
基于SURF和VLAD特征编码的面料图案检索研究
2023-09-25 11:21:02赵文浩潘如如
纺织学报 2023年8期
赵文浩, 向 军, 张 宁, 潘如如
(江南大学 纺织科学与工程学院, 江苏 无锡 214122)
随着快时尚时代的到来,消费者对纺织品的需求更加多元化,这也导致纺织服装生产企业的产品也随之变得更加多元化[1]。其中,面料在这种趋势下表现得更为明显,而面料多元化的同时为企业的仓储、管理带来了不小的挑战。如何从万级的面料库快速精准地挑出想要的图案面料对企业来说具有重要意义。目前,面料的相似图案检索主要采用基于内容的图像检索技术,并取得一定的效果。
基于内容的图像检索技术主要有二大类特征:低阶特征和高阶特征[2]。高阶特征需要通过网络模型进行训练提取相应特征,然而,训练模型需要覆盖面较广的数据,相对低阶特征需要的时间和计算资源要求更高[3]。低阶视觉特征从图像的平面属性来划分,有纹理、颜色、形状等特征,现有将不同的特征进行结合互补来实现对图像的有效内容进行表征,其不需要像高阶特征那样进行人为标注训练数据,提取消耗时间短,针对性较强。近几年国内基于低阶特征进行面料图像检索的研究主要有:康锋等[4]通过提取特定范围的SURF(speeded up robust features)特征对织物图案进行检索;向忠等[5]结合颜色和形状特征有效地在分辨印花图案形状的同时兼顾颜色特征;曹霞等[6]采用灰度共生矩阵、灰度梯度共生矩阵和局部二进制算子进行结合的方法对蕾丝图案有不错的检索效果。以上的研究针对少量且简单的面料图案有不错的效果,但不适用于企业级应用。因为面料企业的面料种类多种多样,数据库超过万级,这对检索算法的要求更加严格。刘颖等[7]通过SIFT与VLAD(vector of locally aggregated descriptors)聚合特征和全局特征结合对海量的现勘图像分类有着不错的效果,这对于同样海量的面料检索有着较好的参考价值[8]。
因此,本文针对大批量、结构复杂的面料图案的检索问题,提出了基于SURF和VLAD特征编码的面料图案检索算法并对其进行研究。
1 图像预处理
本实验采用从企业收集的面料样本建立数据集,共选取1 000张图案不同的面料图片作为原始数据图像库,对原始图像进行裁切、旋转、放缩等处理获得10张面料图片以扩充图像数据库。原始图像为 605像素×605 像素,分辨率为96像素/(2.54 cm),对原始图像进行旋转、裁切、放缩等一系列处理后,保存的图像尺寸为512 像素×512 像素。每张原始图像经过裁切并放大生成4张子图;分别经过旋转30°、60°、90°、120°、150°并在原始图像中取300 像素×300 像素的图片,统一放大到512 像素×512 像素,由一张原始图片获得9张子图,构建图片数为10 000张的数据库。
2 特征提取及相似性度量
2.1 SURF特征提取
SURF算法是由Herbert等[9]提出的一种图像局部特征描述算子,其采用了Hessian矩阵对积分图像中的每个像素点进行处理,构建尺度金字塔检测局部极值点,然后基于二维Haar小波变换定位特征点的主方向,并形成特征矢量,如图1所示。
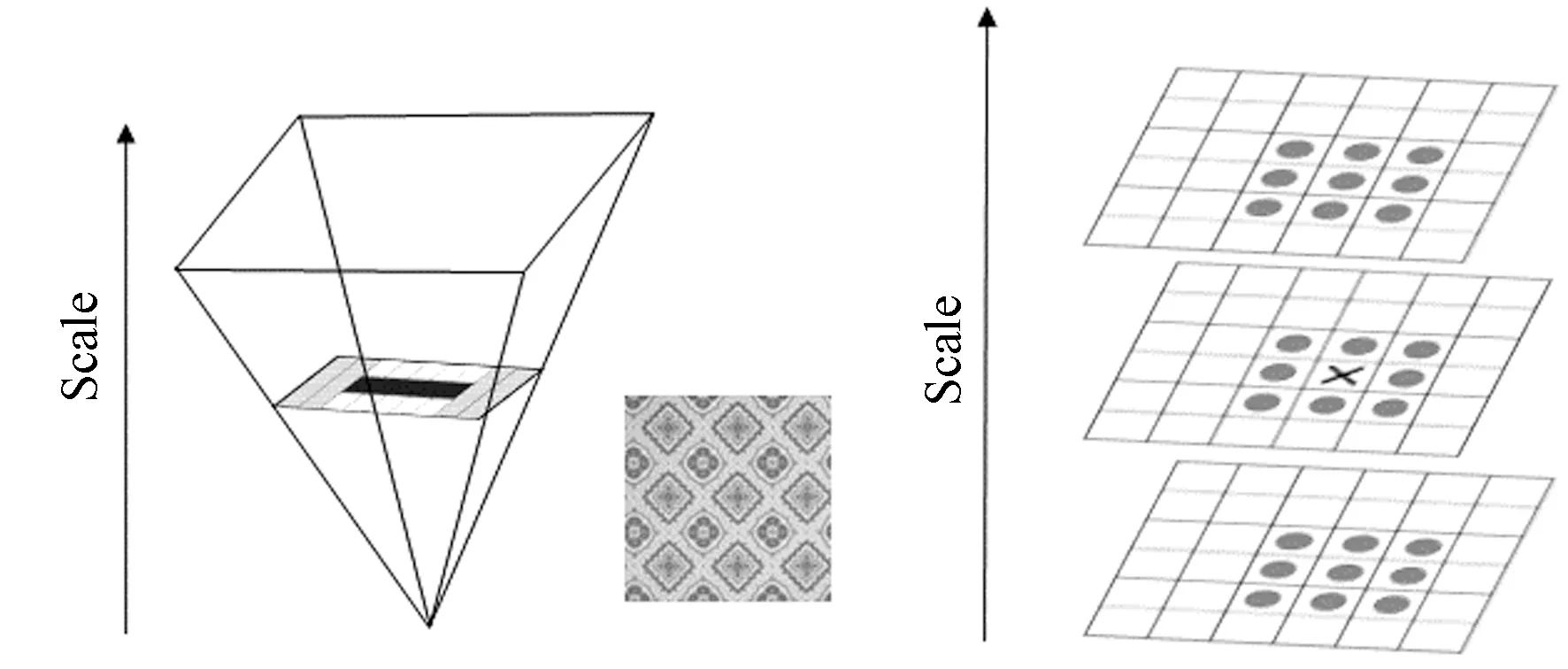
图1 尺度空间的构建与特征点的定位Fig. 1 Construction of scale space and location of feature points
构建图像金字塔时,常常使用盒式滤波器来近似卷积,每个像素的Hessian矩阵行列式近似值可由下式计算所得。
det(H)=Dxx×Dyy-(0.9×Dxy)2
(1)
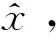
SURF特征具有旋转不变性,其对图像的偏移、旋转有较好的适应性。其特征向量的计算方式为:1)确定主方向。通过统计以特征点为圆心,6 s为半径的水平和垂直方向的Haar小波响应,然后以60度为一个区间进行旋转,计算各个区间的Haar小波特征总和及特征值,选取最大的区间方向作为该特征点的主方向;2)计算特征向量。通过确定的主方向对特征点进行旋转使其保持一致,区域大小为 20 s×20 s, 再进一步均匀划分为16个子区域,分别对子区域的水平和垂直方向的小波响应求和及绝对值加和。如图2所示,一个子区域得到一个分向量V,因此16个区域总共能得到64维的向量。
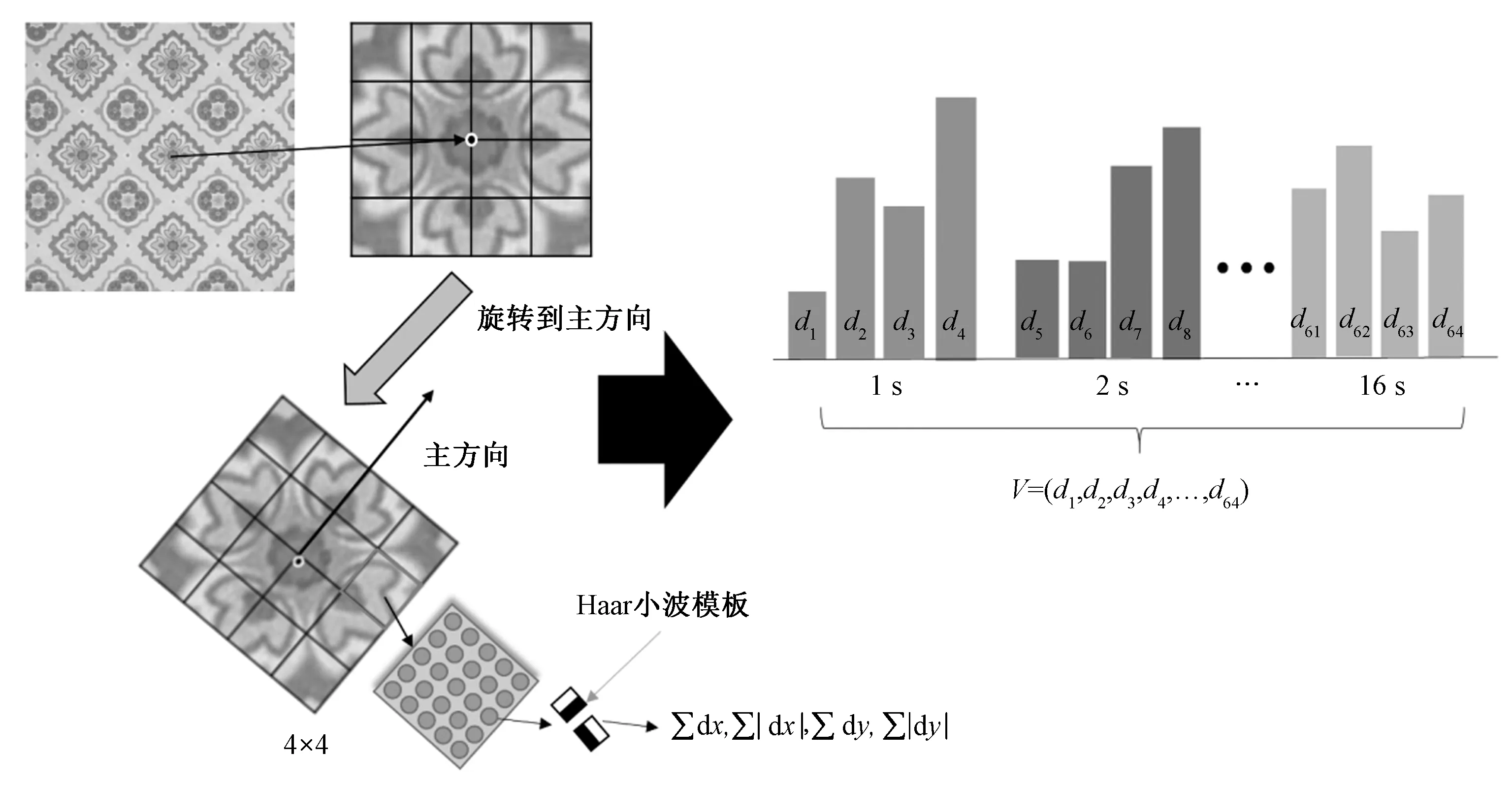
图2 特征描述子的生成Fig. 2 Generation of feature descriptor
2.2 VLAD特征
2.2.1 码本的生成
VLAD的码本是由聚类生成的,本文所采用的Mini Batch K-Means算法[10]是K-Means的一种优化方案,其适用于数据规模较大的聚类。该方法将大规模的数据通过每次只采取小部分少量的数据进行中心节点的更新,不断迭代至中心节点达到稳定或者达到设定次数,才会生成码本。该方法相较于K-Means节省了大量的计算资源和计算时间,对于海量数据有较好的效果。图3示出码本的训练流程。
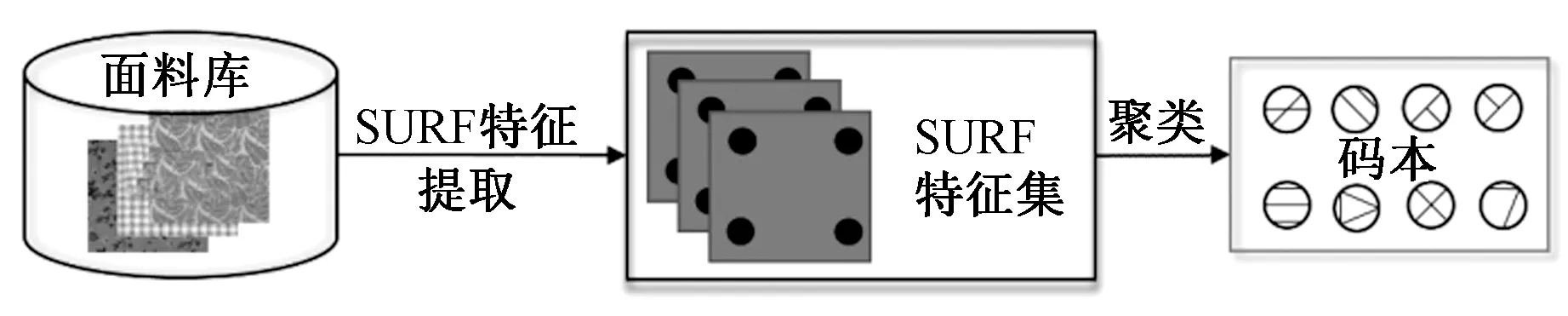
图3 码本的生成Fig. 3 Generation of codebook
2.2.2 VLAD的生成
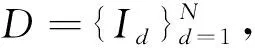
通过NN近邻法将待检面料的SURF特征si,j与码本类比,将特征点与码本的类别进行归类,i是类别号,j是该特征点在这个类别的排序,进而计算残差值ri,j。残差值计算如式(2)所示。
ri,j=si,j-ci
(2)
每个类别中,对待检图像的所有SURF描述符计算残差,所以每个类别的VLAD特征通过式(3)计算可得。因此,每张图像的VLAD向量就是计算k个类别,即长度为k×64。VLAD的特征算法生成过程如图4所示。
(3)
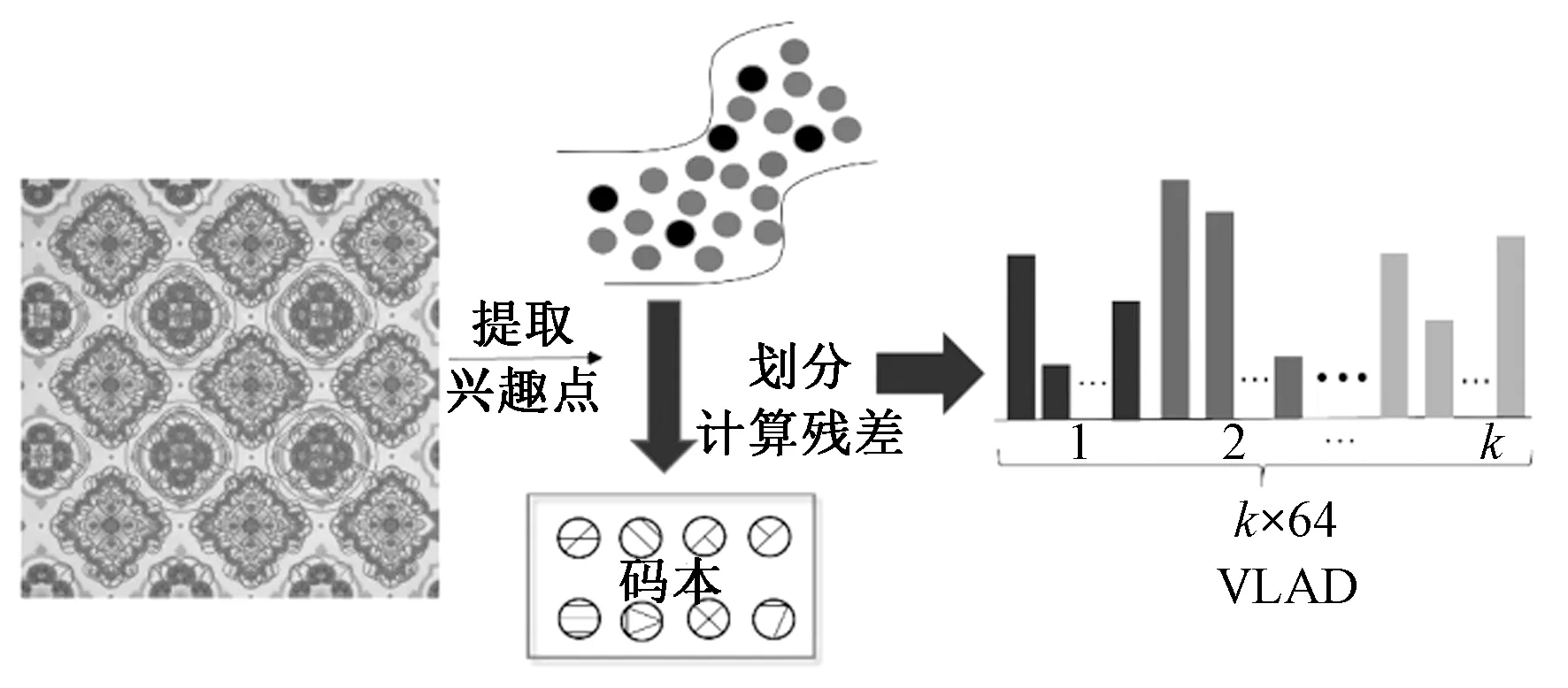
图4 VLAD特征算法的生成Fig. 4 Generation of VLAD
对于面料图像来说,其图案复杂多变,结构差异大,且重复性结构较多,导致在特征提取时其特征点数量较多,且大都为重复,不利于检索迅速响应。因此本文采用主成分分析法(PCA)对VLAD进行降维,VLAD的特征矩阵为V(V1,V2, …,Vk) 。通过优化得到式(4)目标函数。
YP=WTV
(4)
式中:V表示提取训练正样本VLAD特征向量;YP表示降维后的VLAD特征向量;W为协方差矩阵。
2.3 相似性度量
相似性度量一般直接通过计算待检图像特征与数据库中图像特征之间的距离实现,由于数据库的图片数量庞大,特征维度高,在检索过程中计算会耗费大量计算资源,检索效率低下。为解决这个问题,通常采用最近邻的快速计算,常用的3种算法是暴力计算、KD-tree、Ball-tree。对于D维度中的N个样本来说,暴力计算的复杂度为O[DN2],随着样本数N的增加,暴力计算的复杂度迅速增大,使用其用来构建索引和查询都不切合实际;KD-tree结构为二叉树结构,其查询时间的变化是很难精确描述的,对于低维度(D<20)的近邻搜索非常快,其成本大约是O[Dlog2(N)],但当D增大到很大时,其成本的增加接近O[DN],且由于树结构引起的开销导致查询的效率比暴力计算还要低;不同于KD-tree的沿笛卡尔坐标轴分割数据,Ball-tree是在一系列嵌套的超球体上分割数据,虽然在构建数据花费上超过KD-tree,但在高维数据上的表现很高效[12],其查询时间大约以O[Dlog2(N)]增长。对于稀疏的数据,Ball-tree和KD-tree的查询效果几乎一样。本文中样本数为10 000,经过VLAD编码并降维后的数据维度为512,且数据稀疏,所以综合考虑,选用Ball-tree更为合适。图5示出了Ball-tree结构,每个节点代表1个球。
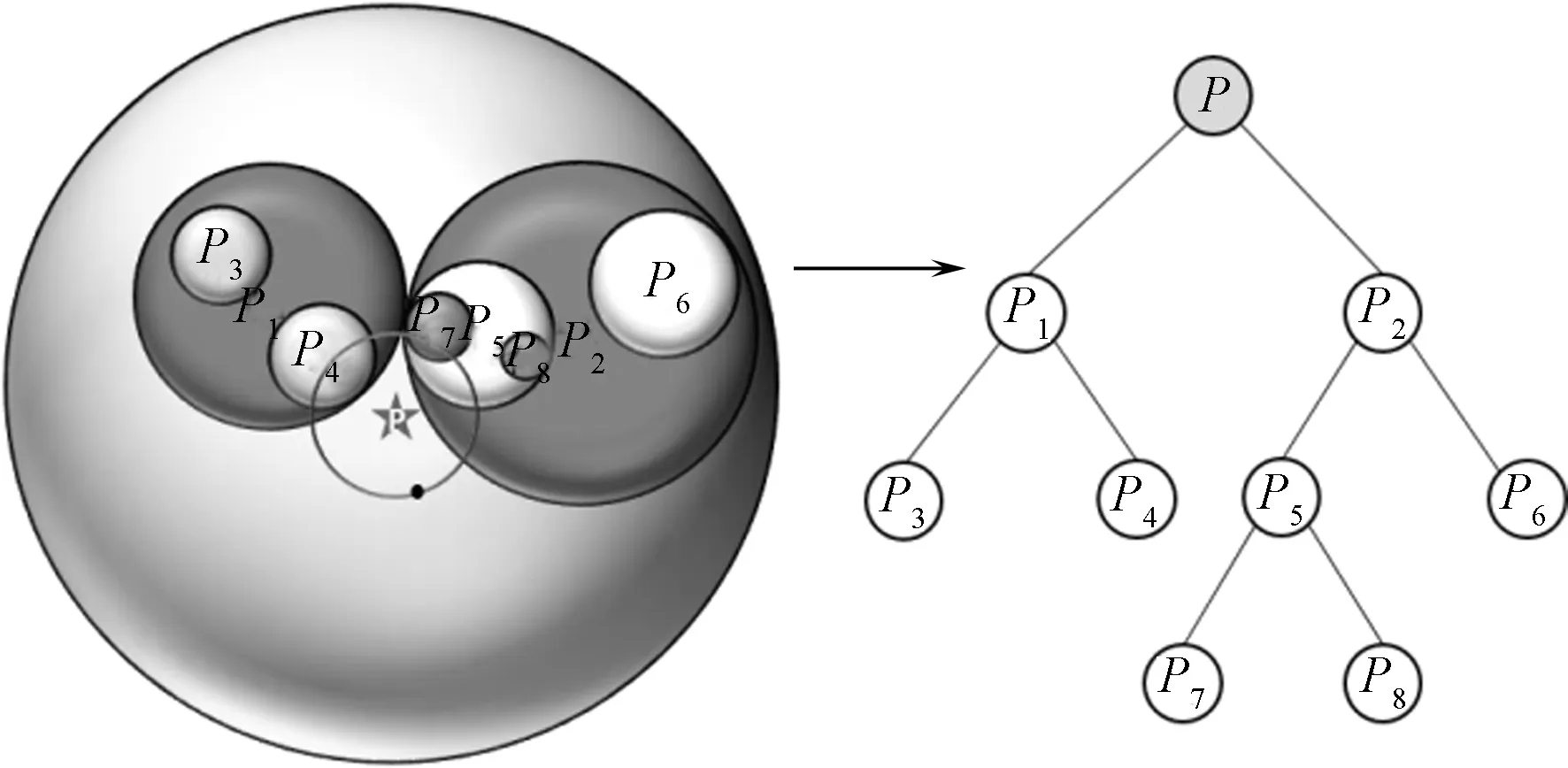
图5 数据集的球树结构Fig. 5 Spherical tree structure of data set
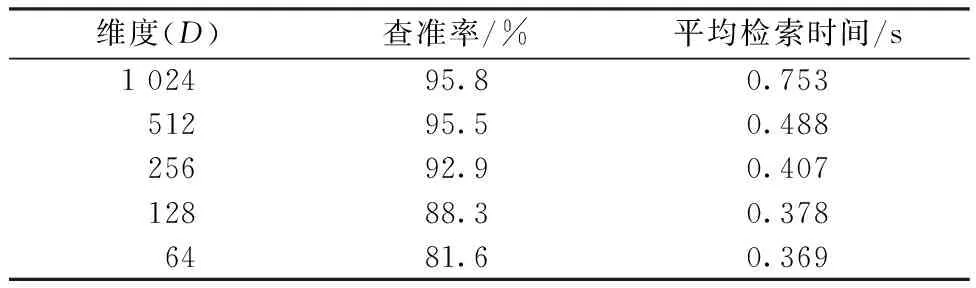
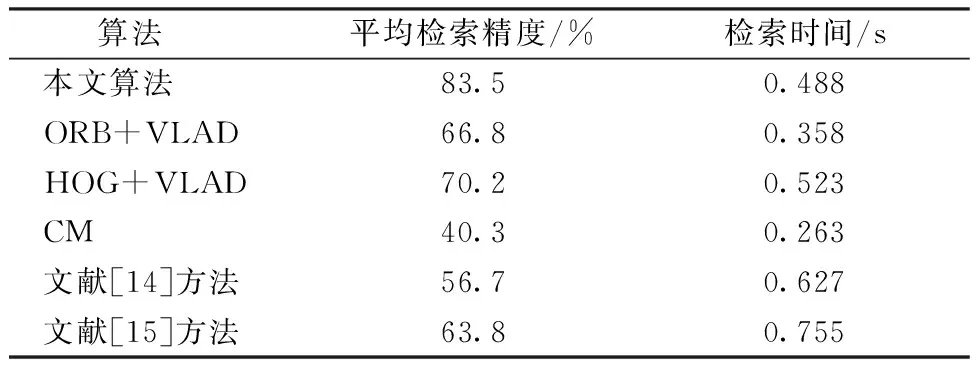
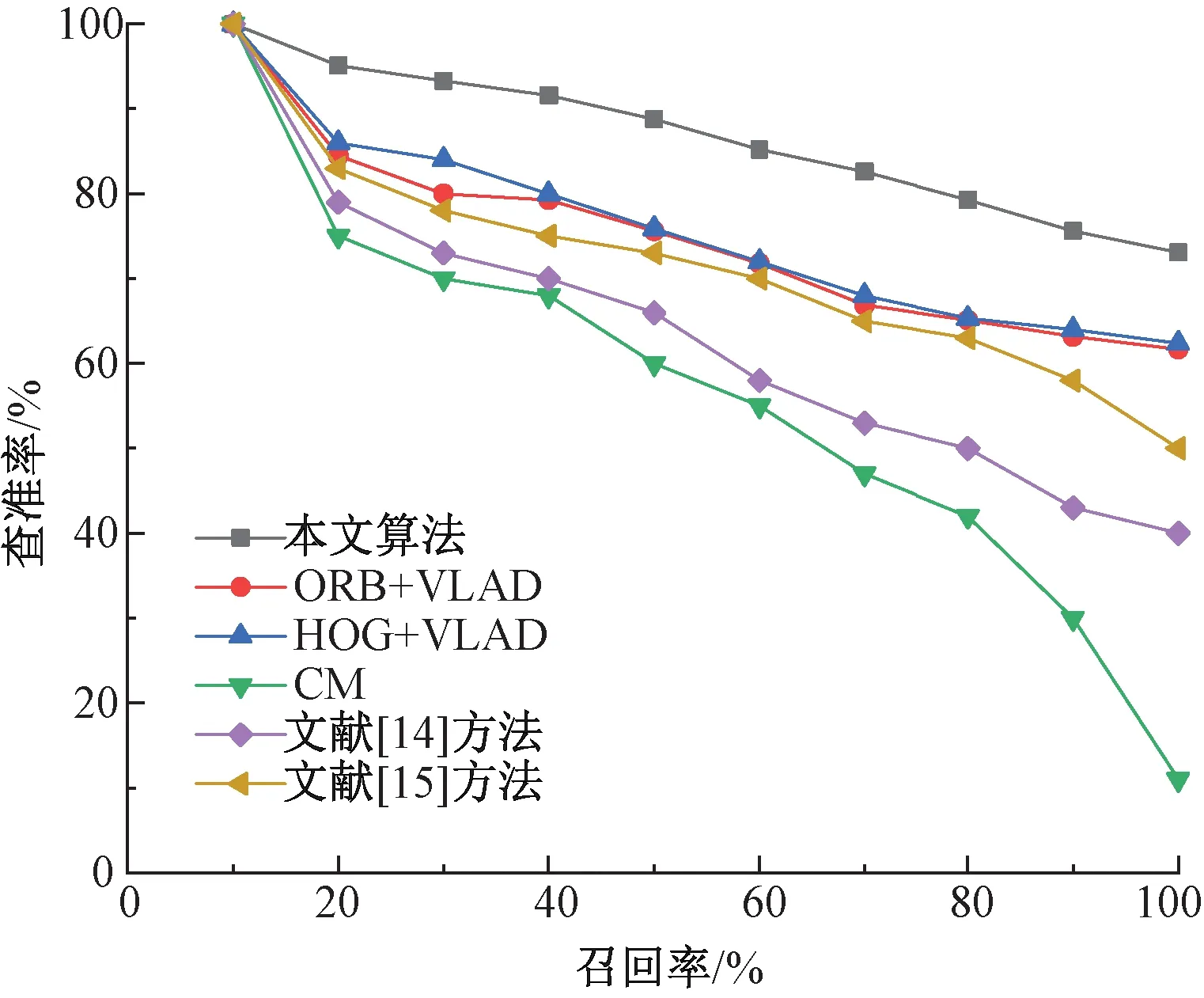
使用Ball-tree查询时,用来搜索目标点P的K个最近邻。假设DS是目标节点与最近邻点的最小距离,DS=maxx∈pin∣x-t∣,t和当前节点的距离可通过式(2)~(4)定义,其中pin表示发现的最近邻点。若DS DN=max{DN.parent,|t-center(N)|-radius(N)} (5) 本实验通过SURF算法提取面料的图案特征,将图案特征进行聚类构建视觉码本,将面料库里图像的SURF描述子找到与码本中最近的聚类中心计算残差,最终得到VLAD特征;由于得到的VLAD特征维数比较高,采用PCA[13]进行降维,降维后的VLAD通过Ball-tree算法构建索引。当输入待检索图像时,首先对其提取SURF特征,然后根据码本生成VLAD并降维,将降维后的VLAD特征在构建好的Ball-tree中查询,按相似度的大小进行排序并返回结果,实现对图案类面料的检索。整个检索流程如图6所示。 图6 图案类面料检索算法流程Fig. 6 Flow chart of pattern fabric retrieval algorithm 本文利用查准率(P)、召回率(R)以及每张照片的检索精度(PAP)和平均检索精度(PmAP)作为实验性能评价指标。计算公式如下所示。 (6) (7) (8) (9) 式中:S为检索结果中与待检索图像相似的图像数量;U为检索结果中与待检索图像不相似图像的数量;V为未检索到的与待检索图像相似的图像数量;P(K)为截止点K处的精确率;r(K)为指示函数。当图像在K处是待检索图像的相似图像,则r(K)等于1,否则等于0。K和n分别表示截止点和检索的图像数目;NR表示相似图像的数量;Q表示检索次数即检索的图片总量。 为验证本文算法对图案类面料检索的有效性和可行性,实验在Pycharm 2021.3软件运行实现。计算机硬件配置为Intel Core i5-7300HQ处理器,CPU主频2.50 GHz,16 GB内存,操作系统为Windows10,从面料数据集中随机挑选5 000张图片作为待检索图像,在包含10 000张图像的数据集上进行实验,对本文算法进行论证。 4.1.1 评估不同视觉词典规模的影响 当Mini Batch K-means算法采用不同的视觉词典规模(K),选取前10张返回图片计算查准率,查准率和时间的变化如表1所示。 从表1可以看出,在一定范围内,随着字典规模K的增加,面料的查准率有所提升,然而,当K增长到1 024时,查准率增幅较小,检索所耗时间翻倍增长。这是因为当视觉词典规模较小时,视觉单词较少,生成的VLAD编码不能很好的描述图像的特征,而当视觉词典规模较大时,在聚类生成词典时会出现分类过度,产生一些噪声单词,导致生成的VLAD编码的分辨能力有所降低,减弱了查准率的提升。由于随着视觉词典规模的增大,训练视觉词典的复杂度和时间成本大大提升,所以综合考虑,本文后续的实验中取K=512。 表1 不同视觉词典规模下的查准率和时间对比Tab. 1 Comparison of retrieval precision and time under different visual dictionary sizes 4.1.2 评估不同维度下VLAD特征的影响 对于面料图像来说,其图案复杂多变,结构差异大,且重复性结构较多,这导致了在特征提取时其特征点数量较多,且多为重复,不利于检索迅速响应。因此,采用主成分分析(PCA)对VLAD特征进行降维生成P-VLAD,选取前10张返回图片计算查准率,保留后的特征维度数(D)对查准率和时间的变化如表2所示。 从表2可以看出,随着维度的降低,面料的查准率不断降低,当维度降到64时,面料的查准率下降幅度大大提升,检索时间下降幅度缓慢。这是因为当VLAD维度减少较少时,可有效去除冗余信息,但当维度下降较多会导致VLAD的有效信息部分丢失,不利于有效地表达图像特征,维度的适度下降可有效地降低计算成本,节省检索时间。综合考虑算法的有效性和时间复杂度,在本文后续的实验中取D=512。4种典型纺织面料图案检索效果如图7所示。前3张检索结果理想,第4张的检索结果最后一张出现了误检。误检原因是图像之间的相似度较高,而本文为了提高检索的效率,降低了视觉词典的规模和VLAD的维数,忽略了图像的部分细节。 表2 维度对查准率和时间的影响Tab. 2 Influence of dimension on retrieval precision and time 注:数字1~10代表检索结果返回顺序。图7 检索效果展示Fig. 7 Display of retrieval effect 颜色矩(CM)和灰度共生矩阵(GLCM)是图像检索中常用的颜色和纹理提取方法,ORB,HOG通常用来提取图像的形状、纹理特征。为验证本文算法对图案类纺织面料的优越性,对比“ORB+VLAD”、“HOG+VLAD”、“颜色矩”、文献[14]中的“CM+GLCM”和文献[15]中的“分块颜色直方图+GLCM”方法进行检索验证。其中,“ORB+VLAD”、“HOG + VLAD”的参数与本文保持一致,特征组合类算法的特征权值均为0.5,相似性度量方法采用欧氏距离。表3示出对上述算法的平均检索精度和单张图片检索时间的对比。可以看出,本文的算法模型对该数据集有着较好的检索效果,其平均检索精度高达83.5%,明显优于其它算法。在检索时间上面,由于CM只计算了颜色矩所以速度明显快于其它算法,而文献[15]方法计算了分块颜色直方图,导致检索时间增加,其余几种算法的检索时间差异不大,检索效率大致相同。本文主要关注检索精度,综合来看本文的算法是有效的。 表3 不同算法的平均检索精度和检索时间对比Tab. 3 Comparison of mean average precision and retrieval time of different algorithms 在纺织企业的实际生产中,面料的花纹大小以及采集面料的角度和尺寸具有一定的随机性,这就要求使用的算法具有一定的尺寸不变性和旋转不变性。为验证本文提出算法的尺寸不变性和旋转不变性,选用文献[14]和文献[15]的算法作为对照组。如图8所示,文献[14]算法的检索效果较差,从检索结果来看,只有第1张,第3张,第6张是与待检面料相关的,这3张图片均相较于待检图像而言只是旋转了30°的范围,而其余经过尺寸放缩的图片未检出一张,说明文献[14]算法不适用于图片尺寸放缩变换、旋转角度大的情况,不具有旋转不变性和尺寸不变性。文献[15]算法是分块颜色直方图和灰度共生矩阵的结合,由图8的检索结果来看略好于文献[14]的算法,检索结果中前五张和第九张待检图像相关,与文献[14]相比,分块颜色直方图相较于传统的颜色直方图在关注全局颜色特征的同时联系了颜色之间的空间局部特征,具有一定的尺寸不变性,所以前5张检出了经过旋转处理的图片,但由于灰度共生矩阵不具有旋转不变性和尺寸不变性,所以经过放缩变换的图片只在检出一张。由图8可知,本文算法检出的10张图片均与待检图片相关,本文提出的算法对于图片的旋转、放缩均有较好的检索效果,证明了本文所提算法具有良好的尺寸不变性和旋转不变性。 注:a—待检图像;b—本文算法检索结果;c—文献[14]算法检索结果;d—文献[15]算法检索结果。数字1~10为检索结果返回顺序。图8 不同算法的检索效果Fig. 8 Retrieval effect of different algorithm 图9示出不同检索算法的查准率-召回率(P-R)曲线。可以看出,本文的算法在所建数据集上表现最好,“HOG+VLAD”略好于“ORB+VLAD”,这表明了SURF相较于ORB和HOG能够更好地描述图案类面料的特征,文献[14]和CM在所建数据集上表现较差,这表明CM、文献[14]和文献[15]方法不适用于复杂结构的面料图案检索。 图9 不同算法的P-R曲线图Fig. 9 P-R curves of different algorithms 本文针对数据量大、图案多元化的面料图案检索问题,提出了一种基于SURF和VLAD特征编码的纺织面料检索算法,讨论了在视觉词典规模(K)和主成分分析法(PCA)保留维度数(D)对检索效果的影响。实验结果表明,在视觉词典规模为512,保留维度数为512时,该算法对面料图案检索的平均检索精度达到了83.5%,平均检索时间为 0.488 s, 且具有良好的尺寸不变性和旋转不变性,这对纺织企业的实际运用有着一定的现实意义。3 检索算法流程与评价标准
3.1 检索算法流程

3.2 评价标准
4 结果与分析
4.1 参数优选
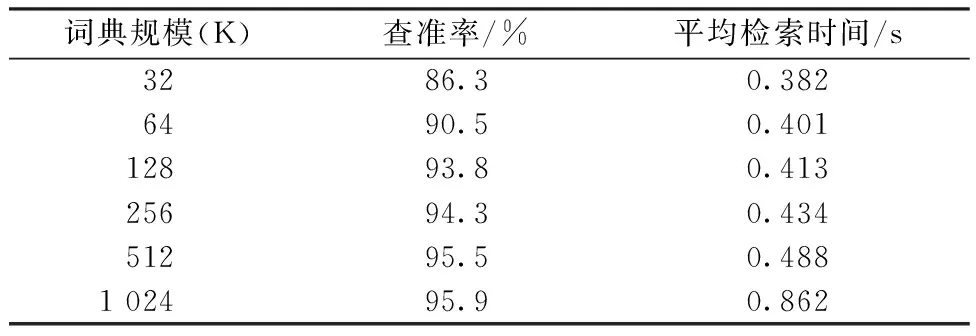

4.2 不同算法比较

5 结 论
猜你喜欢
中国民航大学学报(2022年5期)2022-12-19 16:46:40
南京邮电大学学报(自然科学版)(2022年4期)2022-09-20 01:41:50
中国民航大学学报(2021年3期)2021-08-04 03:20:50
纺织服装流行趋势展望(2020年3期)2020-02-01 06:43:08
纺织服装流行趋势展望(2020年1期)2020-02-01 06:33:14
纯粹数学与应用数学(2018年3期)2018-10-10 08:07:40
现代电子技术(2017年23期)2017-12-20 13:23:31
计算机应用(2016年10期)2017-05-12 11:02:20
纺织服装流行趋势展望(2016年6期)2016-05-04 03:53:12
纺织服装流行趋势展望(2016年1期)2016-05-04 03:45:58
