
驾驶员手机使用检测模型:优化Yolov5n算法
2023-09-25 08:56王鑫鹏王晓强李雷孝李科岑陶乙豪
计算机工程与应用 2023年18期
王鑫鹏,王晓强,林 浩,李雷孝,李科岑,陶乙豪
1.内蒙古工业大学信息工程学院,呼和浩特010080
2.天津理工大学计算机科学与工程学院,天津300384
3.内蒙古工业大学数据科学与应用学院,呼和浩特010080
近年来,智能手机给人们生活带来了极大的便利,若驾驶员在驾驶过程中使用手机,将会危及自己乃至他人的生命,给交通安全带来隐患。然而,目前针对该行为的监督依旧存在不足:特定路段中的抓拍系统只能对固定范围内的违章行为进行监控,仅能在一定程度上约束驾驶员的手机使用行为,而驾驶过程中使用手机的行为是不确定且频繁的,在未被监控的路段仅靠驾驶员的自觉性很难保证行车的安全性。因此,为避免驾驶员在驾驶途中使用手机,减少因注意力分散而导致的交通事故,提出一种实时性、轻量化、适用于车辆内部的目标检测模型,这将规范驾驶员的行车行为。
对驾驶员手机使用检测算法的发展进程进行分析,得知现有的检测方法主要存在如下缺点与不足:(1)图像处理技术易受背景、光照以及驾驶员特征多样性与不确定性的影响,不能在不同场景下达到良好的识别效果[1-2];(2)传统机器学习方式由于复杂的检测、处理流程以及在处理大数据样本时大量的迭代计算而导致检测速度过慢,使得算法很难达到实时性[3-5];(3)一些自建卷积神经网络因网络结构设计简单、所提取到的目标特征信息不足而影响检测精度[6-8];(4)深度学习的典型目标检测算法虽然不需要人为划分处理过程,端到端的算法设计简化了检测操作以及得到了硬件加速的计算支持,但由于深层次的数据操作导致算法模型的计算量仍然较大,不能很好地进行车内的实时性检测[9-11];(5)基于深度学习的检测模型在优化后实时性有所提升,但优化程度往往取决于在何种算法上(优化的基础)进行何种优化(优化的程度),当前所优化后的目标检测算法仍然不够理想,在一些计算效率较低的嵌入式设备或者移动设备上运行仍然略显不足[12]。
针对上述缺点,本文提出了一种兼具准确性、实时性及轻量化的驾驶员手机使用检测模型。该模型将Focal-EIoU Loss 与FocalL1 Loss 相结合,加快框回归损失收敛的同时也提高了框回归的准确性;其次,在优化过程中会对轻量化检测算法Yolov5n 进行Slimming剪枝,进一步减少该算法的参数量、计算量及不必要的通道数,确定Slimming 剪枝在轻量化设计中的优越性。本文具体工作如下:(1)通过将Focal-EIoU Loss与FocalL1 Loss相结合,验证了结合后的损失函数能够在高质量样本较多的数据集中发挥重要作用;(2)实验对比了多种轻量化改进方法,进而说明Slimming 剪枝的有效性;(3)提出一种更加适用于嵌入式设备或移动设备的实时检测模型,并通过消融实验来说明每个优化步骤所发挥的作用;(4)利用本文提出的优化方案在公共数据集Pascal VOC 2012上进行实验,验证该优化方案的通用性。
1 优化Yolov5n算法
由于Yolov5 算法能够有效地对目标进行检测与识别,因此该系列算法受到众多研究学者的热爱。Yolov5n算法属于Yolov5 系列算法中最为轻量化的目标检测模型,相比Yolov5系列的其他算法,其在保持一定检测精度的前提下极大地减少了模型参数量与计算量。因此在Yolov5n 算法上进行改进将会更有利于实现驾驶员手机使用行为的高实时性、高准确性检测。本文对于Yolov5n算法的优化主要包括三方面:数据增强、框回归损失函数、Slimming 剪枝算法。优化后的算法流程如图1 所示,虚线部分表示优化后的操作。其中,由于剪枝算法会破坏模型原有的权重信息,同时为了提高模型的训练及剪枝效率,本文在进行稀疏训练时将利用原始训练集对剪枝操作进行指导,而在之后的模型微调中则会通过数据增强后的训练集来让模型学习到更加丰富的图像特征。
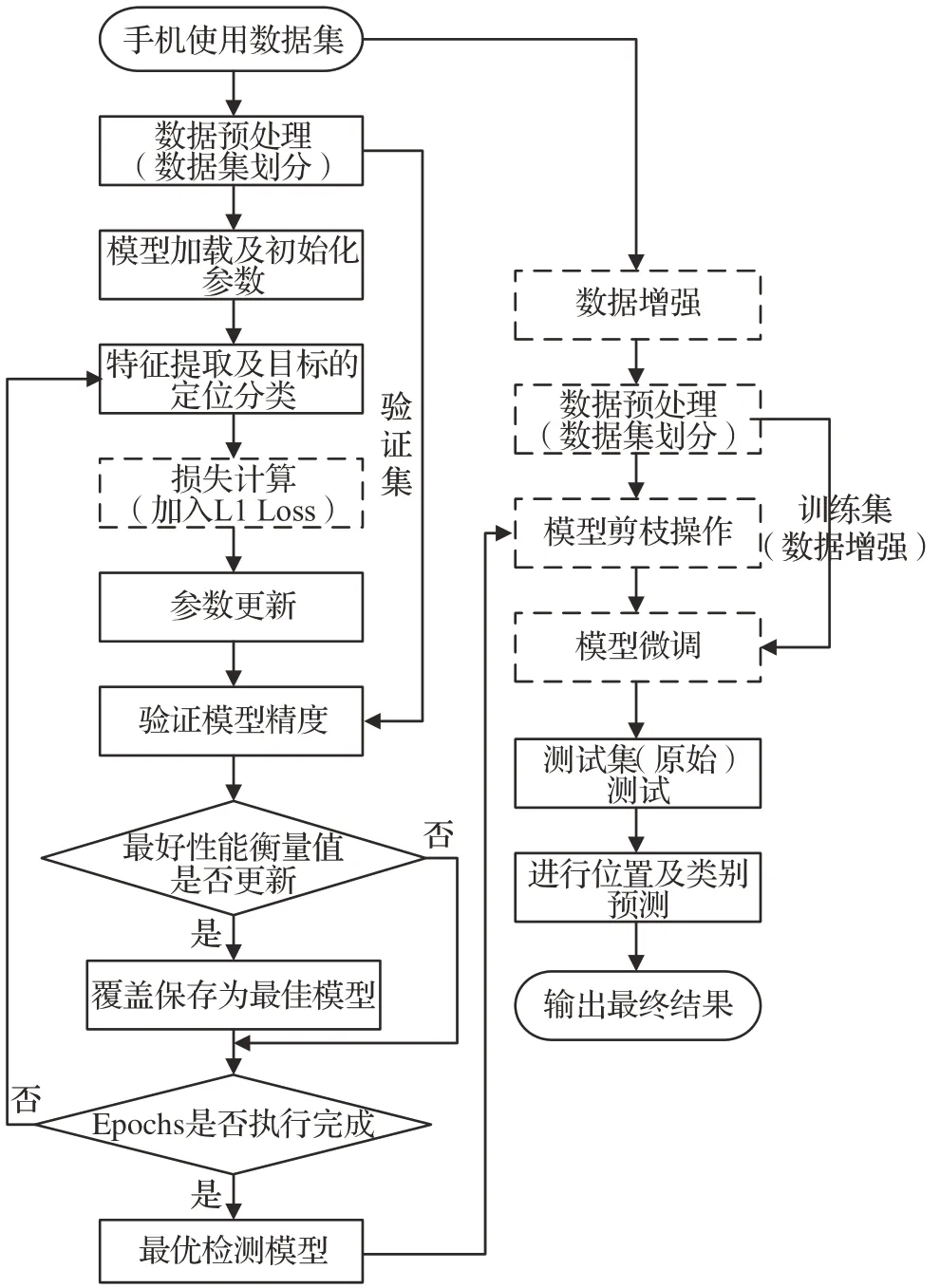
图1 算法流程图Fig.1 Algorithm flowchart
1.1 数据增强
数据对于模型的表现有很大的影响,利用数据增强方法对数据集进行扩充,减少模型过拟合的同时增加了原有数据图像的丰富性,使经过训练后的模型能更好地适应复杂的检测环境。
Yolov5n 算法本身内置了一些数据增强方法,如模糊处理、灰度化等,但这些方法是对每张图像同时进行增强处理,虽然这种操作增加了图片的丰富性,但却不能显著增加图片数据量。由于驾驶员使用手机的行为图像较为缺少,因此,本文将会单独采用一些增强方法分别对每张图像进行处理,图像每经过一次处理原数据量则增加一倍,同时该操作也解决了数据集图像较为单一的问题。
本文采用的手机使用数据集为Driver Behavior Dataset[13]中的部分类别,即:打电话行为和编辑信息行为。该数据集结合了State Farm 数据集与其他相关数据集,两种不同拍摄角度的数据采集可使训练后的模型泛化性更强。本文利用数据增强库Albumentations中的8 种数据增强方法分别对数据进行扩充,扩充方法如图2 所示。其中,本文通过Hue SaturationValue 方法来人为改变原图片Hue(色调)、Saturation(饱和度)、Value(明度)的范围,相应增加或减少原图片的明亮,进而有效地模拟光照环境,使模型在光照环境下能有更好的检测精度。

图2 数据增强方法Fig.2 Data augmentation methods
1.2 框回归损失函数
本文所使用的框回归损失Focal-EIoU Loss(s)结合了Focal-EIoU Loss与FocalL1 Loss[14],使得结合后的损失函数能够提供更加快速的损失收敛与预测框的定位。
1.2.1 CIoU Loss
有效的损失函数可以提高模型的收敛速度与检测精度。传统的Yolov5n 算法使用的CIoU 损失导致预测框的长宽不能同时进行同方向调整,从而使得损失收敛变慢、框定位不够精确。CIoU损失的计算公式如式(1)所示:
v关于边长w和h的梯度如式(2)所示:
式中,IoU为预测框与目标框的交并比,IoU范围在[0,1]之间;ρ()⋅代表预测框和目标框中心点距离,c代表预测框和目标框最小外接矩形的对角线距离;α代表平衡参数,不参与梯度计算;v用来衡量预测框和真实框的宽和高之间的比例一致性;gt代表目标框;由式(2)可知w和h的梯度值具有相反的符号,这在训练的过程中会出现如下问题:当w和h其中一个值增大时,另一个必然减小,不能保持同增同减,这会导致损失函数收敛过慢以及框定位的不精确。推导如下:
由上述梯度更新公式(其中αt为t轮迭代的学习率)可知,在进行梯度更新时,w、h参数的更新方式将如下所示:
将公式(2)代入上述更新方式,可得:t
由于w、h会相加或相减同一数值,故在进行参数更新时,w、h参数必有一个增大,一个减小。
1.2.2 Focal-EIoU Loss(s)
对于CIoULoss 存在的问题,EIoU 损失直接舍弃了长宽比的惩罚项,而是利用w和h的预测结果对损失的收敛进行指导,计算公式如式(3)所示:
其中,Cw和Ch分别是预测框和目标框最小外接矩形的宽和高。从中可以看出,EIoU 将损失函数分成了三个部分:IoU损失LIoU、距离损失Ldis、边长损失Lasp,而基于边长的惩罚将有利于模型中损失函数的快速收敛及精度的提升。
另一方面,为进一步增加高质量样本在训练时的重要程度,在借鉴了解决类别不平衡问题的Focal Loss之后,文献[14]相继提出了用于解决回归不平衡问题的FocalL1 Loss 与Focal-EIoU Loss。FocalL1 Loss 函数图像及梯度曲线如图3 所示,公式如式(4)所示,Focal-EIoU Loss的定义公式如式(5)所示。

图3 FocalL1 Loss函数图像及梯度曲线Fig.3 FocalL1 Loss function image and gradient curve
式(4)中,β可控制曲线的弧度,不论β为何值时α都可控制函数的梯度在[0,1]之间,α=eβ,C=(2αlnβ+α)/4;式(5)中γ为可控制抑制程度的参数。
FocalL1 Loss函数的主要设计理念如下:当框回归误差较小(高质量样本)时,梯度更新的幅度应该迅速增加,而在框回归误差较大时(低质量样本),梯度更新的幅度应该逐渐减小。这种理念增加了高质量样本在模型训练时的作用,提高损失函数收敛速度的同时也增加了定位精度。为了结合EIoU Loss 与Lf(x)的优点,使EIoU Loss关注于高质量样本,把EIoU Loss作为Lf(x)的x值代入公式(4)中显得更为合适,即当EIoU Loss的损失值减小时,其将加快梯度的更新(关注于高质量样本)。但当EIoU Loss趋于0时,预测框的梯度更新将会逐渐减小,这反而抑制了高质量样本对模型训练的影响[14]。为解决该问题而提出了Focal-EIoU Loss 损失,该损失利用IoU 值对EIoU Loss 进行加权,使得高质量样本(框回归损失较小)得到的权重更大,在模型训练时将会更加关注高质量样本。
FocalL1 Loss 与Focal-EIoU Loss 在框回归的过程中都将关注于高质量样本,但Focal-EIoU Loss 基于加权的做法在高质量样本较多时就会显得不那么高效,而FocalL1 Loss 不会受到高质量样本较多而导致回归效率降低的影响,当高质量样本较多时,FocalL1 Loss 的梯度更新甚至会加快。因此本文将结合FocalL1 Loss与Focal-EIoU Loss来提高损失函数的收敛速度与框定位精度,结合后的回归损失函数称为:Focal-EIoU Loss(s),公式如式(6)所示。
虽然当EIoU Loss 趋于0 时,FocalL1 Loss 与EIoU Loss系列相结合会抑制高质量样本对模型训练的影响,但实验表明,这种抑制作用对本文所用数据集的影响是微弱的。
1.3 Slimming剪枝算法
减少Yolov5n模型的参数量和计算量可以通过多种方法实现,例如优化骨干网络、模型压缩等。考虑到模型实时性,仅仅关注参数量与计算量是不够的,还要关注模型在优化后的推理速度,有些优化方案虽然减少了参数量与计算量,但模型的推理速度也相应增长,这将导致模型的实时性变差。因此本文在对比了多种优化方案后选择使用Slimming剪枝算法[15]对模型进行压缩。
Slimming 剪枝算法利用BN(batch normalization)层的γ参数来衡量当前通道的重要程度,并使用L1 损失来稀疏化γ值。BN层作为一种能加速网络收敛及提高网络性能的标准方法,被广泛应用到现代神经网络中,其基本公式如式(7)所示:
其中,zin和zout分别是BN层的输入和输出,μB表示本批次该层输入的均值,σB表示本批次该层输入的方差。BN 层会对卷积后的输出特征乘上γ因子(缩放因子)来调整其分布,如果γ因子很小,那么这个通道的输出值也会很小,进而就代表着该通道对于后续网络的贡献就很小,在剪枝时就会删减这些不重要的通道,保留较为重要的通道,从而实现模型的压缩。
Slimming剪枝算法的定义公式如下:
其中,(x,y)是训练的输入和目标,W为网络中的可训练参数,前一项代表卷积神经网络中的训练损失函数,g(⋅)是缩放因子上的惩罚项,λ是两项的平衡因子。在现实研究中,L1 正则化(g(s)=| |s) 被广泛地用于稀疏化。该剪枝算法包含三个步骤:稀疏正则化、剪枝、微调,其中稀疏正则化就是在模型训练时利用L1 损失来标记通道的重要程度,剪枝则是根据通道的重要程度进行修剪,而修剪不重要的通道可能会造成模型短暂的性能降低,因此在剪枝后还需要进行模型的微调。
为了提高模型的训练效率,使模型在微调后能有更好的检测效果,本文在进行模型稀疏正则化时仅利用原始训练集对模型进行稀疏训练,而在微调阶段时才利用数据增强后的训练集对模型进行微调。如果使用数据增强后的训练集进行稀疏训练,虽然这种做法增加了模型最初的检测精度,但模型经过剪枝后又会使检测精度大幅度降低,影响了模型的训练效率,而使用原始训练集进行稀疏训练不仅能有效识别不重要的通道数,还降低了稀疏训练的时间。在微调时使用数据增强后的训练集可以使模型微调到更加优秀的检测精度,有利于模型整体性能的提升。
2 实验结果分析
为了满足实际检测需求,本文使用“手持通话”“编辑手机”两种类别数据对模型进行训练、验证及测试。去除掉图片间的重复信息后,数据集的具体信息如表1所示,其中手机使用数据集在进行数据增强后,训练集的整体数量由3 268 张扩展到29 582 张,验证集的整体数量由482 张扩展到4 056 张,测试集由411 张扩展到3811张。

表1 数据集信息Table 1 Dataset information
为保持数据的随机性,在进行数据集的划分时训练集、验证集、测试集的比例基本保持在8∶1∶1。此外,为了保持数据增强后的数据集也具有随机性,本文在对数据进行数据增强之后才进行训练集、验证集及测试集的划分,而不是在原始训练集、验证集及测试集的基础上进行数据的增强。在进行模型训练时超参数皆为默认,实验环境如表2所示。
表2 GPU服务器配置Table 2 GPU server configuration
2.1 框回归损失函数对比实验
本实验的目的是通过对比LEIoU、LFocal-EIoU、Lf(LEIoU)、Lf(LFocal-EIoU)这四种损失函数,进而验证Lf(LFocal-EIoU)在类别数量相对较少,识别目标相对较大,高质量样本相对较多的数据集中能表现出更高的有效性。本文在手机使用数据集(原始)及Pascal VOC 2012 数据集的基础上,通过更改Yolov5n 的框回归损失函数来进行上述四种损失函数的对比试验,结果如图4所示,其中Lf(x)中的β值与γ值取实验结果最优的值:β值为0.8,γ值为0.5[14]。

图4 框回归损失函数在数据集上的对比Fig.4 Comparison of box regression loss functions on datasets
由图4可知,Lf(LFocal-EIoU)相比LEIoU、LFocal-EIoU以及Lf(LEIoU)不论是在收敛速度还是回归精度上都能使模型达到更高的检测性能。其次,Lf(x)相比LFocal-EIoU会在高质量样本较多(与目标框重叠较多)的数据集中发挥更重要的作用,即在原数据集上(该数据集目标种类少、识别目标大),LEIoU到LFocal-EIoU所实现的精度提升并不大,但LEIoU到Lf(LEIoU)的提升却是巨大的。产生这种现象的原因可能在于:LFocal-EIoU是利用IoU 的权重来关注高质量样本,但当高质量样本在数据集中出现较多或者样本的整体质量得到提升时,这种加权的做法就会显得不那么高效,而Lf(x)不会受到高质量样本较多而导致回归效率降低的影响,当高质量样本较多时,Lf(x)的梯度更新甚至会加快。另一方面,当LEIoU趋于0时,虽然Lf(x)与LEIoU系列相结合的损失函数会抑制高质量样本对模型训练的指导,但这种影响还是要低于高质量样本对于LFocal-EIoU的影响。因此,Lf(LEIoU)及Lf(LFocal-EIoU)能够在本文甚至Pascal VOC 2012 这种类别数量较少,识别目标较大,高质量样本较多的数据集中表现出较高的回归精度与收敛速度,但随着类别数目逐渐增大,识别目标逐渐减小以及高质量样本的逐渐降低,例如在COCO 数据集中,LFocal-EIoU这种基于IoU权重的方式所发挥的作用随之增加,进而在性能上超过Lf(LEIoU)[14]。
2.2 轻量化对比实验
该实验验证了Slimming 算法能更加有效地增加Yolov5n模型的轻量化和实时性水平。本实验中利用常见的Ghost Conv[16]、MobileNet v3-small[17]、ShuffleNet v2[18]三种算法来优化Yolov5n 的骨干网络并与Slimming 算法进行对比实验。其中,利用算法对每张图片的推理时间Time 来衡量算法的实时性,Time 取10 次中的平均值;“Ghost Conv-C3”表示利用Ghost Conv来替代Yolov5n中的Conv 模块以及C3 模块中的Conv 模块,“Ghost C3”表示利用Ghost Conv 来替代C3 模块中的Conv 模块。利用验证集进行验证时,经过实验对比,选取conf-thres=0.01,iou-thres=0.37,同时batch-size=1。
由表3 可知,在保持模型轻量化的基础上,与其他轻量化算法相比Slimming能有效地降低模型的推理速度,进而提高模型原有的实时性。上述四种算法减少参数量与计算量的同时也降低了模型的检测精度,但检测精度可通过其他方式提高,例如本文的数据增强方法、框回归损失函数等。Ghost Conv、MobileNet v3-small、ShuffleNet v2都增加了模型的推理时间,这也说明这些方法不利于模型的实时性检测,原因在于:Ghost Conv、ShuffleNet v2都使用了分组卷积,虽然分组卷积能够降低计算的复杂度(FLOP),但这也带来了更多的内存访问消耗(memory access cost,MAC),从而降低了推理速度,相关实验表明分组数越大MAC也就越大;另一方面,MobileNet v3-small 中使用SE-Net 进一步增加了模型的复杂化,这种多路径的结构对具有强大并行计算能力的设备不够友好,推理速度也会有所降低。因此,为减少分组卷积的使用以及精简网络结构,利用Slimming对Yolov5n算法进行剪枝可有效提高模型的轻量化和实时性。
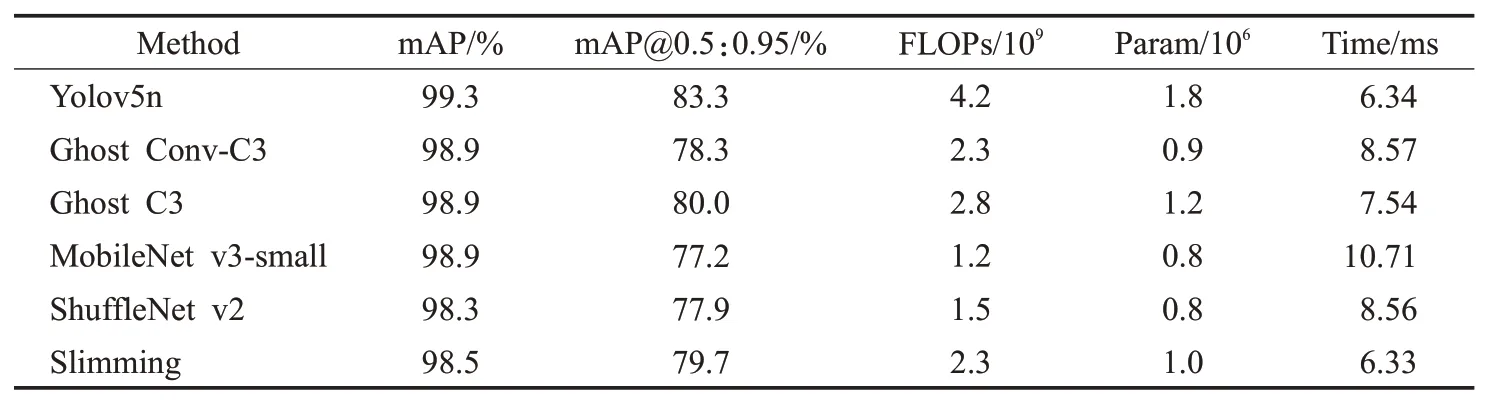
表3 骨干网络优化方法Table 3 Backbone network optimization methods
2.3 消融实验
本实验的目的是利用上述Focal-EIoULoss(s)、Slimming 剪枝以及数据增强方法对Yolov5n 算法进行消融实验,进而对比出各优化步骤对于模型性能的提升,实验结果如表4 所示。其中,所有模型中的剪枝操作仅使用一次,为了能使模型在微调时充分学习到增强数据的有效特征,微调操作均采用较大的epochs 值60;模型B、C均使用原始数据进行微调;为了突出微调操作的重要性,模型C、F 在进行微调时会使用Focal-EIoU Loss(s),而在之前的稀疏学习时使用原损失函数CIoU Loss,同时模型D、F的增强数据也只会在微调操作中使用。Times 表示模型处理每张图片所用的时间,即模型预处理时间、模型推理时间以及NMS(non maximum suppression)处理时间三者之和,Times 取10 次实验的平均值。在利用验证集进行以下模型的验证时,经过实验对比,选取conf-thres=0.01,iou-thres=0.37,同时batch-size=64。

表4 Yolov5n消融实验Table 4 Yolov5n ablation experiment
由表4 可知,对Yolov5n 模型进行剪枝可以使其减少44.4%的参数量以及45.2%的计算量,但这也使得模型精度有所降低;Focal-EIoU Loss(s)及数据增强都提高了模型的检测精度,进而增加了模型剪枝后的检测效率。通过对比,数据增强非常有利于模型精度的提升:由模型C、F 可知,使用数据增强后模型F 的mAP@0.5:0.95 值提高了5.8 个百分点,所以在进行算法优化时使用数据增强操作是必要的。除此之外,对比模型B、D以及模型C、F可知,Slimming可以在一定程度上减少模型的检测速度,数据增强操作会增加模型的检测速度。最后,经过上述三种方法的改进可使优化后的Yolov5n 算法(F 模型,Model-F)在手机使用数据集上的mAP 值提高0.2 个百分点,mAP@0.5:0.95 提高2.4 个百分点,在batch-size=64 的条件下,模型处理图片的时间由2.89 ms缩小到2.30 ms(346 FPS 增加到434 FPS)。Model-F 模型相比其他模型能同时兼具更优的检测精度、计算量、参数量以及较为优秀的检测速度,完全可以进一步实现在移动设备及嵌入式设备上的实时性检测。Model-F模型的检测图例如图5所示。

图5 Model-F模型的检测示例Fig.5 Model-F model detection example
2.4 模型通用性实验
为验证本文提出优化方法的有效性,利用Yolov5n及优化后的算法Model-F 分别在Road Signs Dataset数据集[19]和Pascal VOC 2012 数据集上进行了对比实验,结果如表5 所示。其中,Road Signs Dataset 包含4种类别信息以及真实场景下拍摄的交通标志图片,部分图片识别目标较小,识别难度要高于本文所采用的手机使用数据集;Pascal VOC 2012数据集多为真实场景下的数据,包含多种类信息的同时具有良好的图片质量和完整的标签,多用作模型性能的评估。

表5 Yolov5n与Model-F的对比实验Table 5 Comparison test of Yolov5n and Model-F
通过对比表4 和表5 可知,针对手机使用数据集、Road Signs Dataset、Pascal VOC 2012,Model-F模型的检测精度(mAP)相比原始算法分别提升了0.2、7.5、12.3个百分点;由于驾驶员手机使用的数据集识别目标较大、类别总数较少,Yolov5n算法已经能达到较高的检测精度,所以Model-F模型在该数据集上的精度提升是有限的,而随着识别目标减小、类别数量增多,Model-F 模型在精度上的提升也越大,这进一步说明了该模型改进方法的有效性;Slimming 根据通道的重要程度进行剪枝,因此Model-F 模型在上述三种数据集中所得到的FLOPs 以及Param 不尽相同;在Road Signs Dataset 数据集上,Model-F 的实时性可达411 FPS,相比原算法提升了94 FPS,在Pascal VOC 2012数据集上,Model-F的实时性可达431 FPS,相比原算法提升了90 FPS。通过在Road Signs Dataset、Pascal VOC 2012两种数据集上的对比结果可知,本文提出的方法具有良好的通用性。
3 结语
针对驾驶员手机使用检测实时性不足的问题,结合Slimming 剪枝算法、Focal-EIoU Loss(s)以及数据增强技术,提出了一种兼具轻量化、高精度、实时性的Yolov5n检测模型。经过优化后的Yolov5n模型(Model-F模型)在检测手机使用数据集、Road Signs Dataset 数据集、Pascal VOC 2012 数据集时都能够获得性能上的显著提升,这说明Model-F模型在驾驶员手机使用场景中具有较好的适用性,同时也说明了本文所提出的改进方法具有较好的通用性。由实验可知,Model-F 模型的检测速度可达430 FPS,有利于模型进一步在移动设备及嵌入式设备上的部署及实时性检测。
另一方面,本文通过与其他多种框回归损失函数进行对比,验证了Focal-EIoU Loss(s)能够在本文数据集以及Pascal VOC 2012这种识别目标较大、高质量样本较多的数据集中表现出较高的回归精度与收敛速度。其次,在应用Slimming剪枝技术的过程中,本文对比了常见的网络结构更改方法(Ghost Conv、MobileNet v3-small、ShuffleNet v2),发现这些方法虽然都能有效减少模型的计算量,但也相应地增加了模型的推理时间,不利于模型的实时性,这也表明这种结构的改进并不能一定增加模型的实时性,而应用Slimming 剪枝却能增加一定的实时性,这种对比发现将会对其他算法的改进研究提供一定的思路。
现如今对于驾驶员手机使用的检测模型已经能够达到较为准确的精度,但实时性往往并不理想,未来进一步提高模型在移动设备或嵌入式设备上的实时性检测,这一研究将会备受关注。
猜你喜欢
保健医苑(2022年5期)2022-06-10
数学小灵通·3-4年级(2021年5期)2021-07-16
高技术通讯(2021年3期)2021-06-09
成都信息工程大学学报(2021年6期)2021-02-12
今日农业(2019年15期)2019-01-03
电测与仪表(2017年24期)2017-12-19
北京航空航天大学学报(2017年12期)2017-04-23
天津诗人(2017年2期)2017-03-16
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
