
基于卷积神经网络的交通标志识别方法研究*
2023-09-29 05:51袁穆佳惠
计算机与数字工程 2023年6期
袁穆佳惠 陈 晓
(陕西科技大学电子信息与人工智能学院 西安 710021)
1 引言
2020年2月疫情来袭,在武汉多地都使用了无人智能化汽车来进行喷洒消毒液、运送物资等工作,对于严重的疫情的地区而言,无人汽车的使用大大降低了防疫工作人员的操作风险,在由Future Today Institute 发布的《2021 年科技趋势报告》中可以看到中国对人工智能技术高度重视,给予AI 产业强大的推动力,促进人工智能方面的算法研究[1],伴随着人工智能、计算机视觉等技术的快速发展,智能汽车也在这些年里不断被研发和推广并转向商用,智能化将是下一个汽车时代的分水岭。
交通标志是汽车驾驶中极其重要的部分,而交通标志的识别任务更是无人智能化汽车中关键性的一步,它负责将检测到的标志进行判别,以确定其所归属的种类从而得到相应的识别结果。Wail[2]发表的报告详细介绍了交通标志自动检测与识别所面临的挑战以及未来的发展趋势,由于交通环境复杂多变,对识别的结果也有极大的影响。
交通标志识别算法有很多,目前主流的有模板匹配法、机器学习法和深度学习法。模板匹配法就是利用滑窗从待识别图像中提取特征向量与模板对应的特征向量进行比较[3],其弊端在于只能识别相同条件下的图像,不利于真实场景的识别工作;机器学习法就是通过提取特征并将其特征输入到分类器中来进行图像的识别,该方法可以兼顾识别分类操作的计算量及其鲁棒性,但是特征提取的操作多为人工手动设计,泛化性差且效率较低,典型的分类方法有支持向量机[4]、决策树[5]、随机森林[6]等。而深度学习法是现如今应用最为广泛的方法之一,它模拟人类大脑对未知事物的学习分析能力,使用卷积神经网络进行图像特征提取。近年来,深度学习法在交通标志识别领域迅速发展,其中最为经典的模型分别是RCNN[7]、Fast-RCNN[8]、YOLO[9]、SSD[10]等,由于深度学习的方法不需要人工设计来提取图像特征,在数据集足够庞大的时候可以准确的识别图像,得到了大力的推广。
在国内,虽然交通标志识别技术起步较晚,但是近年来该技术不断的得到突破。2017 年,党倩等提出一种基于二级改进LeNet-5 的交通标志识别算法,其中第一级将感兴趣区域包含的交通标志分为6 类,第二级改进粗分类结果进行细分类[11],从而进行交通标志的识别。2019 年,褚莹等提出了TSRCNN 模型,对经典卷积神经网络LeNet-5 进行四大改进,对模型进行基础结构调整,提升数据集平衡性的数据增广以及加入Drop层改善过拟合等策略[12]。2020 年,张猛等提出了ILN-CNN 模型对交通标志进行识别,该模型对原有的LeNet-50 网络模型构造两个相对独立的不同卷积核的子卷积网络,用于加快特征提取;其次增加子网络中的卷积核个数以增强网络区分不同交通标志的能力[13]。
现如今深度学习算法模型层出不穷,对于交通标志识别的准确度也大大提高,本文提出一种将提取到的特征图连接起来进行识别的模型RI-Model,该模型基于迁移学习,将图像输入模型进行预处理,结合ResNet-50 与Inception-V3 两种在深度学习算法中对识别分类操作效果较好的网络进行改进识别,在比利时交通标志数据集(BelgiumTS)上得到了较好的识别准确度,并有效提高了训练的收敛速度。
2 相关理论
2.1 卷积神经网络及迁移学习
卷积神经网络(Convolutional Neural Networks,CNN)是由输入层、卷积层、池化层、全连接层和输出层组成的,其训练通常分为两个过程。第一阶段是输入的数据从网络模型开头向网络模型末尾传播的阶段,即前向传播,另一个阶段是比对得出结果与输入理想之间的差距,将它们的误差从模型末尾向模型开头传播进行权重更新的阶段,即反向传播[14]。CNN 之所以在图像识别方向有很好的应用是因为它选用局部连接的方式,在一定程度上较少了网络的复杂性;其次是共用权重,网络中同一层的一些神经元使用相同的权值。基于这两个特点,卷积神经网络可以在一定程度上降低模型的复杂度和运算时间。
由于卷积神经网络需要经过大量的样本训练才能得到最优化的训练结果,可现实中优质的数据集少之又少,所以在2014 年,Bengio 等提出了深度学习中各个层的特征可迁移性[15]。迁移学习是指将源领域中某一任务学习到的知识迁移到另外的目标领域中完成新的任务,即是把已经训练好的模型参数迁移到新的模型来帮助训练,大大减少了训练所耗费的时间以及需要收集的数据等,此次实验采用迁移学习来训练模型,将最后全连接层的参数改为62来适用于此次的标志识别分类操作。
2.2 ResNet网络
2012 年,AlexNet[16]在ILSVRC 挑战赛中大幅度领先后面的选手并取得了冠军,让人们对该网络进行了广泛的研究,“越深的网络正确率越高”的说法在广泛传播,但是随着网络的不断加深,准确率在不断提高的同时出现了所谓的“退化”现象。何恺明等针对这个问题利用残差学习的思想[17]来解决由于模型过于复杂而导致的过拟合、梯度消失等现象,残差网络现如今被广泛应用于织物疵点检测[18]、网络的年龄估计[19]等。
ResNet 核心结构如图1 所示,它提出了一种“shortcut connection”的连接方式,通过提供residual mapping 及identity mapping 两种方式来解决“退化”问题。图中X为输入数据,X经过两个权重层后得到输出结果为F(X),在残差模块中还有一个分支是输入数据X不经过任何处理直接和卷积输出的结果F(X)做加法堆叠得到最优输出结果为F(X)+X,从而避免了因为网络层数的加深而丢失信息的情况发生。

图1 残差模块示意图
此次实验中选择其中ResNet-50 作为识别网络,因为在ImageNet 上ResNet-50 的表现结果很好,相较于传统的卷积神经网络的复杂度更低,且该网络层次更深但是不会出现梯度弥散等问题。
2.3 Inception-V3模型
提升网络性能的方法一般是增加网络的深度和宽度,但是不断增加网络深度和宽度时需要计算的参数也会不断地增加,因此Google引入了稀疏特性提出了Inception 结构。此次使用的Inception-V3[20]结构是在GoogLeNet[21]的基础上改进而来的,GoogLeNet 又叫做Inception-V1,Inception 的基础模块如图2 所示,它通过扩展网络的宽度来提升模型的复杂度,并使用了多分支分别进行处理,使用1×1 的卷积来处理输入的尺寸从而降低计算量,Inception-V3 将5×5 的卷积替换成两个连续的3×3进一步降低了计算成本,使用不同大小的卷积核来实现拼接从而实现不同尺度的特征融合。Inception-V3 可以在不断增加计算成本的基础上扩张网格[22],在相同的计算能力下提取更多的特征从而大大提高训练的效果。
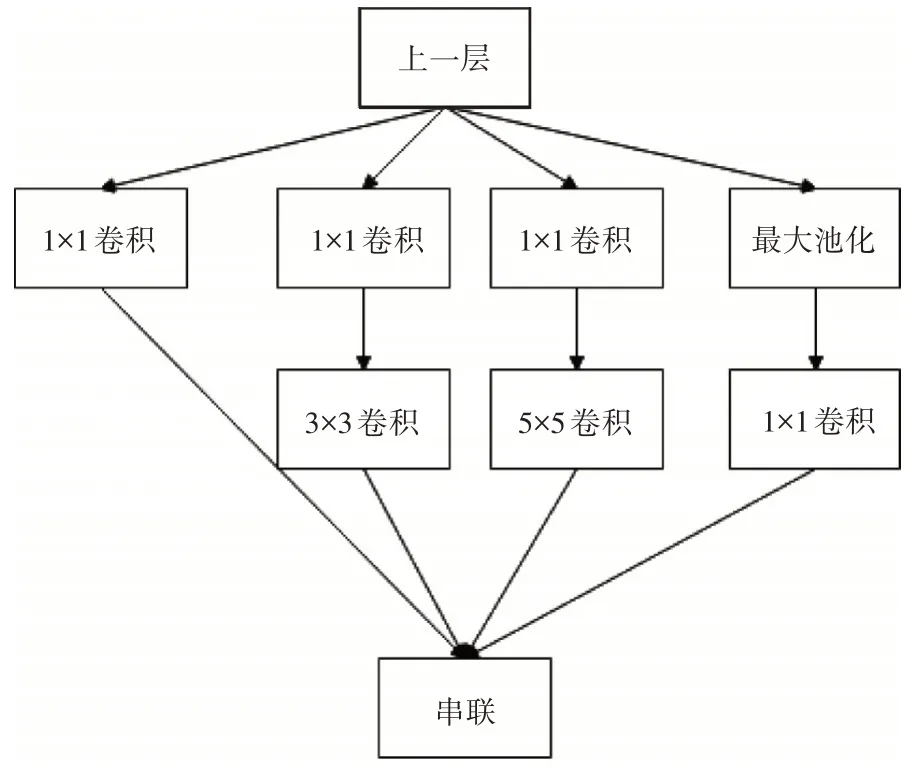
图2 Inception基础模块
3 交通标志识别算法
3.1 Inception-V3与ResNet-50模型
基于迁移学习,使用ImageNet大型数据集上训练好的ResNet-50 与Inception-V3 两种模型,用其与训练好的卷积基来进行数据的特征提取,对其全连接层进行优化改进并在此次实验中所使用的数据集上进行局部训练,使用Dropout来抑制过拟合,图3、图4 是其使用Inception-V3 与ResNet-50 网络进行训练的结构,首先将标注好的图像数据输入模型中,进行数据预处理以及数据增强的操作后输入到预训练模型中进行特征提取,再通过全局平均池化、Dropout 层以及全连接层输出最后的62 种标志种类。
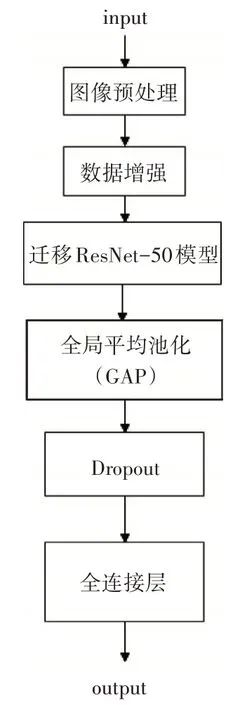
图3 引入ResNet-50模型
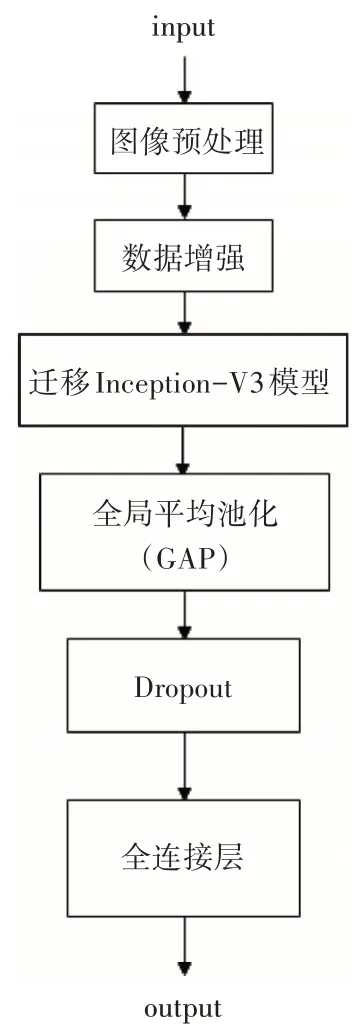
图4 引入Inception-V3模型
3.2 RI-Model模型设计
该模型是一个对称结构的网络模型,将ResNet-50 与Inception-V3 特征提取网络所提取到的特征结合起来,得到更细粒化的特征,得到更好的识别效果。首先将输入图像进行预处理与数据增强后并行输入到两个封装好的ResNet-50 以及Inception-V3 两种模型中,将再ImageNet 上与训练好的卷积基迁移到BelgiumTS 上进行特征提取,采用对称结构提取到图像中的特征向量将其进行汇合后转为一个综合特征向量,最后通过全连接层对综合特征向量进行多分类后得到最高概率的类别,其RI-Model的网络架构如图5所示。
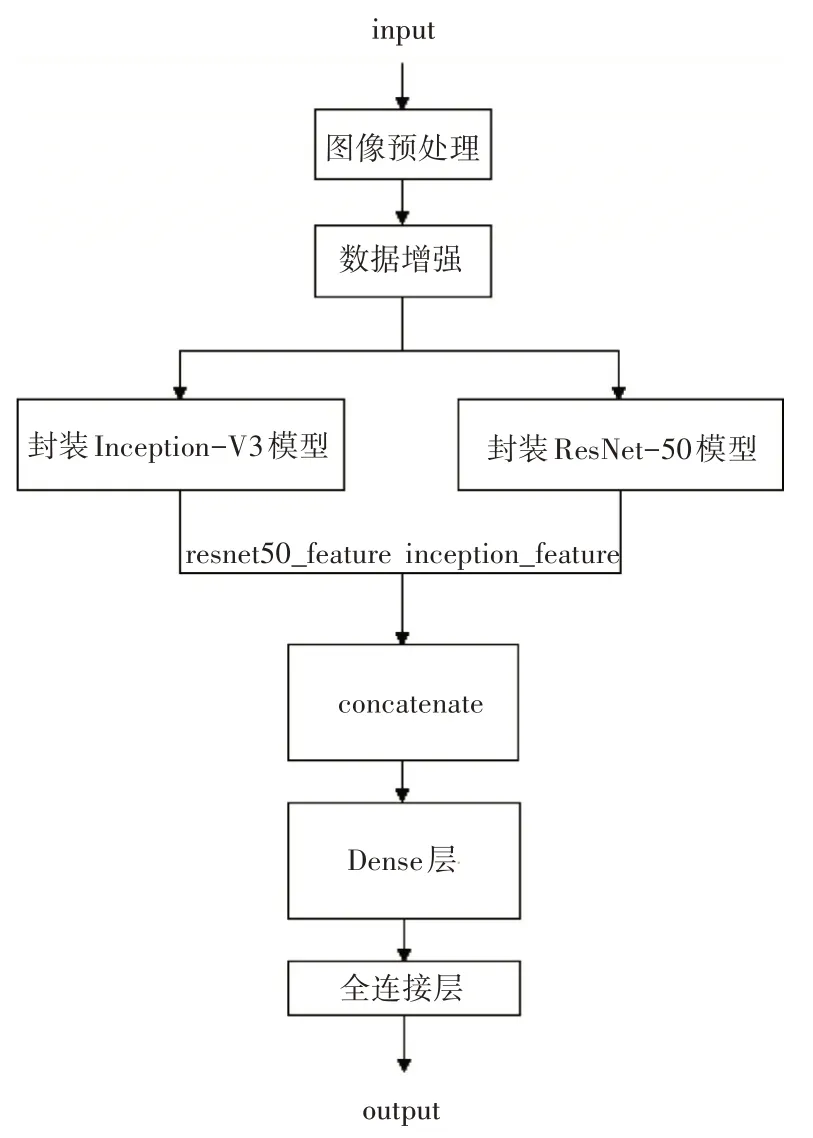
图5 RI-Model模型

图6 BelgiumTS示例图
4 实验
实验在windows 开发系统下进行,使用的硬件处理器配置为Intel(R)Core(TM)I5-8250U CPU@ 1.60GHz,软件使用集成开发环境Annaconda 开发环境,Python3 作为编程语言,由于TensorFlow 具有较好的移植性和灵活性,被广泛应用于图像识别、智能交通等领域,故使用TensorFlow进行开发。
4.1 数据集
本文在选用的是BelgiumTS,它是一种包含了62 种交通标志的数据集,其中有7074 张交通标志的图片。该数据集中的图片质量较高,包含了汽车行驶路线中的各个拍摄角度、光照条件、有无遮挡以及阴暗、变形等复杂情况,提高了训练模型质量。由于数据集中的图片都是大小不一的,所以将图片都裁剪或拉伸为180×180 大小的图片,使用这个尺寸的照片可以尽可能多地保存图片的信息。
4.2 图像增强
由于选择学习的样本较少,导致无法训练出最优的结果,所以需要通过对现有训练样本的强化,生成更多的训练数据。数据增强方法是通过随机变换来增加样本,从而生成各种可靠的图像。该方法的目标是在模型训练过程中不必看同一幅图像两次,使模型能够观察到更多的数据,具有良好的泛化能力。表1就是常用的数据增强的方法。图7是进行数据增强后的结果图。

表1 图像增强方法

图7 数据增强的示例图片
4.3 实验模型训练
本次实验的损失函数使用的是稀疏类别的Cross Entropy Loss Function(交叉熵损失函数)和Adam 优化器来对网络模型进行Forward Propagation、Back Propagation 以及参数的更新,Batch 设置为32,Epoch设置为40。
4.4 结果分析
将ResNet-50 模型、Inception-V3 模型、RI-Model 分别在BelgiumTS 中进行训练,得到的验证集Accurary以及Loss值如表2所示。
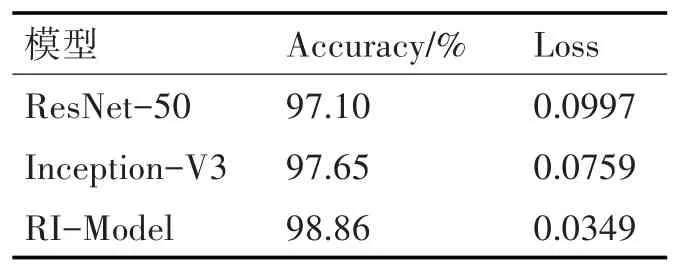
表2 实验结果
由表可以看出,在ResNet-50 和Inception-V3上的准确率分别为97.10%、97.65%。RI-Model 在数据集上的准确率达到了98.86%。实验证明,使用RI-Model 的识别正确率要比直接使用ResNet-50以及Inception-V3模型高1.5%左右,在测试集中进行测试的结果正确率也远远优于单独使用网络模型。BelgiumTS 包含了拍摄角度、大小像素以及光照等各个情况,证明该模型具有很好的分类效果,算法具有很好的鲁棒性。
5 结语
本文提出了RI-Model 模型来提高交通标志的识别精度,该模型是一种对称结构,基于迁移学习与特征结合的方法,对于处理后的图像进行特征提取,将对称结构中的两个网络提取的特征结合起来的到细粒化的特征,利用BelgiumTS进行实验,其结果表明:该方法能够在较短的训练时间内达到更好的收敛性能,相较于原模型的识别准确率有了一定的提升;由于该数据集包含了各种环境下的交通标志,RI-Model 模型识别正确率高,证明该方法可以在昏暗、运动模糊以及不定像素的情况下均可以达到较好的识别结果,具有很好的鲁棒性。但是整个网络结构还有很多的改进空间,亦可以选择更具有现实意义的数据进行扩充,例如雾霾、恶劣天气等不利识别情形下的交通标志,由此来提升其实用性。
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
小天使·一年级语数英综合(2016年8期)2016-05-14
噪声与振动控制(2015年4期)2015-01-01
小天使·一年级语数英综合(2014年7期)2014-06-26
电视技术(2014年19期)2014-03-11
