
基于概念结构与分布式表征的术语语义知识库构建
2023-09-26 00:39:04王裴岩李林娜沈思嘉
中国科技术语 2023年4期
王裴岩 李林娜 沈思嘉
(沈阳航空航天大学人机智能研究中心,辽宁沈阳 110136)
0 引言
词汇语义知识库在自然语言处理的各任务中都扮演着重要角色。现有的词汇语义知识库主要是面向通用领域的,面向特定领域的较少,因此,构建特定领域的术语语义知识库具有重要意义。
本文以航空术语语义知识库ATHowNet为基础,基于HowNet[1]的理论体系和概念表示形式,提出一种面向复合术语的术语语义知识库自动构建方法。该方法秉承复杂概念由简单概念构成的思想,由术语内子词概念构筑术语概念。术语概念采用了计算机可读的形式化表示方式。通过实验验证了本文提出的方法在自动生成复合型术语概念表示方面的有效性,并且能够扩展ATHowNet知识库的数据量。
1 HowNet与ATHowNet
1.1 HowNet与概念表示方法
HowNet最初是由董振东和董强在20世纪90年代设计和构建的一个以汉语和英语词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间关系为基本内容的常识知识库[1]。HowNet最大的特点是采用可计算的知识库标记语言KDML(Knowledge Data Base Markup Language)描述概念。“HowNet的知识表达模式是针对计算机的信息处理特点而制定的。”[2]KDML这种形式化表达方式,便于将HowNet应用于相似度计算[3]、情感分析[4]、词向量[5-6]、语言建模[7]等。目前,HowNet的网络开源版本OpenHowNet[8],包含35 202个概念和237 974个中英文词。
HowNet遵循还元论,通过义原(sememe)和语义角色(semantic role)描述概念。义原是最小的不可分割的语义单元。HowNet通过对大量中文字的语义进行标注与归纳,定义了2540个义原,建立了义原的分类(taxonomy),分为事物(thing)、部分(part)、属性(attribute)、时间(time)、空间(space)、事件(event)与属性值(attribute-value)7大类。语义角色定义为参与者在真实或想象的情境中与事件之间的固有关系,用以描述概念中义原的角色[9]。HowNet定义了116个语义角色。表1给出了术语“橡胶减震垫”所表示概念的HowNet表示形式(KDML),并列出了涉及的全部义原和语义角色含义。“part|部件”与“shiver|颤动”等为义原,whole与instrument等为语义角色。概念表示以“DEF”开始,“{}”表示不同层级的概念,“patient=”表示事件“weaken|削弱”的受事是“shiver|颤动”。需要特别指出的是,“part|部件”作为第一个义原被称为首义原。KDML的详细语法规则和义原及关系集,可以参考HowNet在线手册[10]。

表1 “橡胶减震垫”的概念KDML表示
1.2 ATHowNet与术语概念结构
ATHowNet(Aviation Terms HowNet)[11]是基于HowNet的理论体系与概念表示方法所构建的一个航空领域术语语义知识库,包含4152条记录、3864个术语和3700个概念。ATHowNet扩宽了HowNet的适用领域,通过形式化描述航空领域的概念语义,能够实现领域概念相似性运算与概念关系推理。
ATHowNet针对航空领域术语多为复合词或词组的特点,更加注重概念间的构筑结构,即复杂概念由简单的概念构建,简单的概念由更为简单的概念构建,直至基础概念。表2展示了“橡胶减震垫”的多层级概念构筑关系。可见,“橡胶减震垫”由“垫”“减震”与“橡胶”三个子概念通过语义角色构成。如“垫”用来“减震”,由于“减震”的首义原“weaken|削弱”是事件类义原,因此“垫”与“减震”省略了语义角色,其含义是“减震”事件的施事者为“垫”。

表2 “橡胶减震垫”概念层次构筑关系
2 概念与文本的分布式表征
分布式表征(distributed representation)[12]又叫作嵌入(embedding),是将词、图片与文本等离散量转为低维、稠密、连续向量的技术。分布式表征能够通过向量计算实现不同粒度与形式数据的关系计算,如词与文本间或文本与图片间的计算。通常,分布式表征向量间的距离或是向量夹角余弦等运算能够体现两个被表征对象间的语义距离。这种性质被应用于句子相似度计算[12]、问答系统[13]、图片搜索[14]等问题,例如在句子相似度计算中将句子中的词转为低维、稠密、连续的分布式表征向量,通过两个句子向量间的夹角余弦或欧式距离来体现句子间的语义相似性。
本文利用分布式表征方法表征概念与术语定义文本,能够计算概念与概念间、概念与文本间的语义距离,用于术语子词概念消歧和语义角色判断。对于概念,其分布式表征向量是全部义原表征向量的平均向量。首先,提取概念内全部义原,从腾讯词向量[15]中查询出该词的分布式表征向量,将该向量作为义原的表征向量。腾讯词向量是通过大规模文本数据训练获得的,在中文词语相似度运算、词类比及自然语言处理相关任务上都具有较好的效果。对于术语定义文本,其分布式表征向量是全部词表征向量的平均向量。用腾讯词向量的词表对术语的定义文本进行分词,并查询出每个词的词向量,求得所有向量的平均向量作为术语定义文本的分布式表征向量。
3 术语概念表示的自动生成方法
人类从客体特性出发,在脑中形成特征和概念(concept),概念反映事物的本质属性,同时也反映具有这种属性的事物[16]。术语是专业领域科学概念的语言指称[17],可以是单个词,也可以是复合词,一个词可以承载多个概念,一个概念也可能由多个词来体现。复合术语[18]是指由多个词组合而成的术语,组合结果所表达的语义构成了领域的重要概念,如“航空地球物理探矿”和“空中加油装置”是航空领域的复合术语,拥有完整的语义,表示领域内的重要概念。概念的内涵和外延是概念的基本特征,概念的内涵反映概念中对象的本质属性,概念的外延反映于思维中具有相同本质属性的事物对象,外延是受内涵制约的,如猫的外延包括白猫、花猫等,但不包括黄牛、泰迪。根据概念的基本特性可将概念分为属种概念[19],属概念指具有各个种概念的共同属性,外延大,内涵少,为一般概念,也可理解为上位概念,种概念相对而言是个别概念,根据种属概念的从属关系,特定语境下种概念会使属概念的外延缩小[20],直至缩小为独立概念。复杂概念就是由种、属概念组合而成,来共同描述现实世界的事物,本文为了方便描述,将种概念和属概念称为简单概念,复杂概念则由简单概念构筑而成。
本文沿袭并利用ATHowNet的领域概念构筑关系的思想,专门面向复合型术语,提出术语概念KDML表示自动生成方法。
3.1 总体流程
本文提出的方法包括以下四步:
(1)术语子词切分:切分出构成复合术语的子术语。
(2)子词的概念消歧:对切分后的子术语,确定在该术语内所代表的概念。
(3)子词概念间语义角色判断:判断各个子词概念间是否存在语义角色,若存在则语义角色是什么。
(4)术语概念描述生成:按照KDML语法规则,生成术语的概念表示。
3.2 术语子词切分
本文以OpenHowNet和ATHowNet中的词作为词表,采用逆向最大匹配算法对生成概念表示的术语进行分词。以OpenHowNet和ATHowNet中的词作为词表,能够保证切分出的词都带有KDML概念表示。逆向最大匹配算法能够保证最大粒度的切分,减少概念消歧和子词概念动态角色判断的数量,也能够保证最大粒度地重用已知概念。例如术语“橡胶减震垫”,其切分结果为“橡胶”“减震”“垫”三个子词。若词表中存在“减震垫”,则切分为“橡胶”与“减震垫”两个词。并且将术语最后一个词作为术语核心词,其概念为属概念,属概念的义原为首义原。
3.3 子词概念消歧
术语子词切分之后,从OpenHowNet与ATHowNet中查询出每个子词的全部KDML概念表示。以术语“橡胶减震垫”为例,其切分后每个子词的概念列入表3。可见“减震”与“橡胶”是单义词,即对应1个概念;而“垫”为多义词,对应2个名词与2个动词4个不同的概念。依据术语“橡胶减震垫”的定义“保护设备和仪表部件免受振动和冲击影响的橡胶用具”,词“垫”在该术语中的概念应为第1个,表示一种嵌入设备应用的部件。

表3 “橡胶减震垫”的概念KDML表示
术语定义对术语概念具有一定的约束性。依据定义“保护设备和仪表部件免受振动和冲击影响的橡胶用具”,术语“垫”的概念不可能为2个动词概念, “设备”和“仪表”作为“整体”,使得“部件”概念可能性增加。
由此,采用的概念消歧方法是计算子词每个概念的分布式表征与术语定义文本分布式表征的语义距离。与术语定义文本分布式表征语义距离更近的概念作为最终被选择的概念。概念分布式表征与定义文本分布式表征采用第2节介绍的方法。语义距离计算方法采用向量夹角余弦,如式1所示,向量夹角余弦越大表明语义距离越小。
式1
其中,ec为概念的分布式表征向量,ed为定义文本的分布式表征向量。以“垫”为例,分别计算4个概念分布式表征向量与术语定义文本表征向量的向量夹角余弦,取获得最大值的概念为“垫”的概念。
3.4 子词概念间语义角色判断
子词概念间语义角色判断采用文献[21]所提出的基于实例的KNN(K Nearest Neighbor)方法。该方法将语义角色判断问题转化为分类问题,分类标签就是HowNet的116个语义角色,即将两个概念分入某一语义角色类。
首先,从OpenHowNet和ATHowNet的每个概念表示中抽取其子概念及子概念间的语义角色,形成“(概念1, 概念2, 语义角色)”三元组作为KNN的实例集。例如对于概念“{weaken|削弱:patient={shiver|颤动}}”,则形成三元组“({weaken|削弱}, {shiver|颤动}, patient)”。本文约定三元组中的语义角色是从概念1到概念2的语义角色,并称概念1为归属概念,概念2为被归属概念。实例集中增加了无语义角色的反例,从而在判断语义角色时能够判断出不存在语义角色关系的两概念。之后,将实例集三元组内的两概念用第2节的方法形成分布式表征向量。三元组形式为(e'c1,e'c2,r'),其中e'c1为三元组概念1的分布式向量表征,e'c2为三元组概念2的分布式概念表征。
判断语义角色时,将待判断语义角色的两个概念采用第2节方法转为分布式表征向量(ec1,ec2)之后,计算(ec1,ec2)与实例集每个三元组(e'c1,e'c2,r')概念间的语义距离,计算方法如式2所示,其值越大表示语义距离越接近。
式2
选取式2最大的前K个三元组,并将K个元组内同一语义角色的语义距离值相加,获得最大值的语义角色作为待判断语义角色的两个概念的语义角色。
3.5 术语概念描述生成
概念的KDML是树形结构,也就是一个词的概念仅有一个属概念,也可称为核心概念。因此,首先判断除术语核心词以外所有子词概念与核心词概念间的语义角色。如果与核心词存在语义角色,则不再判断它与其他词间的语义角色。若与核心词之间不存在语义角色,则判断与其他词间的语义角色。如果存在冲突,如(ec1,ec2)与(ec2,ec1)都存在语义角色,那么保留语义距离计算值较大者,从而保证KDML的结构。
4 实验
本文设计了自动生成术语概念表示质量的评价实验来验证所提出的方法。
由于术语概念表示的KDML以义原和语义角色为基本单元,通过义原-语义角色-义原构筑。因此,本文从义原正确性、语义角色正确性、三元组(义原-语义角色-义原)正确性三个方面来评价。另外,首义原表示了概念的核心语义,因此单独评价所生成概念表示的首义原的准确性。
4.1 实验数据集
本文实验数据集使用了OpenHowNet与ATHowNet航空术语语义知识库,从ATHowNet中选取300条数据作为测试集。其余数据作为KNN的实例集,包含48 983个三元组。
4.2 实验结果评价指标
本文对生成概念的首义原、义原、语义角色、三元组(义原-语义角色-义原)分别与测试集进行对比。其中义原、语义角色、三元组采用准确率P(Precision),召回率R(Recall)以及F1值作为最终的实验评价指标,具体公式如式3、式4与式5。首义原采用精确率A(Accuracy),如式6。
式3
式4
式5
式6
4.3 实验结果
对本文所选数据集获得的实验结果,各评价指标所得结果见表4。
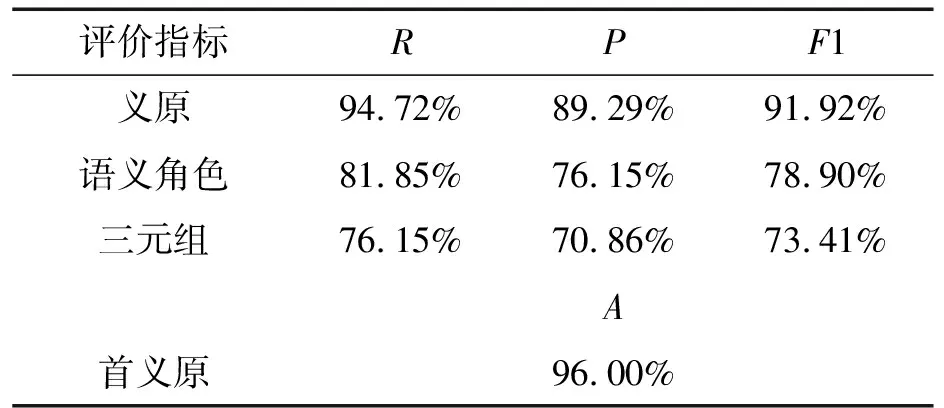
表4 实验结果
本文基于概念结构和分布式表示自动生成术语KDML表示的方法,从表4测试集的评价结果中可以得出:
(1)本文自动生成方法在义原和首义原上的预测结果的F1值和准确率均超过90%,这两个指标是DEF的重要构成部分,其中首义原能描述术语的基本性质,总义原衡量术语整体语义的描述正确与否。实验结果表明,采用本文方法能对复合型术语的基本性质和整体语义进行正确描述,在很大程度上保证了语义描述的准确性和一致性。一方面是因为生成语义描述的过程中减少了义原的判断,进而保证了数据的一致性和准确性,语义消歧过程也使义原选择的准确性大大提高;另一方面,由于测试集选取的是航空领域术语,实验数据中添加了ATHowNet中除测试集之外的3852条数据,ATHowNet构建的初衷是理解复杂的航空术语的语义,同时也对一些简单概念进行标注,本文方法会从这部分数据中获得航空领域的知识,并结合通用领域的知识提高义原预测的准确率。
(2)预测语义角色的F1值达到了78.90%,基于简单概念生成复杂概念描述的思想,减少了义原与义原之间语义角色的判断,另外采用无监督的学习方法从语义角色选择的实例集中确实学习到概念之间语义角色的知识,大大缩小了语义角色的选择范围,使选择正确语义角色的概率大大增加,预测结果更加准确。由于关系种类有116种,义原有2540种,相近概念之间的语义角色也不尽相同,选择K近邻方法虽然缩小了关系选择的范围,但具体情况下使用哪一个语义角色仍具有一定的不确定性;另外,测试集选用人工标注的数据集,由多位专家编写术语DEF,导致在语义角色的选择上存在个体差异,增大了语义角色选择的难度。
(3)预测三元组的F1值达到了73.41%,预测结果虽然没有上述指标高,但能完全体现出采用本文的方法在很大程度上保证了概念描述的一致性和准确性。由于三元组的形式是(义原,语义角色,义原),不仅要求义原是正确的,而且义原与义原之间的语义角色也要正确,即使义原预测正确,而语义角色不正确,三元组的结果也会受到影响,例如ATHowNet中的术语 “边际成本”,用本文方法预测输出DEF中的一个三元组为(expenditure|费用,RelateTo,Boundary|界限),人工标注对应的三元组为(expenditure|费用,concerning,Boundary|界限),但语义角色“RelateTo”和“concerning”都表示“与什么相关”,语义相似度极高,所以增加了三元组正确预测的难度。
表5列出了不同长度的复合型术语采用本文自动生成术语KDML表示生成结果的实例。
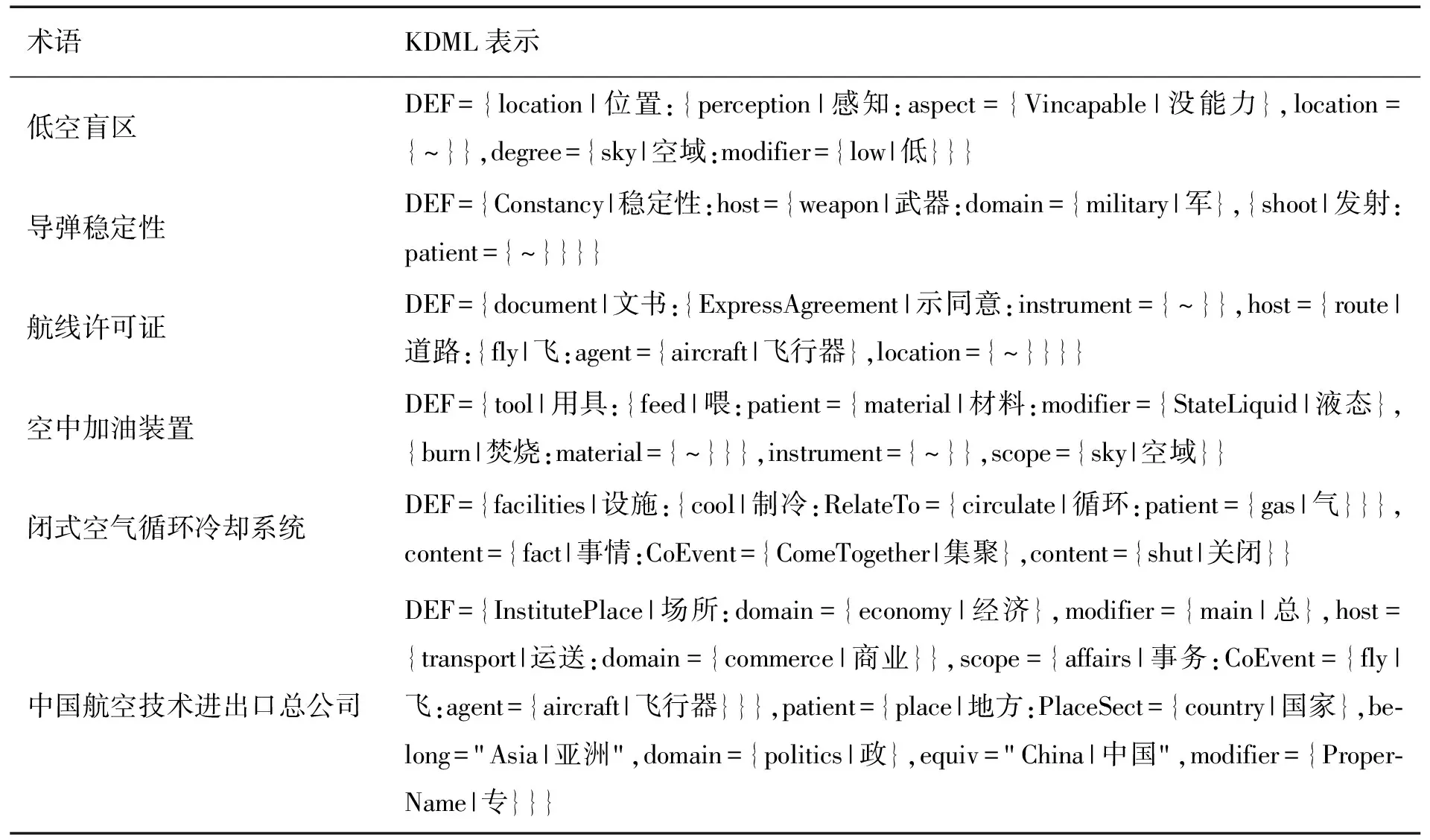
表5 自动生成术语KDML表示实例
4.4 实例展示
本文设计并实现了领域HowNet语义知识库构建系统,系统共分为4个模块,分别是输入模块、输出模块、人工编辑模块和中间计算结果显示模块,在本节以术语“橡胶减震垫”为例进行实例展示,系统实现的实验环境如表6所示。

表6 实验环境说明
(1)系统初始界面。如图1所示。

图1 系统初始界面
(2)系统输入模块。此处以术语“橡胶减震垫”为例,如图2所示。

图2 系统输入模块
(3)系统输出模块。输入术语后,点击系统输出模块生成DEF按钮,系统自动在输出框内输出术语的KDML描述,如图3所示的术语“橡胶减震垫”术语的输出DEF,可理解为“一种在嵌入时削弱颤动由橡胶制成的用具”。
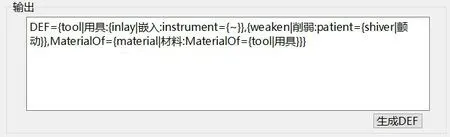
图3 系统输出模块
(4)计算过程结果显示。点击系统最上方的显示控件会显示生成DEF的中间计算过程,并会将语义选择和语义角色选择的计算结果显示在对应的子模块。如图4左边子模块中所显示的,术语“橡胶减震垫”的分词以及消歧后分词对应的DEF,与目标输出“DEF={part|部件:{weaken|削弱:patient={shiver|颤动},material={material|材料}},whole={implement|器具},{inlay|嵌入:instrument={~}}}”相比,可得出基于复杂概念由简单概念构成的思想,使得概念内部的语义角色和义原都保证了极大的一致性和准确性,如义原“weaken|削弱”“shiver|颤动”,语义角色“instrument”“patient”等,极大提高了语义角色和义原的准确率。

图4 计算过程结果显示
表7列出了图4语义角色预测结果子模块中的详细内容,其中子词对(垫,减震)预测得出的语义角色中“RelateTo”“modifier”“null”的得分相同,系统会为概念2处概念首义原类型为事件类义原的情况自动选择“null”,如图3系统预测结果中显示概念“垫”与“减震”之间无语义角色连接,可以验证系统能够正确为概念间预测语义角色,并按照语法规则将概念连接起来。概念“橡胶”与“减震”之间的语义角色使用了“MaterialOf”,理解为“橡胶制成材料为减震”,显然是不正确的,由此也反映出KNN算法能大大缩小语义角色的预测范围,但准确率有待提升,因此本文在设计系统时设置了人工编辑模块,如图5所示,以便校正保存。

图5 人工编辑、格式检查及保存

表7 “橡胶”“减震”“垫”各概念间的语义角色预测结果
5 结语
本文提出了一种基于概念结构与分布式表征的术语语义知识库构建方法,该方法面向复合术语,基于复杂概念由简单概念构成的思想,由术语内子词概念构筑出术语概念。首先将复合术语分为子词,之后消歧确定子词概念,判断子词概念间的语义角色。并且为了使概念与概念之间及概念与文本之间都能够量化计算语义距离,采用了分布式表征方法,将概念与术语定义文本表征为向量,应用于子词概念消歧及语义角色判断。通过实验,验证了所提出的方法能够基于术语及定义自动生成术语概念的形式化表示。在未来的工作中,考虑将该方法扩展至非复合术语,虽然非复合术语概念不是由子词概念构筑的,但也是由其他相关概念构筑的,研究定义术语概念的相关概念范围是未来的重点。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
幼儿画刊(2023年5期)2023-05-26 05:50:10
小学科学(学生版)(2021年6期)2021-07-21 09:18:30
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
小学科学(学生版)(2018年6期)2018-06-26 08:14:46
橡胶工业(2015年4期)2015-07-29 09:17:10
现代防御技术(2014年6期)2014-02-28 18:26:29
中国科技术语(2012年3期)2012-03-20 14:36:13
中国科技术语(2012年3期)2012-03-20 14:36:11
