
基于长短期偏好的自适应融合推荐算法
2023-10-09 09:13王云沼黄树成
江苏科技大学学报(自然科学版) 2023年4期
周 倩, 王 逊*, 王云沼, 黄树成
(1.江苏科技大学 计算机学院,镇江 212100)
(2.32185部队,北京 102400)
随着互联网快速发展,用户在面对电子娱乐、社交媒体等平台带来的海量信息时,很难从中快速找到感兴趣的内容.因此,推荐系统(recommender system,RS)应时而生,它能够缓解信息过载并且指引用户选择感兴趣的信息.但传统的推荐算法[1]在处理数据稀疏性以及冷启动问题上有一定的局限性[2],只能以静态的交互方式捕获用户兴趣偏好,学习到的用户兴趣是变化缓慢或者静态的.对于学习用户历史行为序列的潜在特征是完全忽略的,则会缺少用户短期兴趣的获取,不能很好的模拟用户兴趣变化趋势.
近年来,深度学习(deep learning, DL)已被广泛应用到图像处理、语音识别、在线广告以及自然语言处理等领域[3].但基于深度学习的推荐算法大多是将用户看作一个静态实体,则时间行为序列中蕴含潜在的动态兴趣偏好并不能得到有效挖掘和利用.在深度学习中,循环神经网络(recurrent neural network, RNN)是一种深度前馈神经网络,能够为行为序列信息在不同时刻间的依赖关系进行建模,对历史交互行为信息进行记忆.而且长短期记忆模型(long-short term memory, LSTM)[4]、门控循环单元(gated recurrent unit, GRU)[5]作为RNN成功的变种,它们的网络结构不仅在层与层之间有连接,在各个隐藏层的神经元上也有连接.因此,LSTM和GRU能够高效处理序列信息,并擅于捕捉用户的历史交互序列中蕴含的潜在特征.
为了兼顾用户长短期兴趣偏好对推荐效果的影响,提出利用矩阵分解处理用户和项目的隐向量捕获长期兴趣表示,结合循环神经网络成功的变种——门控循环单元(GRU)处理用户历史行为序列,捕获用户短期动态兴趣表示.此外,在GRU中嵌入注意力机制学习更重要的兴趣偏好,最后融合用户短期动态兴趣和长期兴趣进行用户推荐.文中算法充分结合GRU和矩阵分解(matrix factorization,MF)优势的算法,将两者无缝融合,从而捕获用户长短期兴趣偏好,能够有效提高推荐性能和准确性.
1 相关工作
1.1 矩阵分解算法
矩阵分解(MF)算法是在协同过滤推荐算法中应用最广泛的算法.它能够有效挖掘用户信息和项目信息的潜在的长期兴趣.例如文献[6]提出在矩阵分解中结合标签的推荐算法,从而缓解数据稀疏性,提高推荐准确性.矩阵分解的空间复杂度低且具有一定的泛化能力,能够使用线性函数来表示用户的长期偏好.与深度学习相比,矩阵分解具备可解释性强的优势.矩阵分解灵活性高,有助于与深度学习网络进行组合或者拼接.基于矩阵分解的优点,使用矩阵分解算法学习用户长期兴趣最为合适.
1.2 深度学习在推荐算法中的应用
将深度学习应用于推荐算法是目前主流的研究方向之一.例如文献[7]提出概率神经网络(probabilistic neural network,PNN)算法,该算法输入还加入其他特征,通过特征两两交互捕获更多的潜在特征.随后,有学者提出以并联的方式结合传统推荐算法与深度学习,文献[8]提出WIDE &DEEP算法,兼顾逻辑回归和深度学习的优点,使算法同时具有Wide层的记忆能力和Deep层泛化能力,再并联输出进行预测推荐.文献[9]在WIDE &DEEP算法的基础上,用因子分解(factor machine,FM)算法代替Wide部分的逻辑回归,最后两者输出参与最后的预测,有效提高推荐准确性.
但是,以上基于深度学习的算法大都将特征交叉的行为直接表示用户兴趣,缺少通过用户历史行为序列获取用户动态兴趣偏好的方法.文献[10]提出的因式个性化马尔可夫分解(factorizing personalized Markov chains,FPMC)算法,利用马尔科夫链捕获历史序列中的兴趣特性,大大提高了推荐准确性.文献[11]利用双向长短期记忆网络(Bi-LSTM)模型获取序列中潜在信息特征,达到较好的推荐效果.LSTM或者GRU网络学习历史交互序列,能够较好的捕获用户兴趣变化特征,解决RNN的梯度消失问题.
1.3 注意力机制
在建模过程中考虑注意力机制(attention mechanism,AM)对预测结果会有不错的收益.注意力机制重点在于计算注意力分数,利用分数影响用户相关信息的权重.注意力机制已经成为各种序列模型的组成部分,也可以有效应用于推荐系统.文献[12]提出深度兴趣网络(deep interest network,DIN)算法,利用历史行为序列,并使用注意力机制衡量每个历史行为特征与候选项目之间的关联程度.程度越强,对最后兴趣推荐影响更大,最后被赋予的权重更多.但DIN模型并没有对历史行为序列进行深度处理,只是计算历史行为和候选项目的相似度进行推荐.
2 算法设计
基于长短期偏好的自适应融合算法(recommender unit concatenate factorization,RUCF)的流程图,如图1,主要分为两大模块:长期偏好模块和短期偏好模块.长期偏好模块是通过GMF层和全连接层处理用户和项目特征,提取长期静态的兴趣状态表示;短期偏好模块是由两层GRU结合注意力机制组成,从输入的用户行为序列中提取短期、动态的兴趣状态表示.最后将两者以及辅助信息拼接进行自适应融合输出.
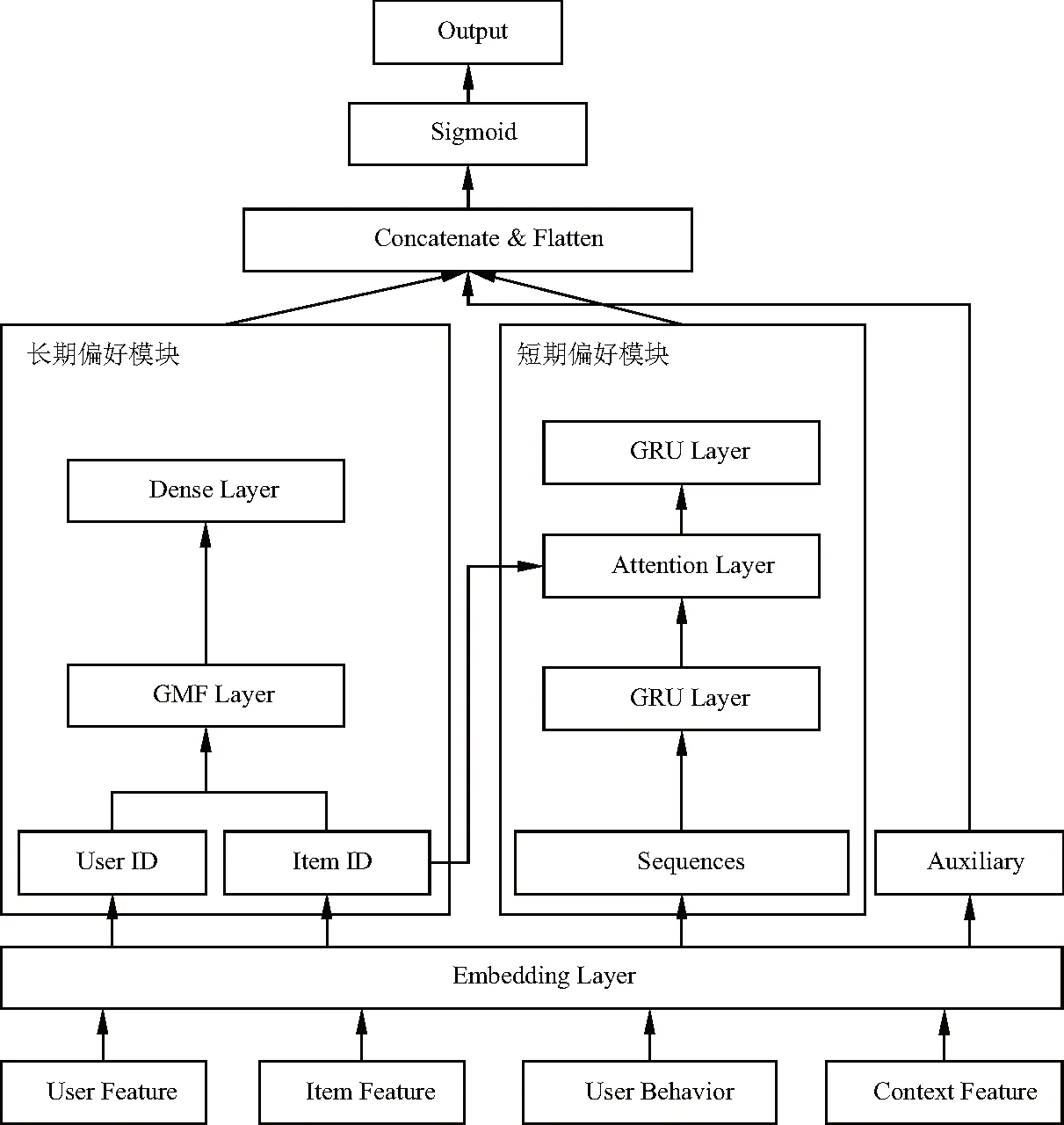
图1 RUCF流程图
实验的整体流程步骤如下:
(1) Input Layer:模型输入特征主要分四个部分:用户特征(年龄,性别,职业)、物品特征(名称、类型)、用户的历史行为特征(用户,项目,评级交互)和上下文特征(时间).输入"UserID", "gender","age","hist_movie_id","Sequences","ItemID"等数据.
(2) Embedding Layer: Embedding层接收InputLayer层的数据,进行Embedding层处理,并经过Flatten层,将输入压平.经过Embedding层处理后,数据分为3部分输入到下一个模块:特征信息输入到长期偏好模型;用户交互序列数据进行处理捕获动态兴趣偏好,输入到短期偏好模型;用户和项目的辅助信息,包括用户性别、年龄以及项目类别等信息,经过Flatten层等待最后的拼接.
(3) 输入经过Embedding Layer的"UserID","ItemID",通过长期偏好模型——GMF层和全连接层处理用户和项目特征,提取长期静态的兴趣状态表示.
(4) 输入"Sequences"、"ItemID"数据,经过短期偏好模型——两层GRU结合注意力机制组成处理,从用户行为序列中提取短期、动态的兴趣状态表示.
(5) 最后,在兴趣融合层,经过Concatenate and Flatten层将短期兴趣特征、长期兴趣表示、辅助信息嵌入向量结合,经过非线性激活函数输出最终结果.
2.1 用户长期偏好模块
为了捕获用户长期静态偏好,使用矩阵分解的通用模型,即广义矩阵分解(generalized matrix factorization,GMF)模型.MF算法将M*N维的共享矩阵R分解成M*K维的用户矩阵U和K*N维的物品矩阵V相乘的操作.其中M、N和K分别表示用户数量、项目数量和隐向量维度.如图2,用户和物品的隐向量通过分解共现矩阵得到.
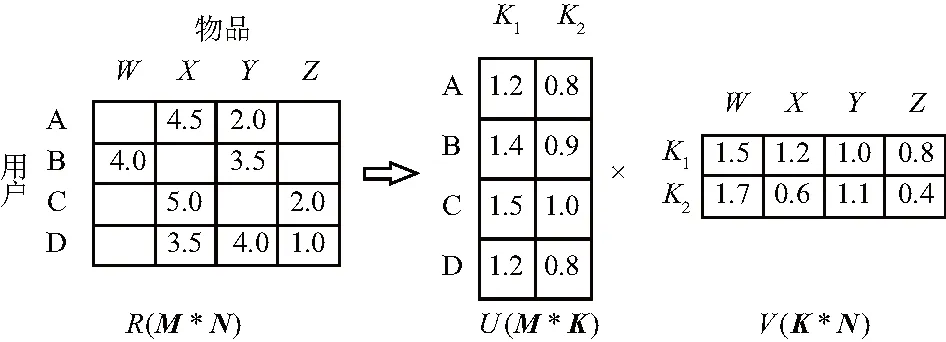
图2 矩阵分解过程
广义矩阵分解模型学习用户的隐空间向量和物品的隐空间向量的点积,然后通过一个全连接线性层加权输出.长期偏好提取部分的输入为用户id和项目id离散特征,首先经过One-Hot编码,然后输入Embedding层,将稀疏且高维的数据转成低维稠密向量,再进行点积,通过GMF模型学习最后的输出表示,结果为:
(1)
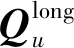
2.2 用户短期动态偏好模块
2.2.1 GRU学习短期偏好
为有效捕获用户短期偏好,使用双层GRU网络来有效学习用户兴趣动态演变过程.GRU网络结构能够有效捕捉用户潜在的短期兴趣变化,与LSTM相比网络结构更加简单,而且效果也很好.图3为短期偏好模块流程图.
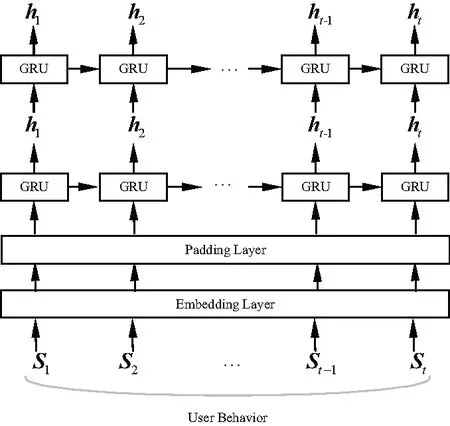
图3 短期偏好模块流程图
首先,将每一个用户U的交互项目以时间顺序排序为Sn=[i1,i2,i3,…,ik,…,in],其中ik为第k个交互的项目,n为序列总长度.然后为每个用户划分n个样本序列:S1=[i1],S2=[i1,i2],S3=[i1,i2,i3],…,Sn=[i1,i2,i3,…,ik,…,in].为了使网络模型的效果更好,随机抽取未交互的项目序列组成负样本序列一同参与训练.验证集由每个用户的倒数第二个项目序列Sn-1组成,测试集由最后一个项目序列Sn组成,剩下的项目序列组成训练集.
然后,根据GRU要求输入序列长度相同,使用Padding层将序列填充或截取为相同长度,文中设置序列长度为50.在GRU模型中有两个门:重置门(reset gate)和更新门(update gate).每层GRU都是由GRU的Cell单元从时间维度连接组成.如图4为t时刻GRU的一个Cell单元结构.
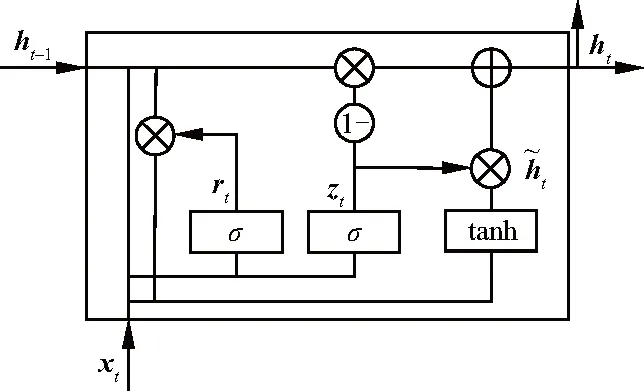
图4 在t时刻GRU单元结构图
在t时刻GRU Cell单元的具体形式为:
rt=σ(Wr·[ht-1,xt]+br)
(2)
zt=σ(Wz·[ht-1,xt]+bz)
(3)
(4)
(5)
最后,用户行为序列经过第一层GRU输出得到各个时间步的隐藏状态ht,作为下一层GRU的输入.
2.2.2 引入注意力机制
RUCF算法使用注意力机制,即在两层GRU网路的基础上,将注意力分数添加在第二层GRU网路的更新门上,更改GRU的结构,从而能捕获更重要的兴趣偏好,反映对预测结果的重要程度,如图5为引入注意力机制图.
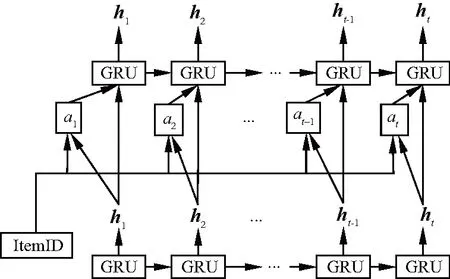
图5 引入注意力机制图
通过注意力机制得到上一层GRU层每个时间步的隐藏状态ht,结合候选项目计算注意力分数at.候选项目为当前项目i经过Embedding后的嵌入向量表示ei.注意力分数计算为:
(6)
式中:ht为时间步t时刻第一层GRU的隐藏状态;ei表示候选项目的Embedding向量;at为一个数值分数,值越大,当前ht对候选项目的贡献越大.
将得到的注意力分数嵌入到第二层GRU的更新门中,如图6,用这个GRU层来更有针对性的模拟与目标项目相关的兴趣演化过程.
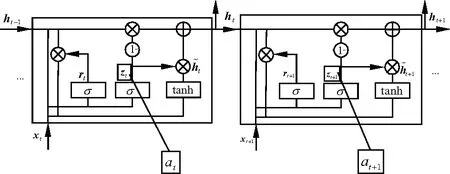
图6 更改GRU门结构图
使用注意力分数更新GRU结构的公式为:
zt′=at·zt
(7)
(8)
最后,该部分结果不使用最后一个隐藏状态当作用户短期兴趣表示,而是把获取到的短期兴趣状态最终表示成所有隐藏状态的加权平均值为:
(9)
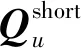
2.3 自适应融合
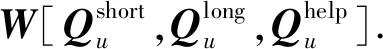
(10)
式中:σ为激活函数;W为权重向量;b为偏置向量.
2.4 模型训练
算法将推荐任务描述为二进制分类问题,使用负对数似然函数(Log-loss)作为损失函数,计算为:
(11)

3 实验研究
3.1 数据集
为了研究捕获用户长短期偏好的有效性,文中构建RUCF算法,并在MovieLens-1M和Electronics两个公共数据集上评估该算法.表1为数据集详细数据统计表.MovieLens-1M是一个电影数据集,包含用户特征、电影特征、评级信息、时间戳等信息.Electronics是亚马逊数据集的一个子集.文中电影和商品被表述为项目.

表1 数据集各项数据统计
在这两个数据集中,都记录了用户对项目进行评级交互的每个时间戳,可以为每个用户构造其交互的项目序列.值得注意的是,不以任何方式使用交互评分的值,只是将交互的项目标签设为1,未交互的项目标签设为0.
3.2 对比模型
文中选取以下经典的推荐算法与RUCF算法进行比较,验证所提算法的可行性和优越性.
DeepFM:在因子分解机(FM)的基础上发展而来,将深度神经网络与FM结合,同时捕获了高阶特征和低阶特征,学习隐式特征交互从而预测用户行为.
FPMC:该算法是马尔科夫链与矩阵分解的结合.它为每个用户创建转移概率矩阵,一方面学习用户和项目偏好,另一方面为历史交互行为序列构建模型,通过线性方式将组合起来进行推荐.
WIDE &DEEP:Wide模块和Deep模块分别让模型具备较强的记忆功能和泛化功能.兼顾深度神经网络和逻辑回归的优势,能高效处理和记忆历史行为特征,同时具备较强的表达能力.
PNN:将用户特征、项目特征和辅助信息特征两两交互,提取特征间交叉信息,充分挖掘各特征间潜在信息.
DIN:使用注意力机制学习用户历史行为中的物品与当前商品广告的一个关联性,改善各个历史行为中每个项目平等性的限制,从而学习更有价值的用户兴趣偏好.
RUCF-NOATT:该算法不引入注意力机制,仅使用MF和两层GRU捕获长短期偏好.
3.3 评价指标
使用平均绝对误差(mean absolute error,MAE)和AUC(area under the ROC curve)指标评估算法的总体表现.MAE能够度量预测误差,而AUC能够度量算法的性能.MAE和AUC为:
(12)
(13)
式中:M为正样本数;N为负样本数;ranki为根据预测概率将样本从小到大排序后第i个正例所在位置.
实验使用深度学习框架:Anaconda Python 3.6.2+Tensorflow 2.0.0+Keras 2.3.1.在MovieLens-1M和Electronics数据集上分别设置BatchSize(一次抓取的数据数量)为64和128.同时设置Dropout层丢失率为0.5,使用交叉熵损失函数,Adam优化器进行训练,学习率设置为0.001.
3.4 实验结果
在模型训练中设置Early Stopping机制,即当验证集上Loss不再降低时停止训练,从而达到充分训练和避免过拟合的作用.实验取20次训练结果的最佳结果.
3.4.1 实验一
实验一是RUCF算法与其他经典算法在Movielens-1M和Electronics数据集上对比的实验,结果如表2、3.

表2 各个算法在AUC上实验结果比较
根据表2和表3可以看到RUCF算法在两个数据集上实现了最佳性能.与DeepMF算法相比较,RUCF算法在Movielens-1M数据集上AUC比DeepMF提高0.044 4,在MAE指标上比DeepMF低0.189 8.因为DeepMF并未使用序列信息进行兴趣提取,文中算法使用历史交互序列学习用户的兴趣变化表示,更能够提取更深层次的用户兴趣偏好,推荐效果更好.FPMC算法已经使用序列进行兴趣特征提取,因此,FPMC算法在MAE上比DeepMF算法有所下降.但仍存在局限性,FPMC算法只能根据已有历史序列进行推荐,缺少泛化能力.
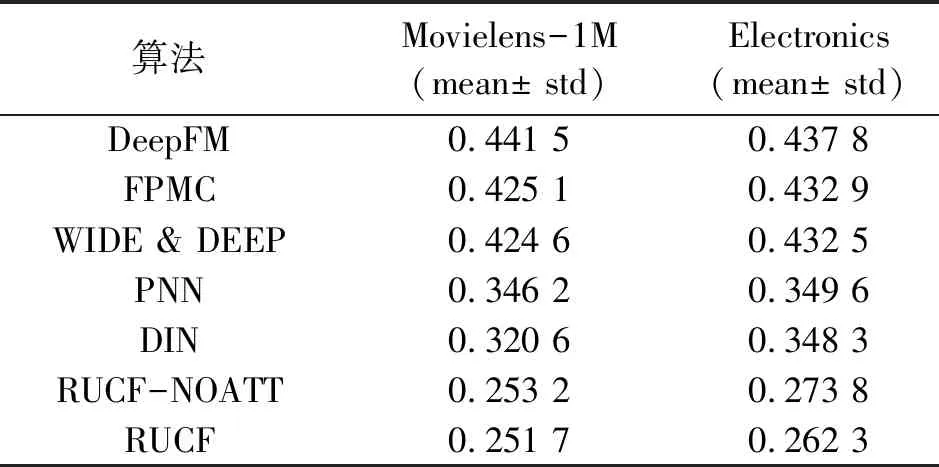
表3 各个算法在MAE上实验结果比较
文中算法使用深度学习自带的优势,即泛化能力强,表2中,RUCF在AUC上比FPMC算法要高0.040 7.WIDE &DEEP模型结合传统推荐算法和深度学习算法的优势,推荐效果有一定的提高,但是并未发掘用户历史序列中的潜在信息,如表3中WIDE &DEEP算法和PNN算法在MAE指标上能够达到0.424 6和0.346 2.PNN算法加强特征间的交叉能力,挖掘特征之间的关系,也能实现很好的推荐效果,但是也没有认识到序列信息的重要性,未考虑用户短期兴趣偏好对最终推荐的影响.
3.4.2 实验二
实验二是引入注意力机制与不引入注意力机制的对比实验.定义RUCF-NOATT为不引入注意力机制的RUCF算法,训练结果如图7、8.

图7 RUCF-NOATT上AUC变化趋势
从图7可以看出RUCF-NOATT在AUC上的变化,最高达到0.747 0.图8可以看出RUCF-NOATT在MAE上随迭代次数呈递减趋势的变化,最低达到0.253 2.
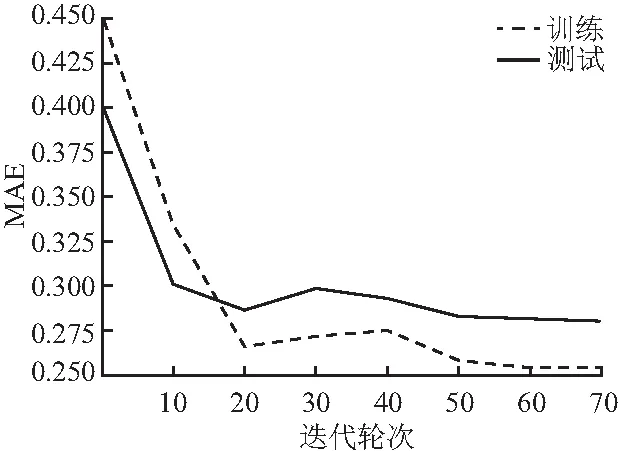
图8 RUCF-NOATT上的MAE变化
图9、10分别为RUCF在MovieLens-1M数据集上AUC和MAE随迭代次数变化.
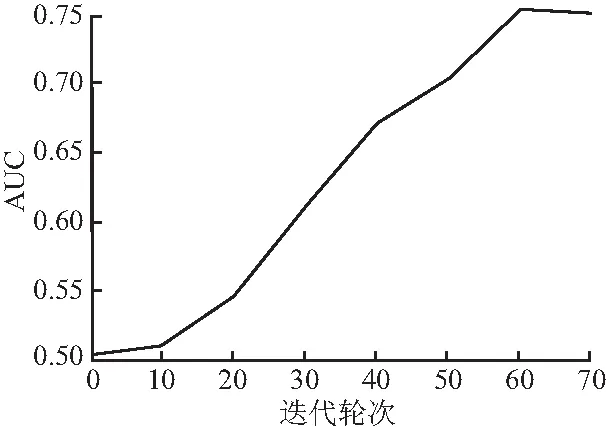
图9 在RUCF模型上AUC变化趋势
图9可以看出文中算法ACU最高可以达到0.765 8,图10可以看到MAE的变化趋势整体呈递减趋势,最低达到0.251 7.对比RUCF-NOATT算法与引入注意力机制的RUCF算法的实验结果得出,使用矩阵分解获取长期偏好与GRU提取短期偏好相结合,并将注意力机制嵌入GRU的方法,能够更敏感的挖掘有价值的兴趣偏好,有效增强泛化能力.
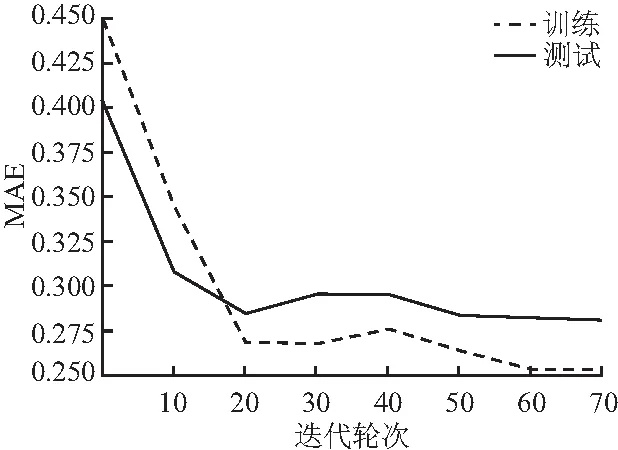
图10 RUCF模型上MAE变化趋势
文中提出的RUCF算法,不仅能学习长期兴趣特征,而且能深度挖掘历史行为序列中的潜在短期兴趣,从整体上提升算法性能.表2、3中,DIN算法在Movielens-1M数据集上AUC和MAE指标达到0.738 2和0.320 6,充分体现注意力机制的优越性,将其引入到深度学习会提高推荐性能.因此,在文中提出的模型中引入注意力机制,改进GRU网路的更新门结构,提取带有价值的权重信息,从而提高推荐质量,使RUCF在对比结果中达到了最高性能.
4 结论
现有的推荐算法无法有效学习用户历史行为序列中蕴含的潜在短期兴趣,不能发挥序列行为特征的重要作用.因此,提出了基于长短期偏好的自适应融合推荐算法RUCF来解决这一难题.RUCF算法包括长期和短期兴趣偏好提取两大核心部分.矩阵分解推荐算法以时间固定的方式捕获长期偏好.门控循环单元在用户历史行为的时间序列上捕捉动态兴趣,并结合注意力机制更敏感地表示兴趣演化过程.这样同时结合了用户动态兴趣偏好和长期兴趣偏好两部分信息,有效提高推荐准确性和性能.但是该算法的不足之处在于,将时间间隔看作均等,这似乎会影响推荐性能,如何设置时间间隔将作为后续的研究.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
文苑(2018年21期)2018-11-09
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
中国卫生(2015年9期)2015-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
中国卫生(2014年3期)2014-11-12
