
一种基于小波变换的YOLOv5火灾检测改进算法
2023-10-12 07:38章曙光邵政瑞
无线电工程 2023年10期
章曙光,唐 锐,邵政瑞,鲍 锐
(1.安徽建筑大学 电子与信息工程学院,安徽 合肥 230601;2.安徽建筑大学 信息网络中心,安徽 合肥 230601)
0 引言
火灾是一种最常见的多发性灾害之一,严重威胁自然环境和人类生命财产安全。实际的火灾场景由于环境复杂、类烟火物体干扰存在误报以及对烟火目标定位不准确的问题,因此,及时、准确地对早期火灾进行探测并预警具有重要的研究意义。
火灾产生的过程中常伴随火焰和烟雾。在利用数字图像检测火灾之前,主要通过温感、烟感和光感等物理传感器进行火灾探测,但这些传统的物理传感设备检测范围有限且信息单一,检测存在较大的延迟且易受外界干扰,难以适应复杂多变环境下的火灾实时探测要求。因此,提出基于计算机视觉的火灾检测方法,主要包括基于图像处理的传统火灾检测算法和基于深度学习的火灾检测算法。
传统火灾检测方法首先使用滑动窗口遍历输入图像得到候选区域,其次使用HOG、SIFT、LBP等算法人工提取火焰和烟雾的颜色、形状和简单纹理等特征,将提取的特征向量传入SVM、贝叶斯网络、BP神经网络等分类器判断候选烟火区域类别[1]。然而这些方法只能提取图像的浅层特征,精度较低,且针对一些复杂场景鲁棒性较弱。
基于深度学习的火灾检测算法能够提取图像更抽象、更高级的特征,在检测精度、速度和泛化能力方面都有显著提升。文献[2]首次将CNN应用到火灾场景检测中,开启了基于深度学习的烟火图像特征采集自适应学习算法的先河。自深度学习技术发展以来,经典的目标检测算法有Faster-RCNN[3]、YOLOv3[4]、RefineDet[5]、SSD[6]等。目标检测算法的改进通常分为2个方向:提升检测精度[7]和轻量化模型便于部署到嵌入式设备[8]。文献[9]通过几何中值的过滤器剪枝算法对YOLOv5模型进行压缩,实现了轻量化处理。文献[10-11]使用轻量化网络替换YOLOv5原主干网络,有效减少网络的参数量,保证了火灾检测的速度,但检测性能会随着IOU阈值的增加显著下降。文献[12]引入基于水平和垂直方向联合加权策略的值转换-注意机制,有针对性地提取烟雾的颜色和纹理,提高了烟雾检测性能。文献[13]针对单个网络模型在复杂场景下特征提取的局限性,将YOLOv5和EfficientNet两个模型并联协同检测火灾,提高了检测精度和召回率,但集成模型严重降低了检测速度。文献[14]将YOLOv3网络与通道注意力相结合,提升网络对火焰和烟雾的特征提取能力,但通道注意力会忽略位置信息且无法建立远程依赖关系,导致部分信息丢失。
以上基于深度学习的火灾检测算法,网络模型相对复杂、计算量大、难以同时满足火灾检测精度和速度的平衡,且在实际应用中,由于特征提取网络的局限性,可能会因为复杂环境下一些类烟火物体(如红色衣物、落日和光线反射)的误检导致一定的假阳性。针对这些不足,本文提出一种将小波变换的时频光谱特征与卷积特征相结合的YOLOv5火灾检测改进算法。该算法采用检测精度较高且速度较快的YOLOv5s算法为基准,使用二维Haar小波变换提取图像的光谱特征,融合到主干网络CSPDarknet中不同尺度的卷积层,并通过嵌入Coordinate Attention(CA)[15]注意力机制的CAC3模块,增强对浅层网络位置信息的关注度,提升网络定位能力。实验证明,小波变换可以描述不同频率的烟火信息,能够提高网络对火焰和烟雾的纹理识别能力,从而实时、准确地检测火灾。
1 改进YOLOv5算法
1.1 改进YOLOv5网络结构
YOLOv5是YOLO系列工作之一,综合了YOLO系列网络优点,其中YOLOv5s网络模型深度和宽度最小,主要分为主干网络、颈部和预测端三部分。主干网络主要由残差卷积构成,其内部的残差块使用跳跃连接来缓解网络深度增加产生的梯度消失问题,引入了Focus通道增广技术来减少计算量,以及空间金字塔池化(Spatial Pyramid Pooling,SPP)结构提高网络的感受野;颈部沿用了YOLOv4的FPN+PAN结构,将浅层的语义信息和深层信息堆叠在一起,增强网络特征融合的能力;预测端使用CIOU作为框回归损失函数且有3个不同尺度的输出,使模型能够处理大、中、小3种不同尺度的目标。
YOLOv5s检测网络在目标检测领域同时具备较高的检测精度和速度,但在火灾检测领域,因烟火的特殊纹理特征、类烟火物体干扰等因素的影响,检测精度难以保证。本文针对YOLOv5s网络的改进主要体现在三方面:添加小波特征融合模块、使用嵌入CA的CAC3模块和改进框回归损失函数。改进后的YOLOv5s网络结构如图1所示,在输入后添加小波特征融合模块,将2次Haar小波变换的输出融入到卷积网络中,并使用CAC3替换原本的C3模块。

图1 基于小波变换的改进YOLOv5s网络结构Fig.1 Improved YOLOv5s network structure based on wavelet transform
1.2 小波特征融合模块
小波是一种小区域、长度有限且均值为0的波形,小波变换就是使用适当的基本小波函数,通过平移、伸缩形成一系列小波,这簇小波作为基可以构成一系列嵌套的子空间,然后将待分析的信号投影到各个大小不同的子空间中,以观察相应的特性。对于能量有限的信号f(t),其小波变换的表达式如下:
(1)
式中:α为尺度,用来控制小波函数的伸缩,τ为平移量,用来描述小波函数的平移尺度,尺度的倒数与频率成正比,平移量对应时间,φ(t)为基本的小波函数。
图像的小波变换是基于二维离散小波变换在图像处理上的应用,可以用分别在水平和垂直方向进行滤波的方法实现二维小波多分辨率分解,将图像信息一层层剥离开来,以获取不同频率的信息。离散小波变换用到了2组函数:尺度函数和小波函数,分别与低通滤波器和高通滤波器相对应。本文使用最简单的基于Haar小波函数的小波变换,它是小波分析中最早用到的一个具有紧支撑的正交小波函数,是支撑域在范围内的单个矩形波。其尺度函数和对应的小波函数如下:
(2)
(3)
Haar小波变换示意如图2所示,每次小波变换后,图像被分解为2倍下采样的子区域,分别包含相应频带的小波系数。其中图2(b)是经过一次Haar小波变换的结果,LL1是低频系数,表征原图的近似信号,HL1、LH1、HH1分别表示水平高频系数、垂直高频系数和对角高频系数,代表图像的噪声和边缘细节信息。图2(c)表示继续进行二次Haar小波变换。
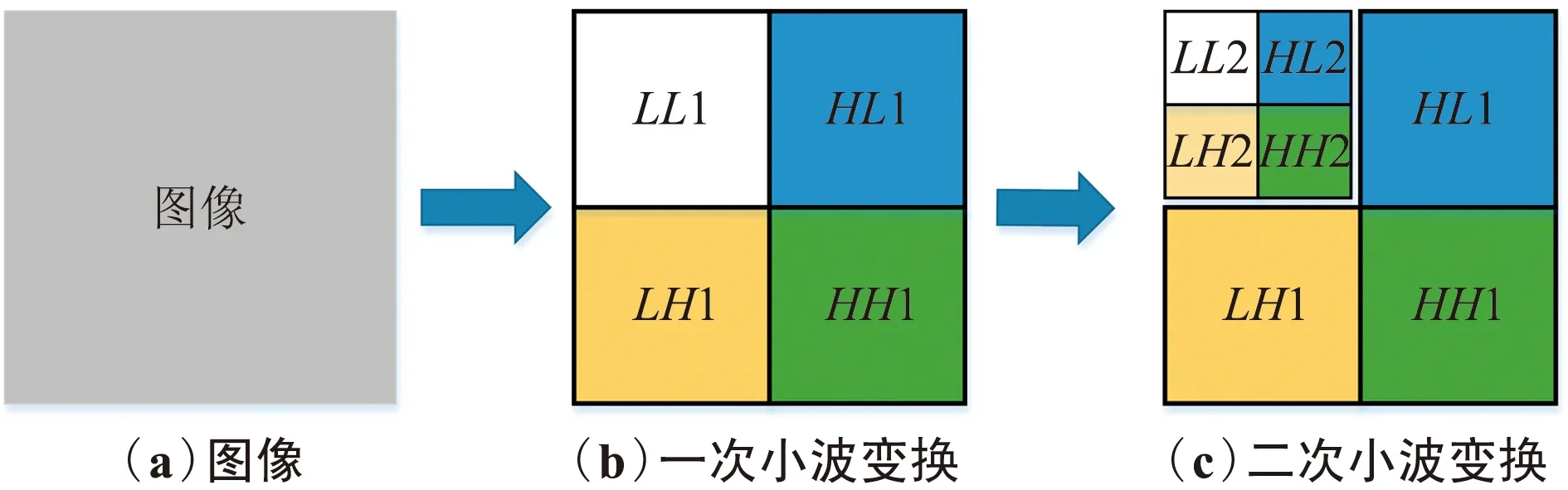
图2 Haar小波变换Fig.2 Haar wavelet transform
取一张火灾图像,对其进行二维Haar小波变换,实际效果如图3所示。

图3 Haar小波变换在火灾图像上的效果展示Fig.3 Effect display of Haar wavelet transform on fire image
YOLOv5网络结构中的Focus层,采用切片操作把高分辨率的图像拆分成多个低分辨率的特征图并拼接,将图像空间平面上的语义信息转换到通道维度,再通过后续的卷积层进行特征提取,但深层的卷积操作过程会丢失目标的边缘细节等信息,尤其对于火焰、烟雾这类浅层特征较为丰富的物体,且烟火目标常因为背景等干扰导致边缘细节信息不显著。因此,通过二维Haar小波变换提取图像的高频系数,并拼接得到小波高频通道特征,这些特征代表了图像变化信息和边缘细节,将小波高频通道特征与Focus切片操作后的卷积特征进行通道上的特征融合,进一步增强烟火目标的纹理细节特征,并为后续的特征提取保留了更完整的图片下采样信息。小波特征融合示意如图4所示。

图4 小波特征融合示意Fig.4 Schematic diagram of wavelet feature fusion
对原始图像同时进行Focus切片操作和一次Haar小波变换,Focus切片类似于邻近下采样,是在RGB图像中每隔一个像素取一个值并进行拼接,从而将W、H维度的信息集中到通道空间。Haar小波变换得到4个同样具有三通道的小波特征:LL1、HL1、LH1、HH1,将其中代表图像边缘细节等信息的9个小波高频通道特征与Focus切片操作后的相同大小的特征图进行通道上的特征融合,后接3×3卷积进行特征提取,得到没有信息丢失的下采样特征图,再将对原图进行二次小波变换得到的9个高频通道特征(HL2、LH2、HH2)与上述相同尺度的特征图进行特征融合,以丰富烟火在浅层网络的细节特征,提升网络对烟火目标纹理细节的学习能力。
1.3 嵌入CA的CAC3模块
融合小波特征后的浅层网络具有丰富的烟火目标纹理轮廓等位置信息,而C3结构中多个串联的BottleNeck模块在提取通道语义信息时会减弱对这些位置信息的关注,引入CA来增强关注并减少信息丢失。CA通过将位置信息嵌入到通道注意力中,不仅捕获跨通道信息,还捕获方向感知和位置敏感信息,保证了网络能捕获更多位置细节,提升网络特征融合能力。
CA弥补了SENet[16]忽略重要位置信息以及CBAM[17]无法建立对视觉任务至关重要的远程依赖关系的不足,其结构如图5所示。为了减轻由2D全局池化引起的位置信息丢失,CA利用2个一维全局池化操作分别沿垂直和水平方向进行特征聚合,得到2个独立的一维特征编码,这样可以在一个空间方向保留精确的位置信息,在另一个空间方向使卷积捕获远程依赖关系。然后将生成的特征图通过通道维度拼接、卷积和归一化等操作编码为一对方向感知和位置敏感的注意力特征图,通过相乘将2个注意力特征图应用于输入特征图以强调关注对象的表示。

图5 CA结构Fig.5 CA structure
嵌入CA的CAC3模块如图6所示,将CA 嵌入到原C3模块的BottleNeck残差结构中,能够保证在带来较少参数量的前提下,借助CA的远程依赖关系减轻干扰信息,加强对融合了小波高频特征的浅层特征信息的提取和定位能力,使得到的信息变得多元,从而提升整个网络的性能。

图6 嵌入CA的CAC3模块Fig.6 CAC3 module embedded in CA
1.4 改进的损失函数
YOLOv5的损失函数由分类损失(Classification_Loss)、边界框回归损失(Localization_Loss)和置信度损失(Confidence_Loss)组成。边界框位置预测通过关注预测框和真实框的交并比对边界框的位置进行回归预测。
YOLOv5采用CIOU作为框回归损失函数,将真实框与锚框之间的距离、重叠率、尺度以及纵横比都考虑进来,但是纵横比描述的是相对值,而不是宽高分别与其置信度的真实差异,且由于复杂火灾场景下烟火边界区域判定的差异性,会忽略难易样本不平衡的问题,阻碍模型有效的优化相似性。因此,本文基于EIOU[18]和α-IOU[19]的优点采用了改进后的α-EIOU作为新的框回归损失。EIOU将原本CIOU纵横比的损失项拆分成预测框宽高分别与最小外接矩形宽高的差值,明确地衡量了重叠区域、中心点距和宽高真实差,如式(4)所示。同时借鉴α-IOU自适应地重新加权高低IOU目标的损失和梯度,通过引入权重参数α对这些损失进行幂变换,使回归过程专注于高质量的锚框,以提高模型定位和检测的性能,如式(5)所示。
(4)
(5)
式中:CW、CH是真实框和预测框的最小外接矩形的宽度和高度,b、bgt分别表示预测框和真实框的中心点,ρ(b,bgt)计算2个中心点间的欧氏距离,ρ(w,wgt)、ρ(h,hgt)分别表示预测框与最小外接框宽高的差值,α>1用于对锚框设置绝对梯度权值,IOU越大的边界框损失也越大,从而加速对高质量锚框的学习,提高对梯度自适应加权的边界框回归精度。
2 实验及结果分析
2.1 数据集的制作
针对火灾检测任务,目前尚未有公开的权威数据集。本文按照PASAL VOC2007格式标准构建了一个场景丰富的火焰和烟雾目标检测数据集。该数据集中的图像主要来源于土耳其比尔肯大学 (http:∥signal.ee.bilkent.edu.tr/VisiFire/)、江西财经大学袁非牛团队 (http:∥staff.ustc.edu.cn/~yfn/vsd.html)、韩国启明大学火灾视频库(https:∥cvpr.kmu.ac.kr)以及网络上采集的图片和视频,包括森林、公路、工地和高楼等多个不同场景。为了减少模型的误检率,参考coco数据集1%的负样本图片比例,加入了100多张非火灾图像,如夕阳、晚霞、反射的光影和红色车辆等。使用随机旋转、缩放和平移等数据增强方式将数据集扩充到16 000张图像,部分数据如图7所示。使用LabelImg工具进行标注,数据集包含fire、smoke两类,将其按照8∶1∶1比例随机划分训练集、验证集和测试集。

图7 数据集部分展示Fig.7 Presentation of partial datasets
2.2 实验平台与模型训练
实验在Python3.8、CUDA11.1、PyTorch1.8.0环境下进行,所有模型均在配备32 GB显存的Tesla V100显卡上进行训练和测试。
训练时,加载在ImageNet数据集上训练好的YOLOv5s预训练权重,以提高模型的泛化能力。输入图像分辨率为640 pixel×640 pixel,批处理数为16,初始学习率为0.001,训练总共迭代200次,得到最终的烟火检测模型权重。加载训练得到的权重文件,利用测试集进行推理测试。
2.3 评价指标
本文主要采用平均精度(mean Average Precision,mAP)和每秒传输帧数(Frame Per Second,FPS)作为模型评价指标。AP表示每个类别的平均检测精度,通过对每一类别的准确率-召回率曲线求积分得到,本文使用的AP默认为AP50,即预测框与真值框的IOU在大于50%前提下的单个类别的平均精确度,mAP是所有类别AP的平均值,mAP值越大表示该模型的总体识别准确率越高,mAP0.5:0.95是指在不同IOU阈值(0.5~0.95,步长为0.05)上的平均mAP。其中准确率(Precision,P)和召回率(Recall,R)的计算方式如下:
(6)
(7)
(8)
式中:TP为实际正类且预测正类,FP为实际负类但预测正类,FN为实际正类预测负类,N为类别数。
2.4 实验结果分析
本文设计了一组消融实验和一组对比试验,通过消融实验分析本文不同改进部分对网络性能的影响,再通过改进YOLOv5模型与主流网络模型(SSD、YOLOv3、YOLOv4-Tiny)的对比实验,综合分析模型性能。
2.4.1 消融实验
为了分析不同改进部分对网络性能的影响,使用YOLOv5s作为基准模型,向网络结构中陆续添加小波特征融合模块、CAC3模块和改进的α-EIOU损失函数,并对改进后的网络模型进行训练与测试,实验结果如表1所示。对表1分析可见,改进1向主干网络添加小波特征融合模块丰富了烟火目标的细节纹理等信息,mAP和精确率各提升了1.3%,召回率提升1.5%;改进2在此基础上引入CA注意力机制,嵌入到C3模块中,提升了通道对空间信息的注意力,增强了网络对小波变换提取的烟火位置信息的关注,mAP提升了0.8%,召回率依然有较明显的提升(1.1%);改进3使用α-EIOU(α=2时效果最好)代替原本的CIOU提高边界框回归精度,精确率提升1.5%,mAP和召回率也都有略微提升。改进后算法的mAP相较YOLOv5s基准模型提升了2.3%,mAP0.5:0.95提升了2.5%,证明了检测网络整体性能的优越性。

表1 消融实验Tab.1 Ablation experiment
2.4.2 对比实验
为进一步验证本文算法的优势,将其与主流目标检测算法SSD、YOLOv3、YOLOv4-tiny在相同实验环境下做对比实验,增加了FPS以及对测试集中每张图片的平均检测时间分析,对比试验结果如表2所示。由表2分析可知,改进YOLOv5算法的mAP达到了81.4%,mAP0.5:0.95达到了55.1%,相较于SSD和YOLOv3算法以及网络结构更加轻巧的YOLOv4-tiny,改进后的算法在mAP上高出10%以上,且FPS及检测时间等各项指标都要优于SSD和YOLOv3算法。相较原YOLOv5算法,改进后算法由于小波特征融合模块和CAC3模块的引入,网络运算过程增加了少量的参数量,使得改进后算法在保证检测精度有明显提升的同时,FPS仅存在轻微的下降,模型仍然具有较快的检测速度,对图片的检测时间也符合火灾检测的工业需求。因此,改进后的YOLOv5算法更适用于工程应用。

表2 对比实验Tab.2 Contrast experiment
2.4.3 检测结果
为验证改进算法在实际火灾场景中的有效性,选取存在类烟火物体干扰、烟火轮廓模糊、有多处着火点以及着火点较小等几种特殊情况的图像进行检测。为了在避免烟火漏报的同时减少因复杂背景以及类烟火物体干扰产生的误报,将置信度阈值设为0.65,在改进后算法和原YOLOv5算法上的实际检测效果对比如图8所示。由图8可以看出,原YOLOv5算法会将夕阳这一类烟火物体识别为火焰,改进后算法有效避免了类烟火物体的误检,且对轮廓纹理模糊、与背景不易区分的烟雾也能够较好地检测出。原YOLOv5算法在有多处着火点以及着火点较远或较小的火灾场景中存在漏检等情况,而改进后的算法对这些火灾场景也有较好的检测效果,且对检测框的准确度有明显提升。经验证,本文改进后的算法在检出率和检测精度上都有良好的性能表现,适用于不同场景下的火灾检测任务。

图8 检测效果对比Fig.8 Comparison of detection effect
3 结束语
本文针对现有目标检测模型在复杂环境下易受类烟火物体干扰检测困难的问题,提出了一种基于小波变换的YOLOv5火灾检测改进算法。该算法在YOLOv5s基础上,融合了小波变换提取到的烟火纹理特征等信息,并通过CAC3模块捕获更多位置细节,提升网络的定位能力。实验结果表明。本文提出的改进算法在保证检测速度的同时,提升了火灾场景下的烟火检测性能,并有效减少类烟火物体的误报情况,能够满足实际工程应用需求。
猜你喜欢
科技风(2021年19期)2021-09-07
阅读(快乐英语中年级)(2021年2期)2021-04-01
学生天地(2020年35期)2020-06-09
电子制作(2019年13期)2020-01-14
读友·少年文学(清雅版)(2019年10期)2019-05-21
制造技术与机床(2017年10期)2017-11-28
文理导航·趣味课堂(2016年6期)2016-09-09
火花(2016年7期)2016-02-27
电测与仪表(2014年8期)2014-04-04
故事作文·高年级(2009年7期)2009-08-20
