
基于Zeppelin+Hive的数据分析与可视化
2023-09-25 17:13张玉叶孙延坤
现代计算机 2023年14期
张玉叶,孙延坤
(1. 济南职业学院计算机学院,济南 250014; 2. 济南沃尔菲斯科技有限公司,济南 250014)
0 引言
随着移动互联网和智能手机的迅速普及,电子商务、云计算、虚拟现实、人工智能等技术的不断发展,传统产业不断被重塑,大数据产业成为了新的产业革命核心[1]。各行各业正在以前所未有的速度每天产生海量数据,数据正在成为一种新的资源和新的生产要素[2]。大数据产业当前仍处于技术高速发展时期,用到的框架和工具有很多,其中用于做数据分析处理及可视化的方案也有很多,可根据实际使用场景来选择。本文选用的是Zeppelin 和Hive,Zeppelin 是一个基于Web 的notebook,提供交互式数据分析和可视化功能。后台支持接入多种数据处理引擎,如Spark、Hive 等。同时支持多种编程语言,如Scala、Python、Spark、Markdown、Shell 等;Hive 是一个基于Hadoop 的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,然后通过相应的SQL 语句来对海量数据进行联机分析处理[3]。Zeppelin 本身内置了柱状图、折线图、饼图、散点图、面积图等最常用的几种基本图形,只要将相应的数据查询出来,不需要写任何代码就可直接实现数据可视化,使用起来相对比较简单,因此利用Zeppelin和Hive做数据分析与可视化是目前业界应用较广也是比较容易掌握的一种方案。
本文利用Zeppelin 和Hive 来对一组房屋销售数据进行分析处理及可视化,通过此例来展示使用方法,从而快速上手数据分析与可视化。
1 数据集
数据来源于某地区的房屋销售记录,选取了某一年的销售记录作为原始数据集,数据集中的部分数据如图1所示。
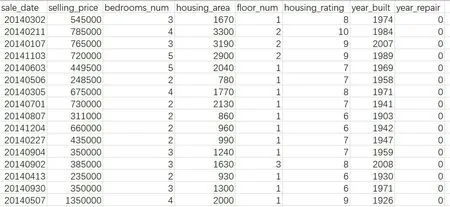
图1 数据集中部分数据
数据集中各字段含义依次为销售日期、销售价格、卧室个数、房屋面积、楼层数、房屋评分、房屋建造年代和房屋修缮年代。
2 环境准备
要使用Zeppelin和Hive,首先需要先搭建好相应的Hadoop,可根据实际情况选择搭建伪分布式或完全分布式,然后安装好相应的Hive[4]。确保Hadoop 和Hive 能够正常使用,然后安装部署Zeppelin。本文示例所使用的是Hadoop 伪分布式,各组件相应的版本为Hadoop2.7.7、Hive2.3.4和Zeppelin0.10.0。
3 数据分析及可视化
数据分析是指用适当的分析方法对收集来的大量数据进行分析,提取有用信息和形成结论,对数据加以详细研究和概括总结的过程。数据分析包括狭义的数据分析和广义的数据分析。狭义的数据分析是指根据分析目的,采用对比分析、分组分析、交叉分析等分析方法,对收集的数据进行处理与分析,提取有价值的信息的过程;广义的数据分析是指依据一定的目标,通过统计分析、聚类、分类、回归等方法发现数据中隐含的信息的过程。即狭义的数据分析主要是从数据中提取显性的信息,而广义的数据分析则主要是从数据中挖掘隐含的信息,因此广义的数据分析实际上是狭义的数据分析加上数据挖掘[5]。
数据可视化就是以图形化方式表示数据。要想把数据可视化,必须知道它表达的是什么。数据是对现实世界的简化和抽象表达,当可视化数据时,其实是在将对现实世界的抽象表达可视化。数据可视化可帮助人们从一个个独立的数据点中解脱出来,换一个不同的角度去探索和理解它们。
通常,使用自然语言、数字等形式表达的概念是枯燥的、不易懂的,而可视化的技术可增加数据的生动性,图表的应用可使数据更具有可读性。“一图抵千言”,数据可视化能让决策者通过图形快速直观地看到数据分析结果,从而更容易理解业务变化趋势或发现新的业务模式[6]。
在人工智能和大数据时代,数据分析与可视化是人类理解和处理海量数据的关键技术,可以帮助人们快速从海量数据中发现和获取相应的信息或者帮助人们在错综复杂的数据中发现和验证不同维度和指标之间的关联。
不同的数据集有不同的分析目标和数据指标。通常情况下可将数据分为三类:用户数据、行为数据和商品数据。用户数据通常是记录用户基本信息的;行为数据则是记录用户做过什么,如对于电商数据则可能是用户的购买行为、浏览行为或是收藏行为等;而商品数据则是记录商品的基本信息。对于不同的数据有不同的数据分析指标,如对于用户数据比较关注的是新增用户数、用户活跃率和留存率等,对于行为数据则比较关注访问次数、访问人数、转换率等指标,而对于商品数据比较关注的则是成交量、成交额等。
上面列举的只是一些通用数据指标,对于具体的数据集除了一些通用数据指标外还可以根据具体情况来分析其它的一些相关数据指标。本数据集属于商品数据,因此对于此数据集,其分析目标主要是房屋的成交量、成交额,除此之外还可以分析房屋面积与价格之间的关系、不同评分或不同类型的房屋数量等。
3.1 统计每月的房屋销量
数据集中存放了2014 年的房屋销售数据,通过统计每月的房屋销量,可以得出每个月的销量情况。相应的代码及查询结果如图2所示。
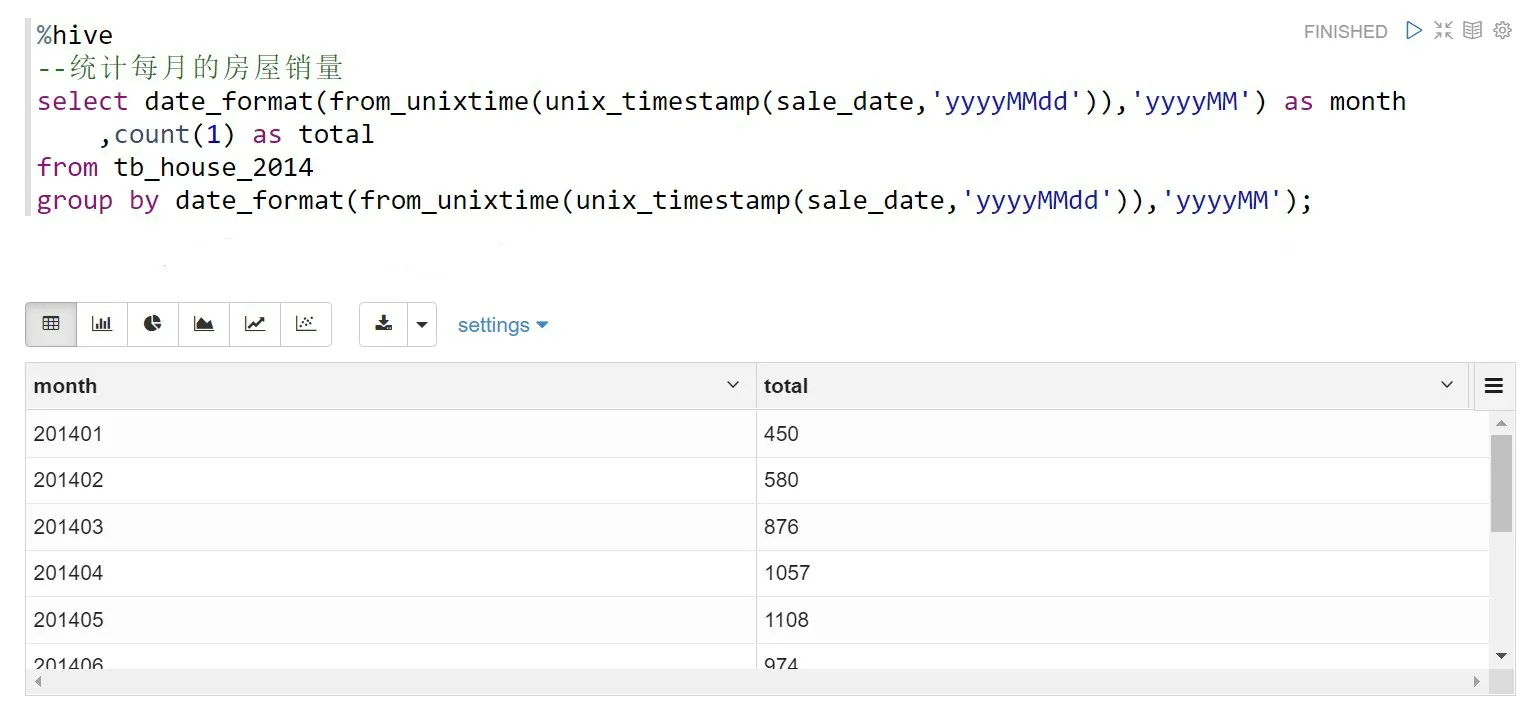
图2 每月的房屋销量查询结果
Zeppelin 中,默认情况下数据查询结果是以二维表格的形式显示的。可通过点击数据上方的相应按钮来快速实现数据的可视化。如单击折线图按钮,则数据以折线图显示。结果如图3所示。也可以直接通过点击柱状图按钮,将其以柱状图显示,结果如图4所示。柱状图适宜展示各分组数据之间的数量比较。

图3 每月房屋销量折线图
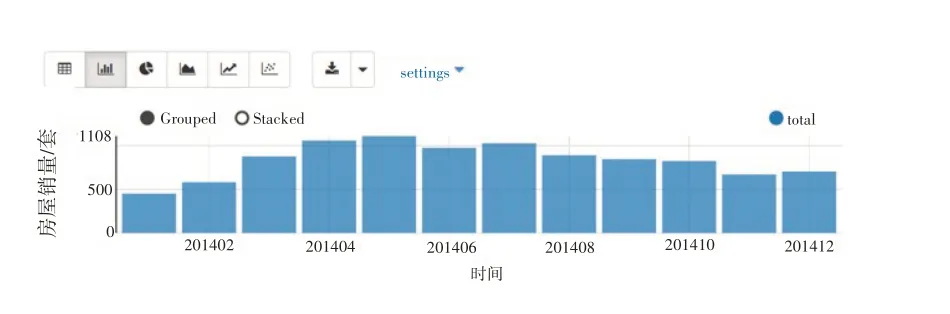
图4 每月房屋销量柱状图
如果是想查看各月的销量占比情况,则可直接点击饼图按钮,将其以饼图显示,结果如图5所示。饼图适宜描述各分组数据在总数据中的占比情况。

图5 每月房屋销量占比饼图
同样的方法可统计分析每月的房屋销售额,还可以按季度来统计房屋的销量和销售额等。对于统计得到的数据可根据需要以相应的图形进行展示。
3.2 房屋面积与销售价格之间的关系
如果想要了解房屋面积与房价之间的关系,可通过绘制相应的散点图来查看。散点图适宜展示两个变量之间的相关性。代码及结果如图6所示。

图6 房屋面积与房价散点图
通过上述结果可以看出,房屋面积与房价之间具有一定的正相关性,即房屋面积越大,其房价越高。
3.3 不同评分的房屋数量
如果想要了解用户对房屋的评分情况,可通过分析不同评分的房屋数量来获取。代码及结果如图7所示。同样,如果是想查看数量,可用柱状图展示,如果想查看不同评分的房屋占比,则可改用饼图展示。类似的方法还可统计不同楼层数或不同卧室数的房屋数量等。

图7 不同评分的房屋数量柱状图
4 结语
大数据时代如何快速有效处理海量数据,从中发现和提取人们所需要的有用信息已经成了各行各业的急需。而基于Zeppelin 和Hive 的数据分析及可视化可用相对简短的代码帮助人们快速有效地处理数据并获取到相关信息,掌握Zeppelin 和Hive 的使用已经成了各行业数据分析师所必备的基本技能。本文通过一个实际数据集展示了如何利用Zeppelin 和Hive 来进行数据分析及可视化,其实现简单方便,在目前大数据时代背景下有着广泛的应用领域和良好的使用前景。读者可参考其实现思路稍微改动一下即可实现更多类似的数据分析及可视化效果,从而快速提高数据分析及可视化能力。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代水产(2021年7期)2021-11-04
喀什大学学报(2021年6期)2021-03-12
当代陕西(2019年14期)2019-08-26
汽车观察(2019年2期)2019-03-15
汽车与驾驶维修(汽车版)(2017年2期)2017-03-18
中学数学杂志(初中版)(2016年5期)2016-11-01
现代计算机(2016年16期)2016-10-18
家用汽车(2016年4期)2016-02-28
河南水利与南水北调(2015年22期)2015-08-19
