
基于特征权重与K-Medoids 算法结合的非均衡数据处理方法*
2023-09-29 05:51张瑞祥
计算机与数字工程 2023年6期
杨 栋 程 科 张 晨 张瑞祥
(江苏科技大学计算机学院 镇江 212100)
1 引言
非均衡数据集中不同类别之间数据样本分布不均衡,其中多数类样本属于某种类别,而余下的属于其它类别。这些数据广泛地存在于医疗诊断[1]、信息检索系统[2]、欺诈性电话的检测[3]、直升机故障检测[4]等领域中,并且它们都有一个共同的特性,即数据的类别、数量不均衡。非均衡数据处理方法的出现,使得数据挖掘技术向前迈进了一大步的同时也极大地推动了大数据的发展,提高了大数据的市场价值。
非均衡数据处理的方法主要分为两种:一是基于样本数据的处理,通过重采样等方法,对原始数据增加或者减少,从而使得非均衡数据转化为均衡数据;另一种则是基于算法的处理,通过改进传统的分类学习算法。目前基于样本数据处理的方法通常存在会引入新的噪音数据同时还会改变原始数据的分布等问题,而现有的基于算法的处理通常会有算法过于复杂、计算复杂度高等问题[5]。本文主要研究的是欠采样方法,基于上述问题,提出了一种基于特征权重与K-Medoids 算法相结合的欠采样处理方法,其关注于数据处理方面并且考虑了样本数据特征权重值大小的问题。
2 相关工作
2.1 重采样算法研究
欠采样方法[6]就是在样本数据多数类数据中对一部分样本数据进行增删处理,使之与少数类样本数量相对平衡,从而转化为均衡分类问题,常用的方法主要有随机欠采样方法、Hart提出的紧缩最近邻规则、Wilson提出的Tomek links方法等。欠采样方法即是去除一部分样本数据,导致其删去了所具有的一部分特征属性,从而影响到了不平衡数据分类效果。
过采样方法则是增加少数类的数据,其中最简单的一种就是随机过采样算法;其中最著名的算法就是文献[7]中的SMOTE算法。文献[8]中,Borderline-SMOTE 方法则是对先前算法的改进;Sáez[9]等提出了一种名为SMOTE-IPF 的框架,经实验表明该框架具有很好的效率;KE CHENG[10]等提出具有噪声过滤的分组SMOTE 改进算法,其采用高斯混合模型准确估计了每个训练实例的概率密度,进一步发现和过滤噪声实例,并根据实例的分布特征将实例划分为不同的组,以进行个体采样。
上述方法在数据层面上对于非均衡数据分类问题得以解决,提高了样本的分类精确度,但都使得数据的特征分布发生改变以及其他问题,这些问题对整体样本的分类结果造成了一定影响。
2.2 K中心点算法(K-Medoids)的研究
K-Means算法是一种基于样本间相似性度量的间接聚类算法,可以将数据集划分成不同的簇[11]。该算法实现的代码简单、训练效果快速[12]。但是,该算法也有聚类个数难以确定等缺陷[13]。而K 中心点聚类(K-Medoids)算法则是提出了新的选取质点方式,很好地解决了上述问题,该算法使用不同于相对误差标准的绝对误差标准来定义一个分类簇中紧密程度变化。每次选取的质点都是从其聚类方法的样本点中选取,选取当该样本点成为新质点后能提高各分类簇的聚类质量的样本点作为新的质点,因而各簇的样本更为紧靠一起[14]。
3 基于特征权重与K 中心点算法结合的欠采样方法
在数据分类过程中,并不是所有的数据样本都是重要的,因为其中有一部分样本数据容易被学习,对于新样本的合成提供的信息少。而上述提到的方法的缺点就是未能将全部样本数据的特征权重纳入分类算法或者采样方法中。因此,本文提出了一种基于特征权重与K 中心点聚类算法(K-Medoids)相结合的欠采样方法(Under-sampling method based on the feature weights and K-Medoids,UsfwKM),其在对不平衡数据分类决策时,起主要作用的样本特征的权重值进行增大,又同时减小了对分类决策时起次要作用的样本特征的权重值,又结合K 中心点算法,抽样出的数据对于分类决策会更加有用,并且提高分类器对于不平衡数据的分类性能。
3.1 提出的UsfwKM方法
该方法分为两部分,一是对样本数据特征权重值提取,二是基于特征权重的K-Medoids 聚类。如图1 是UsfwKM 方法的流程图,其中,D表示样本集;DMi定义为样本集中的少数类样本;DMa定义为其中多数类样本;少数类样本的第i特征与多数类样本的第i特征之间的相关系数定义为Corri;Wi定义为第i特征值的权重值;Masizei定义为通过K中心点聚类算法得到的第i簇中的多数类样本的数量,Misizei定义为通过K 中心点聚类算法得到的第i簇中的少数类样本的数量;Db表示均衡数据。
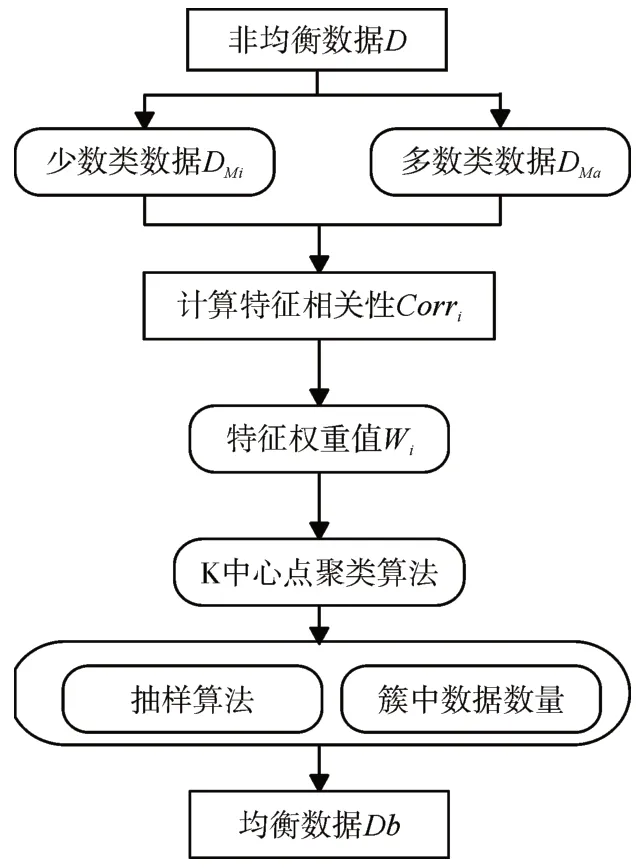
图1 UsfwKM方法流程图
该欠采样方法的具体实现步骤如下。
1)设定一个非均衡数据D={(x1,y1),(x2,y2),(x3,y3),…(xn,yn)},(其中,xi表示为第i个样本,yi是指其所属类别,n为样本数量。)按照数据的标签分类为少数类数据DMi、多数类数据DMa,对于少数类样本中DMi的第i个特征,计算其与多数类样本DMa的第i个特征之间的皮尔逊相关系数,因此可以得到其相关系数为Corri。
2)针对计算出的第i个特征之间的相关系数,计算第i个特征所拥有的权重值,Wi的计算公式为Wi=1-Corri,上述过程中得到具有特征权重样本集Dw,然后用K-Medoids 方法对具有特征权重的样本集Dw进行聚类,得到k个簇C1,C2,…Ck。
3)由式(1)计算得出各簇中应抽取的多数类样本数量:
其中,Majsize定义为原始训练集D中多数类样本集的数量。
4)根据上步得到的CMadatasize,采用随机采样方法从多数类数据集中得到多数类样本,然后再与D中全部的少数类样本DMi相结合组成均衡数据样本集。
3.2 数据特征权重值的选取
设训练数据集为D={(x1,y1),(x2,y2),(x3,y3),…(xn,yn)},其中第i个数据定义为为(xi,yi),根据所拥有的标签yi得出少数类样本DMi与多数类样本DMa。其分类方法的公式为
具体计算特征权重的步骤如下:
1)首先是数据样本间的特征相关性系数Corri。先设各Fmii之间的皮尔逊相关系数为1,针对少数类样本的第i特征Fmii,再计算其与多数类样本的第i特征Fmai之间的相关系数Corri。由于在非均衡数据中多数类与少数类样本数量有很大差距,所以本文将多数类样本的第i特征Fmai分成若干个与少数类样本数量相当的小集Fmai-j,并假设j有k个,然后分别计算Fmii与Fmai-j之间的相关系数,以求取平均值,平均值计算公式可以表示为
2)在计算样本特征权重值时,如果多数类数据中的特征Fmai与少数类数据的特征Fmii相关程度较低,则说明此特征对于分类非常有用。特征权重Wi=corrcoef(Fmii,Fmii)-corri,corrcoef(Fmii,Fmii)值近似为1,所以可以默认为1,此时Wi=1-corri。W={W1,W2,…Wi,…Wm} ,m为数据集中的特征数目。
3.3 基于特征权重的K中心点聚类
1)根据第一步得到的特征权重W,将其与原始样本D相组合,得到Dw,即Dw=D×W。
2)使用K-Medoids 方法对附有特征权重的数据集Dw聚类,得到k个簇,即C1,C2,…Ck,对于第i个簇Ci,其少数类样本数量表示为Misizei,多数类样本数量表示为Masizei。此时,对簇Ci对应的去特征权重值后的多数类样本使用无放回抽样方法抽取数量为CMadatasize的样本数据量,其计算的公式为
因而得到与少数类数据样本数量相等的多数类数据Dsample,最终组成的均衡数据集为Db=Dsample+DMi。实验需求可以多次欠采样得到多个均衡数据Db。
4 实验结果及分析
4.1 实验数据集描述
本实验采用的标准数据集来源于KEEL 高度不平衡数据集库,数据集的不平衡率从一点几到几百不等,非常适合做非均衡数据分类的研究,对于本次实验,随机选择其中六组数据集,其样本对应的属性如表1所示,表中IR表示其样本数据的非均衡比。

表1 标准非均衡数据集介绍
4.2 实验过程及结果分析
使用本文提出的UsfwKM 方法与随机欠抽样方法对其中选取的六个数据集进行采样处理,对采样得到的均衡数据使用朴素贝叶斯算法[15]、集成规则为Max Rule 方法[16]作为基准分类器进行测试。在实验中,设K-Medoids 算法聚类为三个簇,实验性能评估指标则采用AUC(Area Under the Curve)值[17]。使用上述非均衡数据集进行实验,可分别测得本文所提出的欠采样方法(UsfwKM)与已有方法的实验结果如表2所示。

表2 经实验测得的AUC值
由图2 可以看出,基于本节结合的集成方法得到的分类结果相比于随机欠采样方法得到的分类结果在选取的六个标准非均衡数据集上性能均有较大的提升,并且AUC指标值平均提升了约0.10。
通过上述实验证明,本文提出的UsfwKM 方法将所有样本特征权重值考虑到分类方法中,在与K中心点聚类方法相结合使用时抽样得到的多数类数据更加适合于分类。通过实验得到的柱形图上可以清楚表明,在处理非均衡数据时能够拥有更好的分类效果。
5 结语
在处理非均衡数据时,为了考虑各样本的特征权重值,本论文提出了一种基于特征权重与K-Medoids 算法结合的非均衡数据处理欠采样方法——UsfwKM算法。这是对特征权重赋值进行改进的一种方法,从而抽样出更有利于分类决策的数据,通过将其与K-Medoids 算法相结合,用来构建非均衡数据处理的分类模型。选择KEEL 公开标准数据集上的六组数据集进行实验后,结果表明了本文提出的UsfwKM 方法提高了分类器对于非均衡数据的分类性能,分类效果较好,同时有较强的鲁棒性。本文后续工作在于从非均衡数据算法的层面对现有集成规则进行改进来解决不平衡问题。
猜你喜欢
当代陕西(2020年17期)2020-10-28
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
人大建设(2018年5期)2018-08-16
电子测试(2017年15期)2017-12-18
电信科学(2017年6期)2017-07-01
雷达学报(2017年6期)2017-03-26
少儿美术·书法版(2016年1期)2016-02-06
大众摄影(2015年9期)2015-09-06
电子设计工程(2015年6期)2015-02-27
