
一种基于Lexicon-CBOW 命名实体简写识别技术*
2023-09-29 05:51朱小龙周从华
计算机与数字工程 2023年6期
吴 健 朱小龙 周从华
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
命名实体识别[1~2]是一项基础且关键的任务,其工作是对文本中有特殊意义的词语进行标注。命名实体识别广泛应用于问答系统、机器翻译、信息提取等众多自然语言处理(Natural Language Processing,NLP)任务。
Rau[3]等于1991 年最早提出了命名实体识别任务,早期命名实体识别任务采用基于词典与规则的方式,在此期间,命名实体识别的发展主要受限于词典的大小与质量。基于规则的方法主要的缺点在于需要手工制定规则,并且不能实现领域迁移。传统的机器学习模型,如隐马尔可夫模型(Hidden Markov Model,HMM)[4],最大熵(Maximum Entropy,ME)[5]、条件随机场(Conditional Random Fields,CRF)[6]等将命名实体识别看成序列标注任务。基于统计的机器学习模型对语料要求较为严格,不同的特征选择与组合对模型的性能影响较大。在深度学习领域,Collobert[7]等首次将神经网络与命名实体结合,Hammerton[8]等最早将长短时记忆网络(Long Short Term Memory,LSTM)模型应用于命名实体识别,并取得了良好的效果。Lample[9]等结合LSTM与CRF对句子进行建模抽取实体。
相比于英文的命名实体识别,由于中文语句的连贯性、词义多样性,导致中文命名实体识别边界更加模糊、识别更加困难。
俞鸿魁[10]等提出了基于隐马尔可夫的中文命名实体识别,冯元勇[11]等提出了基于改进CRF的中文实体识别算法。
目前命名实体识别的研究偏向于通用领域,由于数据特点的原因,通用领域的命名实体识别模型应用于很多专业领域其识别准确度并不高。例如,在生物医学领域,未看到的生物医学实体提及的数量(如疾病名称、药品名称),以及临床记录等。其数据缺失或数据不规范,导致识别困难,识别准确率不高。在社交媒体领域,易黎[12]等提出基于联合模型的中文社交媒体命名识别在微博数据集实现了74.63%的名词实体识别准确率。魏笑[13]等使用部件CNN 在网络安全数据集得到了90%以上的准确率。
其中实体简写的问题在很多领域都有涉及,例如在高中升学规划领域,自然语言中同一个学校或者专业名可能存在多个同义简写表达。例如计算机科学与技术专业、南京大学,通常被简称为计科、南大等等。其中简写问题可以分为截断简写与缩略简写两类,截断简写是指截取实体的某一连续部分表示实体,例如同济大学简称为同济;缩略简写是指抽取实体的不连续部分来表示实体,例如哈尔滨工业大学简称为哈工大。
目前命名实体识别应用最广泛的架构分为词向量层、特征提取层及输出层。其中词向量层通常采用word2vec训练的词向量,特征提取层广泛采用统计与深度学习相结合的双向长短期神经网络接条件随机场模型。在实验中我们发现对于实体的简写识别此模型效果有限,主要原因在于词向量训练语料来源于结构化网站的结构化信息,文本表达较为规范。而简写实体由于实体的不完整性,其给定的词,与待预测的词与规范实体训练的情景不一致,因而将其训练的词向量用来表示简写实体,会存在概率偏差,因此本文考虑在词向量的表示上进行改进,从而更好地支持简写实体识别。
2 相关工作
2.1 命名实体识别模型
命名实体识别模型结构如图1 所示,首先在词向量层会将语料表示成向量编码的形式,词的向量化表达能够有效减少数据的维度,加快运算速度;将向量化表达的文本输入到特征提取层,由机器学习或深度学习模型对输入的信息进行特征提取;最后将提取的特征输入到输出层进行标签预测。

图1 命名实体识别模型结构
图1 中为word2vec 训练的词向量作为词向量层,双向长短期记忆网络接条件随机场作为特征提取层,经过最大化条件概率作为输出层的命名实体识别模型结构。
2.2 Word2vec-BiLSTM-CRF模型简介
Word2vec-BiLSTM-CRF模型主要包括Word2vec训练的词向量层,BiLSTM 的特征提取层以及CRF的序列标注。
2.2.1 Word2vec词向量
由于机器学习的模型都是数字输入,向模型直接输入文本不便于模型对文本之间的关系进行学习。将文本变为向量表示[14],可以简化文本的表达形式,方便文本在计算机模型上进行运算。
早期使用词袋模型对文本进行向量表示,即每一个单词对应一个编码,编码长度与词典中单词个数相等。词袋模型的向量维度大小与词典大小成正相关,向量的稀疏表示造成极大的空间资源浪费,并且独热编码无法度量单词之间的关系。
Yoshua Bengio 最早于2003 年提出了基于神经网络的方法来训练词向量[15],但是限制于机器硬件与方法并未成熟等原因,这些编码方法并未得到大规模应用。直到谷歌于2013 年推出了word2vec 词向量训练工具[16],其中包括跳字模型(skip-gram)和连续词袋模型(continuous bag of words,CBOW),文本的向量表示得以快速发展。
skip-gram 利用当前词来预测上下文。由给定的中心词通过条件概率计算来预测中心词的上下文(背景词)。
在CBOW 模型中,则是已知词w的上下文Context(w),需要预测w,对于给定的词w就是一个正样本,其他词是负样本,给定一个正样本(Context(w),w),我们希望最大化训练文本中每个单词的概率和g(w)。如图2 所示,给出待预测词“滨”,其上下文分别文“哈尔”、“工业”,我们逐个计算每一个字在其上下文下的条件概率g(w),其公式如下:
其中,单个单词的概率计算公式为
2.2.2 BILSTM特征提取
LSTM 最早由Sepp Hochreiter 和Jürgen Schmidhuber 于1997 年提出[17],Graves[18]等在2005 年提出了改进的双向LSTM 模型,由前向LSTM 与后向LSTM组成。LSTM由于其设计的特点,非常适合用于对语音数据,文本数据等时序数据的建模。由于序列标注任务需要对上下文进行建模,来理解不同语义下词语的含义,因此LSTM 在序列标注任务中得到了广泛应用。
LSTM 主要由记忆单元链接组成,单个记忆单元如图3 所示。单个记忆单元主要组成包括输入门,遗忘门,输出门和单元,我们将训练集的输入语句用向量表示成L=(x1,…,xm)输入到LSTM 的门单元,LSTM各门单元计算公式如下:

图3 单个LSTM记忆单元
其中,σ为激活函数,i,f,o,c分别表示输入门,遗忘门,输出门和单元,各门单元向量维度大小与隐藏层向量h维度一致。
2.2.3 CRF序列标注
LSTM在序列标注时认为当前时刻的输出仅与当前状态有关,忽略了当前输出标签与上一时刻输出标签之间的联系,因此无法对标签转移关系进行建模。
CRF是一种典型的判别式模型,它在观测序列的基础上对输出目标进行建模,重点解决序列标注的问题。对于给定观察序列的整个标签序列的联合概率,CRF 有一个单指数模型。因此,不同状态下不同特征的权值可以相互交换。因此解决了MEMM(Maximum entropy Markov models)[19]等模型使用前一个状态指数模型导致的标签偏移问题。将LSTM 的输出作为CRF 的输入,CRF 条件概率计算公式如下:
其中,tj(yi+1,yi,x,i)是定义在观测序列的两个相邻标记位置上的转移特征函数,sk(yi,x,i)是定义在观测序列的标记位置i上的状态转移特征函数,tλj和uk为参数,Z为规范化因子。
3 我们的工作
3.1 问题的提出
利用目前应用最广泛的基于深度学习的模型将实体向量化表达,经长短期神经网络训练输入条件随机场,用于计算各标签得分的概率分布来进行序列标注,可以在一定程度上缓解输入错误与未出现的实体造成的识别错误问题。但在基于BiLSTM-CRF 模型的实体序列标注训练过程中,实体的状态转移概率起着较为重要的作用,简写的实体与规范的实体状态转移概率不一致,因此在预测简化表达的实体时可能会产生错误标注。
3.2 解决方案
此模型在解决简写实体的序列标注时能力有限,原因在于预训练的语料来自于百度百科等结构化网站,缺乏简写实体的信息,词向量训练中不能够有效模拟简写导致训练的词向量不能够有效表示简写;在此基础上提取的特征向量在表示简写实体时输入到特征提取层会出现状态转移概率偏差,从而影响序列标注的正确性。我们针对此改进了CBOW 词向量训练模型,使得模型能够模拟简写实体的情况,从而使实体的向量表示更贴合实际情况,使得经训练得到的转态转移概率更符合含有简写实体的情况,最终提高命名实体识别准确率。
本文针对简写问题的特点,对词向量的训练模型进行了改进,在训练词向量的过程中使用规范化词典来对训练语料进行标注,对训练语料添加了标签信息,将能够匹配词典的字标签信息标为“1”,不能匹配的标签标为“0”;进一步地我们将标签为“1”的进行分词,例如“哈尔滨工业大学”会被分为(哈尔滨,工业,大学),我们对标签进行细化,如{(1,1,1),(2,2,2),(3,3)},在训练过程中我们会对非“0”标签的上下文进行遮掩操作,从而模拟简写的情况。实验结果表明,改进的算法模型在命名实体识别任务中,能够更好地识别简写实体,从而取得更高的准确率。
3.3 Lexicon-CBOW模型介绍
模型结构如图4 所示。首先我们会将可能存在简写的实体e 加入到待匹配的实体库M,在训练时,我们首先对输入语句L={w1,w2,w3,w4…}的每一个字增加flag=0 的初始标签,训练时我们将实体与语料进行匹配,i,j分别表示实体在语料中的起始位置与结束位置,我们定义成功匹配的标签如下:

图4 Lexicon-CBOW词向量模型
为了保证缩略简写与截断简写两种情况的发生,我们进一步地将实体e=(wi…wi+j)按照词语分词再次切分为e=(wi…wi+m,…,wi+n…wi+j),对不同的分词标签细分为
在训练过程中分为两种情况,第一种为有20%几率同时抹除“1”之后的同种标签的字,我们称之为“全标签遮掩”;第二种为对各种标签中部分字遮掩,但每种标签仍然保留第一步操作,我们定义在一条输入语句L中两种遮掩方式互斥。其公式如下:
其中lexicon表示实体库,context(e)表示语料库中的规范实体。
4 实验部分
4.1 实验数据集
本文的实验语料与数据来自于高校官网、百度百科以及升学规划团队提供的家长在高中升学规划阶段所询问的问题记录。问题中在大量简写实体,在对数据进行整理、清洗、增强之后,我们得到的训练数据与测试数据量如表1 所示。 实体类别与各类别实体数量如图5 所示。由于领域特殊性,升学规划领域实体不存在单字符命名实体,故采用B-I-E-O方法标记,命名实体标签如表2所示。

表1 训练数据集

表2 命名实体标注方法

图5 实体数目
4.2 超参数设置
Python版本为3.6.3,Tensorflow版本为1.6.0,本文模型部分实验参数设置:词向量窗口大小为3,词向量维度为64,全局学习率(learning_rate)为0.002,训练语料最大长度(sequence_len_pt)为100,BILSTM层dropout值(lstm_dropout_rate)为0.2,BILSTM 与全连接层之间的dropout 值(dropout_rate)为0.5,全连接层正则化率(l2_rate)为0.001。以上参数设置均为实验调参过程得到的最佳结果。
4.3 评价指标
本文采用正确率P、召回率R 和F1值作为评价指标:
4.4 实验结果
本文的词向量语料库来源于高校首页及阳关高考网。为了测试本文所提方法对简写实体识别的有效性,本文设置了词向量层基于CBOW 模型、Skip-gram 模型与改进的Lexicon-CBOW 词向量模型作为对比,特征提取层为BiLSTM-CRF。结果如表3所示,其中下标为P的表示规范实体,下标为N的表示简写实体。
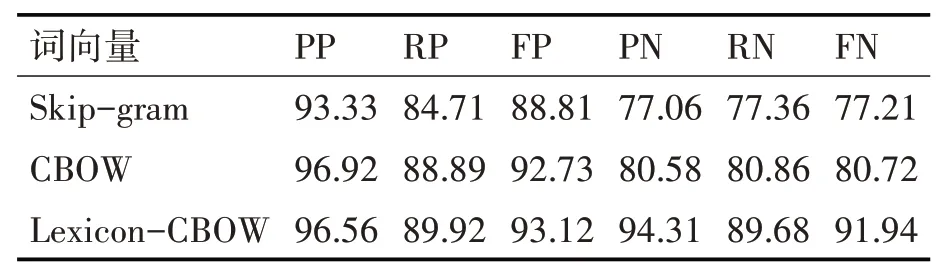
表3 实验结果
4.5 实验结果分析
从实验结果可以看出,我们的词向量模型在简写实体的准确率、召回率与F1 值上与基于skip-gram,CBOW模型相比均有大幅提高。证明了Lexicon-CBOW模型在模拟简写实际情况上训练出的词向量能够更加贴合简写的实际情况,训练出的词向量能够对简写实体有着更加准确的表示。测试集合用新的简写向量表示输入到特征提取层,特征提出层能够学习到更加贴近简写实际情况的状态转移特征,减少简写实体的标注错误。
5 结语
中文命名实体识别应用广泛,本文提出的在给定词预测目标词的基础上,引入了实体标签信息的词向量模型能够有效提高实体的简写识别准确率,将其应用到简写较多的领域如高中升学规划,以支持例如问答系统、信息提取方面的工作,可以有效提升系统的性能。下一步的工作是进行实体消歧[20],区分两个表达完全相同,含义不同的简写实体,以更好地支持实体简写识别。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
电子制作(2018年19期)2018-11-14
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
自动化学报(2017年11期)2017-04-04
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
噪声与振动控制(2015年4期)2015-01-01
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
