
基于掩码预测和多尺度上下文聚合的人脸图像修复算法
2023-10-12 07:37孙剑明吴金鹏沈子成彭俄祯
无线电工程 2023年10期
孙剑明,吴金鹏,沈子成,彭俄祯
(哈尔滨商业大学 计算机与信息工程学院,黑龙江 哈尔滨 150028)
0 引言
图像修复[1]是指利用已知上下文信息填充图像中缺失的区域。尽管研究人员已经提出许多图像修复方法,无论是传统算法还是现有深度学习算法,在修复图像时都难以同时恢复合理的内容和清晰的纹理。
早期的图像修复工作[1-13]试图通过基于扩散或基于补丁的算法来解决这一问题。基于扩散的算法将上下文信息从边界传播到等照度线方向的孔洞(缺失区域)中。基于补丁的算法通过从未损坏的图像区域或外部数据库复制相似的补丁来合成缺失区域。现有的深度模型在低分辨率图像的语义修复方面已经表现出良好的效果。但在更高分辨率(如512 pixel×512 pixel)使用这些深度模型往往会生成不合理的内容且纹理细节不真实,阻碍了用户在高分辨率图像中的实际应用。
为了克服以上2种问题,提出了一种基于掩码预测和多尺度上下文聚合的人脸图像修复模型。它包括一个以编码器、多尺度上下文聚合模块(Multi-Scale Context Aggregation Module,MSCAM)、解码器为框架的生成器网络和一个以掩码预测为训练任务的判别器网络。
为了在破损图像生成合理的内容,通过堆叠多个MSCAM。通过使用各种扩张率的空洞卷积来利用遥远的距离上下文信息进行上下文推理,同时通过拼接多个特征图来实现多尺度的特征融合。使用跳跃连接将编码器中每一层卷积层的输出与解码器对应位置的输入在通道维度上拼接,使得图像的上下文信息向更高层分辨率传播,从而为缺失区域生成更合理的内容。
为了生成真实的纹理细节,使用了一种新颖的掩码预测任务来训练判别器。大多数现有的深度模型使用了带有谱归一化的PatchGAN判别器,从而迫使判别器将修复图像中的所有补丁块预测为假,而忽略了那些缺失区域之外的补丁块确实来自真实图像的事实。因此,这些深度模型可能难以生成逼真的细粒度纹理。为了克服以上问题,使用掩码预测的PatchGAN(Mask Prediction-PatchGAN,MP-PatchGAN)判别器,迫使判别器区分真实和生成的小块(缺失区域)的纹理细节。换句话说,对于修复图像,判别器期望从真实图像中分割出合成的图像块。这样的学习目标导致了一个更强的判别器,并且反过来促进生成器来合成逼真的细粒度纹理。
本文的贡献如下:
① 首次提出了MSCAM和MP-PatchGAN判别器。MSCAM进行特征提取,融合了来自不同感受野的特征图,可以用来捕捉遥远距离的上下文信息和感兴趣的模式增强上下文推理。MP-PatchGAN判别器迫使判别器区分真实和生成的小块(缺失区域)的纹理细节,进一步提升人脸面部修复性能。
② 设计了一种基于掩码预测和多尺度上下文聚合的人脸图像修复网络,以便生成合理的内容和逼真的纹理。
③ 本文设计的模型与其他主流的基于深度学习模型进行定量、定性评估,且评价结果优于其他深度模型。
1 相关工作
由于图像修复对图像编辑应用(如物体移除和图像复原)的重要实用价值,图像修复已然成为近几十年来活跃的研究课题之一。现有的修复算法可以分为2类:基于传统的算法和基于深度学习的算法。
1.1 基于传统的图像修复算法
基于扩散的算法[1-6]沿着等照度线方向将上下文像素从边界传播到孔洞。具体地,在像素传播期间,通过使用偏微分方程来施加许多边界条件。然而,这些方法通常会引入扩散相关的模糊,因此无法完成大面积缺失区域。
基于补丁的算法[7-13]通常通过从已知的图像上下文或外部数据库复制和粘贴相似的补丁块来合成丢失的内容。然而,这些方法在完成复杂场景的大面积缺失区域的语义修复方面存在不足。这是因为基于补丁的方法严重依赖于通过低级特征的逐片匹配。这种技术不能合成已知区域中不存在类似补丁的图像。
传统算法往往在修复面积较小、纹理结构较为简单时有比较好的效果。一旦缺失区域比较大(30%以上)时,修复效果往往会特别差。这是因为传统的图像修复算法往往不能深层地理解图像中的语义信息。因此,随着2015年之后深度学习的火热,越来越多从事图像修复的研究人员开始采用深度学习方法以获取更深层次的语义信息理解以及更高质量的修复效果。
1.2 基于深度学习的图像修复算法
深度特征学习和对抗训练的出现使得图像修复取得了重大进展。与基于传统算法相比,深度修复模型能够为复杂的场景生成合理的内容和逼真的细粒度纹理。
Pathak等[14]提出了上下文编码器(Context Encoder,CE)模型,利用潜在特征空间中的通道等宽全连接层(Channel-wise Fully Connected Layer)将编码特征和解码特征连接。该模型首次使用生成对抗网络(Generative Adversarial Network,GAN)框架,生成器由编码器、解码器组成。取AlexNet前5层作为编码器,解码器部分则由反卷积实现从高维特征向图像真实大小的转变。通过CE模型已经能使街景、人脸生成有希望的结果。然而,由于使用了通道等宽全连接层,使得该模型只能处理固定大小(128 pixel× 128 pixel)的图像。CE结构如图1所示。
针对上述问题,Iizuka等[15]提出在全卷积网络(Fully Convolutional Network,FCN)建立模型,使得该模型能处理任意大小的图像。为了生成逼真的细粒度纹理,通过采用GAN的框架进行语义修复,已经取得了重大进展。通过生成器和判别器之间的博弈论最小最大博弈,基于GAN的修复模型能够生成更清晰的纹理。为了进一步改进判别器网络,通过全局和局部判别器进行联合训练,从而达到全局和局部一致性。FCN结构如图2所示。
然而,由于FCN中判别器网络使用了全连接层,局部判别器只能处理固定形状的缺失区域。为了解决这一问题,Yu等[16]继承了PatchGAN判别器, PatchGAN判别器旨在区分真实图像的Patch和修复图像的Patch。但基于PatchGAN的模型通常忽略了这样一个事实:那些缺失区域之外的补丁块确实来自真实图像的事实,并且盲目地促进判别器来区分这些相同的补丁块是假的,因此会削弱生成器生成缺失区域之外的真实块的真实内容。除此之外,为了捕获基于FCN的远距离上下文,提出了上下文注意力模块,以通过逐片匹配从上下文中找到感兴趣的补丁块。Yu等提出的网络结构如图3所示。
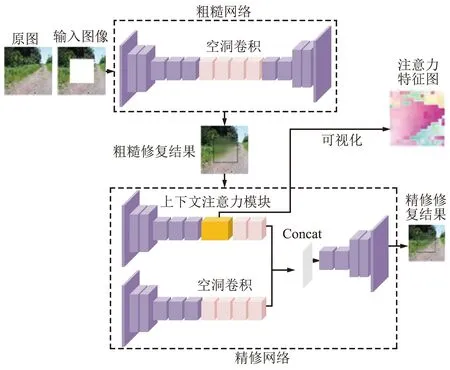
图3 上下文注意力机制网络结构Fig.3 Contextual attention mechanism network structure
Liu等[17]提出部分卷积层代替标准卷积来处理缺失区域内外颜色差异和伪影的问题。部分卷积将像素分为有效和无效像素,且只对有效像素做卷积。Yu等[18]在上下文注意力模块的基础上使用了门控卷积学习掩码的分布,进一步提升了修复性能。Yi等[19]提出了上下文残差聚合(Contextual Residual Aggregation,CRA)机制,该机制可以通过对上下文信息中的残差进行加权聚合来生成缺失区域的高频残差,提出的CRA网络仅需输入低分辨率图像,再将低分辨率修复结果和高频残差合并得到高分辨率图像。
传统的图像修复算法只适用于修复与背景相似的纹理,但人脸图像面部成分之间存在紧密的相关性,人脸修复结果应当具有全局语义的合理性,如眉毛对齐、眼睛对齐等。因此,传统的图像修复算法不适用于人脸图像修复。
随着GAN的发展,有关深度学习的人脸图像修复算法性能不断提升。现有基于深度学习的人脸图像修复算法主要分为4类:基于全连接层的算法、基于FCN的算法、基于注意力机制的算法和基于掩码更新的算法。文献[14]提出的CE网络使用通道等宽全连接层完成脸部特征的长程迁移,但由于使用了全连接层,其网络只能使用固定大小的人脸图像。针对这一问题,文献[15]首次提出使用FCN进行人脸修复,使其能处理任意大小的人脸图像。文献[16]提出了上下文注意力模块,该模块具有优秀的脸部特征长程迁移能力。但是,这个模块大尺寸图像会占用巨大的显存,因此无法在多尺度特征上使用,修复结果仍然会出现全局语义信息不合理的情况。文献[17-18]和文献[20]使用不同掩码更新策略进一步提升了局部语义修复性能。但是,其在全局语义上存在如左右眼不对称等不合理的问题。
2 网络结构
2.1 MSCAM
受Inception v3[21]网络的启发,MSCAM将标准卷积层拆分为4个子层,每个子层拥有较少的输出通道,如图4所示。首先,使用4个不同padding大小(1、2、4、8)的ReflectionPad2d转化为4个特征图。其次,将具有256个输出通道的标准卷积层拆分为4个子层,使得每个子层具有64个输出通道。每个子层通过使用不同扩张率(1、2、4、8)的空洞卷积来执行上一ReflectionPad2d层输出特征图的不同变换。具体来说,通过在连续位置之间引入零来扩展卷积核。使用较大的扩张率使得卷积核能够“看到”输入图像的较大区域,而使用较小扩张率只能使卷积核关注于较小感受野的局部区域。随后通过在通道维度上拼接多尺度感受野的不同变换。最后使用标准卷积层进行多尺度上下文聚合。通过MSCAM能够聚合遥远距离的上下文信息和感兴趣的模式来增强上下文推理。
2.2 MP-PatchGAN判别器
在早期深度修复模型的判别器中,通常采用softmax函数输出一个整张图像是否为真实的概率。最近的深度修复模型使用了带有谱归一化的PatchGAN判别器。然而,使用softmax函数的GAN判别器对于不规则破损图像修复是不适用的。尽管,PatchGAN判别器适用不规则破损图像修复,但PatchGAN判别器会将修复图像中的所有补丁块预测为假,而忽略了那些缺失区域之外的补丁块确实来自真实图像的事实。因此,无论是softmax函数的PatchGAN判别器,还是PatchGAN判别器都可能导致边缘处结构扭曲、产生伪影。为了促进生成器生成细粒度的纹理,本文算法使用MP-PatchGAN判别器。图5为训练不同判别器的说明。

图5 训练不同判别器的说明Fig.5 Description of different training discriminators
具体来说,对输入掩码进行下采样,作为真实图像掩码预测任务的真实值。使用补丁级别的软掩码作为生成图像掩码预测任务的真实值,它通过高斯滤波获得。通过计算判别器生成的真实图像的预测掩码和输入掩码均方误差(Mean Squared Error,MSE),再通过计算判别器生成的修复图像的预测掩码和补丁级软掩码的MSE。将判别器的对抗性损失表示为:
Ex~Pdata[(D(x)-1)2],
(1)
式中:D为判别器,G为生成器,σ为下采样和高斯滤波的合成函数,z为修复图像,m为掩码,1为与掩码相同大小的元素全为1的矩阵,x为真实图像,σ(1-m)为补丁级别软掩码。相应地,生成器的对抗性损失表示为:
(2)
式中:D为判别器,G为生成器,z为修复图像,m为掩码,⊙为逐像素相乘。仅对缺失区域的合成块的预测被用于优化生成器。通过这样的优化,使得判别器从缺失区域之外的真实上下文中分割缺失区域的合成块,从而增强判别器的性能,反过来可以帮助生成器合成更真实的纹理。
2.3 算法整体框架
基于掩码预测和多尺度上下文聚合的人脸图像修复算法在设计上采用了GAN框架,用编码器-MSCAM-解码器为框架构造了生成器。首先,通过将真实图像和不规则掩码图像合并成受损图像作为输入图像。然后,编码器提取图像高层次的语义信息。再通过堆叠8层MSCAM捕获遥远距离的上下文特征和丰富的感兴趣模式来增强上下文推理。使用跳跃连接将编码器每一卷积层的输出和解码器对应位置上的输入在通道维度上做拼接,使得图像的上下文信息向更高层分辨率特征图传播。最后通过解码器使得提取的特征图向真实图像的分辨率大小转变,通过重建损失、对抗损失、感知损失、风格损失的联合损失函数训练生成器模型。本文算法在判别器上改用MP-PatchGAN判别器,通过对抗损失进行判别器训练。该判别器用于区分真实和修复的Patch,从而生成更为清晰的纹理。本文算法结构如图6所示。
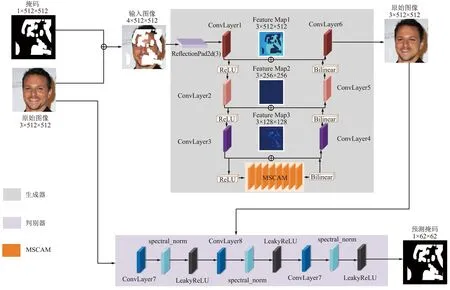
图6 基于掩码预测和多尺度上下文聚合的人脸图像修复模型Fig.6 Face image inpainting model based on mask prediction and multi-scale context aggregation
3 损失函数
图像修复优化目标既要保证像素重建精度,又要保证修复图像的视觉效果。为此,遵循大多数现有深度修复模型,选择4个优化目标:重建损失、对抗损失[22]、感知损失[23]和风格损失[24]。采用对抗损失来优化判别器,采用4个损失的加权联合损失来优化生成器。
3.1 重建损失
首先,使用L1损失,以确保像素级别的重建精度,重建损失表示为:
(3)

3.2 感知损失和风格损失
由于感知损失和风格损失对于图像修复的有效性已经得到广泛验证[25],将它们包括在内以提高感知重建的准确性。具体而言,感知损失旨在最小化修复图像和真实图像的激活图之间的L1距离,感知损失表示为:
(4)
(5)
在本文算法优化中,感知损失计算VGG19网络前5层修复图像和真实图像的激活图之间的L1距离。风格损失计算VGG-19网络前4层修复图像和真实图像的深度特征的格拉姆矩阵之间的L1距离。
3.3 联合损失
使用重建损失、对抗损失、感知损失和风格损失加权联合损失函数优化生成器模型。联合损失函数表示为:
(6)
式中:λ1=1,λ2=0.01,λ3=0.1,λ4=250。
4 实验及分析
4.1 数据集来源
本文在公开数据集CelebA-HQ中训练和测试模型,CelebA-HQ包括30 000张分辨率为512 pixel×512 pixel的人脸图像,其中训练集26 000张,验证集2 000张,测试集2 000张。本文使用了Liu等[17]提供的任意形状掩码数据集,其中包括12 000张不同破损比例的任意形状掩码图像。数据集样例如 图7所示。

图7 数据集样例Fig.7 Samples of dataset
4.2 参数设置
本文所有实验均在CentOS平台下进行,本文算法基于PyTorch 1.12、CUDNN 8.6和CUDA 11.6实现。CPU为Intel Xeon Platinum 8375C 2.90 GHz,GPU为NVIDIA GeForce RTX 3090。使用Adam算法[26]优化模型,动量衰减指数β1=0.5、β2=0.999,学习率为0.001,批量大小为16。
4.3 现有深度模型
深度模型及其缩写和简要介绍如下:
① CA[16]是一个由粗到细的两阶段模型。它使用一个基于Patch的非局部模块,即上下文注意力模块。
② PConv[17]采用提出部分卷积层代替标准卷积来处理缺失区域内外颜色差异的问题。
③ GatedConv[18]在上下文注意力模块的基础上,结合了用于图像修复的门控卷积和SN-PatchGAN判别器。
④ CRA[19]采用提出上下文残差聚合模块,该模块通过加权聚合上下文的残差来产生缺失内容的高频残差。将高频残差和上采样后生成图像聚合来生成高分辨率图像,且用同一组注意力分数多次注意力转移。注意力分数的共享实现了更少的参数以及在模型训练方面更好的效率。
⑤ MAT[20]是首个基于Transfomer的人脸修复网络,其提出的多头上下文注意力模块能够获取长距离的上下文信息提升脸部修复能力。MAT是目前人脸修复领域里SOTA算法。
4.4 定性分析
为了证明本文提出的人脸修复算法的优越性,将本文算法与CA、PConv、GatedConv、CRA和MAT五种算法的修复结果进行定性比较,如图8所示。

图8 不同深度模型在CelebA-HQ测试集上的修复结果Fig.8 Inpainting results of different depth models on CelebA-HQ test set
结果表明,大多数深度模型在完成强语义的极大缺失区域修复时效果不理想。具体来说,CA模型通过提出的上下文注意力模块可以从已知图像内容中寻找与待修复区域相似度最高的Patch,然后使用这个Patch的特征做反卷积从而重建该Patch,但如果已知图像内容和待修复区域差距很大,往往会产生不合理的内容,人脸的五官会出现扭曲(如图8(c)所示)。PConv模型通过提出的部分卷积对每一卷积层的Mask更新,从而优化修复结果,将已知区域内的像素视为有效像素,将缺失区域内的像素视为无效像素,且只对有效像素进行卷积,使用部分卷积代替标准卷积,能在一定程度上避免缺失区域内外颜色差异的问题,但眼睛会产生伪影(如图8(d)所示)。GatedConv模型通过提出的门控卷积优化部分卷积中Mask更新机制,该Mask更新机制是可学习的,但GatedConv模型使用PatchGAN判别器驱使已知区域像素改变,进而影响修复结果(如图8(e)所示)。CRA模型通过多次的注意力转移导致了严重的伪影(如图8(f)所示)。MAT模型通过多头上下文注意力模块以及Transfomer架构的优势,其获取长距离的上下文信息和全局感受野也能带来不俗的修复性能(如图8(h)所示)。而本文通过提出的MSCAM来捕捉遥远距离的上下文信息和更多感兴趣的模式和训练掩码预测的判别器来增强判别器的性能,以此生成更合理的内容和更清晰的纹理(如图8(g)所示)。
4.5 定量分析
为了客观评价本文模型在人脸图像修复效果,对CA、PConv、GatedConv、CRA、MAT和本文提出的模型进行定量比较。评价指标包括L1Loss、峰值信噪比(Peak Signal to Noise Ratio,PSNR)、结构相似性(Structural Similarity,SSIM)和弗雷歇初始距离(Fréchet Inception Distance,FID)(如式(7)、式(8)、式(10)、式(11)所示),分别衡量修复图像和原始图像像素级差异、整体相似度、感知相似度以及特征相似度,其中L1Loss、FID 越低修复效果越好,PSNR、SSIM越高修复效果越好。具体来说,使用了CelebA-HQ验证集的所有图像。在不同孔洞率的掩码下,对上述方法分别做测试。对于每个测试图像,随机采用自由形状的掩码作为测试掩码。为了公平起见,在掩码孔洞率一样的情况下,对所有方法的相同图像都使用了相同的掩码。
(7)
式中:N为样本的数量,W、H、C分别为图像的宽度、高度以及通道数,Iout为修复图像,Igt为真实图像。
(8)

(9)
式中:X1为修复图像,X2为真实图像,H、W分别为图像的高度和宽度。
(10)
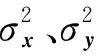
(11)
式中:μx、∑x分别为修复图像在Inception Net-V3输出的2 048维特征向量集合的均值和协方差矩阵,μg、∑g分别为真实图像在Inception Net-V3输出的2 048维特征向量集合的均值和协方差矩阵,tr为矩阵的迹。
定量分析结果如表1和表2所示。不难看出,本文模型在L1Loss、PSNR、SSIM和FID指标下都优于CA模型、PConv模型、GatedConv模型、CRA模型。本文模型与MAT模型的定量分析结果如表3所示,不难看出,本文模型的L1Loss、PSNR、SSIM均优于现阶段人脸修复MAT模型,由此说明本文提出的模型与现有先进深度模型相比,具有更优秀的人脸面部修复能力。
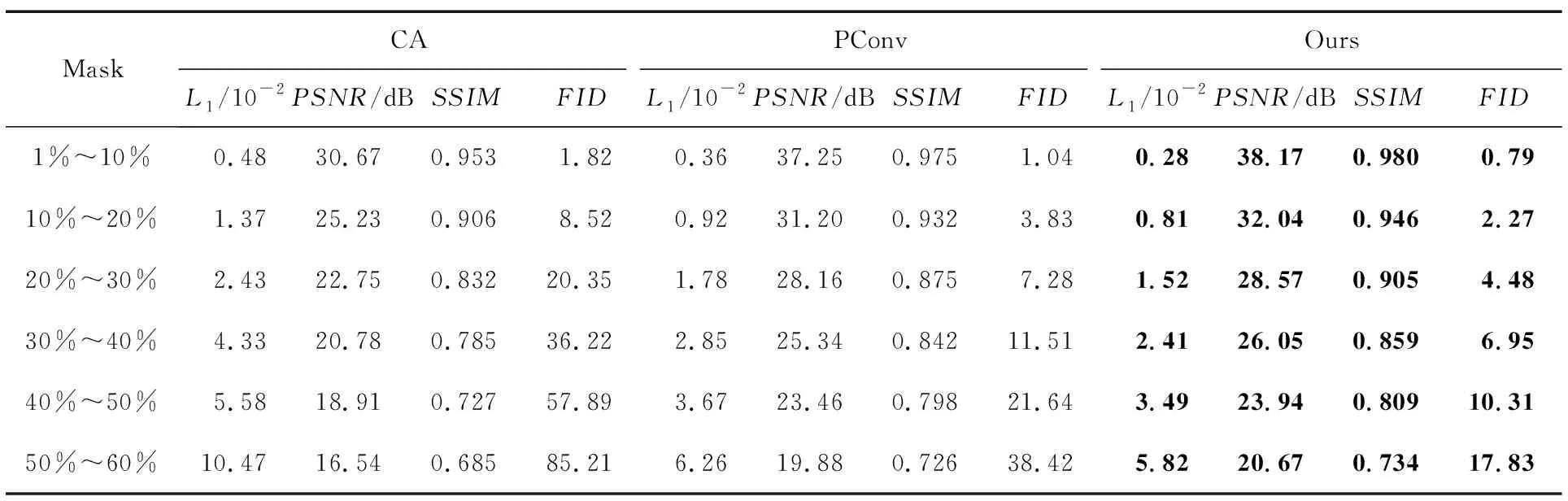
表1 CA模型、PConv模型和本文模型在CelebA-HQ测试集下的平均指数对比Tab.1 Average index comparison of CA model,PConv model and proposed model under CelebA-HQ test set
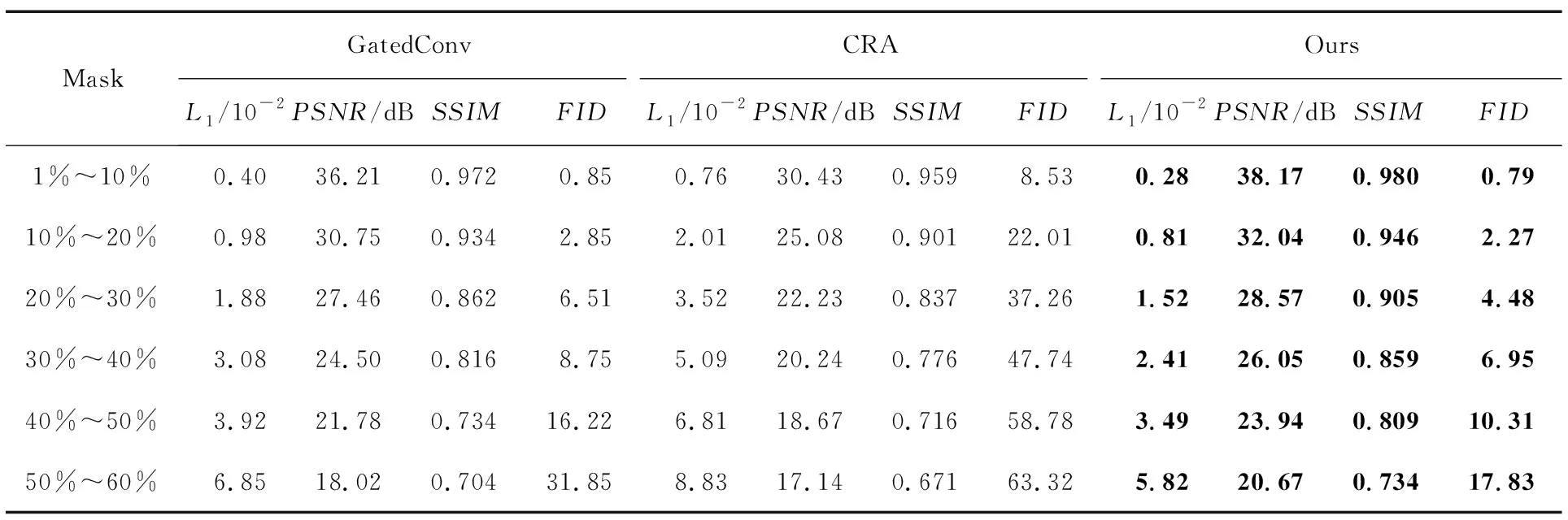
表2 GatedConv模型、CRA模型和本文模型在CelebA-HQ测试集下的平均指数对比Tab.2 Average index comparison of GatedConv model,CRA model and proposed model under CelebA-HQ test set

表3 MAT模型和本文模型在CelebA-HQ测试集下的平均指数对比Tab.3 Average index comparison between MAT model and proposed model under CelebA-HQ test set
5 结束语
本文提出了一种基于掩码预测和多尺度上下文聚合的高分辨率人脸图像修复模型。该模型由一个生成器和一个判别器组成。生成器由编码器、多层MSCAM和解码器组成。为了生成看似合理的内容,提出了MSCAM来构造生成器,融合了来自不同感受野的特征,且可以捕捉遥远距离的上下文信息和感兴趣的模式进行上下文推理。为了改善纹理合成,通过使用MP-PatchGAN判别器迫使它区分真实和生成的小块(缺失区域)的纹理细节。此外,使用跳跃连接将编码器中每一层卷积层的输出与解码器对应位置的输入在通道维度上拼接,使得图像的上下文信息向更高层分辨率特征图传播。实验表明,本文模型在人脸图像修复任务中能够生成合理的内容和逼真的细粒度纹理。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
通信学报(2019年5期)2019-06-11
学与玩(2018年5期)2019-01-21
文苑(2018年18期)2018-11-08
动漫星空(2018年9期)2018-10-26
幼儿画刊(2018年7期)2018-07-24
通信技术(2018年3期)2018-03-21
浙江大学学报(工学版)(2015年4期)2015-03-01
发明与创新(2015年33期)2015-02-27
电子设计工程(2015年20期)2015-01-29
