
基于关键场景的预期功能安全双闭环测试验证方法 *
2023-10-12 02:15吴思宇于文浩邢星宇张玉新李楚照李雪轲古昕昱李云巍马小涵郝圳茂
汽车工程 2023年9期
吴思宇,于文浩,邢星宇,张玉新,李楚照,4,李雪轲,古昕昱,李云巍,马小涵,路 伟,王 政,郝圳茂,王 红,李 骏
(1. 清华大学车辆与运载学院,北京 100084;2. 同济大学汽车学院,上海 201804;3. 吉林大学,汽车仿真与控制国家重点实验室,长春 130025;4. 中国汽车工程研究院股份有限公司,重庆 401122;5. 燕山大学电气工程学院,秦皇岛 066000;6. 北京理工大学机械与车辆学院,北京 100081;7. 北京航迹科技有限公司,北京 100193;8. 新加坡国立大学系统科学学院,新加坡 119077)
前言
汽车是交通中广泛应用的运载工具。随着科学技术的发展和变革,汽车成为前沿技术集成的最佳载体之一,正在加速向新四化转型。作为新一代复杂的工业化产品,智能网联汽车集控制技术、信息技术、智能技术于一体,在带来舒适、节能和高效运载能力的同时,其安全性也受到社会公众的广泛关注。
预期功能安全是道路运行安全的关键组成,与智能网联汽车的电气电子系统和信息智能算法强相关。随着智能网联汽车向着高级别发展,预期功能安全问题逐渐暴露,是制约技术应用和推广的严峻挑战,相关保障技术成为业界和学术关注的热点研究。其中,测试验证是预期功能安全保障的关键技术,支撑智能网联汽车安全开发的全生命周期[1]。
近年来,国际组织相继推出的智能网联汽车相关标准都明确包含了预期功能安全的测试验证。联合国自动驾驶验证方法工作组提出了自动驾驶的评估测试框架,以多支柱法为核心建立可重复、客观和可循证的框架说明自动驾驶的安全性,并将预期功能安全作为重要要求之一;国际标准化组织联合多家企业发布了自动驾驶标准ISO/TR 4804[2],提供了产品安全评估、监管和协作标准,并在其中确定了预期功能安全设计流程;国际标准化组织下属的自动驾驶测试场景工作组,建立围绕场景的自动驾驶评估框架3450X 系列标准[3-7],旨在提供从场景构建、分类到测试的标准化规程,并在场景构建过程中重点考虑了预期功能安全的典型触发条件;欧盟针对L3 及以上自动驾驶级别建立了ECE R155-157[8-10]系列标准,提供了网络、软件更新、自动车道保持系统的安全验证工程实践,并将预期功能安全作为基本要求;UL 4600[11]建立的面向安全目标评估标准,包含了对预期功能安全的评估。目前,智能网联汽车诸多标准中均提及了预期功能安全的必要性。然而,预期功能安全作为前沿技术概念,相应接受准则和论证方法尚处于研制和实践中,未在标准中进行具体规定。
国内外相关企业和项目组结合研发经验,在系统开发的工程实践中引入多样的测试方法和内容。Waymo 公司提出了自动驾驶28 个核心能力测试,并对整车级别进行公共道路测试、避碰能力测试、硬件可靠性和耐久性测试;Tesla 公司通过影子模式对特定驾驶行为及其场景数据进行识别和提取,积累数据用于支撑相关研发和测试[12];Continental 公司引入了安全分析工具对产品进行评估[13];宝马公司牵头的PEGASUS 项目组提供六层场景模型[14]来支持测试用例的构建,并综合因果分析[15]、多支柱方法和分层验证[16]等理念建立测试验证方法[17];美国交通部NHTSA 基于21448 预期功能安全标准对L3 级及以上的高速巡航系统进行安全分析实践,并提供了风险评估方案[18];欧盟的ENSEMBLE 项目提供从功能危害分析到风险评估的具体指导,并将功能失效按照系统进行归类[19];日本的SAKURA 项目面向L3级及以上的高速运行自动驾驶系统建立明确流程,并提供了具体测试场景分类[20]。上述工程实践面向自动驾驶系统或整车,将经典测试方法和专家经验分析进行充分结合,形成具有较强可操作的测试方案,并一定程度上考虑了预期功能安全问题。然而,上述方法大多基于专家经验分析,缺少系统的论证过程和充分的理论支撑。Zhang 等为避免不同基准数据集对测试评价的影响,设计级联坦克模型建立不同细粒度的难度等级[21];Huang 等基于共克里金模型(co-Kiriging model)综合分析了不同可信程度的测试结果[22];Xu 等开发了基于场景的测试平台SafeBench,集成多个关键测试场景和测试指标[23];此外,多个文献也综述了当前自动驾驶测试技术和应用进展[24-26]。上述测试方法主要面向自动驾驶算法,然而预期功能安全具有特殊性和复杂性,不能简单复用经典测试方案和框架,须根据其特征设计新的方法论和技术手段。
智能网联汽车系统的复杂性和道路运行语境的开放性给预期功能安全测试验证提出了新的挑战。因此,需要一个兼具高效性和通用性的框架支持预期功能安全系统性测试验证。具体而言,智能网联汽车预期功能安全测试验证方法应考虑预期功能安全特点,建立通用的框架支撑完整的系统性论证过程,并将基于经验的分析方法和前沿的智能方法相结合形成兼具可操作性和可靠性的测试验证技术。
本文从预期功能安全概念分析出发,结合智能网联汽车特点创新性提出一种双闭环框架,分为封闭验证和开放论证两个阶段进行测试验证(第1节)。进一步地,本文针对关键场景和接受准则两个核心问题,设计了关键用例和交互环境的构建流程并综合论述具体实现技术,同时提出双层接受准则的量化方式并引入了人类驾驶员模型作为接受准线。最后,本文从场景构建实践、测试工具、数据积累3 个方面对预期功能安全测试验证领域面临的挑战进行总结和展望。
1 预期功能安全测试验证框架
随着智能网联汽车对电气电子系统和复杂算法依赖性的增加,ISO 21448标准定义了预期功能安全概念,对功能安全(functional safety, FuSa)[27]所定义的电气电子故障之外的安全风险进行补充。本节从智能网联汽车特点和预期功能安全概念分析出发,说明测试验证目标和需求,并提出一种全新的双闭环框架。
1.1 智能网联汽车预期功能安全分析
智 能 网 联 汽 车(intelligent connected vehicle,ICV)是一种搭载传感器、控制器和执行器等先进装置,融合现代通信与网络技术,进行人、车、路的信息交换共享并具有不同级别自动驾驶能力的新一代运载设备。环境感知、地图定位、决策规划、控制执行、网联通讯、人机交互是ICV 典型6 大系统[28-29]。此外,也有研究和应用将部分系统功能整合,形成端到端的黑盒系统[30-31]。ICV 集成了复杂多样的软硬件技术。从顶层技术框架到具体的算法参数设置,不同ICV 配置具有较大差异。另一方面,ICV 系统软件和算法深度应用人工智能技术,在建立自动驾驶的同时也带来了不可解释的特点,其行为动机在部分案例下与人类驾驶模式具有一定差异性。因此,无法只依赖人类驾驶经验或系统结构分析对ICV 的封闭系统进行故障排查和测试验证。
预期功能安全(safety of the intended functionality,SOTIF)定义为不存在因预期功能不足引起的危害而导致不合理风险[32]。其中,预期功能是在整车层面定义的功能,在考虑能力局限下的标称功能界定为预期行为。功能不足既包括规范定义的不足(如不完整的规范定义),也包括性能局限(如技术局限)。功能不足的指向范围既有整车层面的预期功能,也包含电气电子要素的实现(包括硬件、算法等)。功能不足会导致危害行为或无法防止、探测及减轻合理可预见误用。
图1 展示了智能网联汽车伤害(harm)触发路径。运行环境中未知或已知的风险要素形成触发条件,导致整车或系统层面对预期功能的规范不足,亦或是系统组件的性能存在局限无法满足功能定义的期望,形成SOTIF 风险。SOTIF 和FuSa 造成的危害(hazardous)行为包括直接产生风险(如造成新的损伤或原有损失的严重度增加),或间接使风险的控制能力降低(如原有的控制措施失效,或危害事件发生概率提高)。如果定义的控制措施无法有效控制危害行为,则危害行为转为危害事件,对交通参与者、道路设施等具体实体对象产生伤害。
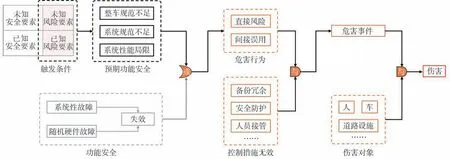
图1 智能网联汽车伤害触发路径
SOTIF危害来源于ICV,在运行环境中产生和演化,最终又影响ICV 整车和系统。ICV 需要面对人-车-环境高度耦合的动态场景,丰富的时变要素共同构成了“维度爆炸”问题[33]。随着ICV 向着高级别自动驾驶发展,运行范围逐步扩大,“长尾效应”带来的稀有事件影响进一步放大。因此,ICV 的SOTIF 测试验证离不开系统本身和运行环境。
1.2 SOTIF测试验证要求分析
测试验证贯穿从定义到确认的完整研发流程,是保障道路运行安全的必要环节。测试验证通过观察被测对象在设置条件下的系统响应,评估被测对象在实际运行条件下的状态。
SOTIF 测试验证重点论证系统“未失效”情况下的“不完美”的程度。SOTIF 测试验证通过一定流程对ICV 系统及整车潜在的功能不足和危害行为进行暴露,促进研发流程中对相关功能的维护以及整车或系统运行范围的规范,为监管部门提供安全状态的确认证据,并向市场客观评价性能水平。
因此,ICV 的SOTIF 测试验证目标定义为在一定的框架范式中综合各类技术手段,应用有限资源,高效、可信地暴露系统功能不足,规范整车安全运行范围,提供相应证据确认风险在可接受范围内。进一步地,对ICV 的安全性能进行说明。综合考量ICV 产品快速迭代的特性以及测试验证对于安全保障的重要地位,论证的可操作性和严谨性是测试验证方案的主要导向,细化的要求包括但不限于如下内容。
通用性:测试验证应具有通用可扩展的流程框架,能够适应不同的测试对象和层级,兼容不同技术手段以充分支撑测试内容。
高效性:测试验证方案设计应兼顾覆盖度和效率,提高具体方案的效能,减少不必要的成本。其中,低冗余是提高效能的关键,包括但不限于减少测试用例的重叠、非必要技术手段和轮次的重复。
客观性:测试过程应保持客观中立,方案设计和实施流程应统一、明确;验证目标需要通过全面、有效的证据说明;确认准线或阈值的设定不应随被测对象的具体配置或结构更改。
完备性:测试对象应包括从软硬件系统到整车集成的多个层级;测试内容应覆盖所有必要的考量因素;评价指标应避免单一安全指标,综合考虑不同评价维度。
一致性:测试验证结果应和现实道路运行具有一致性,包括具有一定保真度的技术实施手段、与现实环境相同的交通运行逻辑等。
可循证:论证过程应明确可靠,包括合理的假设与前提、严密的理论说明、可重复的执行过程、可回溯的证据链条等。
除了上述要求外,测试验证方案设计还应关注过程的规范性、实施的安全性等。
不同于FuSa 等安全验证思路,SOTIF 与系统功能、运行环境强相关。ICV 的系统组成具有多样性、封闭性,且与人类驾驶逻辑存在一定差异。运行环境的开放性导致了时变高维和长尾场景。考虑上述挑战,本文提出如下SOTIF测试验证要点。
(1)基于关键场景的执行载体
ICV 在特定交通环境下引发SOTIF 风险。将特定运行条件转化为关键场景作为外部条件,获取测试对象的系统响应,分析评估实际运行范围内功能情况,判断潜在的SOTIF 安全风险是否可接受。其中,关键场景可以是精心设计的时序片段用例,也可以是一定运行范围内的连续交互环境。
(2)分层次的多支柱技术手段
完全依赖开放道路进行SOTIF 测试会产生高昂的成本和不可控的安全风险。结合测试目的和技术特点,引入多种仿真手段和封闭场地构建多支柱测试平台。考虑被测对象的特点、测试的成本和需求,匹配相应的技术手段进行分层次、分周期的综合测试,在误差允许范围内提供高保真的结果。
(3)数据驱动的可循论证
数据支撑严谨可信的SOTIF 论证过程。基于路采数据,能够设计出与现实环境一致的场景要素(如运动分布),进而构建合理、符合现实运行逻辑(如交互规律)的场景;基于测试过程获得的数据(如指标),能够为测试目标的验证和确认提供具有说服力的证据;基于统计数据,可以进一步为接受准线的设定提供有效支撑。
1.3 基于关键场景的双闭环测试验证框架
兰德公司在报告中指出,需要进行百万公里的测试里程才可证明被测系统在95%的置信度下具有和人类驾驶员相同的安全水平[34]。在开放环境下论证无条件的绝对安全难免落入西西弗斯的困境。因此,测试验证的方案设计应兼顾论证充分性和执行的可操作性。具体而言,有两个核心问题:
(1) 如何设计测试内容,在保证充分性的前提下提高测试效率?
(2) 如何确定测试终止条件,从而保证验证内容的充分性可被接受?
考虑SOTIF 特点和前述挑战,从二八定律得到启发,本文提出一种基于关键场景的SOTIF 双闭环测试验证框架,如图2 所示。框架分为封闭验证和开放论证两个阶段,第一阶段对80%以上的已知典型风险场景进行快速验证,以优秀谨慎人类驾驶员为基准确认基本安全;第二阶段构造非定式的交互环境,通过挖掘被测对象的长尾场景持续论证等价于百万公里及以上里程的残余风险情况。
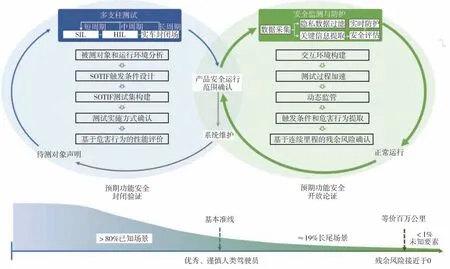
图2 基于关键场景的双闭环测试框架
封闭验证阶段基于待测对象的声明,将已知运行风险转化为代表性测试用例,综合多种测试技术安全可控、高效全面地对潜在SOTIF 危害进行验证。进一步地,对标优秀、谨慎的人类驾驶员确认安全运行范围,对SOTIF潜在危害进行说明。
首先,基于待测对象所声明的设计运行条件、驾驶动态任务和相关系统确定场景要素、预期行为和潜在功能局限,从而获取触发条件和潜在危害行为并转化为有限时长的最优测试集。其中,最优测试集覆盖已知触发条件,并根据验证目标赋予关键要素代表性数值。接着,综合被测系统响应和测试需求,分配软件在环、硬件在环和整车实测等实施技术和周期频次。最后,分析危害行为并设计恰当的指标进行评价,对标人类驾驶员通过情况设立测试准线,验证被测对象是否满足基本安全要求并确认合理的运行条件。若在封闭验证阶段有充分证据说明被测对象满足基本要求,则进入开放论证阶段。
开放论证阶段构建了非定式的交互环境,在不影响整车操作运行的前提下进行数据采集和脱敏、关键信息提取以及安全评估与防护,通过“监-测”并行在动态监管的同时履行后测试的论证工作,进而暴露游离在封闭验证之外的触发条件、识别新的危害行为,并确认SOTIF累计残余风险。
开放论证阶段首先需要构建具有真实性的交互环境作为论证对象的运行空间,包括高保真的本体和一致的交互逻辑。其中,高保真的本体应具有和现实世界相同的交互过程、特征分布,而一致的交互环境则应包含合理的运行逻辑、信息传递以及逼真的畸变等趋向于现实世界的物理局限。特别地,开放道路是构建真实的交互环境最直接的方式,但成本和安全风险较高。在此基础上,通过加速测试技术在不改变环境真实性和论证置信度的前提下加快危害事件暴露。运行过程中,设计合理的动态监管过程,基于实时状态数据确认系统安全情况。
若系统正常运行,可基于连续运行里程直接计算残余风险;若系统触发异常状态(包括潜在危害、交通违规等情况),则启动安全防护策略并以最低风险形式暂停运行。同理,对于升级等系统变更情况,也需要暂停开放论证运行。与此同时,基于采集的数据信息和异常状态,提取触发条件与其诱发的危害行为。当系统完成维护后应对变更部分进行重声明和补充的封闭验证。若相关验证结果满足预设的接受准线,则可再次进入开放论证阶段。
封闭验证面向已知场景构建最优测试用例集,在有限测试资源下对风险进行快速、高效地暴露,并结合危害行为对标优秀、谨慎的人类驾驶员验证基本安全,确认合理运行范围;开放论证通过构建非定式的交互环境,挖掘被测对象未在封闭验证阶段暴露的触发条件和危害行为,确认等价连续里程的残余风险,进一步加强论证置信度和覆盖率。双闭环框架用最小资源成本快速完成主体验证内容,确保基本安全;进一步通过持续论证来接近理想安全情况,减少危害事件。同时,以人类驾驶员为准线来兼顾论证的充分性和执行的可操作性。
2 双闭环SOTIF场景构建
场景是SOTIF 测试验证的基本载体。双闭环两阶段分别将关键场景设置为测试用例和交互环境,诱导SOTIF 风险,通过观察被测对象状态进行安全验证。本节将对SOTIF 场景关键概念进行定义,并建立触发条件的提取路径,对双闭环中测试用例和交互环境的构建技术和平台进行综述。
2.1 SOTIF场景定义
在交通领域,场景通常包含道路、交通流和相关影响因素。当前,多位学者从不同角度给出了场景定义[26,35-40],可以总结为场景是现实交通语境的描述与再现。基于本体论,本文对场景概念定义如下。
定义1:场景(scenario)是时间序列下的环境、交通参与者、观察者自我的组合表征以及各自的实体关系的描述,数学模型如下:
式中:Object表示组成场景SA,T的所有实体概念,具有一组描述物理特征及其传递信息的属性;Relation表示场景实体间存在的物理或信息关系,可以是两个特定实体关联或一组实体共有的联系。
定义2:自车Ego表示场景中重点关注的实体,通常设置为被测对象,是一种特殊的Object。
定义3:观测途径View表示场景中实体(被观测者)和实体(观测者)在特定物理条件下的映射关系,是一种特殊的Relation,受到观测角度δ、观测设备Equipment、采样精度Δ共同影响。
基于场景定义,综合信息熵(information entropy)和语义层次(semantic level)将场景表达建立为数据-本体的双层表达结构。
本体层通过领域知识,提取场景信息中的类和关系,在概念层面构建场景的时空图,数学模型为
式中:O对应场景本体中Object的具体要素类型,对应面向对象方法中“类(class)和实例(instance)”;R对应场景本体中的Relation的具体关系数据。
特别地,O和R在地理空间范围A、时域范围T内具有一定动态演变逻辑,通过状态特征集X表示。其中,样本x(i)满足分布x(i)~ΠX。
数据层基于观测途径,将场景实体集合的观测信息映射到特定维度,形成一定格式的时序数据文件,数学模型为
数据层的具体表达形式与观测设备、角度强相关,具有多模态特点。数据层所捕获的模态越丰富,采样频率越小,信息量越丰富。本体层记录场景中所包含的类和关系,并形成语义和知识层级的理解。从数据层到本体层,信息被不断提取、理解,抽象程度增加;从本体层到数据层,概念被逐步具象、记录,信息量升高。
预期功能安全场景(SOTIF scenarioes)为能够引发SOTIF 风险,且在实施不恰当控制的情况下会引发危害的场景。
SOTIF 场景架构从SOTIF 角度划分并形成层次关系的场景要素集合及描述方式,包含所有可能会引起SOTIF风险的场景要素及其组合。
基于Groh 等学者对于交通场景架构设计[41-44],本文提出一种SOTIF 场景架构设计,如图3 所示,包含道路结构、道路设施、道路临时改变、交通参与者、天气环境、数字信息和自车状态共计7层。
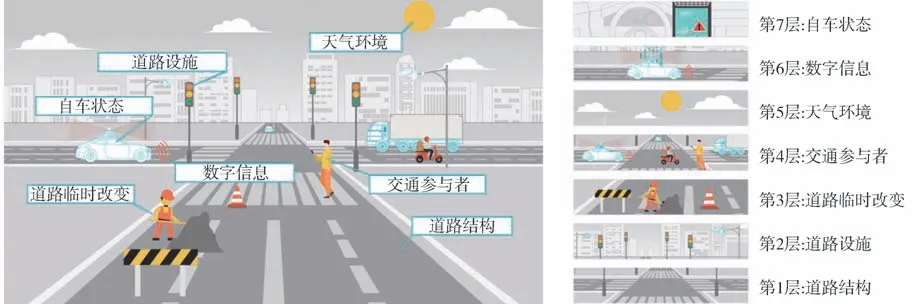
图3 预期功能安全场景架构
基于场景抽象层次[45],被测对象确定功能场景类型;进一步,逻辑场景给定m个场景要素,第i个要素有ni个状态且满足分布ΠXni,进一步按一定演化方式ξ确定场景状态序列。
2.2 SOTIF触发条件提取
触发条件(trigger condition)是引发SOTIF 风险的来源,由场景中特定的实体O*、关系R*或其组合构成,数学模型为
从本体语义角度考虑触发条件来源为环境态势理解、应对的不足;从多模态数据角度考虑来源于观测数据的不充分或错误。特别地,触发条件中实体和关系的关键特征可能满足特定分布范围,进而引起SOTIF风险。
特别地,Ego系统作为实体本身或特定View关系也是一种典型的触发条件,通常由固有的物理局限性产生SOTIF 风险,不由外部特定实体组合引发。前者和人机交互规范与误用情况相关,后者包括但不限于观测角度产生畸变导致识别错误、采样精度不足产生的漏检或误检、观测设备噪声和反射带来的问题。
触发条件暴露ICV 系统功能不足,导致了危害行为或无法防止、探测及减轻合理可预见的间接误用[3],概率模型表示为
式中:H表示危害行为;P(tc)表示触发条件概率分布;P(H)对应风险发生概率;P(H|tc)表示触发条件tc到危害行为H的转化概率,显化了触发路径。
特别地,触发条件引起前序系统的功能不足或危害行为后,会随着驾驶流程向后续系统传递放大直到被安全策略阻断。
基于上述模型,触发条件本质上是对场景要素和系统危害行为进行因果推断(casual inference)。触发条件提取可以视为为结构方程构建(structural equation models)和因果效应估计(casual effort estimation)两个主要问题[46]。
归纳方法(inductive method)从研发或运行过程采集的大量数据中识别归纳触发条件,如图4 所示。首先,对场景的组成要素进行分析、拆解,包括但不限于与危害事件相关的实体、关系以及自车受到影响的系统。接着,排除混杂因子(cofounder)并提取因果模型的关键要素。最后,综合基于约束[47-48]、基于分数[49-50]、基于结构模型[51-53]等推断方法或基于人工智能[54-58]建立因果模型或提取因果效应。
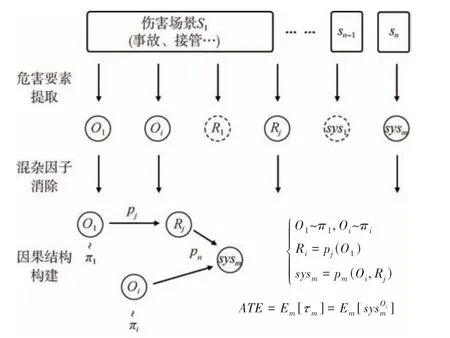
图4 归纳方法分析路径
归纳方法本质上是基于大数据的统计学方法,对危害发生的过程和程度进行归因。若系统结构和行为范式不了解、危害发生的机理不明确、缺少充分先验知识,可以采用归纳方法提取触发条件。
演绎方法(deductive method),从系统功能属性出发推演危害行为并获取触发条件,如图5 所示。首先,从场景要素的特征分布中选择初始状态X0,基于一定转化策略P确定场景演化过程并记录状态。进一步地,基于专家分析等方法[59-60]确定危害判定条件并提取关键状态。最后,综合对关键要素进行分析、提取,确定产生危害的因变量和特征分布,并估计因果效应[61-63]。

图5 演绎方法分析路径
演绎方法的本质是基于确定的演化策略进行事件推演,从而对危害事件和因果模型进行补充。演绎方法适用于缺少样本的触发条件分析,但需要有充分先验知识以支持系统演化和关键状态判定。
最后,基于上述方法获得的因果关系对当前触发条件框架进行补充和完善:对同型触发条件进行合并、重构和扩展,如要素类型优化、特征分布调整;对新型触发条件进行补充、规范和泛化,如框架分支增加、关键因素泛化;此外,还可以对要素的特征分布进行因果分析,在要素基础上进一步挖掘从特征分布到危害的因果关系。
2.3 封闭验证测试用例的构建
封闭验证将已知场景构建为有限资源条件下最优测试用例集合,本质上是将运行条件进行重构采样,通过被测系统对有限采样用例中的风险应对情况,充分、有效地还原在实际道路上的状态响应并暴露潜在风险。基于场景本体模型,封闭验证的最优测试集合可以建模为如下优化问题:
式中:LS表示所构建逻辑场景类型总数;Numls表示第ls个逻辑场景类型下采样的具体场景数目;Xlns表示具体场景要素属性的状态采样,满足分布Xlns~ΠXS;sys(Xlns)表示被测系统在具体测试用例Xlns中的响应操作;Critical(*)表示场景关键性评价公式;Cost(*)表示测试成本量化方式;Coverage(*)表示场景覆盖度评价公式;Costmax表示测试资源的限制;Coveragemin表示场景覆盖度的最低要求。优化问题的目标为最大化测试用例集合关键性,约束条件分别代表测试资源限制和论证充分性要求。最优测试集合的构建需要通过合理的场景建模、准确的指标设计和高效的采样技术共同实现。
上述方法中,覆盖度、风险度是测试用例集合评价的主要维度。对于覆盖度而言,多因子组合(Twise)[64-69]和修正判定条件覆盖(modified condition/decision coverage, MC/DC)[70-72]提供了结构化的充分性量化方法;相似性从另一个角度衡量覆盖度[73],在此基础上可以通过添加相似度较低的新场景来提高测试集合覆盖情况[74-76];风险度是安全验证的核心指标,也是测试用例效用的直接体现。场景风险评估指标主要基于代理模型的安全状态进行评估[77]。学者从反应时间[78]、意图[79]、不确定性[80]等角度量化碰撞风险;Malin 基于统计学分析场景条件组合和事故风险的概率关系[81];Althoff 将生成场景风险与可达解空间关联[82];此外,复杂度也是衡量场景风险的一种间接指标,通常认为危害行为在复杂场景下更容易产生危害。复杂度可以基于对系统产生关键影响的因子数量和耦合情况进行量化[83-86]。
数据重构场景的方法提取现实道路运行中的关键事件、分类并重构为测试用例。实际交通事故通常包含一定危害条件,从关键数据重建模拟场景并进行测试验证是基本的评估路线方法[76,87]。随着数据采集技术的丰富,提取、分类和聚类方法研究提供了更有价值的场景信息。Zhang 等结合高斯速度场给出了俯瞰视角下场景轨迹时变交互趋势的表示方式[88];Oeljeklaus 等提出了两路集成的深度神经网络对视频数据同时进行图像语义分割和道路拓扑识别[89];Zofka 等从传感器中导出轨迹数据提取道路布局[90];Bolte 等针对感知系统定义边缘场景为无法预测类别,并结合语义分割和图像检测从视频输入提取边缘场景[91];Siami等对手机获取的轨迹数据依次进行自组织映射、深度编码器和分区聚类实现无监督的行为识别[92];Ries 等将场景用顶视图网格(topview grid)表示,并通过卷积神经网络和长短期记忆神经网络提取场景的时空特征[93];Mavrogiannis 等提出采用拓扑编织(topological braids)来捕获场景的关键交互情况[94];Erdogan 等提供了基于规则、有监督和无监督3 类从传感器数据提取场景的方法[95];Gruner等综述不同场景的表示方法和基于神经网络的分类技术[96];考虑到隐马尔可夫能够有效处理非定长数据,Wang 等和Martinssor 等分别基于该模型提取场景基元[97]并进行分类[98];Beglerovic 等展示了深度学习在场景分类上的应用[99];此外,随机森林[100-101]、基于距离[102-103]等方法也能对场景数据进行主动聚类。
数据重构场景方法主要对采集的关键事件进行再现,或在原有事件基础上进行扩展泛化。然而,实际道路中关键事件的稀缺性,数据采集的成本和安全性给这一类方法路线带来较大的负担和压力。机理建模场景的方法在一定目标和约束下,通过场景模型的建立和相关参数的选择完成测试用例的生成,提供了一种低成本、高效率的场景构造方法,且可能挖掘到实际运行过程未发现的长尾场景。
本体表示对客观事物的系统性描述,是机理建模场景方法的重要基础。早期场景本体建模主要服务于自动驾驶系统,将知识转化为概念以便自动驾驶系统能够理解场景,从而更好地进行风险辨识[104-105]、推理[106-107]、感知[108-109]、决策和规划[110-112]。随着相关研究的推进,学者们逐步优化交通参与者[113]、道路地图[114-115]、空间关系[116]、交通规则[117,28]等本体模型,并引入面向对象语言[35,118]、领域特定语言[119,40]、图数据库[120]等进行技术实现。进一步地,学者将场景本体应用于场景数据标注和提取[121-123]、场景库存储[124]和聚类[125,37]、测试用例的导出[126-127]等相关工作。
组合和优化是机理建模场景的主要路径。前者通过对场景要素的合理组合实现逻辑场景及更高层次的用例构建;后者则将用例生成的目标和要求建模为优化问题并对最优参数进行搜索。
组合测试将前述本体转化为被测系统输入算法,通过组合方法生成逻辑场景[128],并通过参数采样形成具体用例;Gao 等提出一种基于复杂度的组合测试算法,进一步构建联合仿真测试平台实现测试闭环[129-130];Fujikura 等引入时序逻辑语言对场景演化状态进行形式化描述并通过路径穷举构建高覆盖度危险场景[131];Manna 等关注到场景交互的关键性,从模态序列图中组合构建最小测试集[132];Gladisch 等面向感知系统将领域知识进行表达,并通过环境特征组合进行覆盖度确认,识别缺少的测试场景[133];优化方法通常在给定场景范式下,采用随机优化迭代[134]、梯度下降[135]、非线性优化[136]、模拟退火[137-138]、快速搜索随机树[139]、粒子群算法[140]、随机森林[141]、贝叶斯优化[142-144]等方法加快对参数采样空间的搜索;进一步地,进化算法为场景生成提供一种兼顾多样性和关键性的优化方法,能够较好处理多参数耦合的复杂场景问题[145-147];Scheibler 等提供了一个i-SAT 算法,对待约束空间的场景优化生成问题进行求解[148];Zhu 等结合社会认知优化算法(social cognitive optimization, SCO)、密度峰值聚类和(density peak clustering, DPC)冷却调度函数在逻辑场景层面进行全局搜索,同时采用多维卷积算法在具体场景进行局部采样[149];此外,Zhu等开发了一个由探索和利用模块、移动概率确定模块、步长确定模块、内存模块和结果分析模块5 个部分组成的场景强化搜索方法[150];Olivares 等结合马尔科夫链和蒙特卡洛采样方法生成场景道路结构[151];Jesenski等引入贝叶斯网络允许场景在任意道路拓扑上建模[152];Rocklage 等将轨迹规划器作为场景可行性检查工具,同时引入回溯算法对约束进行处理[153];考虑到复杂场景的高维空间耦合导致测试样点分布更加稀疏,Yang 等使用多元线性回归技术调整测试场景,实现关键变量的稀疏控制[154];Geld 等提出奇异值分解(singular value decomposition, SVD)来降低场景参数向量维度[155]。
如图6 所示,开环场景构建方法通常假设代理模型和被测系统具有一致性。自适应测试可根据系统响应主动调整环境并构成闭环反馈,通过响应情况定制化测试过程从而减少代理模型和黑盒被测系统的响应差异。
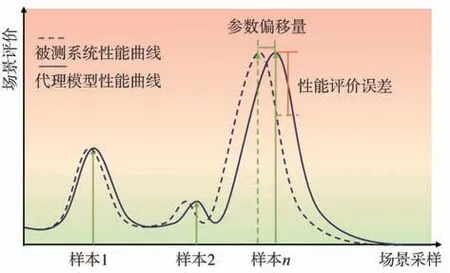
图6 开环场景构建样本偏差
Mullins 等针对黑箱自动驾驶系统,提出了基于仿真结果的自适应场景搜索,并进一步通过无监督聚类对测试场景进行分类[156-157];Koren 等在自适应压力测试框架下,用深度强化学习代替蒙特卡洛提高搜索效率[158],提出Go-Explore 算法来避免依赖特定的启发式奖励[159],并通过递归神经网络减少计算复杂度,建立相似初始条件的潜在关系[160];Du 等将域知识[158]和轨迹相异性[161]引入奖励函数引导自适应搜索;Feng等为补偿代理模型和被测系统的差异,基于贝叶斯优化方法建立一个自适应场景库生成测试框架,采用基于分类的高斯过程回归估计非固定的差异度函数并设计捕捉函数来确定的新增测试场景,具有更高测试效率和鲁棒性[162-164];Yang 等考虑场景高维问题,在自适应测试中应用基于控制变量的多元线性回归技术对测试过程进行优化[154];Ding等基于一组自回归场景构建块并通过联合采样生成不同场景,同时分别将场景和被测系统视为智能体,以风险为奖励通过策略梯度强化学习方法对其进行训练优化[165];进一步地,Ding 等提出了一种基于流的多模态安全关键场景生成器,通过最大化加权似然函数来优化生成模型,并基于生成器的学习进度反馈自适应地调整采样区域,形成对抗性训练框架[166];此外,Ding 等将知识分为对象的性质和关系,提出树结构变分编码器(tree-structured variational auto-encoder, T-VAE),通过对节点和边的属性施加语义规则提高了场景生成过程的可控性和可解释性,从而利用深度生成模型将领域知识显式地集成到生成过程中[161]。
封闭验证场景延续经典测试方法理论,将先验知识和理论技术方法相结合构造具体的有限测试用例,旨在通过最小测试资源最大化完成验证需求。封闭验证对基本的SOTIF 安全情况进行说明,将一致性、残余风险等论证过程后置到开放论证中。
2.4 开放论证交互环境的实现
开放论证基于现实交通情况构建非定式的交互环境,本质是将场景要素按照与现实环境一致合理的分布和运行规律进行演化,通过被测对象和外部场景要素的持续交互,全面、直接还原系统对运行条件的响应情况,对低概率危害或系统异常响应进行暴露并计算性能水平。基于场景本体模型,开放论证的交互环境可以建模为如下数学模型:
式中:xis和xisys分别表示交互环境和被测系统的状态采样;t标识进程时间;sys(*)表示状态空间到动作空间映射,即被测系统基于指定时刻t自身状态和外部环境状态情况所执行的操作;ϵ(*)表示由于不确定性、观察误差等所造成的噪声项;ξ(*)表示被测系统下一时刻状态的转换映射(X)表示被测系统Sys在特征X构成交互环境中的性能情况;H表示安全评估所关注的危害事件;μsHys表示系统残余风险,为被测系统Sys在真实运行条件下危害事件H出现的概率期望[167]。上述公式依次代表合理场景、系统响应和残余风险的理论概率模型,也是构建交互环境的核心内容。
数据驱动的交通参与者建模为构建和现实场景具有一致性的运行逻辑提供重要基础。早期研究分析跟车[168-171]、变道[172-173]、拥堵环境[174]、交叉路口[175]等不同语境下的交互特征从而建立驾驶行为模型,并基于现实数据对模型进行校准[176-178];为捕捉人类驾驶的宏观特征和个体不确定性,学者们基于随机过程理论应用高斯过程[179-180]、分段混合分布[181]等概率模型对驾驶行为进行建模,并引入高斯噪声项[182-184];Barão 等将高斯随机场和K 均值聚类方法结合,从观测轨迹中估计多个动态模型[185];Guo等基于随机向量场建立多车交互模型,利用非参贝叶斯学习潜在运动模型,并通过高斯过程和狄利克雷过程模拟多车交互并匹配到特定场景[186];Zhang 等通过非参贝叶斯学习将场景划分为可解释的轨迹基元,并将基元变化点拟合到规划算法获取的期望路径以生成无碰撞的交互轨迹,进一步引入高斯过程回归控制生成轨迹的方差和平滑度[187];Ding 等基于变分贝叶斯方法提出一个基于数据的轨迹合成框架,将安全和碰撞的数据潜在空间分布通过生成模型进行连接,并通过条件概率匹配到不同道路结构上[188]。
人工智能技术为深入表征和提取交通参与者模型提供了新的思路。Tan 等结合神经自回归模型对交通场景进行高保真建模[189];Jenkins 等结合递归神经网络从实际事故数据中生成碰撞轨迹[190];基于对抗神经网络和变分自动编码器两种架构,Krajewski等设计无监督轨迹学习模型[90]并引入贝塞尔曲线作为输出层优化轨迹的重构误差和平滑性[191],Ding 等则在架构基础上设计双向编码器和多分支解码器生成更加合理的多车交互场景[192];长短期记忆神经网络能够有效捕捉驾驶行为的非对称性[193],并同深度神经网络[194]、深度信念网络[195]和混合重训练约束[196]等方法相结合展现了良好的可扩展性和精度;Yoon 等在学习嵌入空间联合优化过程中引入监督和对抗目标,从而在生成时序数据过程中兼具无监督模型的通用性和监督模型的强控制[197];Demetriou等基于循环条件生成对抗网络和递归自动编码生成对抗网络分别构造轨迹生成器,并引入自动编码器进行特征提取和聚类[198-199];Zhu 等应用深度强化学习框架从历史数据模仿类人驾驶策略,展示出良好的精度和泛化能力[200];进一步,研究通过奖励的设置来提高模仿学习过程中对于差异性和风险性的偏好,以适应生成多样且危险的场景[201-203];此外,对抗生成网络提供了模仿学习的另一种方法,从而减少轨迹扰动的误差积累,建立可靠人类驾驶模型[204-205]。
交互性是交通场景的重要特征,上述方法将交互过程通过交通参与者相对关系隐含地建立在模型中。博弈将交通参与者视为多智能体,显式地对场景交互过程进行描述。Talebpour 等将车道变换通过合作与零和两类博弈过程描述[206]; Oyler 等将驾驶行为建立为部分可观测马尔可夫过程,结合层次推理和强化学习完成驾驶员模型构建[207];Li 等提出了基于层次推理的交互行为建模方法[208],并对斯塔克伯格(Stackelberg)和决策树两类博弈策略进行比较[209];Albaba 等将深度强化学习和k 层博弈方法结合构建驾驶员模型框架[210];Wang等通过k层博弈和社会价值理论描述交互行为,进一步将关键主车设置为博弈代理,通过强化学习进行策略训练[211];Na等则以纳什均衡为基础建立驾驶员模型并通过实验提取关键参数[212]。
数据驱动的交通参与者模型和多智能体的博弈过程构建出合理交互的环境。然而,稀有但高风险事件是从一般代理环境中获取完整响应的重要挑战。在此基础上,加速测试的技术手段能够加快对问题的暴露,提高单位测试时长或里程的效能。
在博弈理论基础上,自适应调整技术能够对智能体的对抗性进行强化,提高系统危害条件的出现概率。Qin 等通过信号时序逻辑将对智能体的动态约束转化为层次序列规则,从而控制环境对抗性程度,并进一步结合信号聚类技术区分不同类别关键事件[213];Xie 等提出了一种主动驱动算法控制智能体,并引入系数引导迭代方法是算法能够在不同条件下运行[214];Chen 等考虑危险场景多模态特性,使用集成模型表示局部最优值并通过非参数贝叶斯对环境对抗策略进行聚类[215];基于深度强化学习框架训练对抗环境,Behzadan 等在训练过程中引入自适应探测的机制[216],Sun 等则应用特征提取和聚类技术,识别有价值的边缘场景[217];Mullins 等基于深度神经网络构造代理模型,并结合单一多层感知结构编码和控制多个任务级行为,同时通过分位数拖拽方法(quantile-dagger, Q-DAgger)删除对最终策略没有贡献的样本[218]。
上述方法能够有效加强测试验证环境的对抗性,提高危害行为论证效率并能够挖掘一部分长尾场景。进一步地,以风险论证为目标,重要度采样提供了统计学方法,能够在保证无偏性的前提下加速测试进程,更高效、准确地获得系统响应情况。
Zhao 等将重要度采样方法应用于切入[219]、跟车[220]以及高速[221-222]等场景进行测试,取得良好的加速效果;Huang 等分别使用高斯混合分布[223]和多项式核方法[224]构造重要度抽样分布,并基于克里金模型进行采样以减少需要评估的用例数量[225],改进了梯度估计量来搜索最佳测试场景[226]; Wang 等将可达集和重要性采样相结合,并通过截断高斯混合模型提取交互作用[227];Xu 等基于加速策略评估方法,建立零方差抽样分布,并引入函数逼近器,讨论了在正则条件下的收敛性[228];针对系统黑箱问题,Arief基于深度概率加速评估框架,在主导点附近生成场景样本[229],将黑箱采样器转化为松弛效率可信框架[230],通过深度重要性采样计算失效率上界,并用深度神经网络逼近估计值[231];Yan 等从大规模自然驾驶数据中得到不同条件下人类驾驶行为的基本经验分布,并进一步结合马尔可夫过程将模拟的固定分布和真值进行匹配从而优化模型的误差累积[167];在此基础上,Feng 等基于数据分布建立了自然驾驶环境 (naturalistic driving environment, NDE),同时,通过机动挑战识别关键变量并应用强化学习进行对抗性策略训练从而构建自然对抗驾驶环境(naturalistic and adversarial driving environment,NADE),最终基于粗蒙特卡洛理论进行无偏加速估计[232];Feng 等提出一种密集深度强化学习(dense deep-reinforcement-learning, D2RL)从安全关键事件的密集信息中学习对抗性代理模型,进一步加速测试[233];进一步地,Yan等针对多智能体交互行为提出了冲突批评模型和安全映射网络,建立Neural NDE 的深度学习框架改进安全关键事件的生成过程[234]。
开放论证通过一致性场景环境的重构,基于系统对交互环境的运行情况还原状态响应,并在此基础上计算运行风险情况。在封闭验证安全确认的前提下,开放论证通过真实合理的场景构建和无偏充分的加速论证过程,重点确认封闭黑箱系统的非预期响应场景挖掘,以及两阶段系统响应分布和风险情况的一致性,从而实现全面、可信的SOTIF论证。
2.5 SOTIF场景技术实现
可信的SOTIF 测试验证除了要求测试过程的充分性外,还要求测试结果能够如实反映现实运行空间系统响应情况,即测试论证结果的可信度。一方面,合理的场景要素特征分布和运行逻辑从场景角度提供了构建的一致性;另一方面,高保真的测试手段平台从技术角度提供了实施的一致性。同时,考虑测试的成本和效率,应综合测试目标、被测对象特点和测试用例需求,选择合适的技术手段构建分层、分频次的多支柱测试技术平台。
图7 所示为基于场景的测试验证平台框架。其中,左侧为测试场景工具,支撑双闭环中测试用例和交互环境的实现。右侧为被测系统,包括软硬件、系统集成到整车的不同层级。特别地,左右侧通过信息传递途径将场景和被测系统耦合。具体而言,场景采样的状态信息(真值)通过观测途径映射为数据(点云、图像等)提供给被测系统;被测系统基于获取的数据和自身状态选择合适的操作,并转化为响应状态提供给场景进行下一轮采样。

图7 基于场景的测试验证平台框架
以被测对象为核心,测试验证的一致性表示为左侧场景的要素满足一定分布,通过前述场景构建方法实现;测试验证技术的保真度则表示为右侧被测系统的输入输出和现实运行环境下相同,可视为信息传递途径的噪声分布和现实环境无偏。
开放道路测试(road test)信息传递途径均为真实,包括噪声分布在内的各项信息即为论证的真值。然而,开放道路的高昂成本和测试过程安全不可控,难以满足SOTIF测试验证的工程可操作性。
封闭场地测试(field of test, FOT),类似开放道路测试,信息传递途径均为真实,且由于在封闭区域,测试过程相对安全可控。然而,封闭场地测试往往需要测试设备的安装、调试,测试的成本较高、效率较低。此外,尽管相比开放道路测试,封闭场地具有能够编排测试内容的优点。但是由于场地设施约束,实际上能够覆盖的场景相对有限。
硬件在环仿真(hardware in loop, HIL)的平台部分组件(通常为被测系统或整车)为真实设备,往往被测系统到场景的状态响应和现实道路情况具有一致性;HIL 通常对场景进行部分或完全的仿真,场景到系统信息传递的Path A 有一定程度的失真。工控机-实时机联合仿真、室内台架模拟仪仿真、混合现实封闭场测试都属于广义上HIL,具有不同真实程度的要素仿真。HIL 具有测试效率较高、成本相对固定、兼有模拟极端场景工况的优势,能够满足硬件测试的真实性需求。然而,HIL 的场景到系统的信息传递途径仍和现实情况有一定差距。
软件在环仿真(simulation in loop,SIL)通过仿真重建场景和被测对象相关要素。SIL 平台中被测对象的输入信息传递途径Path A 和状态响应途径Path B 均通过仿真手段实现,与现实环境具有一定偏差,特别是对传感器的模拟保真度有限。SIL支持并行测试,能够快速部署以算法为主体的被测对象,大幅降低测试成本,能够满足快速迭代更新的测试需求。此外,SIL能够覆盖包括极端工况在内的各类场景,不会造成安全隐患和额外的成本消耗,具有较高测试覆盖度。
基于上述分析,各测试技术手段优缺点总结如图8 所示。在具体的测试验证过程中,首先应根据测试对象、测试目标和测试用例实现的要求,确定可用的测试技术。在满足基本要求前提下,综合低成本、高效率、测试过程安全性最终确定响应的测试技术和周期频次。

图8 测试技术优缺点总结
仿真器的保真度是SIL 层面的主要挑战,限制了以SIL 为支柱的测试可信度。一方面,高质量的光影效果是提高仿真质量的重要途径[235-238]。另一方面,高保真传感器数据建模也是优化仿真器的重要环节。Arnelid 等基于改进递归条件生成对抗网络模拟传感器输出,能够处理任意长度的时间序列,并引入长短期记忆网络来产生时序传感器的误差噪声[239];Yang 等提出UniSim 模拟器,通过神经特征网络重建场景中的静态背景和动态角色,结合动态对象学习先验知识并通过卷积网络完成未知区域的渲染实现模型的组合外推,以更低的域间隙生成逼真的传感器数据[240];Xiong 等将点云的几何结构进行编码,通过和稠密点云的表示对齐实现稀疏点云进行致密化,以较低成本生成多样逼真的场景级激光点云数据[241];Yang等将物体表面信息标识为神经符号距离函数,并用反射率模拟物理外观,从稀疏原生数据中重建三维场景[242]。基于实际数据的定向合成是提供高保真场景感知数据生成的新方法。Mildenhall 等基于神经辐射场(neural radiance fields,NeRF)建立复杂场景的隐式表达,结合体渲染和新的位置编码实现不同视角的逼真图像合成[243];进一步地,学者们将其扩展为Block-NeRF[244]、iNeRF[245]、BARF[246]、Climate NeRF[247]等 形 式;Wang 等 基 于CAD 模型和感知对象的几何与语义先验信息,结合能力模型优化迁移先验知识重建车辆视觉信息,可微绘制生成可编辑网格,实现形状、纹理和动态的创建和调整[248]。
混合现实和数字孪生为HIL 和FOT 扩展可测试场景范围、提高测试效率提供了一种可行方式。Wang 等提出并行测试的智能网联汽车测试方案和具体的技术方法[249-253],并与多家企业共同完成实地项目的建成和实验[254];Feng 等将测试场景生成方法集成到增强现实测试平台,在实地测试轨道上生成模拟背景交通与真实的被测对象交互,并在M-city中得到实践应用[255]。
高保真测试验证技术平台实质是支撑被测系统噪声滤除能力和应对不确定性鲁棒能力的进一步确认。ICV 测试验证涉及不同系统层级、不同场景尺度。为实现可信、高效的测试验证过程,SOTIF 测试验证方案应协同多样的技术支柱,在双闭环中集成恰当的用例构建、测试周期频次。
3 SOTIF接受准则
ICV 作为未来重要的道路交通参与者,应保证风险应该在合理可行的运行范围内尽可能低(as low as reasonable practice, ALARP)。SOTIF 接受准则(acceptance criterion)说明了由SOTIF 触发ICV 危害的合理风险水平标准,可以分为危害行为和残余风险两个层级。其中,危害行为是SOTIF 接受准则的底层基本单元,判定场景中ICV 的操作是否造成危害或产生风险;残余风险作为上层目标,从统计角度量化ICV持续运行过程中整体的累积风险情况。
优秀、谨慎的人类驾驶员是一种具有说服力的SOTIF 接受准则基线[256]。一方面,优于人类驾驶员的ICV 的性能情况和残余风险能够说明ICV 运行过程不会导致现有交通情况事故率的提高;另一方面,人驾车辆是到目前为止主流交通方式,且仍将持续一段时间,因此相关数据较为充分、丰富[257-259],能够支撑建立明确、合理的具体阈值。
3.1 危害行为接受准则
SOTIF 的核心是ICV 预期功能不足以及由此引发整车层面危害行为,并在相应场景环境中导致伤害。其中,危害行为通过整车或系统的状态情况指明了相关功能响应的不恰当或不充分:
式中:XH表示危害状态,包括危害发生时刻外部场景状态xHs和被测系统状态xHsys;μH表示危害行为,即导致危害发生的前序操作;φ(*)为评价指标,基于可观测状态确定当前时刻特定维度的性能情况;ΨH为危害阈值,超过该阈值说明特定危害产生。
危害行为既包含以碰撞为代表的伤害发生,又包含潜在导致伤害的状态情况,同时还可以拆解为部件和整车两个层级。因此,基于危害行为的形式化定义,转化为以状态为变量的多维度安全评价指标体系。其中,整车层级的危害行为定义为造成自车内部或对外部交通的碰撞或干扰,或违反相关法律法规,可以将其归纳为安全性和合规性两个维度。部件层级的危害行为设定为部件性能表现与预期的偏差或出现规范行为之外的动作或状态。
当前指标研究主要关注整车级的安全性评价,通过整车风险进行量化。碰撞时间(time to collision)通过计算预期碰撞的时间量化风险程度[260-261],并进一步延伸出修正碰撞时间[262-263]、最坏碰撞时间[264]、碰撞时间积分[265]、停止时间[266]、行车间隔时间[267]等变体指标;此外,受到TTC 启发,权重风险水平[268]、碰撞指数[269]、事故发生时间[270]、入侵后时间[271]等指标从时间维度上衡量关注危害事件的风险情况;责任敏感安全模型(responsibility sensitive safety, RSS)基于可避免碰撞距离衡量安全程度[272],设计了最小安全距离违规、最小安全距离系数、适当反应行动[273]、预测最小距离[274]等指标,也启发了包括紧急减速碰撞潜在指数[275-276]、停车距离比例[277-278]、碰撞裕度[279]、临近间隙[280]等一系列基于距离的指标;进一步地,避免碰撞减速率、潜在碰撞指数[281]、临界指数[282]等从加速度角度对风险进行评价;此外,潜在碰撞严重指数[283]、人工势场[284]、临界冲击次数[285]等从不同角度扩展了安全评估的范畴;特别地,道路违章规则、人工交通控制违规率[272]等指标建立了合规性评价;Pek 等提出了一种形式化变道交通规则安全性验证[286];Yu等基于原子命题建立层次化的合规性评价方法和监测应用[287]。
封闭验证重点确认被测系统在有限测试用例的危害行为接受情况。以人类驾驶员为基线的危害行为接受准则要求,对于选定的场景范围,被测系统应通过所有人类驾驶员能够通过的用例;且对于人类驾驶员未能通过的用例,被测系统应造成不高于人类驾驶员的危害结果。
3.2 残余风险接受准则
SOTIF 测试验证的最终论证目标是系统残余风险的期望能够被接受。其中,残余风险通过合理运行区间内危害行为累积发生次数进行量化:
在开放论证阶段,若构建的交互环境和现实环境具有一致性,即各场景要素状态满足分布,则被测系统的残余风险计算为
式中:L表示测试验证的累计运行里程,对于开放论证则可直接通过累积运行里程或运行时长T进行换算;Xl表示测试验证累积运行里程中采样的场景和系统状态数据。
对于基于重要度采样的无偏加速测试验证环境,残余风险可以表示为
开放论证重点确认被测系统在实际运行环境下的残余风险接受情况。以人类驾驶员为基线的危害行为接受准则要求被测系统的实际运行造成不高于人类驾驶员的平均累积危害率。特别地,残余风险的置信度与折算的运行里程呈正相关,即所测试验证的有效运行里程越长,残余风险置信度越高。一般地,论证可信的等价连续运行里程应在百万公里及以上。
在封闭验证阶段,假设系统响应满足李普希兹条件,即系统响应对状态分布是概率连续的。那么,系统在完成测试验证后残余风险为
式中:φs为安全阈值;P(φ(xis,sys(xis))≤ΨS)表示系统在测试用例xis下的安全概率;E(Xs=xis)表示测试用例xis暴露度,即组成要素在实际运行环境中的出现概率[42]。
同样的,测试用例样本数所覆盖的暴露度越高,论证结果的充分性越高。
总体而言,系统风险可接受的基本要求为车辆行为对自身或外界不构成不可接受的危害:除了场景中本身不存在造成危害条件的情况外,场景中危害出现概率小、严重度低,或危害出现的概率大但能够被控制、危害较强但出现概率罕见等情况,上述情况下危害可接受。
4 研究展望与总结
ICV 正逐步进行产业落地和应用并朝着高级别自动驾驶迈进,SOTIF 是允许道路运行必不可少的安全考量和要求之一。测试评价是SOTIF 重要保障基础之一,在促进系统性能优化、规范系统运行范围、确认产品通过等环节起到重要作用。本文从SOTIF概念和ICV 特点出发,分析了SOTIF测试验证的目标和需求,提出了基于关键场景的双闭环测试验证框架,结合场景模型细化了两个闭环的场景构建和实施方法以及面向接受准则的论证说明。
本质上,基于场景的SOTIF 测试验证是通过系统对样本响应情况,还原系统在实际运行条件下的状态分布,并通过风险评价和接受准则论证系统性能情况。SOTIF 双闭环框架基于具有不同测试定位的双闭环,通过合理设置场景样本和高保真的技术手段,高效、充分地完成系统的论证过程。封闭验证面向已知场景构建有限的最优测试用例集,充分暴露系统功能不足,基于危害行为接受准则验证基本安全情况;开放论证则面向场景开放性和未知性构建趋同于现实世界的交互环境,通过持续运行对未知的触发条件进行挖掘和归纳,同时对残余风险进行直接论证。
SOTIF 测试验证作为ICV 研发的重要一环,理论研究和实践应用仍有许多工作需要推进。以基于关键场景的SOTIF 双闭环测试验证框架为路线,综合关键挑战和难点,提出如下研究展望。
(1)推动基于关键场景的测试验证方法论研究与实践:考虑ICV 的复杂性和场景的开放性,仍有包括基于因果推断的触发条件分析、封闭黑箱系统的分布还原与长尾场景的挖掘、无偏加速的场景构建等诸多问题亟待解决;此外,需要进一步应用场景构建理论方法和技术,打造典型SOTIF 场景库,完善多维安全评价指标体系,通过产学研结合在工程实践中打通不同系统层级的双闭环测试验证流程,形成具有中国特色的SOTIF测试验证方案。
(2)建立高保真、高效率测试技术手段:优化包括传感器模拟在内的仿真组件保真度,增强仿真部分和现实世界的一致性,提高相应测试手段的可靠性;引入数字孪生、混合现实等方法,进一步丰富多支柱测试手段,降低测试成本、提高测试效率、扩展技术手段的可用性,为可信、可靠的SOTIF 测试验证提供有力支撑证据。
(3)持续推进运行数据采集,完善统计论证的理论方法:持续推进有效、多样的交通场景数据采集,支撑包括高保真环境模型构建、基于人类驾驶员的接受准则设定等关键环节;建立广泛、持续的数据共享机制,构建具有理论基础的SOTIF 数据驱动论证方案;完善场景暴露度和接受准则的概率统计方法,基于业界和政府一致共识形成兼具理论充分性和工程可行性的SOTIF接受准线。
总之,SOTIF 测试验证是安全开发的重要支撑,也是运行安全保障的关键技术。然而,当前行业内关于SOTIF 测试验证的标准化工作刚刚起步,相关工程实践也正处于积极的探索阶段,但缺乏系统性框架和可操作的理论技术支撑。本文提出了一个基于关键场景的预期功能安全双闭环测试验证框架,将广泛理论技术研究和工程实践经验纳入到框架之中,并对SOTIF 测试验证的关键问题进行梳理。本文将标准中的关键概念和理论方法转化为工程实践可用的技术流程,从而助力智能网联汽车预期功能安全测试验证后续进一步的理论研究和工程实践。
猜你喜欢
今日农业(2022年15期)2022-09-20
少儿科学周刊·少年版(2022年20期)2022-05-30
海峡姐妹(2020年12期)2021-01-18
幽默大师(2020年12期)2021-01-04
幽默大师(2020年11期)2020-11-26
幽默大师(2020年10期)2020-11-10
摄影之友(影像视觉)(2019年3期)2019-03-30
摄影之友(影像视觉)(2019年2期)2019-03-05
摄影之友(影像视觉)(2018年12期)2019-01-28
新少年(2017年6期)2017-06-16
