
面向复杂道路目标检测的YOLOv5算法优化研究
2023-09-25 08:58刘鑫满刘大东
计算机工程与应用 2023年18期
刘 辉,刘鑫满,刘大东
1.重庆邮电大学通信与信息工程学院,重庆400065
2.重庆邮电大学数智技术应用研究中心,重庆400065
随着经济社会的发展,汽车在出行方面给民众带来了极大便利,但随着汽车数量的增多也带来了一系列的问题,例如交通事故频发、道路拥堵严重等。自动驾驶技术已成为解决这些交通问题的关键性技术,并持续受到众多国家和企业的广泛关注。
自动驾驶汽车在行驶过程中,需要持续地感知瞬息万变的周边道路环境,并在必要时根据感知到的信息采取相应的措施。目标检测是自动驾驶汽车环境感知系统的重要组成部分,其通过检测车辆前方或周围的障碍物目标,使决策系统接收到道路信息进行决策从而保证驾驶的安全性。自动驾驶领域的目标检测方法多样,包括基于三维点云、基于双目视觉、基于单目视觉等不同数据形式的检测方法。其中,基于单目视觉的方法以其设备部署简单、数据形式易于组织分析且对硬件负担较小等优点,成为了自动驾驶感知系统研究的热点[1-3]。
单目视觉目标检测的传统方法对道路目标的检测需要手工设计合适的特征提取器,如尺度不变特征变换(scale-invariant feature transform,SIFT)[4]、方向梯度直方图(histogram of oriented gradient,HOG)[5]等,这些方法不仅设计工作量大且泛化能力与鲁棒性较差,难以应用于身处复杂道路环境的自动驾驶汽车上。基于深度学习的方法以其检测精度高、泛化性能强等优势,开始广泛进入自动驾驶领域目标检测的研究者们的视野[6-7]。曹磊等[8]基于Faster RCNN 方法进行车辆检测,精度良好但实时性较弱。Faster RCNN 属于二阶段目标检测算法,这类算法在检测速度上不如单阶段算法,且由于其框架限制导致检测速度难以满足要求,而单阶段算法尽管精度稍低但更容易改进。Yin等[9]基于SSD单阶段检测算法,改进了特征融合网络并引入空洞卷积提升特征图的感受野,提升了对于多尺度目标的检测效果,权衡了模型的检测精度和速度。郁强等[10]基于多尺度特征图的YOLOv3算法提高了道路小目标的检测精度,一定程度上改善了检测效果。
自动驾驶汽车面临复杂的道路环境,存在众多尺寸较小且存在遮挡的难检测目标,常规检测算法对此表现一般,要获得较好的检测效果往往需要对其进行针对性改进。单阶段目标检测算法YOLO自面世以来,就受到业界学者的广泛关注,近年来,YOLO算法不断优化、更新版本,到了YOLOv5版本,算法在满足实时性的同时,还具备了较高的检测精度和较为轻量化的网络结构,适合运用于对自动驾驶场景中目标的检测进行针对性改进[11-14]。Wang 等[15]基于YOLOv5 增加浅层检测层来提高道路小目标的检测精度,但使得模型提取的有效特征被过度分散而不利于常规目标的检测导致整体精度提升不明显。郑玉珩等[16]通过采用BiFPN 的特征融合结构改进YOLOv5 算法来提升网络的特征复用和组合能力增强了特征表达的多样性,从而改善遮挡目标易漏检误检的问题,但其大量增加的跨层连接导致了模型推理速度下降,这对算法的实时性影响较大。
针对常规算法对于道路小目标和遮挡目标易漏检、误检的问题,本文基于YOLOv5s 模型进行改进研究:(1)针对由于道路目标尺寸分布的不平衡导致现有聚类算法效果不佳问题,改进现有的K-means++算法,并采用改进算法重新聚类预设锚框,缩短边界框的收敛路径;(2)为提升对道路小目标的检测性能,设计了一种融入了注意力机制的多梯度流残差结构的路径聚合型特征增强模块PAA(path aggregation with attention),替换骨干网络中的C3 模块,增强模型对小目标的检测能力;(3)通过引入EIoU(effective intersection-over-union)loss来增强模型对于目标边界框的定位精度,提高算法对于遮挡目标的检测能力。通过上述网络结构调整、预设边界框及损失函数改进,使算法能够更好地适用于复杂道路场景的目标检测,获得优良的检测效果。
1 YOLOv5s算法介绍
YOLOv5s模型是YOLOv5五种规模的模型(YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x,由前往后规模不断提升)中权重文件大小和检测性能较为均衡的一个模型,其权重文件的大小只有14 MB且可胜任常规场景的检测任务。YOLOv5s 的6.0 版本的网络结构包括输入端(input)、骨干网络(backbone)、特征融合网络(neck)和预测端(prediction)4 个部分,各部分具体结构如图1所示。

图1 YOLOv5s 6.0版本的网络结构Fig.1 Network structure of YOLOv5s of version 6.0
由图1 可知,backbone 的第1 层是包含卷积核尺寸为6×6的大卷积核的Conv模块,与之前版本的Focus模块有所不同,作为一种有参数可训练的模块,Conv可以更具针对性地下采样,有选择性地保留道路目标的重要细节信息。backbone第3层是C3模块,其作为残差学习的主要模块,能够有效增强下采样得到的道路目标特征图的同时防止网络退化。backbone 第10 层是SPPF 模块,可以将不同尺寸的输入图像统一为相同尺寸的特征图,以提高算法的灵活性。YOLOv5s 的neck 部分为特征融合层,采用FPN(feature pyramid network)+PAN(path aggravation network)的框架,将具象的纹理细节信息丰富的浅层特征图与抽象的语义信息丰富的深层特征图进行多维融合。Prediction部分即特征检测层设置了3 个独立并行的检测器,对特征融合层输出的3 组分辨率不同的特征图进行卷积,得到对应的预测边界框及预测类别,实现对复杂道路场景中各类目标的检测。
2 YOLOv5s模型优化与改进
2.1 基于K-means+D的预设锚框优化
YOLOv5作为基于锚框的目标检测算法,与无锚框类算法相比,对于初始锚框的设置具有相对较高的依赖性。考虑到原算法给定的初始锚框为对大型通用数据集ImageNet[17]使用聚类算法生成,而ImageNet中目标与道路目标的尺寸相差较大,为了获得更适合检测道路目标的锚框,本文对道路目标数据集进行重新聚类。
K-means聚类算法[18]是一个经典的聚类算法,其主要做法为:(1)从数据集中随机选取K个样本作为初始聚类中心C={}c1,c2,…,ck;(2)针对数据集中每个样本点,使其加入距离最近的聚类中心所在的类中;(3)针对每个类别Ci,选择Ci中每个样本xj到Ci中Ni个样本的距离之和最小的样本作为新的聚类中心;(4)重复(2)、(3)直到聚类中心不再发生变化。
由于K-means 算法采用完全随机的方式选取初始聚类中心,因此稳定性较差,不同的随机结果会较大程度影响最终的聚类结果,容易导致其陷入局部最优情况。K-means++算法[19]对此进行改进的思想是约束算法选取初始聚类中心的随机性,对于不同的样本点被选取到的概率进行规定,使得与当前已有聚类中心的距离之和越远的样本越容易被选择,从而使得选取的K个初始聚类中心尽可能分散。
尽管K-means++在常规情况下比K-means做得更好,但对于分布不均的数据样本,简单地使初始聚类中心设置得足够远可能效果并不好。而道路目标检测的数据集就属于这种分布极度不均的情况,尺寸较小的行人目标分布密集且与其他各种尺寸目标并存,图2展示了自动驾驶领域的KITTI[20]和Udacity[21]数据集的目标尺寸分布。
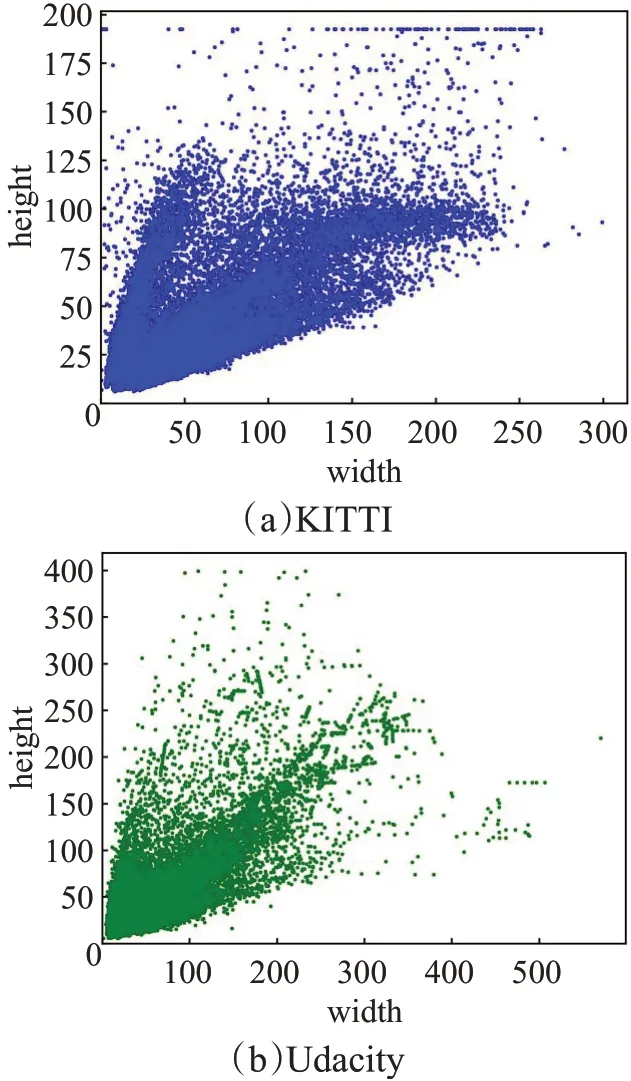
图2 KITTI和Udacity数据集目标尺寸分布Fig.2 Distribution of target size of KITTI and Udacity
由图2 可知,KITTI 数据集中尺寸在50×50 以下的目标极为密集,而在宽度230以上、高度125以上的目标又过于稀疏,Udacity数据集存在类似的现象,即目标尺寸分布极度不均。在此情况下,K-means++选出的初始聚类中心会趋向于较为分散的边缘区域样本点,但这些样本点大部分属于特例样本点,难以很好地代表全局分布。
因此,本文基于K-means++算法并对其进行改进,使得初始聚类中心的确定额外基于样本点的密度,其他步骤不变,名为K-means+D,其选择初始聚类中心的四个步骤详述如下:
(1)从数据集中随机选择1个样本作为初始聚类中心之一c1。
(2)计算出每个样本与最近一个已有聚类中心的距离D(x)以及每个样本的密度因子dx,这里距离D(x)通过交并比(intersection over union,IoU)来表示,密度因子dx用于衡量当前样本点x周围一定范围区域样本点的稠密程度,计算方式如式(1)所示:
式(1)中,Rx表示当前样本点x周围一定区域样本点的集合,Ω表示全体样本点的集合。
(3)设定每个样本x被选的概率px,并按照轮盘法选出下一聚类中心,px的计算方式如式(2)所示:
(4)重复步骤(2)、步骤(3)K-1 次即可确定出全部的K个初始聚类中心。
K-means+D 算法在确定初始聚类中心时,同时考虑聚类中心之间的距离和每个聚类中心周围区域样本点的密度,使得确定的初始聚类中心可以更好地接近数据的全局分布情况以提升后续聚类效果。
总体来说,K-means、K-means++及本文提出的Kmeans+D 三种聚类算法的不同实现方法决定了它们具有不同的适用场景。K-means采用完全随机的方式来确定其K个初始聚类中心,容易在不同的选择下陷入不同的局部最优,具有不稳定的缺点;K-means++针对K-means算法的不稳定性进行改进,采用距离决定被选概率的机制来确定初始聚类中心,使得初始聚类中心尽可能分散,考虑了样本集合的全局特征,但对于分布不均的样本,所选的聚类中心只具有距离上的全局性而缺乏密度上的全局性,因此其只适用于分布较为均匀的样本集合;K-means+D 算法在K-means++算法的基础上进行改进,在选择初始聚类中心时加入样本密度因子,考虑了样本分布密集程度,因此其更加适用于尺寸分布不均的道路目标样本集。
2.2 基于多梯度流结构的特征提取网络改进
YOLOv5s 的backbone 主要由Conv 模块和C3 模块组成。Conv 模块实现对特征图的下采样及非线性变换,而C3 模块则穿插布局于Conv 模块之间,实现对特征信息的增强处理,并采用残差结构缓解深层神经网络的退化问题。在复杂道路场景下,除常规大中目标外还存在一些不易检测的小目标,小目标的难检测问题是无人驾驶安全性的巨大隐患之一。考虑到当前算法对于小目标的检测效果一般,本文对特征提取网络中的C3模块进行改进,使用多梯度流残差结构进行特征增强实现对语义特征和定位特征的和谐处理,同时融入注意力机制实现高效的特征选择,将改进后的模块命名为PAA模块,其体系结构如图3所示。

图3 PAA模块结构Fig.3 PAA module structure
PAA模块结构的设计灵感主要来源于Vovnet[22],其使用多个卷积块的堆叠作为特征提取网络的统一结构,来提升网络捕捉细节的能力。PAA 模块首先对输入特征图做恒等卷积,实现特征图的通道压缩以提升待聚合特征图的信息密度。接着对待聚合特征图使用两次卷积层加工,生成具有不同感受野和不同层次语义信息的特征图,再对前几部分深浅度各异的特征图进行拼接融合以得到含复杂梯度流特征的特征图。最后通过ECA[23](effective coordinate attention)模块提取注意力信息筛选重要特征,并将得到的筛后特征图与输入特征图相加形成残差结构,以防止网络退化,ECA 模块结构如图4所示。
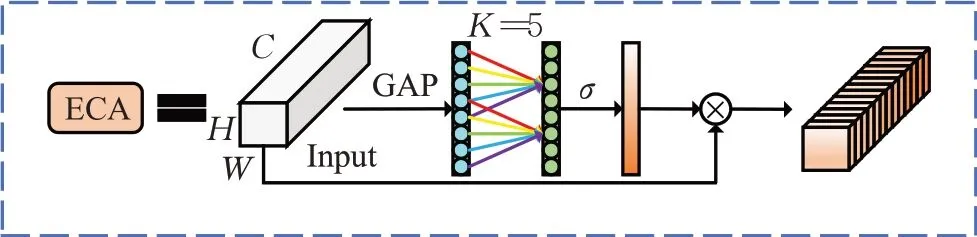
图4 ECA模块结构Fig.4 ECA module structure
ECA模块是一种高效的通道注意力模块,其采用非全连接不降维的注意力权值生成方式,既能防止降维造成的信息损失又降低了通道连接的冗余度。
PAA 模块与ECA 注意力模块相结合,重要细节信息可以选择性通过多梯度流结构和残差连接向深层传递,丰富的语义信息也在其中得到强化,因此既能提升模型对道路小目标的检测性能,又可保持对于道路常规目标的检测能力。同时与原C3 模块相比,PAA 中包含了2个3×3卷积,因此参数量会有少量的提升,但减少了2 个恒等卷积,GPU 的并行运算能力可以得到充分发挥,这可以加速模型的推理。
2.3 针对遮挡目标检测的损失函数改进
在YOLOv5s的6.0版本中,算法采用CIoU(complete IoU)函数[24]作为边界框的损失函数。与之前版本采用的GIoU(General IoU)函数不同,CIoU 的计算如式(3)所示,其中的υ和α分别如式(4)和式(5)所示,而GIoU的计算公式如式(6)所示:
式(3)中,IoU表示预测框和真实框的交并比,ρ表示两框中心点的欧氏距离,c表示两框最小外接矩形的对角线距离。式(4)中,wgt、hgt分别表示真实框宽、高,w、h分别表示预测框宽、高。式(6)中,Ac表示预测框和真实框最小外接矩形的面积,u表示两框的并集面积。GIoU虽然解决了预测框和真实框无交集时无法收敛的问题,但其收敛速度较慢,GIoU 公式中的项与CIoU公式中的项变化趋势相似,都随两框中心点距离减小而减小,但后者在两框出现交集后变化更迅速的特点有利于加快收敛,此外CIoU 函数计算时涉及的因素更多,包括交并比、中心点距离及宽高比,这样做的好处是使预测框的收敛方向更准确,从而进一步加快收敛。然而,CIoU 计算式中的宽高比因子υ对w和h求梯度时,会发现二者梯度方向相反,如式(7)和式(8)所示:
这会使得神经网络在通过随机梯度下降算法更新参数时令w和h每次都向相反的方向变化,而这并不合理。图5展示了CIoU loss作为损失函数的边界框收敛过程和理想收敛过程的对比。

图5 收敛过程对比Fig.5 Comparison of convergence process
图5(a)、(b)中左下角的蓝色矩形为真实边界框,右上角黑色矩形为初始预测边界框,从左到右每幅图中间的红色或绿色矩形展示了动态收敛过程。可以看到,初始预测框与真实框宽度接近而高度相差较多时,若如图5(b)理想收敛过程所示,使高度不断朝着接近真实框高度的方向更新,两框可以很快重合,而图5(a)展示的使用CIoU的收敛过程由于预测框宽高在更新时相互制约,导致收敛过程变得缓慢。因此引入EIoU[25]函数作为损失函数,其计算如式(9)所示:
式(9)中,wc、hc分别表示预测框和真实框的最小外接矩形的宽、高,ρw、ρh分别表示两框宽差值、高差值。EIoU对宽、高独立计算损失,因此可以实现如图5(b)所示理想收敛情况以提高定位精度。
定位精度的提高可以有效提升算法对遮挡目标的检测能力。在YOLOv5中,为提高检测精度对于同一个目标以多个网格为中心来生成更多预测框,最终对初步预测结果采用非极大值抑制(non-maximal suppression,NMS)方法去除相同目标的重复预测框。NMS 通过计算不同框之间的交集判断是否来自同一目标,而相互遮挡的目标由于同样存在交集,若预测框定位不准,则可能被NMS当作相同目标的重复预测框滤除。因此对于遮挡目标的检测而言,边界框定位精度极大程度影响了其被漏检的可能性。
对比几种损失函数对定位精度的影响,CIoU 对边界框与预测框的宽高比进行计算,可以使得预测框在保持形状与真实框相似的条件下进行收敛,防止在收敛过程中因为形状变化不定而难以实现与真实框重合,这使得采用CIoU的模型边界框定位精度比GIoU高,因而对遮挡目标具有更强的检测能力;EIoU解决了CIoU在形状收敛任务中存在的宽高制约问题,优化了形状收敛效果,这进一步提升了边界框的定位精度,可以更加有效地防止遮挡目标被NMS误滤除。
在复杂道路场景中,自动驾驶汽车视角下的遮挡目标众多,引入EIOU loss 作为算法的边界框损失函数,可以有效降低道路遮挡目标的漏检率。
2.4 改进后的模型
为提升对复杂道路目标的检测性能,结合上述章节改进内容,得到改进后的模型DPE-YOLO(YOLO withK-means+D,PAA and EIoU),模型结构如图6所示。
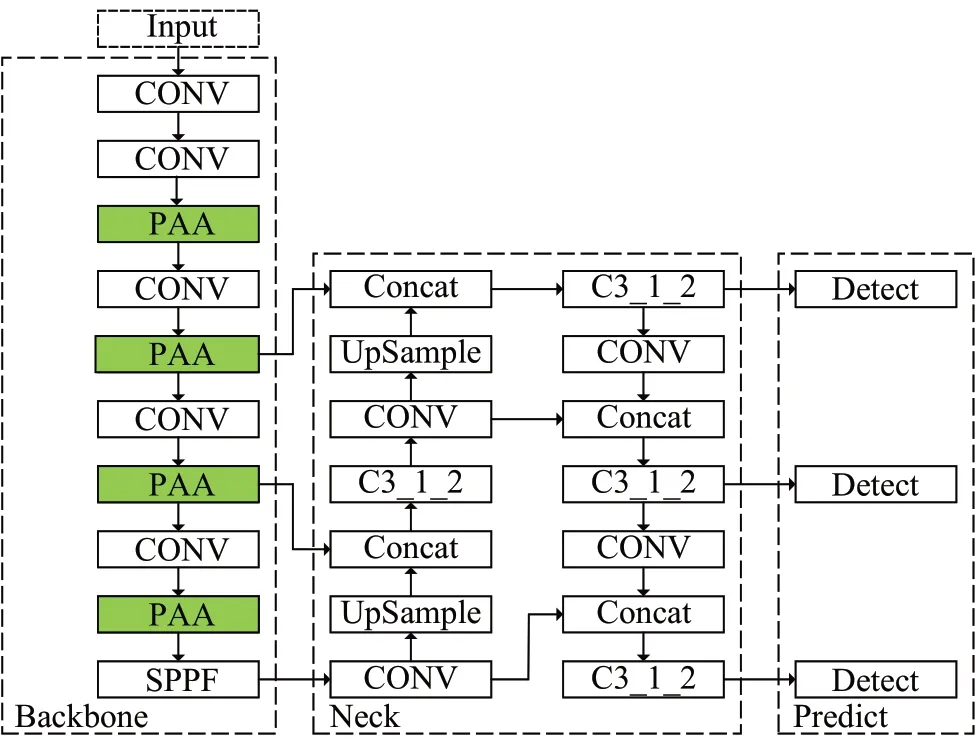
图6 DPE-YOLO网络结构Fig.6 DPE-YOLO network structure
由图6可知,DPE-YOLO中骨干网络采用PAA模块代替原C3模块,其余网络结构与YOLOv5s相同。与此同时,模型训练的预设锚框由K-means+D 聚类算法对道路目标数据集进行重新聚类生成,使用的定位损失函数由CIoU loss改进为EIoU loss。
3 实验及结果分析
3.1 数据集
为验证本文提出的DPE-YOLO 道路目标检测模型的性能,使用自动驾驶领域的经典数据集KITTI 和Udacity 来进行测试。其中,KITTI 数据集包含市区、乡村和高速公路等场景下采集的真实图像数据共7 481张,每张图像中最多达15 辆车和30 个行人,小目标较多,且存在各种程度的遮挡。Udacity 数据集是一个用于自动驾驶汽车算法比赛的数据集,共15 000张城市道路采集图像,这些图像在具有较多汽车和行人目标的同时,光照条件变化更加剧烈,进一步增加了检测难度。使用KITTI和Udacity数据集可较为全面地检验改进算法对于小目标和遮挡目标的检测效果。
对于KITTI 数据集,将其随机划分出6 732 张作为训练集,749张作为验证集。同时,对所有标签数据做如下处理:合并Truck、Van、Tram到Car类,合并Person_sitting到Pedestrian 类,并忽略非常规目标的DontCare 和Misc类,最终剩下Car、Pedestrian和Cyclist三个类别的标签。对Udacity 数据集对其进行以下处理:去除Trafficlight类标签,合并Truck 到Car 类,剩下有标签图像12 996张,其中9 098 张作为训练集,3 898 张作为验证集。由于数据集的规模差异,根据模型精度收敛曲线,对采用KITTI 和Udacity 的实验,其训练轮次(epoch)分别设置为200和120。
3.2 实验环境
本文所有实验的环境配置如表1所示,超参数的设置除epoch外均为YOLOv5s的6.0版本默认。

表1 实验环境配置Table 1 Experimental environment configuration
3.3 评价指标
为定量评估目标检测器性能,采用模型尺寸指标、精度性能指标和速度性能指标。模型尺寸指标为模型参数量(parameters),精度性能评价指标为mAP,具体包含:mAP@0.5、mAP@0.5:0.95,二者区别在于IoU 阈值不同,mAP@0.5:0.95表示IoU阈值为0.5到0.95的mAP均值;速度性能评价指标FPS表示每秒可检测的图像数量。其中,mAP计算如式(10)所示:式
(10)中,N为检测目标的类别数,APi为类别i的平均准确度,其计算公式如式(11)所示:
式(11)中,n表示召回率区间的数量,Pi(Rj)表示对i类目标检测的结果中,第j个召回率(Recall)区间下准确率(Precision)的最大值,P和R的计算方式分别如式(12)和式(13)所示:式(12)和式(13)中,TP表示被正确识别的正样本数量,FP表示被错误识别成正样本数量的负样本数量,FN表示被错误识别成负样本的正样本数量。
此外,为定量评估聚类算法的全局表达能力,针对矩形框,采用平均交并比(mean intersection over union,MIoU)为评价指标,其计算如式(14)所示:
式(14)中,N表示数据集所包含目标框的数量,Bi、分别表示第i个样本目标框和其所属聚类的聚类中心样本框。
3.4 聚类算法改进实验
为了验证提出的K-means+D 聚类算法的实际效果,本实验对K-means、K-means++及K-means+D的聚类效果进行比较。为说明K-means+D聚类算法在自动驾驶数据集中的普适性,本实验在KITTI 和Udacity 两个数据集上进行,对三种聚类算法的直接聚类效果及对检测性能的影响进行实验对比,结果如表2所示。

表2 几种聚类算法的MIoU及对模型检测效果影响的比较Table 2 Comparison of MIoU and influence on model detection effect of several cluster algorithms单位:%
由表2可知,由于道路目标尺寸分布的不均衡,Kmeans++算法在这种情况下的聚类效果甚至不如Kmeans 算法。在KITTI 数据集上,在MIoU 指标上Kmeans+D相比K-means++提升了3.5个百分点,相比Kmeans 提升了2.1 个百分点,相比原算法提升了9.1 个百分点,同时K-means+D 所生成锚框使得检测指标mAP@0.5提升了1.1个百分点,在Udacity数据集上,以上几种指标也均有一定的提升。实验结果说明,相比另外两种聚类算法,K-means+D 对模型检测性能的提升更加明显。
为进一步探究K-means、K-means++与K-means+D三种算法的聚类差异,以KITTI数据集为例,图7进一步展示了几种聚类算法的可视化结果。
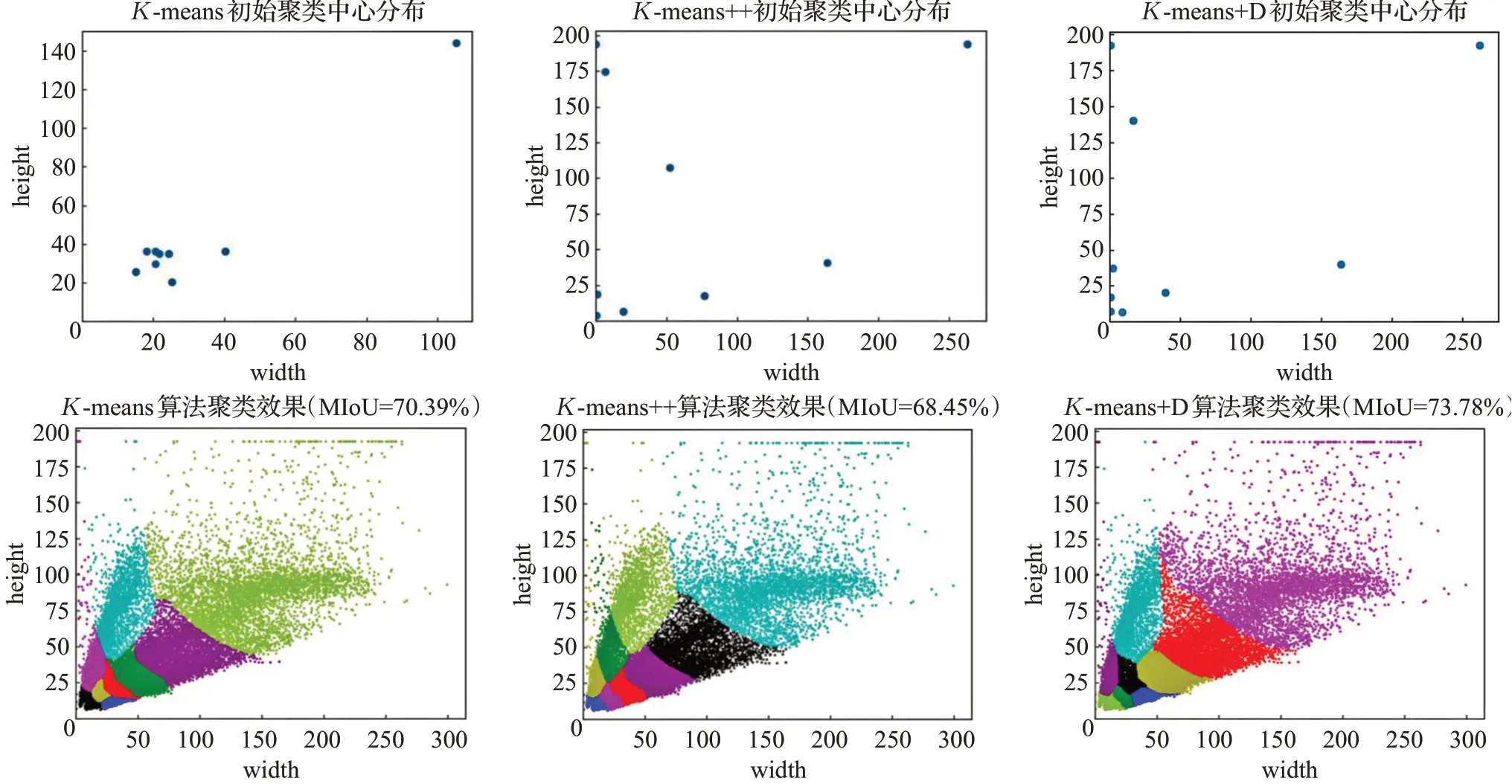
图7 几种聚类算法的可视化展示Fig.7 Visualization of several algorithms
由图7可知,K-means的初始聚类中心主要分布在样本点较多的小目标区域,约有5/6 区域的样本点都未被选择,这是因为此区域的样本较多因此在随机选择中更容易被选到。尽管如此,其初始聚类中心相比Kmeans++更具有密度上的全局性,因此聚类的MIoU 比K-means++更高。K-means++与K-means+D的初始聚类中心分布都较为分散,但后者在样本密集区域的样本点更多,选出的初始聚类中心更好地代表了样本的分布情况,因此K-means+D 的聚类效果更好。且由于Kmeans+D 同时考虑了样本距离和区域样本密度上的全局性,因此聚类的MIoU最高。
以上实验结果一致说明了K-means+D聚类算法的有效性,其对于分布不均的样本可以生成更符合全局分布的聚类中心,从而聚类出更优的锚框以有效改善模型对各种尺寸的道路目标的检测性能,尽管其相比原算法在生成初始聚类中心时增加了一定计算量,但由于计算量的增加是在模型训练前,因此并不影响模型的检测速度。
3.5 PAA模块加入注意力机制实验
为了验证在PAA 模块中加入注意力机制对模型的影响,本实验以KITTI 数据集作为实验对象,将PAA 模块结合不同注意力机制后得到的几种模型的检测效果进行了对比,实验结果如表3所示。

表3 融合不同注意力机制的PAA模块的对比Table 3 Comparison between several PAA modules fused with different attention mechanism
表3中,PAA_noAtt 表示包含无注意力机制的PAA模块的模型,表3 中PAA_SE、PAA_CA、PAA_CBAM 和PAA_ECA分别表示包含加入SE、CA、CBAM和ECA的PAA模块的模型。由表3可知,相比其他几种注意力模块,结合了ECA 模块的PAA 模块使得模型对于道路目标的识别效果最优,同时几乎不增加参数量,且对于检测速度的影响最小。这说明了ECA注意力机制可以在包含复杂梯度流的特征图中更好地挖掘出重要特征信息以提升检测效果。
3.6 损失函数改进实验
为了说明不同损失函数对于模型检测性能的影响,本实验以KITTI数据集为实验对象,将分别使用GIoU、CIoU(原算法)和EIoU几种边界框损失函数模型的检测性能进行对比,实验结果如图8所示。

图8 不同边界框损失函数对检测结果的影响Fig.8 Influence of different bounding box loss functions on detection results
由图8 可知,相比使用GIoU 和CIoU,使用EIoU 作为边界框损失函数后mAP@0.5分别提升1.5个百分点、1.3 个百分点,同时mAP@0.5:0.95 分别提升了1.4 个百分点、1.1 个百分点,实验结果验证了EIoU 损失函数对模型整体检测效果的提升。
为说明不同损失函数对遮挡目标检测的影响,图9进一步展示了不同损失函数对应模型对于遮挡目标实例检测效果的可视化对比。由图9 的局部放大部分对比可知,由于两辆车的高度重叠后面的车被严重遮挡,使用GIoU 和CIoU 损失函数的模型边界框定位误差较大,导致被NMS 滤除了一个预测框,均只检测到一辆车,而使用EIoU的模型以其更优的边界框定位能力,避免了漏检。实验结果验证了使用EIoU损失函数训练模型的更高边界框回归准确度,使其可以更好地处理遮挡目标的检测,以提高检测精度。

图9 不同边界框损失函数对遮挡目标实例检测效果对比Fig.9 Comparison of different bounding box loss functions on occlusion target instances
3.7 消融实验
为了验证K-means+D、PAA模块和EIOU loss对模型性能的提升效果,本实验对DPE-YOLO 进行消融研究。实验在KITTI数据集上进行,实验结果如表4所示,由其中信息可得如下结论:

表4 不同优化方式对模型性能的影响Table 4 Impact of different optimization methods on model performance
(1)K-means+D 的有效性。由表4 可知,在原算法基础上使用了K-means+D 后mAP@0.5、mAP@0.5:0.9分别提升了1.1 个百分点、0.8 个百分点,且FPS 相同。说明使用K-means+D聚类算法生成的锚框可有效提升模型检测性能,且不影响检测速度。
(2)PAA 模块的有效性。由表4 可知,在原算法基础上加入PAA 模块后模型在增加了少量参数量的情况下,mAP@0.5、mAP@0.5:0.9分别提升了1.4个百分点、2.2 个百分点,且从FPS 指标可知使用基于PAA 的模型检测速度更快。
(3)EIoU loss 的有效性。由表4 可知,在原算法基础上使用EIoU loss 使mAP@0.5、mAP@0.5:0.95 分别提升了1.3 个百分点、1.1 个百分点,FPS 指标也说明由于其不增加额外计算量而不影响检测速度。
(4)以上优化方式的耦合性较好。从表4 可以看出,在任何一个已优化过的模型上加入新的优化方法后,检测精度均可得到提高,且不会降低检测速度,说明采用的几种优化方式的耦合性良好。
3.8 对比实验
为了验证本文所提出的模型的有效性,本实验将在KITTI和Udacity两个数据集上进行,将其与当前主流的算法模型的检测结果进行对比分析。
表5展示了不同模型在KITTI 数据集上的实验结果,主要对Faster-RCNN、SSD、YOLOv3、YOLOv4、YOLOv5s、YOLOv5m及DPE-YOLO模型进行了检测精度和检测速度两方面的比较。实验表明,所提出的DPE-YOLO 相较于基线模型YOLOv5s,检测精度得到了较大提升,mAP@0.5、mAP@0.5:0.9 分别提升了2.8个百分点、2.7个百分点,mAP@0.5与FPS均超越其他主流模型,相比原算法每秒可多检测5张图像。
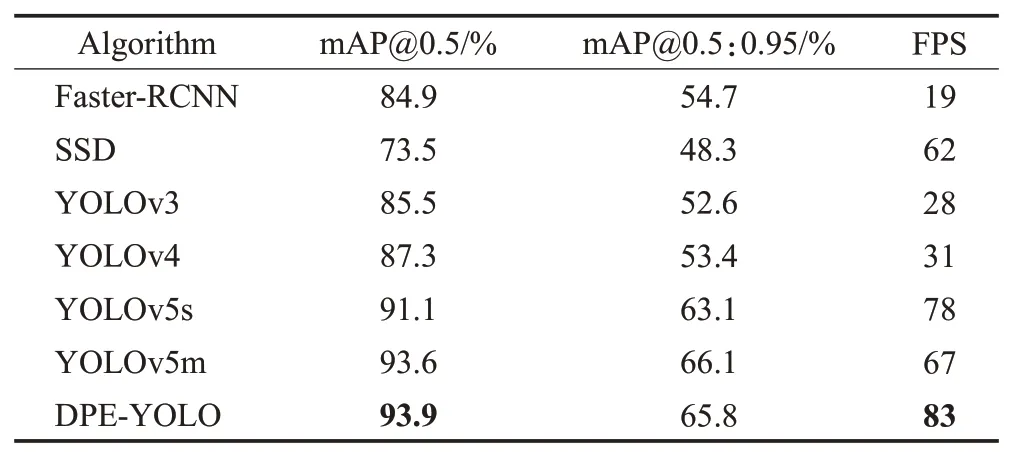
表5 KITTI数据集对比实验Table 5 KITTI dataset comparison experiment
为进一步检验模型对不同目标的检测效果,图10对YOLOv5s和改进模型DPE-YOLO对各类目标的检测精度进行了可视化对比展示。数据显示,改进模型在3个类别上检测精度都高于YOLOv5s,其中类别Pedestrian的检测效果提升最明显,与YOLOv5s 相比,mAP@0.5、mAP@0.5:0.95分别提升了5.3个百分点、3.2个百分点,且在所有道路目标中,Pedestrian类别的目标通常较小,实验结果验证了DPE-YOLO模型对于常规道路目标检测能力的提升及对道路小目标检测能力的显著提升。
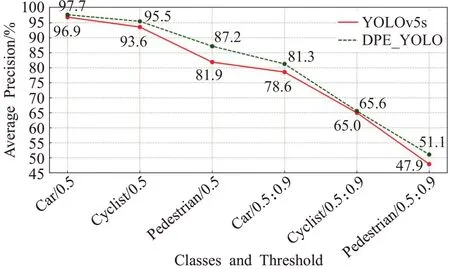
图10 两种模型对各类别检测精度的对比Fig.10 Comparison of detection precision of each classes between two models
最后,为验证模型的泛化性能,继续在Udacity数据集上进行对比实验。结果见表6,与其他主流模型相比,改进算法在mAP@0.5 与FPS 指标上同样处于优势,且相比原算法mAP@0.5、mAP@0.5:0.9分别提高了1.6个百分点、2.9个百分点。

表6 Udacity数据集对比实验Table 6 Udacity dataset comparison experiment
在KITTI 和Udacity 数据集上,改进算法有不同的效果提升,并且其在KITTI数据集的提升更明显。这是因为Udacity 数据集的图像光线变化更剧烈,其一定程度上限制了模型处理细节信息地能力的发挥,但效果提升仍然是可观的,这也说明DPE-YOLO 在复杂光线条件中相比原算法仍然具有更强的检测能力。
图11、图12 分别展示了算法改进前后对KITTI 数据集、Udacity数据集部分图像的检测效果的对比,两图左、右均对应YOLOv5s 和改进后的DPE-YOLO 模型效果。在图11的放大图b和图12的放大图a中,改进算法成功检测到原算法未检测出的行人小目标,这体现了改进后的算法对小目标检测能力更强的优势;在图11 的放大图a 中,行驶的车辆由于互相遮挡,而被YOLOv5s漏检,DPE-YOLO以其更优越的边界框回归能力避免了遮挡目标的漏检,体现出其对遮挡目标检测能力的提升;此外,从图12 的放大图b 中可以看到改进算法正常检测到原算法未识别出的被草丛遮挡的汽车,说明其聚焦关键信息的能力更强。

图11 KITTI数据集检测效果对比Fig.11 Comparison of detection effect on KITTI dataset

图12 Udacity数据集的检测效果对比Fig.12 Comparison of detection effect on Udacity dataset
4 结语
针对目前的目标检测算法对复杂道路场景中的小目标、遮挡目标存在严重的漏检误检问题,造成整体检测率不高的情况,本文提出了基于YOLOv5s 的改进算法DPE-YOLO。针对原算法的预设锚框不符合道路目标尺寸特点,且道路目标尺寸分布不平衡问题导致现有聚类算法效果不佳,提出了K-means+D 聚类算法生成更适合道路目标检测的预设锚框,缩短目标边界框回归路径,使得不同尺度的目标都更容易找到正确的收敛方向以提升各类目标的检测精度;针对道路中小目标容易漏检误检的问题,提出了PAA模块,其多梯度流与注意力机制的融合结构使得模型可以更高效、灵活地提取小目标的重要细节特征,提升小目标的检测精度;针对道路中遮挡目标容易漏检误检的问题,引入了EIoU loss作为算法的边界框损失函数,提高边界框定位精度,降低遮挡目标被NMS 误滤除的概率,使遮挡目标的检测精度得到提升。
实验结果表明,改进算法在自动驾驶数据集KITTI和Udacity 上表现良好,在付出少量参数量成本的情况下,不仅降低了小目标和遮挡目标的漏检误检率,实现了更高的检测精度,还提升了检测速度。后续的工作中,将继续从以下两个方面优化算法:一方面在提升模型鲁棒性的方向上进行研究,实现更强的抗干扰性能以继续提升检测精度;另一方面,在保持精度的同时,对模型进行剪枝,降低模型的参数量以减轻自动驾驶的硬件系统负担。
猜你喜欢
当代陕西(2022年4期)2022-04-19
小猕猴学习画刊(2022年3期)2022-03-28
中学生数理化·高一版(2021年2期)2021-03-19
青年歌声(2020年12期)2020-12-23
知识经济·中国直销(2018年8期)2018-08-23
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
读写算·高年级(2015年1期)2015-07-25
