
基于Transformer的自动驾驶交互感知轨迹预测
2023-10-09 01:56:40景荣荣吴兰张坤鹏
科学技术与工程 2023年26期
景荣荣, 吴兰, 张坤鹏
(1.河南工业大学电气工程学院, 郑州 450001; 2.河南工业大学机电工程学院, 郑州 450001; 3.清华大学自动化系, 北京 100084)
在可预见的未来,自动驾驶车辆将成为智能交通的重要组成部分,能够极大地改善人们的出行环境,具有十分重要的研究价值[1-2]。自动驾驶车辆在行驶过程中,需要及时、准确地预测周围交通参与者(如汽车、公共汽车、卡车、自行车、行人等)的轨迹,从而提前合理地规划自身的行驶路径,避免发生碰撞。因此,能否准确地预测周边其他交通参与者的运动轨迹是衡量自动驾驶技术安全性和可靠性的重要指标。在现实交通环境中,准确预测车辆的轨迹是十分困难的。因为车辆的轨迹不仅受到道路结构、交通信号、交通规则等先验知识的约束,还会不可避免地受到交通场景中其他交通参与者的影响。目前,中外研究者针对自动驾驶汽车的轨迹预测方法大致可以分为两类:传统预测方法和基于深度学习的预测方法。
传统的方法可以分为3类:物理方法、驾驶意图方法和交互感知方法[3]。物理方法将车辆视为受物理定律支配的动态实体,通常假设其速度或加速度恒定,然后通过动态模型[4]或运动学模型[5]预测车辆轨迹。驾驶意图方法假定车辆的运动对应于一系列的驾驶动作(如变道、保道、转弯、超车等),并独立于其他车辆执行。它们通常依靠两种策略来预测轨迹,即原始轨迹聚类和意图估计。前者通过基于集群的方法将未来的轨迹与先前观察到的轨迹相匹配[6]。后者则是先估计驾驶员的驾驶意图,然后相应地预测轨迹[7]。交互感知方法考虑了周围交通参与者对车辆运动的影响。因此,与基于物理和基于驾驶意图方法的模型相比,交互感知模型更加有效[8]。尽管传统方法在一些交通场景中展现出令人满意的性能,但由于建模能力有限,难以适用于复杂场景。
近年来,由于可以对大规模、复杂数据进行有效的建模,深度学习技术被广泛应用于各个领域[9-12],其优异的性能也在轨迹预测中得到了验证[13-16]。深度学习模型的性能取决于输入数据的类型和它的表征方法。基于深度学习,递归神经网络(recurrent neural networks,RNN)被用来预测城市交叉口的司机驾驶意图和未来轨迹[17]。一些研究也提出基于长短时间记忆(long short-term memory,LSTM)的轨迹预测方法[18],根据交通参与者的坐标、速度、大小和方向来预测其轨迹。这些方法将轨迹预测建模为序列生成任务,在预测轨迹的过程中仅考虑了目标交通参与者自身的运动,没有考虑与相邻交通参与者的交互。尽管目标交通参与者的历史轨迹能够为预测其未来轨迹提供不可或缺的运动信息,但由于忽略了周围其他交通参与者的影响,上述方法预测出的轨迹往往难以满足实际需要。为了轨迹预测过程中有效地考虑交通参与者之间的交互,学者们试图将目标交通参与者和周围交通参与者的历史轨迹同时作为预测模型的输入。例如,Alahi等[19]提出利用全连接的池化层对目标交通参与者及其周围一定数量的参与者的信息进行提取,进而提高预测准确度。Zhang等[20]提出使用卷积社会池化层来学习一定范围内交通参与者之间的交互信息。这些模型在进行轨迹预测的过程中只考虑了固定数量的交通参与者之间的交互。由于现实场景中交通参与者的数量是动态变化的,因此上述模型无法对交通环境的动态性进行有效地建模。
近来,一些研究尝试将交通场景构建为交通图来解决上述问题。交通图的节点和边分别表示交通参与者及其交互关系。例如,Diehl等[21]利用图神经网络(graph neural networks,GNN)对交通图进行运算,进而预测交通图中交通参与者的轨迹。Li等[22]提出了一个基于图卷积网络(graph convolutional networks,GCN)和门控递归单元(gated recurrent units,GRU)的交互感知模型。该模型通过GCN对交通图进行学习来捕捉交通参与者之间的交互,最终使用GRU来同时对多个交通参与者进行轨迹预测。然而,由于不能区分周围交通参与者的影响程度,这些基于图的方法并不能有效地捕捉交通图中最关键的交互。此外,这些方法也未能考虑周围道路基础设施(如道路几何和交通信号)对交通参与者运动轨迹的影响。
考虑到道路基础设施的对轨迹预测的影响,学者们探索在具有详细道路信息的栅格化鸟瞰图上勾画交通参与者的历史轨迹[23-24]。Djuric等[23]将交通参与者和周围环境信息编码到鸟瞰图中作为卷积神经网络(convolutional neural network,CNN)的输入,并利用池化层提取有用特征。然而,使用池化层往往会遗漏交通场景中有价值的信息。Liu等[24]通过堆叠多个Transformer网络,提出mmTransformer模型用于预测交通参与者的轨迹。在该模型中,历史轨迹和道路信息被输入到不同的Transformer单元。通过定制的特征提取器,它可以分层次地整合不同的环境信息。虽然这种结构可以有效地提取目标的历史轨迹和周围环境的特征,但这种分层结构增加了模型的计算复杂性,需要更多的推理时间。
为了解决上述问题,现提出一种基于改进Transformer的交互感知轨迹预测方法,用于对自动驾驶车辆周围交通参与者的运动趋势进行估计并输出相应预测轨迹。将轨迹预测对象建模为交通智能体,构建了轨迹预测Transformer(trajectory prediction transformer,TPT)模型。首先将包含交通智能体的历史运动轨迹和周围交通环境信息的道路信息图作为TPT模型的输入。然后,利用改进的Transformer对交通环境进行建模,并捕捉交通智能体与交通环境之间的交互信息,预测其未来运动轨迹。在注意力机制的帮助下,TPT模型可以捕捉最值得注意的交互信息,以提高模型的预测性能和可解释性。最后使用Lyft数据集[25]进行数值实验,验证TPT模型的有效性。
1 模型建立
1.1 问题构建
轨迹预测可以被表述为这样一个问题,即基于交通智能体的历史轨迹和来自周围交通参与者和道路基础设施的时空交互来估计交通智能体的未来位置。具体来说,让V表示交通场景中观察到的交通智能体的过去特征。公式为
V=[v1,v2,…,vt,…,vT]
(1)
式(1)中:t=1,2,…,T,为时间节点;vt=(xt,yt,ot);xt和yt为交通智能体在t时刻的位置坐标;ot为其他属性(如车辆的长、宽、高、车头朝向等)。
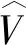

图1 Lyft数据集可视化
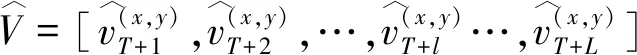
(2)
1.2 轨迹预测Transformer模型
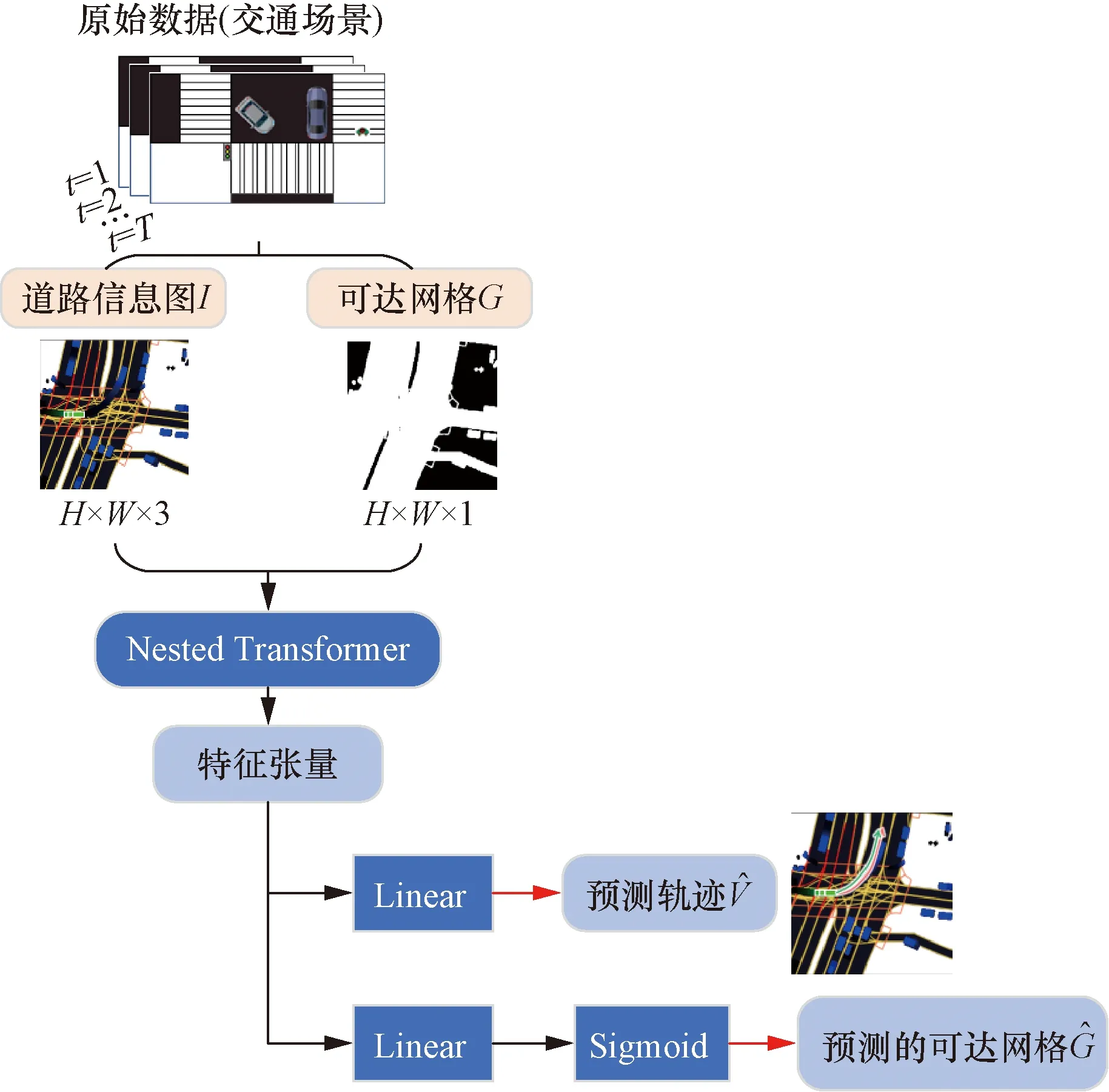
图2 TPT模型结构

(3)
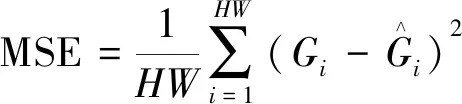
(4)
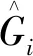
1.3 Nested Transformer
图3所示为3层架构的Nested Transformer。可以看出,Nested Transformer的第i层的嵌套将整张图像分成(2i)2个小块,i=1,2,…,Tl,Tl为总层数。Nested Transformer利用不同的层次结构对道路信息图和可达网络进行特征提取。在图3中,道路信息图I和可达网格G作为模型的输入,随后被分割成(H×W)/(S×S)个图像补丁。每个大小为S×S的图像补丁被线性投影到向量空间中的一个嵌入。然后,所有的嵌入都被划分为块,作为Transformer的输入x。该过程可以表示为
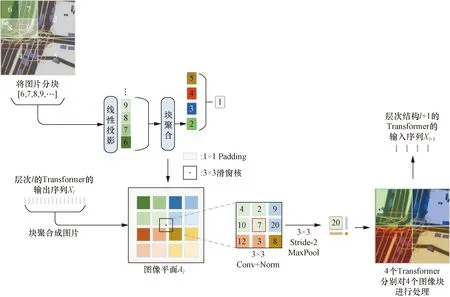
Padding、Conv、Norm和 Stride-2 MaxPool即填充、卷积、归一化和步长为2的最大池化操作
x=Block[PatchEmbed(I,G)]
(5)
(6)
x′=LN(x)
(7)
y=x+MSA(x′,x′,x′)
(8)
x″=y+FFN[LN(y)]
(9)
式中:y为单个图像块x经过Transformer处理所提取的特征。
由于所有块在同一个层次结构中共享参数,Nested Transformer可以对所有块并行运算MSA,增加了运算效率。在TPT中,Nested Transformer利用MSA捕捉交通智能体周围值得注意的不同类型的交通参与者,并提取它们的交互信息。
与其他Vit不同的是,Nested Transformer采用层间块聚合实现相邻图像块之间的信息耦合和通信。在块聚合步骤中,通过卷积和池化等简单的空间操作实现全局信息的通信和融合。
Aggregate(y,i)=Block×
{Conv×Norm×MaxPooli[Unblock(y)]}
(10)
式(10)中:Aggregate为块聚合操作;Unblock为图像块合并操作。
图3的下半部分是Nested Transformer块聚合操作的具体过程,结合式(10)可以看到,首先层次结构l的输出Xl经过Unblock操作以填满图像平面Al,随后对降采样特征映射应用空间操作,最后使用Block操作将特征映射回Xl+1,用于层次l+1。可以看到,经过块聚合后,每一层的图像块总数减少为最初的1/4,直到在顶层减少到1。在图像平面上执行的Conv、Norm和MaxPool操作允许上层的不同图像块之间进行通信。采用分层嵌套结构,仅利用局部注意力,Nested Transformer就能具备较高的计算效率和较好的收敛性,从而缩短了轨迹预测模型的推理时间。
2 实验与分析
2.1 数据集来源
为了对所提方法进行评价,使用Lyft自动驾驶数据集。该数据集是迄今为止最大的自动驾驶运动预测数据集,拥有1 118 h的数据。这是由20辆自动驾驶汽车组成的车队在4个月的时间里收集的,这些汽车在加州帕洛阿尔托的郊区路线上行驶了超过2.6万km。它由17万个场景组成,每个场景持续25 s,包含自动驾驶汽车附近车辆、自行车、行人的精确位置、大小和移动时间。该数据集包含该地区详细的高清语义地图,包含15 242个标记元素,包括道路规则、车道几何形状和其他交通元素。为了进一步帮助预测,该数据集还提供了该地区的高分辨率航空地图,覆盖了74 km2。此外,交通场景中红绿灯的变化也包含在Lyft的数据集中。
Lyft数据集的每条轨迹被分割成8 s的序列,其中前3 s作为历史观测轨迹,其余5 s作为真实轨迹,预测交通智能体未来5 s的轨迹。Lyft的训练数据集包含超过13.4万个场景,用于训练提出的TPT模型。为了确定最佳超参数,随机选择训练数据集的10%作为验证数据集。TPT模型的性能通过验证数据集进行验证,该数据集包含1 100个场景。
2.2 评价指标
评价指标采用平均位移误差(average displacement error,ADE)和最终位移误差(final displacement error,FDE)。其中DEt为t时刻真实轨迹坐标与预测轨迹坐标之间的欧氏距离,计算公式为
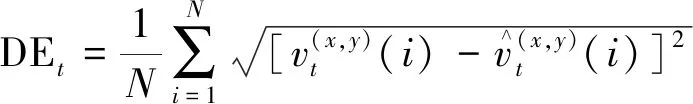
(11)
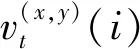
所有预测步长的真实坐标与预测坐标之间的平均欧氏距离ADE为
(12)
预测时间步T+L的真实坐标与预测坐标之间的平均欧氏距离FDE为
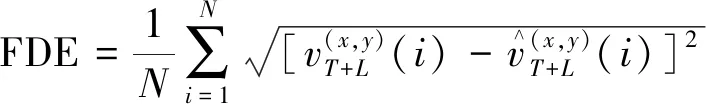
(13)
2.3 模型比较
引入几种现有的轨迹预测方法,并与所提出的TPT模型进行比较,验证模型的有效性。
(1)Constant Velocity(CV):CV模型认为交通智能体的状态不随时间的变化而变化,没有考虑来自其他交通智能体的影响。
(2)LSTM:利用基于LSTM的编码器-解码器结构,该模型利用交通智能体的历史轨迹,预测未来轨迹。该模型在预测过程中考虑了交通智能体的状态在时间维度中的演进,未能考虑来自其他交通参与者的影响因素。
(3)Conv-LSTM:Conv-LSTM模型利用卷积神经网络从交通图像中提取历史轨迹特征,然后利用LSTM进行轨迹预测。
(4)Conv-attn-LSTM:在Conv-LSTM的基础上,Conv-attn-LSTM引入注意力机制来捕获交通场景中值得注意的交互。
(5)Conv-attn-GRU:将Conv-attn-GRU模型中的LSTM块替换为GRU块。
(6)TPT-ORIG:TPT-ORIG模型使用原始的Transformer从交通图像中提取特征,其输入和输出和TPT模型相同。
如表1所示,以ADE和FDE为评价指标,与现有方法相比,TPT取得了最准确的预测结果。由于缺乏考虑交通状态的时间相关性和交通场景中不同交互作用,CV模型的预测结果最差。与CV模型相比,LSTM模型考虑了交通智能体的交通状态随时间变化的特性,获得了更准确的轨迹预测结果。与LSTM模型相比,Conv-LSTM模型考虑了周围环境和其他交通参与者的影响,取得了更好的预测表现。Conv-attn-LSTM模型利用注意力机制捕获交通场景中值得注意的交互作用,提高了轨迹预测准确度。Conv-attn-GRU模型的性能略优于Conv-attn-LSTM模型。相较于Conv-attn-LSTM模型,两种基于Transformer的模型(即TPT-ORIG和TPT)取得了更好的预测结果。与TPT-ORIG相比,TPT模型的预测准确度得到了较大的提升。这表明相较于原始的Transformer,Nested Transformer的分层嵌套结构具有更好的性能,使得TPT不仅可以有效地捕获车辆与车辆之间的交互,还可以有效捕获车辆与基础设施之间的交互,从而提高其预测准确度。

表1 模型预测结果对比
此外,推理时间是衡量轨迹预测模型能否成功应用于实际工业场景的重要指标。表1中还展示了7个模型的推理时间。以预测1 000个交通智能体的未来轨迹为例,CV模型所花费的时间为0.85 s,是所有模型中最短的。这是因为CV作为传统的预测模型在预测过程中认为交通智能体的运动状态不随时间变化,并且不考虑其他因素的影响,所需的计算量远低于深度学习模型。TPT模型只花费1.78 s,远少于其他深度学习模型。这表明在Nested Transformer的帮助下,TPT模型具有更好的计算效率,可以显著减少推理时间。
2.4 模型分析
2.4.1 实验1:预测结果可视化
图4显示了TPT和TPT-ORIG在3种不同驾驶场景下对单个交通智能体的预测结果。在预测场景中,交通场景中的一个交通智能体被视为目标交通智能体,将道路信息图I、可达网格G和历史轨迹R作为模型输入对其未来轨迹进行预测。然后,利用l5kit软件包提供的坐标变换功能,将预测的轨迹绘制成图。可以看出,TPT可以准确地预测交通智能体在各种驾驶情况下的未来轨迹。相比于TPT-ORIG模型,基于改进的Nested Transformer的TPT模型能够更准确地预测交通智能体的轨迹,表明了Nested Transformer相较于原始Transformer的优势。图5为TPT多车交通场景的预测结果可视化,该交通场景中的每个交通智能体被视为目标交通智能体。可以发现,TPT模型能够准确地预测该交通场景中每个交通智能体的未来轨迹。
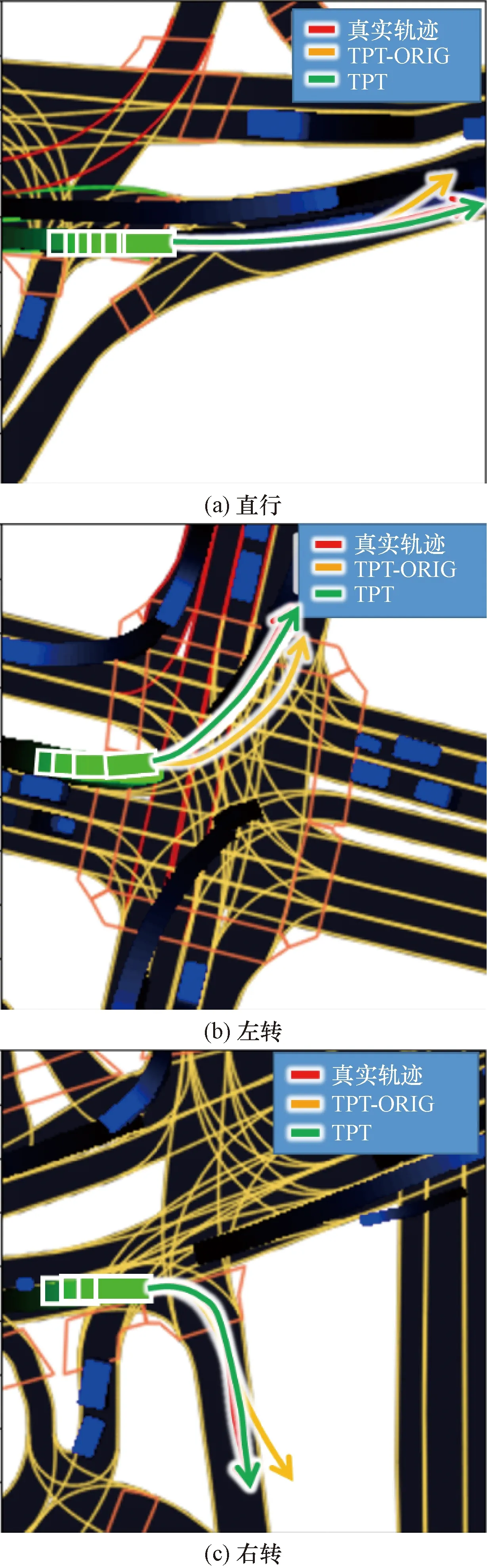
红色曲线代表真实轨迹;黄色曲线代表TPT-ORIG预测的轨迹;绿色曲线代表TPT预测的轨迹

图5 多车交通场景的预测结果可视化
图6为TPT在原始Transformer和Nested Transformer下的训练过程。可以看出,相比于使用原始的Transformer,使用Nested Transformer的TPT模型具有更好的收敛性能和更高的预测精度。这表明相较于原始的Transformer,Nested Transformer的分层嵌套结构使其具有较高的计算效率和较好的收敛性,可以帮助TPT模型在更短的时间内更准确地预测交通智能体的未来轨迹。
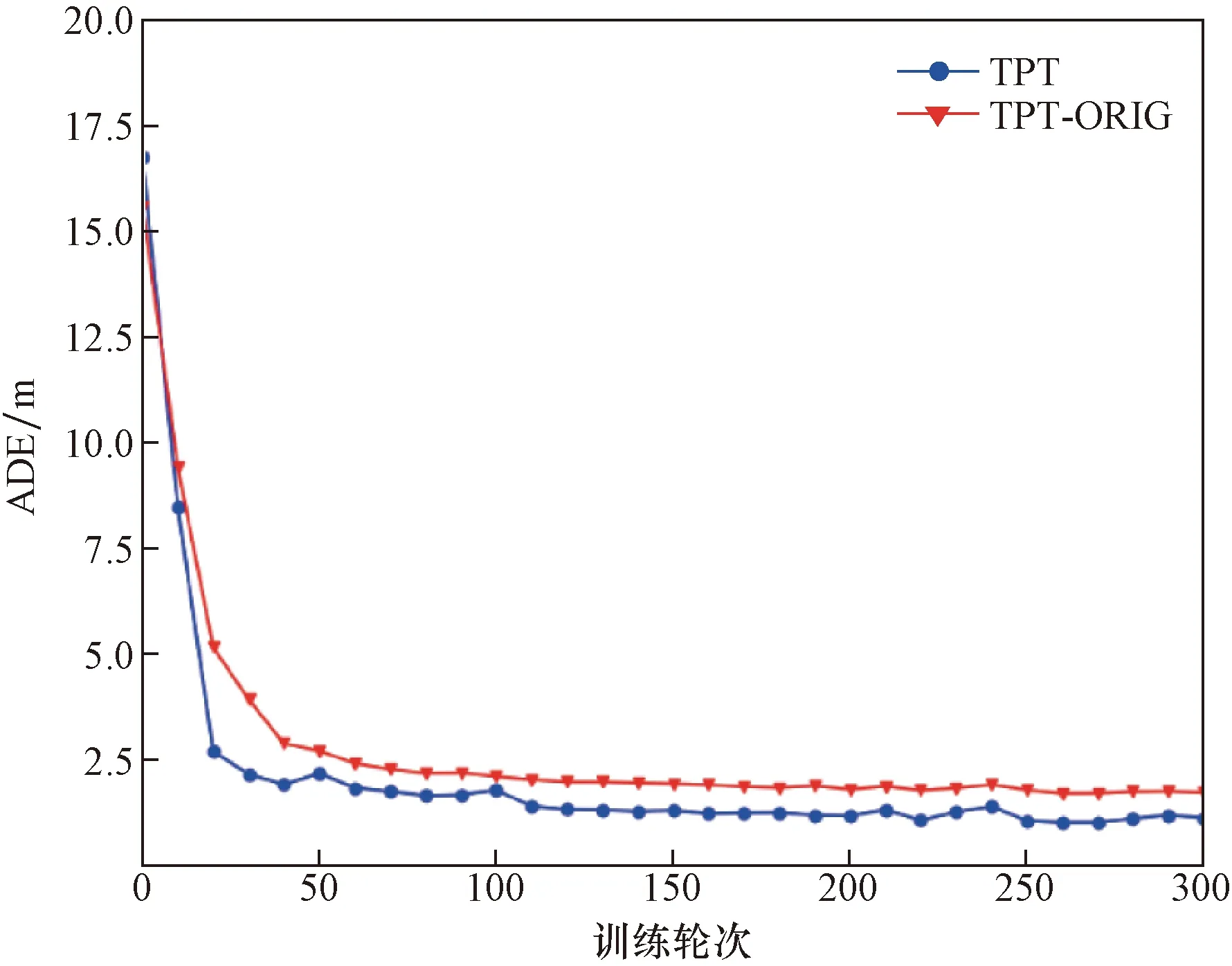
图6 基于原始Transformer和Nested Transformer的TPT训练过程
2.4.2 实验2:TPT的注意力图
利用注意力机制捕捉交通智能体周围值得关注的交互是TPT模型主要的优点。图7是TPT在预测交通智能体直行和右转时未来轨迹的注意力图,不同的颜色深度表示不同的关注度。从图7可以看到,无论是直行还是右转,TPT模型在预测未来轨迹的时候,都会给与交通智能体的历史轨迹极大的关注,同时也会关注周围移动的交通参与者。不同的是,在右转的情况下,TPT会给与周围移动的交通参与者更多的关注。这也符合现实情况,在现实交通场景中,人类驾驶员在判断周围车辆走向时,会关注该车辆的历史轨迹。在直行时无需过多的关注周围的车辆,而在进行转向时,则要对周围移动的车辆给予足够的关注,然后对车辆进行及时的调整以避免碰撞。实验表明,在注意力机制的帮助下,TPT可以在不同驾驶情况下有效地捕捉交通智能体周围最值得注意的交互,并准确地预测其未来轨迹。

图7 TPT的注意力图
2.4.3 实验3:交通图像类型
Lyft的数据集以不同的形式提供地图,包括卫星图和道路信息图。还可以将卫星图和道路信息图整合起来,从而得到交通环境图。表2显示了使用道路信息图的TPT模型获得了预测性能。当TPT模型使用卫星图作为输入时,它的性能比使用交通环境图和道路信息图时差。这可以解释为,卫星图只包含道路信息,没有交通信号。道路信息图包含道路几何形状和交通信号等信息,并排除了不必要的信息,使其成为最佳选择。
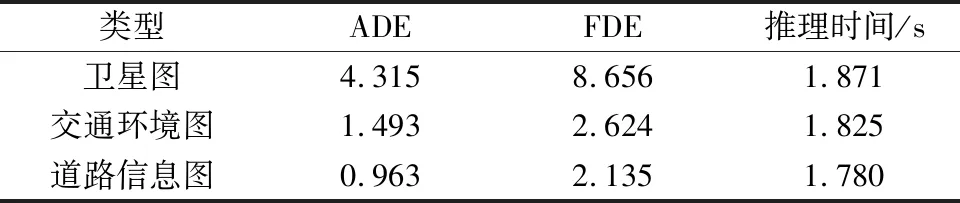
表2 使用不同类型交通图像的TPT性能比较
2.4.4 实验4:交通信号
在Lyft数据集中,车道边缘颜色代表交通信号,当交通信号发生变化时,车道边缘颜色也会发生变化。红色的车道边表示此时该车道为红灯,绿色的车道边表示此时该车道为绿灯,黄色的车道边代表黄灯。图8展示了交通信号对TPT性能的影响。在图8(a)中,当前车道显示绿灯表示可以行驶时,TPT模型可以提供合理的预测结果。在没有交通信号信息的情况下,图8(b)中TPT对轨迹的预测具有较大的随机性,导致预测结果不够准确。这是因为在注意力机制的帮助下,TPT可以有效地关注到交通智能体周围包括交通信号在内的值得注意的交互(实验2中已经进行了论证)。因此,TPT也可以有效地将交通信号对轨迹预测的影响纳入考虑中。
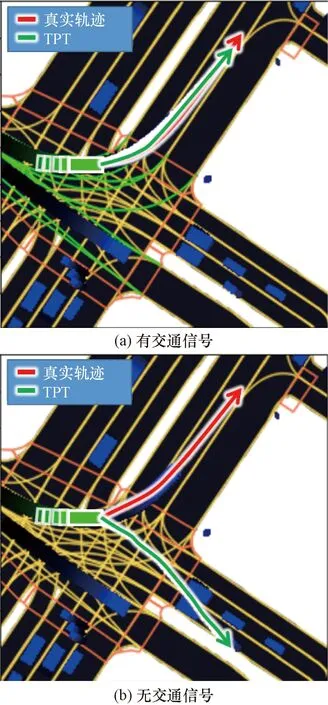
图8 有无交通信号的预测结果
2.4.5 实验5:突然出现的交通参与者
本次实验旨在检验模型对交通场景中突然出现的交通智能体的预测能力。事实上,这对于轨迹预测模型在实际中的应用是非常重要的。在一个十字路口内,分别使用1 s和2 s的历史轨迹来预测交通智能体的5 s未来轨迹。预测结果如图9所示。可以发现,即使只有1 s的历史轨迹,交通智能体的未来轨迹也是可以被预测的。如图9(b)所示,在有2 s历史轨迹的情况下,TPT模型的预测结果更加准确。

图9 对突然出现的交通参与者的预测结果
2.4.6 实验6:可达网格
为了提高模型的预测性能,将可达网格作为模型的先验知识,然后计算网格损失。网格损失迫使模型关注车道覆盖的交通区域。3种不同情景下的预测结果如图10所示。可以发现,可达网格的引入显著提高了预测准确度。

图10 在有无可达网格的情况下TPT预测结果的可视化
2.4.7 实验7:历史观测轨迹
为了验证历史观测轨迹长度对预测精度的影响,通过使用不同长度的历史观测轨迹来进行预测。实验结果由图11可知,当输入为3 s的历史观测轨迹时,模型的预测精度最高。随着历史观测轨迹长度的增加,模型的预测精度随之下降。因此可以知道,在一定范围内增加历史观测轨迹长度可以相应提高模型的预测精度,而超过这个范围则对提高模型的预测精度没有帮助。同时也可以知道,预测交通智能体的未来轨迹只与一定时间长度的历史观测轨迹有关。
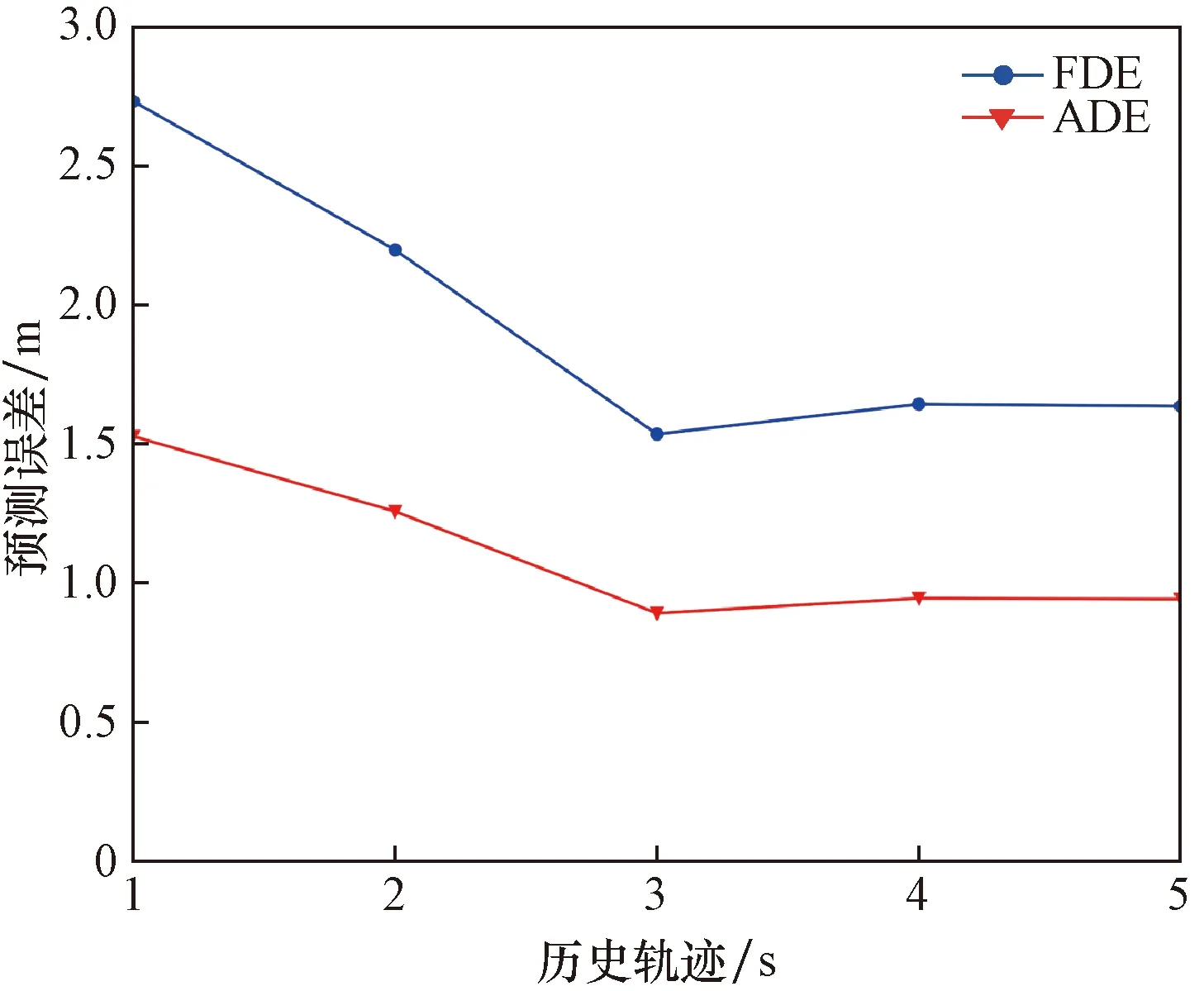
图11 TPT在不同长度历史轨迹下的预测结果
3 结论
在考虑道路几何信息和交通参与者之间的交互信息的情况下,提出了TPT模型来实现自动驾驶车辆的轨迹预测。将包含历史轨迹和周围环境信息的多通道图作为输入,利用改进的Nested Transformer对交通环境进行建模,有效地考虑了车辆之间的交互以及车辆与基础设施之间的交互。在公开的自动驾驶数据集Lyft上的实验结果表明,与现有方法相比,TPT在所需推理时间更短的情况下获得了更好的预测结果。得出以下结论。
(1)将交通智能体的历史运动轨迹和周围交通环境信息整合到多通道图中作为输入,利用改进的Nested Transformer有效地建模来自环境的时空交互,从而准确地预测交通智能体的未来轨迹。
(2)利用注意力机制,TPT模型可以捕获周围环境中最值得注意的交互作用,从而提高了性能,改善了模型的解释性。
(3)将道路信息图处理后得到的可达网格图作为先验知识输入到模型中,引导TPT模型学习道路信息图中的可行驶道路区域,提升了TPT的预测精度。
(4)在未来的工作中,探索将TPT模型扩展到同时对多个交通智能体进行轨迹预测,进一步提升预测的效率。此外,TPT模型仅对交通智能体进行了单模态轨迹预测。考虑到轨迹预测的多模态性,将对TPT模型进行改进,使其能够为交通智能体提供多条可能的预测轨迹。
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23 13:46:18
童话世界(2020年32期)2020-12-25 02:59:14
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
现代营销(创富信息版)(2018年10期)2018-10-12 03:01:28
小学生导刊(2018年16期)2018-07-02 09:20:52
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
华人时刊(2016年13期)2016-04-05 05:50:03
计算机工程与应用(2013年18期)2013-07-20 07:55:26
