
基于毫米波雷达与视觉融合的碰撞预警 *
2023-10-12 02:16李勇滔孙晨旭郑伟光许恩永李育方王善超
汽车工程 2023年9期
李勇滔,孙晨旭,郑伟光,2,许恩永,李育方,王善超
(1. 广西科技大学,重型车辆零部件先进设计制造教育部工程研究中心,柳州 545616;2. 吉林大学汽车工程学院,长春 130000;3. 东风柳州汽车有限公司,柳州 545616)
前言
随着汽车“新四化”(电动化、智能化、网联化、共享化)概念的提出[1],汽车的各方面技术不断发展,由于目前交通道路日益复杂,极易发生交通安全事故,而高级驾驶辅助系统(advanced driving assistance system, ADAS)是提高智能汽车安全性与平稳性的重要技术之一,通过主动安全装置避免事故发生[2-3]。环境感知为驾驶辅助系统的核心技术之一,其通过不同类型的车载传感器获取周围环境的物理信息,从而提醒驾驶员或辅助系统做出决策[4]。
毫米波雷达预警装置具有高识别率、不易受环境影响以及较高的灵敏度和抗干扰性成为智能预警装置的首选,但其分辨检测目标的类别能力较差,对静目标识别率低[5]。于增雨[6]针对上述分类较差问题,提出了一种结合CNN 与LSTM 的毫米波雷达目标分类方法,加强了对细节信息与时序信息的关注,有效地提高了目标分类的正确度。王战古[7]考虑到天气与车辆状态等因素的影响,建立了多因素耦合的雷达车辆检测模型,有效提高了毫米波雷达在不良天气下对车辆检测的精度。
与毫米波雷达装置相比,视觉传感器能够获取丰富的图像信息,能够准确识别静态目标及其类别。视觉传感器目标检测算法主要分为两大类算法,一类为基于传统的机器学习目标检测方法,另一类则为基于深度学习的目标检测方法。其中,基于传统的机器学习目标检测注重于特征的提取,与具体应用密切相关,但泛化能力及鲁棒性较差,又因为复杂的道路环境与车辆特征的复杂性,导致识别率低,误检率高[8]。深度学习目标检测算法主要有两大类:一类为基于候选区域提名的目标检测算法,如RCNN[9]、SPP-net[10]等;另一类为基于端到端(end-toend)的目标检测算法,无须区域提名的,如YOLO[11]、SSD[12]。张海明等[13]基于Faster R-CNN 网络模型做出改进,针对池化层压缩特征图丢失信息问题,加入了空洞卷积,并采用多尺度特征融合等方法,提高了目标检测的精度。谈文蓉等[14]针对车辆检测速度无法适应高速环境与小目标检测困难的问题,对YOLOv4 算法的主干网络、FPN 层与PAN 层进行改进,提高了识别准确率与检测速度,但在雨天和雪天等环境下精度较低。
然而,视觉传感器检测目标易受环境影响[15]。但是,通过毫米波雷达与机械视觉的目标融合算法可以互相弥补单个传感器的缺陷,且它们的成本低廉。Wang等[16]针对雷达的现有缺陷问题,利用提出的标定方法对摄像头与雷达进行标定,并采用视觉算法YOLO 与雷达检测结果进行决策级融合,结合两传感器各自优势,减少了车辆检测的误差。张炳力等[17]针对单一传感器检测精度差问题,将雷达检测结果与深度视觉YOLOv2 算法检测算法结合,并通过EKF 算法对目标进行追踪,提高了检测准确率,但采用的EKF 算法易受噪声影响,会出现严重波动。胡延平等[18]提取视觉图像Haar-like 特征,利用Adaboost分类算法检测车辆并生成车辆感兴趣区域,与雷达信息目标融合,最后通过KCF-KF 组合滤波算法对车辆目标追踪。虽然该方法有效地提高了环境感知的准确率,但所采用的传统视觉检测算法受到人工调试经验的影响,采用的追踪算法也未考虑外部环境影响。甘耀东等[19]对上述出现的问题,提出了自适应扩展卡尔曼滤波算法进行毫米波雷达追踪目标,并与改进的SSD 深度视觉检测目标信息相结合进行信息的决策级数据融合,充分考虑到外部因素对雷达追踪的影响,有效地提高了识别车辆目标的精度。但文献中设计的自适应追踪算法采用传统的开窗估计法,可能会使新息估计方差与实际差别较大,而采用的SSD 视觉检测算法需要人工设置预选框,导致调试过程非常依赖经验。
前碰撞预警系统通过安全距离与碰撞时间的设计,发出报警信息来提醒驾驶员做出判断。王艳玲[20]研究了驾驶员行为特性与环境因素对反应时间的影响,提出了基于模糊理论控制的安全距离模型,通过不同的反应时间来设置安全距离阈值,提高了预警系统的安全性与稳定性,但未进行实车测试,也未考虑车辆实际状态。
针对上述问题,本文提出了一种基于毫米波雷达与视觉融合车辆碰撞预警方法,其中对于雷达追踪目标问题,提出一种改进的遗忘自适应卡尔曼滤波算法追踪目标;对于视觉检测目标算法,采用改进的YOLOv5 视觉检测算法,由此提高检测精度。最后将雷达追踪目标ROI与视觉检测ROI进行决策级融合,如图1 所示。经实验证明,该方法提高了前方车辆识别的准确性与对外部环境的适应性。
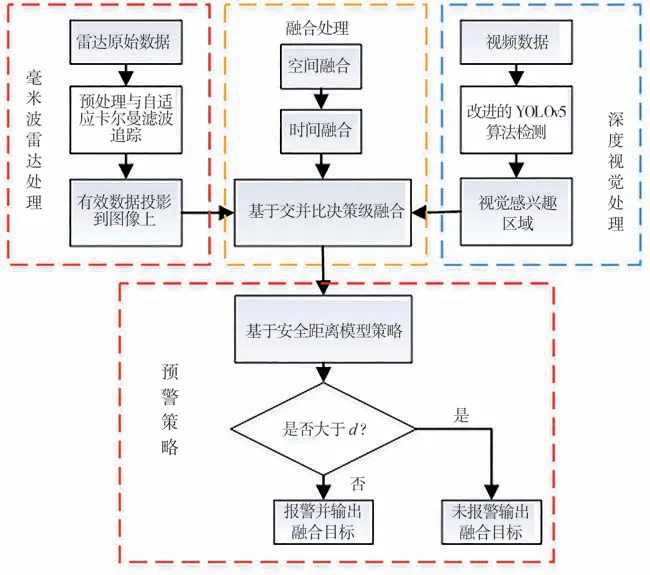
图1 融合预警算法的整体框架
1 基于毫米波雷达追踪前方目标
1.1 毫米波雷达数据预处理
毫米波雷达输出数据为目标点,包括探测目标点的横向距离、纵向距离、速度、角度等信息。在输出的原始数据中含有大量的空目标、虚假目标以及非危险目标,对真实有效目标造成了一定的干扰,也增大处理程序的计算量。因此,迫切需要去除干扰目标。针对空目标,其距离和相对速度等物理信息均为0,将此类数据筛选去除即可。基于相对速度与横向距离能够有效地将干扰数据进行滤波,设置有效数据点横向距离与相对速度阈值为
式中:X为后车与前方目标的横向距离;X0为设置的有效目标横向距离阈值;v为前方目标与后车的相对速度。毫米波雷达的检测速度范围为-66~66 m/s,根据相关公路规定以及大量实验证出,选取X0=4.75 m。
针对持续时间较短、连续出现较少的虚假目标,本文采用目标生命周期的方法[21]对虚假目标进行过滤,将生命周期设置为如下3 个阶段:形成、持续和消失。为此设定下列参数:DetectNum 为前方目标被探测的次数;LoseNum 为前方目标连续丢失的次数。
当前方目标每帧被探测到一次,则DetectNum加1;当前方目标每帧丢失一次,LoseNum 加1。根据设置阈值来处理,具体生命周期处理规则如表1所示。
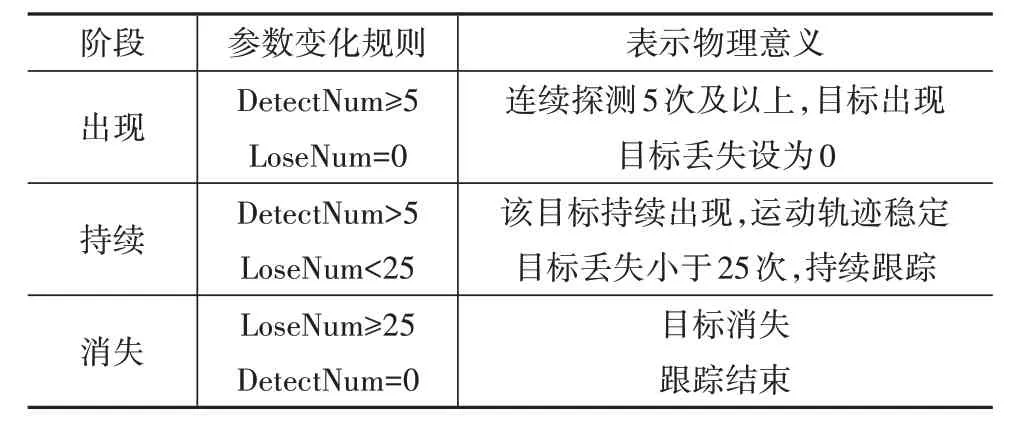
表1 目标生命周期阶段表示规则
毫米波雷达数据预处理具体算法流程如算法1伪代码所示。首先定义阈值等相关参数,通过横向距离与相对速度阈值条件对集合G的每个数据点进行筛选,得到处理后的数据集合G′,将同一时间采集的数据进行分类,并对此集合每帧数据进行生命周期统计,最后计算出真实目标数据集合G"。
图2 所示为毫米波雷达选取原始数据与数据预处理的对比。图中的数据点表示检测到的数据,其中绿点表示有效目标,而白点表示噪声。

图2 原始数据预处理效果对比图
1.2 改进的遗忘自适应卡尔曼滤波追踪
毫米波雷达通过检测前方目标,获取目标位置等数据,然后对该数据进行处理,自动形成航迹,并预测目标在下一时刻的位置。当雷达获取目标距离速度信息时,由于测量误差或过程中产生的噪声,使所获取的信息数据不准确,因此须采用滤波算法降低测量与实际值的误差。卡尔曼滤波(KF)是一种采用最小估计均方差(MMSE)准则的递归算法,可以通过获得先前观察到的目标状态估计和当前状态的测量值来估计目标的当前状态。由于交通道路车辆的非线性运动过程,可采用扩展卡尔曼滤波(EKF)将非线性问题线性化。EKF 主要包括目标状态估计与更新校正两大部分。

算法1 毫米波雷达数据预处理算法# define X0 4.75# define vmin -34; vmax 10//DetectNum为前方目标被探测的次数//LoseNum为前方目标连续丢失的次数输入:原始采集未处理数据点集合G={G1,G2,…,GN};输出:真实目标数据点G"1: 初始化环境、初始化数据G0,k←0;2: for k←1 to N do 3: 将集合G 中数据分别与阈值进行比较 //每个数据集合G(Xi,vi,…),包含距离、速度等4: if |Xi|<X0 && vmin<vi<vmax then 5: 将满足条件的个体放入集合G′中;//将集合G′中同一帧采集的数据进行分类6: end 7: DetectNum←0;LoseNum←0;8: for i←1 to N do 9: if 此帧探测到数据点Gi 10: DetectNum++;11: else LoseNum++;12: end 13: end 14: if DetectNum≥5 && LoseNum<25 15: 将满足条件的个体放入集合G"中;16: end 17: return G";
(1)目标状态估计
对于前方目标做非线性运动,其状态方程与测量方程分别为
式中:Wk-1为过程噪声;Vk为测量噪声,皆服从于高斯分布,Wk-1~N(0,Q),Vk~N(0,R) 。利用泰勒公式将式(3)中的非线性方程进行求偏导,得到雅可比矩阵,保留1 阶项以实现对非线性函数近似线性化。
扩展卡尔曼滤波更新依赖测量精度R和预测精度Q,由于外部环境等因素不断干扰信息过程,致使噪声以及其方差统计特性是未知且不断变化的,且不确定因素会造成扩展卡尔曼滤波无法精确追踪目标等问题。根据此问题,本文提出了一种遗忘自适应拓展卡尔曼滤波算法(FAKF)。
将k时刻式(3)实际观测值Zk和预测观测值Z^ -k之差,即新息ek,其公式为
则新息协方差Cek为
为保证协方差矩阵Rk是正定的,本文采用基于残差的自适应方法来估计Rk。
将k时刻实际观测值Zk和估计观测值^k之差定义为残差εk,其公式为
残差的理论协方差Cεk公式为
从上式得出噪声协方差矩阵Rk为
通过记忆指数加权法来估计新息的协方差矩阵,传统的开窗法只是对数据的平均,而此方法可以对最新测量的数据加权,提高最新时刻数据的权重,减少旧数据的影响,设置加权系数,根据负指数函数的运算规则对加权系数进行赋值,其公式为
式中b为遗忘因子,在运用过程中,当系统受到影响较少变化平缓时,b取较大值,反之b取较小值,b的取值范围为0.7~0.95。
由于式(9)对加权系数序列的要求,令
则加权系数为
利用遗忘因子求出自适应Rk:
同理利用新息求出状态噪声方差Q:
加入遗忘因子后求出自适应估计值为
1.3 建立目标追踪运动模型
在复杂的交通环境中,常见的CV 模型[22](恒定速度模型)、CA 模型[23](恒定加速度模型)为线性运动模型,不适合障碍目标的追踪。考虑到目标的转向等运动,本文采用更精确的CTRV 模型[24](恒速度恒角速度运动模型)。设运动目标的追踪状态量为
式中:x、y为目标位置;v为速度(x、y的合速度);θ为朝向角;w为偏航角速度。
假设目标的直线加速度aa和偏航角加速度aw为常数,考虑到实际运动中伴随着加速度的噪声,最终状态方程为
考虑到ω= 0时,简化公式为
在CTRV 模型中,对各个元素求偏导可以得到状态方程与观测方程的雅克比矩阵F和H。
2 基于深度学习的目标检测
选择YOLOv5 深度学习目标检测算法,只使用一个CNN 网络直接预测不同目标的类别与位置,并采用全图信息来进行预测目标的bounding boxes,以识别目标的类别。在准确率较高的情况下,实现端到端实时目标检测任务。
YOLOv5 具有比较简洁的结构,确保一定整体检测精度的条件下,计算处理速度快,但YOLOv5 在复杂的道路环境下检测准确度还不够,漏检率和误检率较高。YOLOv5 的4 个模型中的YOLOv5s 模型由于深度浅、宽度窄的因素,部署成本降低,便于模型的快速部署[25]。因此,选择YOLOv5s 并对其进行改进。
2.1 改进的CBAM注意力机制
为提高YOLOv5 的检测精度,本文提出了在卷积Conv模块加入双通道的注意力机制(convolutional block attention module,CBAM),结合了通道注意力和空间注意力的轻量级模块,促使卷积网络更加注重于所需局部目标特征的信息区域,减少全局冗余信息。基于通道注意力部分(CAM),特征图输入,通过并行的最大池化处理(MaxPool)与平均池化处理(AvgPool)后,进入多层共享神经网络(MLP),然后将MLP 输出的特征进行基于元素逐层相加,再经过sigmoid 激活函数操作,生成具有权重的通道注意力特征图。对于空间注意力模块(SAM),将通道进行压缩,在通道维度分别进行平均池化处理和最大池化处理,再将两个通道的特征图进行通道拼接(concat),最后通过卷积操作,经过sigmoid 激活生成最终的特征。经过实验,将两个模块串行组合最优化,特征图先进行通道注意力模块,再启用空间注意力模块,其过程公式为
式中:F为输入的特征图;MC为通道注意力的输出加权处理;F1为经过通道注意力加权特征图;MS为空间注意力的输出加权处理;F2为F1空间注意力加权得到输出特征图。
CBAM 中的通道注意力模块是将特征图在空间维度上进行压缩,得到一维矢量,然后通过逐元素求和合并,最终得到通道注意力图。由于空间的降维处理导致部分通道特征信息缺失,为避免此情况发生,选用ECA 模块代替CAM 模块。ECA 为不降维的局部跨信道交互策略,该策略可以通过一维卷积有效地实现。输入特征图通过全局平均池化(GAP),自适应选择通过大小为k的一维卷积核大小进行卷积且特征提取。k的自适应取值公式为
式中:k表示局部跨通道交互的覆盖范围;C为通道维度;|t|odd表示距离t最近的奇数;γ设为1;b设为2。
此外,空间注意力模块中的池化操作会先压缩特征图,然后利用上采样还原特征图,这种先压缩再还原的方式会导致特征图的信息丢失,促使网络提取的特征量不足,精度下降。利用空洞卷积[26]可以在感受野增大的同时,保持特征图尺寸不变,一定程度避免了特征信息的丢失。空洞卷积结构如图3 所示,以3×3 为例,可以通过3×3 的卷积操作,从而达到5×5或7×7的卷积效果。
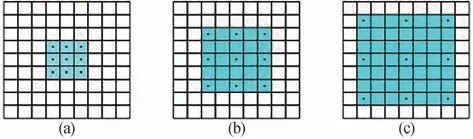
图3 空洞卷积的效果图
空洞卷积实际卷积核大小计算公式为
式中:k1为原始卷积核大小;d为空洞卷积参数空洞率。因此可以将空洞卷积与SAM 结合,首先将输入分别进行通道维度上的平均池化和最大池化,再进行空洞率为2 的空洞卷积处理,具体改进的SAM 结构如图4所示。
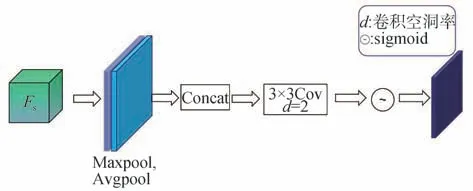
图4 改进的SAM空间注意力结构
2.2 数据集验证与对比结果
以国际通用的NYC3Dcars车辆公开检测数据集为主,其他数据集为辅进行整合,用作本文的数据集库,并利用labellmg 标注工具进行手动标注,如图5所示,并定义好检测车辆的类别,将改进后的YOLOv5s模型作为数据集训练权重,选用2 026张数据集作为YOLOv5 的训练集,并选用1 488 张数据集作为测试。该数据集分为晴天、晴雨、晴夜、雨夜4 种天气环境,占比分别为 34%、25%、30%、11%。检测后对检测数据集所有车辆类别进行mAP 指标计算,所得指标为76.16%,而本文提出的改进YOLOv5训练mAP为78.79%。

图5 手动标注数据集示意图
图6 为视觉算法检测效果。表2 为YOLOv5 与本文改进的YOLOv5 的检测对比结果。表中浮点运算数表示算法的计算量,本文算法与YOLOv5 算法相比,在轻微增加计算量与降低检测速度的前提下,检测平均精确度提高了2.73%,其中在YOLOv5 检测时,环境中其他非危险物体被误检测为车辆目标,如广告牌、房屋等,以及远处多车辆重叠未能检测出全部车辆目标等情况。而本文改进算法,添加了改进的注意力机制,更加注重目标特征,对上述问题起到一定的减轻作用,但还须借助毫米波雷达使精确度进一步提升。
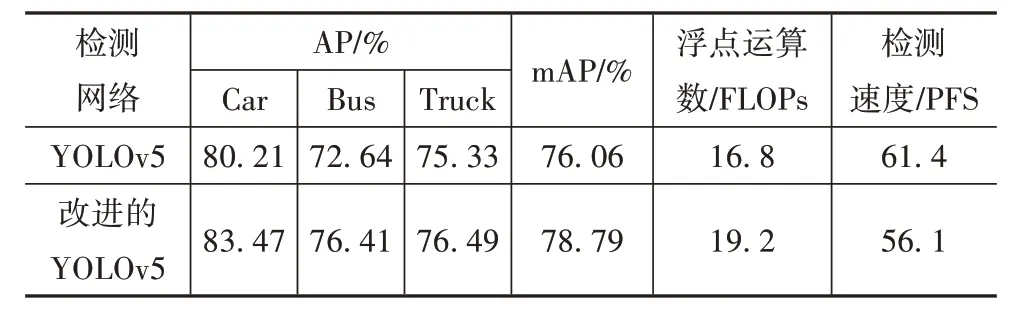
表2 本文算法与YOLOv5算法的检测精度对比

图6 视觉算法检测效果图
3 毫米波雷达与视觉融合预警策略
本文提出的融合方法是将雷达数据形成感兴趣区域,并与摄像头识别的图像数据进行匹配。由于毫米波雷达与摄像头的空间位置和采样频率不同,同一目标不同传感器感知的信息无法匹配。因此,当毫米波雷达与摄像头融合算法进行前方目标识别时,需要对不同传感器在空间和时间上进行同步。
3.1 空间融合
毫米波雷达与视觉融合的关键之一是实现毫米波雷达坐标系、三维世界坐标系、相机坐标系之间精确的转换关系,将不同的传感器坐标的测量值统一到一个坐标系,主要的空间同步方法为将以毫米波检测得到的目标坐标系转换到图像坐标系上。具体步骤为将毫米波雷达坐标系的坐标转换到世界坐标系,然后将世界坐标系的坐标转换到图像像素坐标系。毫米波坐标到世界坐标系的转换关系为
式中:[XY]为世界坐标系的二维横纵坐标;[XwYw]为毫米波雷达在世界坐标系的偏移量;[XrYr]为毫米波雷达二维坐标。
世界坐标系(Xw,Yw,Zw)转化为图像像素坐标系(u,v) 的关系式为
式中:Zc为相机坐标系中的Z轴坐标;(u0,v0)是图像坐标系投影点在像素坐标系中的坐标;R为相机外参旋转矩阵,是一个3×3的正交矩阵,有3个自由度;T为相对位移向量;f为摄像头焦距;dx、dy分别为每个像素对应像素坐标系横纵坐标轴的单位物理量。
3.2 时间融合
毫米波雷达与视觉传感器经过空间的融合后,还须在时间采集上进行融合。本文采用毫米波雷达的目标更新频率为20 Hz,而视觉传感器的采集频率为30 Hz。即雷达每帧采集数据的时间间隔为50 ms,视觉传感器的为33.3 ms。以毫米波雷达为基准,将具有较快采样率的传感器与具有较慢采样率的传感器兼容,融合具体原理如图7所示。雷达每隔2帧时采集数据,视觉传感器每隔3 帧采集数据,二者以100 ms 为周期同时进行采样。例如,当毫米波雷达在100 ms 时,获取一帧数据信息,同时视觉传感器也完成图像的采集,在采集时间上保持同步,以实现多传感器时间上的融合。
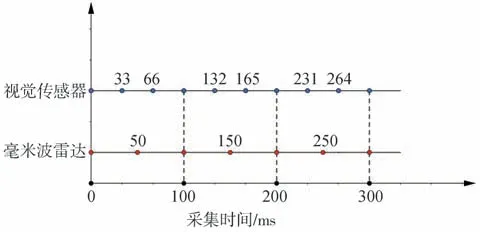
图7 毫米波雷达与视觉时间融合
3.3 基于交并比的决策级融合
本文提出决策级融合,将毫米波雷达检测结果与视觉检测结果对同一目标进行匹配,毫米波雷达基于遗忘自适应卡尔曼滤波处理后,输出的数据点通过空间转换投影到图像上,如图8所示。

图8 图像投影上的雷达数据
而视觉传感器通过改进的YOLOv5 算法,识别障碍车辆目标,由此形成视觉感兴趣区域,与雷达数据点为中心的感兴趣融合采用交并比[27](IoU)的方法进行数据匹配。交并比公式为
式中SC、SR分别为摄像头与雷达感兴趣区域面积。设置交并比的阈值为0.3、0.5。当0.5 ≤IoU≤1时,雷达与摄像头对同一目标均可识别,且检测结果基本匹配。当0.3 ≤IoU<0.5 时,此时融合效果一般,但仍判断目标存在,此时根据毫米波雷达与视觉各自优势,视觉输出目标的类别,毫米波雷达输出目标动态信息。
3.4 基于安全距离的前碰撞预警策略
当毫米波雷达与视觉传感器检测到前方障碍目标后,须通过碰撞预警控制策略对其做出决策,辅助驾驶员及时发现前方危险。本文在马自达安全距离模型[28]的基础上,结合了驾驶环境变化和驾驶员制动行为特征的影响,提出了一种精确的分段距离估计模型,如图9所示。

图9 防撞最小安全距离模型
如图10 所示,当前方车辆突然停止时,后车驾驶员并没有立即做出相应的制动,而是通过τ1时间之后才开始意识到采取措施,直到τ2时间才开始进行制动,在反应时间段τ=τ1+τ2中,主车视为匀速运动。踩下制动踏板时,由于离合器膜片弹簧内端和分离轴承间的空隙,此时制动力逐渐增长,此时主车做变加速运动,此阶段需要经过时间τ3。制动逐渐稳定后,主车开始做匀减速运动,此阶段经历τ4时间,后车停止。预警最小安全距离d为
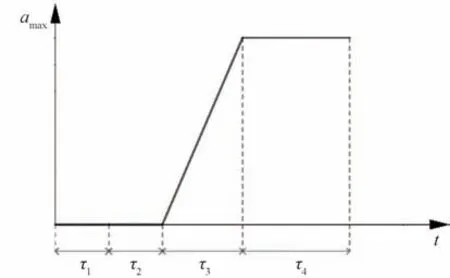
图10 减速度变化图
式中:v0为后车初速度,km/h;amax为后车最大减速度;L为车身长度,m。主车检测到前方目标,当超过最小安全距离d时,做出报警决策。
4 实验与分析
为验证本文融合预警方法的准确性与实效性,在晴天、晴夜、多云白天、多云夜晚、雨天、雨夜等多种天气条件下进行实车测试。道路环境也包括不同路面、不同工况等多种情况,实验采用的毫米波雷达型号为深圳的ANNGIC FR55F,工作频率范围为76~77 GHz,采用的图像识别传感器型号为深圳的ANNGIC FV-12M,输出图像分辨率为1280 ×1080 pixels,帧率为30 帧/s,计算机采用Intel Core i5-7300 处理器,内存为8 GB。算法采用MATLAB语言,上述设备满足实验计算要求。实验车辆与传感器如图11所示。

图11 实验车辆与传感器
在东风柳汽商用车试验中心将实验车按照规定的运动状态与路径进行测试,记录毫米波雷达探测的实车数据,以验证本文提出的基于遗忘因子的自适应卡尔曼滤波算法的可靠性,如图12 所示。分别利用FAEKF 算法与EKF 算法追踪前方目标,并将两种算法进行对比。图12(a)中的真实值是对车速传感器的实时车速与时间积分后进行差值计算获得,测量值为毫米波雷达传感器测得,两值皆用高斯噪声处理。图12(b)为两种算法每段时间与真实值的百分比误差,可以明显看出本算法的误差较低,通过均方根误差RMSE 来评价两种算法的精度,具体公式为
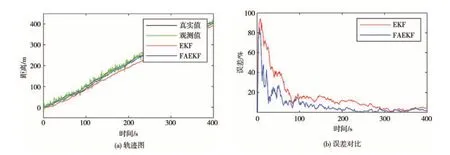
图12 EKF与FAEKF的轨迹图与误差曲线
式中:表示算法处理的最优估计值;yi表示真实值。通过计算得出传统算法EKF 的RMSE值为12.043 6,而本文算法FAEKF的RMSE值为9.750 4,对比显示,本文所用的算法得到的最优估计值与实际值误差较小,精度更高。
毫米波雷达与视觉融合效果图如图13 所示,其中前3幅图为晴天与晴雨道路场景,后3幅图为夜天与夜雨道路场景。每幅图中左边动画图的绿点为毫米波雷达检测出的障碍车辆,右边图为融合效果图。为展示本文提出的融合预警算法相比于传统的EKF算法和YOLOv5 算法结合的融合预警算法的优势,将不同算法分别进行实车测试,预警的定义为当目标进入最小安全距离,系统应该正常预警,若未报警则是漏警,而误报警的定义为前方未有危险目标而错误报警。表3 为本文预警算法与YOLOv5 和EKF联合的传统融合预警算法的实验对比结果。通过对比可得,基于相同的场景环境与里程数,相比于传统方法,本方法在预警准确率、漏警率和误警率方面都有明显优势。传统方法中使用的YOLOv5 算法在夜晚的识别效果较差,且传统的EKF 算法易受环境等噪声的影响,误警率较高。而本方法采用的视觉算法更加注重目标特征信息,一定程度上降低了漏检率,采用的FAEKF 跟踪算法自适应更新环境等噪声影响,提高了雷达跟踪目标的准确性。总体上本预警方法的准确率为94.72%,漏警率为2.97%,误警率为2.53%,相比传统的融合方法,准确率提高了2.41%,漏警率与误警率分别降低了0.78%、1.85%。
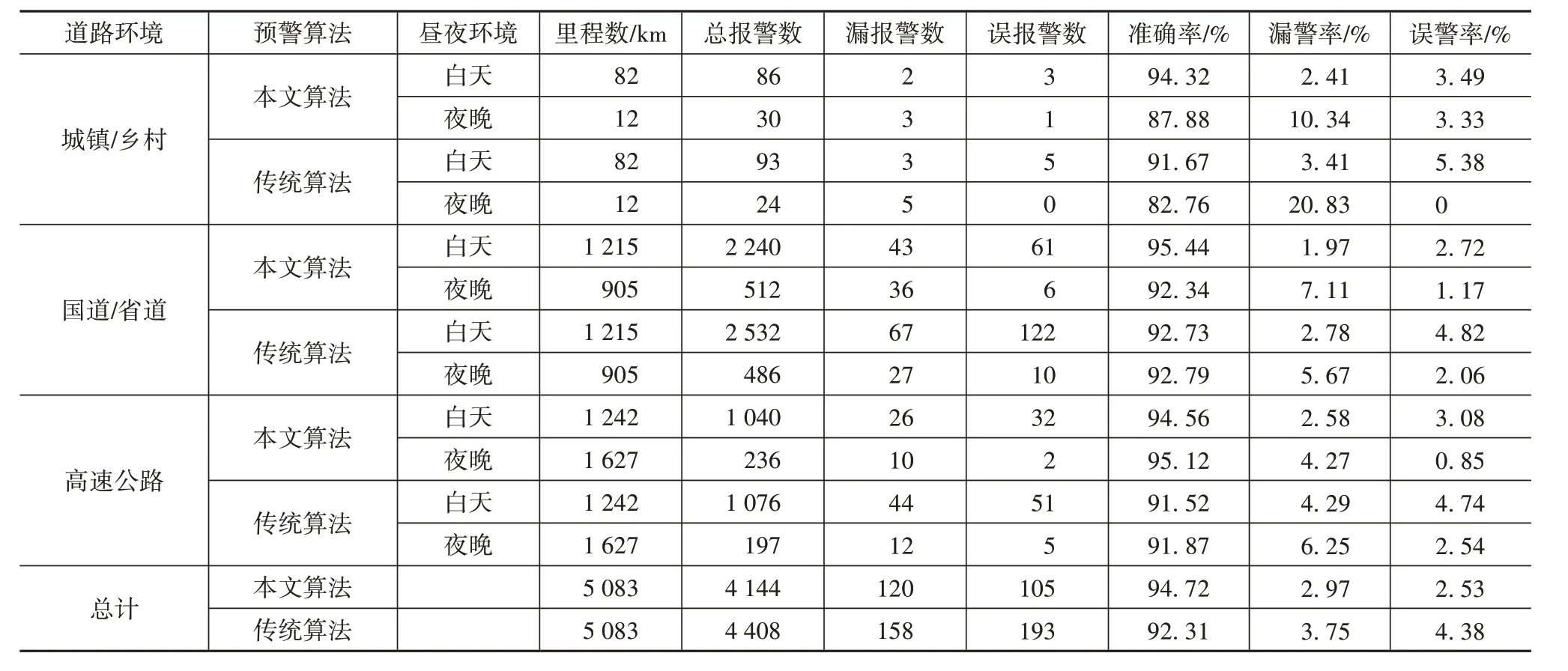
表3 本文融合预警算法与传统预警算法实验对比结果

图13 融合算法检测结果图
5 结论
提出一种基于毫米波雷达与视觉融合的碰撞预警方法对前方车辆目标进行监测,通过报警方式提醒驾驶员做出决策。根据毫米波雷达目标识别率较低的问题,提出了基于遗忘因子的自适应卡尔曼滤波算法,通过遗忘因子自适应更新与修正噪声及其方差统计特性,提高追踪目标的准确性。对于深度视觉算法精度较低、准确率较差的问题,提出了改进的YOLOv5 算法,在卷积模块中加入改进的CBAM双通道注意力机制,对前方车辆进行识别,促进了视觉检测的精度。
本文的毫米波雷达与视觉融合的预警决策方法通过不同道路场景的实车测试,验证结果证明,该融合检测碰撞预警方法的误警率和漏警率更低,具有更好的鲁棒性与准确性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年15期)2019-08-27
今日农业(2019年12期)2019-08-13
电子制作(2019年11期)2019-07-04
小学生学习指导(低年级)(2018年12期)2018-12-29
北京航空航天大学学报(2018年1期)2018-04-20
现代园艺(2017年22期)2018-01-19
火控雷达技术(2016年3期)2016-02-06
火控雷达技术(2016年3期)2016-02-06
百科探秘·航空航天(2015年4期)2015-11-07
