进行分类,其中类的数量被分配为植物病害类型的实际数量。以这种方式,这些CNN被创建并通过在ImageNet数据集上注入预先训练的权重来初始化权重参数。
在训练过程中,采用SGD算法配置各个网络的权值和偏差,以降低损失函数。SGD随机选择较小的训练集和样本量,样本量设置为32,学习率为0.001,较小的样本量保证了搜索的精度;动量设置为0.9,这决定了SGD收敛到最优解的速度。图5a显示了网络模型的特异性和灵敏性之间的关系,AlexNet,InceptionV3和VGGNet-16特异性和灵敏性数值波动相对较大,对比GoogLeNet最低波动范围超过了2.50%,而本研究提出的VGG-INCEP16是基于VGGNet-16改进的,在特异性和灵敏性性能表现方面波动范围仅为1.01%,与VGGNet-16相比波动值降低了1.99%,虽然改进导致特异性降低了1.99%,但灵敏性却提高了2.02%,综合性能比较提高了0.03%。通过NAS方法设计的NNSS取得了最优特异性和灵敏性,相对于次优性能的VGG-INCEP16特异性和灵敏性平均提高了4.43%,特异性和灵敏性波动差异仅为0.3%。在准确率方面,由图5b可见,NNSS达到了最高的准确性,对比改进的VGG-INCEP16与VGGNet-16分别提高了1.2%和2.1%。
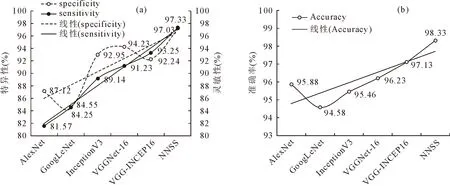
图5 网络模型的特异性、灵敏性与准确率Fig.5 Specificity,sensitivity and accuracy of network models
试验结果表明,NNSS方法提高了模型的精度。经典神经网络模型依靠人工设计模型结构的方式具有一定的局限性,例如数据分析受限于人的主观评价,因而设计产生的模型结构仅适用于部分数据集,虽可通过结构优化的方式提升模型性能,但结构优化并不适合所有数据集,并在多数情况下会带来更多的模型参数,故在轻量级模型场景下劣势明显。NNSS自动构造神经网络模型的方式使得模型可以自动适应多种数据集,这个过程不再依赖于人工,通过自动分析建立的模型结构能对样本特征充分学习,赋予分类器的样本特征权重更加确切,最终取得的模型参数量控制在预计范围内,因此NNSS方法可以得到较高的识别精度。
2.3 NNSS识别方法精度验证
基于保留植物病害数据集,利用NNSS自动建立神经网络模型的方法对12类植物24种叶片类型进行分类,得到的测试结果采用ROC曲线评价模型分类器的分类效果,植物病害预测结果与植物叶片真实所属类别的相关信息则通过混淆矩阵反映(图6、图7)。对于12类植物将10类植物的患病叶与健康叶组合进行精度评定,剩下的2类则采用单独标定的方式(表3)。
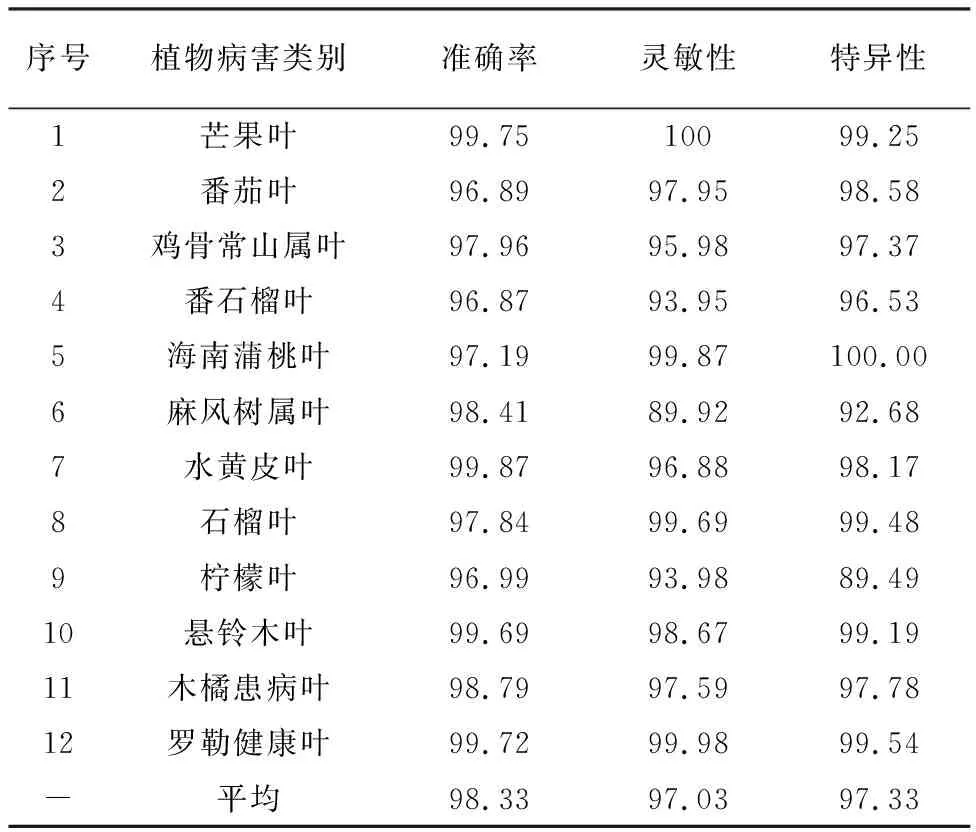
表3 NNSS方法在不同植物精度验证Table 3 Accuracy validation of NNSS method in different plants (%)
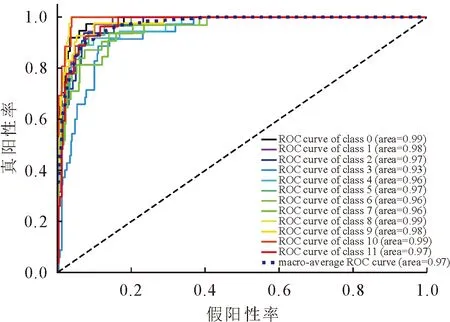
单个曲线表示一类叶片类型,各个曲线越靠近ROC曲线的左上角,对应曲线所占面积值越大,值越大说明模型整体性能越好。0~9分别表示健康叶与患病叶组合,10~11表示健康叶或患病叶。图6 植物病害测试数据集ROC曲线Fig.6 ROC curves of plant disease test dataset
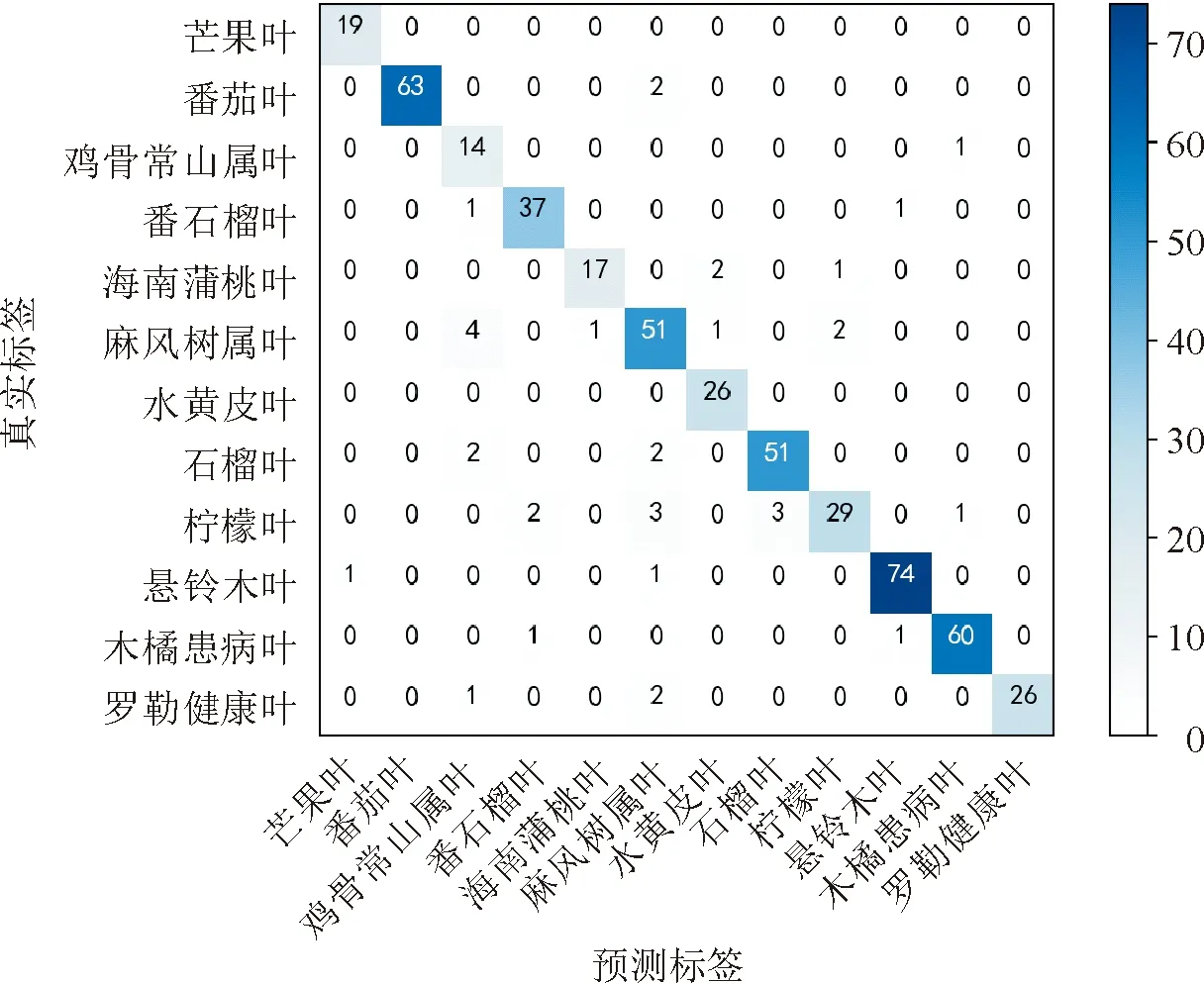
对角线深色区域上的值是预测的正确率,数值越大说明识别的准确率越高,而非对角线的值则是预测错误的比例。除木橘患病叶与罗勒健康叶表示单个叶子类别,其余分别表示健康叶与患病叶组合。图7 植物病害测试数据集混淆矩阵测试结果Fig.7 Confusion matrix test results for plant disease test dataset
从图6可以看出,所有类别的曲线普遍接近该图的左上角,平均ROC曲线达到了97%以上,这揭示了ROC曲线的理想工作点。此外,查看图7的混淆矩阵,所提出的NNSS方法已准确识别出图像类别。该方法共成功识别了19张芒果叶与26张水黄皮叶图像;麻风树叶类共59个实例准确鉴定了51个样本;除9个错误分类外,29个样本被提出的方法正确识别为柠檬叶类别。综上所述,在503个实例图像中正确识别了468个样本,其中将类别错误但正确识别的患病叶也归属于错误识别。由表3可见,在未见过的测试图像上平均识别准确率达到98.33%,平均灵敏性和特异性也分别实现不低于97.03%和97.33%。本研究提出的自动构建模型对麻风树叶与柠檬叶的识别能力稍弱,对其他9类病害的识别准确率均在98.00%以上,这是因为麻风树叶的患病叶与健康叶分辨特征不明显,而柠檬叶的患病叶展现的病害严重程度不同,患病斑点特征位置颜色较浅,不利于模型对的特征学习,所以识别错误率略高。
3 结论与讨论
为满足精准农业多元化的发展需求,提出基于神经网络结构搜索的植物叶片病害增强识别方法。通过模糊c均值聚类分割植物叶片图像,以关注叶片的感染点,然后,运用主成分变换通过快速灰度共生矩阵提取叶片特征,并形成特征向量供NNSS生成的模型进行分类。研究结果表明,采用基于神经网络结构搜索提出的NNSS方法可极大地提高生成模型的识别精度,平均准确率达98.33%,对比4类经典的神经网络模型特异性和灵敏性浮动差异仅为0.3%,具有较强的稳定性与鲁棒性。在未知的测试数据集验证,平均识别准确率为95.34%,ROC曲线覆盖区域达到了97%,相对于改进的VGG-INCEP16准确率提高了1.2%,特异性和灵敏性平均提高了4.43%。因此,该方法的使用在同类研究中具有显著的优势。
神经架构搜索(NAS)方法实现了生成网络结构的自动化,但过去研究中初始预定义了网络的基础性结构,后续自动搜索的网络结构在初始定义的网络结构基础上堆叠产生,因而与人工设计网络结构存在一定的相似性,自动搜索被限制在预定的搜索空间内。本研究提出的NNSS算法利用块架构搜索空间作为研究基础,网络结构搜索实现了并行化,搜索产生的局部块结构堆叠存储在队列中,基于访问单元的解释模块能够对队列进行优化,保留最佳的块结构单元,它能够为科研人员提供通用的网络结构空间搜索算法,辅助构想最佳的网络结构。自动建立的最优网络结构能够在限定的数据范围内取得较好的网络性能,但对于复杂的颜色纹理特征通常劣势明显,这是由于模型中的卷积核无法匹配特征参数造成的,通过调整卷积核参数一定程度上能够解决特征提取的问题,因而结合NNSS算法的同时需要及时对初始预定义的块结构单元做出人为调整,这揭示了本研究当前面临的问题。综上,所提出的NNSS方法相较于经典神经网络模型或经改进的神经网络模型,在模型性能上都有不同程度的提高。VGGNet选择Inception模块通过传统结构优化的形式改善模型性能,虽取得了一定的效果,但带来了更多的模型参数,而NNSS方法预先设定块搜索空间限制模型参数,在提升性能的同时维持模型轻量级的特征,可适应多种环境下的模型需求,这为植物叶片病害检测中的精度与模型参数量问题提供了潜在的补救措施。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
北京航空航天大学学报(2021年9期)2021-11-02
高技术通讯(2021年3期)2021-06-09
湖北农机化(2020年4期)2020-07-24
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
课程教育研究·学法教法研究(2017年12期)2017-07-12
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年1期)2016-11-07
现代农业(2016年6期)2016-02-28
