
多行人轨迹多视角三维仿真视频学习预测法
2023-10-13 12:23曹兴文郑宏伟吴孟泉王灵玥包安明
测绘学报 2023年9期
曹兴文,郑宏伟,刘 英,吴孟泉,王灵玥,包安明,陈 曦
1. 中国科学院新疆生态与地理研究所荒漠与绿洲生态国家重点实验室,新疆 乌鲁木齐 830011; 2. 中国科学院大学资源与环境学院,北京 100049; 3. 鲁东大学资源与环境工程学院,山东 烟台 264025
近年来,伴随智慧城市中智能交通系统(intelligent transportation system,ITS)的快速发展,领域学者对城市地理信息系统(urban geographic information system,UGIS)与智能视频系统(intelligent video system,IVS)融合研究不断深入[1-2]。智能视频系统中的多行人轨迹预测技术被广泛应用于自动驾驶、机器人导航、城市安全和视频监控等领域[3-7]。多行人轨迹预测作为一项极具挑战性的任务,难点之一在于如何有效对行人间的交互关系进行建模,这些关系将导致行人未来一系列运动行为,如为避免碰撞而加速、减速或转向,受他人阻挡而被迫跟随行走,以及其他复杂微妙的运动行为,而行进时人们会遵循一定社会准则来调整行进路线,这使得预测行人轨迹愈发困难。
早期研究侧重于手工设计特征来构建动力学或社会驱动模型表示行人行进过程中相互吸引和排斥情况[8-9],但手工设计特征的方法大多为均速线性预测器,只适用于匀速直线运动,未涉及预测非线性场景下行人轨迹和在复杂场景下表示隐含的人群交互行为。近年来基于循环神经网络(recurrent neural network,RNN)的数据驱动和图神经网络(graph convolutional network,GCN)的特征信息融合方法广泛应用于行人轨迹预测任务。目前,基于RNN数据驱动代表方法有社会长短时记忆模型(social long short-term memory,S-LSTM)[10]、基于社会生成对抗网络(social generative adversarial networks,S-GAN)[11]和基于社会规则和物理约束的生成对抗网络[12]。虽然基于RNN数据驱动方法较早期社会驱动模型在预测精度和交互建模上取得一定进步,但由于行人轨迹具有多模态性,即同一起点同一终点相同障碍,行人会有不同行动方式,而RNN类方法倾向于预测行人未来所有轨迹的平均值[13],这不符合轨迹预测多模态性的特点。基于GCN特征信息融合代表工作有社交注意力模型(social attention network,S-Atten)[14]、图注意力网络(graph attention network,GAT)[15]和时空图变换网络(spatio-temporal graph transformer network,STAR)[16]。上述GCN特征信息融合方法网络大多存在冗余度大,可解释降低问题,对行人交互建模时仅考虑两两交互,多人交互只是将信息简单融合,忽略行人群体之间的内在联系。
事实上,一个泛化效果强的行人轨迹预测模型,不仅能准确预测行人未来轨迹,还能应对不同视角变化,高效建模行人间的交互关系。现有基于RNN数据驱动和GCN特征信息融合的研究工作大多在单个或两个数据集内进行训练和测试,且对行人轨迹预测大多在固定视角摄像机[17]下进行,没有推广至多视角摄像机[18-19],不能自动适应新的视频场景,需要不断注释新数据来调整模型。目前,真实场景数据集还存在数据量不足、视角变化小和标注难等局限,而仿真数据作为物理世界信息的集成,能从虚拟场景中产生任意量具有完善数据分布和低成本定制化的标注数据。众多研究工作开始将仿真数据应用于视频检测、视频跟踪、动作识别和轨迹预测等任务[20-22],如文献[23]提出将CARLA仿真模拟器用于自动驾驶,文献[24]利用仿真模拟数据进行人类动作识别,文献[25]基于时空图变换预测虚拟场景中行人多未来轨迹,文献[26]利用仿真场景视频和场景语义分割特征相结合进行单目标行人轨迹预测。此外,领域内其他学者还通过深度神经网络(deep neural network,DNN)、Faster R-CNN、YOLOv4等目标检测方法对视频中运动目标进行检测追踪,而后使用预测算法进行轨迹预测[27-29]。
考虑到仿真数据在扩充现有真实数据集、模拟新视角的优势,本文提出一种多行人轨迹多视角三维仿真视频学习预测方法(multiple trajectory prediction-simulation 3D,MTP-Sim3D),用于构建行人间的交互模式并进行轨迹预测。该模型:①基于CARLA仿真模拟器[23]生成所需多视角轨迹标注数据,生成的多视角仿真视频序列无论行人外貌和运动轨迹都接近于真实视频序列,有效扩大行人轨迹预测数据集的数据量,MTP-Sim3D在仿真数据上进行训练,能应用于多视角场景行人轨迹预测;②基于图注意力循环神经网络(graph attention recurrent neural network,GATRNN),提出两阶段编码-解码网络,序列编码器通过检测跟踪算法获取行人观测序列,并对行人运动特征和交互信息进行编码,计算行人在场景中的时空状态,作为解码器的即时输入,粗位置解码器输出行人轨迹热图,细位置解码器生成符合规则的未来轨迹。在公开数据集试验结果表明,本文在多视角行人轨迹预测精度上得到很好提升,并能应用于摄像机拍摄未知视频序列,有较强泛化效果及可解释性。
1 多视角仿真数据学习的多行人轨迹预测方法
1.1 一般多行人轨迹预测问题定义
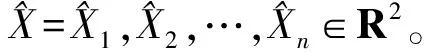
1.2 多行人轨迹预测模型网络结构
多行人轨迹多视角三维仿真视频学习预测方法(MTP-Sim3D)框架如图1所示,由4个模块构成。①三维仿真数据生成模块:CARLA仿真模拟器[23]生成不同视角的训练轨迹,通过多视角语义分割特征图进行表示;② 数据增强模块:从给定一组多视角轨迹K中选择最难学习轨迹和从原始视角中生成的对抗轨迹通过Mixup凸函数[30]进行组合,生成增强轨迹;③目标检测跟踪模块:使用对象关系检测器[31]和DeepSort[32]追踪算法对行人外观信息进行编码和跟踪;④轨迹预测网络模块:采用GATRNN作为基础网络,将增强轨迹和编码信息作为网络输入,实现多行人轨迹预测。
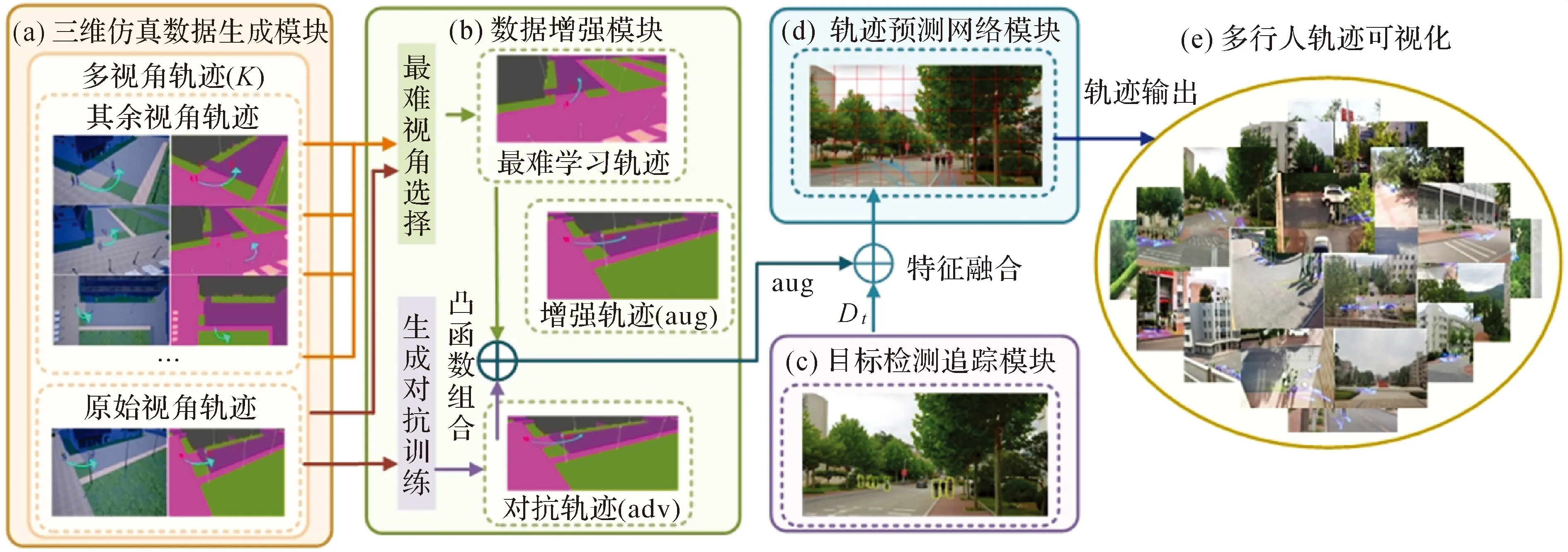
图1 多视角三维仿真视频学习的多行人轨迹预测模型Fig.1 Multi-pedestrian trajectory prediction model of multi-view 3D simulation video learning
1.3 多视角仿真轨迹数据生成

Ln+1:T={pn+1(xn+1,yn+1),pn+2(xn+2,yn+2),…,pT(xT,yT)}
(1)


(2)
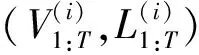
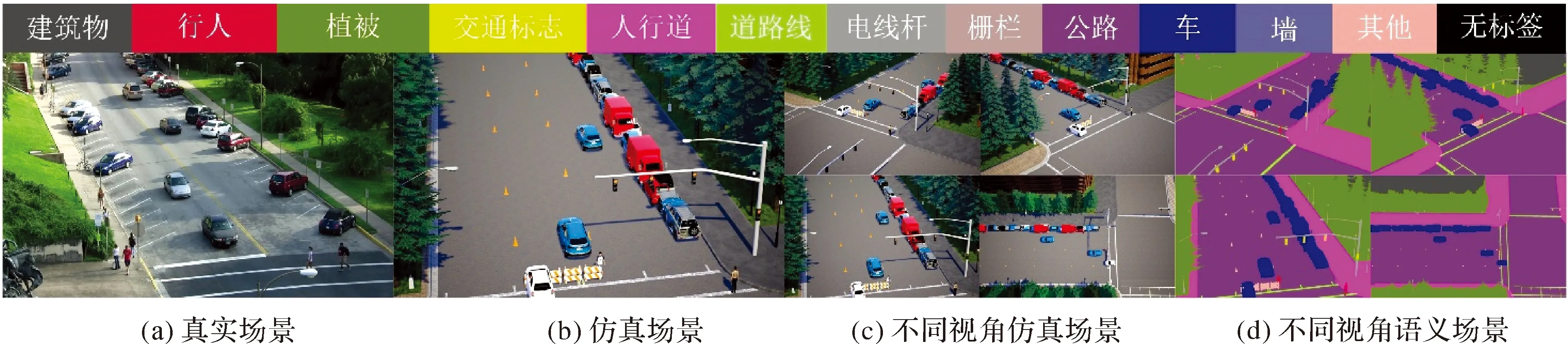
图2 多视角三维仿真数据可视化Fig.2 Visualization of multi-view 3D simulation data
1.4 多视角仿真轨迹数据混合增强
根据训练集中多视角轨迹集合K,每次给定一个多视角轨迹,将其作为锚点来搜索与模型所学内容最不一致视角,本文称为最难学习视角轨迹,受文献[36]提出的分类损失函数启发,将其作为给定视角轨迹与最难学习视角轨迹损失的计算标准
(3)

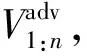
(4)
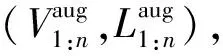
(5)
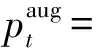
(6)
(7)
式中,λ由超参数α所控制的beta(α,α)分布求出;pt为式(2)中表示原始视角下的真实轨迹坐标;one-hot(·)函数将x-y二维坐标位置投影映射至轨迹预测网络模块中预定义网格上。
1.5 地理场景多行人检测跟踪方法
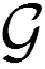

图3 多行人检测跟踪Fig.3 Multi-pedestrian detection and tracking
(8)
这种对数函数编码方式以几何距离和分数框的大小来计算几何关系,表示行人间未来轨迹更容易受到同伴或近距离物体影响。在行人追踪时,本文使用DeepSort和卡尔曼预测算法相结合框架[32]进行跨帧匹配,追踪过程中每个行人的状态被建模为8维状态空间
x=[u,v,γ,h,u′,v′,γ′,h′]
(9)
式中,(u,v)为目标边界框的质心;γ为边界框纵横比;h为高度;(u′,v′,γ′,h′)表示为图像坐标系下前一个状态变化速率。将(u,v,γ,h)和它们在图像坐标下各自速度作为卡尔曼算法初始状态,计算预测的卡尔曼状态和新到达的测量值之间的马氏距离,并通过式(10)来合并运动信息
(10)
式中,dj表示第j个检测框的位置;yi表示第i个追踪器对目标行人的预测位置;Ai表示检测位置与平均追踪位置的协方差矩阵。

(11)

ci,j=μd(1)(i,j)+(1-μ)d(2)(i,j)
(12)
式中,ci,j表示第i个跟踪目标和第j个检测目标之间的关联代价;μ表示超参数。检测跟踪过程结束后,对于t时刻的每个输入帧fH×W,通过式(13)定义一个矩阵Dt,其中包含了n个被检测行人在序列帧网格RH×W中的位置
(13)
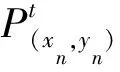
1.6 GATRNN预测多行人轨迹


图4 轨迹预测网络Fig.4 Designed network module for trajectory prediction
1.6.1 序列编码器
(14)

1.6.2 位置解码器
获取行人时空状态特征上下文向量H后,通过粗位置解码器预测行人在未来t时刻单位格网的置信状态Ct(i),即
Ct(i)=p(Yt=i|Yn:t-1,H),∀i∈G,t∈[n+1,T]
(15)
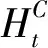
(16)
(17)

(18)
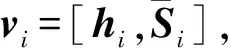
(19)

(20)
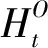
(21)
结合式(20)—式(21),使用式(22)表示行人在地理场景最终预测位置
(22)

1.6.3MTP-Sim3D模型训练
(23)
对于精细位置解码器,使用真实轨迹Ln+1:T={pn+1,pn+2,…,pT}作为训练标签,使用目标检测中smoothL1作为损失函数,即
(24)
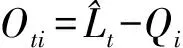
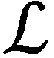
(25)
2 试验结果和分析
2.1 试验环境与数据集介绍
试验基于Tensorflow1.15建立网络模型,Python版本为3.6,Cuda版本为11.0。试验的训练和测试工作在Ubuntu 18.04服务器上进行,处理器为Intel(R) Core(TM) i9-10900K CPU @ 3.70 GHz、内存为128 GB、显卡为Nvidia RTX 3090 GPU。为验证MTP-Sim3D模型轨迹预测性能,选用不同摄像机视角和场景拍摄的真实视频数据集进行测试,包括ActEV/VIRAT[17,33]、ETH/UCY[39-40]、Argoverse[19]数据集和LDU数据集。ActEV/VIRAT数据集是NIST于2018年发布用于视频活动检测研究的公共数据集,包括不同视角下来自12个不同场景的455个每秒30帧分辨率为1080 P的视频;ETH/UCY包含ETH、HOTEL、ZARA1、ZARA2、UNIV 5个不同场景中1536位行人运动轨迹,轨迹数据均被转换为世界坐标系的坐标点,获取时间间隔为0.4 s坐标序列,所有场景均采用固定俯拍视角;Argoverse数据集是用于支持自动驾驶中3D跟踪与运动预测任务,包括3D tracking与Motion Forecasting两个子数据集。本文使用3D tracking数据集中的车载前置中心摄像机视角拍摄验证集视频;LDU场景为本文在校园拍摄的视频序列,用于测试所提出模型泛化能力,包括不同摄像机视角下60个每秒30帧分辨率为1080 P的多行人步态视频。与之前采用的留一法[10]不同,本文只在仿真三维数据上进行训练和验证,在ETH/UCY、ActEV/VIRAT、Argoverse、LDU等多视角或新场景数据集上评估模型泛化能力。
2.2 参数设置与评价指标
MTP-Sim3D模型建立在图注意力循环神经网络上,通过标准数据增强方法(水平翻转和随机输入抖动等)对训练集进行扩充。数据增强中原始视角采用Targeted-FGSM对抗攻击学习方法生成对抗轨迹,迭代次数设置为10。式(4)—式(6)中参数ε=δ=0.1,α=0.2,式(25)中λ1=0.5。轨迹预测网络模块中编码器和解码器使用ConvLSTM网络结构,嵌入尺寸设置为32,编码器和解码器隐藏层尺寸均为256。对于视频行人检测和场景语义特征提取,本文利用预训练的目标检测模型提取行人包围框和外观特征,并进行编码;在ADE20k数据集上预训练deeplab模型中提取场景语义特征。模型采用Adam优化算法更新模型参数,初始学习率设置为0.3,权重衰减为0.001。
为了判断模型性能优劣,将模型与现有方法进行比较,根据文献[10]关于行人轨迹预测任务定义,MTP-Sim3D模型在测试时先观察每个行人3.2 s(8帧),并预测未来4.8 s(12帧)行人的轨迹,并使用两个指标来评价预测轨迹准确性。
(1) 平均偏移误差(average displacement error,ADE):预测轨迹每一时刻t下真实坐标序列和预测坐标序列间的平均欧氏距离,计算公式为
(26)
(2) 最终偏移误差(final displacement error,FDE):预测最终结束时刻的预测坐标序列与真实坐标序列间的误差,计算公式为
(27)
2.3 多行人轨迹预测定量分析
2.3.1 MTP-Sim3D模型消融试验

表1 本文算法MTP-Sim3D在调整指定模块下的ADE/FDE比较结果
2.3.2 ActEV/VIRAT和Argoverse多视角数据集精度评价
本文将MTP-Sim3D模型在ActEV/VIRAT和Argoverse多视角数据集上进行试验,与S-LSTM[10]、S-GAN[11]、Next[5]、Multiverse[22]、SimAug[26]等基线模型进行对比,在ActEV/VIRAT和Argoverse数据集精度评价是以像素为单位,试验结果如表2所示,前5行模型在ActEV/VIRAT真实场景数据集进行训练。由表2可知,本文方法在多视角公共数据集上的评估指标上都优于其他基线方法,MTP-Sim3D在ActEV/VIRAT数据集上ADE和FDE较Multiverse分别提升4.2%和2.5%,在Argoverse数据集上ADE和FDE较SimAug方法分别提升3.7%和1.6%,因为MTP-Sim3D通过多视角仿真数据提升模型的整体,所有的仿真数据均可以通过CARLA仿真模拟器[23]生成,无须对真实轨迹进行额外注释,解决真实训练数据量不足,标注难问题。模型在ActEV/VIRAT真实场景数据集上进一步微调,与基线模型相比,在ADE和FDE预测精度均取得最优。
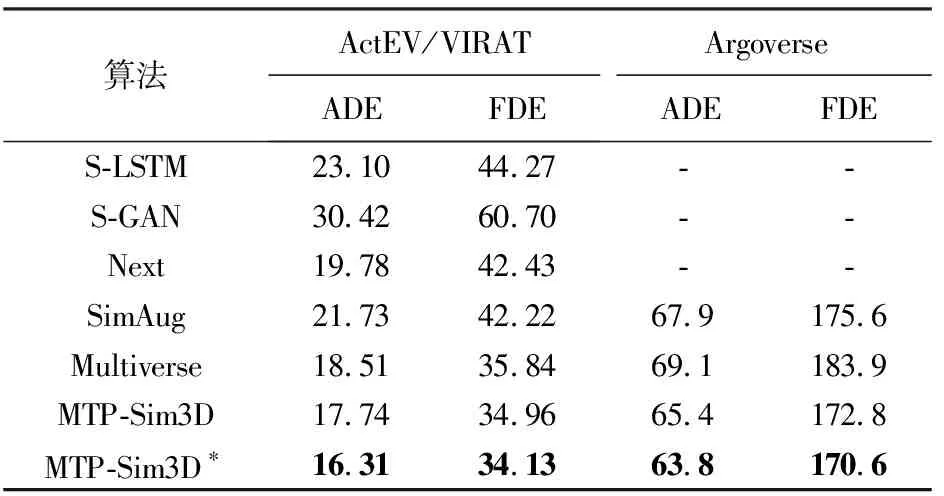
表2 不同方法在多视角数据集的ADE/FDE对比
2.3.3 ETH/UCY固定视角数据集精度评价
在ETH和UCY固定视角数据集上进行试验,同时选取当前主流的行人轨迹预测算法进行对比,如S-LSTM[10]、SoPhie[12]、S-GAN[11]、Next[5]、S-Atten[14]、STGAT[15]和STAR[16],试验的ADE和FDE见表3,表中黑体为表现最好的预测结果。由表3可知,MTP-Sim3D模型在ADE和FDE的平均值上优于S-LSTM、SoPhie、S-GAN、Next、S-Atten、STGAT、STAR,取得了最佳性能。MTP-Sim3D在UNIV数据集上ADE和FDE均优于其他对比算法,是由于UNIV场景为大学校园路口,行人密度大,且长时间停留在摄像机视野中,行人前进目标明确,而本文模型基于图注意力和生成对抗网络训练,对于长时间固定视角下的多行人轨迹预测表现突出。S-Atten和S-LSTM模型在UNIV和ZARA2场景下,ADE和FDE与MTP-Sim3D模型相差较大,原因是它们只捕获个体的运动信息,没有获取行人之间的交互信息。在这两个交互行为丰富的场景数据集中,交互信息缺失将导致预测结果与真实结果偏离较大。相较于SoPhie、Next和S-GAN算法分别使用场景信息、行人姿态信息和生成对抗网络预测行人轨迹,而MTP-Sim3D融合多视角增强轨迹和行人外观信息, 更有利于在各种场景中泛化。由于ETH数据集较小,MTP-Sim3D与其余对比算法在ETH表现都一般,但在FDE上取得最佳预测精度。与使用图注意力神经网络的STGAT和STAR相比,MTP-Sim3D通过三维仿真学习和图注意力循环神经网络(GATRNN)建立行人与场景交互模式,加强了对行人自身运动特性的挖掘,使算法具有较强语义解释性,在5个数据集上平均ADE上与STAR持平,比STGAT高4.7%,平均FDE上比STAR提升5.7%,较STGAT高1.2%,试验结果证明MTP-Sim3D在预测多视角行人未来轨迹具有稳健性。
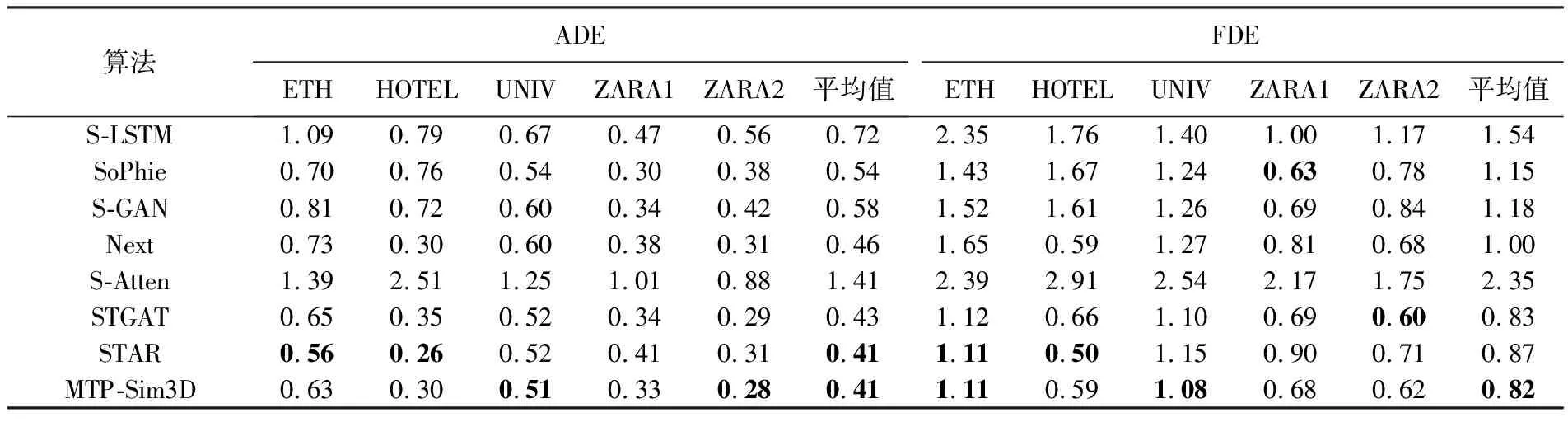
表3 不同方法在各数据集的ADE和FDE
2.4 行人轨迹预测可视性分析
2.4.1 行人检测跟踪可视化
本文在测试场景下对行人轨迹进行可视化,图5为MTP-Sim3D模型在各数据集上观测3.2 s内的行人检测跟踪可视化效果,其中每个数据集可视化结果的第1列都表示观测开始时对象关系检测器检测各场景中行人,第2列中蓝色轨迹表示经过观测时间(3.2 s)内行人行走路径,第3列表示结束时刻行人最终位置。由图5可以看出,基于对象关系的监测器能有效对场景中行人外观特征进行编码,进行多行人检测,在行人密度大且长时间停留的场景中依然保持高准确率和实时性。

图5 行人检测追踪可视化Fig.5 Pedestrian detection and tracking visualization
2.4.2 行人轨迹预测热图可视化
本文同时在各数据集进行行人轨迹预测热图可视化,进一步分析本文算法的语义可解释性,图6为粗位置解码器在大小为RH×W×1的2D格网上输出各测试数据集3个场景的行人轨迹预测热图,由图6可以观察到MTP-Sim3D模型能较为精确预测行人未来轨迹强度,原因在于本文在训练时采用GATRNN,能有效获取周围场景环境信息和对周围行人分配注意力权重。MTP-Sim3D模型在ETH/UCY数据集上的第3个场景轨迹热力图输出不佳,预测方向与行人行走真实方向偏差较大,原因在于上述场景均采用移动摄像机进行拍摄,相机视角转换较快,模型获取环境信息较少,仍需在精细位置解码器中进一步优化。

图6 MTP-Sim3D在各数据集上的行人轨迹预测热力图可视化Fig.6 Heatmap visualization of pedestrian trajectory prediction by MTP-Sim3D on various datasets
2.4.3 行人轨迹预测可视化
图7为不同场景下多行人轨迹预测追踪效果,蓝色表示观测时间3.2 s行人行走的路径,红色表示细位置解码器输出精细化行人预测位置,橙色为粗位置解码器输出的轨迹预测热图,绿色为检测器标定的检测框。在图7中,LDU数据集第1和第2个场景、 VIRAT/ActEV数据集第1个场景、ETH/UCY数据集第2个场景、Seg_videos数据集第2和第3个场景中的同向而行或并行的人群受到周围不经过自身路线的行人影响较少(即原本近似直线行走的行人),模型根据图注意力分配情况能够觉察附近的行人不阻碍自身运动,预测行人保持原有路线运动。在VIRAT/ActEV数据集第2个和第3个场景、LDU数据集第3个场景、Seg_videos数据集第1个场景、RGB_Videos数据集全部场景中,模型利用语义场景和行人外观信息成功预测处于相向行走的行人在相遇时因避免相撞轨迹方向发生轻微偏移;在ETH/UCY数据集第1和第3个场景中行人密度较大且空间拥挤情况严重,行人间有很强的相互影响,模型通过生成增强轨迹和图注意力分配可以有效预测行人在各场景中最终位置。在Argoverse数据集选取3个不同街道的场景,由于车载摄像机和行人目标的表观特征和运动速度不同,MTP-Sim3D算法将行人外观特征和行人目标交叠率作为跟踪匹配的权重,增强了目标跨帧匹配的准确性,细位置解码器则输出优化后预测轨迹,提高模型对快速视角变化下轨迹追踪预测。

图7 多行人轨迹追踪预测Fig.7 Multi-pedestrian trajectory tracking prediction
3 结 语
多行人轨迹预测作为智能交通系统与城市地理信息系统融合关键任务之一,广泛应用于自动驾驶、机器人导航、城市安全等领域。现有方法由于数据集不足、标注难,没有充足监督样本进行网络训练和优化,存在过拟合和泛化性不高问题,对此本文提出多行人轨迹多视角三维仿真视频学习预测方法。该方法首先通过CARLA仿真模拟器生成训练所需多视角仿真轨迹标注数据,生成的仿真视频序列无论行人外貌和运动轨迹都接近于真实视频序列,有效扩大了行人轨迹预测数据集的数据量;然后加入了视频行人几何编码信息,增加了行人的姿态特征;最后利用GATRNN对增强对抗轨迹和行人编码信息进行训练,并通过位置解码器输出预测行人轨迹。在公共数据集上的试验相较其他改进算法在性能上得到很好提升,能应用于摄像机拍摄未知视频序列,具有较强泛化效果及可解释性。由于CARLA仿真模拟器难以对所有的真实数据进行重建,合成的仿真轨迹数据仅包含真实轨迹数据的65%左右,此外在处理多视角下仿真轨迹相关性的单应矩阵仍需要大量手动操作,未来在此基础上引入多源空间场景信息并采用更先进检测追踪算法,以进一步提升整体预测精度和追踪实时性。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
意林(2021年5期)2021-04-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
家庭影院技术(2019年8期)2019-12-04
扬子江(2019年1期)2019-03-08
数学物理学报(2017年5期)2017-11-23
小天使·一年级语数英综合(2017年6期)2017-06-07
