
面向混合存储的时空大数据存储策略研究
2023-10-11 08:48王意
地理空间信息 2023年9期
王 意
(1.山东省国土测绘院,山东 济南 250013)
时空大数据是基于统一时空基准,活动于时空中与位置直接或间接关联的大数据[1],是支撑宏观经济决策的战略级资源[2]。时空大数据存储性能的优劣直接影响其计算效率和服务性能[3]。目前混合存储是时空大数据管理中一种较好的选择[4-5]。本文在分析当前主流存储管理系统和硬件的基础上,按照数据类型和结构对存储对象进行了划分;结合时空混合索引方法,建立了时空大数据存储模型;分析了时空大数据存储影响因素,并进行定量化表达;提出了基于混合存储技术的时空大数据存储策略,建立了高效可靠的时空大数据放置与迁移方法,以期更好地服务于时空大数据存储和业务化应用。
1 现状综述
20 世纪90 年代关系型数据库成为空间数据存储管理系统的主流应用模式。由于时空大数据非结构化的数据读写场景,分布式文件系统和分布式非关系型数据库技术应运而生(表1)。

表1 混合存储中常见的存储管理模式
传统的机械硬盘(HDD)面对大数据时代的挑战已显得力不从心,新型存储介质具有体积小、能耗低、带宽高、时延低、抗震性强、可靠性高等特点。其中,闪存的发展最迅速,已达到了实用化水平,固态盘(SSD)是闪存最主要的形式。
2 混合存储策略
2.1 问题描述
1)不同管理系统间的数据关联问题。时空大数据在访问特性和时效要求上差异较大[6-8]。混合存储需满足不同管理模式下数据的动态关联需求,将通用的混合存储技术与空间信息技术(空间大数据组织方法、空间分布式索引等)深度融合,形成集中统一的数据访问接口。
2)数据存储策略缺少对时空大数据的动态感知和弹性调度能力。时空大数据的存储策略应具备动态感知和弹性调度数据的能力,可根据应用的历史访问记录、存储设备特征等因素实时调整数据存储路径;通过一个有效的迁移算法为不同数据动态选择存放介质,使整个存储系统达到存储效率和经济性的最佳平衡,从而最大程度地提升整个存储系统的性能。
2.2 总体设计
在混合存储架构中的数据层构建面向时空大数据的关系型数据库集群、NoSQL 数据库集群、分布式文件系统集群的存储框架,实现不同管理模式下的数据动态关联;以SSD、HDD作为二级存储,根据I/O特性和数据价值,将不同类别的数据分配到SSD或HDD上;设计数据迁移算法,实现数据在不同介质间的移动。
2.3 数据存储模型构建
构建结构化数据、半结构化数据和非结构化数据3 种存储模型,并建立元数据及其索引,将具有相同编码的数据进行关联。
1)将一个结构化的数据库或子数据库切分为若干具有固定大小的组块,并对数据块建立两层索引。存储模型包括数据块集合、第一层索引和第二层索引3 个部分,其中数据块中包含空间几何信息、空间数据信息和其他属性信息(图1)。通过统一的空间编码方法和哈希编码方法使每条数据具有唯一编码。
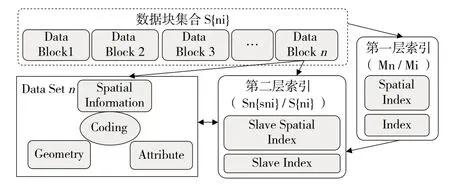
图1 结构化数据存储模型
2)半结构化数据通过面向数据片的方式管理和查询数据,建立空间编码(索引)。半结构化数据存储模型包括数据分片集合和空间编码两大部分,其中数据分片中包含数据、编码深度和编码(图2)。数据分片无需进行二次检索,通过统一的空间编码和解码即可快速查询和获取瓦片。
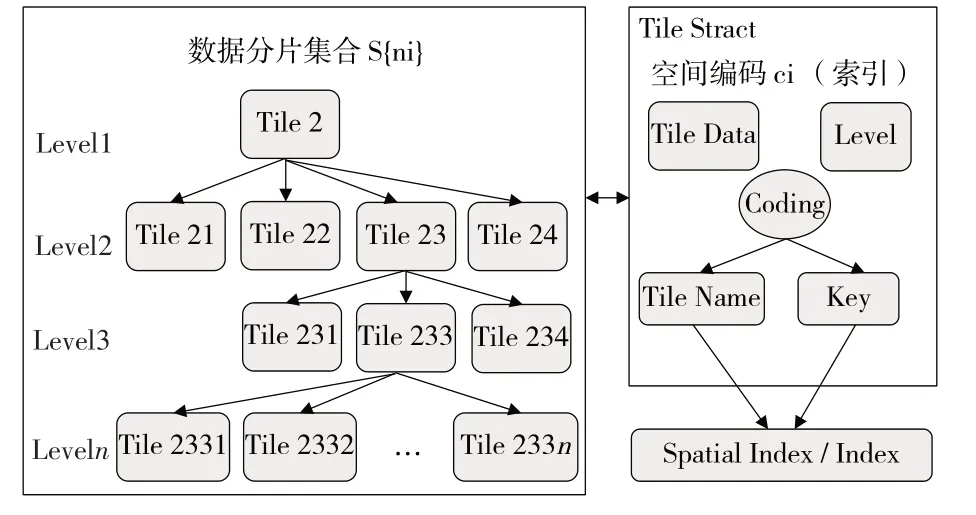
图2 半结构化数据存储模型
3)非结构化数据不能直接存储矢量数据,需转换为能保存的空间信息和属性信息。非结构化数据存储模型包括文件集合和关联编码两大部分,其中文件集合记录文件信息,并通过统一的关联编码方法使其具有唯一编码(图3)。关联编码属于第一级索引,对于常规索引检索的n个结果,可采用分布式并行的方法进行并行读取,并可通过aci 对文件进行命名,与其他具有相同编码的数据进行关联。
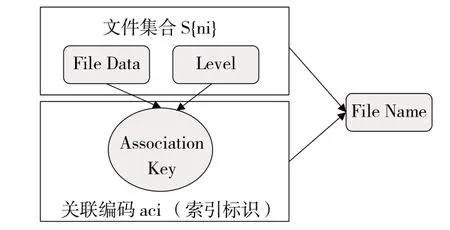
图3 非结构化数据存储模型
2.4 数据放置与迁移策略
影响因素主要包括:①空间分辨率,反映数据的空间详细程度,值越高,识别物体的能力越强;②时间分辨率,表示重复探测同一目标时,相邻两次探测的时间间隔;③光谱分辨率,反映成像的波段范围,划分越细、波段越多,值越高;④存储时间,数据存放较长时间后,其被访问频率将降低,数据价值也将降低;⑤数据热度是反映数据价值的直观指标,利用价值高的数据会被反复读取加以利用;⑥随机度,使SSD 服务绝大多数的随机I/O 访问,HDD 服务剩余的I/O访问,匹配度越高的数据,越能体现或挖掘其数据价值;⑦数据大小,数据量越小,越有利于存储资源的利用,数据大小与价值成反比。
2.4.1 数据静态放置策略
本文选择时空大数据的空间分辨率、时间分辨率、光谱分辨率作为评价指标,不随数据应用而改变。根据主观经验设置权重Q,满足条件的数据优先使用性能更高的SSD作为存储介质。假设某应用可调用n个数据,单个数据价值的计算公式为:
式中,Qs、Qt、Qf分别为空间分辨率、时间分辨率、光谱分辨率的权重,由人为确定;Jsi、Jti、Jfi分别表示数据i的3 个指标是否满足应用需求,若满足,值为1,不满足,值为0。
选择该应用价值最大的数据优先放置在SSD 上,计算公式为:
2.4.2 数据迁移函数
数据每次被访问的时间集为{t1,t2,…,tn},距离当前时刻t的时长为t-t1,t-t2,…,t-tn,用C1,C2,…,Cn表示。设数据访问热度为q,随机度为r,初始值均为0,访问一次数据,q加1,判断该访问的起始位置是否对应该数据上次访问的结束位置,若相同且与上次访问类型相同、时间间隔也在给定的阈值内,则r不变;否则r加1。在存储时间C1,C2,…,Cn内的访问热度为q1,q2,…,qn,随机度为r1,r2,…,rn,计算公式为:。由此可知,数据价值与q、r成正比,与C、数据大小成反比。
单个数据价值和所有数据总价值的计算公式为:
所有数据的总价值应尽可能的大,根据数据价值变化,系统I/O 动态地在SSD、HDD 之间进行数据迁移,以保证价值较高的数据优先使用SSD存储。设数据大小为si,应保证集合中SSD上所有数据大小的总和不能超过SSD的总空间大小(CAPACITYSSD),即
设置模型的起止时间和SSD的空间总量,计算得到使数据总价值最大的存储方案,进而调整数据存储位置。
3 实验与性能分析
为验证本文提出的时空大数据存储策略,以山东省地理信息时空大数据中心为依托,分别测试数据存储和加载效率。实验设备配置见表2。

表2 实验设备配置
3.1 实验数据
本文选取两组数据:①山东省省级基础测绘“十二五”地形要素数据,共5 977 个MDB、51.7 GB,“十三五”数字正射影像6 578幅、2.73 TB;②1.6亿条矢量要素数据、120 TB 影像数据和500 GB 地形数据(DEM数据),数据具有明显的时空大数据特征。
3.2 存储时间
两组数据采用相同配置的终端,分别存入部署混合存储策略的数据库(实验库)和原始库,初始存放位置均为HDD。数据入库时间对比见表3,可以看出,第一组实验库的数据入库时间比原始库约减少10%,入库效率小幅提升,这是由于数据量较少时,存在较固定的数据传输和备份时间消耗,因此优势不明显;第二组实验库的数据入库时间缩短近一半,而矢量要素数据和地形数据入库时间缩短为原时长的1/8,说明本文设计的混合存储策略综合考虑了数据特征、混合存储管理系统、混合存储设备3 个要素,提高了数据放置的合理性,减少了系统开销,大幅提高了入库效率。

表3 数据入库时间对比
3.3 加载时间
本文对实验数据进行加载浏览,分别测试了不同数据存储策略下10 万、100 万、500 万条数据的初始加载时间和多次打开数据库后的加载时间,结果见表4,可以看出,混合存储管理端初次加载时长有所减少,并随数量的增加,加载时长减少越多(30%),说明混合存储策略数据加载时效率显著提升;普通终端多次打开数据库后的加载时间没有明显变化,而混合存储管理端在多次打开数据库后,加载时间约为初次加载时间的50%,说明通过数据迁移,将随机访问和热点访问的数据迁移到SSD上,有效减少了整个系统的访问延迟。

表4 数据加载时间对比
4 结语
本文分析了混合存储技术在时空大数据存储中的应用现状,提出了面向混合存储的时空大数据存储组织模型和数据存储策略;并基于山东省地理信息时空大数据中心开展性能实验,对比了普通终端和混合存储策略终端的时空大数据存储和加载效率。结果表明,在存储数据量较少的传统测绘数据成果时,混合存储策略效率提升不明显;但随着数据量和数据种类的增加,混合存储策略的效率显著提升;在多次数据读取后,数据的动态迁移可有效提升数据访问性能。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
河北理科教学研究(2021年4期)2021-04-19
小学生学习指导(低年级)(2020年11期)2020-12-14
计算机教育(2020年5期)2020-07-24
数学物理学报(2019年3期)2019-07-23
作文大王·低年级(2018年10期)2018-12-06
家庭影院技术(2018年9期)2018-11-02
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
小猕猴智力画刊(2016年5期)2016-05-14
