
基于层次耦合聚类的用户社区划分方法:以主题公园社交平台为例
2023-10-09 09:37:34刁雅静吴嘉辉王志英朱庆康
江苏科技大学学报(自然科学版) 2023年4期
刁雅静,吴嘉辉,卢 健,王志英,朱庆康
(江苏科技大学 经济管理学院, 镇江 212100)
随着社交媒体的快速发展,越来越多的用户喜欢通过微博和微信等平台发表自己的观点.然而无限制的网络信息交互导致了用户无目的搜索,以及平台商家无法实现服务的精准推荐等问题.以主题公园社交平台为例,主题公园商家无法准确获知游客用户的偏好需求,同时游客用户也无法精确了解主题公园商家提供的服务[1].究其原因是对用户偏好识别不准确,对用户人群划分的判断方法存在缺陷.为了更加准确识别用户偏好和社区划分,学者们开始研究相关算法的改进.文献[2-4]将自然语言处理技术与数据科学技术相结合,设定相关领域的情感词表,通过对比预处理后的文本与情感词语实现对用户情感喜好的分析研究,进而识别用户偏好和进行社区划分.文献[5-6]考虑时间的因素前提下使用动态聚类算法,实时跟踪用户偏好需求的变化,挖掘和识别用户需求偏好.还有学者使用数据库存储的大规模用户信息数据和行为数据来合理有效的提取用户的短期需求和长期兴趣,进而实现识别用户偏好[7],以及基于Folksonomy的分布式分类系统中的用户偏好识别问题研究[8-9].多数研究聚焦领域知识和行业经验,在原先基础上改进模型或者根据需要构建新的适用性模型,探寻更优的发现用户社区的方法,进而实现用户社区划分[10-12].上述研究中聚类方法多是对象的社区划分聚类,较少涉及对象属性的领域划分聚类,进行对象社区划分与属性领域划分的层次性耦合聚类的相关研究较少;在用户偏好识别特征选取算法中,目前的研究主要运用基于聚类以及基于遗传算法等特征选择方法来实现属性维度的约减,这样可能会导致特征选择性能不高、精确度较低、鲁棒性较差以及运算量大的现象发生,直接导致选取的属性特征质量较差,最终影响实验结论的准确性和实验理论的实用性[13-15].基于此,文中基于主题公园社交媒体平台的用户客观行为数据,挖掘用户及其偏好属性之间的耦合关联关系,构建基于耦合聚类的用户社区划分模型;同时通过运用随机森林算法实现特征选择,依托模型寻找到最优的阈值,实现偏好领域最优划分,进而解决用户偏好识别和用户社区划分的问题.
1 研究设计
1.1 数据特征及相似性计算策略
社交媒体用户依据自身的需求偏好或者根据其对其他社交媒体用户生成内容产生的认同和反驳行为,进行交流互动,主动生成用户行为数据.用户通过社交媒体平台积极主动表达自己的需求,进而产生真实可靠历史和实时行为数据,通过分词、去停词等数据预处理操作实现行为数据中偏好主题词的提取.以行为参与者用户为行、偏好主题词为列构成“用户—偏好主题词”二维矩阵.该矩阵有两个主要的数据特征:① 不同的偏好范围可形成层次性的游客用户社区.即不同的用户对于同种偏好范围有着相同的喜好和关注,那么依据相同的偏好主题词就可以将这些用户划分在同一个用户社区内,实现用户社区划分.② 不同社区的用户之间可能有多个相同的偏好主题词,因此用户之间所涉及到的偏好范围具有层次性和交叉性.由于文中的数据不符合连续正态分布(排除使用皮尔逊相关性计算),同时文中数据构建的向量为稀疏词语空间向量,因为余弦相似度在处理词语空间向量和稀疏向量之间有着非常好的效果,所以此处相似性策略选择余弦相似度.
1.2 用户偏好识别算法
1.2.1 基于偏好主题的用户社区划分
从由用户的主动交互生成内容构建起的“用户—偏好主题词”矩阵中,提取出用偏好主题词构成的用户向量,采取余弦相似性算法策略计算用户之间的相关性,在充分考虑用户和偏好主题词之间的关联影响关系的基础上,运用层次性耦合聚类的方法较为精确划分用户社区,直到满足耦合停止的条件,即停止耦合迭代聚类,此时耦合聚类的结果即是实验的最终结果.基于偏好主题的用户社区划分算法如表1.

表1 基于偏好主题的用户社区划分
1.2.2 基于用户的偏好主题相关性分析
从由用户的主动交互生成内容构建起的“用户—偏好主题词”矩阵中,提取出由用户构成的偏好主题词向量,采取余弦相似性算法策略计算偏好主题词之间的相似性,在充分考虑用户和偏好主题词之间的关联影响关系的基础上,运用层次性耦合聚类的方法较为准确的识别用户偏好,直到满足耦合停止的条件,即停止耦合迭代聚类,此时耦合聚类结果即是实验的最终结果.基于用户偏好主题相关性分析算法如表2.

表2 基于用户的偏好主题相关性分析
1.3 用户偏好算法实验分析
通过典型的社交媒体用户生成内容平台“百度贴吧”“百度指数”的数据,对典型的主题公园企业“成都欢乐谷”的用户偏好进行耦合聚类识别,在耦合聚类实验中,分别以用户社区划分和偏好主题词领域划分为两个起点,通过游客用户与偏好主题词之间的耦合聚类,实现用户社区的逐层精细划分和游客用户偏好的逐层准确识别.基于层次耦合聚类的用户偏好识别模型验证流程如图1.

图1 基于层次耦合聚类的用户偏好识别流程
通过Python语言与Scrapy框架相结合的方法爬取1 045条典型社交媒体“百度贴吧”中的“成都欢乐谷贴吧”的数据.使用Python3.5中的Jieba模块实现分词处理,在实验中,不断修正Jieba模块中的Dict文件,提高了分词的准确性,取得较好的分词结果,进而生成准确的“游客用户—偏好主题词”矩阵.在二维矩阵基础上,将其中意思相同特征属性(即意思相同的偏好主题词)组合合并,实现属性维度的初步约减.最后通过相关网络爬虫和数据预处理技术获得571条游客用户数据和381条偏好主题词数据,构建571×381二维矩阵.
2 实验结果
(1) 基于偏好主题的游客用户社区划分
游客在社交平台“成都欢乐谷贴吧”中贡献的实时和历史行为数据反映了游客用户需求.通过耦合聚类的方法(根据偏好主题词对游客用户聚类→根据游客用户对偏好主题词聚类→再根据偏好主题词对游客用户聚类),选取特定类别进行研究,从而挖掘游客用户间的潜在联系以及对应的兴趣偏好,实现用户社区更精确的划分:① 计算游客用户向量相关系数矩阵.根据381个词语构成的游客用户向量,计算游客用户向量之间的余弦相关系数,得到相关系数矩阵.② 根据相关系数将用户聚类.将游客用户聚成6类,选取其中的特定游客用户社区为代表性研究对象.③ 计算偏好主题词语向量相关系数矩阵.提取其中46个游客用户,将其与原先381个偏好主题词构成46×381矩阵,通过计算46个游客用户组成的381个偏好主题词的稀疏向量之间的余弦相关度,得到词语相关系数矩阵.④ 根据词语相关系数实现偏好主题领域划分.再一次进行聚类,将381个偏好主题词聚成5类,选取其中的特定偏好主题词领域作为代表性研究对象.⑤ 最终依据上面结果再次划分特定游客用户社区.提取其中的56个偏好主题词,将其与之前的46个游客用户,组成46×56矩阵.通过56个偏好主题词构成的46个用户向量,计算游客用户之间的余弦相关系数,构成相关系数矩阵,进行第三次聚类.此时,将游客用户聚成两类,当调整阈值的时候,彼此之间关联边依旧没有改变,说明此时游客用户之间的关联性较高,符合迭代停止条件,最终实现更精确的用户社区划分.耦合聚类结果如图2.
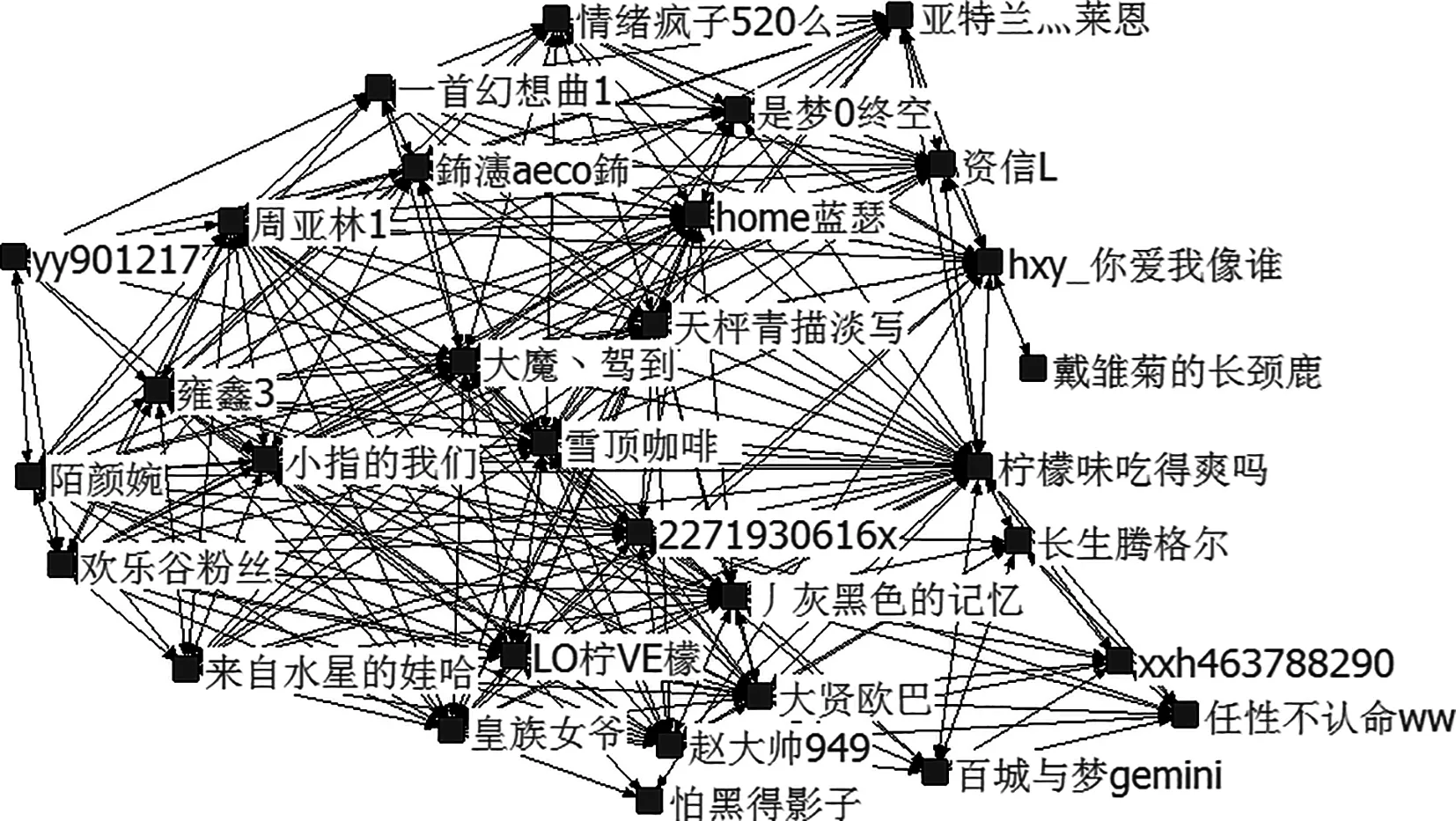
图2 第三次耦合聚类后的特定游客用户社区(包含31位游客用户)
(2) 基于游客用户的偏好主题相关性分析
分词处理后的词语,即偏好主题词,是游客用户需求偏好的直接体现.需求偏好的识别是关联分析的基础,因此,通过耦合聚类的方法,根据游客用户贡献的实时和历史行为数据更加精确识别游客用户的需求偏好,就变得尤为重要.① 计算偏好主题词向量相似性矩阵.利用余弦定理计算571个游客用户构成的381条偏好主题词稀疏向量之间的余弦相似性,构成词语相似系数矩阵.② 根据相关系数矩阵,进行第一次聚类,选取其中特定偏好主题词领域作为研究对象.③ 提取其中34个词语,计算34条由偏好主题词构成的571条游客用户向量之间的余弦相关系数.④ 根据余弦相关系数,调整边值使用户之间达到最优分布,通过余弦相关系数实现第二次聚类,选取特定游客用户社区作为研究对象.⑤ 提取其中的45个游客用户,计算由45个游客用户组成的34条偏好主题词稀疏向量,通过余弦定理计算偏好主题词之间的相似性,构成相关系数矩阵.⑥ 通过偏好主题词之间的相关系数,进行第3次聚类,根据行业领域知识和生活经验得出此时的聚类结果已经符合停止迭代条件,最终的偏好主题词领域划分更加准确的展现用户的需求偏好.耦合聚类包含15个偏好主题词,如图3.
3 模型验证
在确定目标特征属性的前提下,通过KNN分类、logistic回归分类、SVM分类以及随机森林分类4种分类算法的数据处理,比较不同阈值下的十折交叉验证的平均AUC数值,选取最优阈值再进行聚类分析,进而完成最优偏好领域划分.
根据随机森林特征选择方法得到贡献度最大的75个偏好主题词属性和目标属性特征“享受”,共同构建起571×76的二维二分矩阵.在二维矩阵的基础上,规定偏好领域划分的领域数量为3,偏好领域阈值从0.1取到0.9,随后在分类模型中再分别对不同的阈值使用十折交叉验证的方式计算出偏好领域的AUC数值,比较不同模型不同阈值下的AUC平均值,最终实现偏好主题词领域的最优划分.研究选择平均AUC数值作为选取最优阈值的依据指标.从随机森林特征选择中提取出对于目标属性特征“享受”贡献度最大的75条词语向量.
(1) 根据KNN分类模型算法选取最优聚类阈值.
由图4可知,在KNN分类模型前提下,分别从0.1取到0.9阈值,可以计算得到10折(从左到右依次为1~10折)交叉验证中折数对应着的AUC平均值.依托最大AUC平均值0.79(精确到两位小数,下同)选取出最优阈值为0.4,进而可以达到偏好关键词领域的最优划分.
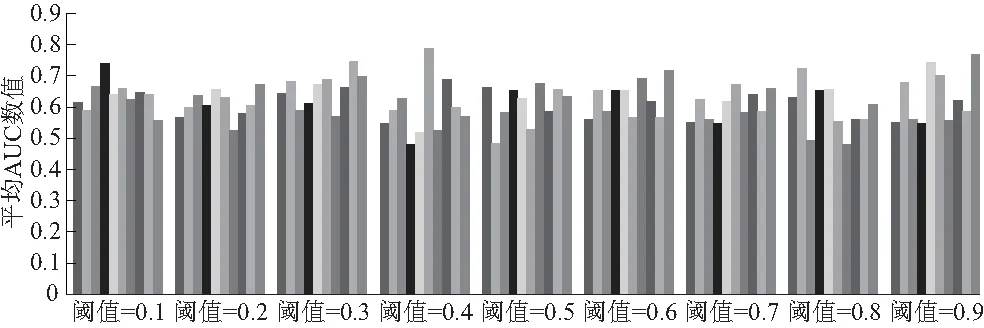
图4 基于KNN模型的平均AUC数值
(2) 根据logistic分类模型算法选取最优聚类阈值.由图5(从左到右依次为1~10折)可以看出,在logistic回归模型前提下,依据最大的AUC平均值0.74选取出偏好领域划分的最优阈值为0.9.在阈值取0.9的情况下,因为大部分偏好主题词之间的相关度都低于0.9,偏好关键词领域划分只能达到2类,无法达到3类,所以领域划分的效果不好.因此本研究数据使用logistic回归分类模型选取最优阈值的效果较差.
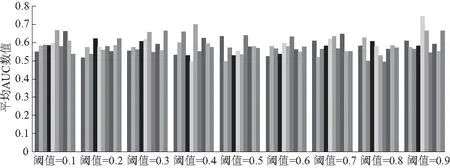
图5 基于logistic模型的平均AUC数值
(3) 根据SVM分类模型算法选取最优聚类阈值.由图6可以看出,在SVM回归模型前提下,依据最大的AUC平均值0.81选取出偏好领域划分的最优阈值0.2(从左到右阈值依次为0.1~0.9).SVM分类模型以“享受”为分类目标属性特征选取0.2为最优阈值,将词语分成3个偏好主题词领域(剔除阈值小于0.2不相关的节点),可以看出阈值降低的情况下偏好主题词节点明显增加.
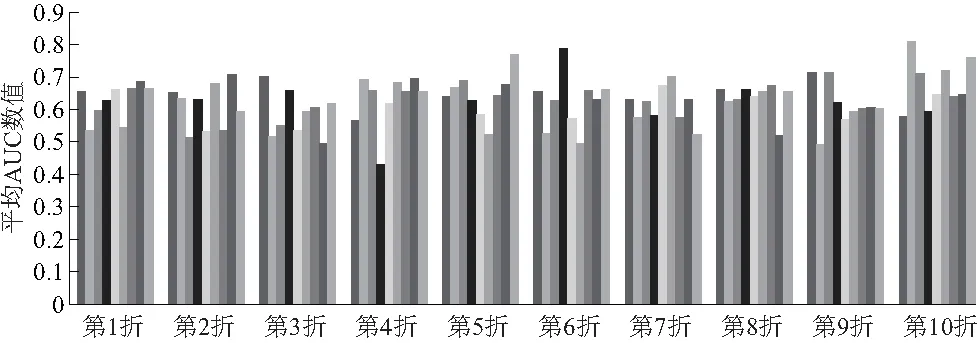
图6 基于SVM模型的平均AUC数值
(4) 根据RF(随机森林)分类模型算法选取最优聚类阈值.由图7(从左到右依次为1~10折)可以看出,在随机森林模型前提下,依据最大的AUC平均值0.82选取出偏好领域划分的最优阈值0.3.RF分类模型以“享受”为分类目标属性特征选取0.3为最优阈值,将词语分成3个偏好主题词领域(剔除阈值小于0.3不相关的节点),相较于SVM分类模型结果没有较大的变化,虽然偏好主题词节点数变少,3个领域结果内容都类似于SVM分类模型实验结果.

图7 基于随机森林模型的平均AUC数值
综上所述,在耦合聚类模型的验证中,不同的分类模型可能对应不同的阈值,需要根据更加具体的实际应用要求决定最终的阈值选取.此外,因为文中实验的0.9阈值的偏好领域划分的效果较差,所以实验过程中也要注意数据特征对于分类模型的适用性.
4 结论
(1) 通过考虑用户偏好主题词的层次性关联关系和用户社区与偏好主题词领域之间的耦合关系,提出了层次耦合聚类分析方法,以特殊“迭代”的形式,实现了用户社区划分和偏好主题词领域划分的耦合性聚类,揭示了用户社区及偏好主题的多样性及新颖性.
(2) 通过先分类再聚类的逻辑进行模型验证,以AUC作为阈值选择的依据,避免传统意义上人为规定阈值出现的误差,排除了部分人为因素的影响,进而使实验的最终结论具有更好的说服力和可信度.
猜你喜欢
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
电子测试(2017年15期)2017-12-18 07:19:27
河北遥感(2017年2期)2017-08-07 14:49:00
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
西北工业大学学报(2015年1期)2015-02-22 00:29:19
西北工业大学学报(2015年1期)2015-02-22 00:29:19
沈阳医学院学报(2014年4期)2014-12-27 13:44:34
