
海上大兆瓦风电机组故障预测与识别
2023-10-10 03:11张智伟黄煜明郑俊杰
科技和产业 2023年17期
张智伟, 王 靖, 黄煜明, 郑俊杰
(1.上海海湾新能风力发电有限公司, 上海 200433; 2.江苏金风科技有限公司, 江苏 盐城 224003;3.北京金风科创风电设备有限公司, 北京 100176)
随着“双碳”目标战略的加速推进,可再生能源对于优化我国能源结构、保障能源安全、构建新型能源体系、助力实现“双碳”战略目标具有重要作用。风力发电作为重要的可再生能源之一,已经成为世界各国推广的重点。而海上风电机组具有风能资源丰富、单机装机容量大、利用率高等优势,已经成为风力发电的重要发展方向。然而,由于海上风电机组地理位置偏远、环境恶劣,因此故障率较高,维护难度也较大[1-2]。因此,对于海上风电机组的故障预测和识别技术的研究具有重要的现实意义[3-4]。
变流器是风力发电机组中最关键的部件,其主要作用是将风力发电机产生的交流电转换为高质量的交流电,以便通过电网进行输送和利用。变流器可以控制风力发电机的转速、电压、频率等参数,从而实现最佳的发电效率和稳定性[5]。而变流器水冷系统则是为了保证变流器的稳定性和可靠性而设计的。由于变流器在工作时会产生大量的热量,如果不能及时散热,就会导致变流器温度过高而损坏。因此,变流器水冷系统可以通过水循环来吸收热量,并将其散发到外部环境中,从而保持变流器的正常工作温度,提高其工作效率和寿命[6]。每年春夏季节,柳树和杨树的絮屑随气流飘荡后阻塞外部散热器的进风口[7],给海上风电运维工作带来了严重困难。
夏博等[2]在风电采集与监视控制系统数据问题上与深度学习方法相结合,并对今后的研究重点进行了展望。程江洲等[8]提出了一种基于改进贝叶斯网络的风电机组故障诊断与风险预测模型,为风电机组故障诊断和风险预测提供有效依据。沈剑飞和翟相彬[9]通过风电场选址、风机选择、融资方式选择3个手段来降低风电场在全寿命周期下的总成本。朱国栋[10]为了解决风电故障寿命问题,对风电项目可持续发展能力进行了研究,从风资源、风电消纳、运行状况、财务状况4个考虑建立评价指标体系,对故障问题方面进行了阐述分析。苗青等[11]对变流器结构性能进行对比分析,做出对变流器拓扑结构的合理选择。对风电机变流器的故障研究方式众多,但对变流器的故障模式缺少更准确的研究。
针对变流器的主要故障模式,本文提出一种基于Python sklearn的机器学习框架,用于预测和识别海上大型兆瓦机组的故障。特别是使用支持向量机(support vector machine,SVM)、随机森林(random forest,RF)和深度学习(deep learning,DL)等算法来建立模型,分析和测试关于实际故障发生的数据。实验和结果表明,使用来自sklearn的机器学习技术在识别故障方面具有较高的准确率,可以有效地提高海上风电机组故障的预测和识别。
风电大数据故障预警模型上线流程如图1所示。本文中着重对特征标准化、特征提取、数据转换、模型训练和模型评估5个方面进行详细阐述[12]。
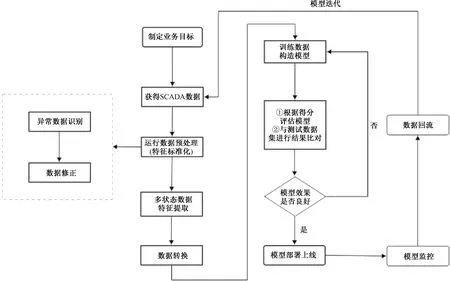
图1 风电大数据预警模型上线流程
本文中提出的风力发电机组大数据故障预警模型是针对华东地区海上某风场的6.45 MW机组变流器主要故障模式进行设计的,监控风机变流器水冷系统的运行情况。为预测变流器水冷系统的温度[13],筛选出6个直接决定和影响变流器温度的相关参数,包括水冷系统出口温度、水冷系统出口水压、水冷系统进口水压、水冷系统进口温度、环境温度和风机功率。
1 特征标准化
特征标准化是数据预处理过程中常用的一种方法[14]。它可以将数据转化为均值为0、标准差为1的标准正态分布,也可以将数据标准化到0~1。特征标准化可以使得各个特征的大小范围相同,避免了某些数据的特征对结果的影响较大,从而提高了模型的准确性和预测能力,同时能够减少样本误差,稳定模型的性能。
在Python中,可以使用MinMaxScaler函数对数据进行标准化。MinMaxScaler函数是sklearn.preprocessing模块中的一个类,可以将数据转化为0~1的范围之内。其中的关键步骤是对样本进行计算平均值和标准差的统计,再利用测试样本进行min-max缩放。
MinMaxScaler实现特征标准化采用如下公式:
X_std=(XX.min(axis=0))/
(X.max(axis=0)-X.min(axis=0))
(1)
X_scaled=X_std*(max-min)+min
(2)
式中:axis=0为计算每一列的最大值和最小值。函数将X中的每一列缩放到0~1,然后进行平移和缩放,使得每一列都符合标准正态分布。
2 特征提取
特征提取是一个旨在识别和提取重要特征的任务,从而降低数据的复杂度,以便更容易进行模式识别和分类[15]。在时间序列数据中,特征提取是一个特别重要的任务,因为时间序列数据具有高度相关性和复杂性。因此,通过提取出数据中最相关的、最有用的特征,可以帮助更好地理解和处理数据。
使用时间序列数据进行特征提取,并通过小波包分析和卷积神经网络(convolutional neural network,CNN)进行特征融合和分类。在特征提取过程中,将时间序列数据切分成固定长度的时间序列样本,可以减少数据噪声和冗余,更好地保留数据的有用信息;通过小波包分析,则可以更好地处理信号的这些高频成分;CNN则可以从中提取出更高级、更抽象的特征。在将小波包分析和CNN结合起来时,小波包分析通常用于分解各个频率下的信号,CNN则用于处理来自各个分量的图像特征,从而实现特征融合。这样可以将时间序列问题转化为监督学习问题,从而可以使用监督学习算法来训练和测试模型。
综上所述,特征提取的原理是基于对原始数据进行转换和处理,提取出数据潜在的有用特征,从而更好地反映数据的本质特征。在时间序列数据的处理中,小波包分析和卷积神经网络联用是一种有效的方式,可以运用不同的技术取长补短,提取更为有效的数据特征,并加以融合,从而提高数据分类和预测的准确性,提高数据处理和监督学习的效率和精度。
3 数据转换
数据转换的作用是将原始数据转化为适用于机器学习和深度学习算法处理的有监督学习问题,使得机器可以从数据中学习规律和模式,并用于未来的预测和决策。特别地,对于时间序列数据,数据转换可以将观测值按照一定的时间范围进行滚动,以创建时间窗口,并将该时间窗口中的数据作为输入特征,窗口最后一个时间点的数据作为输出标签[16]。通过这种方式,可以获得单位时间内的数据变化规律,使得机器可以对未来单位时间内的数据进行预测,而且可以帮助消除原始数据的噪声、消除数据中的周期性波动以及减少渐进性漂移等问题。特别是应用在风电机组数据的这种复杂时间序列数据中,数据转换还可以改进预测的准确性。
数据转换的原理是基于滚动时间窗口将时间序列数据转化为监督学习问题,具体步骤如下:
1)通过观察时序数据的特点来确定合适的窗口长度,在本例中,选择30 min和60 min作为窗口长度,以便学习时间尺度内的数据模式。
2)按照窗口长度滚动数据,并将窗口内的数据作为输入特征,窗口末尾时刻的数据作为输出标签。这样,就可以创建有标签的数据点,用于监督学习算法的训练。
3)基于这些有标签的数据点,训练预测模型,通过对未来时间点的输入特征进行预测,以预测未来的标签。
4 模型训练
LightGBM是用于处理具有复杂特征和大量数据的问题,如图像识别、自然语言处理、预测和推荐等[17-18]。LightGBM使用了一种称为GOSS(gradient-based one-side sampling)技术来加快训练速度,该技术可以通过去除梯度小的样本来减少数据数量[19-20],从而提高模型的效率。此外,LightGBM通过使用直方图来对特征进行离散化,并且可以快速地找到最佳划分点,从而提高特征筛选的效率。在训练时,LightGBM使用了基于leaf的决策树来进行优化,即只考虑每个树叶子节点的信息,而不是考虑整个树。
在风电数据领域,LightGBM相比其他机器学习算法(如决策树、随机森林、神经网络等)有以下几个优势:
1)高效性。风电数据通常属于高维稀疏数据,包含大量的定量和定性特征,对于这种数据而言,LightGBM在处理大规模数据时比其他算法更高效,由于使用了GOSS,可以忽略那些梯度比较小的样本点,减少训练集的样本数。因此,它对于计算资源的要求更小,可以更快地训练模型。
2)准确性。由于使用切分点的直方图算法,LightGBM能更准确地寻找最优划分点,同时使用leaf优化提高了模型的精度。
3)鲁棒性。LightGBM能够在不均衡数据集、高维度数据集和缺失数据集上表现出更好的鲁棒性,具有更高的容错性和泛化性能。
4)可解释性。LightGBM拥有容易理解的模型结构,输出的树形结构是可解释的,有助于深入理解变量和特征之间的关系,从而更好地进行数据分析和建模。
将时间序列数据转换为适合机器学习算法处理的数据格式,创建适合LightGBM模型处理的数据集,并使用LightGBM模型对数据进行训练和预测。
5 模型测试与评估
模型评估是使用sklearn.metrics库中的函数,用于评估机器学习模型的性能,其中包括以下几个指标[21-22]:
1)均方误差(mean squared error, MSE)。MSE表示预测值与真实值之间差值的平方和除以样本个数,是回归问题中最常用的评估指标。它的计算公式为
MSE=1/n∑(y_pred-y_true)2
(3)
式中:n为样本个数;y_pred和y_true分别为模型的预测值和真实值。
2)平均绝对误差(mean absolute error,MAE)。MAE表示预测值与真实值之间差值的绝对值之和除以样本个数,也是回归问题中常用的评估指标。它的计算公式为
MAE=1/n∑|y_pred-y_true|
(4)
3)平均绝对百分误差(mean absolute percentage error, MAPE)。MAPE表示预测值与真实值之间差值的绝对值除以真实值再乘以100%的平均数。它对于处理数据单位不同的数据集时非常有用,也是回归问题中常用的指标之一。它的计算公式为
MAPE=1/n∑(|y_pred-y_true|/y_true)×100%
(5)
4)R2得分(R squared score)。R2得分表示模型的解释能力,即模型对因变量的变异能够解释多少。它的值为0~1,值越接近1表示模型的解释能力越好。它的计算公式为
R2=1-∑(y_pred-y_true)2/∑(y_true-y_avg)2
(6)
式中:y_avg表示真实值的平均数。
这些指标的作用在于对机器学习模型的性能进行评估,以确定模型预测准确性的好坏。在选择模型和调整模型参数时,可以根据不同的指标进行评估和比较,从而选择最合适的模型和参数组合。
在进行模型测试过程中,首先需要对模型进行训练,然后利用测试集对模型的性能进行评估,根据评估结果进行优化调整,得到最终的表现最佳的模型。
在本文中,采用了LightGBM模型进行训练和测试,并按照如下步骤进行调整优化[23]:
1)采用默认参数进行训练,得到基准性能。在测试集上,得到R2得分为0.955,MAE为0.291。
2)将learning rate从默认值0.1调整为0.01,并将max_depth从默认值-1调整为5。在测试集上,得到R2得分为0.972,MAE为0.222,即已经比前一步有一定的提高。
3)将min_child_samples从默认值20调整为3,并进一步调整learning rate和max_depth。在测试集上,得到R2得分为0.978,MAE为0.184,此时模型的表现已经达到了最佳状态,可以作为最终模型进行应用。
6 模型结果展示
机组变流器主要故障模式进行设计测试集采用的数据是华东地区海上某风场的6S机组,单台容量6.45 MW。图2为海上风力发电机组机组外观全貌。变流器为2套3 MW机组功率并联的结构,协助变流器IGBT模块散热的方法为水冷方式,由冷却液流经变流器带走热量,冷却液由循环泵的进口经室外空气散热器与冷空气进行热交换,散热后再进入变流器。其中冷却液的正常温度范围一般处于35~42 ℃。

图2 海上风力发电机组机组外观图
对机组变流器温度进行采集,并采用本文的预测方法对变流器温度进行预测,预测结果如图3所示。

图3 预测结果
图3中,蓝色数据为机组实际表现值;桔红色数据为模型预测值;纵坐标为水冷系统出口温度,℃;横坐标为数据标签点,相邻标签点之间的时间间隔为6 s。
为了评估模型的性能,抽取了8段时间的实际温度数据进行对比分析。
实际温度均值为37.836、38.154、38.378、38.812、38.761、38.392、39.443、37.496 ℃。
预测温度均值为38.103、38.019、38.701、38.932、38.848、38.635、39.254、37.592 ℃。
计算得出使用测试集测试模型的MAE为0.183,MSE=0.039 97。
然后计算模型的精确率、召回率,得出模型在测试集上的精确率为0.986,表示在所有被预测为高温(即温度达到故障门限)的样本中,有98.6%的样本预测正确。召回率为0.984表示在所有实际高温样本中,有98.4%的样本被正确地预测为高温。
评估结果显示,变流器水冷系统温度预测模型在预测高温事件方面具有高度准确性和可靠性。经过在测试集上评估该LightGBM模型的性能,发现该模型在预测目标值时表现出高准确性和稳定性,适用于生成高质量的预测结果,并已成功将预警模型软件挂载到大数据预警平台上,目前已应用到数据预警和监控工作当中。
此外,基于时间序列数据的特点,随着预测时间的增加,预测准确性会降低。因此,提出一种方法来实现预测模型的本地化效果。具体做法是,在使用Python运行模型后,利用joblib库中的dump函数将LightGBM模型对象保存到本地。随后,通过风机主控使用joblib库中的load函数重新加载该模型对象,从而实现预测模型的本地化。目前,预警模型已经挂载到主控程序算法的项目中,并正在控制系统部门进行稳定性测试。
7 结语
本文的基于有监督学习的风电机组故障预测模型,为风电行业提供了一种新的思路和工具。未来,该模型还可以进一步发展和优化,应用于风电机组的实时监测、故障诊断与预警等多个方面,促进新能源产业的发展和应用。随着信息技术的不断进步,相信不久将会看到风电机组故障预测模型呈现轻量化和实时化的发展趋势。这种趋势会使风力发电机组提供更多优质、高效的绿色能源。
猜你喜欢
河北电力技术(2021年2期)2021-07-29
能源(2018年6期)2018-08-01
能源(2018年6期)2018-08-01
能源(2018年8期)2018-01-15
电测与仪表(2016年8期)2016-04-15
通信电源技术(2016年4期)2016-04-04
风能(2016年12期)2016-02-25
电测与仪表(2015年16期)2015-04-12
电测与仪表(2014年19期)2014-04-04
自动化博览(2014年9期)2014-02-28
