
面向拥挤行人检测的改进DETR算法
2023-10-10 10:38:56马小陆
计算机工程与应用 2023年19期
樊 嵘,马小陆
安徽工业大学 电气与信息工程学院,安徽 马鞍山 243002
行人检测任务是目标检测的一个分支领域,在安保监控、智能驾驶以及交通监控领域具有重要应用价值。实际行人检测任务中,待测场景多为拥挤行人场景,场景中行人目标尺寸较小且相互间存在大量遮挡会给检测带来一定挑战。主要表现在三个方面:(1)拥挤场景中行人密度较大,行人目标之间易产生相互遮挡现象。使得具有完整行人特征的目标缺失部分特征信息,影响模型的特征提取效率;(2)遮挡现象在减少目标特征的同时,会在行人的表征特征中引入噪声干扰,使模型难以对重要特征进行有效提纯;(3)拥挤场景下行人目标个数较多,单个目标的分辨率较低特征信息较少,易使模型产生漏检现象。
针对拥挤行人检测场景中部分被遮挡目标的漏检问题,Xu等[1]提出了基于RCNN的提取行人特定部位信息的检测算法,通过对人体关键点及部位进行检测间接实现对行人目标的检测。邹梓吟等[2]通过在骨干网络中引入注意力模块,提出了一种基于注意力机制的特征提取增强检测算法。李翔等[3]提出了一种改进YOLO-v3算法,通过对损失函数及特征融合进行优化提升了对遮挡行人的检测性能。孙旭旦等[4]通过对被遮挡行人特征进行语义增强,减少了检测场景中被遮挡行人的漏检。谢斌红等[5]通过在网络中加入残差密集网络,实现了浅层与深层特征的直接融合,减少了被遮挡行人特征的丢失。Hou等[6]采用多相机视角综合判断减小了遮挡对行人检测的影响。以上方法虽然有效提升了模型对遮挡目标的检测能力,但面向含有大量小目标行人的拥挤行人检测场景时仍易产生漏检。
针对拥挤行人检测场景中部分小目标行人的漏检问题,邵香迎等[7]通过构造具有超分辨率思想的特征细化模块,对小目标特征信息进行放大重构,缓解小目标漏检问题。Hong 等[8]利用注意力机制、尺度增强模块、尺度选择模块构建了一种用于小目标行人检测的尺度选择金字塔网络,优化小目标检测的效果。Zhao等[9]通过将不同尺度的特征进行融合,有效缓解了小目标特征信息不足的问题。Kim 等[10]通过生成不同尺度的特征并将其扩展到统一尺度聚合上下文信息,有效缓解了小目标特征信息不足的问题。以上方法虽然有效提升了对小尺寸目标的检测能力,但主要通过特征融合与特征重构操作增强小目标的特征信息,当运用于含有大量噪音的密集遮挡行人检测场景时,检测效果提升有限。
为有效解决上述问题,本文在注意力模型DETR[11]的基础上进行了以下三点改进:
(1)采用改进的EfficientNet[12]骨干网络作为特征提取网络,改进后的EfficientNet骨干网络融入了通道空间注意力模块[13](convolutional block attention module,CBAM),对特征图中的重要通道信息与空间信息有较高的提取与提纯效率。
(2)采用可变形注意力编码器[14]替代注意力编码器[15]对多尺度特征图进行注意力编码,使算法可以自然聚合多尺度特征,增强对小目标物体的检测能力。
(3)训练时采用Smooth-L1 结合GⅠOU 作为损失函数,提升训练效率并使模型可以收敛至更高的精度。
最后,在当前具有一定说服力且含有大量小目标行人与遮挡目标行人的Wider-Person 拥挤行人数据集上与现有的部分常用行人检测算法进行了对比实验。实验结果表明,改进DETR算法具有较强的拥挤行人检测能力。
1 改进DETR检测算法
本文提出的改进DETR算法包含三个部分,分别是进行行人检测的改进的注意力检测模块、将骨干网络输出特征进行预处理并输出多尺度特征图的颈部网络以及进行特征提取的改进的EfficientNet 骨干网络。进行行人检测时,骨干网络对送入的RGB 图像进行特征提取并将网络第6、7、8 层输出的特征图传入颈部网络。颈部网络将得到的特征图转化为通道数均为256,尺寸不变的多尺度特征图。注意力检测模块给颈部网络转化的多尺度特征图加注可学习的位置编码后送入可变形注意力编码器(deformable transformer encoder)进行注意力编码,编码结束后由解码器(transformer decoder)进行解码并输出检测锚框。改进DETR 网络结构图如图1所示。

图1 改进DETR网络结构图Fig.1 Ⅰmproved DETR network structure diagram
1.1 改进的注意力检测模块
DETR采用注意力检测模块进行检测结果输出,但注意力检测模块难以有效利用含有较多小目标信息的多尺度特征图,导致对小目标行人的检测效率较低。针对此问题本文采用可变形注意力编码器(deformable transformer encoder)对DETR 注意力检测模块进行改进。DETR注意力检测模块结构,如图2所示。

图2 DETR注意力检测模块Fig.2 DETR transformer detector module
1.1.1 注意力编码器
注意力编码器(transformer encoder)为注意力检测模块的编码结构,加注可学习的位置编码特征图输入注意力编码器后,编码器会计算特征图中的采样点与其他所有像素点之间的注意力权重,进而构建全局特征图。其与注意力解码器(transformer decoder)结合使模型拥有了全局建模能力。利用全局建模能力模型可以将目标检测问题转化为集合预测问题,在输出检测结果时不会输出冗余的预测框,避免了使用对检测性能影响较大的非极大值抑制后处理模块。并且由于使用了注意力检测模块,在输出检测结果时模型会聚焦于特定的重要特征,缓解噪声对目标检测的干扰,使得模型可以在缺失部分目标特征的前提下完成遮挡目标检测[11],因而采用注意力检测模块的模型可以较好地应用于遮挡目标检测任务。
1.1.2 可变形注意力编码器
可变形注意力编码器与注意力编码器一样拥有特征编码能力,与解码器结合使网络保留了全局建模能力。不同于注意力编码器,可变形注意力编码器仅计算采样点与其附近部分(由模型训练得到)像素点之间的注意力权重,使模型在保留性能的同时降低了计算量,且可变形解码器可以自然聚合不同尺度的特征图,使模型在不使用特征金字塔[16](feature pyramid network,FPN)结构的情况下也能有效地利用骨干网络提取的多尺度特征图,进而减少小目标语义信息在下采样过程中的损失,提升对小目标物体的检测性能。本文采用可变形注意力编码器对注意力检测模块进行改进,使模型可以有效利用多尺度特征图。采用可变形注意力编码器的注意力检测模块结构,如图3所示。
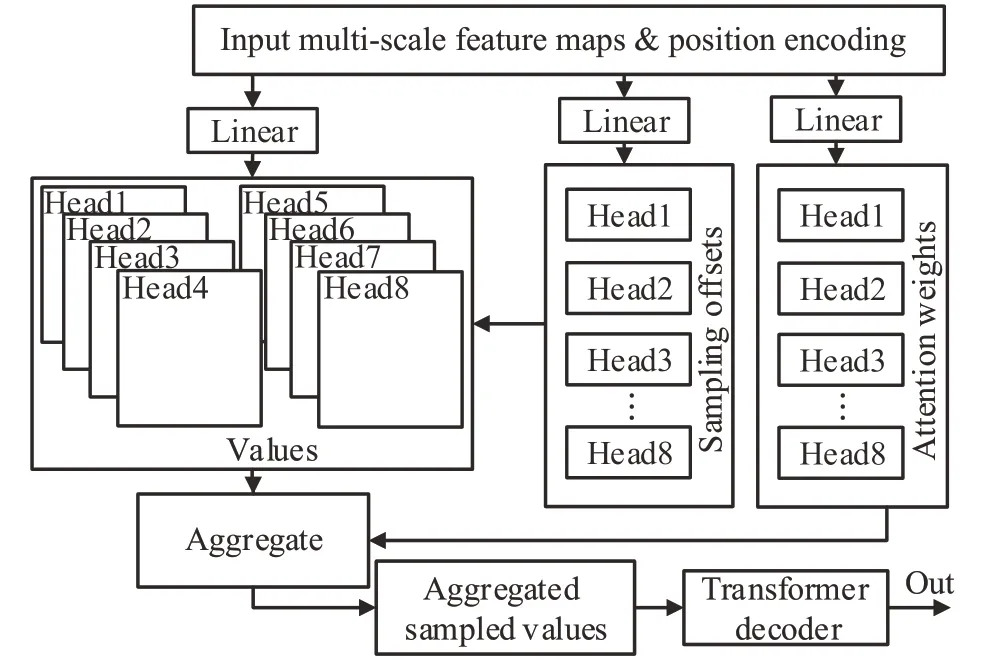
图3 采用可变形注意力编码器的注意力检测模块Fig.3 Attention detector with deformable attention encoder module
图3中,Neck层输出的多尺度特征图按位置添加可学习的位置编码后送入可变形注意力编码器进行注意力权值更新,送入的多尺度特征图通过三个全连接层分别转化为像素点注意力权重W′m x,注意力偏移量∆Pmlqk以及注意力权重系数Amlqk。其中注意力偏移量为当前参考点与其附近像素点进行偏移量计算后得出的与当前参考点相关联的像素点的位置偏移量,注意力权重系数为与当前参考点相关联的像素点所拥有注意力权重值。当可变形注意力编码器关注到一个参考素点后,通过注意力偏移量计算与当前参考点关联的所有像素点,并将这些像素点结合其对应的注意力权重与注意力权重系数更新当前参考点的注意力权值,进而完成对所有像素点的全局注意力权重编码。完成全局注意力权重编码的特征图被送入解码器后直接输出检测结果。多头可变形注意力定义如式(1)所示:
其中,zq为输入的原始特征,p̂q为当前参考点的归一化坐标,x为特征图编号,Wm为多头注意力,m为注意力编号(本文中m最大值为8),l为特征金字塔的维度编号,k为当前采样点编号。
1.2 改进的骨干网络
采用可变形注意力编码器的DETR算法已经具备有效利用多尺度特征图的能力,为了给可变形注意力编码器提供高效的多尺度特征图,本文采用改进的Efficient-Net 骨干网络代替DETR 原有的ResNet-50 骨干网络进行特征提取工作。
1.2.1 基础网络ResNet-50骨干网络
DETR基于经典骨干网络ResNet-50[17]搭建,ResNet-50系列网络引入残差结构缓和了深度神经网络在训练时产生的梯度消失问题,但ResNet-50 系列网络采用增加网络模块层数的方式提升网络性能,虽然获得了较好的特征提取能力,但其本身参数量较大且堆叠层数较深,难以对信息量较少的被遮挡目标特征进行有效提取并为后续编码网络提供高效的多尺度特征图。
1.2.2 基础网络EfficientNet骨干网络
EfficientNetB0-B7 系列骨干网络通过自适应神经架构搜索[18](neural architecture search,NAS)得到,其中最小的EfficientNet-B0 骨干网络已不到ResNet-50 骨干网络四分之一的参数量,在ⅠmageNet 分类任务上领先ResNet-50约1%的TOP1准确率。EfficientNet骨干网络的核心模块为MBConv 模块,此模块由深度可分离卷积[19](depthwise separable convolution)连接压缩与激励模块[20](squeeze and excitation,SE)并最终通过Swish激活函数构成。在MBConv模块的作用下,EfficientNet骨干网络在特征提取阶段实现了对重要通道特征的高效提纯。
1.2.3 通道空间注意力模块
实际检测任务中,目标间的空间信息是检测被遮挡目标的重要依据,而在卷积过程中,特征图尺寸逐渐减小,目标间的空间信息也因此而逐渐贫乏。为了更好地对空间信息进行提纯进而提升算法对遮挡目标的检测性能,本文采用通道空间注意力模块替换MBConv模块中的压缩与激励模块。
通道空间注意力模块是一种轻量级卷积注意力模块,它会依次计算通道与空间两个维度的注意力图,并将注意力图与特征图相乘以进行自适应特征优化[21]。张宸嘉等[22]针对5个同型号电台辐射源信号作为数据集进行仿真实验,利用ECA-Net[23]、SE-Net、SK-Net[24]、ResNeSt[25]、CBAM、DANet[26]、PAFNet[27]等7 种不同注意力模块,在相同网络条件下对数据集进行分类识别,测得通道空间注意力模块的效果最优。通道空间注意力模块结构图,如图4所示。

图4 通道空间注意力模块Fig.4 Convolutional block attention module
由于现有的一些加速器无法充分支持深度可分离卷积,导致在浅层网络中使用包含深度可分离卷积的模块可能降低网络工作效率[28],为了减轻深度可分离卷积对网络效率的影响并有效利用特征图中的空间信息,本文设计了融合通道空间注意力模块且包含深度可分离卷积的CBAMConv模块以及不包含深度可分离卷积的Fused-CBAMConv模块。两模块结构如图5和图6所示。

图5 CBAMConv模块Fig.5 CBAMConv module

图6 Fused-CBAMConv模块Fig.6 Fused-CBAMConv module
1.2.4 改进的EfficientNet骨干网络
为了防止在浅层网络中出现过多的深度可分离卷积影响网络的检测效率,本文将EfficientNet 骨干网络的前4个层级模块替换为Fused-CBAMConv模块,最后3个层级模块替换为CBAMConv模块。以输入图像为3通道分辨率300×300的RGB图像为例,改进的Efficient-Net骨干网络参数,如表1所示。

表1 改进的EfficientNet骨干网络参数Table 1 Ⅰmproved EfficientNet backbone network parameters
1.3 损失函数的优化
由于本文仅针对行人进行检测与定位,在检测阶段属于二分类问题。因此本文将GⅠOU[29]损失函数与Smooth-L1损失函数结合作为回归损失,对检测边框进行预测回归。
GⅠOU 损失函数考虑到了两框的非重叠区域,可以有效反映出两框的重叠情况,当两框不重叠时也可以返回梯度便于优化。GⅠOU定义如式(2)所示:
式中,A表示预测框面积,B表示真实框面积,C表示能同时包住A与B的最小方框面积。
Smooth-L1损失函数结合了L1损失函数与L2损失函数的优点。模型的前50轮训练中锚框与标定框的数值差距较大,Smooth-L1可以很好地对反向传播梯度进行抑制,避免梯度爆炸;而在最后50 轮训练中,锚框与标定框的数值差距较小,此时也可以继续返回梯度使模型进一步收敛到更高精度[30]。其定义如式(3)所示:
式中,bσ(i)表示第i个索引的标定框,表示第i个索引的锚框。
Smooth-L1 损失函数在计算损失时仅使用了锚框与标定框的横纵坐标值及长宽数值,无法描述锚框与标定框之间是否存在包含关系。针对此问题,在计算回归损失时引入GⅠoU损失函数计算锚框与标定框之间的重叠损失。通过将以上两种损失函数融合作为本文的回归损失,使得模型的训练效率得到提升。
2 实验结果与分析
2.1 实验数据集
本文在已公开的Wider-Person[31]拥挤场景行人检测数据集与USC 行人检测数据集上,对本文模型进行实验验证。Wider-Person数据集是室外行人检测基准数据集,包含13 382张图片,共计40万个不同遮挡程度的人体目标,图像来源于多种场景。本文选择取了数据集中给出标签的9 000张图片按8∶2划分为训练集与验证集进行对比实验。USC 行人检测数据集中图像大多来源于监控视频,共包含358 张图片,共计816 个行人目标,存在少量遮挡目标。本文将358 张图像全部重新标注后按8∶2划分为训练集与验证集进行消融实验。
由于采用transformer 编码器的模型对训练资源需求量较大且收敛较慢,为了便于模型的训练与性能检测,消融实验阶段使用图片体量较小的USC 行人检测数据集,验证各个改进模块的有效性;横向对比实验阶段使用较为庞大的Wider-Person行人数据集,验证本文算法在小目标与遮挡目标检测中的性能优越性。
2.2 实验设备与评价指标
本文在运行内存32 GB,Ryzen5-3600X 处理器,NVⅠDⅠA TeslaP40显卡的硬件平台上进行模型训练,运行库版本为CUDA11.6,软件环境为Pytorch1.12.0 与MMDetection[32]。为了更好地与其他检测网络进行性能与体量对比,本文采用平均精准度(average precision,AP)来衡量模型检测精度,平均精准度ⅠoU阈值取0.5以及0.5~0.95,分别记作AP50与AP50:95。为了进一步验证本文对小目标的检测性能,采用MSCOCO[33]数据集中的评价APs 来衡量对像素点小于32×32 的小目标的检测性能,ⅠoU 阈值取0.5~0.95。采用GFLOPS 衡量模型的计算量。
2.3 消融实验
为验证本文所提改进模块是否有效,设置了消融实验。为便于性能对比,每组实验模型仅替换DETR原模型的对应模块。每组模型在USC行人检测数据集上进行300 轮训练。由于USC 行人检测数据集包含少量遮挡行人及小目标行人,故使用AP50与AP50:95作为模型的性能衡量指标。所有实验组均选择Adam 优化器进行优化,学习率为0.000 1,实验编号与结果如表2所示。
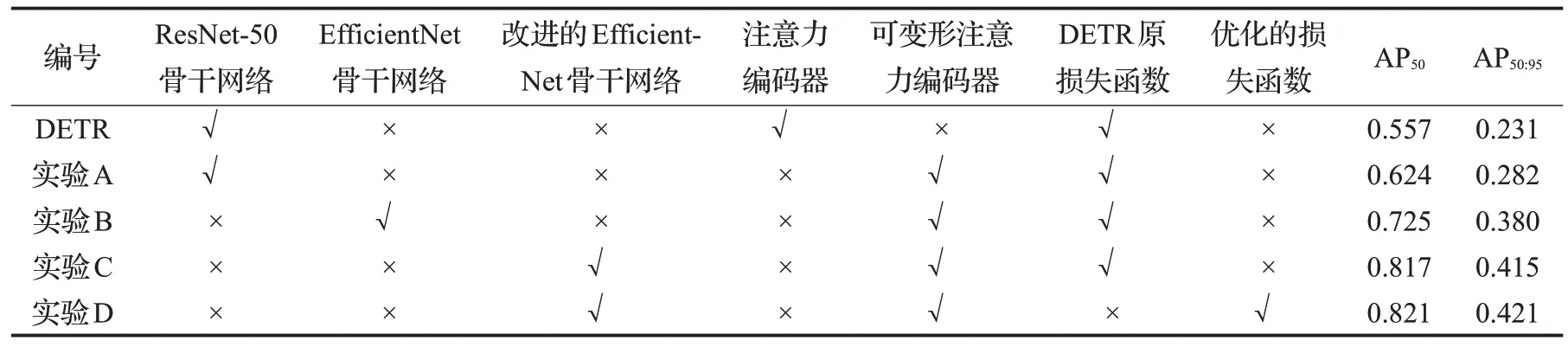
表2 消融实验编号与结果Table 2 Ablation experimental number and results
表2 中实验DETR 为使用ResNet-50 骨干网络以及注意力编码器的DETR原模型及其实验结果,对比实验DETR与实验A可知,可变形注意力编码器通过聚合多尺度特征图有效提升了模型检测精度;对比实验A与实验B 可知,EfficientNet 骨干网络相较于ResNet-50 骨干网络有更高的特征提取效率,有效增加了模型检测精度;对比实验B 与实验C 可知,融入通道空间注意力模块的改进的EfficientNet骨干网络相较于EfficientNet骨干网络有更高的特征提纯效率,进一步提升了网络检测精度;对比实验C 与实验D 可知,优化后的损失函数使网络进一步收敛至更高的检测精度。以上结果表明所提改进方法均可有效提升DETR模型的检测精度
2.4 横向对比实验
将本文算法与部分常用行人检测模型进行对比实验。每个模型在Wider-Person 拥挤场景行人数据集上进行200 轮训练,由于Wider-Person 行人检测数据集含有大量遮挡目标行人与小目标行人,故使用AP50、AP50:95与APs50:95作为模型的性能衡量指标。所有实验组均使用Adam 优化器进行优化,学习率为0.000 1,实验结果如表3所示。

表3 性能对比实验结果Table 3 Performance comparison experiment results
由表3 可知,在密集行人检测场景中,本文的常规检测精度与小目标检测精度均高于YOLO-x 以及YOLO-v5等常用行人检测算法。
为了更好地对比本文与DETR原模型的检测效果,本文在图7中可视化了DETR原模型以及本文模型在拥挤行人场景中的检测效果,左侧为DETR 模型检测效果,其中存在较多漏检情况,右侧为本文检测效果,其中存在较少漏检情况。本文模型可以较好地应用于拥挤行人检测任务。

图7 检测效果对比Fig.7 Comparison of detection results
3 结束语
本文以DETR 作为基础框架,提出了改进DETR 检测算法。采用改进的注意力检测模块使模型可以聚合多尺度特征图,有效提升了模型对小目标及被遮挡目标的检测能力。采用改进的EfficientNet 骨干网络作为特征提取网络,提升模型对重要特征的提取能力以及提纯效率,提高了模型的检测精度。训练时采用由Smooth-L1与GⅠoU结合构成的损失函数,使模型可以进一步收敛至更高精度。
本文在Wider-Person 密集行人检测数据集中检测精度高于YOLO-x 与YOLO-v5 等常见行人检测算法。虽然采用注意力检测结构的算法在遮挡目标与小尺度目标的检测中更有优势,但使用此结构的模型需要较多的计算资源。在本文单GPU实验平台及数据集上对改进DETR 算法进行200 轮训练需要约145.6 小时,是YOLO-v5 算法消耗时间的5.4 倍。如何降低注意力检测结构算法所需训练资源并提升其训练效率,仍是未来的研究重点。
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
当代水产(2019年11期)2019-12-23 09:02:54
扬子江(2019年1期)2019-03-08 02:52:34
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
知识经济·中国直销(2017年5期)2017-06-15 20:28:19
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
中国学校体育(2014年11期)2014-05-10 09:57:04
电测与仪表(2014年13期)2014-04-04 12:04:18
