
基于空洞卷积的医学图像超分辨率重建算法
2023-09-27 06:31:58王雅婧马巧梅
计算机应用 2023年9期
李 众,王雅婧,马巧梅*
(1.中北大学 软件学院,太原 030051;2.山西省医学影像人工智能工程技术研究中心(中北大学),太原 030051)
0 引言
随着医疗影像技术的广泛应用,医学图像已成为重要的医学诊断辅助工具。通过超分辨率重建得到纹理细节丰富且清晰的医学图像既可以帮助医生更清楚地判断病例的早期病变,也可以避免通过增加扫描次数或扫描时间的方式取得高分辨率医学图像,造成成本高昂、辐射过量的问题[1]。
医学图像超分辨率(Super-Resolution,SR)重建指通过对低分辨率(Low Resolution,LR)医学图像的一系列操作,生成高分辨率(High-Resolution,HR)图像的过程。基于插值的超分辨率重建算法[2]简单有效、容易实现,但重建后的图像容易存在边缘模糊的问题。基于重构的方法[3]需要先验信息对结果进行约束,重建的纹理边缘比插值法更清晰,但容易出现先验信息不足的问题。基于深度学习的方法则利用卷积神经网络(Convolutional Neural Network,CNN)获取LR 与HR 间的映射关系,是近几年来学者研究的热点。Dong 等[4]提出的基于CNN 的图像超分辨率(Super-Resolution CNN,SRCNN)算法是在图像超分领域运用深度学习方法的首次尝试,使用3 个卷积层便能有效提取图像内部的特征,并取得优于其他算法的重建效果。Kim 等[5]提出VDSR(Very Deep convolutional networks Super-Resolution)超分模型,利用残差加速网络收敛,提高了超分算法性能,但增加了计算的复杂度,并且可能引发梯度消失问题。Lim 等[6]提出EDSR(Enhanced Deep residual network for Super-Resolution)模型,通过堆叠大量残差单元增加网络深度以提升重建效果,但堆叠的残差网络使总参数量激增,计算成本加大。Chollet[7]提出了深度可分离卷积,利用一个深度卷积和一个点卷积代替标准卷积,实现通道空间区域的独立运算,可有效减小参数量,提升计算效率。单一的感受野对网络中的各层做简单的链式堆叠,对特征提取不充分,无法保证神经网络的鲁棒性与泛化性。Chen 等[8]提出了空洞卷积(Dilated Convolution,DC),对普通卷积注入空洞,扩大感受野,捕获图像更多的信息且不给网络增加额外的参数,可以在重建中取得较好效果。胡雪影等[9]在残差学习的基础上引入空洞卷积,对卷积的感受野起到了提升作用,并且提升了网络优化速度,但对于奇数放大倍数来说表现不佳。注意力机制最早是用于解决自然语言处理问题,Woo 等[10]通过对通道信息和空间信息的融合,提出了CBAM(Convolutional Block Attention Module)增强特征中重要信息的表达,但无法捕获不同尺度的空间信息,容易造成特征全局信息的丢失。张晔等[11]提出基于多通道注意力机制的图像超分辨率网络,引入多通道注意力模块对图像纹理进行信息提取,提升了生成图像的质量,但未考虑到图像不同尺度间的信息差异。
随着超分辨率重建在医学领域应用的不断深入,基于深度学习的医学图像超分辨率重建算法也取得了显著进展。Zhang 等[12]在2017 年提出了一种基于深度学习和迁移学习的单张医学图像超分辨率重建方法,通过对医学图像的不同特征进行共享,提高模型泛化能力,相较于其他医学图像重建算法取得了更好的重建效果。基于残差学习的思想,Wang 等[13]于2019 年提出了一种使用三维CNN 提高计算机断层扫描(Computed Tomography,CT)图像分辨率的算法,在保证图像重建质量的同时提高了计算效率。高媛等[14]提出了一种基于深度可分离卷积和宽残差网络的医学图像超分辨率重建方法,大幅降低了网络参数量。Chen 等[15]提出了反馈自适应加权密集网络(Feedback Adaptively Weighted Dense Network,FAWDN),利用反馈机制和自适应加权策略,使网络专注于信息量大的特征,从而提高医学图像质量。2021 年Qiu 等[16]提出了一个多重改进残差网络(Multiple Improved Residual Network,MIRN),结合几个不同深度的残差块,使模型可以专注于医学图像的细节恢复并且有效避免了迭代后医学图像过度平滑的问题,但对于含丰富病理信息的医学图像重建效果较差。
相较于自然图像,医学图像存在大量的细小纹理且往往伴随许多无用信息,例如由病人器官律动造成的阴影和噪声斑点等,这要求重建算法的效果更加精确。并且医学图像相较于自然图像更注重主观视觉感受,无法单纯从评价指标的角度衡量图像质量,因此重建出符合医生感官的医学图像更有助于模型的实际应用。目前已有的研究大多采用单一尺度提取图像特征,对于医学图像中的细节还原度欠佳,而且在医学图像中边缘部分是医疗诊断中的重要信息。为此,本文提出一种基于空洞可分离卷积(Dilation Separable Convolution,DSC)与改进的混合注意力机制的医学图像超分网络,突出了医学图像重建细节与边缘部分,在提升重建效果的同时尽可能降低网络参数量。主要工作如下:
1)在深层特征提取阶段将可分离卷积与不同空洞率的空洞卷积相结合,利用空洞率不同的三个并行空洞卷积,提升不同尺度特征表达,获取不同感受野下的全局信息。
2)引入融合边缘特征的通道注意力机制与使用大感受野的空间注意力机制,增强图像在通道与空间维度的特征表达。
1 相关工作
1.1 残差学习
经典的CNN 在信息传递时会存在信息丢失、梯度消失等问题。He 等[17]将残差结构引入深度神经网络,通过增加跳跃连接将梯度由浅层传递到深层部分,使得梯度在反向传播时得到保留,从而使网络的训练更加稳定。普通网络结构与残差网络结构对比如图1 所示。
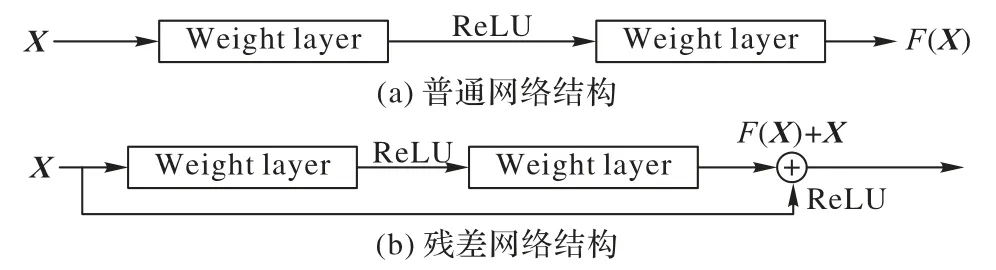
图1 普通网络与残差网络的结构对比Fig.1 Comparison of ordinary network structure and residual network structure
相较于普通网络结构,残差网络结构在网络中添加直接连接,在网络的输出部分直接添加输入X的映射,学习输入与输出之的残差。残差模块保留了输入的原始信息,加深网络层数,减少原始特征的流失。本文算法的网络基础结构基于深度残差网络,引入跳跃连接将所提取的不同程度的图像信息连接起来,随着训练深度的增加而额外获得增益。
1.2 深度可分离卷积
深度可分离卷积是CNN 中的一种卷积操作,相较于传统卷积操作在所有输入和输出通道之间进行卷积计算导致参数量极大,深度可分离卷积能有效减小模型参数和计算量,提高网络效率。深度可分离卷积的过程如图2 所示,分为逐通道卷积和逐点卷积两部分。
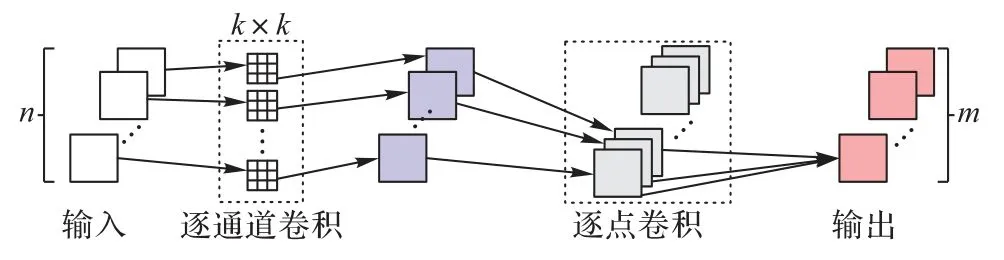
图2 深度可分离卷积过程Fig.2 Depthwise separable convolution process
令输入为n个通道特征图,首先在各特征图上分别进行k×k卷积,并将得到的n个特征图依次输出,再与m个1×l 的卷积核进行卷积,最终输出m个特征图。逐通道卷积用来提取空间的平面特征,只在通道内部进行卷积,而不对各通道间信息进行融合;逐点卷积则负责通道间的特征融合。假设输入为N×H×W的特征,卷积核大小为k×k,输出特征为M×H×W。令标准卷积的参数量为P1:
深度可分离卷积的参数量为P2:
因此,深度可分离卷积的参数量和标准卷积的参数量之比如式(3)所示:
由式(3)可知,深度可分离卷积的使用能大幅降低模型参数量。因此,本文使用深度可分离卷积代替标准卷积操作,在不损害模型性能的前提下降低网络参数量。
1.3 医学图像基础
医学图像包括CT、磁共振(Magnetic Resonance,MR)、正电子发射断层扫描(Positron Emission Tomography,PET)图像等多种图像,本文主要采用CT 图像进行实验分析。
CT 成像是一种结合X 射线成像与计算机技术的成像技术,能获得更详细的断层影像,多用于检查头颅、脊柱、胸腹部等部位。CT 采集的HU(HoUnfield)值为射线衰减值,根据图像的HU 值可以区分肺、血液、骨骼和其他组织器官。
提高CT 图像分辨率的主要方法是通过静脉碘造影剂注射,使目标部位造影剂浓度升高,从而获取高分辨率影像。然而,注射造影剂可能会产生一些潜在的副作用,使用超分辨率重建算法来提高医学图像分辨率是一种更加无创的方法,可以在提高医生诊断能力的同时减少患者因注射造影剂带来的潜在风险。
2 本文算法
本文构建了一种基于空洞可分离卷积的医学图像超分辨率重建算法,整体结构如图3 所示。
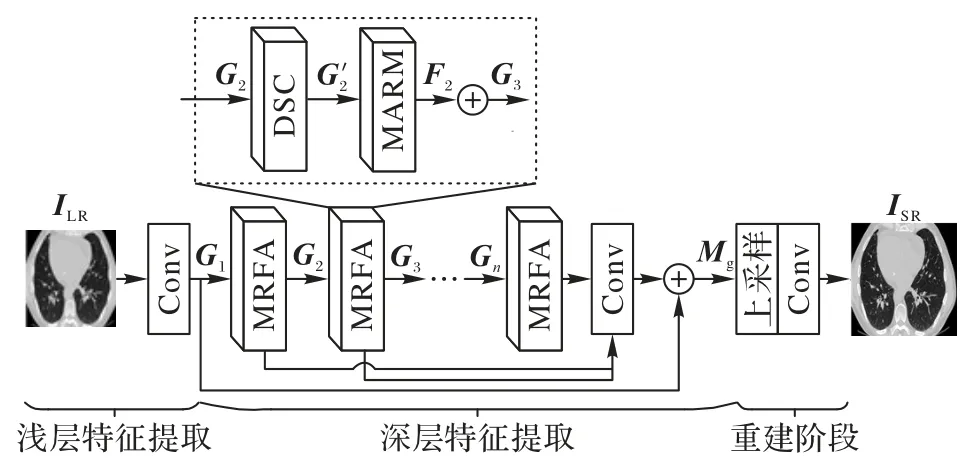
图3 本文算法的结构Fig.3 Structure of the proposed algorithm
本文算法的网络主要由浅层特征提取、深层特征提取、图像重建三部分组成。浅层特征提取部分利用一层3×3 卷积对输入的图像进行通道变换,提取浅层特征G1,具体过程如式(4)所示:
其中:ILR为输入的低分辨率图像;Conv3×3为核大小为3×3 的卷积运算。
在深层特征提取阶段,将浅层特征G1输入到X个由空洞可分离卷积(DSC)模块与混合注意力模块(Mixed Attention Residual Module,MARM)串联而成的多感受野注意力(Multi-Receptive Field Attention,MRFA)模块,提取目标在不同尺度下的中间与高频特征,并对提取的特征图进行通道融合,生成深层特征Mg。过程如式(5)所示。
其中:Hg(*)为MRFA 模块的特征提取过程;concat 为特征融合操作。
重建阶段首先通过亚像素卷积对融合后的特征图进行上采样,再使用3×3 卷积得到最终重建图像,如式(6)所示:
其中:Hu(*)表示图像重建操作;ISR为超分辨率重建图像。
2.1 DSC模块
医学图像细节更丰富,纹理更复杂,往往包含了许多不同尺度的细节信息。常见的图像超分辨率网络往往只关注单一尺度的图像信息而忽视了不同尺度间的信息融合。针对上述问题,本文提出了DSC 模块,结合不同空洞率下的空洞卷积与深度可分离卷积,获取图像局部和全局特征信息,如图4 所示,其中:D表示空洞率,C表示输入通道数。
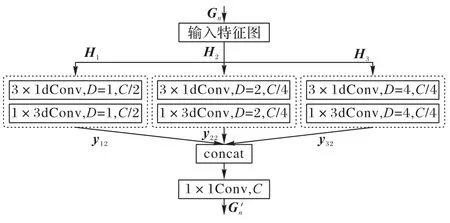
图4 空洞可分离卷积模块的结构Fig.4 Structure of dilation separable convolution module
在空洞卷积中,邻近像素是通过对相互独立的子集卷积得到的,相互之间缺少相关性;因此使用单一空洞率的空洞卷积容易导致图像局部信息的丢失,造成网格效应。不同的空洞率有利于提取不同层次的图像特征,为此本文采用多尺度空洞率融合的方法提升网络的特征表达性能。
首先,将输入的特征图Gn分为三个分支Hl(l=1,2,3),为保证图像特征信息的完整性,缓解因空洞卷积操作引起的网格效应,使用3×3 大小的深度可分离卷积对第一个分支的通道特征进行提取,另外两分支使用不同空洞率的空洞可分离卷积代替3×3 的可分离卷积,为网络提供不同的感受野大小,帮助网络更好地提取图像特征。整个过程如式(7)所示:
最后,采用concat 和一个1×1 卷积对所提取特征进行融合与降维,输出结果如式(8)所示:
2.2 MARM
图像经过浅层特征提取后,各个部分往往表达不同特征,但这些特征都保持着相同权重,而没有考虑不同特征之间重要程度的区别,不利于突出目标的特征信息。神经网络中添加注意力机制可以使模型注重于感兴趣的区域,聚焦重要特征的提取。在使用注意力机制进行特征提取过程中需要关注以下2 个问题:1)图像的每个通道都含有大量的低频与高频信息分量,高频分量往往含有许多边缘信息,因此在对高低频信息进行区分与整合过程中需要额外关注边缘信息的重要程度。2)注意力机制中的滤波器往往只能接收局部信息。为了使模块能够关注到特征图全局信息,需要提高模块对于不同尺度特征的关注程度。
针对上述问题,本文改进的混合注意力模块的结构如图5 所示。

图5 改进的混合注意力模块的结构Fig.5 Structure of improved mixed attention residual module
针对本文1.1 节获得的特征图像,使用改进的MARM,选择性地获取图像低频与高频信息。MARM 利用跳跃连接降低网络优化难度,缓解梯度消失问题,将提出的边缘通道注意力模块(Edge Channel Attention Module,ECAM)与改进的空间注意力模块(Improved Spatial Attention Module,ISAM)串联,进一步提取图像特征。计算过程如式(9)所示:
2.2.1 ECAM
通道注意力可使网络在训练中对含有不同丰富度信息的通道赋予不同的关注度,将资源尽可能地分配在信息更丰富的通道,提升网络性能[18]。而对于医学图像,图像边缘有助于区分器官结构边界,是辅助医生诊断的重要因素之一。因此,利用特征图边缘信息的丰富程度对各通道所占权重进行分配,可使特征图中的纹理细节在通道层面被充分利用。图6 为边缘通道注意力模块。
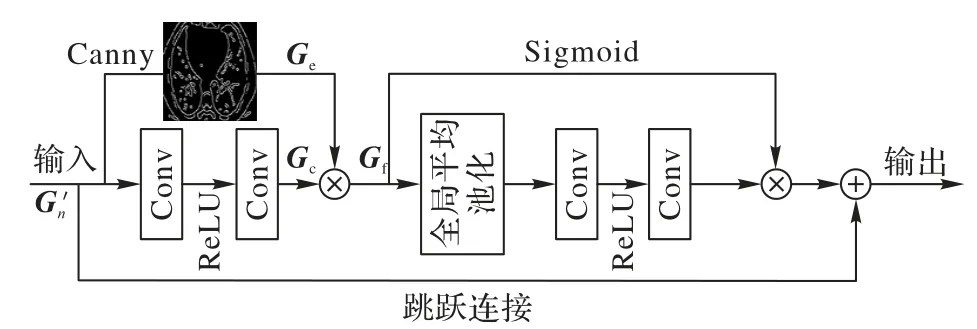
图6 边缘通道注意力模块的结构Fig.6 Structure of edge channel attention module
使用Canny 边缘检测算法[19]对输入特征图进行边缘提取,与经过卷积操作的特征图Gc进行乘法聚合操作,得到边缘增强后的特征图Gf。整个过程可如式(10)所示。
其中,Canny(*)表示Canny 边缘检测算子。Gf经全局平均池化获得整体特征信息,Sigmoid 函数分配各通道权重,从而使最终特征在通道上增强对边缘信息的关注。通过跳跃连接将输入的初始特征图与网络底层连接进行残差学习,以降低网络训练难度。
2.2.2 ISAM
空间注意力是指在计算卷积特征图时,根据输入的特征图的不同位置赋予不同权重的技术。相较于通道注意力,空间注意力侧重于提取空间位置信息。通过对特征图进行空间维度的信息提取,加强网络对图像细节部分的学习,从而对通道注意力模块忽略的信息进行补充。改进的空间注意力模块如图7 所示。
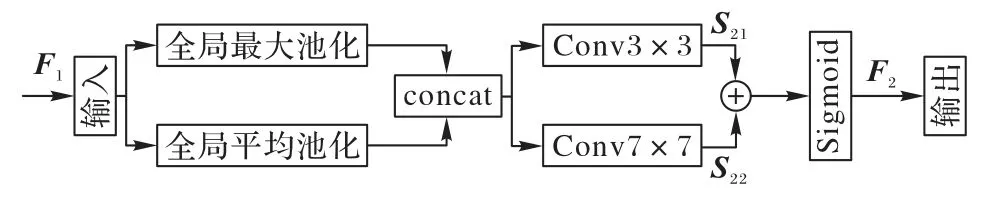
图7 改进的空间注意力模块的结构Fig.7 Structure of improved spatial attention module
将前一阶段的输出作为本模块的输入,利用平均池化和最大池化得到两个不同信息表示的特征图,并对两个特征图进行拼接。空间注意力机制中,更大的感受野可以增强全局信息提取能力,因此,改进的空间注意力机制设置3×3、7×7,步长为1 的两种不同的卷积核,对特征图信息进行捕捉,通过对应位置相加的方式将生成的两种特征图S21、S22进行融合,之后使用Sigmoid 激活函数生成最终的空间注意力特征图。整个过程如式(11)所示:
其中:σ为Sigmoid 激活函数;⊕表示加和操作;f3×3、f7×7表示卷积核为3×3、7×7 的卷积操作。
2.3 损失函数
2.3.1 像素损失
大多数基于深度学习的超分算法使用像素损失作为模型的损失函数,主要包括L1、L2 损失函数[20-21]。L1 损失衡量的是预测结果和真实结果差的绝对值之和,而L2 损失则衡量的是预测结果和真实结果的平方差之和。相较于L2 损失,L1 损失函数对离群值更加敏感,因此会使得重建图像的纹理和细节更加清晰且L1 损失的梯度相对于L2 损失更加稳定,这意味着L1 损失更容易收敛,训练过程更加稳定,不容易陷入局部最优解。L1 损失函数定义如式(12)所示:
其中:θ表示模型的参数集;n表示训练输入的图像块数量;(f*)表示本章提出的超分辨率网络表示第i个低分辨率医学图像与对应的高分辨率图像。
2.3.2 感知损失
感知损失在网络中针对特征图细节进行计算,比像素损失更符合人体视觉感知[22]。感知损失函数分别将重建图像y'与真实高分辨率图像y输入到预先训练好的图像分类网络,提取一组尽可能相似的特征计算欧氏距离,借助VGG-16[23]结构,用全连接层前最后一个卷积层的输出作为特征。定义φ(•)表示特征提取操作。损失函数Le如式(13)所示:
2.3.3 整体损失函数
为提高重建图像的清晰度,降低模糊图像对模型性能的影响,本文将L1 损失与感知损失结合,作为整个网络的损失函数,可表示为:
其中,α、1 -α为两项损失的平衡权值。为比较α的取值对实验结果的影响,使用L2R2022 医学图像配准比赛中的肺部图像数据集L2R2022-CT(https://learn2reg.grand-challenge.org/learn2reg-2022/)进行2 倍放大对比实验。
首先使用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)作为客观评价指标,对结果进行评估,如图8 所示。
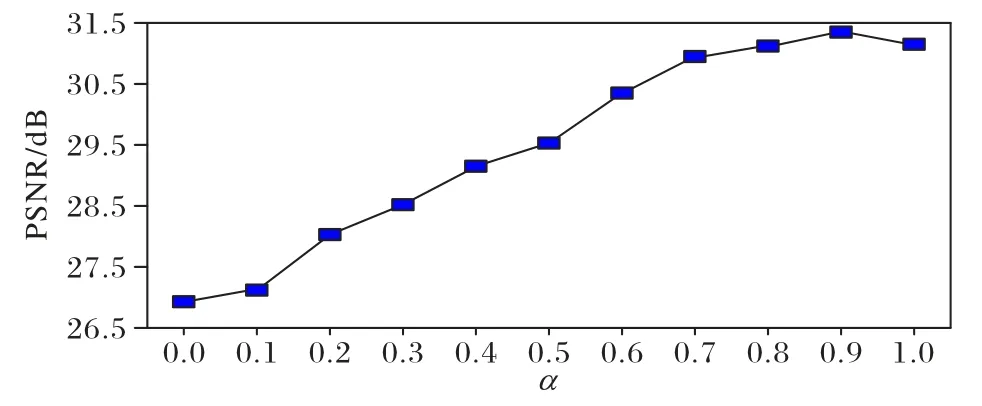
图8 不同α 下的PSNR对比Fig.8 Comparison of PSNR under different α
由图8 可知,当α=0 时整体损失函数完全由感知函数组成,即L=Le,此时重建图像的PSNR 值为最低。当α处于[0,0.9]内评价指标PSNR 值递增,并在α=0.9 时达到最高值31.35 dB。而当α=1 时L=L(θ),整体损失将由L1 损失得出,此时PSNR 相较于之前有所下降。
为进一步探讨α取值对图像重建效果的影响,本文分别对α=0,0.9,1 时的重建图像进行直观对比,结果如图9所示。
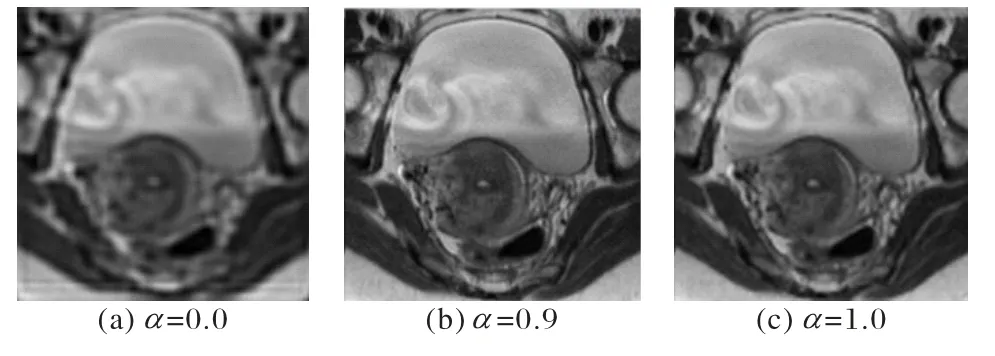
图9 不同权值重建图像的直观对比Fig.9 Visual comparison of reconstructed images with different weights
通过对比可以看出:α=0 时重建图像最模糊;而α=0.9时重建图像效果最佳,且相较于α=1 时的重建图像拥有更加清晰的边缘与完整的结构。这符合图8 所示的PSNR 变化趋势,综合PSNR 与主观图像对比分析,当α=0.9 时模型重建效果最佳,因此本文设置平衡权值α为0.9 进行下述实验。
3 实验与结果分析
3.1 实验设置
本文实验数据采用L2R2022 医学图像配准比赛中的肺部CT 图像数据集以及癌症基因组图谱(The Cancer Genome Atlas,TCGA)(https://www.cancer.gov/ccg/research/genomesequencing/tcga)中的腹部CT 图像。各取2 400、1 100 张细节纹理丰富、清晰度高的图像按照4∶1 的比例划分为训练集A、B 与测试集A、B。准备阶段使用下采样方式由原始图像生成低分辨率图像,并将它一一配对用于后续实验。图10展示了其中的两组图像对,分别表示原始高分辨率(HR)图像与低分辨率(LR)图像。
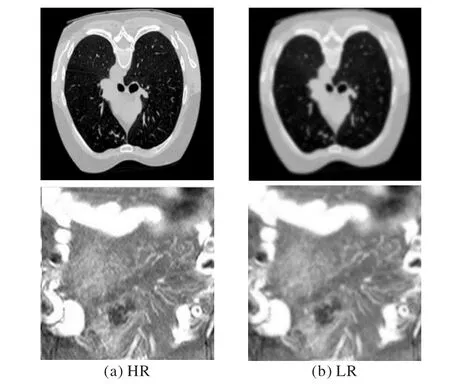
图10 原始数据样本Fig.10 Raw data samples
实验环境如下:Intel Core i7-8750H CPU @ 2.20 GHz,GPU 为NVIDIA Quadro RTX,内存24 GB,Python 3.8.3,深度学习框架为PyTorch 1.4.0,CUDA 版本为10.1。batch size 为16。采用Adam 算法进行优化,相关参数β1=0.9,β2=0.999,ϵ=10-8,初始学习率为0.000 1,每训练200 个epoch 学习率减半。采用PSNR 和结构相似性(Structural Similarity Index Measure,SSIM)作为客观评价指标。PSNR 反映图像失真水平,数值越高表示重建质量越好。SSIM 主要评估图像之间的相似性,数值越接近1 则重建的图像越接近原始图像。
3.2 实验与结果分析
3.2.1 MRFA模块数量分析
本文使用MRFA 模块进行深层特征提取,当MRFA 模块数量X发生改变时,重建出的图像质量也会随之改变。为探讨网络中MRFA 模块数量对重建图像峰值信噪比的影响,本节基于测试集A 在2 倍放大下对重建效果进行分析。图11为不同MRFA 模块数下的性能对比。
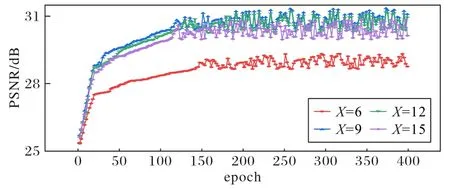
图11 不同MRFA模块数的PSNR对比Fig.11 Comparison of PSNR with different MRFA module numbers
由图11 可知,MRFA 模块数量X的取值不同,重建图像的PSNR 指标也有所区别。当X=9 时,重建图像的PSNR 值最高,因此本文取MRFA 模块为9 进行下述实验。
3.2.2 消融实验
为验证本文算法中各模块性能,对DSC 模块、ECAM、普通通道注意力(Channel Attention,CA)模块、传统的空间注意力模块(SAM)、ISAM 在测试集A 中进行2 倍放大的消融实验。首先仅使用DSC 模块进行深层特征提取,之后在此基础上引入ECAM 对不同通道间信息进行增强,通过对DSC+SAM 模块与DSC+ISAM 模块的重建性能对比,探讨特征的空间位置信息,最后将三个模块级联,对比分析各模块对图像超分重建性能的作用。实验结果如表1 所示。
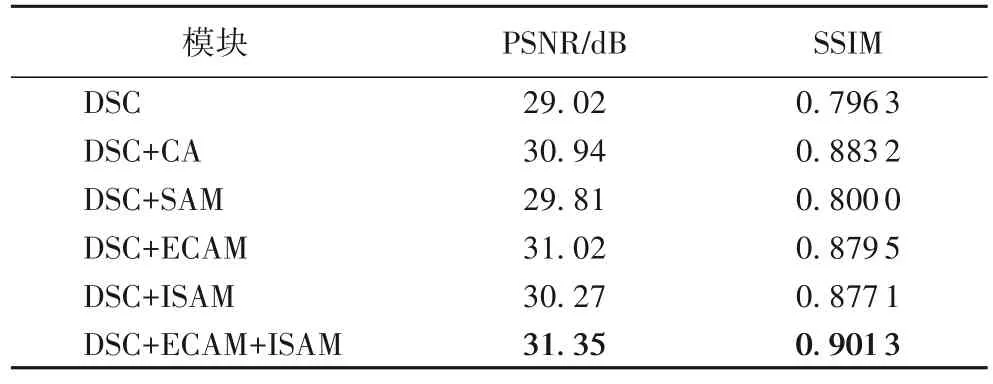
表1 不同模块的重建性能比较Tab.1 Comparison of reconstruction performance of different modules
由表1 可知,结合DSC 模块与ECAM 的图像重建效果优于DSC 模块与CA 相结合的结果。而相较于其他组合方式,DSC、ECAM 与改进的混合注意力模块(ISAM)可以获得更大的感受野与图像通道与空间信息,使算法拥有更好的重建性能。
3.2.3 对比实验分析
将本文算法与经典的超分辨算法Bicubic[24]、SRCNN[4]、FSRCNN(Fast SRCNN)[25]、VDSR[5]、基于残差通道注意力的超分网络RCAN[26]以及基于多尺度注意力残差的重建网络[27]、FAWDN[15]与MIRN[16]等具有代表性的超分辨率重建网络分别在测试集上进行测试。结果如表2 所示。
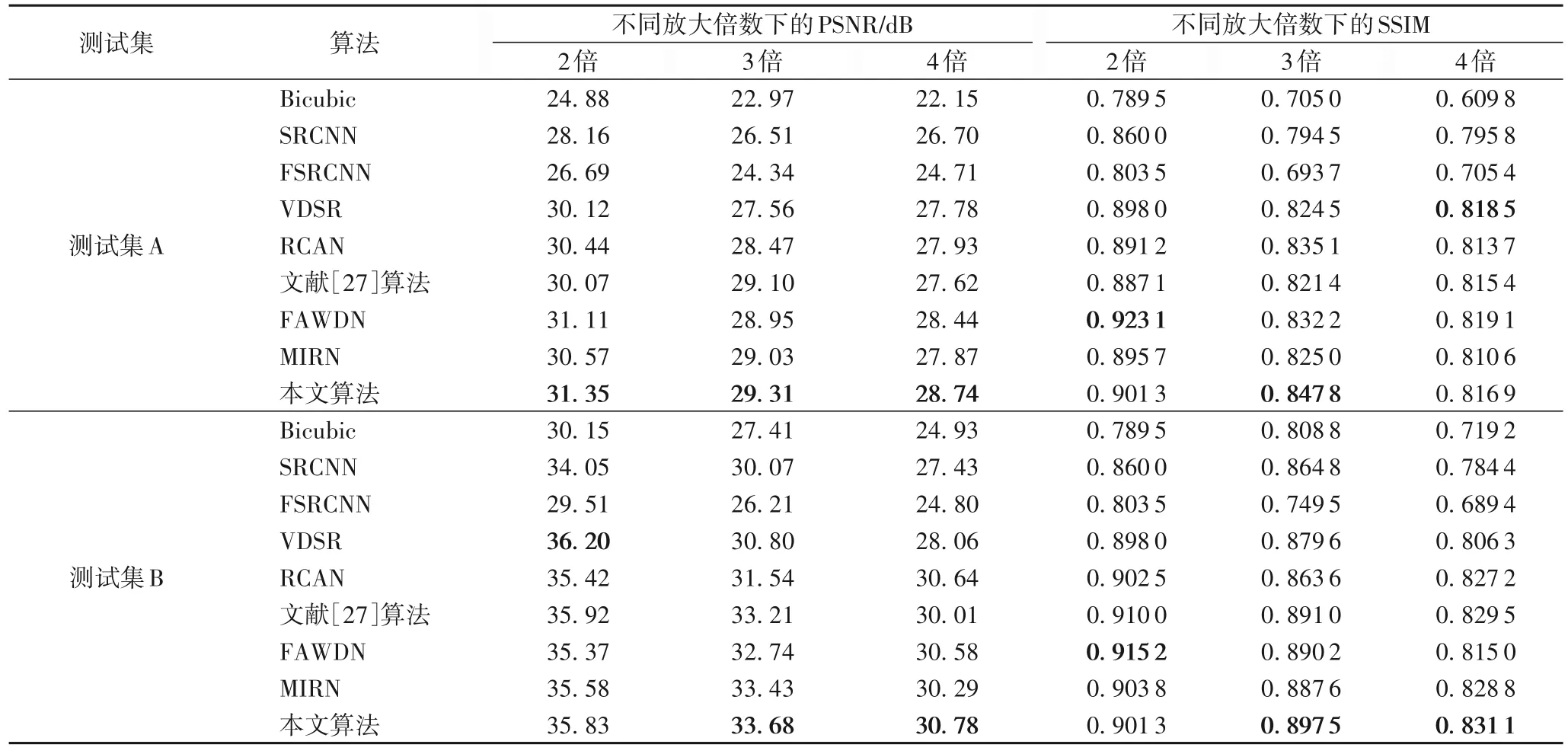
表2 不同算法的PSNR/SSIM值比较Tab.2 Comparison of PSNR/SSIM values of different algorithms
从表2 可以看出,本文算法在不同放大倍数下,在各数据集上均有良好表现。当放大倍数为3 时,与SRCNN、VDSR相比,本文算法的PSNR 平均提高了11.29%与7.85%;SSIM平均提高了5.25%和2.44%。可以看出,在各放大倍数下,本文算法均有一定提升,但是在放大倍数较大时PSNR 与SSIM 比放大倍数较小时更低,因此在今后的研究中将着力于解决放大倍数较高时的图像重建问题。
图12 展示了各算法在实验所用数据集下的4 倍放大的重建效果。图12(a)主要对各算法对图像的整体还原能力进行对比。可以看出,不同算法对图像还原程度不一,其中:文献[27]算法相较于其他算法对LR 图像质量有了一定提升,但在边缘部分存在模糊现象;而本文算法则还原出了更加清晰的图像边缘,且拥有更加丰富的纹理信息。图12(b)主要对比了细节放大下各算法的重建效果,对比发现,SRCNN、FSRCNN、VDSR 等对比算法均出现了不同程度的噪声干扰,而本文算法还原的图像最贴近于原始图像,对于细节还原更加清晰。整体来说本文所提网络训练的图像更加接近原始图像,对比其他网络,本文算法对图像整体结构的复原更加完整,对边缘纹理的还原度也更高;但相较于原始图像,重建的清晰度仍有不足。
3.2.4 模型运行时间比较
重建模型的计算时间往往和网络参数量与算法复杂度呈正相关,因此本文通过对各模型重建图像的平均用时的比较来衡量算法复杂度。表3 为通过对50 组测试图像的重建测试得到的不同重建算法重建图像的平均用时。
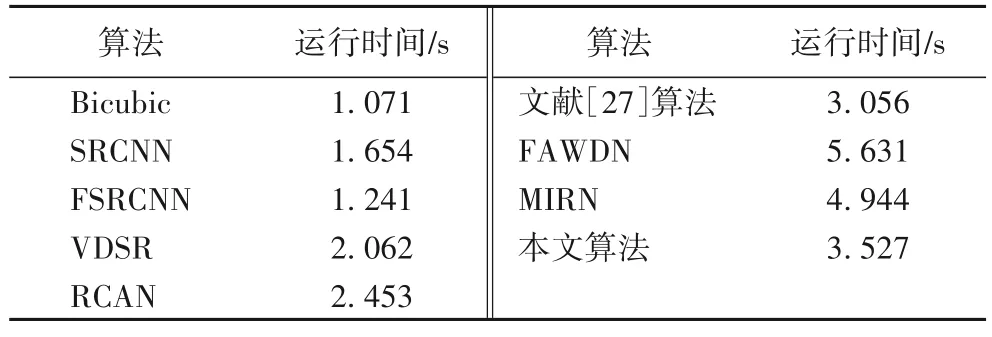
表3 不同算法重建图像的平均用时Tab.3 Average time spent to reconstruct images by different algorithms
由表3 可知,网络设计较为复杂的模型往往重建时间较长,且重建效果更佳的网络往往也有着更长的重建用时。对重建时长较长的文献[27]算法、FAWDN、MIRN 以及本文算法的重建效果进行对比得出,本文算法在不损失图像重建精度的同时可以尽可能地缩短重建用时,且能在较复杂的结构设计下保持较高的重建效率。
4 结语
本文提出了一种基于空洞可分离卷积与改进的混合注意力机制的图像超分辨率重建算法,解决了传统超分辨率网络对于图像特征提取尺度单一、容易丢失边缘及高频细节的问题。使用空洞可分离卷积对图像进行不同尺度特征提取,同时尽可能减少网络参数量;使用改进的边缘通道注意力结构,融合特征图像的边缘信息,将资源分配到信息更加丰富的部位;对于空间注意力机制,更大的卷积核可以拥有更强的全局信息提取能力,因此使用两种不同大小卷积核,提取特征,生成最终空间注意力特征图。同时结合像素损失与感知损失,设置一种更加适于人体视觉评价的复合损失函数作为整体损失函数,保证网络收敛效果的同时使重建图像更加符合视觉标准。通过对常用的几种超分辨率重建算法与本文所提算法的对比分析验证,本文算法在客观评价指标方面有显著提升,且可以获得细节纹理更加清晰的重建图像,验证了本文算法在医学图像超分领域的准确性与实用性。本文算法在3、4 倍放大倍数下均可以获得视觉效果更佳的重建图像,然而目前临床诊断越来越需要更大尺寸的医学图像进行辅助,因此在后期工作中会更加关注较大倍数下图像还原能力,以及时间与资源的消耗问题,着重于构建细节纹理还原度更高且还原更加快速的超分网络。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
故事作文·高年级(2017年2期)2017-03-01 13:03:27
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
新闻传播(2015年20期)2015-07-18 11:06:46
电视技术(2014年19期)2014-03-11 15:38:20
世界科学(2013年11期)2013-03-11 18:09:47
