
一种基于ARMv8架构CPU的算法加速方法
2023-09-27 08:16:06王静娇
雷达与对抗 2023年3期
孟 承,王静娇
(中国船舶集团有限公司第八研究院,南京 211153)
0 引 言
实时性是雷达信号处理领域一个不可忽视的指标,算法的运行速度是决定整个流程性能的关键。典型雷达的信号处理算法流程通常包括脉冲压缩、动目标显示、恒虚警率检测[1-2]等。这些算法中包含一些基础算法,例如三角函数、快速傅里叶变换、复数求模、拷贝等。目前,在ARMv8[3]架构的CPU平台上,除了基本的标准库外,还有一些开源的算法库可以使用,如NE10、FFTW、OpenCV[4]等。这些库函数可以满足雷达信号处理开发人员对算法正确性以及精度的需求,但是在处理速度上,部分库函数如三角函数、复数求模函数等在大规模流水使用时很难达到性能指标。
本文以基础函数atan2为例,对其性能进行优化和硬件平台实际测试,并与标准库函数进行性能对比,其他函数按类似的优化方法,同样可以得到性能提升。
1 加速原理介绍
(1)高速缓存
CPU内部与主存之间有一级、二级、三级高速缓存区,其特点是容量依次变大,运行速度依次降低,如图1所示。
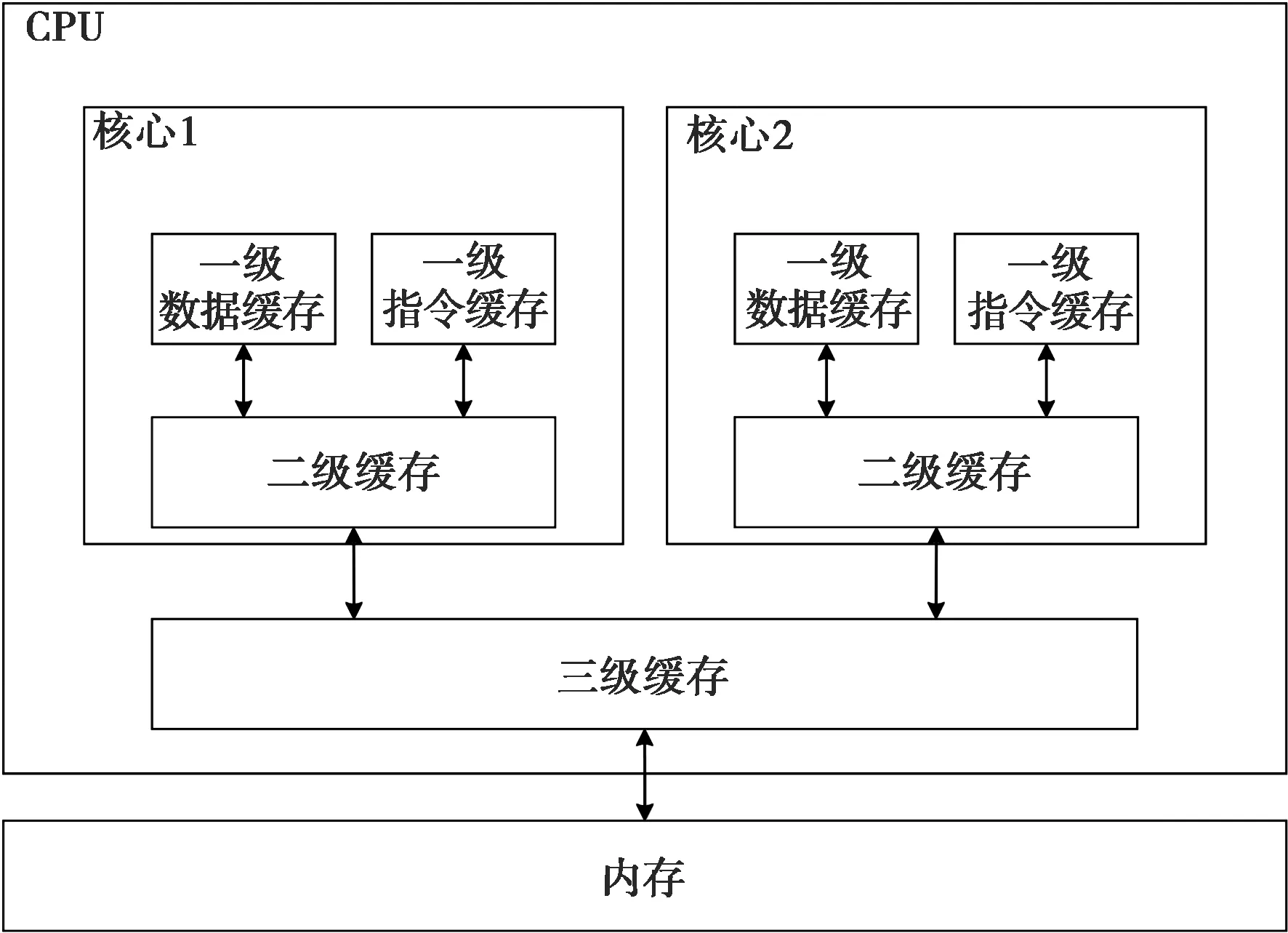
图1 CPU缓存结构
如图2所示,CPU整个工作流程包括取指、译码、执行和数据更新。由于CPU特殊的存储结构,指令和数据都需要从内存中按照三级缓存、二级缓存、一级缓存依次搬运,数据的搬运最小单位为块(通常为64字节),而不是以字节为单位[5]。CPU会先在最快的一级缓存中寻找需要的数据,如果没有发现,则继续往下一层寻找,以此类推。因此,针对CPU的性能加速可从以下几个方面进行:单个指令周期内完成尽可能多的操作;数据按照内存位置顺序处理,提高缓存命中率等。
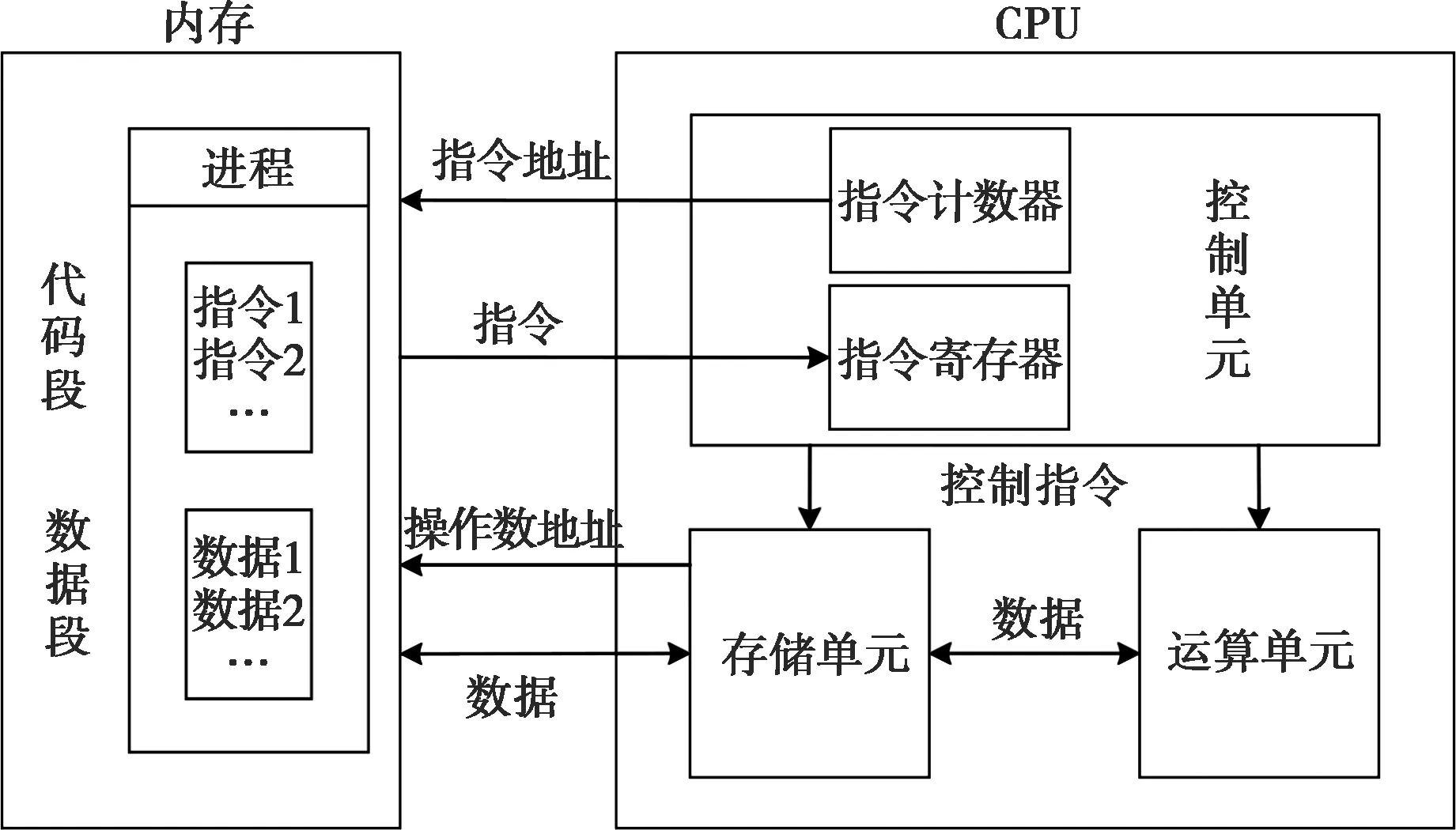
图2 CPU工作流程
(2)Neon指令集
Neon指令集是单指令多数据(Single Instruction Multiple Data,SIMD)技术在ARM上的实现,利用同一个命令控制多个单元以达到并行处理的效果,提供了宽度为128 bit的向量运算。
针对“单个指令周期内完成尽可能多的操作”,本文基于Neon指令集,在ARMv8架构CPU上重新实现基础函数,以达到加速效果。
2 算法具体设计
本文的atan2(y,x)功能实现基于OpenCV开源库的算法流程进行Neon指令重写,所有使用的函数皆由arm_neon.h头文件[6]中定义,主要流程如图3所示。
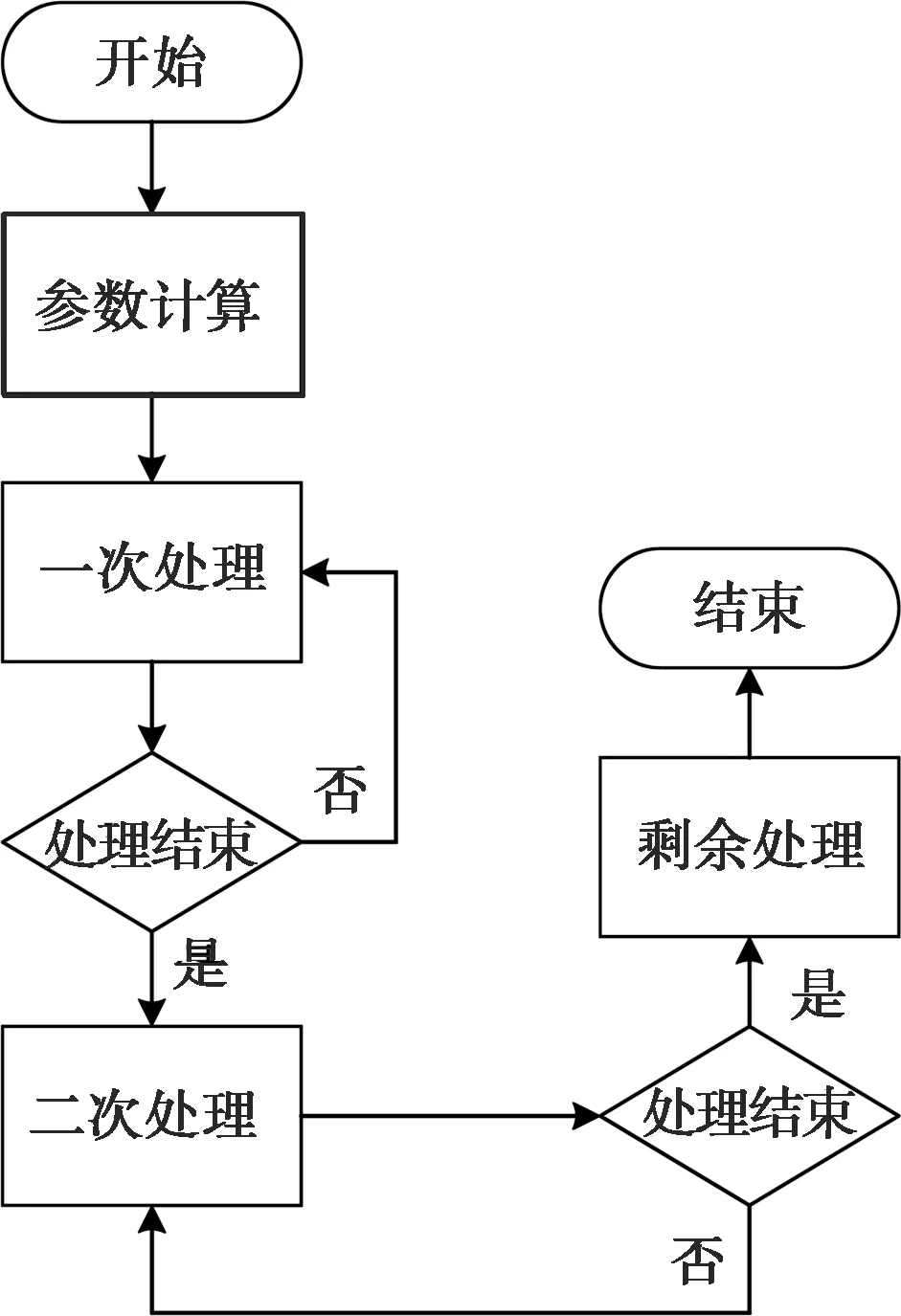
图3 算法主要流程
(1)参数计算
ARMv8架构CPU提供了32个128 bit的浮点寄存器,Neon指令集可以操作整个寄存器。本算法首先计算一次处理和二次处理的次数。一次处理每次以4个浮点寄存器为单位进行计算,即每次对64字节的数据进行操作。例如对32位float类型的数据进行加法操作,调用8个浮点寄存器,一次操作即可完成对16个浮点数与另外16个浮点数的加法计算。二次处理每次以单个浮点寄存器为单位进行计算,即每次对16字节的数据进行操作,一次操作可以并行计算4个浮点数。最后计算一次处理和二次处理后的数据剩余量,将未处理的长度信息传递给剩余处理环节,一般来说在16个字节以内。
(2)一次处理
处理流程如图4所示。

图4 atan2处理流程
首先是元素导入,利用vld1q_f32函数将要计算的数据导入到预先按照数据类型声明好的向量中,便于后续使用。
其次是条件语句转换,条件跳转是影响缓存不能命中的最大因素,所以这里考虑采用条件语句转换,以增加Cache命中概率,进一步提升运行性能。本算法进行转换时,先计算出各条件的系数(符合条件,系数值为1,否则为0),然后将各条件内的计算与其系数相乘,最后将所有的结果相加,例如条件A>B,可使用vcgtq_f32(A,B)函数计算该条件的系数(128位浮点寄存器的返回值由4组32 bit数据组成,符合条件时,每组数据所有bit位为1,否则为0);其次,使用vshrq_n_u32函数将系数返回值以组为单位右移31位,将返回值每组32 bit数据的大小转换为1和0两种,便于后续计算。
再次是相关计算,根据头文件约束的函数对向量寄存器进行加减乘除等运算来复现算法流程,包括向量加(vaddq_f32)、向量除(vdivq_f32)、向量乘(vmulq_f32)等。
最后是元素导出,计算过程皆在向量寄存器中进行,临时数据或者结果也保存在向量寄存器中。单次计算结束后需要使用vst1q_f32函数将向量中的结果数据导出至指定的数据空间。
(3)二次处理
二次处理的流程与一次处理相同,区别在于二次处理每次仅处理16字节的数据,寄存器使用量是一次处理的四分之一。
(4)剩余处理
在经过一次处理和二次处理后,剩余的数据长度一般不超过16字节,如果是32位float类型的数据,此时元素个数不超过4个。此时对剩余元素的计算直接使用OpenCV函数库原本的c语言算法实现即可。
3 测试方案与结果分析
测试环境如表1所示。

表1 测试环境
本文对比测试方案如下:
(1)创建float类型的数据数组A、B和C,数据为-500到500的随机数,测试时元素长度按照32/64/128/256/512/1 024/2 048/4 096/8 192依次设定;
(2)每次计算将数组中A和B的所有元素进行atan2(A,B)运算,结果保存至数组C中。每次时间测试进行10 000次,然后求每次计算的耗时平均值,单位为μs。分别测试两种计算方式的耗时,一种为直接使用math.h中定义的atan2函数计算,另一种即本文使用neon指令集改写的算法;
(3)选取1 024元素点的结果数据,分别将两种方式计算得出的结果保存至文件,然后由matlab进行对比分析。
图5为耗时对比图,表2为具体测试数据。可以看出,经过本文算法改写后,atan2函数的计算速度提升了1 000%左右。
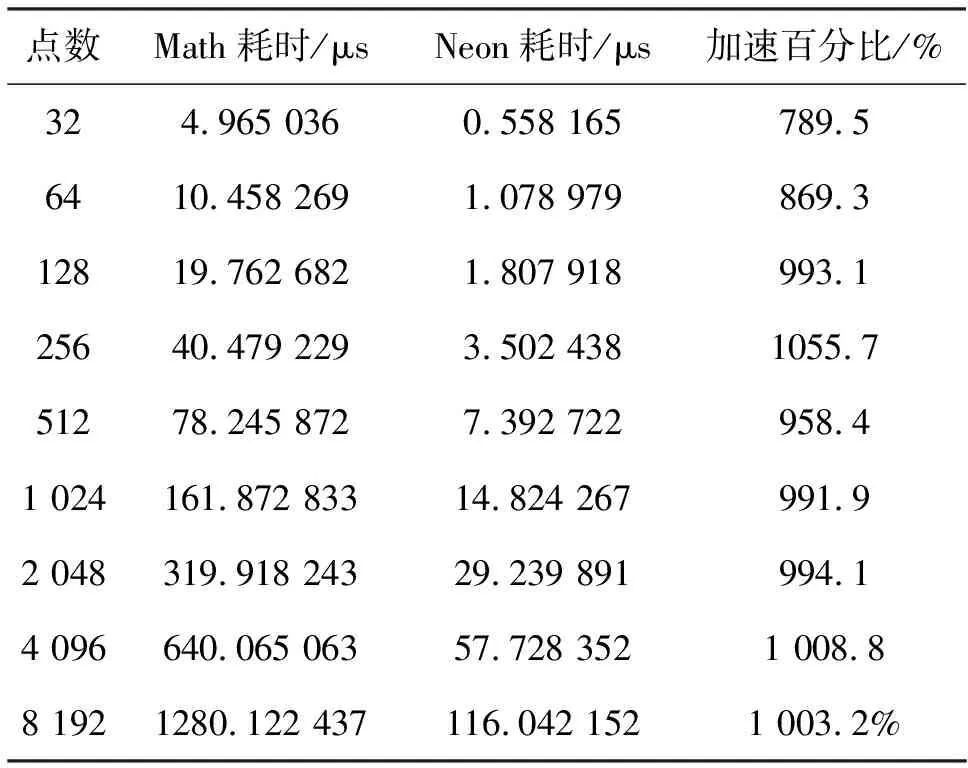
表2 耗时测试数据

图5 atan2函数耗时对比
由图6可以看出,本文改编的atan2算法与c标准库中的atan2函数计算结果基本一致。通过计算结果差值与c标准库计算的值作比,得出误差百分比,如图7所示,可看出结果误差比值不超过0.025%。
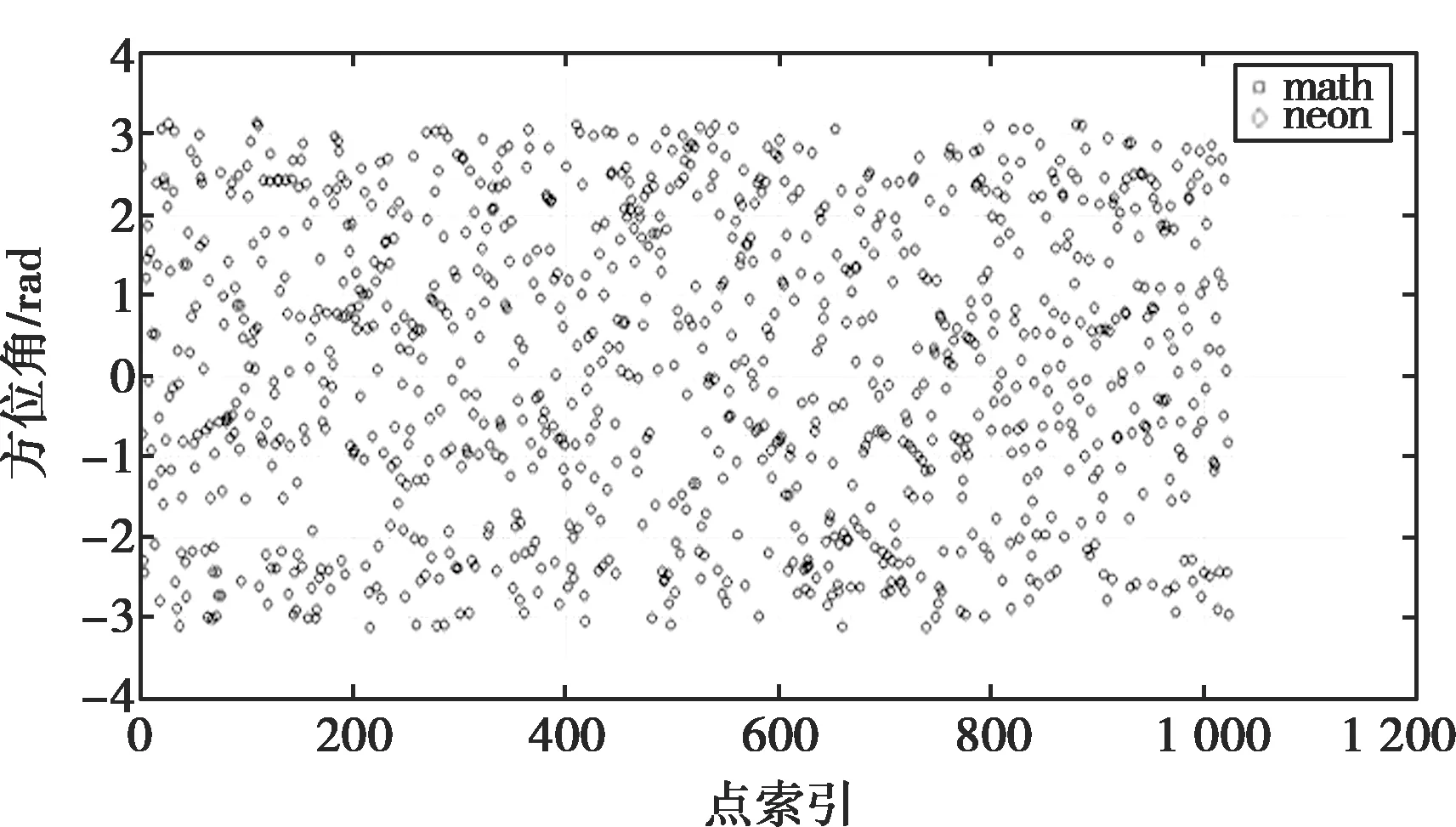
图6 atan2函数结果对比
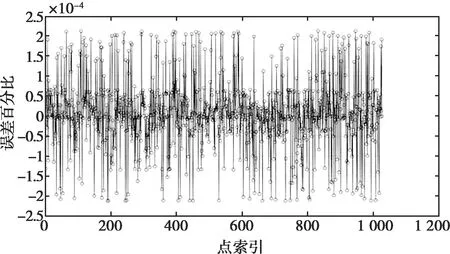
图7 atan2函数结果误差
4 结束语
本文基于ARMv8架构CPU平台,基于Neon指令集,以常用的atan2函数为例,对其进行算法优化和性能提升。实验结果表明,本文所采用的方式相比于c标准库对算法的运行速度有显著提升,也能保证一定的精度,同时该优化算法通过相似的步骤也可以推广到其他基础函数中,从而可以提升整个雷达信号处理算法的实时性。
后续工作可在两方面展开:一是可以采用更加灵活、高效的汇编语言或者使用内联汇编,以寻求更好的性能;二可以按照统一的标准接口规范,重写更多的基础算法,封装成库,便于雷达信号处理开发人员使用。
猜你喜欢
导航定位学报(2022年2期)2022-04-11 03:17:34
销售与市场(营销版)(2021年10期)2021-11-21 20:15:03
电脑报(2021年49期)2021-01-06 18:36:55
铁道通信信号(2019年4期)2019-10-10 03:42:38
销售与市场(营销版)(2019年6期)2019-06-21 01:16:38
网络安全技术与应用(2017年9期)2017-09-20 09:54:28
电测与仪表(2016年21期)2016-04-11 12:42:34
电测与仪表(2015年18期)2015-04-12 00:45:24
电子设计工程(2015年3期)2015-02-27 12:03:45
中国信息化周报(2014年19期)2014-07-22 15:43:11
