
利用字节模式二维特征的ROP链智能检测方法*
2023-09-28 07:21黄恺杰张梦杰刘星彤
国防科技大学学报 2023年5期
王 剑,黄恺杰,张梦杰,刘星彤,杨 刚
(国防科技大学 电子科学学院, 湖南 长沙 410073)
数据执行保护(data execution prevention,DEP)、地址空间布局随机化(address space layout randomization,ASLR)等内存防护机制的普遍应用,使得传统的代码注入攻击难以奏效。Shacham[1]提出了面向返回编程(return oriented programming,ROP)的概念,打破了传统注入攻击需要注入外部可执行代码的局限,通过选取并拼接目标系统软件内存空间中的已有代码片段(称之为Gadget)来实现恶意功能。Gadget是目标程序内存空间已存在的以跳转指令为结尾的代码片段,可以实现内存读写、数据处理、系统调用和函数调用等功能。Gadget是构成ROP链的基本单元,ROP链通过拼接多个Gadget,完成恶意攻击过程中的特定操作。由于ROP链中没有显性表示的恶意代码,因此可以突破DEP的防护。ROP链在实际漏洞攻击中通常作为攻击代码的重要组成部分,如在针对CVE-2014-0322、CVE-2016-10190、2021-22555、CVE-2022-0995等漏洞攻击的代码中均包含了ROP链[2]。
ROP链的检测分为动态检测与静态检测:
动态检测通过建立蜜罐、沙箱等目标环境,对外部输入数据进行动态执行监控,获取其动态特征,如寄存器或内存状态、指令执行状态、控制流完整性等,采用行为规则匹配、执行特性统计分析、内存状态推演等方法实现对ROP的检测。DROP 基于动态二进制插桩对代码指令的执行情况进行监控,通过检查“ret”指令间隔的指令数,判断是否存在ROP恶意代码片段[3]。蒋廉[4]使用基于内核的虚拟机(kernel-based virtual machine,KVM),利用动态插桩,结合软硬件分层过滤,嵌套检测ROP攻击。SCRAP在DROP的基础上根据指令指针的跳转行为定义攻击行为签名,利用签名匹配检测ROP攻击[5]。Ropecker基于硬件辅助的最近分支记录,通过识别间接分支跳转的频率实现对ROP攻击的判定[6]。ROPdefender通过识别软件控制流是否出现异常来检测ROP攻击[7]。CFIMon利用硬件辅助的方法监控CPU指令执行,检测破坏控制流完整性的异常跳转事件[8]。ROPDetector[9]和MIBChecker[10]利用硬件性能管理单元的事件触发机制,针对预测失败的分支进行实时ROP检测。ROPStop通过对间接分支跳转事件的统计分析,有效地捕获控制流异常事件,进而识别ROP攻击[11]。ROPscan推测性地驱动目标进程地址空间中已经存在的代码的执行,并在运行时检测ROP代码的执行[12]。动态检测方法能够得到较为可靠的检测结果,但其需要构建目标软件动态环境并监控执行样本的动态特征,存在环境构建困难、算法开销大、应用部署复杂等缺点。
静态检测根据ROP在数据层面上的取值范围和具体数值的排布顺序,基于特征码匹配、字节流统计分析、模拟执行推演等方法直接分析流量数据以实现对ROP攻击的检测。EavesROP利用滑动窗口筛选潜在的可疑数据段,并使用快速傅里叶变换匹配滤波的方式对网络流量中的疑似地址值与已知库文件中的Gadget地址值进行匹配,以发现ROP攻击[13]。Strop根据Gadget地址的统计特征,如静态地址数量、静态地址距离、相同地址数量、地址范围等,实现对ROP链的检测[14]。DeepReturn采用反汇编的方法分析可疑ROP攻击链,并将其编码输入到卷积神经网络中进行分类检测[15]。ROPminer通过在目标代码段和动态链接库中收集可能的Gadget,学习ROP组件的字节取值特性和组件次序,并运用隐性马尔可夫模型实现对输入数据流的检测[16]。Code-Stop通过模拟执行数据中的可疑Gadget地址,对比其语义是否类似调用Windows特定函数时对寄存器的赋值模式,从而判断是否存在ROP攻击[17]。静态检测方法较之动态检测方法具有开销小、架构简单、部署方便等优点,但是当前的静态检测方法一方面依赖程序内存地址的上下文信息,包括特殊的函数调用地址信息或是受保护进程的内存地址信息,方法的泛用性较差;另一方面存在检测效率低、真实ROP攻击检测性能差等问题。
本文提出一种基于字节模式二维特征的ROP链检测方法。该方法基于ROP链的字节波动特征,通过序列抽取、滑动分组、数值量化,将输入的一维流量数据转换为二维特征向量,保留了更多的数据信息,并采用卷积神经网络实现对ROP链的检测。该方法解决了现有方法地址内存信息依赖的问题,无须考虑目标系统环境,包括操作系统版本、目标软件版本,且具有较高的检测准确率、较低的时间开销和系统开销。
1 ROP链检测模型
1.1 模型设计
本文提出的模型适用于32位和64位操作系统。为便于理解,下面以4 B地址空间的32位操作系统为例进行阐述。检测模型的总体方案如图1所示,包含数据准备、数据预处理、模型训练和模型检测四个部分。数据准备主要是建立ROP流量数据集和非ROP流量数据集;数据预处理部分将流量数据包的有效载荷转换为类灰度图像的二维数值矩阵;模型训练部分将经过预处理后的数值矩阵输入到神经网络模型中进行训练;模型检测部分将测试数据预处理后输入到测试模型中,从而得到所属类别。神经网络模型相较于传统数学模型以及机器学习模型具有更强的特征提取能力,能够自动地、智能地提取类灰度图像的二维数值矩阵特征。同时基于神经网络的检测模型具有优秀的鲁棒性和泛化性,对于未出现在训练集的新ROP链具有良好的检测性能。因此,采用神经网络模型对ROP链进行检测。

图1 模型设计总体方案Fig.1 General design program of the model
1.2 数据集构建
当前,ROP链的检测还没有可用的公开数据集。ROPgadget[18]、Ropper[19]等工具能自动生成ROP链。但是一方面这些工具生成ROP链的方法过于标准化,使得生成的不同ROP链所包含的Gadget数量区别不大;另一方面用于生成ROP链的Gadget通常选自同一代码段,功能较为单一。因此采用这些工具生成的ROP链并不能很好地反映真实ROP链的特点,不适合神经网络模型的学习训练。
由于构成ROP链的Gadget的第一字节与其他字节的分布差异大,因此本文基于ROP链所在区域的字节波动特征实现对ROP攻击的检测,并通过对真实ROP链进行分析,依据真实ROP链的结构特点来构建数据集。ROP链数据的生成方式是将真实Gadget的首字节与三个随机的字节组合形成扩展的Gadget,并将若干个扩展Gadget拼接组成ROP链。通过从CVE和Expliot Database等收集并分析大量真实攻击样本,发现ROP链中Gadget的选择来源往往小于6个不同的代码区域。为提高模型检测能力,本数据集提取了10个不同首字节的代码地址段,每个代码段有64 MB的地址空间。研究表明,在x86架构下,攻击者实现简单的条件转移逻辑也需要串接11个不同的 Gadget[20],因此本数据集设定ROP链包含Gadget的数量在10~50个不等。ROP链数据集的构建如表1所示,ROP链的长度表示其包含的Gadget数量,地址段数表示ROP链包含的Gadget的地址段数量,如:地址段数为1表示Gadget都处于相同的地址段,其对应的首字节相同;地址段数为2表示ROP链中的Gadget有2个不同的首字节。该数据集既考虑了ROP链的长度,又考虑了Gadget的地址范围,总样本量在12 000以上,能满足神经网络训练需求。
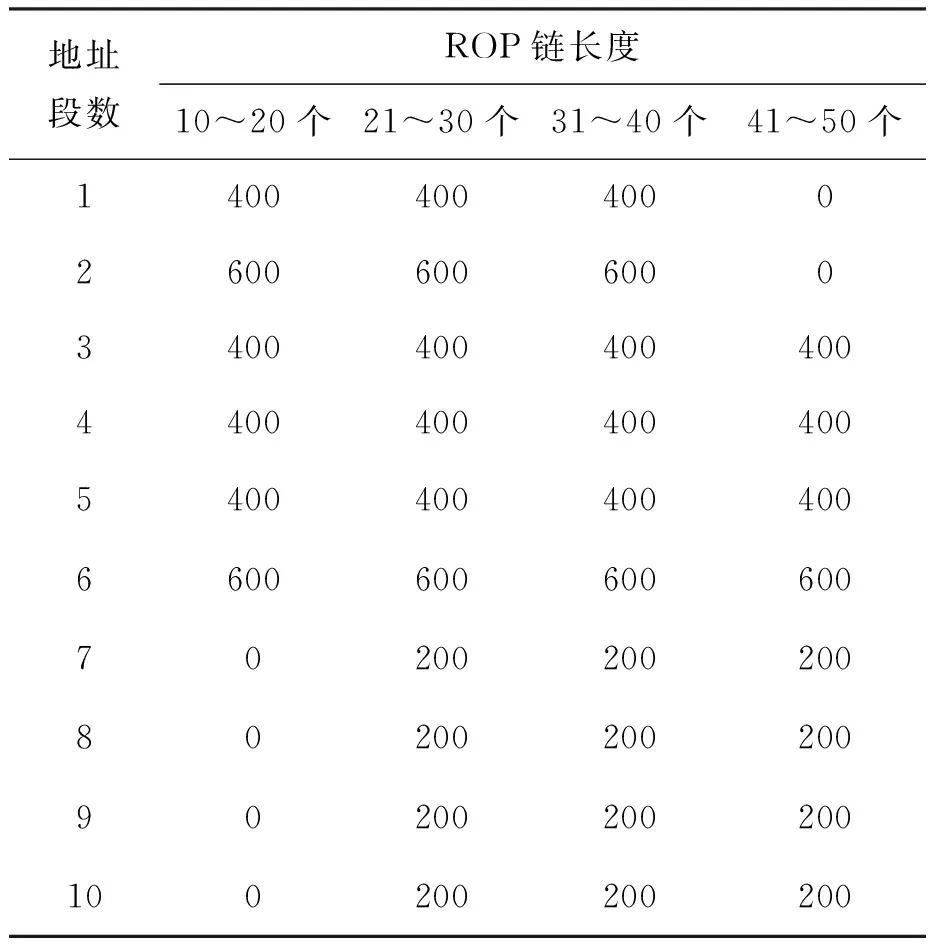
表1 ROP链数据集Tab.1 ROP chains data set
正常流量数据由USTC-TFC数据集构建[21]。USTC-TFC数据集包含异常流量和正常流量两部分,本文选用其中的正常流量部分进行实验,包含点对点(peer-to-peer,P2P)流量、多媒体流量、文件传输流量、电子邮件流量等。
1.3 数据预处理
ROP链包含Gadget内存地址和填充数据两种数据,均为4 B,因此ROP链在流量中表现为多个4 B数据组成的代码串。ROP链的核心单元是Gadget,它的字节数值表示所调用的代码段在内存空间的具体位置。ROP链具有明显的字节模式特征,即当Gadget是从同一个代码段或相邻代码段中选取时,Gadget的第一个字节数值大小相同或相近,且Gadget后三个字节的数值是随机的[17]。基于ROP链的字节模式特征,本文采用顺序抽取的方法将流量数据分成四组,并采用滑动窗口进行数值量化,最后将一维流量数据转化为二维矩阵,共4个步骤,如图2所示。
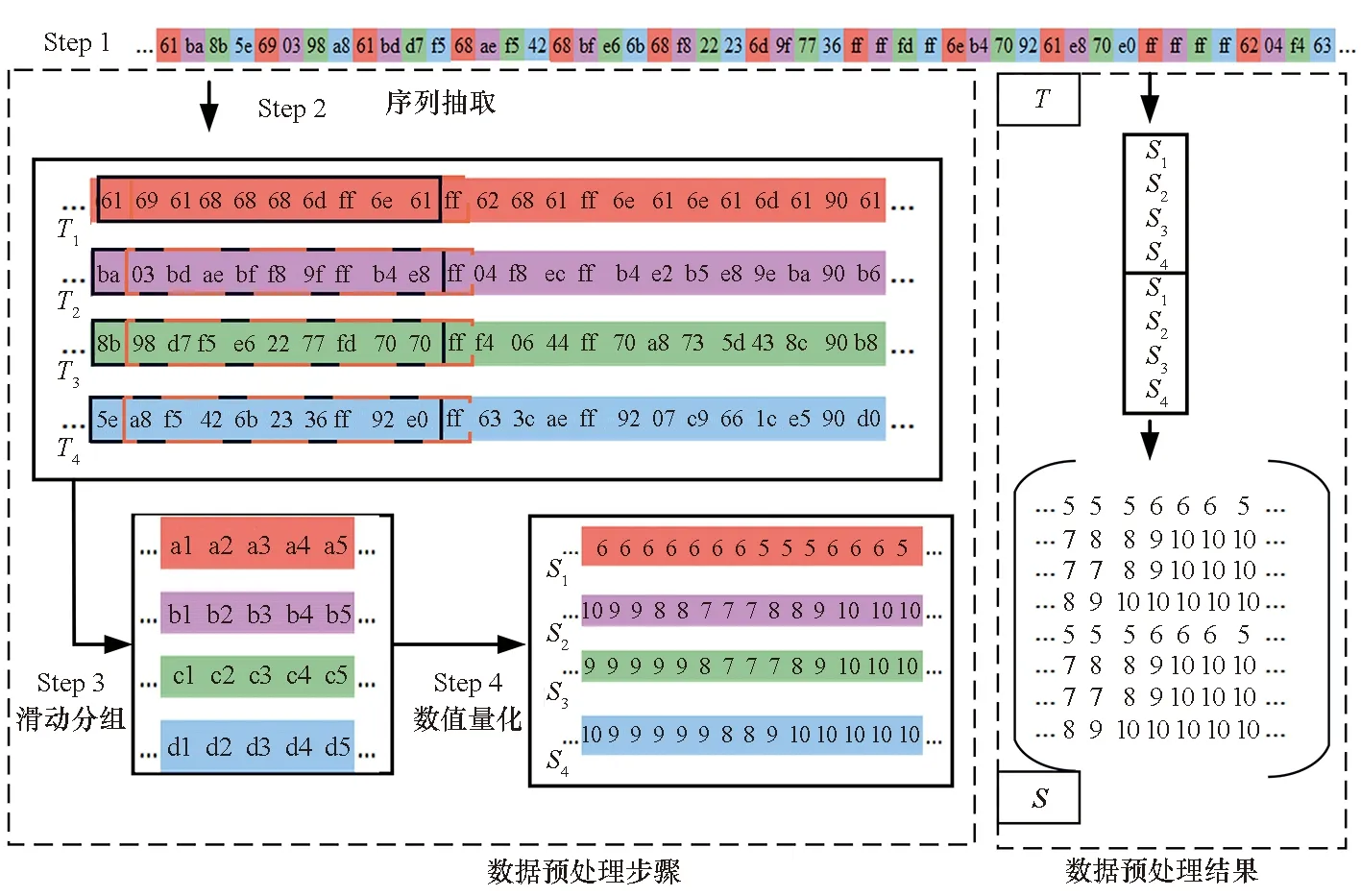
图2 二维特征数据预处理Fig.2 Preprocessing of two-dimensional feature data
Step1:对待测流量数据进行标准化清洗。去除数据包协议头部,保留有效负载,输出流量序列T。假定序列T总长4n,舍弃多余的字节。
Step2:将ROP链中所有Gadget字节有序分离并组合。将流量序列T从首字节开始,以0、1、2、3顺序依次标号,并将同一标号数据组合为一组,共输出4组数据T1、T2、T3、T4。经过第二步操作,ROP链中的Gadget的首字节一定属于这4组数据中的某一组,这组数据的数值变化较小,波动平稳。另外3组数据分别包含Gadget的后3 B,其数值波动较大。
Step3:在T1、T2、T3、T4上选取窗长为L、步长为1的滑动窗口,对滑动窗口内的字节波动大小进行量化,量化方式有类化、熵化、拟熵化等。类化是统计滑动窗口内不同字节数值的个数,熵化是计算滑动窗口内字节的熵值,拟熵化是对熵化的改进。H1(x)、H2(x)、H3(x)分别表示采用类化、熵化、拟熵化的滑动窗口内的波动量化值。
H1(x)=n
(1)
(2)
(3)
其中,n表示滑动窗口内不同字节数值的个数,p(xi)表示滑动窗口内不同字节出现的次数。
Step4:单步滑动窗口,输出4组数据S1、S2、S3、S4,输出序列长度为365,长度不足则补零,叠加组合输出矩阵S。这一步是得到神经网络所用的标准数据,对数据进行叠加组合可以提取数据边缘信息。
本文所提数据预处理方法,是在分析ROP链中Gadget不同字节波动特征的基础上,通过序列抽取的方式,并结合滑动窗口对数据进行量化,从而实现数据特征的有效提取。该方法将一维流量数据转为类灰度图像的二维数值矩阵,包含了更为丰富的数据信息,且不需要预知目标软件的地址信息。
1.4 卷积神经网络结构
ROP链在网络流量中的局部特征明显,且ROP链的检测结果与其在流量中的位置无关。卷积神经网络具有很强的局部上下文特征提取能力,并具有平移不变性的特点。经实验验证,卷积神经网络在ROP链检测任务中的准确率优于深度神经网络以及循环神经网络。因此,将卷积神经网络作为检测模型。
ROP链的检测有实时性要求。本文设计了简单且轻量级的卷积神经网络结构,交替使用卷积层和池化层提取局部特征并减少模型参数,同时应用Dropout正则化增强模型对噪声的鲁棒性。检测模型的结构如图3所示。输入8×365的定长二维数值矩阵,在第1个二维卷积层中先对输入进行卷积,卷积核为3×3,共16个通道,生成16个长为6×363的特征图。然后通过二维池化核2×2的最大池化层生成16个长为3×181的特征图。在第2个二维卷积层中,卷积核为3×3,共32个通道,生成32个长为2×181的特征图,然后通过二维池化核2×2的最大池化层,生成32个长为1×90的特征图。完成上述操作后,将特征序列展平,通过两个全连接层将序列依次转换为128和1。模型使用的超参数如下:使用参数为0.6的Dropout正则化,输出层采用Sigmoid函数作为激活函数,其他层使用ReLU函数作为激活函数,ReLU函数没有复杂的指数运算,计算简单、运算效率高。学习率设为1×10-4,训练轮次为30,训练总参数为37万余个,损失函数采用二分类交叉熵损失函数。

图3 卷积神经网络结构Fig.3 Structure of convolutional neural network
2 实验分析
2.1 数据预处理参数选择实验
滑动窗口长度L以及量化边界D是影响模型数据预处理效果的两个关键特征。为探究这两个变量对算法性能的影响,依据相邻代码段首字节数值大小相近的特点,设置了长度范围为5~24和量化边界为0~3的循环实验,共80个训练模型进行性能对比,对比结果如图4~6所示。
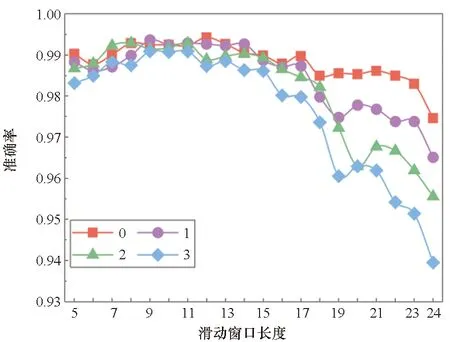
图4 窗口长度与量化边界对准确率的影响Fig.4 Influence of window length and quantization boundary on accuracy rate
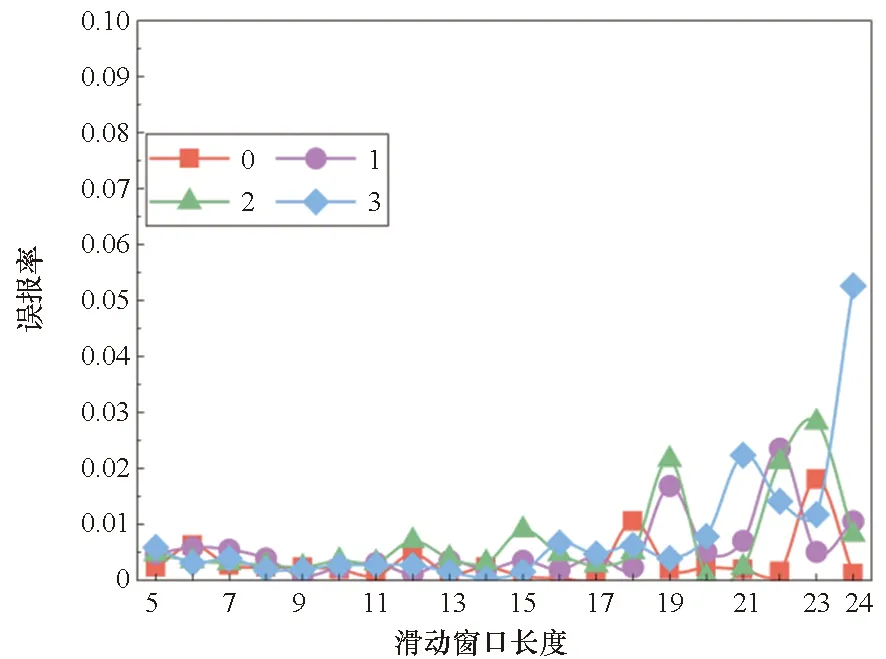
图5 窗口长度与量化边界对误报率的影响Fig.5 Influence of window length and quantization boundary on false alarm rate

图6 窗口长度与量化边界对漏报率的影响Fig.6 Influence of window length and quantization boundary on miss alarm rate
总体来讲,采用不同窗长和量化边界均能有效区分ROP链,准确率在94%以上,最高可达99.4%。通过对不同窗长和量化边界的模型性能进行分析,可以发现:当窗长大于15时,模型的准确率下降较快,且量化边界越大准确率越低;当窗长大于12时,模型的漏报率上升明显,且量化边界越大漏报率越高;模型的误报率受窗口长度和量化边界的影响较小;当窗长大于18时,模型性能波动剧烈,因为窗长过长容易涵盖ROP链区域外的正常流量字节,造成模型性能不稳定。模拟训练时的损失函数收敛曲线如图7所示,随着训练轮次的增加,检测准确率稳定上升,误差损失值平稳下降。
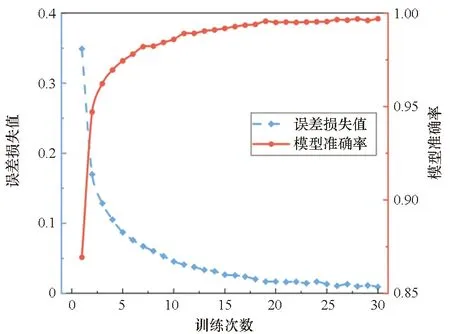
图7 损失函数收敛曲线Fig.7 Loss function convergence curve
2.2 模型性能评价实验
实验使用的神经网络框架为TensorFlow。实验硬件GPU为GeForce RTX 3060 Laptop,CPU为11th Gen Intel(R) Core(TM) i7-11800H@2.30 GHz,内存为16 GB。
实验选取长度在150~1 550范围内的数据包,滑动窗口长度设为12。为验证不同预处理方法模型的检测效率,将数据包分别输入采用不同量化方法的二维特征检测模型中,测算从数据输入到检测结果输出的时间开销,实验结果如图8所示,图中散点表示对于单个数据包检测的时间开销,而直线是对这些单个数据包检测开销的拟合结果。三种量化方式的时间开销均在0.14 s以内,类化方式所用时间开销明显低于熵化和拟熵化,类化方式大部分数据包的检测时间在0.1 s以内,拟熵化模型次之,熵化模型时间开销最大。

图8 不同量化方法的时间开销Fig.8 Time costs of different quantization methods
为验证数据预处理的有效性,开展了未经数据预处理的源数据和数据预处理后数据的模型性能对比实验,如图9所示。实验结果表明:经过数据预处理后,模型的准确率提升9.9%,误报率降低5.7%,漏报率降低14.1%,充分验证了数据预处理方法和检测模型的有效性。

(a) 准确率对比(a) Accuracy rate comparison

(c) 漏报率对比(c) Miss alarm rate comparison图9 二维特征预处理前后模型性能对比Fig.9 Comparison of model performance before and after two-dimensional feature preprocessing
为验证模型对真实ROP链的检测性能,分别选取ROPgadget、Exploit Database、CVE中的ROP链进行检测实验。通过ROPgadget生成的ROP链188个,分别模拟10次攻击。Exploit Database漏洞库中漏洞利用程序的ROP链共计445个,分别模拟10次攻击。在Github中收集的CVE漏洞利用程序的ROP链49个,分别模拟100次攻击。实验表明,经过数据预处理后的模型具有较强的泛化性能,能够以极低的漏报率实现对真实ROP链的有效检出,而未经数据预处理的模型漏报率非常高,如表2所示。实验发现一个有趣的结果,两种模型检测由ROPgadget工具产生的ROP链的漏报率均为0,因为ROP链自动生成工具的生成逻辑往往会遵循某些固定范式,产生的ROP链也非常规范,容易被检测。如果采用此类工具产生的ROP链来训练神经网络模型,模型的训练性能非常好,但是实际检测性能往往非常差。

表2 不同来源真实ROP链检测的漏报率Tab.2 False negative rate of real-world ROP chains
2.3 模型能力探究实验
ROP链的长度决定了目标区域的长度,其长度越长,特征也越明显。以往的研究很少关注ROP链的长度对模型性能的影响。实验分析二维特征检测模型对6个分组(每个分组的地址段数不同,如表1所示)中不同长度(10~30)ROP链的检测能力(用漏报率衡量)。模型类别采用L-D表示,L为窗长,D为量化边界。选用最高准确率模型12-0、最短窗长模型5-0和较长窗长模型17-0进行实验。由于量化边界为0时,模型性能较优,因此模型的量化边界统一选择为0。
实验表明窗长和地址段数对模型的检出性能影响较大,如图10所示,随着ROP链长度的增加,漏报率均可降低至1%以下。在窗长相同的情况下,地址段数越多,则模型漏报率越高、波动越大,因为地址段数越多,ROP链的字节特征与正常流量字节特征更接近。窗长越短,模型对于不同地址段数的漏报率的波动越大,因为短窗口对连续区域的波动量化能力有限,无法很好地规避波动干扰。窗长越长,模型对于不同地址段数的漏报率变化趋势越相似,因为长的窗口可以抵消地址段数增加带来的负面影响。

(a) 5-0模型(a) 5-0 model

(c) 17-0模型(c) 17-0 model图10 模型漏报率Fig.10 Miss alarm rate of model
2.4 对比分析实验
ROPminer、SPRT[22]、DeepReturn等模型虽然具有较高的准确率,但这些方法都依赖程序的内存地址信息。本文提出的方法与已有方法最关键的区别在于不依赖程序的内存地址信息,具有更低的复杂度和更广泛的应用场景,对比数据如表3所示。虽然Strop方法也不依赖内存地址信息,但该方法对于68个ROP样本仅检测到51个,漏报率高达25%。本文方法、SPRT和ROPminer都是完全静态的方法,仅根据网络数据流就可实现ROP链的检测。DeepReturn需要对流量字节进行反汇编,虽然其误报率较低,但该方法需要结合内存地址信息,通用性较差。SPRT和本文方法探索了ROP链长度对算法性能的影响。在SPRT中,当训练数据集ROP链长度为10~50时,准确率仅为93.2%;当训练数据集ROP链长度为20~100时,准确率才达到99.0%。本文方法在训练数据集ROP链长度为10~50时,准确率可达99.4%。因此本文方法在检测较短长度的ROP链时具有更高的准确率。Strop、ROPminer、DeepReturn等方法均采用真实ROP样本验证方法的有效性,但本文用于实验验证的真实样本数量远多于其他方法。以上方法中,ROPminer进行了时间开销实验,单文件的时间开销为0.9 s,本文方法的时间开销在0.1 s以内。
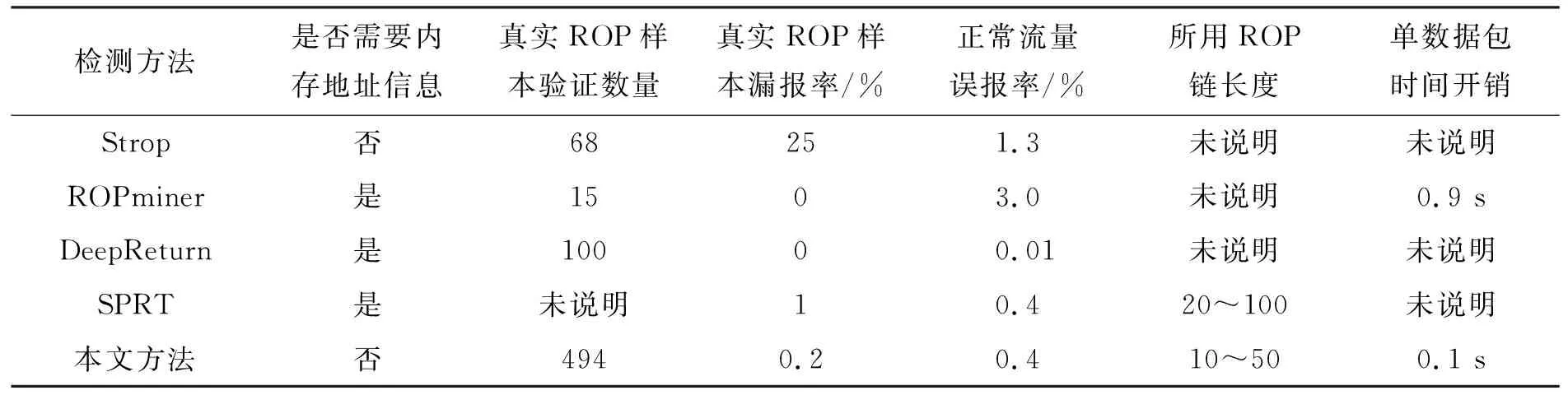
表3 与现有方法的对比分析Tab.3 Comparison with existing methods
3 结论
本文提出了一种基于字节模式二维特征的ROP链检测方法,首先对原始流量数据包进行数据清洗,然后对清洗后的数据进行序列抽取,经滑动窗口采样后对数据进行量化处理,将输入的一维数据转换为二维特征向量,并采用卷积神经网络模型实现对ROP链的检测。该方法能自动从样本中提取ROP链字节模式二维特征,并具有良好的泛化能力,能检测训练集中未出现过的新ROP链。模型的检测准确率达到99.4%,单数据包的时间开销在0.1 s以内,且模型对真实ROP样本的测试漏报率接近于0,相较于Strop、ROPminer、SPRT等传统方法,在检测性能上具有明显优势。同时,该方法可直接对流量数据进行检测,不需要预知代码段加载内存地址,部署方便并具有良好的可解释性。下一步将深入分析不同类型漏洞样本的特征,建立更为丰富的漏洞攻击样本库,并研究基于语义分析的检测模型,进一步提高模型的泛化性能,以及模型对不同类型漏洞攻击的检测能力。
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21
销售与市场(营销版)(2019年6期)2019-06-21
制导与引信(2017年3期)2017-11-02
网络安全技术与应用(2017年9期)2017-09-20
中国质量监管(2016年10期)2016-07-10
工业设计(2016年11期)2016-04-16
环境科技(2015年6期)2015-11-08
电网与清洁能源(2015年2期)2015-02-28
卫生职业教育(2014年20期)2014-05-16
湖南安全与防灾(2014年12期)2014-02-27
