
基于一致性训练的半监督虚假招聘广告检测模型
2023-09-27 07:01:04王瑞琪纪淑娟郭亚杰
计算机应用 2023年9期
王瑞琪,纪淑娟,曹 宁,郭亚杰
(山东省智慧矿山信息技术重点实验室(山东科技大学),山东 青岛 266590)
0 引言
近年来,网络招聘行业发展迅速,“云招聘”、视频面试、人工智能(Artificial Intelligence,AI)面试等新型招聘形式涌现,网络招聘逐渐取代传统的线下招聘方式。根据国家工业信息安全发展研究中心的报告[1]显示,2020 年,中国线上招聘服务占整体招聘服务市场规模的32.3%,并且这一数字近年来持续上升。艾瑞咨询的调查[2]显示,2021 年上半年网络招聘网站月平均覆盖量超7 000 万人,用户数量突破8 000万。中国人民大学中国市场营销研究中心发布的《中国Z 世代求职趋势调查报告》[3]也显示,有76.1%的求职者通过网络招聘平台、搜索引擎等线上招聘渠道寻觅工作机会。以上种种数据均显示出网络招聘具有广阔的市场空间。
然而,网络招聘市场在迅猛发展的同时,在线招聘欺诈却越来越多。《2019 年中国互联网招聘行业市场研究》[4]的数据显示,在网络平台的各种不良体验中,求职者最介意企业信息不真实的情况,占比达34.8%;其次是个人信息遭泄露,占比31.8%。有的诈骗分子利用所谓的“体检费”“保证金”骗取求职者的钱财,还有一些诈骗分子在网络招聘平台发布高薪招聘信息,诱导受害人至境外从事非法活动。因此,有效地检测出虚假招聘广告不仅可以维护求职者的合法权益,也有利于维护公平公正的就业环境。
在现有的虚假招聘广告检测方法中,文献[5-10]中通过建立规则集来识别虚假招聘广告;文献[11-15]中利用机器学习检测虚假招聘广告;随着深度学习的发展,文献[16-17]中利用深度神经网络强大的学习能力来检测虚假招聘广告。上述检测算法均是基于有监督学习技术的检测方法。众所周知,训练基于有监督学习模型,特别是深度神经网络需要大量的有标签数据,但现实世界中标签数据的收集很困难,并且标注成本较高。因此,有监督训练容易受大量标注数据的限制。虽然半监督学习技术在图像检测与分类[18-21]、情感分析[22-23]等领域的应用已经趋向成熟,但在虚假招聘广告检测领域上的应用还尚待探索,并且现有基于半监督学习的方法仅在无标签数据上使用一致性正则化,忽视了Dropout 模型的随机性带来的在标签数据上训练和推理之间的不一致性问题,从而限制了模型性能的提高。
为了解决上述问题,本文提出基于一致性训练的半监督虚假招聘广告检测模型(Semi-Supervised fake job advertisements detection model based on Consistency training,SSC)。本文的主要工作如下:
1)提出一种基于一致性训练的半监督虚假招聘广告检测模型,可以有效解决标签数据较少带来的局限问题。
2)分别对标签数据和无标签数据应用一致性正则项,最大限度地减小在扰动样本上进行的模型预测之间的双向差异,有效提高了模型的学习能力。
3)在招聘广告数据集EMSCAD(EMployment SCam Aegean Dataset)上,SSC 整体性能优于基线模型,即使在标签数据极少的情况下虚假招聘广告检测的准确率也优于BERT(Bidirectional Encoder Representation from Transformers)[24]等模型。
4)由于现有的公开的虚假招聘广告数据集较少,并且本文方法主要使用招聘广告文本进行虚假招聘广告检测,与情感分类任务具有相似性,因此也在电影评论IMDB 数据集(Internet Movie DataBase)上进行了实验,验证了本文方法良好的可拓展性。
1 相关工作
按照检测过程中应用的人工智能方法不同,将现有的虚假招聘广告检测方法分为三类:1)基于规则的学习方法,主要考虑了写作风格、语言学特征和上下文特征;2)基于传统的机器学习方法,主要使用逻辑回归、随机森林、决策树、多层感知器等传统的机器学习技术检测虚假招聘广告;3)基于深度学习的方法,利用深度神经网络强大的学习能力进行虚假招聘广告检测。
1.1 基于规则的学习方法
针对在线招聘中虚假招聘广告越来越多的问题,并考虑到就业欺诈与垃圾邮件检测具有相似之处,Vidros 等[5]基于垃圾邮件检测建立了一个初步的规则集,为每个规则赋予一个评分因子,通过评分因子为每条数据计算欺诈总分。Habiba 等[6]将公司标志、就业类型、所需经验等7 个特征从文本转换为数字,在不进行任何自然语言处理的情况下对虚假招聘广告进行分类。针对在线招聘欺诈没有得到应有重视的问题,Vidros 等[7]定义并描述了在线招聘欺诈的特点,公开并评估了虚假广告公共数据集EMSCAD,通过对数据集的统计观察和经验评估,建立了一个由上下文、语言、元数据特征组成的规则集。针对现存的就业欺诈检测方法仅使用招聘广告中文本和结构信息,但没有考虑提供职位公司重要性的问题,Mahbub 等[8]集中在一种新的特征空间设计上,分别从数据集中提取公司名称和有关该公司的上下文信息,包括公司网站的URL(Uniform Resource Locator)、域名年龄、LinkedIn 页面的URL。Nindyati 等[9]提出一种基于行为活动上下文特征的虚假招聘广告检测算法,使用行为活动包括招聘广告的发布者、发布时间、发布间隔作为上下文特征进行虚假招聘广告检测。Lal 等[10]利用投票技术设计了一个基于集成学习的虚假招聘广告检测模型。
1.2 基于传统的机器学习方法
为了检测出就业欺诈,Alghamdi 等[11]使用支持向量机(Support Vector Machine,SVM)提取数据中的主要特征,提出一种基于随机森林分类器的检测模型;Dutta 等[12]使用单分类器包括朴素贝叶斯、多层感知器、K近邻、决策树和集成分类器包括随机森林、AdaBoost(Adaptive Boosting)、梯度增强分别进行虚假招聘广告的检测;Mehboob 等[13]使用朴素贝叶斯、K近 邻、决策树、SVM、随机森林和XGBoost(Extreme Gradient Boosting)作为分类器,采用两步策略找出最佳的特征组合;Shree 等[14]针对虚假招聘广告损害求职者利益的问题,提出基于机器学习技术的虚假招聘广告检测算法,包括逻辑回归、K近邻、随机森林,使用文本和元数据信息进行虚假招聘广告检测;Tabassum 等[15]使用了7 种机器学习算法检测虚假招聘广告,包括逻辑回归、AdaBoost、决策树、随机森林、LightGBM(Light Gradient Boosting Machine)、梯度增强等,并比较了不同机器学习算法的性能和被移除的特征对检测精度的影响。
1.3 基于深度学习的方法
针对欺诈规则容易被人学习从而限制检测性能提高的问题,Kim 等[16]提出基于层次聚类的深度神经网络来检测虚假招聘广告,通过层次聚类得到的簇预训练初始权重,进而计算欺诈候选预测,利用聚类和深度神经网络揭示了欺诈之间存在的内在关系。由于虚假的招聘广告往往包含一些与特定领域实体有关的不可靠事实,例如技能、行业、薪酬等方面,针对这一问题,Goyal 等[17]考虑特定领域实体之间的关系,提出基于特定领域常识的虚假招聘广告检测算法,通过构建事实验证数据集,使用自动事实检查算法查找缺失的事实;另外,使用预训练好的BERT 为所有招聘广告生成上下文,提取数据的元特征,包括教育程度、工作地点等。
1.4 小结
综上所述,在基于规则的学习方法中,规则集的制定耗时耗力并且静态规则集拓展性较差,难以应用到新数据集。基于传统的机器学习方法和基于深度神经网络的方法需要大量的标签数据。但现实世界中标签数据的收集耗时、耗力、成本较高,且需要专家经验[25],因此传统的机器学习方法和基于深度神经网络的方法受到了标签数据较少的限制。
半监督学习技术[26]能有效利用标签数据和无标签数据,只需要少量标签数据和大量无标签数据就有很好的效果,更适用于现实世界的应用。但目前先进的基于半监督学习的方法[23,27-28]忽略了Dropout 模型的随机性带来的训练和推理之间的不一致性。
与现有半监督学习算法仅在无标签数据上应用一致性正则项不同,本文提出的基于半监督学习技术的虚假招聘广告检测模型(SSC)同时在标签数据和无标签数据上进行一致性训练,并且考虑了标签数据进行训练和推理之间的双向差异,将一致性正则化技术同时应用于标签数据和无标签数据,提高了模型的学习能力。
2 SSC
本章将详细介绍基于一致性训练的半监督虚假招聘广告检测模型(SSC)。如图1 所示,SSC 主要分为3 个模块:无监督训练模块、有监督训练模块和联合训练模块。无监督训练模块产生无监督损失Lu;有监督训练模块产生有监督损失Ls;联合训练模块将无监督损失Lu和有监督损失Ls进行整合得到半监督损失Lsemi,最后使用半监督损失进行优化整个模型。
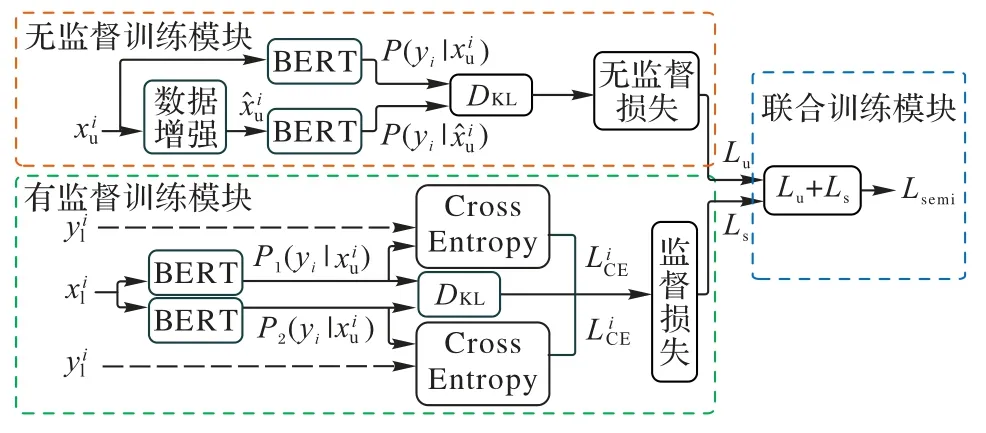
图1 SSC结构Fig.1 Structure of SSC
2.1 无监督训练模块
无监督训练模块的目的是获得无标签数据产生的无监督损失。无监督训练模块使用数据增强、KL(Kullback Leibler)散度计算等操作。将无标签数据输入Augmentation 模块进行数据增强,得到增强后的样本。回译技术[29]是数据增强的一种,能将一种语言A翻译成语言B,再从语言B翻译回语言A,如图2 所示。回译技术可以在保留句子原始语义的同时生成不同的释义,还可以保留句子的上下文信息。本文在Augmentation 模块使用Hugging Face发布的预训练模型mbart-large-50-many-to-many-mmt[30]进行离线回译。BERT 采用深层的双向Transformer 组件构建整个模型,并使用特殊标记[SEP]、[CLS]等聚集整个序列表征,可以生成融合上下文信息的语言表征。鉴于BERT 强大的编码能力,本文将和增 强后的样本分别送入BERT 编码器,通过BERT 的随机掩码机制进行预测,得到输出分布散度计算模块通过计算输出分布的KL 散度来最小化增强样本与原始样本之间的差异,得到无监督训练模块的损失Lu,如式(1)所示:
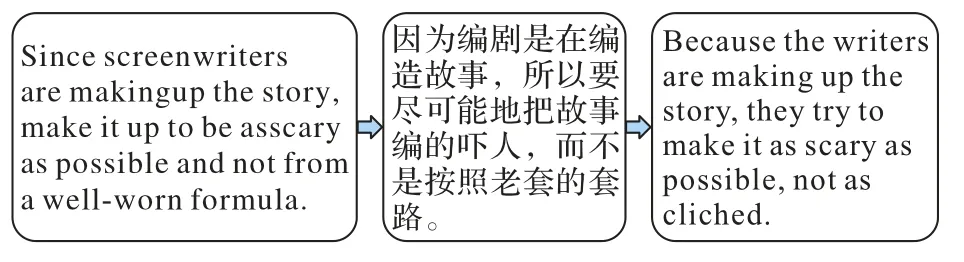
图2 回译示例Fig.2 Example of back translation
2.2 有监督训练模块
有监督训练模块旨在通过计算KL 散度和交叉熵损失从标签数据中获得有监督损失。在训练深度神经网络时,正则化技术[31]对于防止过拟合和提高深度模型的泛化能力必不可少,使用正则化技术可以减少Dropout 模型的训练和推理之间的不一致性,最大限度地减少在输出扰动样本上进行的模型预测之间的双向差异[32],有助于更好地从标签数据和无标签数据进行学习。受对比学习的启发,本文对有标签数据使用Dropout 一致性正则化方法,并使用Wu 等[33]提出的R-Drop 计算双向KL 散度作为正则化损失,如图3 所示。将有标签数据分别输入BERT 两次,由于Dropout 机制会随机使一些神经单元失效,因此会产生两个不同的概率分布,将这两个概率分布输入KL 散度计算模块DKL,通过计算双向KL 散度来最小化两个概率之间的双向差异,同时结合标签yi计算交叉熵损失,相加得到有监督部分的损失Ls,如式(2)所示:
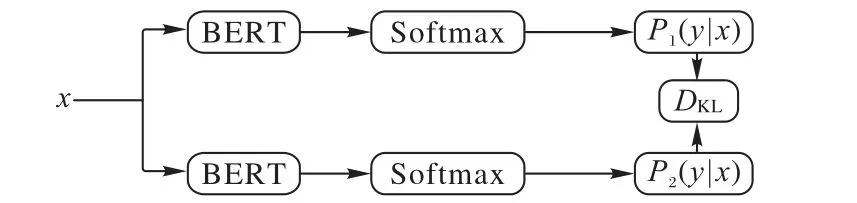
图3 R-Drop的简单框架Fig.3 Simple framework of R-Drop
2.3 联合训练模块
联合训练模块的目的是同时整合从有监督训练模块得到的有监督损失Ls和无监督训练模块得到的无监督损失Lu,相加得到最终的半监督损失Lsemi,最后用半监督损失优化整个模型,如式(3)所示。SSC 使用半监督损失优化模型,有效利用了标签数据的信息,又充分利用了无标签数据的信息,可以使模型学习到更充分全面的信息。
3 实验与结果分析
3.1 数据集
本文在实验过程中使用了两个公开数据集。第1 个数据集是由Vidros 等[7]发布的EMSCAD,包括17 880 篇来自真实世界的招聘广告,原始数据集分布如表1 所示,数据集的详细信息如表2 所示。由于目前公开的就业欺诈检测的数据集较少,并且本文主要使用招聘广告文本进行虚假招聘广告检测,与情感分类任务具有相似性,因此,本文选择了电影评论IMDB 数据集[34]进一步验证模型的有效性和可扩展性。IMDB 数据集包括50 000 条来自互联网电影数据库两极分化的评论,数据集的详细信息如表3 所示。

表1 原始数据集分布Tab.1 Distribution of original datasets
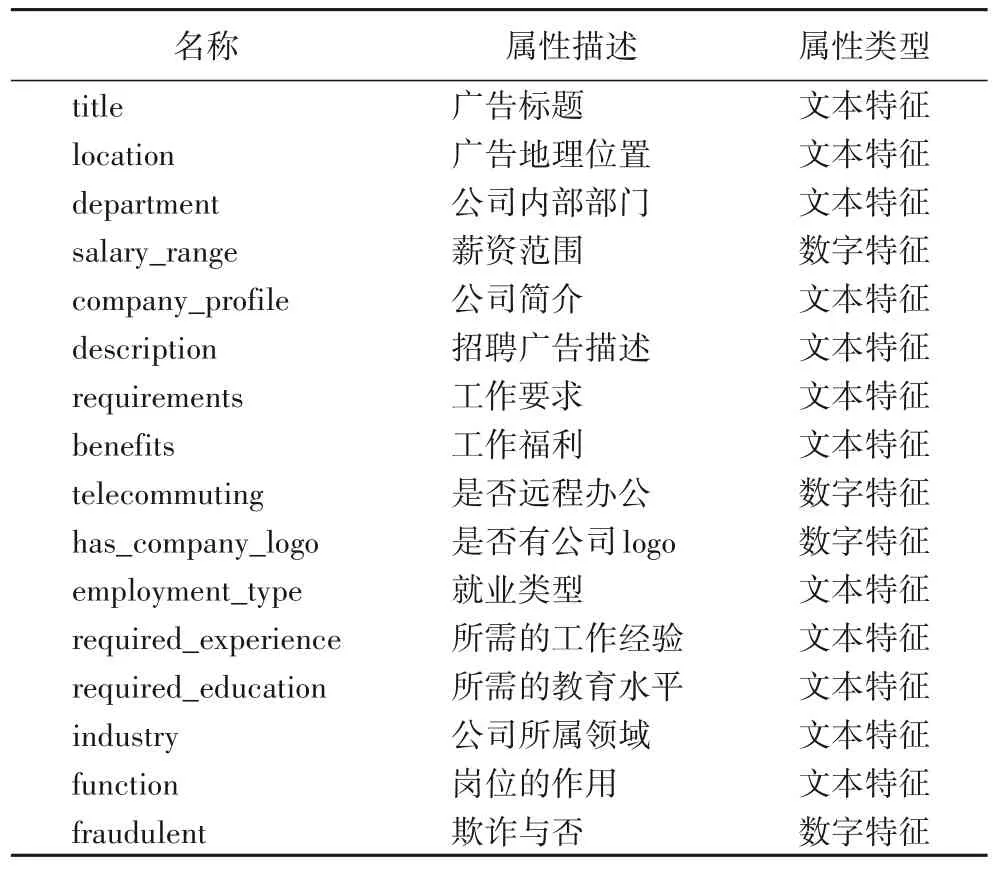
表2 EMSCAD的详细信息Tab.2 Detailed information of EMSCAD

表3 IMDB的详细信息Tab.3 Detailed information of IMDB
本文参考Xie 等[23]的数据集划分方法,从完全监督数据集中随机采样一定数量的平衡样本数据,测试集和无监督数据集采用上述同样的划分方法。在EMSCAD 上,本文在有监督训练过程选择20 条平衡样本数据(10 条正样本、10 条负样本);同时,在无监督训练过程中选择1 732 条平衡数据(866条正样本、866 条负样本)作为样本。在IMDB 数据集上,本文在有监督训练过程同样选择20 条平衡样本数据(10 条正样本、10 条负样本),在无监督训练过程中选择20 000 条平衡样本数据(10 000 条正样本、10 000 条负样本)。
为了进一步研究标签数据的样本数对实验结果的影响,在保持无监督训练过程中数据样本设置不变的情况下将20条有监督训练数据分别扩大5、10、15、20 倍得到4 个数据集。此外,为了验证本文的SSC 在整个数据集上的性能,在标签数据20 时,使用原始完整数据集作为无监督训练过程中的无标签数据集进行了实验。在EMSCAD 和IMDB 上构建的数据集详细信息如表4 所示。
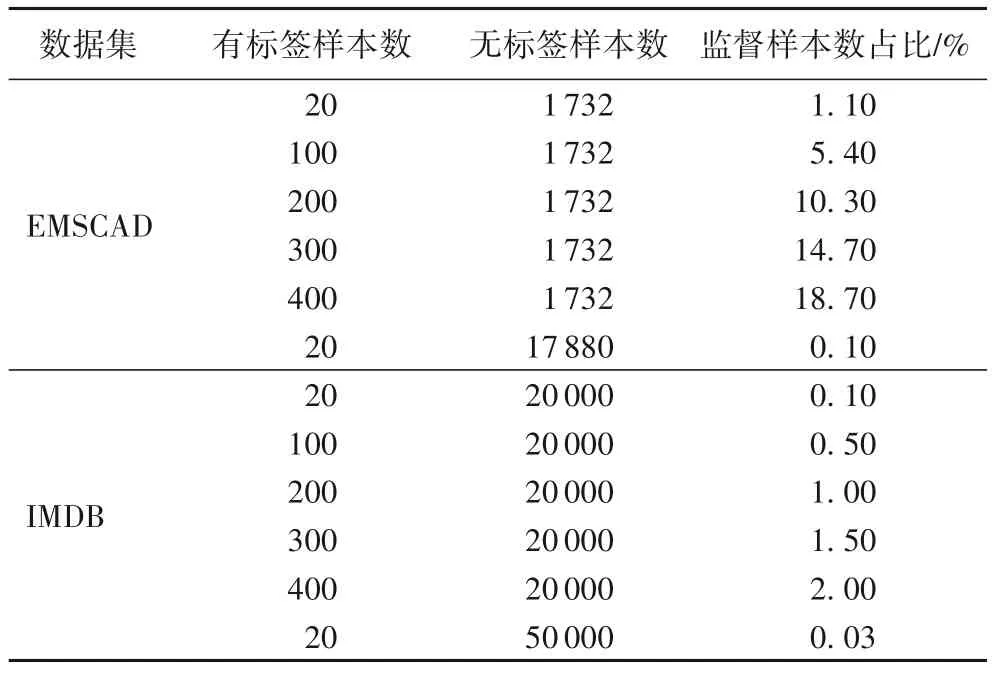
表4 基于EMSCAD和IMDB构建的数据集及其分布Tab.4 Datasets and distributions based on EMSCAD and IMDB
3.2 评价指标
本文采用4 种评价指标来衡量模型在虚假招聘广告检测任务上的效果,分别是:虚假招聘广告检测的准确率Acc、精确率P、召回率R和F1 值,针对虚假招聘广告检测问题,这4 种评价指标的计算方法如式(4)~(7)所示:
其中:TP(True Positive)为正确检测的虚假招聘广告数;TN(True Negative)为错误检测的虚假招聘广告数;FP(False Positive)为错误检测的真实招聘广告数;FN(False Negative)为正确检测的真实招聘广告数。
3.3 对比实验与参数设置
将本文算法与以下4 种算法进行对比:
1)随机森林:一种集成学习算法,以决策树为基分类器,通过投票的方式输出结果,解决了决策树性能瓶颈的问题,对噪声和异常值有较好的容忍性,对高维数据分类问题具有较好的可扩展性。
2)支持向量机(SVM):建立在统计学习理论基础上的一种数据挖掘方法,SVM 的机理是在空间中寻找一个满足分类要求的最优超平面,使该超平面在保证分类精度的同时,还能使超平面两侧的空白区域最大化。
3)BERT[24]:是谷歌提出的通用预训练语言模型,利用语言遮掩模型(Masked Language Model,MLM)进行预训练,并采用深度Transform 组件构建模型,在语义捕捉方面具有强大的能力,在大多数自然语言处理任务上,BERT 取得了很好的效果。
4)UDA(Unsupervised Data Augmentation)[23]:使用随机增强和反向翻译等先进的数据增强方法代替简单的增强方法,为无标签数据添加高质量的噪声来提高一致性训练效果。在半监督文本分类和情感分析领域,仅使用少量标签就取得了优越的效果。
随机森林和SVM 是经典的机器学习算法,BERT 是近几年深度神经网络中优秀的预训练语言模型,以上3 种均是有监督学习模型;而UDA 是现有情感分类方法中较先进、新颖的半监督学习框架。因此,本文选择它们作为基线算法。
本文实验中涉及学习率、序列最大长度、λ、Dropout 概率等参数,多数参数遵循UDA 模型的默认参数设置,少数具体的参数设置如表5 所示。

表5 实验参数设置Tab.5 Experimental parameter setting
3.4 实验结果与分析
本文分别在EMSCAD 和IMDB 数据集上进行了实验并对实验结果进行了详细分析。表6 是标签数据分别为20、100、200、300、400 时的实验结果。
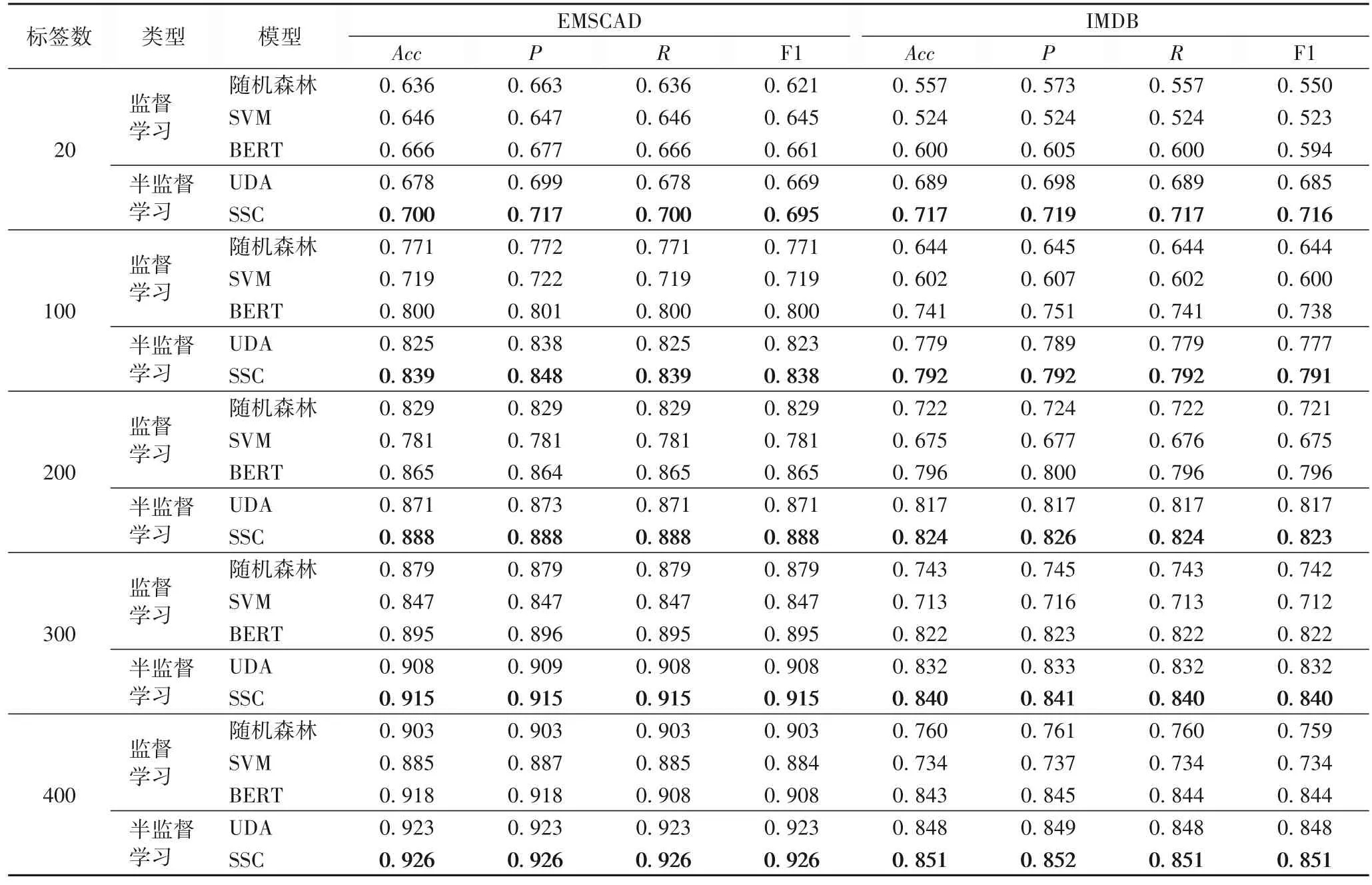
表6 标签数不同时EMSCAD和IMDB上的实验结果Tab.6 Experimental results with different number of labels on EMSCAD and IMDB
可以看出,本文提出的SSC 在EMSCAD 和IMDB 数据集上均优于基线比较算法。与传统的机器学习模型随机森林和SVM 相比,SSC 具有明显的优势;与最近流行的强基线模型BERT 和UDA 模型相比,SSC 也取得了最好的检测效果。
在EMSCAD 中,招聘广告以文本的形式呈现,并且大多数以中性的语言进行描述,招聘广告文本中不存在感情极性,这使得真实的招聘广告和虚假的招聘广告更难以区分。但在标签数据极少的情况下,本文的SSC 与先进的半监督学习方法相比性能仍有提升,进一步说明了SSC 的有效性。在EMSCAD 上,当标签数据仅为20 条时,SSC 与传统的机器学习方法中表现最好的SVM 和深度学习模型BERT 相比,准确率提高了5.4 和3.4 个百分点,说明了半监督学习技术能有效地利用无标签数据,解决标签数据不足带来的局限问题。与次优的UDA 相比,SSC 的准确率提高了2.2 个百分点,说明SSC 在标签数据极少的情况下的有效性。
与EMSCAD 类似,IMDB 数据集中的电影评论也是文本形式;与EMSCAD 不同,这些电影评论信息中带有感情极性。在IMDB 数据集上,当标签数据仅为20 条时,SSC 与传统的机器学习方法相比具有明显的优势,与机器学习方法中表现最好的随机森林模型相比,准确率提高了16.0 个百分点,与深度学习模型BERT 和UDA 模型相比,准确率提高了11.7和2.8 个百分点。因此,可以得出如下结论。
结论1 SSC 不仅可以用于虚假招聘广告检测,还可以应用于其他基于文本的分类任务中,具有良好的扩展性。
从表6 还可以看出,在EMSCAD 和IMDB 数据集上,传统的机器学习模型表现较差,且SVM 模型表现最差。随着标签数据个数的增加,在EMSCAD 和IMDB 数据集上准确率、精确率、召回率和F1 值都在逐步上升,并且SSC 始终表现最好,UDA 模型的表现次之。整体上,在标签数据较少时,SSC与其他基线模型相比具有明显的优势;随着标签数据个数的增加,SSC 的性能与BERT、UDA 强基线模型相比性能差距在逐渐缩小。因此,可以得出如下结论:
结论2 SSC 在标签数据极少的情况下更具有优势。
为了进一步验证模型的性能,本文在完整的原始数据集上进行了实验,由于随机森林、SVM 和BERT 模型不使用无标签数据训练模型,且标签数据为20 时的实验结果已在表6列出,因此本文单独对原始数据集上的实验结果进行了统计分析,如表7 所示。
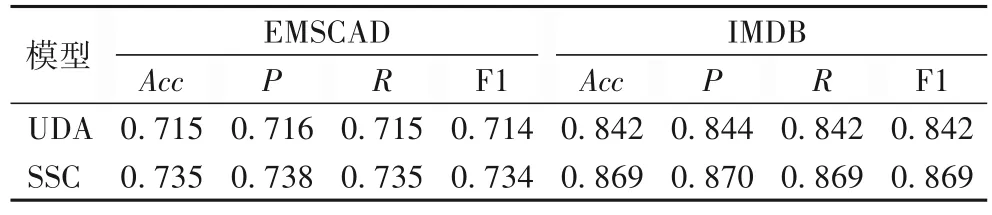
表7 标签数为20时,UDA和SSC在原始数据集上的结果对比Tab.7 Comparison of UDA and SSC results on original datasets when number of labels is 20
从表7 可以看出,在EMSCAD 和IMDB 数据集上,SSC 整体上优于UDA 模型。与强基线模型UDA 相比,SSC 的准确率提高了2.0 和2.7 个百分点,有效地验证了它在原始完整数据集上的有效性。参考表6 可以看出,在EMSCAD 上,使用原始数据集作为无标签数据可以略微提升模型的性能;在IMDB 数据集上,使用原始数据集可以显著提升模型的效果。这是因为EMSCAD 是极不平衡的数据集,而IMDB 的原始数据集是平衡数据集,当无标签数据中的类别分布严重不平衡时,半监督学习技术就失去了应有的优势[35]。未来旨在设计更普适的半监督学习检测算法,更好地解决无标签数据中出现不可见类和类别严重不平衡的问题。
结论3 SSC 在原始完整数据集上仍具有较好的表现效果,在无监督训练过程中增加无标签数据且无标签数据类别平衡时可以显著地提升检测效果。
3.5 可视化分析
为了进一步分析SSC 的有效性,本文在标签数分别为20和400 时在EMSCAD 上应用t-SNE[36]方法,将SSC 和UDA 学习到的特征表示进行可视化,如图4 所示。
图4(a)、(b)分别是标签数为20 时UDA 和SSC 学习到的特征可视化。可以看出,SSC 学习到的特征表示优于UDA 学习到的特征表示。这是因为从图4(a)可以看出,有较多特征被错误分类,且类别之间的间隔比较模糊,可区分性较低。相较于图4(a),图4(b)中虽然也存在特征被错误分类的情况,但被错误分类的特征大大减少并且类别之间的间隔比图4(a)更明显。
图4(c)、(d)分别是标签数据为400 时UDA 和SSC 学习到的特征可视化。可以看出,当标签数据增多时两者都可以学习到更准确的特征表示;但本文的SSC 学习到的特征更准确,类别之间的距离更明显,并且被错误分类的特征更少。这是因为本文使用KL 散度最大限度地缩小了训练和推理之间的双向差异,缓解了Dropout 模型的随机性带来的训练和推理之间的不一致。因此,可以得出如下结论:
结论4 SSC 可以更准确地学习招聘广告文本的特征表示,因此检测虚假招聘广告的效果更好。
3.6 消融实验
为了验证SSC 中各模块的有效性,在EMSCAD 和IMDB数据集上通过简化模型分别进行了消融分析,其中:EMSCAD 的有标签数为20,无标签数为1 732;IMDB 数据集的有标签数为20,无标签数为20 000。实验结果如图5 所示。简化模型如下:

图5 模块消融分析Fig.5 Module ablation analysis
1)SSC:包含所有模块,使用无监督损失和有监督损失共同优化模型。
2)w/o R:删除有监督训练模块中的KL 散度计算模块,使用有监督训练模块中的交叉熵损失和无监督训练模块中的无监督损失共同优化模型。
3)w/o U:删除无监督训练模块,使用有监督损失优化模型。
4)w/o S:删除有监督训练模块,使用无监督损失优化模型。
从图5 可以看出,在SSC 的基础上删减模块之后,模型在EMSCAD 和IMDB 数据集上的准确率都有一定程度的下降,其中w/o S 的准确率最低,说明有监督训练模块产生的有监督损失对模型优化有着重要的作用。在EMSCAD 上w/o U 的准确率高于w/o R,但在IMDB 上w/o U 的准确率更低,这表明在EMSCAD 上KL 散度计算模块比无监督训练模块更重要,而在IMDB 上无监督训练模块对准确率的影响更大。在EMSCAD 和IMDB 数据集上,w/o R 和w/o U 的准确率均低于SSC,说明通过KL 散度计算模块计算双向KL 散度可以有效减小模型预测时的双向差异,提高模型的学习能力,而无标签数据可以在标签数据有限的情况下帮助模型学习到更好的表示,有效提高模型的检测效果。因此,可以验证SSC 中的模块在检测性能提升方面的有效性。
3.7 时间效率分析
本节对SSC 和基线模型在EMSCAD 和IMDB 数据集上的时间效率进行了对比,各个模型的运行时间如表8 所示。

表8 时间效率比较分析Tab.8 Comparative analysis of time efficiency
模型在IMDB 上的运行时间均高于EMSCAD,原因在于IMDB 的数据量大于EMSCAD,运行时间会随着训练数据的增加而增加。不论在哪个数据集上,在基于监督学习技术的模型中,SVM 的运行时间都是最短的。相对地,采用了12 层双向Transform 组件构建的BERT 模型的运行时间最长,而且是传统机器学习方法105倍。基于监督学习技术模型的时间效率优于基于半监督学习技术的模型,这是因为基于半监督学习技术的模型要同时联合有监督模块和无监督模块进行模型训练。相较于BERT 模型,在EMSCAD 上,基于半监督学习技术的模型UDA 和SSC 的运行时间虽然是BERT 模型的2.5 倍和5.5 倍,但它们仍处在相同的数量级。所以,对比深度监督学习方法,半监督学习技术用时间效率的降低换取精度的提高是值得的。
4 结语
本文提出了一种基于一致性训练的半监督虚假招聘广告检测模型(SSC),同时对标签数据和无标签数据应用一致性正则化技术,通过联合训练的方式整合有监督损失和无监督损失得到半监督损失,使用半监督损失对模型进行优化。在EMSCAD 上的实验结果表明,SSC 取得了最好的效果,可以有效检测出虚假招聘广告;在IMDB 数据集上的实验结果表明,SSC 具有较好的可拓展性,可以应用到其他自然语言处理任务。在未来工作中,本研究团队旨在收集更多的虚假招聘广告检测相关的数据集,研究检测效果更好、更普适的虚假招聘广告检测算法。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
阅读(低年级)(2019年6期)2019-08-27 04:29:53
住宅科技(2018年3期)2018-11-10 01:26:22
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
数学物理学报(2017年5期)2017-11-23 07:51:31
中国劳动关系学院学报(2016年2期)2016-09-26 01:57:42
反歧视评论(2016年0期)2016-07-21 14:54:47
公民与法治(2016年10期)2016-05-17 04:12:58
