
基于钻进参数的煤岩界面识别系统研究
2023-09-27 05:16王杰
煤田地质与勘探 2023年9期
王 杰
(1.瓦斯灾害监控与应急技术国家重点实验室,重庆 400037;2.中煤科工集团重庆研究院有限公司,重庆 400039)
目前,煤矿瓦斯灾害治理的根本途径是煤层瓦斯抽采。其中,巷道法预抽邻近层及卸压层瓦斯是瓦斯治理中有效的区域性措施,该方法需在底(顶)板巷中向突出煤层施工大量的钻孔,通过钻孔工程的扰动使煤体部分卸压[1-3]。根据瓦斯抽采钻孔的施工要求,底抽巷穿层钻孔需进入煤层底板后再穿出煤层顶板不少于0.5 m。而现阶段的全液压回转钻机,在施工过程中无法准确地判断钻头层位,只能依靠人的经验知识来判断钻孔是否到达设计层位,一般根据钻孔泥浆颜色、排渣特征、钻机压力变化情况等信息来进行岩层或煤层识别,该方法受经验积累程度、信息滞后、干扰因素多的影响,判断结果往往具有一定的偏差、延迟和误差。若不能及时识别煤层的顶、底板,则可能出现钻孔不到位,导致抽采空白带的出现。
在工程实践中,基于钻进参数的地层信息识别方法广泛用于地层评价和界面识别[4-5]。在煤矿巷道围岩分类方面,提出了一种基于钻进参数的核模糊Cmeans 聚类(Kernel Fuzzy C-means,KFCM)算法的含煤地层岩性模糊识别方法,主要用于巷道围岩特征识别[6]。研发的煤矿巷道液压锚杆钻机随钻参数系统可通过计算破岩比能对岩石的力学性能进行识别[7]。在煤矿井下自动钻进方面,提出了一种基于地层识别的自动钻进控制方法,系统通过比功法自动识别3 种地层并匹配相应的钻进参数[8]。在地质钻进方面,采用数字式钻孔过程监测(Drilling Process Monitor,DPM)系统对香港地区复杂风化花岗岩地层的界面进行了成功识别[9]。在凿岩掘进方面,提出一种基于PCA-BP(Principal Component Analysis-Back Propagation)神经网络随钻参数岩性智能感知方法,通过凿岩钻机试验台采集的6 种敏感钻进参数对泥岩、砂岩和软弱层进行了识别[10]。在石油钻井方面,将3 种机器学习模型应用于基于钻进参数的地层岩性和顶部实时预测,研究成果表明优化后的人工神经网络模型(Artificial Neural Network,ANN)的精度性能优于自适应神经模糊推理系统(Adaptive Neuro-Fuzzy Inference System,ANFIS)和函数神经网络(Functional Neural Network,FNN)[11]。上述研究表明了基于钻进参数进行地层识别的可行性,但多数应用于巷道围岩分类、地质钻进、凿岩掘进和油气井等工程领域,在瓦斯抽采钻孔工程中的相关文献较少。
由于煤矿井下环境的特殊性和钻孔类型的多样性,钻进参数的获取和分析难度较大。因此,在煤矿井下钻进参数采集系统设计和煤岩界面识别方法中开展相关研究工作,并将机器学习算法应用于煤岩分类中,获得钻进参数和地层之间的分类关系,建立基于钻进参数的煤岩界面识别模型,以期实现煤岩界面的自动识别,为钻孔层位判定提供一套技术装备。
1 基本原理
1.1 钻进参数与破碎比功
对于回转切削的成孔方式,钻进过程包括回转和推进两个主要做功部分,钻进参数主要有钻杆转速、回转扭矩、推进力(钻压)和推进速度(钻速)4 个基本参数。研究表明某些岩石的物理性质与钻进参数之间存在一定的响应关系,在理想环境下,钻进参数的差异可明显区分不同的模拟地层,可较准确地对地层进行界面识别[12-14]。
在实际应用中,由于地质条件的复杂性及钻孔过程的随机性,钻机的工作参数是动态变化的,难以用准确的阈值范围来区分不同地层类型。而能量指标综合考虑了各种因素的影响大小,有效的避免了上述不利因素。在施工设备和技术水平固定的条件下,破碎单位体积岩石所需的能量与岩石物理力学性质之间存在一定的相关性,利用能量参数可较为精确的表征钻进过程中物理参数与地层信息之间的响应关系[13]。在各种能量指标中,破碎比功是近年来被许多科学家认可的比较合理的一种方法,即通过破碎单位体积岩石消耗的能量评价岩石破碎的难易程度。其计算公式[15-16]为:
式中:E为破碎比功,MPa;Fd为推进轴向力,N;Az为钻孔横截面积,m2;n为钻杆转速,r/min;Tr为钻机回转扭矩,N·m;vd为推进速度,m/min。
从式(1)可以看出,当钻孔横截面积确定后,破碎比功主要由4 个基本参数决定,是钻进参数的一个派生参数。因此,只需要在钻孔过程中采集钻进参数,就可得到顶板岩层和煤层的破碎比功值,近似反映当前钻进地层的强度大小,从而识别钻进地层。
1.2 支持向量机分类原理
支持向量机(SVM)是机器学习中的一种分类方法,本质上是一种按监督学习方式对数据进行二元分类的广义线性分类器。其基本思想是:对于线性可分的数据集,在原空间寻找两类样本的最优分类超平面,该超平面不仅能正确分类每一个样本,且使得每一类样本中距离超平面最近的数据到超平面的距离尽可能远。当线性不可分时,通过使用非线性映射将低维度输入空间的样本映射到高维度空间使其变为线性可分,从而在该映射空间中寻找最优分类超平面[17-18]。其分类原理如图1 所示。

图1 支持向量机分类原理Fig.1 Classification principle of SVM
图1 中,实心和空心圆点分别代表两类二维数据,分割它们的任一超平面可用线性方程描述为:
式中:w为法向量,决定了超平面的方向;x为二维数据构成的样本向量;b为位移量,决定了超平面与原点的距离,w和b这两组参数可通过训练得到。
对于训练样本(xi,yi),定义yi=1 时为正样本,yi=-1 时为负样本,则可用以下公式表达:
距离超平面最近的几个样本点使得yi(wTxi+b)=1成立,它们被称为“支持向量”,支持向量到超平面的距离之和被称为“间隔”。由解析几何中的距离公式可得到间隔d的表达为:
则优化目标为求间隔d最大值时对应w和b,显然,最大化间隔等于最小化||w||,也等价于最小化||w||2,加上约束条件后,求解的优化问题可以写成:
1.3 煤岩界面识别流程
煤岩界面的识别工作包括煤岩分类预测和界面位置确定两方面需求。整个过程的识别流程如图2 所示。其中,界面位置的确定由钻机的工况识别系统实现钻杆数量的自动记录,通过钻机液压系统的各种条件判断和逻辑规则识别进、退杆工况,在进杆时增加钻杆数量,实现钻孔深度的记录,具体原理在本文中不再详细赘述。
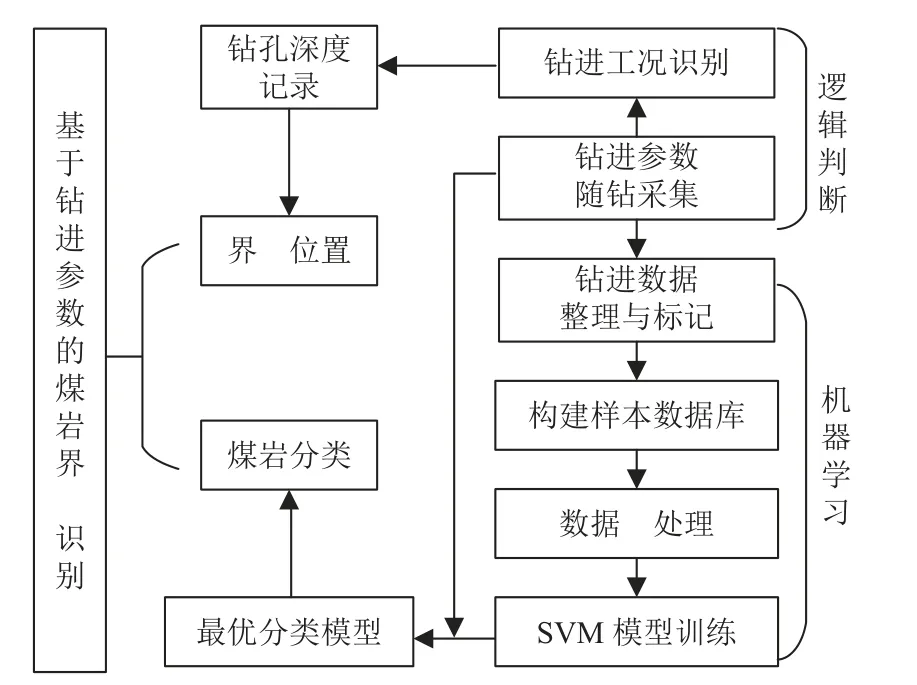
图2 基于钻进参数的煤岩界面识别流程Fig.2 Coal-rock interface recognition process based on drilling parameters
煤岩分类预测采用机器学习的方法进行自动识别,基于钻机工作时压力、扭矩和相关能量的动力传递过程,在钻机每根钻杆的钻进过程中,对钻机的4 个钻进参数和破碎比功开展随钻检测与自动采集。在此基础上,对钻进数据进行整理和标记工作,构建基于钻进参数的样本数据库和基于支持向量机的煤岩分类识别模型。通过模型训练和参数调整不断提高预测准确率和泛化能力,直到获得理想的输出为止,最后再根据此最优的模型训练结果去识别未知的钻进参数。
2 煤岩界面识别系统设计
2.1 系统总体方案设计
为了实现煤岩界面识别过程的自动化,设计了基于钻进参数的钻孔煤岩界面识别系统,整套系统由数据感知层、采集层和分析层组成。其中,数据感知层主要用于测量和变送钻机参数,是该系统的基础部分,由各类物理量传感器和相应的电气线路及液压管路组成。数据采集层主要用于钻进参数的采集与计算、钻进工况识别、钻孔深度记录和破碎比功曲线绘制,是整个系统的核心部分,由数据采集仪、工控计算机和相应的数据采集程序组成。数据分析层主要用于样本数据收集、数据学习、煤岩识别和结果输出,是该系统的人机交互部分,由专用软件和输入输出设备组成。整个系统的结构框架如图3 所示。
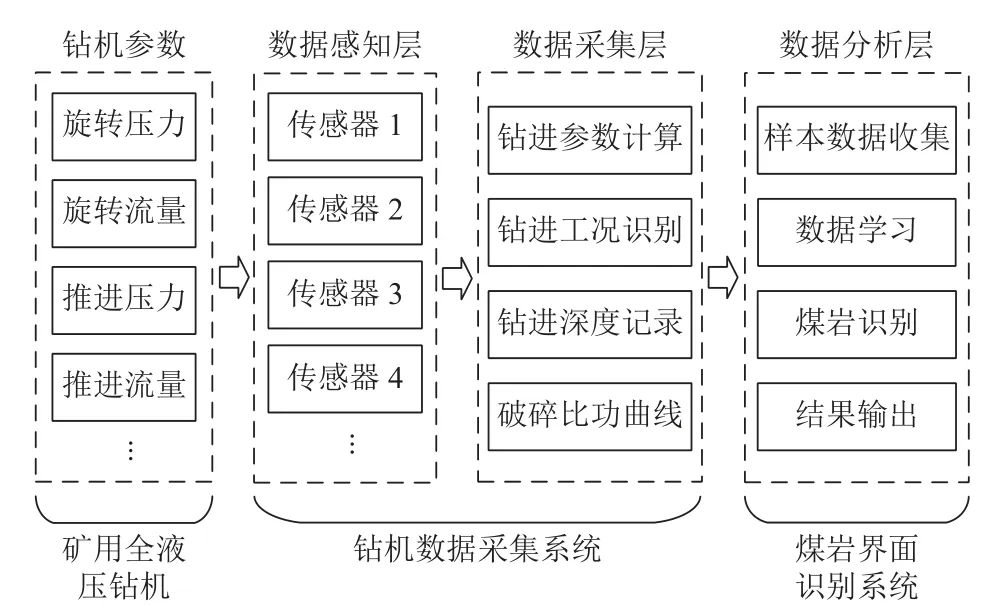
图3 基于钻进参数的煤岩界面识别系统架构Fig.3 Architecture of coal-rock interface recognition system based on drilling parameters
2.2 钻机数据采集系统设计
钻机数据采集系统主要用于采集钻机液压系统工作参数,同时完成数据计算、显示和记录等功能[19]。该系统由矿用隔爆兼本质安全型电控箱、矿用本质安全型传感器、矿用防爆手机和配套附件等组成,其中数据采集器、工控计算机和各类电气辅件均安装在矿用隔爆兼本质安全型电控箱内,从而满足煤矿井下防爆环境的使用要求;数据采集器通过安全隔离电路完成各类传感器的模拟量和频率量信号采集,再交由工控计算机进行数据处理和显示,所有的人机交互操作通过矿用防爆手机完成,其电气原理如图4 所示。
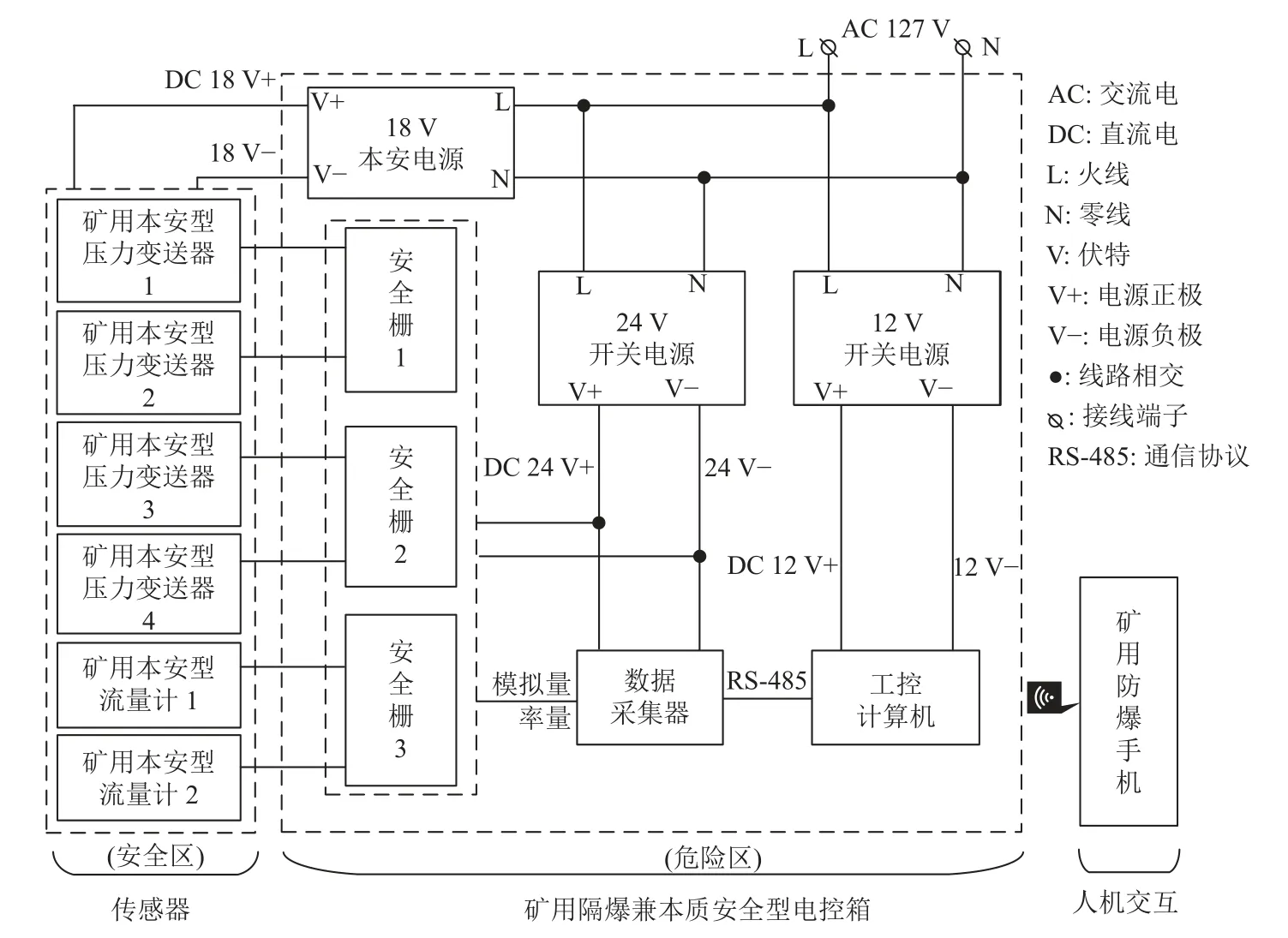
图4 钻机数据采集系统电气原理Fig.4 Electrical principle of drilling rig data acquisition system
2.3 煤岩界面识别软件功能设计
煤岩界面识别软件是基于钻进参数的数据分析类软件,运行在工控计算机的操作系统上。因此,在功能上应具备数据采集、钻进参数计算和数据分析与输出三大功能。其中,数据采集模块负责与数据采集器通信获取传感器输出信号,并实时显示传感器当前数值。钻进参数计算模块主要是读取配置参数、根据传感器数值实时计算各类钻进参数。数据分析与输出模块可完成样本标记、模型训练、煤岩识别结果输出等功能。整个软件的工作流程如图5 所示,工作界面如图6 所示。
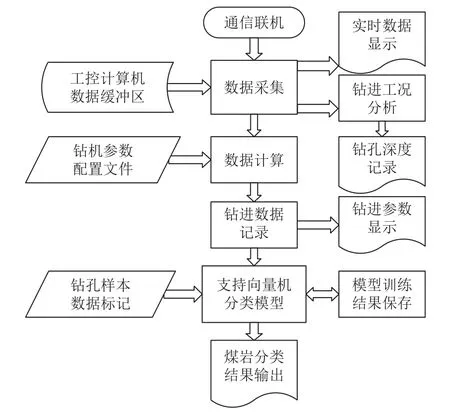
图5 煤岩界面识别软件工作流程Fig.5 Workflow of coal-rock interface recognition software

图6 煤岩界面识别软件工作界面Fig.6 User interface of coal-rock interface recognition software
3 现场试钻参数采集
3.1 试验地点及钻孔设计
煤岩界面识别系统的现场应用在河南省鹤壁中泰矿业有限公司实施,钻孔施工巷道为3116 上底抽巷,施工位置距二煤层底板约40 m,煤层走向132°~270°、倾向42°~160°、倾角4°~18°,平均煤层厚度8.1 m。预测瓦斯含量在6~8 m3/t,瓦斯压力0.60~0.74 MPa,煤的坚固性系数为0.8~1.5。
本次试验共设计4 个钻孔,1-3 号钻孔为试验钻孔,4 号钻孔为测试钻孔,各钻孔的设计参数见表1。

表1 钻孔设计参数Table 1 Design parameters of boreholes
3.2 钻机数据采集系统安装
钻进参数的获取采用间接测量法,即通过液压系统相关回路的流量和压力参数来计算对应的钻进参数。因此,钻孔施工前,需将对应的传感器安装在钻机的液压系统中,使用的传感器类型、数量及安装位置见表2。

表2 传感器参数及安装位置Table 2 Sensor parameters and positions
安装完毕后,为了确保传感器均能正常工作,进行了数据采集测试,如图7 所示。

图7 传感器数据采集测试Fig.7 Sensor data acquicition testing
3.3 钻进参数采集
现场施工采用ZYWL-4000 型矿用全液压钻机,钻孔过程中,控制钻机转速约65 r/min,钻压约14 MPa,所有钻进参数由钻机数据采集系统按设定的采样频率(1 Hz)自动记录,再用其平均值作为当前钻杆的钻进参数,试验现场如图8 所示。

图8 煤岩界面识别系统试验现场Fig.8 Experimental site of coal-rock interface identification
在1-4 号钻孔的每个钻进阶段,钻机数据采集系统实时显示传感器采集参数和钻孔深度,钻进参数中的转速和钻压两个参数由钻机液压系统控制,基本处于稳定状态;回转扭矩、推进速度和破碎比功3 个参数随地层和孔深的变化发生改变。钻孔结束后绘制出这3 个参数随钻孔深度的变化规律,如图9 所示。
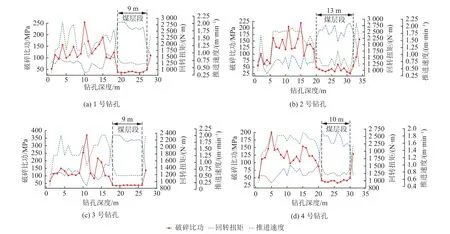
图9 钻进参数随钻孔深度的变化规律Fig.9 Variation law of drilling parameters with drilling depth
从图9 中可以看出以下规律。
(1)回转扭矩、推进速度、破碎比功3 个钻进参数的变化过程和地层之间具有明显的对应关系,这些参数在煤岩界面处均会出现明显的涨落,与煤岩分类结果之间具有较大的相关性。
(2)由参数变化过程可以判断出:1 号钻孔的实际钻孔深度为28 m,其中19~27 m 为煤层段,2—4 号钻孔的深度和煤层段可同理得出,该结果与现场有经验的司钻人员判断一致。
(3)整个钻进过程中,除开孔时的数据外,岩层中钻进的回转扭矩在1 200~2 800 N·m;煤层中钻进时基本在1 200 N·m,但2 号钻孔的回转扭矩存在较大波动。
(4)在稳压钻进模式下,推进速度会产生明显变化,在岩层中推进速度基本在0.3~1.0 m/min,在煤层中该值则为1.2~2.0 m/min,差异明显。
(5)在煤层中钻进的破碎比功基本处于30~60 MPa;在岩层中多数大于90 MPa,具有较强的区分性,但在岩石中开孔时的数值和煤层段存在重叠,可能出现误判。
4 模型训练与测试
4.1 支持向量机分类算法及训练步骤
采用Python 机器学习库Scikit-Learn 中的支持向量机算法(SVM)进行钻进参数的煤岩分类学习,相关步骤[18]如下。
(1)对样本数据集进行分类标记和标签的数字化处理,用不同的数字表示各种分类。
(2)数据集分割:将样本数据集分割为训练集和测试集,训练集用于模型训练和参数调整;测试集用于模型准确度评价。
(3)对数据集进行标准化或归一化处理。
(4)选择SVM 算法的核函数和对应的超参数。
(5)通过训练集获得最优超参数下的分类模型。
(6)利用测试集测试模型的分类准确度,观察预测结果。
具体流程如图10 所示。
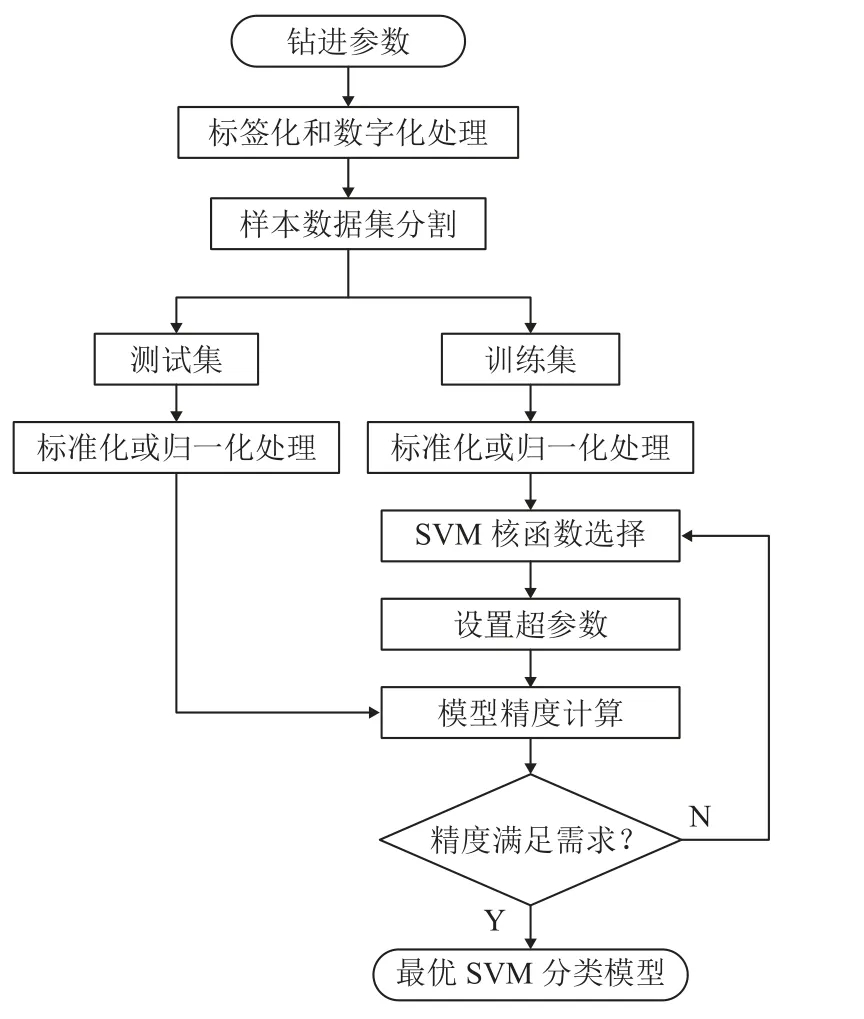
图10 支持向量机(SVM)模型训练步骤Fig.10 Model training steps of SVM
4.2 样本数据集的建立与分割
根据钻进参数与地层信息之间的响应过程,将3 个与煤岩分类结果具有较大相关性的钻进参数作为模型训练的特征参数。确定特征参数后将1-4 号钻孔的数据按顺序进行煤岩分类标记和标签数字化,用数字“0”和“1”分别作为岩石和煤层分类的数据标签,得到用于模型训练的样本数据集,见表3。

表3 样本数据集Table 3 Sample data sets
根据模型训练需要,再将数据集分割为训练集和测试集,各数据集的样本信息见表4,训练集和测试集的数量比例约为3∶1。
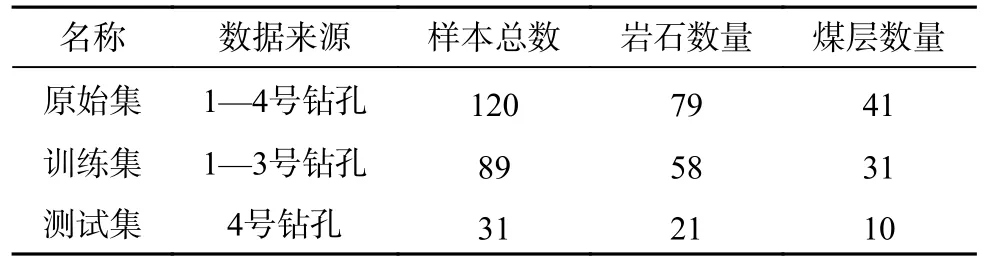
表4 数据集分类信息Table 4 Classification information on data sets
4.3 模型参数搜寻
模型参数搜寻主要是选择SVM 算法的核函数和对应的超参数,常用的核函数有线性核函数,径向基核函数(高斯核函数)和多项式核函数等,其中线性核函数主要用于线性可分的数据集,径向基是SVM 默认的核函数,多项式核函数可以将低维的输入空间映射到高维的特征空间。每种核函数都有其对应的调整参数,其中有两个重要的参数,即惩罚系数C和影响系数γ;C为分类误差的宽容度,数值越大则对误差的容忍程序越小;γ定义了单个样本对于整个超平面的影响大小,数值越大支持向量越少,越小则支持向量越多[20-21]。
模型参数的确定通过训练集获得,为了解训练集各样本点的分布规律,首先绘制了数据散点图,用黑色圆点表示岩石样本点,灰色圆点表示煤层样本点,则分布规律如图11 所示。该图可以表示3 个维度的信息:x轴为样本点的推进速度参数,y轴为回转扭矩参数,圆点的面积由每个样本点的钻进参数计算的破碎比功参数确定,面积越大则代表该样本点消耗的能量越高。
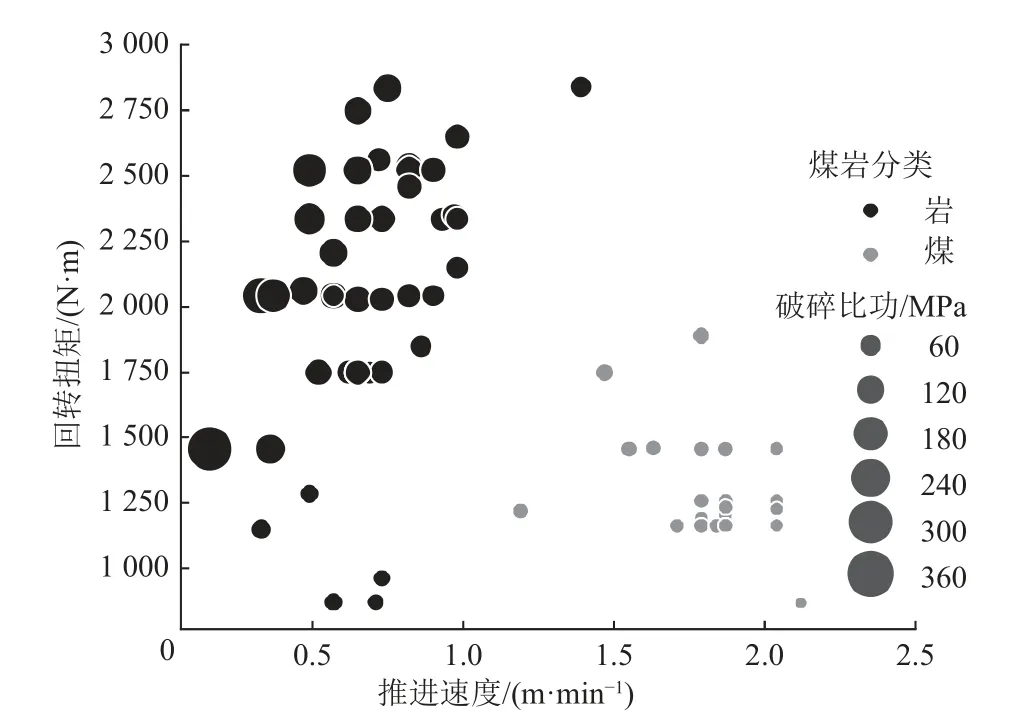
图11 训练集数据的散点分布Fig.11 Scatter plots of the training set data
从图11 中可以看出,岩石和煤层样本点之间具有明显的分界线,说明特征参数和分类结果之间为线性可分的关系,因此,使用SVM 中的线性核函数即可满足分类要求。
线性核函数可以调整的超参数只有惩罚系数C一个参数,采用网格搜索函数(GridSearchCV)在指定的参数范围内按步长依次调整参数并进行比较,直到从所有的参数中找到在验证集上精度最高的参数。设置搜索范围0.1~10.0,步长50,最终获得C的最佳参数为0.1。
4.4 模型精度测试
对于小样本数据,为了最大程度地验证模型的精确度和泛化能力,在模型训练时常采用交叉验证法划分训练集和验证集。考虑到训练集分类数据的不平衡性,采用分层K折交叉验证法,首先将训练集样本划分成K个大小相等的样本子集,并确保每一个子集中的样本类别分布与整个数据集的类别分布一致;依次遍历这K个子集,每次把当前子集作为验证集,其余K-1 个子集作为新的训练集,进行模型的训练和评估;最后把K次评估指标的平均值作为最终的评估指标。
本次训练进行了K=10 的交叉验证实验,具体分组结果如图12 所示。
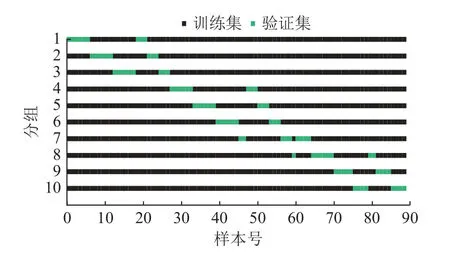
图12 训练集10 折交叉验证分组结果Fig.12 Cross validation results of training set (K=10)
图中横坐标代表样本号0~88,纵坐标代表10 次分组情况,用分组1~10 表示。其中,黑色部分为划分的训练集样本号,绿色部分为验证集样本号。分组确定后,再用同一测试集对所有分组进行模型评估,得到最终的测试结果见表5。
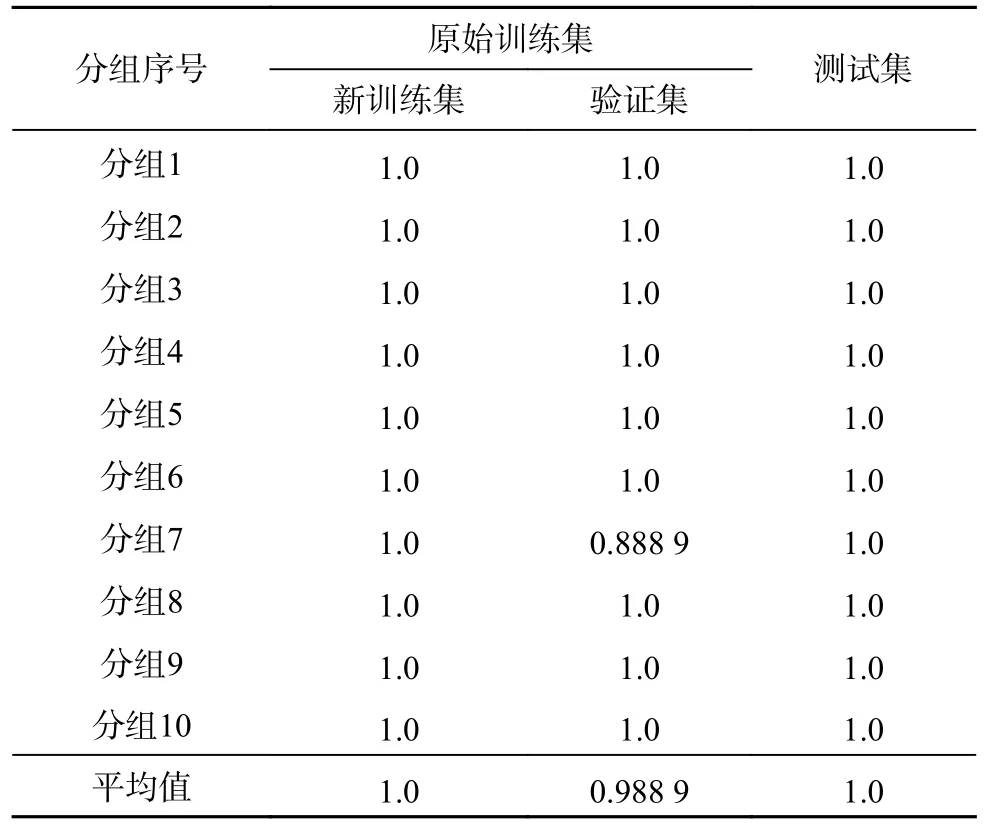
表5 10 折交叉验证模型精度Table 5 Model accuracy of cross validation model (K=10)
从表中可以看出,只有分组7 对应的模型验证集精度为0.888 9,其他9 组模型的验证集精度全部为1.0,验证集的平均精度为0.988 9;测试集的平均精度为1.0。
分组7 虽在验证集中出现了分类误差,但在测试集中分类全部正确。通过数据定位,找到分组7 中验证集分类错误的样本点序号为60,该样本为2 号钻孔第31 m 时的钻进数据,即该钻孔穿出煤层再次进入岩层中的第一根钻杆的钻进参数,该数据的分类错误主要是由于煤岩界面处的样本点数量太少导致的。
5 结论
a.开发的基于钻进参数的煤岩界面识别系统,初步解决了底抽巷穿层钻孔煤岩界面识别缺少技术手段的问题。通过分析钻进参数与煤岩地层之间的响应关系,找到了与地层变化相关性较大的3 个特征参数:回转扭矩、推进速度和破碎比功。其中,破碎比功是综合考虑钻进参数影响的能量指标,在煤岩识别方面,较其他两个特征参数具有更强的参考意义,但在钻孔开孔段的适用性较差。
b.在煤岩分类方面,采用的支持向量机(SVM)分类算法在3 个特征值的二元分类中具有非常高的准确性,特别适合小样本数据集的训练,使用线性核函数的分类模型在测试集中取得了100%的准确度,该结果也验证了特征参数和分类结果之间是线性可分的。
c.经现场试验验证,该煤岩界面识别系统可准确采集和记录钻机的钻进参数,并通过特征参数分析获得当前钻进地层的煤岩分类结果,从而指导司钻人员进行钻孔层位判定,确保钻孔达标,避免抽采空白带的产生。
d.现有煤岩分类模型的学习结果仅对应用煤矿的识别效果最佳。当在新钻场应用(地质条件改变)或改变钻机转速和钻压时,为保证识别的准确度,应增加2~3 个钻孔的钻进参数进行数据学习和模型更新。后续可开展半监督或无监督机器学习算法在煤岩分类识别中的应用,从而减少人的参与程度。
猜你喜欢
煤矿安全(2021年9期)2021-10-17
铁道建筑技术(2021年4期)2021-07-21
当代陕西(2020年13期)2020-08-24
安徽地质(2019年2期)2019-10-30
制造技术与机床(2017年5期)2018-01-19
潍坊学院学报(2016年2期)2016-12-01
凿岩机械气动工具(2016年1期)2016-11-11
凿岩机械气动工具(2015年3期)2015-11-11
江西煤炭科技(2015年2期)2015-11-07
江西煤炭科技(2015年1期)2015-11-07
